
基于语音频谱融合特征的手机来源识别
2018-05-21 01:01:51裴安山王让定严迪群
计算机应用 2018年3期
裴安山,王让定,严迪群
(宁波大学 信息科学与工程学院,浙江 宁波 315211)
0 引言
随着互联网的不断发展和便携式智能终端的快速普及,人们能够更加方便、快捷地借助于各种便携设备在网络上与他人分享自己的所见所闻所感,但是随着数字多媒体编辑软件的普及,以及其功能的强大和操作的简单化,编辑、修改以及发布多媒体信息也变得越来越简单有趣。尽管大多数人对多媒体的编辑只是为了增强表现效果,但也不乏有人无意或是有意,甚至恶意地传播、发布经过精心篡改或伪造的多媒体数据[1]。
音频来源取证是数字音频被动取证中的一个重要环节,目的是通过对获取的录音文件进行信号处理与分析,利用能表征录制设备及其特性的信息,实现对录音来源的辨识。是对音频来源的真实性、完整性等进行验证的,是多媒体取证技术的重要研究内容,其领域随着学者们日益的关注获得了重大的研究进展[2-7]。裴安山等[8]首次将设备的本底噪声应用于语音的设备来源取证研究,将在静音段上采用谱减法去除环境噪声之后的噪声认为是广义的设备本底噪声,在此基础上提出频谱的对数谱特征作为分类特征,在CKC-SD(CKC Speech Database)语音数据库上识别准确率达到99%。之后考虑到本底噪声的提取较大程度上受环境噪声的影响,该特征的实际场景的通用性偏弱,提出在非语音段上提取特征表征设备特有痕迹的方法,该方法减少了利用谱减法去除环境噪声的工作,同时考虑到非语音段包含与语音段相同的设备痕迹信息,具有不会受到说话人、文本、情感等可能因素的干扰的优点,将非语音段上去离散余弦变换(Discrete Cosine Transform, DCT)的梅尔倒谱系数(Mel Frequency Cepstral Coefficients, MFCC)作为分类特征,采用均值归一化方法对提取的特征进行归一化,最后采用LIBSVM分类器对TIMIT翻录语音数据库和CKC-SD语音数据库的样本进行分类识别。实验结果表明,该算法在23种不同型号的设备的识别实验中平均识别率达到99%[9]。Hanilci等[10]提取录音文件的MFCC及其一阶、二阶差分值作为特征向量,用于判断该录音文件归属何种品牌、何种型号的手机。实验结果表明,他们在自建的由14种型号手机组成的音频数据库上能够达到96.42%的分类准确率。Kotropoulos[11]使用整个翻录TIMIT库训练的GMM-UBM(Gaussian Mixture Model-Universal Background Model)构建高斯超向量的稀疏表示作为特征时,测试采用SRC(Sparse Representation based Classification)、SVM(Support Vector Machine)和NN(Nearest Neighbor)三种分类器,对数据库中7种品牌21种型号的手机实现了较高的分类准确率。