
基于用户和产品Attention机制的层次BGRU模型
2018-06-01 10:50郑雄风丁立新万润泽
计算机工程与应用 2018年11期
郑雄风,丁立新,万润泽
ZHENG Xiongfeng,DING Lixin,WAN Runze
武汉大学 计算机学院,武汉 430072
School of Computer Science,Wuhan University,Wuhan 430072,China
随着互联网技术的高速发展,网络上产生大量用户参与的,针对热点事件、产品等有价值的评论文本信息,比如,微博、电商平台、餐饮平台等等。这些评论信息包含了人们丰富的情感色彩和情感倾向。情感分析的目的就是自动地从文本中提取和分类用户针对产品或事件的主观情感信息,帮助商家或者政府部门完成数据分析和舆情监控等任务。因此,情感分析也成为了自然语言处理领域的重要课题之一。情感分析分为情感信息的抽取、情感信息的分类以及情感信息的检索与归纳[1]。本文解决的主要是文档级别的情感信息分类问题。文档级别的情感信息分类任务主要是为了自动分类出用户产生的情感文本中针对某一产品或事件表达的情感倾向(积极或者消极)或者情感强度(如电影或者餐厅评论文本中的1~5星评价)。
目前的大多数方法将情感分类看作文本分类问题的一种。通过机器学习的方法,将情感倾向或者情感评分当作有监督的数据,训练分类器对文本情感进行分类成为一种主流的方法。机器学习中的特征表示是影响分类器效果的重要因素,因此,文本情感语义的特征表示成为文本情感分类问题中的关键且耗时的一步。传统的特征表示方法包括One-hot、N-Gram以及领域专家通过文本或者额外的情感词典设计的一些有效特征[2-4]。在SemEval2013评测任务中取得第一名的系统就是设计了有效的特征达到的[5]。然而,特征工程是一个劳动密集型的任务,且需要较多的领域知识。因此,特征的自动学习渐渐成为人们研究的重点。基于神经网络的深度学习方法就是自动学习特征的一种方法[6]。并且随着深度学习在计算机视觉、语音识别和自然语言处理等领域的成功应用,越来越多的基于深度学习的文本情感分类模型产生,这些模型普遍地利用词嵌入(Word Embedding)的方法进行特征表示[7],这种低维度词向量表示方法不仅能很好地解决传统语言模型中词表示中存在的维度过大的问题,而且,能很好地保留词的语义信息,使得语义相似的词距离更近。另外,在词嵌入的基础上,通过卷积神经网络(CNN)[8-10]、递归神经网络(Recursive Neural Network)[11-12]和循环神经网络(Recurrent Neural Network)[13-14]等神经网络模型,能很好地表示句子或者文档级别的语义信息,由于深度学习具有良好的特征自动抽取能力,从而在文本情感分类问题中得到了广泛的应用。
