
基于启发式强化学习的多智能体覆盖问题研究
2018-06-13 06:51贺荟霖
现代计算机 2018年14期
贺荟霖
(西南交通大学电气工程学院,成都 611756)
0 引言
覆盖问题是研究多智能体系统的重要课题之一,在搜救、清扫、耕种等领域都有着很大的应用价值。覆盖问题理论上需采用移动机器人或是固定传感器,通过物理接触或者传感器感知的方式来遍历目标区域,尽可能满足重复率、完整率、资源消耗这三方面的优化目标[1]。多智能体覆盖问题主要研究如何有效组织多个智能体进行通信、任务分配和协调工作。文献[1]系统阐述了多机器人覆盖问题的定义、分类和应用,指出了该领域前沿的研究和发展方向;文献[2]提出一种新的方法来规划移动机器人的覆盖路径,从点的覆盖引申到区域的覆盖最终实现工作区的全覆盖;文献[3]针对移动传感网络提出了一种自适应控制率来保证避障的同时完成覆盖任务。
本文主要采用强化学习算法实现未知环境下的多智能体覆盖问题,传统强化学习算法的策略搜索方法采用盲目性搜索方式,智能体通过无限次地对策略进行遍历而学习到最优策略,但因此导致了学习速度慢和计算资源消耗大的问题[4]。目前,启发式搜索与强化学习算法已经得到了一定的结合,成为一种重要的加速学习的手段,比如文献[5]采用启发函数H来指导智能体的动作选择,首先提出一种启发式强化学习算法(Heuristically Accelerated Q-Learning,HAQL)来加速 Q学习收敛,该算法将学习过程分为结构提取和反向传播启发两个阶段,有效加速了强化学习的学习速度。因此,有必要进一步研究启发式强化学习在多智能体覆盖问题方面的应用,以加快多智能体覆盖问题的收敛速度。
1 强化学习算法
Q学习算法作为一种常用的强化学习算法,采用评估函数Qt(st,at)表示在状态st下,执行动作at,该状态-动作对得到的最大的累积折扣回报。该函数有界且迭代逼近Q值,每个状态-动作对作为策略都会被访问有限次。Q值更新规则为:

上式中s表示当前状态,a表示在状态s下采取的动作,r表示得到的立即回报,s'为新的状态,γ为折扣因子(0<γ<1),α为学习率(α>0)。Q学习的动作选择策略一般采用ε-贪婪策略:
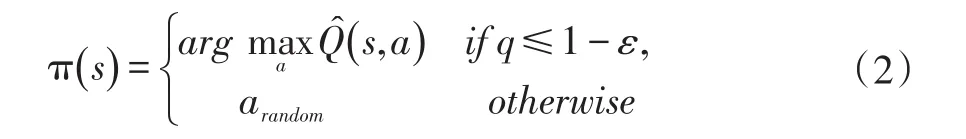