当下语音设备来源取证的研究大多数所提的分类特征是单一特征,如MFCC特征、频谱对数谱特征等。因为当下的研究基于的语音数据库设备的种类和数量较少,设备型号陈旧,导致不同设备采集语音的差异性较大,相关特征在手机来源识别中取得了不错的效果,但是当语音数据库中设备种类和数量达到一定程度之后,特别是随着相同品牌不同型号设备不断增加后,相关特征在手机来源识别中是否依旧能取得不错的效果呢?而基于静音段的特征虽然有效地避免了语义信息和说话人情感等因素的干扰,但是对环境噪声的要求是较高的,当环境噪声过大时,静音段特征提取的工作难度就增大了。
本文通过在现下主流的7个品牌23个型号的手机构建的语音库上分析不同设备语音信号的语谱图,发现:不同设备的频谱信息不尽相同,不同品牌的设备差异明显,可以用频谱单一特征来有效地进行区分;而相同品牌不同型号的设备虽然存在差异,但较为相似,单一的频谱特征难以准确实现不同品牌手机的类内识别。本文研究了语音频谱对数谱特征、相位谱特征和信息量特征在语音手机来源识别中反映的设备差异信息,发现信息量特征和对数谱特征分别增大了高频部分和低频部分频率幅度谱的差异分辨度,而相位谱特征反映了设备语音在相位谱上的差异信息。在此基础上为了构建更好地反映设备语音差异的特征,提出一种基于频谱融合特征的手机来源识别方法。实验结果表明,语音频谱融合特征可以作为语音手机来源识别的特征,识别准确率优于单一的频谱特征和MFCC特征,且融合特征的泛化能力较单一特征会更好。文中算法在由德州仪器(Texas Instruments, TI)、麻省理工学院(Massachusetts Institute of Technology, MIT)和斯坦福研究院(Stanford Research Institute, SRI)合作构建的声学-音素连续语音语料库(The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus, TIMIT)数据库和研究所自建的基础语音数据库(CKC-SD)上的平均识别准确率可以达到99.96%和99.91%。
1 手机来源识别语音库的建立
1.1 手机设备的选择
由于手机和录音笔具备体积小易携带的特点,很多人在进行录音取证时常常会采用。而随着手机的快速普及和手机录音音质的提高,将智能手机作为录音取证设备的人变得越来越多。本文语音库录制采用的手机设备来自7个品牌的23款手机,手机的信息和标签如表1所示。
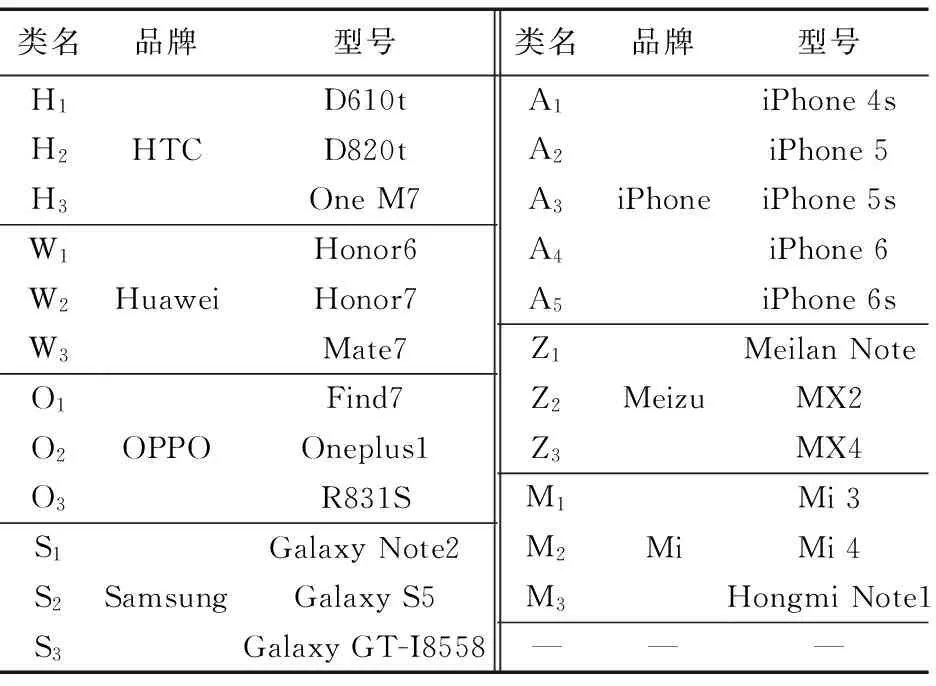
表1 实验手机的品牌列表以及类名Tab. 1 List and specifications of cell-phones
1.2 语音库的构建