然而,目前大多数基于神经网络的文本情感分类模型只考虑了文本内容相关的情感语义,忽略了与文本相关的用户信息以及文本内容所描述的产品信息。同时,有研究表明,用户的喜好与产品的特点对于用户的评分有着重要的影响[15]。因此,唐都钰等人首先提出了通过矩阵和向量的形式将用户喜好和产品信息加入文本情感分类模型的方法[16-17],陈慧敏等人在此基础上,提出了一些改进方案[18]:以向量来表示用户和产品信息,同时,通过Attention的方法将用户和产品信息与文本语义信息结合,该方法在一定程度减少模型参数的同时,使得文本中语义信息更加丰富。但是,这两种方法都是随机初始化用户和产品信息,然后在模型训练过程中更新用户和产品的参数信息。这样的方法得到的用户和产品信息并不一定准确,同时会使得模型参数过大,导致模型的训练速度过慢,甚至导致模型过拟合。为了解决这个问题,文献[19]提出了另外一种生成用户喜好和产品信息的方法,首先将原始数据按照用户和产品分组,然后按照相应的事件顺序排序,然后应用循环神经网络(RNN)模型分别得到用户和产品信息的特征表示。最后将得到的用户和产品信息特征表示和文本的特征表示结合到一起作为分类器的输入特征。虽然解决了用户和产品信息特征表示的问题,但其中的文本情感语义表示模型过于简单,不能有效地将文本中的上下文语义信息与用户和产品信息结合。受到文献[18-19]的启发,同时为了解决当前方法中的问题,本文提出了两个改进方案:
(1)本文改进了文献[18]中的文本语义表示模型,利用双向的GRU模型代替原有的简单模型,结合文档-句子和句子-词的层次模型,更加有效地结合了文本中的上下文语义信息,整体的模型架构如图1所示。
(2)针对用户和产品的评价数据,首先利用奇异值分解(SVD)的方法,得到用户和产品的先验信息,作为预训练好的模型参数,避免了用户和产品信息的参数增加。然后利用基于Attention的神经网络模型将用户和产品信息结合到文本上下文语义的表示中,使得文本的情感语义信息更加准确。
1 基于层次神经网络模型的文本情感分类模型
这部分主要介绍基于层次神经网络的文本情感分类模型中3个重要的步骤:文档特征表示、基于Attention机制的用户和产品信息及文本情感分类模型。首先介绍如何通过层次神经网络模型由词向量得到句子级别的特征表示,再由句子级别特征表示得到文档级别的特征表示,然后介绍通过Attention机制将用户和产品信息与文本情感语义结合的方法,最后将得到的文档级别特征表示作为文本分类器的特征,完成文本情感分类的任务。
1.1 基于层次结构的文本特征表示
研究表明,句子或者文档级别的语义由它们所包含的词的语义和词结合的方式决定的,而文档主要由句子组成,句子主要由词组成。因此,首先得到词的特征表达,也就是词嵌入(Word Embedding),然后在词嵌入的基础上,通过卷积神经网络(CNN)、递归神经网络(Recursive Neural Network)或者循环神经网络(Recurrent Neural Network)的深度学习模型,得到句子级别的特征表示。同理,在句子级别的特征表示基础上,得到文档级别的特征表示。
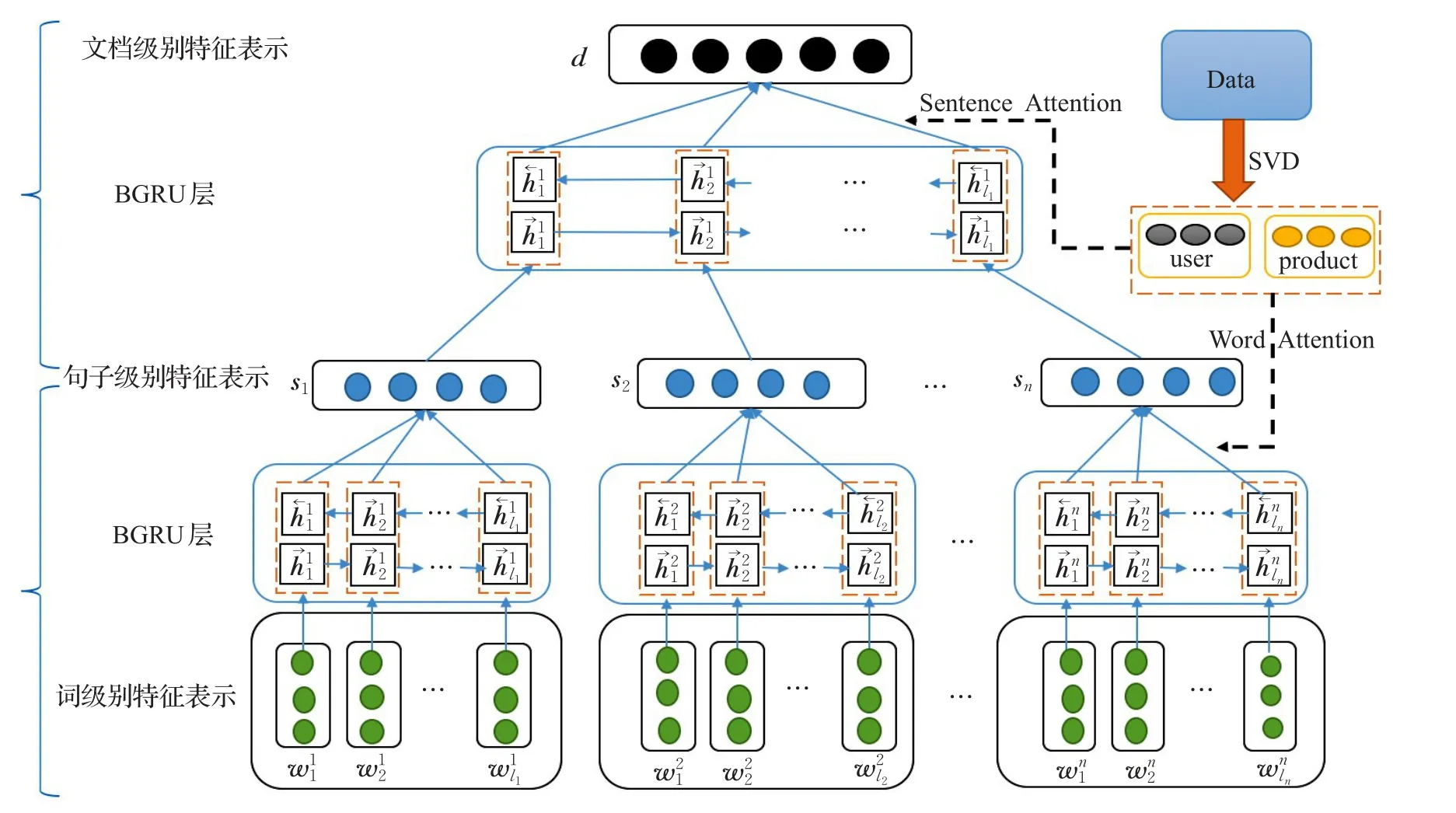
图1 基于用户和产品Attention的神经网络模型结构
假设用户u∈U有一条关于产品 p∈p的评价文本d∈d,文本d由n条句子{s1,s2,s3,…,sn}组成,其中第i个句子由li长度的词组成{,,…,}。
在词级别的语义特征表示中,所有的词是通过一个词嵌入矩阵Lw∈Rd×|V|来表示,其中,d表示词的维度,|V |是所有词的数量。Lw中的词向量∈Rd可以通过两种方法生成:
(1)随机初始化,并作为整个模型的参数的一部分,参与到模型的训练过程中,是一种简单可行的方法。
