
基于迁移学习和显著性检测的盲道识别
2018-06-01 10:50李小舜吴少智
计算机工程与应用 2018年11期
李 林,李小舜,吴少智
LI Lin1,LI Xiaoshun2,WU Shaozhi3
1.成都师范学院 计算机科学学院,成都 611130
2.四川大学 电子信息学院,成都 610065
3.电子科技大学 计算机科学与工程学院,成都 611731
1.School of Computer Science,Chengdu Normal University,Chengdu 611130,China
2.College of Electronics and Information Engineering,Sichuan University,Chengdu 610065,China
3.School of Computer Science and Engineering,University of Electronic Science andTechnology of China,Chengdu 611731,China
1 引言
中国是世界上盲人最多的国家,视力障碍或全盲者,约占全世界盲人总数的18%左右[1]。现如今随着科技的不断发展,出现了很多新型的电子盲杖。盲人以及视力障碍人士虽然患有眼部残疾,但却拥有正常人的智力以及同样的出行需求。盲道障碍物识别实际上是图像场景识别,相关研究非常之多。图像场景分类是基于图像内容信息检索的基础,根据视觉信息将其划归为某一类别,比如判断图像中是否包含飞机,若有则可以将其归为飞机类别[2]。
近年,基于自动特征提取的深度学习技术在场景分类取得了积极进展,比如深度学习模型在大型数据集如ILSVRC[3]上获得巨大成功。此外,Angelova等[4]的研究表明图像场景分类的关键是找到图像的显著性区域,这对提升精确度很有帮助。Chai等[5]认为图像场景分类的重点是判别性区域的定位以及背景区域的剔除,Krause等[6-8]指出判别性区域检测对图像场景分类的重要作用。
为了适应嵌入式应用场景的特殊需求,人们提出了不少高效模型。Rastegari等[9]提出的XNOR网络简单、高效并且有较好的准确率。SqueezeNet模型[10]则通过采用模型压缩网络,大大降低模型大小,以使其能在内存受限的嵌入式场景使用,且分类精度都还不错。Jin等[11]则对网络前向加速进行了探讨,提出的新方案更高效。Mobilenet模型[12]是Google提出的适合移动环境下的深度学习场景分类模型,证明在多种场景效果较好。
由于直接深度学习模型的训练将非常耗时,如何使用已经非常成功训练得到的模型,充分利用其在大数据集获得的良好特征表示,将这些特征描述子应用于个性化数据集上是值得深入研究的[13]。