本研究录制了两个语音数据库。第一个语音数据库是对TIMIT数据库的语音样本进行回放和重新录制的TIMIT翻录语音数据库,这也是录音设备来源识别领域构建基准数据库的典型方法之一。从TIMIT数据库中选取100个人(男性50人,女性50人)的1 000个语音样本,采用高保真音箱(PhilipsDTM3500)进行回放,同时用设备列表中所有的设备一起录制。共同构成每个手机拥有1 000个翻录语音的数据库。第二个数据库是本研究构建的基础语音数据库(CKC-SD)。该构建的数据库采集了12个人(6名男性,6名女性)的语音。每个人参与两段语音的录制,一段是问答和主题演讲,一段是固定语料的朗读,录制时均要求语速、语调和音强匀速正常,时间长短控制在5 min以上。在相对安静的办公室里,将所有录音设备按圆弧形平放在以参录人员为圆心的办公桌上,每个设备距离参录人员约为1~1.2 m;为了保证语音录制具有较好的同步性,由多名同学同时控制所有录音软件的开关。每台设备均获得24段语音,为排除录音开始之前人为因素引起的噪声对语音样本的影响,从语音正式开始录制部分进行切割,将每段录音分割成3 s的语音片段,每个手机获取1 000个语音样本,这样就可构建23 000个语音样本的语音数据库。
2 频谱特征分析与设备来源识别
语谱图又名语音频谱图,能简洁明了地展示语音样本的频谱值在时间轴上的变化。图1给出了8个手机采集的内容为“芝麻开门,我是土豪”的语音的语谱图的灰度图。通过观察图1可以看出不同品牌手机语音的语谱图存在很大差异。例如,Samsung Galaxy Note2语音信号的高频部分语音能量较强;HTC D610t的语谱图在频率为4 000 Hz附近有大幅度的下降;iPhone 4s和iPhone 5的语谱图比较相似,语谱图在15 000 Hz附近有大幅下降;其他型号的手机语谱图语音能量分布规律和开始大幅下降的频率界限也不尽相同。可以得出这样的猜想:即不同品牌手机的频谱特征差异较明显,而相同品牌不同型号的手机的语谱图虽然总体较为相似,但也存在差异。
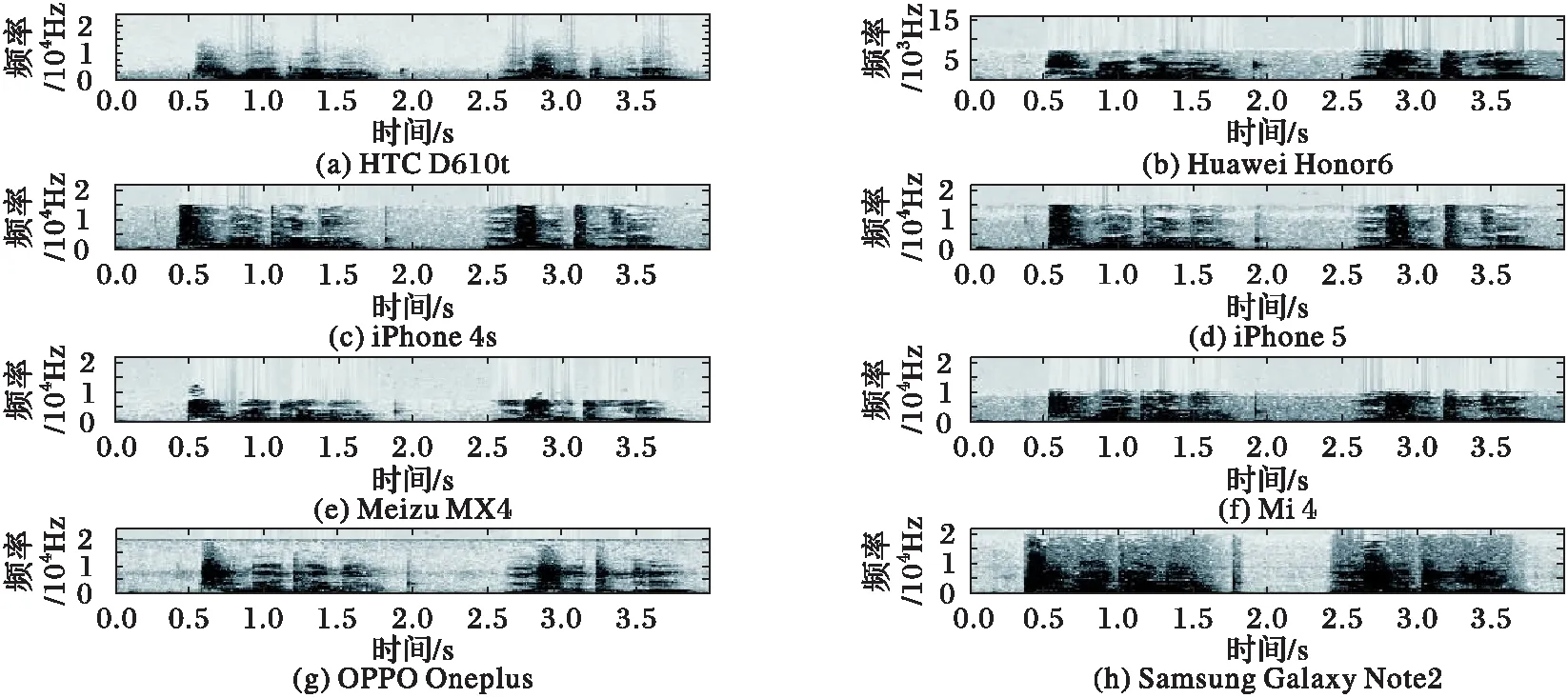
图1 相同语音的语谱图 Fig. 1 Spectrograms of same speech
为了进一步研究不同设备语音频谱特征的差异,本文提取了语音的频谱信息量特征。信息量[12]来源于信息论,它用一个变量的概率描述不确定问题。设一个符号集t={x1,x2,…,xn},第m个符号出现的概率为p(xm),且p(x1)+p(x2)+…+p(xn)=1,每个符号所提供的信息量I=-lbp(xm),某个符号出现的概率越小,则说明该符号携带的信息量就越大。频谱信息量特征的提取过程为:
首先,对语音样本x进行分帧处理,并对第i帧语音进行快速傅里叶变换,即:
(1)
傅里叶变换的点数N=1 024,k=0,1,…,N-1,i=1,2,…,T,T表示总帧数; 对于第i帧第k个频率点的频率值xi(k),求其幅值,即:
(2)
然后,求第k点频率沿时间轴的统计平均值x(k)和总的频率值S(k),即:
(3)
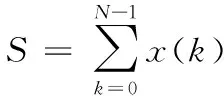
(4)
求出频率点k出现的概率P(k),并得到第k个频率点的信息量特征,即:
P(k)=x(k)/S
(5)
I(k)=-lbP(k)
(6)