(2)结合语料,通过word2vector[7],glove[20]等词嵌入方法预训练生成。
在句子级别的语义特征表示中,通过词向量建模句子级别的语义特征时,有两种结构:树结构[21-22]、层次结构[23]。目前,由于句子或者文档中存在的序列结构,因此序列模型(如RNN等)正广泛地用于自然语言处理,特别是句子或者文档的特征表示中[24]。LSTM模型是RNN模型的一种,是为了解决RNN模型中出现的长距离依赖和梯度消失问题提出的。文献[18]就是采用层次结构,基于简单的LSTM模型分别得到句子和文档的语义特征。LSTM模型将句子中每个词作为序列模型中的神经元,词向量神经元的状态和隐藏状态是利用上一个词向量的神经元状态和隐藏状态来更新的。最后,为了在词向量的基础上得到句子的特征表示,可以利用LSTM模型的最后一个词向量的隐藏状态作为句子的特征表示,或者是利用LSTM模型中所有隐藏层状态取平均作为句子的特征表示。
同理,在文档级别的特征表示中,将文档的每个句子作为LSTM中的序列单元,利用同样的方法,就能得到文档级别的语义特征,作为最终文本分类器的特征输入,就能得到文档的情感分类。
1.2 基于用户和产品Attention模型的文本语义特征
在文本情感分析任务中,与文本相关的用户和产品信息是文本情感分类的重要影响因素[19]。用户的偏好特性会影响用户文本中情感的极性,同时,不同品质产品得到的文本情感极性也会大不相同。唐都钰等人在文献[16]中提出,利用矩阵建模用户和产品的偏好对文本情感的影响。通过实验验证了用户和产品信息对文本内容和文本情感分类的重要性。但是,由于用户和产品矩阵信息会有很大的稀疏性,很难得到比较准确的用户和产品信息。因此,本文提出利用用户和产品向量建模用户和产品偏好对文本情感的影响。另外,基于LSTM得到的文本语义特征有个重要的缺点,那就是序列后面的神经元比序列前的神经元在最后的特征表示中所占权重更大。特别是在文档级别的语义中,往往,有些文档前面的句子比后面的更重要。而采用取平均的方法得到的句子或文档表示能一定程度上缓解这个问题,但会导致所有序列单元所代表的权重一样。而实际情况是不同的词在句子的语义特征表示中所占有的权重是不一样的。
而注意力(Attention)机制是通过文献[25]开始得到了广泛关注,起初注意力机制是被用于图像分类中。文献[26]提出了将注意力机制用于机器翻译的方法,自此,注意力机制开始应用在自然语言领域。由于注意力机制是对人脑注意力的一种模拟,通过自动加权的模型实现,因此,在神经网络模型中越来越流行[27]。本文提出将注意力机制引入文本特征表达中,如图2所示,X表示词向量特征,S表示句子的语义特征,注意力机制在生成句子的语义特征时,是将X的GRU单元通过a加权得到,a的几何意义就是不同词在句子的语义特征表示的重要性,a越大表示这个词在句子中的情感语义更重要。
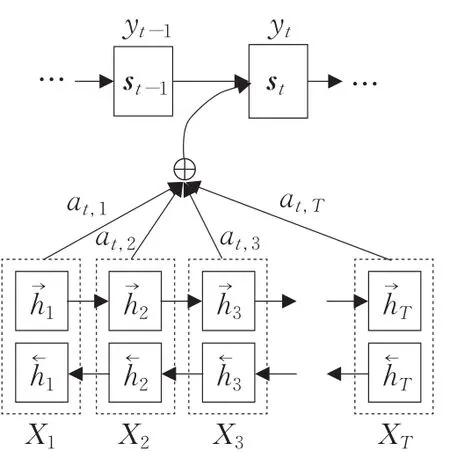
图2 基于Attention机制的句子级别语义特征结构