为此,结合深度迁移学习和图像的判别区域集成显著性检测,设计一套智能盲道障碍物识别系统,提出了一种新的深度迁移学习盲道场景识别方法。整个方法最大优点在于简单,计算性能好,场景类别适应度大,尤其适合于实时状态的自然盲道场景分类。
同时结合嵌入式开发,设计了一套导盲器。导盲器的设计国内案例非常多[14-16],但是基于深度学习提高识别效率的系统还没有,提出的信息导盲系统是对现有产品的一个创新和补充。
2 基于判别区域集成显著性检测和深度迁移学习的盲道场景识别方法
2.1 模型框架
本文提出的基于显著性检测和迁移学习模型整体架构,如图1所示,实现步骤如下:
(1)提取图像的判别区域显著性检测特征表示。
(2)通过转移学习,采用Mobilenet模型,提取在ImageNet上得到的模型参数和瓶颈特征描述子,将判别区域显著性检测表示与瓶颈特征描述子融合。
(3)将融合特征和Mobilenet结合,针对盲道数据集进行训练,得到实际可使用的新模型。
(4)最后将生产的模型应用于自动导盲仪上进行道路实时检测。
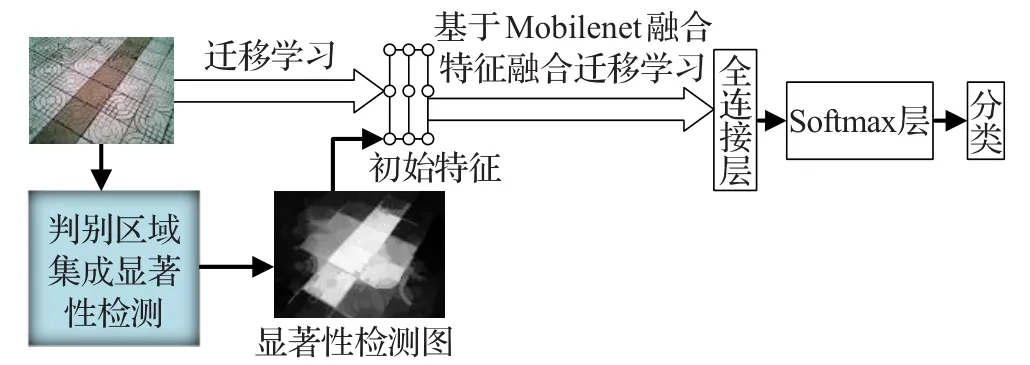
图1 基于显著性检测和迁移学习的盲道场景识别方法
2.2 Mobilenet模型
Mobilenet是一系列为移动设备设计,用在Tensor-Flow中的场景分类模型,它们的设计目标是在手持或者嵌入式设备有限资源下能高效运行,提供较高的准确率。Mobilenet中的一系列模型都是小型、低延迟、低耗能模型,它们为多种不同使用场景的有限资源进行了针对性的参数优化。
Mobilenet模型核心操作是基于深度可分解的卷积,可以理解成将标准卷积分解成一个深度卷积和一个点卷积即采用1×1卷积核。深度卷积将每个卷积核应用到每一个通道,而1×1卷积用来组合通道卷积的输出,这样可以有效减少计算量和降低模型规模。
首先是标准卷积,假定输入F的维度是DF×DF×M,经过标准卷积核K得到输出G的维度DG×DG×N,卷积核参数数量表示为DK×DK×M×N,如果计算代价也用数量表示应该是 DK×DK×M×N×DF×DF。将卷积核进行分解深度卷积DK×DK×M×DF×DF,而点卷积的计算代价是M×N×DF×DF。
Mobilenet使用了大量的3×3的卷积核,极大地减少模型规模,相比其他模型优势明显。Mobilenet结构建立在上述深度可分卷积上,以及通过减小网络的宽度而不是减少层数来选择压缩的模型。
Mobilenet总共27个卷积层和Maxpool层,外加1个Softmax层和最后全连接层。