可以看出每个频率点所携带的信息量受该点频率值幅值、沿时间轴的统计平均值和频率值总和的影响,不同频率值的信息量是不同的,频率值越小其对应的信息量特征越大。由图1可以看出语音信号在高频部分的能量较低,可得高频部分的信息量特征值较大,频谱信息量特征增大了不同设备高频部分差异的分辨率。
图2展示了8款手机(两台iPhone)的语音样本的频谱信息量特征。其具体实现过程为:首先提取语音样本频谱的信息量特征,然后对信息量特征值进行归一化,再采用特征寻优降维的方法选出区分性最大的特征子集,最后画出所选特征子集的折线图。可以看出本文所构建的频谱信息量特征在不同品牌的手机之间有较明显的差异,虽然相同品牌不同型号的手机的特征曲线图较为相似,但可以发现第10~20维特征可以完成相同品牌不同型号的设备区分。
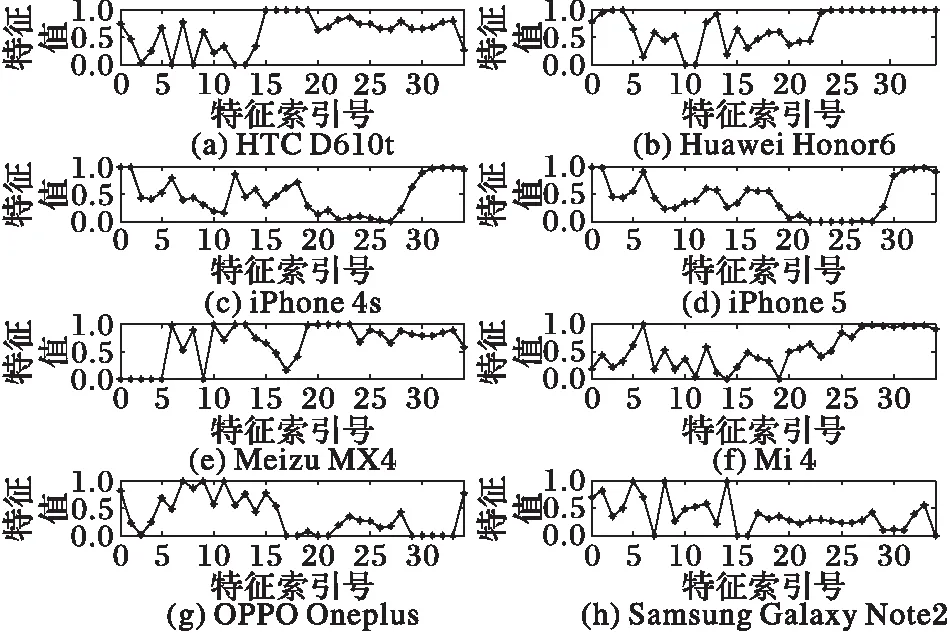
图2 相同语音的频谱信息量特征 Fig. 2 Spectral information quantity feature of same speech
语音信号的对数谱特征是先对语音信号的频谱幅度谱特征作对数运算,然后沿时间轴取统计平均值所得。对第k个频率点幅值作对数运算,然后沿时间轴取统计平均值得到第k个频率点的频谱对数谱特征L(k),即:
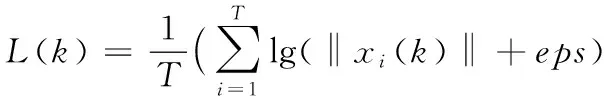
(7)
由式(7)可得,对数谱特征的大小与语音信号频率值幅值变化成正比,频率幅值越大,对应的对数谱特征的值越大。由图1可以看出,语音信号的能量主要集中在低频部分,因此语音信号对数谱特征在低频部分的值较大,对数谱特征可以有效增加不同设备语音频谱低频部分的差异分辨率。
图3为8款手机(两台iPhone)语音样本对数谱特征的折线图。具体实现过程为:先提取对数谱特征,然后对特征值进行归一化,再采用特征寻优降维的方法选出区分性最大的特征子集,最后画出所选特征子集的折线图。可以看出本文所构建的频谱对数谱特征在不同品牌的手机之间有较明显的差异,虽然相同品牌不同型号的手机的特征曲线图相对较为相似,但是仍然可以在第8~10维发现明显差异,作出有效区分。
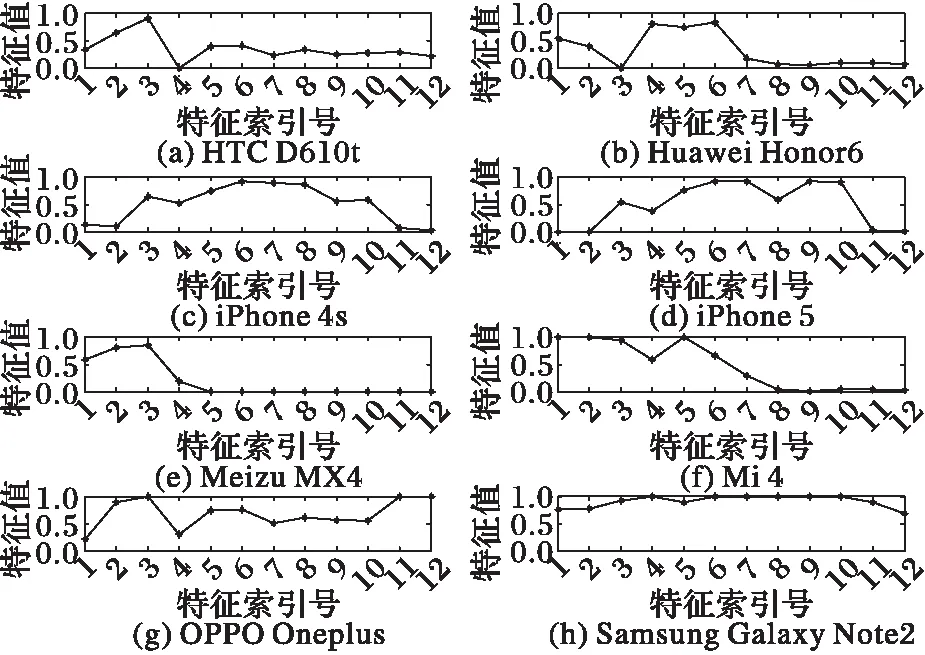
图3 相同语音的频谱对数谱特征 Fig. 3 Spectral logarithmic feature of same speech
频谱的信息量特征和对数谱特征分别有效地增大了不同设备语音样本高频部分和低频部分的频谱差异分辨精度,两组特征都是在语音的频谱幅度谱特征的基础上构建的,较好地反映了不同设备在语音幅度谱上不同频率区间的差异信息。由于频谱是由幅度谱和相位谱共同构成的,为了提升不同设备之间的差异分辨精度,本文研究了语音信号的相位谱特征。其提取过程如下。
对语音信号第i帧求其相位谱特征:
(8)
然后求其第k个频率点的相位谱特征沿时间轴的统计平均值Ψ(k),即为本文所提频谱的相位谱特征:
(9)