因此,本文提出将带有用户和产品信息的向量通过Attention的方法,结合层次BGRU模型,在得到文本的语义特征时,选择与用户和产品相关度较高的词或者句子参与到下一步的计算中。这样,就能得到更准确的文本语义特征。如图1所示,word attention用于在句子级别的语义特征表示中,结合用户和产品偏好信息赋予语义更相关的词更大的权重,sentence attention用于在文档级别的语义特征表示中,结合用户和产品偏好信息赋予语义更相关的句子更大的权重。通过这种层次结构的语义关系生成,同时结合用户和产品信息,就能得到更准确的文本语义特征作为文本分类器的特征输入。具体计算过程如下:
假设用户和产品信息分别通过向量u∈Rdu和p∈Rdp来表示,其中du和dp分别表示用户和产品向量的维度。
在句子级别的文本语义特征表示中,假设si表示通过Attention方法得到的句子语义特征,那么


其中,e是计算词的重要性程度的函数:

其中,WH、WU和WP是参数矩阵,v是参数向量,vT是v的转置向量。
在文档级别的文本语义特征表示中,假设d是通过Attention方法由文本中的句子级别的特征得到的文档级别的特征表示,那么:

其中,βi是句子级别特征表示序列中第i个隐藏层状态hi,计算方法与一致。最终得到的d就是新的文本语义特征表示。
1.3 基于Softmax的文本情感分类
在第1.2节中得到的文档级别的特征表示d可以直接作为文本分类器的特征输入。首先通过一个非线性层(sigmoid,relu,tanh)将d 映射到维度为C 的空间,C是文本分类器中类别的数目,计算公式:

然后,利用softmax分类器,得到文本情感分类分布,计算公式:

其中,pc是文本情感类别为c的预测概率。本文使用交叉熵损失函数作为模型训练的优化目标,通过Back-Propagation方法计算损失函数梯度同时更新模型参数,Back-Propagation计算公式:

其中,D是训练数据集;是文本情感分类为c的0-1分布,即,如果文本情感分类为c,那么的值为1,否则的值为0。
2 基于层次BGRU的语义组合模型
2.1 LSTM模型与GRU模型
Long Short Time Memory(LSTM)模型与Gated Recurrent Unit(GRU)模型都是循环神经网络模型的一种,GRU模型是LSTM模型的一种改进。如图3所示,i,f,o 表示LSTM中的input,forget,output三种门机制,r,z表示GRU模型中的reset和update两种门机制[28]。通过门机制的优化,GRU模型参数量更少,在保证模型效果的同时,很好地简化了模型,在很多场景下得到了广泛的应用[18,29]。
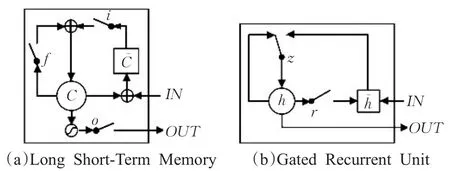
图3 LSTM与GRU的门机制结构
另外,GRU模型更新神经元状态的方法也与LSTM略有不同,GRU模型神经元状态计算框架如图4所示。
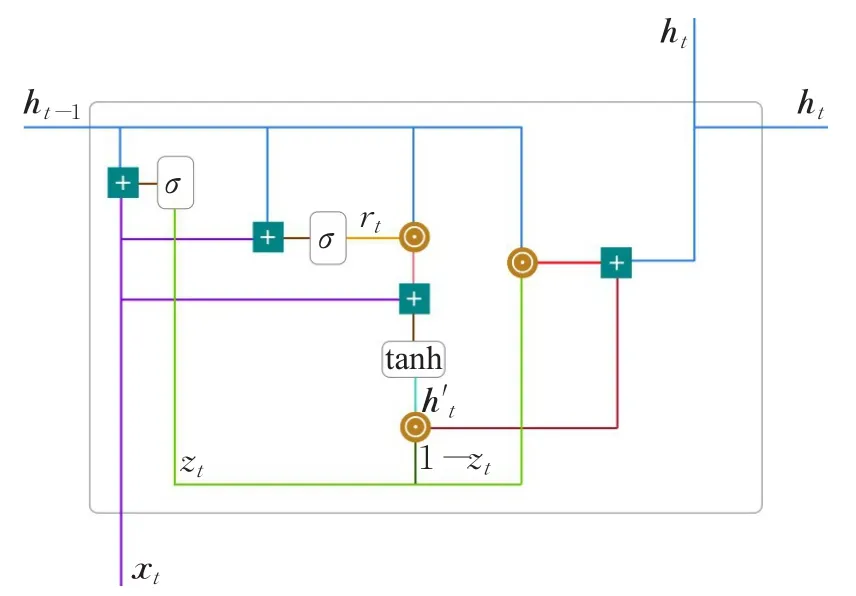
图4 GRU模型结构图
在t时刻,GRU中的状态通过下列公式计算:

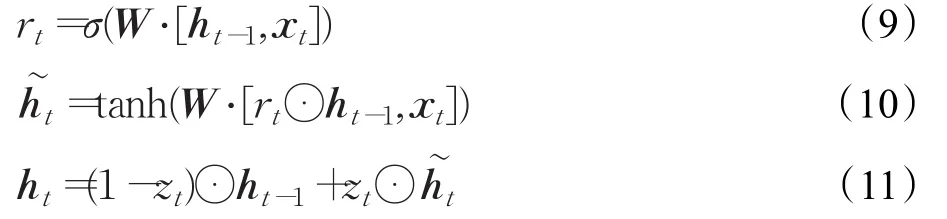
其中,zt,rt分别是update,reset门机制函数,⊙表示矩阵对应元素相乘,σ表示sigmoid函数,W表示GRU模型共享的参数。
2.2 基于双向GRU得到句子级别的特征