为了构建更小和更少计算量的网络,不同应用场景会采用两个重要参数:模型宽度乘数(with multiplier)α和分辨率乘数(resolution multiplier)ρ。调整α和 ρ值,可将Mobilenet应用于许多不同的任务。
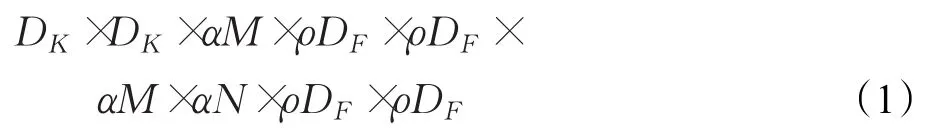
α和ρ分别可以为(0,1]之间的系数,这样可以有效压缩模型。
2.3 判别区域集成显著性检测算法
根据文献[17]评估,判别区域集成[18]方法具有最好的综合性能,为此选择该方法作为显著性检测的方法。判别区域集成方法将显著性对象检测看作回归问题,可直接将区域特征向量直接映射为显著性区域值,主要包含三个步骤:
(1)多级分割,将图像分成多个分割区域[19]。由于很难保证一次性就能正确分割出显著性对象,为了健壮性,需要多次分割,得到一定数量的训练样本。
(2)执行区域显著性计算,通过随机森林回归器,区域特征向量直接映射为显著性区域值。分别计算三种区域特征:区域对照(regional contrast)、区域特性(regional property)和区域背景(regional background)。设区域特征向量为x,随机深林回归器通过训练样本和集成特征,采用判别策略即可给出显著性评估值即:输入x到随机深林回归器 f,输出则为显著性评估值。
(3)显著性特征图通过融合多级分割得到。通过区域显著性计算后,每个区域都有一个评估值。对每个层级,根据每个区域所含像素点对每一区域赋一个显著性值,这样会生成M 个显著性图{A1,A2,…,AM},然后融合它们即:A=g{A1,A2,…,AM}得到显著性图A。
2.4 迁移学习实现盲道障碍物新特征学习
迁移学习是指将一个领域上训练好的模型通过适当的方法将其调整到一个新的领域中。本方案中采用在ImageNet上训练好的Mobilenet模型,保留模型中所有的卷积层参数,替换最后一层全连接。最后一层之前的网络层称之为瓶颈层。
将新的图像通过训练好的卷积神经网络直接送到瓶颈层的过程可以看作是对图像进行特征提取的过程,在训练好的Mobilenet模型中,因为将瓶颈层的输出再通过一个全连接层神经网络可以很好地区分1 000种类别的图像,所以有理由认为瓶颈层输出的节点向量可以被作为任何图像的一个更加精简且表达能力更强的特征向量。
因此,在新数据集上,可以直接利用这个训练好的神经网络对图像进行特征提取,然后再将提取得到的特征向量作为输入来训练一个新的单层全连接神经网络处理新的分类问题。
2.5 迁移学习和显著性特征融合成新特征学习
如图1所示,通过区域对象检测显著性特征需要和迁移学习模型的瓶颈特征算子进行融合。受文献[17]启发,设是获得的瓶颈描述子Bi和显著性特征BS的集合,目标是寻找融合函数 f(B1,B2,…,BK,BS)。实验中可以采用线性组合的方式:

采用最小方差估计,最小化损失函数进行新模型训练。
2.6 学习训练和推理算法
因为面对的是实时应用场景,使用Mobilenet预训练模型,在ImageNet(128万幅图像)上68%Top-5准确率。移除最后一分类层,重新采用本文数据集训练模型,调优各层的参数。在训练中,调整图像大小为224像素×224像素或128像素×128像素,以保持与使用的预训练模型一致,并平衡通过ImageNet训练得到的自然图像特征并与显著性检测特征融合,整个过程即是转移特征学习过程,得到给定特殊数据集上的最优特征表示。
假定输入一幅图像,进行变形,添加翻转,图像色彩调整,再随机裁剪出224像素×224像素或128像素×128像素大小的输入图像,提取瓶颈描述算子,同时提取判别区域集成显著性描述子,并融合两个特征描述算子。使用训练好的新模型进行推理,模型输出:

此处,B是任意一幅图像融合特征描述算子,m(B)是输出每幅图像B的前N个类别的判断概率。
在Tensorflow中,softmax是一个额外的处理层,将神经网络的输出变成一个概率分布。
3 实验设计
3.1 数据集简介
实验在自己手动采集的数据集上测试提出的方案,针对不同参数场景,并进行了分析。数据集统计如表1所示。

表1 盲道周边障碍物数据集
为了适应真实街道情况,采集了成都市区盲道周围障碍物的实景,共采集了六种基本盲道障碍物,外加正常道路,共计七个类别,7 071幅图像。
其中,(1)正常盲道,指可以通行的正常道路;(2)草坪,指盲道周围可能有草地,不宜通行,是障碍物;(3)路边坎,包括绿化护坎、路边休息椅子凳,属于障碍物;(4)自行车,由于共享单车的普及,道路周边停放自行车现象很普遍,属于障碍物类别;(5)框架围栏,道路通行的边缘,属于障碍物;(6)阶梯,道路通行中的阶梯,属于要特别注意的地方;(7)树木,道路旁边的树木,属于障碍物。
3.2 实验设置
实验判别区域集成显著性检测在OpenCV 3上进行分割和实现。实验在谷歌的TensorFlow 1.3深度学习框架上进行模型的转移训练、验证和测试。数据集合采用随机方式选取80%训练集、10%验证集合、10%测试集进行实验。
本文的模型通过反向传播算法进行训练,所有层通过相同的学习率0.001,每30个轮次一个退化因子进行调优。
原始图像像素是320×240,调整到224×224或128×128。每幅图像采用随机方式选择0°到359°,以增加模型样本的旋转适应度。
模型精度计算方法如公式(4)所示:

其中,A是精度,Nerror是错检测图像个数,Ntotal是总的图像个数。