图4是8款手机(两台iPhone)语音样本的相位谱特征的折线图。其具体实现过程为:先提取语音信号的相位谱特征;然后对该特征沿时间轴按帧取平均和对特征值进行归一化;最后采用特征寻优降维的方法选出区分性最大的特征子集并画出折线图。可以看出不同品牌设备的相位谱特征差异明显,相同品牌不同型号的手机设备的相位谱特征虽然较不同品牌差异小,但可以进行分类判别,相位谱特征是语音手机来源识别的有效特征。
本文所构建的语音信号的频谱信息量特征和对数谱特征较为全面地反映了不同设备语音频谱幅度谱上的差异,构建的相位谱特征较好地反映了不同设备相位谱上的差异。为了更好地反映不同设备语音样本频谱特征之间的差异,本文提出了一种基于频谱融合特征的语音设备来源识别方法,将以上三组频谱单一特征的初始特征串联起来,每个语音样本得到一个1 539维的特征,对样本初始特征构成的特征空间进行特征值归一化和采用最佳优先搜索[13]对特征空间寻优降维,特征子集的分类效果的好坏是由CfsSubsetEval评价函数评价的,主要是考量特征子集的预测能力和关联性[14]。预测能力是指每个特征或每个特征子集的分类性能的优劣,关联性指的是特征与特征之间的冗余(重复)程度的高低,首选的最优化的特征子集是:与分类具有高相关性,同时特征与特征之间相关度较低的特征子集。最后将所得的最优特征子集作为本文所提的特征。语音频谱融合特征的构建和基于该特征的手机来源识别的流程如以下步骤所示。
步骤1 对语音样本进行采样分帧和加窗;
步骤2 对每帧语音进行快速傅里叶变换得到语音的频谱xi(k);
步骤3 对频谱取模得到频谱幅度谱‖xi(k)‖;
步骤4 对幅度谱按帧取统计平均,得到平均幅度谱特征x(k);
步骤5 对x(k)求信息量特征I(k);
步骤6 对‖xi(k)‖求每帧的对数谱特征,然后沿时间轴取统计平均,得到样本的对数谱特征L(k);
步骤7 对xi(k)求每帧的相位谱特征,然后沿时间轴取统计平均,得到样本的相位谱特征Ψ(k);
步骤8 将每个样本的信息量特征I(k)、对数谱特征L(k)和相位谱特征Ψ(k)串联起来,构成513×3维的初始的频谱融合特征F(k);
步骤9 按型号依次提取构建23个手机的23×1 000个语音样本的初始频谱融合特征F(k),构成实验的样本特征矩阵;
步骤10 采用WEKA平台的CfsSubsetEval评价函数和最佳优先搜索原则进行特征选择,得到降维后的样本特征矩阵和每个样本的频谱融合特征Fend(k);
步骤11 采用基于径向基核函数(Radial Basis Function, RBF)的LibSVM分类器[15],利用5折交叉验证方式对样本特征选择后的特征矩阵进行模型训练和测试,实验中对惩罚系数(cost,C)和gamma(γ)的值进行了交叉验证寻优。
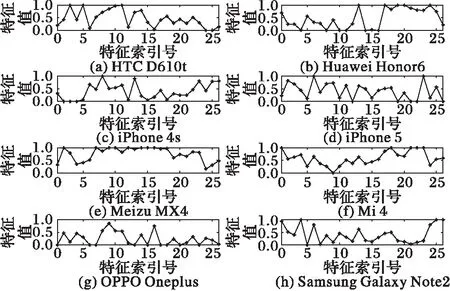
图4 相同语音的频谱相位谱特征 Fig. 4 Spectral phase feature of same speech
3 实验及结果分析
3.1 频谱融合特征分析