单向RNN模型在表示文本上下文语义中存在不足,在模型训练过程中会导致权重的偏差。双向循环神经网络(BRNN)的基本思想是提出每一个训练序列向前和向后分别是两个循环神经网络(RNN),而且这两个都连接着一个输出层。这个结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息。所以,本文提出利用双向的GRU来建模句子和文档级别的语义特征。双向GRU就是在隐层同时有一个正向GRU和反向GRU,正向GRU捕获了上文的语义特征信息,而反向GRU捕获了下文的语义特征信息,这样相对单向GRU来说能够捕获更多的特征信息,所以通常情况下双向GRU表现比单向GRU或者单向RNN要好,得到的上下文语义特征更加准确。
假设一个句子si中有T个词,每个词为,t∈[0,T],将句子si看作一个序列,句子中的词为句子序列的组成部分。那么,分别通过前向GRU和后向GRU模型就能得到句子的表达。
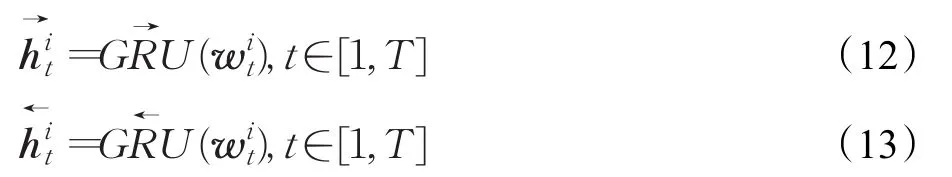
通过结合得到句子si的语义表示:

2.3 基于双向GRU得到文档级别的特征
同理,假设一个文档d中有L个句子,每个句子为si,i∈[0,L],将文档d当作一个序列,文档中的句子为文档序列的组成部分。通过前向GRU和后向GRU模型分别得到文档级别的特征表示:


通过结构就能得到最终的文档级别的语义特征。

将前向GRU和后向GRU得到的结果合并到一起作为最终的句子或文档的特征表达,这样通过上下文共同产生的语义特征更加准确,并且可以直接作为最终文本情感分类器的特征。
3 基于SVD的用户和产品向量
3.1 用户和产品向量初始化
在文本情感分析任务中,与文本相关的用户和产品信息是文本情感分类的重要影响因素。因此,用户和产品向量的初始化对于模型的最终效果也同样重要。其中一种方式是随机初始化用户和产品向量,并作为整个模型的参数的一部分,参与到模型的训练过程中。但这样会导致模型的参数量过大,训练速度慢,甚至可能产生过拟合,从而影响了模型的效果。因此,为了得到准确的用户和产品初始化向量,本文提出通过奇异值分解(SVD)的方法,利用用户和产品的评论信息,得到用户和产品的向量作为模型的先验信息,一方面避免了增加大量的模型参数,另一方面,在有足够数据集的情况下,通过SVD得到的用户和产品信息更加准确,语义信息更加丰富,最终提高模型的收敛速度和准确率。
3.2 基于SVD的用户和产品向量
假设用户-产品矩阵为c,如表1所示,对应的值为用户对产品的评分值,空白部分说明用户对相应的产品没有评分。一般的用户-产品矩阵维度很大,相应的计算量和所需的存储空间都很大。如表2所示,Yelp2014数据集中,用户和产品维度分别为4 818和4 194。SVD就是一种不丢失原有矩阵信息的矩阵分解方法。同时,SVD能得到相应的用户和产品在低维度的潜在语义的向量表示,作为用户和产品向量的初始化值。

表1 用户-产品矩阵c
利用SVD计算用户-产品矩阵c的k-秩近似矩阵xk。其中,xk可以表示成三个矩阵的乘积:xk=UkΣk。通过这种方法,可以将用户-产品矩阵中用户和产品分别映射到低维度的uk和vk中,从而得到一个比原始空间小得多的更加有效的语义空间。uk和vk作为初始化的用户和产品向量,语义相近的用户向量距离越近,语义相似的产品向量距离更近。具体对比结果见实验部分。另外,本文通过对不同k值下用户-产品矩阵信息的保证验证,取k值为100时,能保留原始矩阵99%的信息,同时也有效地降低了用户和产品向量的维度。