上式中q表示分布于[0,1]的随机数,ε表示探索率,ε越大选择随机探索动作的概率越大,arandom表示当前状态下可选动作集合中的一个随机动作。
2 多智能体启发式强化学习算法设计
鉴于智能体需要迭代估算Q值,策略范围越大就需要越久的时间来试错式地探索状态-动作空间,多智能体强化学习在每个状态下将各智能体选择的动作作为一个联合动作考虑,使得学习过程更加复杂,耗时更久,因此可引入启发式搜索来加速强化学习收敛。启发式强化学习算法在多智能体强化学习过程中采用一个启发函数H:S×→R来影响联合动作,指导动作选择[6]。Ht(st)表示在状态st下执行联合动作→的重要性。因此动作选择策略在式(2)的基础上添加了启发函数的影响,调整为:
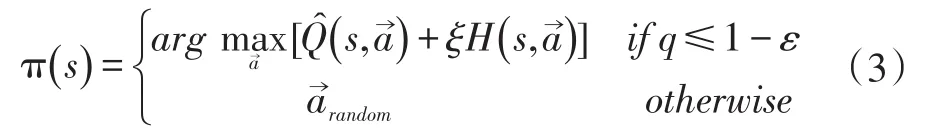
其中ξ为衡量启发函数重要性的实变量。启发函数的定义为:
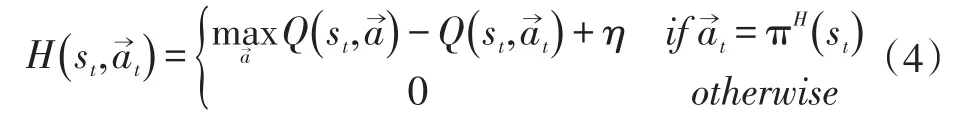
其中η为一个较小的实数,πH表示在启发函数指导下的联合动作。
启发函数的先验知识来源可以是多样的,传统的HAQL算法先验知识来源于多智能体自身的学习经验,学习过程分为两个阶段,第一阶段称为结构提取,在智能体与环境的交互初始阶段,通过探索标记智能体每个动作得到的结果,从而获取一定的环境结构信息,得到状态转移概率的粗略估计;第二阶段称为启发式反向传播,在已获得的结构信息基础上从终态出发反向传播,给出到达这些状态的正确的策略,由此构建启发函数,根据启发的指导进行迭代收敛。
3 基于HAQL的多智能体覆盖算法设计
多智能体覆盖问题的研究主要在于其路径规划算法上,不同的覆盖算法对多智能体的通信方式和环境地图有着不同的要求。对于完全通信的多智能体系统,在未知环境中的覆盖问题,采用启发式强化学习的方式实现覆盖任务,可以用一个四元组模型M=
S,表示智能体所处环境的所有可能状态的集合,它是一个表示环境状态的有限集,采用栅格地图表示环境信息,将环境分解为小栅格,栅格状态分为占用(有障碍物)、未占用(无障碍物)、兴趣点(需遍历的目标点)三种情况,将地图状态存入二维数组;