表2为频谱融合特征子集(即经过特征选择后)为57维时,在TIMIT库上,对23个不同型号的手机的设备来源识别结果,平均识别准确率达到了99.96%。其中只有HTC D610t的样本和HTC D820t的样本分类出现误判,原因可能是两者属于同一个品牌,语音样本特征的差异性相对其他品牌和型号而言较小,所以分类更容易误判,其他型号手机的识别可以达到较好的识别效果。
表3给出了频谱融合特征为46维时,在CKC-SD库上,对23个不同型号的手机的设备来源识别结果,平均识别准确率达到了99.91%。iPhone 5s的识别率最低为98.5%,iPhone 6的识别率为99.5%,两款手机的部分语音样本误判为两者内的另一款手机,其他品牌和型号的手机可以实现无差错分类。可能存在的原因是iPhone品牌内部不同型号的手机采集的语音所包含的频谱特征差异度较小,第2章中的语音信号的频谱单一特征分析也可以证明这一点。
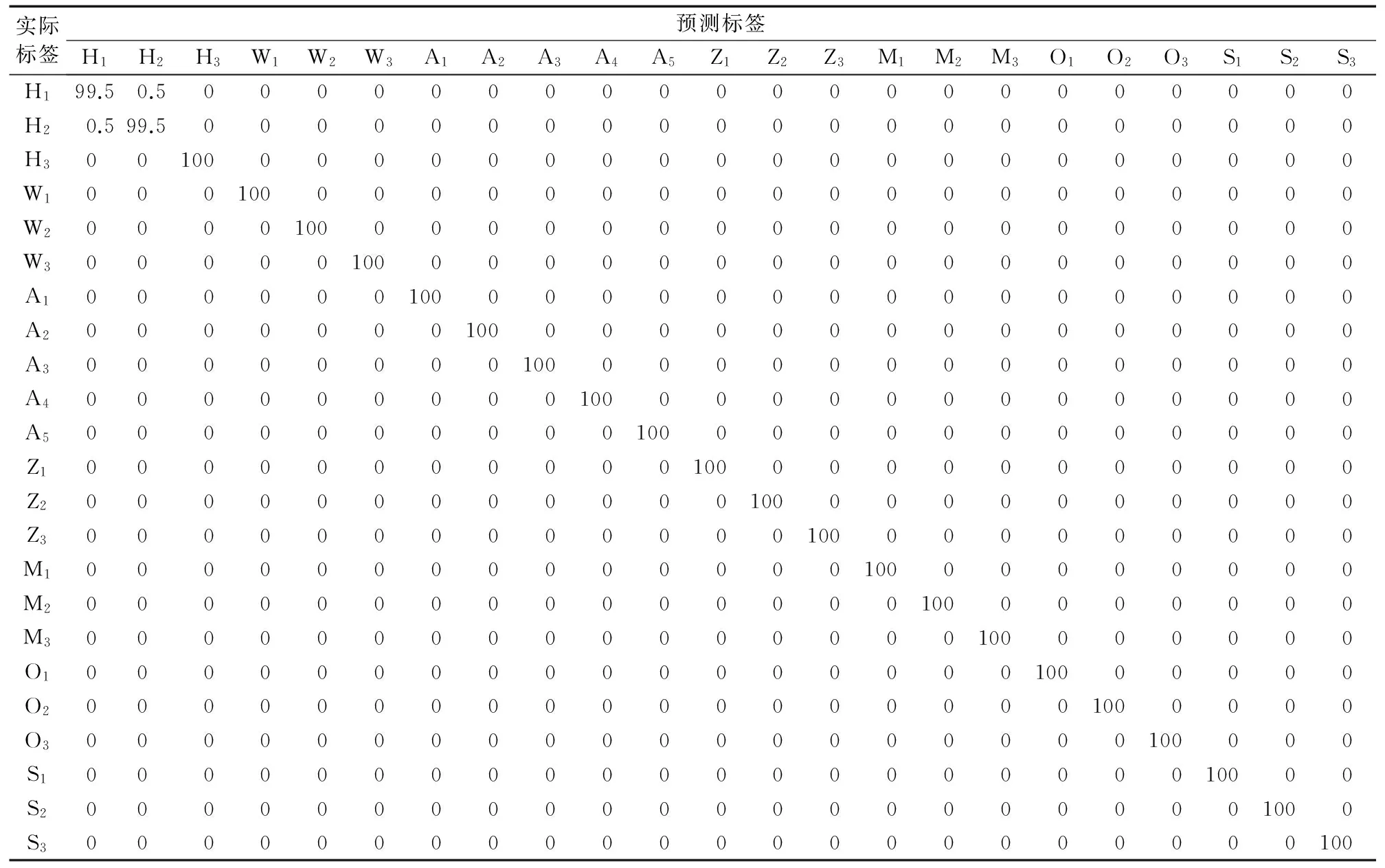
表2 频谱融合特征在TIMIT库上的识别准确率 %Tab. 2 Identification accuracy of spectral fusion feature on TIMIT %
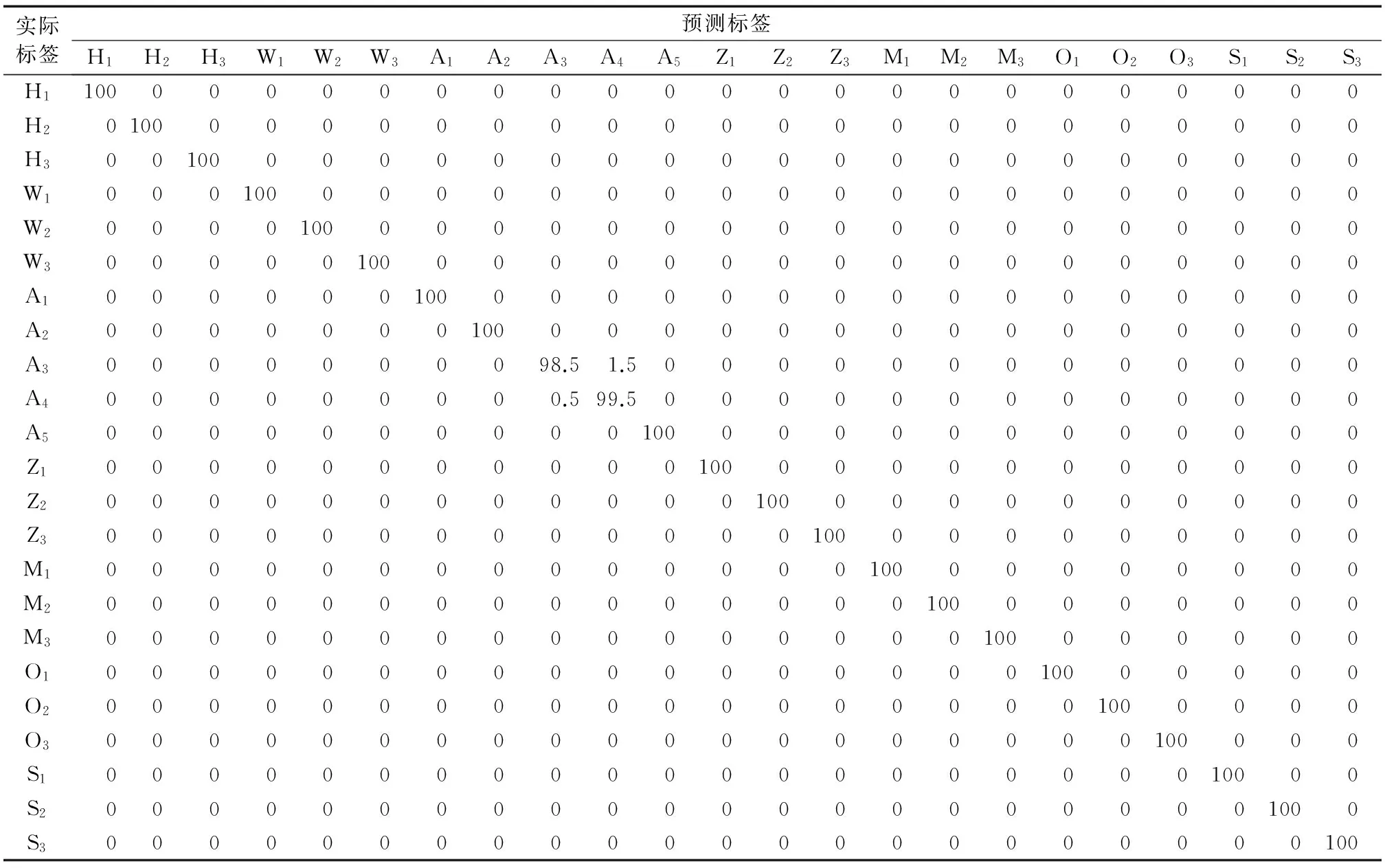
表3 频谱融合特征在CKC-SD库上的识别准确率 %Tab. 3 Identification accuracy of spectral fusion feature on CKC-SD %
为了研究频谱融合特征较语音频谱单一特征识别性能的优劣,表4给出了对数谱特征、相位谱特征和信息量特征在TIMIT库和CKC-SD库上的实验结果。可以看出对数谱特征和信息量特征在本文所用数据库上有较好的识别效果,而相位谱的识别效果相对较差,本文所提融合特征的识别准确率要优于单一特征的识别准确率。另外,由表4可得降维后单一特征在TIMIT库上的特征维数和识别准确率均略高于CKC-SD库,这一规律与融合特征在两个数据库上的表现相互印证,可以得出本文所构建的频谱单一特征和融合特征在TIMIT库上的分类性能要略优于CKC-SD库。
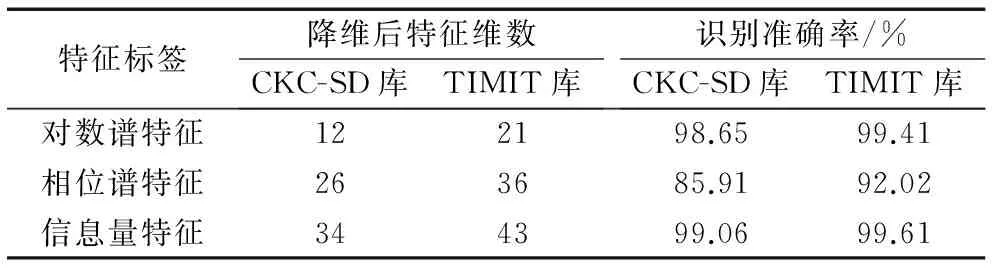
表4 频谱单一特征的语音设备来源识别结果Tab. 4 Source cell-phone identification results with spectral single feature
为了直观研究不同特征对各设备识别准确率的影响,图5给出了不同频谱单一特征在23款不同型号手机闭集识别的准确率。可以看出在TIMIT库上频谱单一特征的识别准确率除HTC品牌以外,基本都优于该特征在CKC-SD库上的识别准确率。三组频谱特征中对数谱特征和信息量特征对各个设备均有较好的识别准确率,而相位谱特征在HTC和iPhone上识别准确率较差,该特征各设备的识别准确率较另外两组特征也略差,可能的原因是不同设备对语音的影响更多地反映在对语音幅度增强的程度不同上,频谱的相位谱信息含有的设备差异性信息较少。综合来看各特征在语音库上的主要误判来自于iPhone和HTC两个品牌的设备的类内区分判别,可能造成此结果的原因是这两款设备的频谱特征的区分性相对较小。