4 实验
实验部分通过三个数据验证了本文提出的方法在文本情感分类任务中的有效性。分别从两方面对比本文提出的方法作出了验证:一是通过文档级别的文本分类任务的准确率对比,验证了基于用户和产品信息的模型有效性;二是通过对比不同的用户和产品信息初始化方法,验证了本文引入的SVD方法有效性。
4.1 实验数据及模型实现
实验数据来自于:IMDB、Yelp2013、Yelp2014[16]。IMDB是用户对电影的评分数据,Yelp2013和Yelp2014是用户对商家的评分数据。具体统计信息如表2所示。实验的评价标准有分类准确率(Accuracy)和平方根误差(RMSE),本文的所有实验均在如表3所示的实验环境中完成。
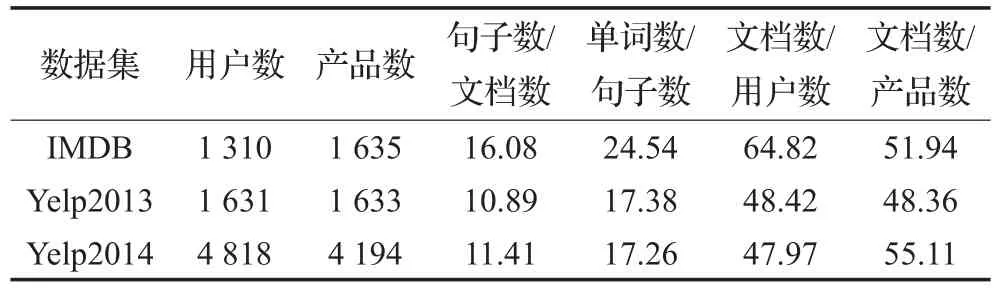
表2 IMDB,Yelp2013和Yelp2014数据集的统计信息
表3 实验环境及配置
(1)数据预处理:原始文本数据使用斯坦福CoreNLP工具进行分词处理得到训练样本,另外,数据按照8/1/1得到训练数据集/验证数据集/测试数据集。实验中超参数通过验证数据集调整,模型分类准确率和平方根误差通过测试集得到。
(2)词向量训练:本文使用word2vector工具,结合相应的实验数据作为语料,得到词向量,词向量的维度为200,不参与模型的训练。根据文献[30]的研究,语料的选择,是生成好的词向量的关键,因此本文利用相应的实验数据(IMDB,Yelp)作为语料,能得到更准确的语义信息。
(3)层次BGRU模型的实现:利用tensorflow 0.11.0的RNN模块实现了基本的GRU单元,输出的语义特征维度为50,在此基础上搭建了层次结构的双向GRU神经网络模型,输出的语义特征维度为100。使用随机梯度下降的方法更新神经网络模型中的参数,相应的学习率设为0.01。
(4)层次BGRU模型的训练:基本的GRU单元输出的语义特征维度为50,双向GRU神经网络模型输出的语义特征维度为100,使用随机梯度下降的方法更新神经网络模型中的参数,相应的学习率设为0.01。
(5)训练过程数据序列化:训练过程中的中间数据通过tensorflow 0.11.0的summary模块序列化,最终通过Excel工具得到如图5中所示的曲线对比图。
4.2 实验对比
本文选取了一些方法作为对比实验:
(1)SVM:根据文本和情感词典设计特征,然后训练SVM分类器得到相应的准确率和平方根误差值。
(2)Paragraph Vector:处理文档级别的情感分类的利用神经网络模型的经典方法。
(3)UPA+LSTM:陈慧敏等人[18]实现的层次LSTM结合User和product Attention的方法,也是本文的主要对比文献。
(4)UPA+GRU:为了验证标准GRU模型的有效性,用GRU模型代替实验3中的LSTM模型。
(5)SVD+GRU:为了验证双向GRU模型的有效性。
(6)SVD+BGRU模型:本文提出的模型。
4.3 实验结果与分析
所有实验结果如表4所示,从实验结果中可以看出:
(1)用户和产品信息在情感分类中的有效性。