4 实验结果及分析
为了实验数据的严谨、准确和一致,本研究中分类准确率保留四位有效数字,时间保留三位有效数字或小数点后两位。
4.1 模型各阶段仿真效果及分析
4.1.1 判别区域集成显著性检测过程仿真
判别区域集成显著性检测采用文献[19]的方法。
如图2所示,实验中,设置分割数为15,通过多级融合为显著性检测描述子。第一行是原始图像,第二行到第五行是15个多级分割得到的中间图像。然后通过随机深林回归器训练样本和集成特征,最后形成判别区域集成显著性检测图。

图2 判别区域集成显著性检测生成图
4.1.2 显著性检测描述子和瓶颈描述子融合过程仿真
在图3中,(1)是原始图像;(2)是显著性检测描述子;(3)是融合后的图像;(4)是瓶颈描述子;(5)是新的模型特征。
实验中首先通过原始图像进行判别区域集成显著性检测,通过与原始图像融合,生成新的显著性驱动的新图像。
结合现有成熟的Mobile模型通过迁移学习生成的瓶颈描述子生成新盲道数据集上的模型,得到新的模型特征。

图3 显著性检测描述子和瓶颈描述子融合
4.1.3 模型类别概率
模型中图像类别概率通过公式(3)计算得到,实验测试如图4所示。
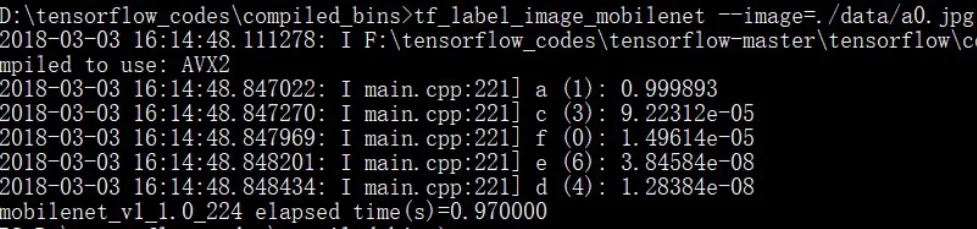
图4 图像Top-5类别测试实验
本实验中列出前5个类别的概率,以分别测试表1中7幅图像为例,如表2所示。
结合图2和表2,可以看到,基于深度学习的模型在类别TOP5评价中,这7个测试图像第一类别即正确分类的概率很高,说明分类正确率高。这跟图像在训练中已经作为训练样本参与训练有关。
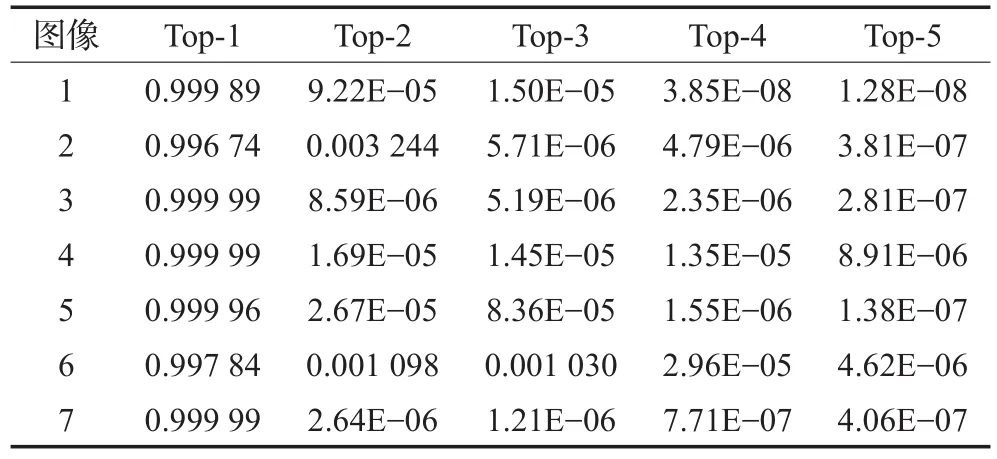
表2 数据集上不同模型和参数测试集的分类结果
4.1.4 迁移学习训练过程仿真
整个迁移学习模型在Tensorflow平台运行训练过程如图5所示。
图5中右边根据显著性检测描述子和MobilenetV1模型的瓶颈特征描述子,融合生成新的中间特征,然后循环进行训练、验证和评估,最后输出训练总的检测准确率。

图5 迁移学习训练过程图
图5 中左边是图像基本处理,包括图像旋转解码等过程。
4.2 模型精度的比较
实验中,模型的分类准确率性能比较,如表3所示。也测试了Mobilenet模型在不同缩放比例和图像尺度下的精度。Mobilenet_v1是模型名称版本,1.0或0.25是宽度乘数。224指图像分辨率尺寸是224像素×224像素;128指图像尺寸是128像素×128像素。从表3中可以看出:
(1)直接训练在增加显著性检测时模型在缩放乘数1.0时效果最好;但总体而言,在本次实验中,直接学习的效果,没有迁移学习得到的效果好,这与文献[12]的结论有出入,分析原因,很有可能是数据集的差异,或者是数据集数量还显不足导致。
(2)增加显著性特征检测在每类测试比较中对精度都有提升。在迁移学习中大约有1个百分点的精度提升。
(3)采用0.25的宽度乘数相对于乘数1而言,精确度略有下降,但幅度不大。
(4)采用224和128的分辨率乘数,得到的结果基本一致,影响不大。
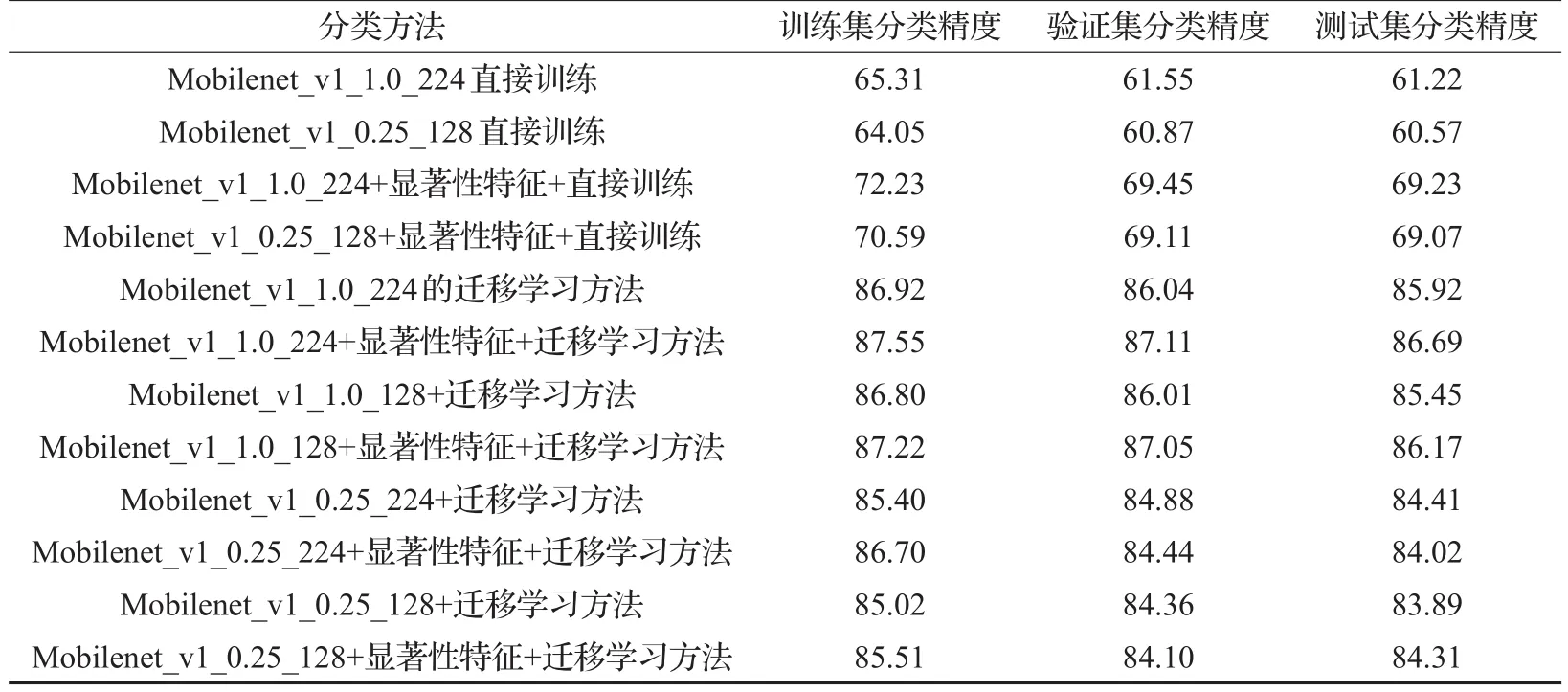
表3 数据集上不同模型和参数测试集的分类结果 %
4.3 模型训练时间比较
实验中为了比较模型的训练时间的差异,通过循环代码,对结果连续循环5次,然后求平均值如表4所示,时间单位为s,生成模型大小以KB计。
从表4中可以看出:
(1)模型在宽度乘数为1时,模型的大小是一样的,和精度系数没有关系。宽度乘数为1时,模型大小是16 714 KB约等于16 MB。宽度乘数为0.25时,模型大小是1 952 KB约等于2 MB。模型压缩比高。
(2)直接模型训练耗时远远大于通过迁移学习的时间,而且精度不一定好。
(3)直接迁移学习时间基本一致,平均差别主要是系统运行误差所致,宽度乘数为1时比为0.25时要长,主要是计算量大的原因。
(4)添加显著性检测后整个训练时间将略有增加,主要是图像显著性检测需要一定时间,不过通过C++优化,基本对模型训练整体影响较小,比不用显著性检测要多出约1 min左右。

表4 数据集上不同比例测试集的训练时间和模型大小比较
4.4 模型训练时间比较
在嵌入式系统中实现了提出的模型,如图6所示。
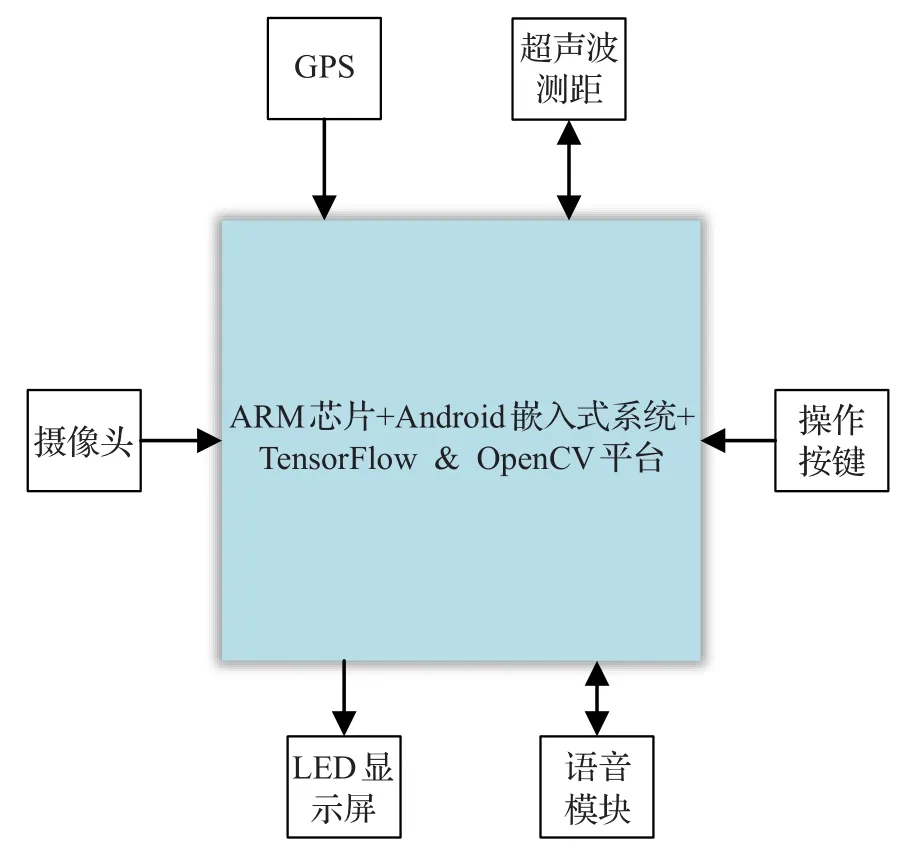
图6 导盲器设计功能图
系统核心开发板采用迅为-i.MX6核心板,是Freescale Cortex-A9四核i.MX6Q。核心由硬件ARM芯片组成,软件采用Android 6.0系统,TensorFlow 1.3,OpenCV 3.3 for Android和百度地图数据,系统主要包括以下模块:
(1)语言模块:自动识别语音输入,并给出各种提示信息回馈。
(2)GPS模块:实现当前位置信息,结合高德地图实现当前位置,并利用电子地图实现自动建议下一步路线的功能。
(3)摄像头模块:获取图像信息,供障碍物检测和报警使用。
(4)超声波测距模块:感知障碍物距离,通过对障碍物类型的鉴别,并报警距离。距离,通过对障碍物类型的鉴别,并报警距离。
(5)LED显示屏,报错或检测信息输出,供调试使用。
(6)操作键模块:供盲人手动控制检测时间,根据需要强制检测。