Ai,表示智能体i能够执行的所有可能动作的集合,每个机器人可选的动作包括上、下、左、右4种,则n个智能体组成的联合动作有4n种,标记为A=A1×…×An;
T,表示状态转移函数,T(s'|s,a)为智能体在状态s下采取动作a,可能转移到状态s’的概率;
R,表示回报函数,表示为S×A→R,是当在状态s下采取动作a所获得的即时回报值R(s,a);
由模型可知,多智能体覆盖问题的强化学习包括环境模型状态表示、动作策略、状态转移和奖惩分配等基本要素,智能体在学习覆盖过程中不断与环境进行交互,所有状态转移组成的序列即为智能体的运动轨迹。对多智能体覆盖问题而言,状态转移过程非常复杂,计算量大且收敛速度慢,因此引入启发式搜索在一定程度上约束策略搜索范围,指导智能体进行动作选择,以加速学习过程。构建启发函数所需的先验知识由智能体事先对环境进行结构提取而得到,基于HAQL的多智能体覆盖算法流程图见图1中,算法分为结构提取和反向传播启发两个阶段。
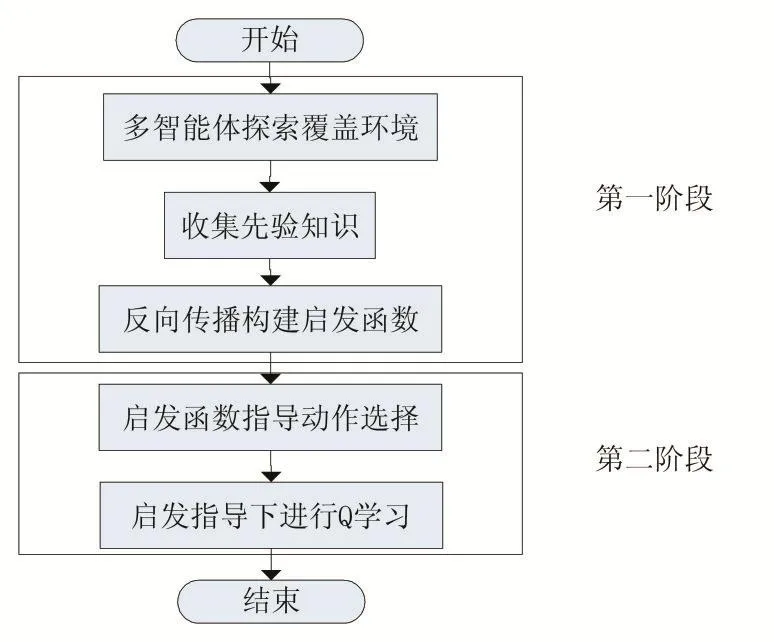
图1 基于HAQL的多智能体覆盖算法流程图
4 仿真结果
为验证本文提出的基于HAQL的多智能体覆盖算法的可行性和有效性,在MATLAB仿真环境中构建如图2所示覆盖地图。在一个10×10的格子世界中,黑色栅格表示边界及障碍物(不可达),其他栅格均可达,其中蓝色栅格表示需要遍历的兴趣点,红、绿栅格分别表示两个智能体的固定起点位置。两智能体的任务是执行联合动作寻找合适的策略最终成功遍历四个兴趣点。
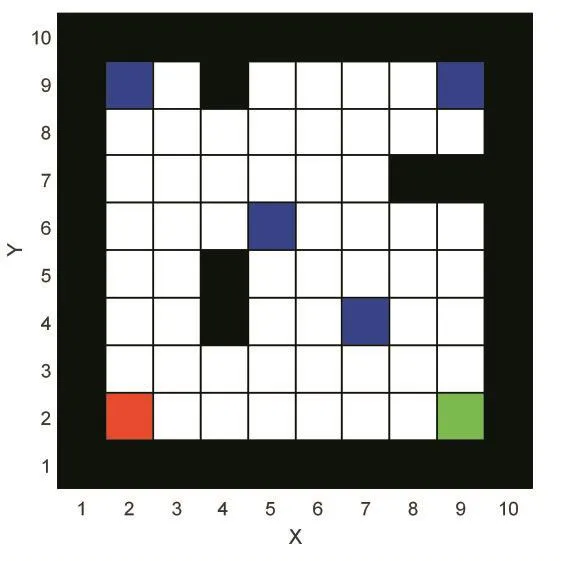
图2 多智能体覆盖仿真环境
对智能体而言,环境的边界、障碍和兴趣点的位置事先均未知,需要在探索的过程中不断学习环境信息。智能体执行动作到达兴趣点时获得回报值100,遇到边界、障碍或其他智能体时获得回报值-1,到达其余位置时回报值为0。若一次任务执行步数超过500步还未遍历全部兴趣点则认为覆盖失败,开始新一幕实验。实验相关参数设置如表1所示。
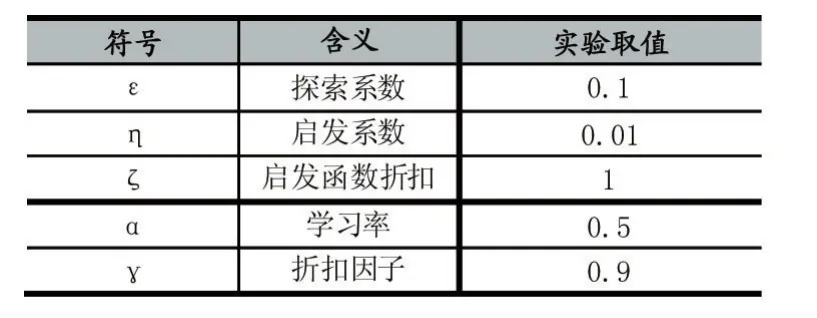
表1 仿真实验参数设置表