3.2 对比算法分析
为了综合考量本文所提的算法,和Hanilci等[10]提出的基于MFCC特征的手机来源识别算法进行了比较。文献[10]的工作,无论是从特征的选择还是实验设置上,都是十分经典和充分的。将该文所提特征在本文所录制的语音数据库上实验,实验设置与文献[10]相同,样本数目与本文实验相同。文献[10]将48维的MFCC及其一阶差分特征作为语音设备来源识别的分类特征。表5展示了文献[10]算法和本文算法在手机来源识别实验中平均识别准确率的对比。

表5 两种算法的识别准确率对比 %Tab. 5 Identification accuracy comparison of two algorithms %
从表5可以看出,本文所提算法在平均识别准确率方面较文献[10]算法好,平均识别准确率在TIMIT库和CKC-SD库上分别提高了6.58和5.14个百分点。可能的原因是:文献[10]中48维的分类特征之中存在冗余特征,其中的冗余的特征可能会降低特征集的识别准确率,而且MFCC特征在提取时的DCT损失了部分语音信号的高频特征信息,而且离散余弦变换(DCT)的降维也无法保证选取到最优的特征子集。而本文算法将1 539维频谱组合特征作为原始分类特征,按照最佳优先原则对原始的组合特征集合进行寻优降维,将特征选择得到的最优特征子集作为最终的分类特征,既有效地降低了特征的维度,降低了计算复杂度,又有效地避免了原始特征中冗余特征对分类识别效果的影响;同时本文所提的频谱融合特征既通过公式放大了语音样本特征在高频部分的差异和语音样本特征在低频部分的差异,又包含了频谱的相位谱信息,有效地涵盖了频谱特征的大部分信息,并降低了计算复杂度,提高了计算效率。相比文献[10]算法,该算法有效提高了识别准确率。
4 结语
本文从特征泛化的角度提出了一种手机来源识别的方法,用语音频谱融合特征表征手机特有的痕迹信息进行分类判别。实验结果也表明了本文所提的特征可以作为语音手机来源识别的分类特征;而且,该特征相比经典的基于MFCC特征的手机来源识别算法有更好的识别效果。该方法应用语音频谱相关特征进行手机来源识别的研究,但是仍然存在一定的局限性,例如没有考虑在噪声攻击的情况下特征的鲁棒性问题,还有基准数据库的完善和科学设置也是一项值得考究的工作,所以在接下来的工作中会对上述问题展开更加深入的研究。
参考文献(References)
[1] 胡永健, 刘琲贝, 贺前华. 数字多媒体取证技术综述[J]. 计算机应用, 2010, 30(3): 657-662.(HU Y J, LIU B B, HE Q H. Survey on techniques of digital multimedia forensics[J]. Journal of Computer Applications, 2010, 30(3):657-662.)