核心开发板基于ARM Cortex™-A9架构,包含单核、双核、四核高延展性的嵌入式处理器,每个内核的运行速率可达1.2 GHz。i.MX6系列应用处理器提供高能效低功耗的处理性能,同时内建卓越的3D图像引擎,支持3D成像的立体图像传感器,支持1080P编解码和高清3D视频播放的高清视频引擎以及独立的UI界面2D引擎。导盲器实物图如图7所示。将训练好的模型文件上传导盲器,通过OpenCV+Tensorflow的C++接口编写检测程序,使用者根据需要按下开启和检测键,实现对周围场景的检测。

图7 导盲器实物图
整个导盲系统特点:(1)针对盲人行为特点设计,经调查国内还无此类应用;(2)采用主流的控制技术与通信技术,保证了产品的通用性及先进性;(3)产品还可以进行进一步的功能完善和成本降低,如添加地理信息存储器(卡),使盲人可以即时了解自己所处位置而不用求助于第三方平台。
当盲人要出行时,输入目的地名称,百度电子地图就会为盲人自动设置路线,并在行走的过程中,通过TTS语音播报导航,指引盲人到达目的地。
表5是模型在自动导盲嵌入式设备上的实时单次检测时间,是5次测试的平均值和极值范围,单位是s。

表5 模型在嵌入式设备上的实时单次检测时间比较
从表5中可以看出:
(1)实时状态单幅图像检测主要和模型大小有关系。
(2)宽度乘数为1时,检测时间都在1.5 s左右,而当乘数为0.25时,检测时间在0.5 s多一点。
(3)加入显著性检测对模型检测影响不是很大,大约多0.1 s左右。
(4)训练时间和检测时间的规律基本相似。
5 结束语
本文分析了嵌入式图像场景识别的一般原理、步骤及其评价方法,并提出了一种简单高效的图像场景识别方法,由于显著性检测和基于迁移学习的Mobilenet分类器的优点,该方法实现盲道场景的实时高效分类和提醒。
(1)本文实验表明在盲道场景识别中,融合显著性检测特征将有助于场景分类精度的提升,同时对训练和执行性能影响较小,说明提出方案的有效性。
(2)迁移学习的重要优点是能够很好地利用现有大规模数据集训练得到的成功特征表达,同时结合自身特殊数据集性质进行有针对性的再训练,既有效节约了训练时间,又保持相对较高的准确率,是值得深入研究的方向。
(3)数据集的构建还需加强和优化,尽管采集了7 000余幅图像,但是都深感数据集代表性和广泛性还存在不足,下一步考虑结合实际应用,采用增量学习的方式,不断增强和完善数据集,改进模型性能。
(4)嵌入深度学习模型优化涉及方面多,如何做到既高效又精准是一个难题,本文在这方面进行了一些探索,下一步,还将探讨模型结构和特征融合的其他影响因素,以期达到更优效果。
参考文献:
[1]李姝颖.基于超声波传感器阵列的导盲系统研究[D].重庆:重庆理工大学,2013.