基于HAQL的多智能体覆盖算法可以在经过一定学习幕数后达到收敛,图3给出了算法收敛后其中一幕覆盖任务的完成情况,图中红色与绿色的线段分别反映了两智能体在此次覆盖过程中走过的路径,可以看出多智能体通过联合动作选择成功地遍历到四个兴趣点,成功完成了覆盖任务。
针对相同的多智能体覆盖仿真环境,分别采用传统的Q学习算法和启发式的HAQL算法进行实验,实验主要从覆盖问题收敛速度和达到收敛后完成实验所需步数的角度考察实验效果。实验结果有着明显不同的学习表现,算法对比图如图4所示。横轴表示学习幕数,纵轴表示每一幕学习完成覆盖任务所需步数。实际实验步数对比和拟合曲线对比均可明显看出两种算法在经过一定的学习幕后都能收敛到稳定的策略,即步数。实验设置HAQL算法在前20幕进行结构提取,此时的动作选择策略与Q学习相同,在第21幕时根据已获知的环境信息构建启发函数,在启发函数的指导下进行动作选择,因此在21幕后学习步数骤降,有效加速了强化学习进程,更快地达到覆盖问题的收敛,并在达到收敛后与Q学习算法有着不相上下的覆盖效果,即最终收敛步数相似。

图3 基于HAQL的多智能体覆盖结果
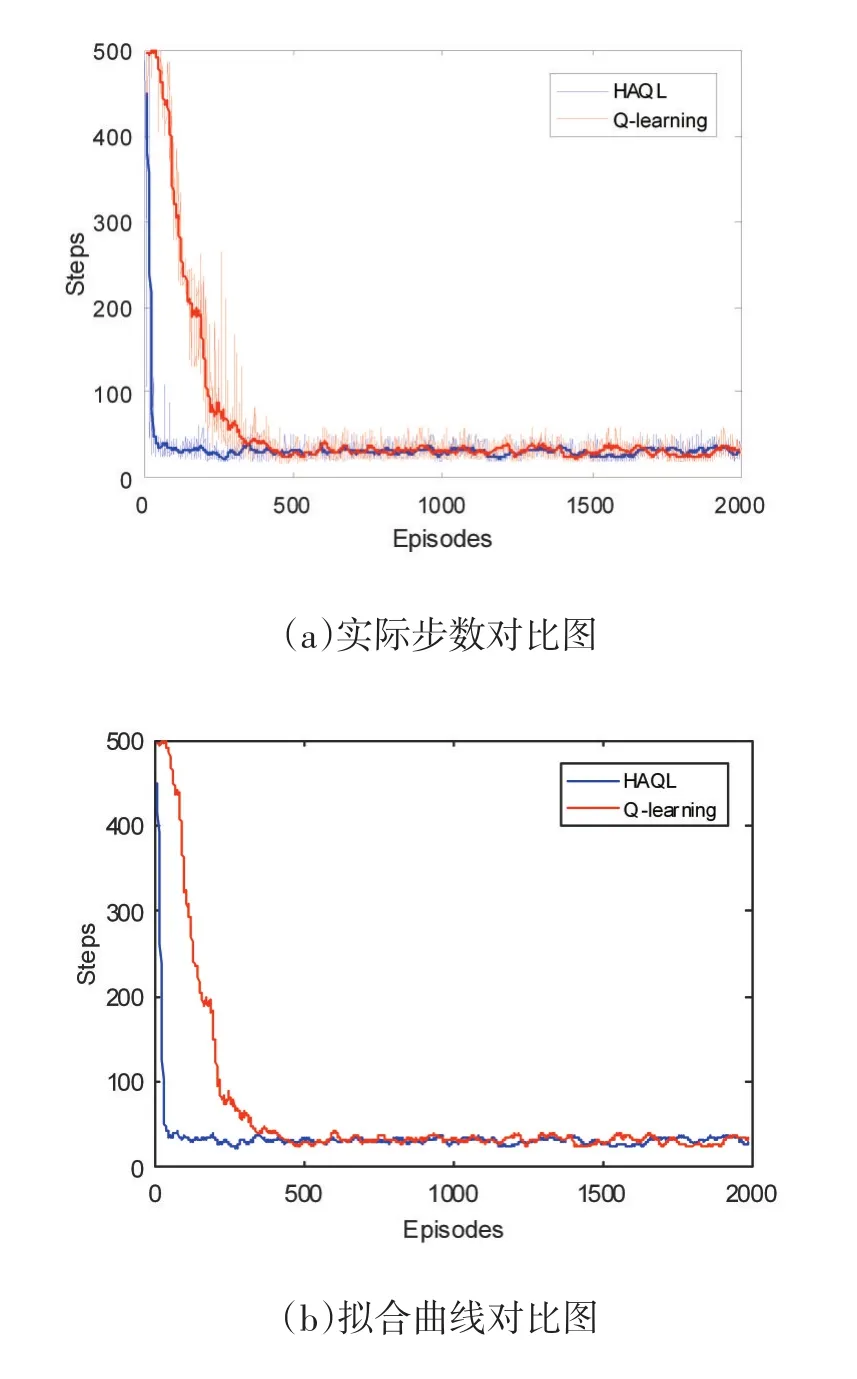
图4 多智能体覆盖算法对比图
通过10次实验取平均收敛幕和收敛步数,对比结果如表2所示,收敛幕表示从该幕起算法达到收敛,反映学习速度;收敛步数表示学习收敛后平均完成一次覆盖任务所需步数,反映学习策略。从数据的角度可以明显看出HAQL算法优化了强化学习进程收敛速度的同时,保持了收敛后与Q学习算法相近的覆盖效果。

表2 两种学习算法效果数据对比
5 结语
本文提出了一种基于启发式强化学习的多智能体覆盖算法,在传统强化学习算法中引入启发函数指导多智能体联合动作的选择,先验知识来源于智能体自身对环境的结构提取,通过仿真实验对比验证了算法在多智能体覆盖问题中能有效加速强化学习进程且不影响最终收敛后的覆盖效果,成功降低了覆盖问题的资源消耗。
[1]蔡自兴,崔益安.多机器人覆盖技术研究进展[J].控制与决策,2008,23(5):481-486.
[2]Bretl T,Hutchinson S.Robust Coverage by a Mobile Robot of a Planar Workspace[R].Karlsruhe,Germany,IEEE International Conference on Robotics and Automation(ICRA),2013.