从实验1、2中采用的是传统的机器学习模型、SVM和Paragraph Vector,实验3、4、5、6采用的是基于用户和产品的神经网络模型,从实验结果对比中可以看出,因为引入了更多的语义信息,在分类准确率方面后者有了10%提升,验证了用户和产品信息在文本情感分类中的重要性。同时,本文提出的基于SVD的方法得到的用户和产品信息更加准确,在所有实验数据中达到最高分类准确率。
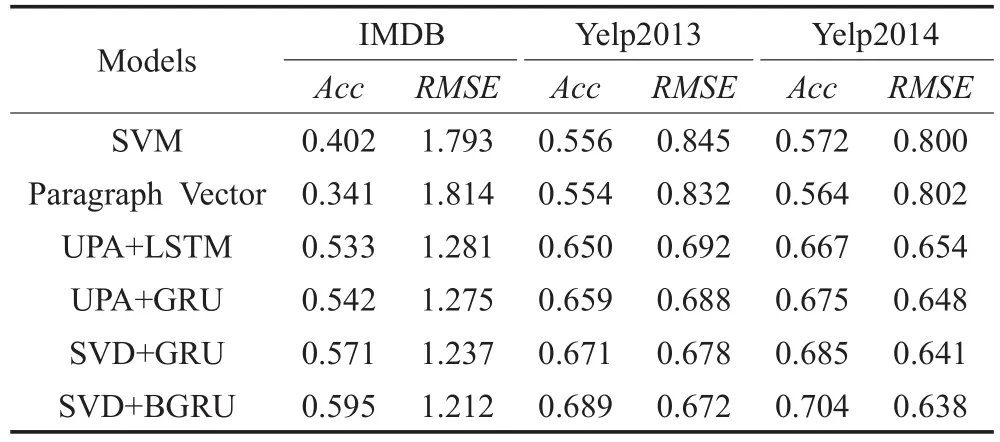
表4 实验结果比较表
(2)基于SVD方法的有效性。
从三个不同实验数据的结果可以看出,基于SVD的方法在IMDB数据中取得的准确率提升最大,接近4%,而Yelp2013和Yelp2014数据的准确率提升只有2%左右,原因是IMDB数据的用户和产品的信息更加丰富。相应的实验数据统计信息如表2所示,IMDB数据中,每个用户平均的文档数是64.82,而Yelp2013和Yelp2014的平均文档数分别是48.42和47.87。这一结果同时也验证了基于SVD方法得到的用户和产品信息在文本情感分类的有效性。
(3)双向GRU模型的有效性。
对比实验3和实验4的结果,可以看出,GRU模型在文本特征抽取中要略优于LSTM模型,准确率普遍提升1%,且GRU模型结构更简单,模型参数更少,可以降低整体的模型效率。同时,对比实验5和实验6的结果,可以看出,相比于标准GRU模型,双向的GRU模型在最终模型分类准确率上有2%的提高。验证了双向GRU模型在文本上下文语义结合中的有效性。
4.4 实验迭代次数的验证
为了验证SVD在减少模型参数,提高模型训练速度的有效性,以IMDB为实验数据,在SVD+BGRU模型的基础上,不改变其他参数,本文做了相应的对比实验,实验1采用随机初始化用户和产品信息,并参与到模型的训练过程中。实验2使用SVD得到用户和产品的信息作为先验信息,不参与到模型的训练过程中,具体的实验结果见图5。
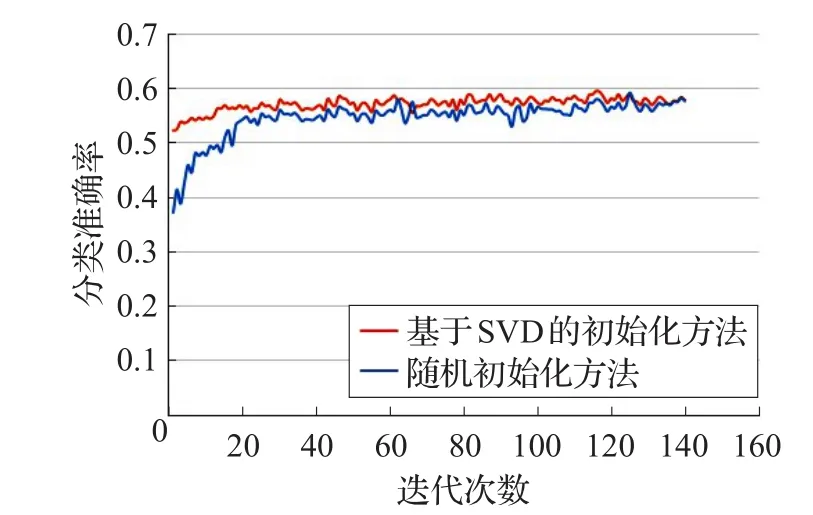
图5 IMDB实验中迭代次数与分类准确率的关系
从分类准确率与迭代次数的曲线图可以看出,本文提出的基于SVD方法产生的用户和产品的先验信息在迭代开始时就取得了接近最高的准确率,验证了SVD方法得到的用户和产品信息的准确性,同时,基于SVD初始化的方法在较少的迭代次数下就达到了最优,验证了SVD方法在提高模型训练速度的有效性。
5 结束语
本文提出了一种基于奇异值分解(SVD)来得到文本中用户和产品先验信息作为神经网络Attention信息的方法,同时引入双向GRU模型作为层次神经网络中的语义组合模型。在用户和产品数据足够的情况下,相较其他方法,SVD能得到更加准确的用户和产品语义信息,在保证模型分类准确同时,减少了模型训练中参数的数量,提高模型的训练效率。在层次神经网络的模型结构基础上,BGRU模型代替常用的LSTM,得到了更加丰富的上下文信息,作为文本情感分类器的特征。提高了最终分类器的效果。另外,如何在用户和产品数据不足,特别是新用户或者新产品的情况下,保证模型的分类效果值得进一步的研究。
参考文献:
[1]赵妍妍,秦兵,刘挺,等.文本情感分析[J].软件学报,2010,21(8):1834-1848.