[2] ESKIDERE O. Identifying acquisition devices from recorded speech signals using wavelet based features [J]. Turkish Journal of Electrical Engineering & Computer Sciences, 2015, 24: 1942-1954.
[3] 贺前华, 王志锋, RUDNICKY A I,等. 基于改进PNCC特征和两步区分性训练的录音设备识别方法[J]. 电子学报, 2014,42(1):191-198. (HE Q H,WANG Z F, RUDNICKY A I, et al. A recording device identification algorithm based on improved PNCC feature and two-step discriminative training[J]. Acta Electronica Sinica, 2014, 42(1): 191-198.)
[4] KOTROPOULOS C, SAMARAS S. Mobile phone identification using recorded speech signals [C]// Proceedings of the 2014 19th International Conference on Digital Signal Processing. Piscataway, NJ: IEEE, 2014: 586-591.
[5] ESKIDERE O. Source microphone identification from speech recordings based on a Gaussian mixture model[J]. Turkish Journal of Electrical Engineering & Computer Sciences, 2014, 22(3):754-767.
[6] PANAGAKIS Y, KOTROPOULOS C L. Telephone handset identification by collaborative representations[J]. International Journal of Digital Crime & Forensics, 2013, 5(4):1-14.
[7] HICSONMEZ S, SENCAR H T, AVCIBAS I. Audio codec identification from coded and transcoded audios[J]. Digital Signal Processing, 2013, 23(5):1720-1730.
[8] 裴安山, 王让定, 严迪群. 基于设备本底噪声频谱特征的手机来源识别[J]. 电信科学, 2017,33(1):85-94.(PEI A S, WANG R D, YAN D Q. Cell-phone origin identification based on spectral features of device self-noise[J]. Telecommunications Science, 2017, 33(1):85-94.)
[9] 裴安山, 王让定, 严迪群. 基于语音静音段特征的手机来源识别方法[J]. 电信科学, 2017, 33(7):103-111.(PEI A S, WANG R D, YAN D Q. Source cell-phone identification from recorded speech using non-speech segments[J]. Telecommunications Science, 2017, 33(7):103-111.)
[10] HANILCI C, ERTAS F, ERTAS T, et al. Recognition of brand and models of cell-phones from recorded speech signals[J]. IEEE Transactions on Information Forensics & Security, 2012, 7(2): 625-634.
[11] KOTROPOULOS C L. Source phone identification using sketches of features[J]. IET Biometrics, 2014, 3(2): 75-83.
[12] 沈连丰,叶之慧. 信息论与编码[M]. 北京: 科学出版社.2004:12-17. (SHEN L F, YE Z H. Information Theory and Coding[M]. Beijing: Science Press, 2004: 12-17.)
[13] XU L, YAN P, CHANG T. Best first strategy for feature selection [C]// Proceedings of the 9th International Conference on Pattern Recognition. Piscataway, NJ: IEEE, 1988: 706-708.
[14] HALL M A. Correlation-based feature selection for machine learning [D]. Hamilton, New Zealand: The University of Waikato, 1999: 51-74.
[15] 林升梁,刘志. 基于RBF核函数的支持向量机参数选择[J].浙江工业大学学报,2007,35(2):163-167.(LIN S L, LIU Z. Parameter selection in SVM with RBF kernel function [J]. Journal of Zhejiang University of Technology, 2007, 35(2): 163-167.)
This work is partially supported by the National Natural Science Foundation of China (61672302, 61300055), the Natural Science Foundation of Zhejiang Province (LZ15F020002, LY17F020010), the Ningbo Natural Science Foundation (2017A610123), the Scientific Research Foundation of Ningbo University (XKXL1509, XKXL1503).
PEIAnshan, born in 1992, M. S. candidate. His research interests include multi-media communication, information security, mobile terminal source detection.
WANGRangding, born in 1962, Ph. D., professor. His research interests include multi-media information security, digital forensics.
YANDiqun, born in 1979, Ph. D., associate professor. His research interests include multi-media information security, digital forensics.
猜你喜欢
数学物理学报(2022年2期)2022-04-26 14:08:06
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
空间科学学报(2021年6期)2021-03-09 06:20:14
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
测控技术(2018年7期)2018-12-09 08:58:22
中学生数理化·高一版(2018年10期)2018-11-08 11:06:56
西南交通大学学报(2018年5期)2018-11-08 10:59:16
新闻传播(2016年11期)2016-07-10 12:04:01
无线电通信技术(2015年3期)2015-12-23 11:37:00
计算机工程(2015年4期)2015-07-05 08:29:20