[3]Hussein I,Stipanovic D M.Effective Coverage Control for Mobile Sensor Networks With Guaranteed Collision Avoidance[J].IEEE Transactions On Control Systems Technology,2007,15(4):642-657.
[4]Wiering M,Otterlo V M.Reinforcement Learning:State-of-the-art[M].New Yord:Springer,2012:27-34.
[5]Bianchi R A C,Ribeiro C H C,Costa A H R.Heuristically Accelerated Q-Learning:a New Approach to Speed Up Reinforcement Learning[C].SBIA.2004:245-254.
[6]Bianchi R A C,Martins M F,Ribeiro C H C,et al.Heuristically-Accelerated Multiagent Reinforcement Learning[J].IEEE Transactions on Cybernetics,2014,44(2):252-265.
猜你喜欢
重庆理工大学学报(自然科学)(2022年1期)2022-02-18
北京航空航天大学学报(2021年5期)2021-06-09
奇妙博物馆(2021年4期)2021-05-04
小学生作文(低年级适用)(2019年5期)2019-07-26
小演奏家(2018年9期)2018-12-06
大科技·C版(2018年11期)2018-10-21
读友·少年文学(清雅版)(2018年12期)2018-04-04
党的生活(黑龙江)(2017年10期)2017-11-09
汽车文摘(2016年1期)2016-12-10
山东青年(2016年3期)2016-02-28