[2]李婷婷,姬东鸿.基于SVM和CRF多特征组合的微博情感分析[J].计算机应用研究,2015,32(4):978-981.
[3]Ding X,Liu B,Yu P S.A holistic lexicon-based approach to opinion mining[C]//International Conference on Web Search and Data Mining,2008:231-240.
[4]Taboada M,Brooke J,Tofiloski M,et al.Lexicon-based methods for sentiment analysis[J].Computational Linguistics,2011,37(2):267-307.
[5]Mohammad S M,Kiritchenko S,Zhu X.NRC-Canada:Building the state-of-the-art in sentiment analysis of tweets[J].Computer Science,2013.
[6]Lecun Y,Bengio Y,Hinton G.Deep learning[J].Nature,2015,521(7553).
[7]Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality[J].Advances in Neural Information Processing Systems,2013,26:3111-3119.
[8]Collobert R,Weston J,Karlen M,et al.Natural language processing(almost) from scratch[J].Journal of Machine Learning Research,2011,12(1):2493-2537.
[9]Kim Y.Convolutional neural networks for sentence classification[J].arXiv preprint arXiv:1408.5882,2014.
[10]Kalchbrenner N,Grefenstette E,Blunsom P.A convolutional neural network for modelling sentences[J].Eprint Arxiv,2014.
[11]Socher R,Huval B,Manning C D,et al.Semantic compositionality through recursive matrix-vector spaces[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,2012:1201-1211.
[12]Socher R,Perelygin A,Wu J Y,et al.Recursive deep models for semantic compositionality over a sentiment treebank[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing(EMNLP),2013.
[13]Wang X,Liu Y,Sun C,et al.Predicting polarities of tweets by composing word embeddings with long shortterm memory[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing,2015:1343-1353.
[14]Teng Z,Vo D T,Zhang Y.Context-sensitive lexicon features for neural sentiment analysis[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing,2016:1629-1638.
[15]Gao W,Kaji N,Yoshinaga N.Collective sentiment classification based on user leniency and product popularity[J].Journal of Natural Language Processing,2014,21(3):541-561.
[16]Tang D,Qin B,Liu T.Learning semantic representations of users and products for document level sentiment classification[C]//Meeting of the Association for Computational Linguistics and the International Joint Conference on Natural Language Processing,2015:1014-1023.
[17]Tang D,Qin B,Liu T,et al.User modeling with neural network forreview rating prediction[C]//International Conference on Artificial Intelligence,2015:1340-1346.
[18]Chen H,Sun M,Tu C,et al.Neural sentiment classification with user and product attention[C]//Proceedings of EMNLP,2016.
[19]Chen T,Xu R,He Y,et al.Learning user and product distributed representations using a sequence model for sentiment analysis[J].IEEE Computational Intelligence Magazine,2016,11(3):34-44.
[20]Pennington J,Socher R,Manning C.Glove:Global vectors for word representation[C]//Conference on Empirical Methods in Natural Language Processing,2014:1532-1543.
[21]Mou L,Peng H,Li G,et al.Discriminative neural sentence modeling by tree-based convolution[J].arXiv preprint arXiv:1504.01106,2015.
[22]Tai K S,Socher R,Manning C D.Improved semantic representations from tree-structured long short-term memory networks[J].Computer Science,2015.
[23]Yang Z,Yang D,Dyer C,et al.Hierarchical attention networks for document classification[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,2016.
[24]胡新辰.基于LSTM的语义关系分类研究[D].哈尔滨:哈尔滨工业大学,2015.
[25]Mnih V,Heess N,Graves A,et al.Recurrent models of visual attention[J].Computer Science,2014,3:2204-2212.
[26]Bahdanau D,Cho K,Bengio Y.Neural machine translation by jointly learning to align and translate[J].arXiv preprint arXiv:1409.0473,2014.
[27]张冲.基于Attention-Based LSTM模型的文本分类技术的研究[D].南京:南京大学,2016.
[28]Chung J,Gulcehre C,Cho K H,et al.Empirical evaluation of gated recurrent neural networks on sequence modeling[J].Eprint Arxiv,2014.
[29]Tang D,Qin B,Liu T.Document modeling with gated recurrent neural network for sentiment classification[C]//Conference on Empirical Methods in Natural Language Processing,2015:1422-1432.
[30]来斯惟.基于神经网络的词和文档语义向量表示方法研究[D].北京:中国科学院研究生院,2016.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
开放教育研究(2020年2期)2020-03-31
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
信息安全研究(2016年4期)2016-12-01
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