[2]Iwan U,Johann B.The guide cane-applying mobile robot technologies to assist the visually impaired[J].IEEE Transactions on Systems,Man and Cybernetics,2001,31(2):131-136.
[3]Russakovsky O,Deng J,Su H,et al.ImageNet large scale visual recognition challenge[J].International Journal of Computer Vision,2014,115(3):211-252.
[4]Angelova A,Zhu S.Efficient object detection and segmentation for fine-grained recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,Portland,OR,USA,2013:110-118.
[5]Chai Y,Lempitsky V,Zisserman A.Symbiotic segmentation and part localization for fine-grained categorization[C]//Proceedings of the IEEE International Conference on Computer Vision,Sydney,Australia,2013:331-339.
[6]Krause J,Jin H,Yang J,et al.Fine-grained recognition withoutpartannotations[C]//Proceedings ofthe 2015 IEEE Conference on Computer Vision and Pattern Recognition,Boston,MA,USA,2015.
[7]Zhang N.Pose pooling kernels for sub-category recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,Providence,RI,USA,2012:563-572.
[8]Yang S,Wang J,Wang J,et al.Unsupervised template learning for fine-grained object recognition[C]//Proceedings of the International Conference on Neural Information Processing Systems,Lake Tahoe,USA,2012:892-901.
[9]Rastegari M,Ordonez V,Redmon J,et al.XNOR-Net:ImageNet classification using binary convolutional neural networks[C]//Proceedings ofthe European Conference on Computer Vision,Amsterdam,The Netherlands,2016:786-794.
[10]Iandola F N,Han S,Moskewicz M W,et al.SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size[J].arXiv:1602.07360v4,2016.
[11]Jin J,Dundar A,Culurciello E.Flattened convolutional neural networks for feedforward acceleration[J].arXiv:1412.5474v4,2014.
[12]Howard A G,Zhu M,Chen B,et al.Mobilenets:Efficient convolutional neural networks for mobile vision applications[J].arXiv:1704.04861v1,2017.
[13]Donahue J,Jia Y,Vinyals O,et al.DeCAF:A deep convolutional activation feature for generic visual recognition[C]//Proceedings of the 31st International Conference on Machine Learning,Beijing,China,2014:786-794.
[14]张兰.基于ARM的超声波导盲系统[D].济南:山东师范大学,2010.
[15]姜瑾.具有定位导航和障碍规避功能的电子盲杖设计[D].北京:北方工业大学,2013.
[16]姬盼盼.基于RFID和语音合成的导盲系统研究[D].南京:南京理工大学,2013.
[17]Borji A,Cheng M,Jiang H,et al.Salient object detection:A benchmark[J].IEEE Transactions on Image Processing,2015,24(12):5706-5722.
[18]Jiang H,Wang J,Yuan Z,et al.Salient object detection:A discriminative regional feature integration approach[C]//Proceedings of the Computer Vision and Pattern Recognition,Portland,OR,USA,2013:215-223.
[19]Achanta R,Shaji A,Smith K,et al.SLIC superpixels compared to state-of-the-art superpixel methods[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(11):2274-2281.
[20]Liu T,Yuan Z,Sun J,et al.Learning to detect a salient object[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(2):353-367.
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
青少年日记·小学生版(2019年2期)2019-09-02
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国与非洲(法文版)(2017年10期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
小主人报(2016年2期)2016-02-28
小学生作文·小学低年级适用(2014年7期)2014-09-10
