
基于不平衡文本数据挖掘的铁路信号设备故障智能分类
2018-05-07 00:34杨连报马小宁吴艳华
铁道学报 2018年2期
杨连报,李 平,薛 蕊,马小宁,吴艳华,邹 丹
(1.中国铁道科学研究院,北京 100081;2.中国铁道科学研究院 电子计算技术研究所,北京 100081)
铁路信号设备是铁路信号、车站联锁设备、区间闭塞设备等的总称,是保证列车运行与调车作业安全的重要保障[1]。随着铁路信号设备的升级改造和快速发展,铁路局积累了海量的铁路信号设备事故故障数据。铁路信号设备故障多以非结构化文本形式记录,需依靠人工理解和专家经验进行故障分类,易造成故障分类的不准确和随意性。在铁路大数据时代,应用文本挖掘等机器学习算法实现铁路信号设备故障的智能分类是当前急需解决的问题。
铁路信号设备类型众多且各设备故障机理不同[2],存在故障类别数据不平衡的问题,即绝大多数文本属于同一类故障,而其他故障只有少量的文本。铁路信号设备故障智能分类通过文本挖掘技术实现对铁路信号设备故障不平衡文本数据的结构化转换,通过故障类别数据均衡以及集成学习EL(Ensemble Learning)[3]实现故障的智能分类。
铁路信号设备故障不平衡文本数据结构化转换,主要是指提取故障文本的特征并转换为向量。目前,文本数据主要基于词袋法BOW(Bag of Words)以向量空间模型VSM[4](Vector Space Model)来表征文档,即将文档看成一系列词的集合,通过抽取能够表征文档特征的关键词并转换为向量。最常用的文本特征提取算法有词频-逆文档频率TF-IDF[5](Term Frequency-Inverse Document Frequency)、信息增益IG[6](Information Gain)、互信息MI[7](Mutual Information)、主题模型TM[8](Topic Model)、Word2Vec[9-10]、卡方检验等。其中,以TF-IDF使用最为广泛和简单。由于铁路行业缺乏语料库,关于铁路信号设备文本结构化转换的研究较少。文献[11]通过主题模型实现对高铁信号系统车载设备文本的特征提取,并通过贝叶斯网络实现故障诊断。文献[12]通过TF-IDF实现文本特征向量提取,并通过词云的形式实现对地铁施工安全风险的分析。
铁路信号设备的故障文本数据均衡与集成学习,主要是从数据和算法两方面来解决数据不平衡问题。数据层面主要是通过更改数据集的样本分布来实现数据的平衡,主要分为过采样和欠采样两种[13]。过采样是自动生成小类别数据,欠采样是选取大类别数据中的部分样本。文献[14]提出的SMOTE(Synthetic Minority Oversampling Technique)算法是过采样中比较常用的一种,主要有Borderline-SMOTE[15]、SVM-SMOTE等几种改进版本。其基本思想是合成新的少数类别样本,实现样本类别的平衡。算法层面主要通过训练多个分类器,充分利用分类器的差异性,通过Voting方式实现不同分类器的集成学习。传统的文本分类主要是基于单个分类器模型,如逻辑回归LR(Logistic Regression)、决策树DT(Decision Tree)、SVM(Support Vector Machine)和离散型朴素贝叶斯Multinomial NB(Multinomial Naive Bayesian)等[16],但这些分类器模型主要适用于平衡的训练数据样本。集成分类器主要包含Bagging和Boosting两种,Bagging的代表算法主要是随机森林RF[17](Random Forest),Boosting的代表算法是梯度提升树GBDT[18](Gradient Boost Decision Tree)等。
本文借鉴专家学者在文本结构化处理和不平衡数据分类中的经验,结合铁路信号设备文本数据特点,提出基于TF-IDF+SVM-SMOTE+Voting的多分类器集成学习分类模型。该模型通过TF-IDF算法实现故障文本的特征抽取和向量转化,并利用SVM-SMOTE算法实现铁路信号设备故障小类别数据的自动生成,通过Voting的方式集成LR、Multinomial NB、SVM等基分类器以及RF、GBDT等集成分类器算法,实现铁路信号设备的智能分类。为验证模型的正确性和有效性,本文选取某铁路局2012—2016年铁路信号设备故障不平衡文本数据共计10类641条进行试验分析。
1 铁路信号设备故障智能分类整体架构
基于不平衡文本数据挖掘的铁路信号设备故障智能分类的整体架构如图1所示,整个架构分为数据处理层、模型优化层和智能分类层3个层次。
框架的最底层是数据处理层。数据处理层主要实现铁路信号设备故障文本数据结构化处理,抽取文本的特征,并转换为计算机可识别和计算的文本向量。针对转化后的文本向量,利用SVM-SMOTE模型对小类别数据进行自动生成,从数据层面解决样本数据不均衡的问题。
框架的中间层为模型优化层。针对数据处理层所得到的样本数据,模型优化层利用逻辑回归、朴素贝叶斯、支持向量机等基分类器,以及随机森林、GBDT等集成分类器进行分类,并根据参数特点进行调优。调优的参数主要有迭代次数、学习步长、采样率等。最后,通过Voting的方式对调优后的集成分类器以及基分类器进行集成学习,得到最终的智能分类模型。
框架的最上层为智能分类层。智能分类层主要是根据模型优化层得到的智能分类模型,对待分类的文本进行自动分类。
2 不平衡故障文本数据处理
铁路信号设备主要包含调度集中CTC(Centralized Traffic Control)设备、列车调度指挥系统TDCS(Train Operation Dispatching Command System)设备、列车运行监控装置LKJ、车载设备、联锁设备、闭塞设备、道岔、轨道电路、信号机、电源屏设备。铁路信号设备故障分类方式有多种,本文按照设备的功能及现象来划分,主要分为10类故障,即CTC设备故障、LKJ设备故障、TDCS设备故障、闭塞设备故障、车载设备故障、道岔故障、电源屏故障、轨道电路故障、微机联锁故障、信号机故障等。图2为某铁路局电务段2012—2016年信号设备故障分布情况。

图1 基于不平衡文本数据挖掘的铁路信号设备故障智能分类整体架构

图2 某铁路局电务段2012—2016年铁路信号设备故障分布情况
由图2可知,故障主要以道岔、轨道电路、信号机等为主,对于微机联锁、TDCS、闭塞等设备的故障较少,不均衡比例达到1∶40,为典型的数据分类不均衡问题,直接通过模型训练容易造成分类的不准确。
2.1 铁路信号设备故障文本数据与中文分词
铁路信号设备故障文本数据主要由现场人员通过自然语言记录所形成。部分实例见表1,表1中记录的主要信息为故障发生经过、原因描述以及故障分类。

表1 铁路信号设备故障文本数据(部分)
铁路信号设备故障文本数据结构化处理首先要实现故障文本的分词。主流的分词技术主要有基于词典匹配的中文分词、基于字统计模型的中文分词、基于字标注的中文分词以及基于深度学习的中文分词等。本文采用Jieba分词工具,利用通用词典和自定义领域词典实现铁路信号设备故障文本的分词,如图3所示。自定义领域词典主要是铁路信号设备故障的常用词汇。

图3 领域词典与通用词典相结合的铁路信号设备中文分词
2.2 基于TF-IDF的故障文本特征提取与向量化
TF-IDF(Term Frequency-Inverse Document Frequency)是一种基于统计的常用加权方法,广泛应用于检索与文本分析中。TF-IDF假设:如果一个词在一个文档中频繁出现,而在其他文档中出现较少或不出现,则认为该词作为该文档的关键词,将该文档与其他文档区分开来。
TF表示词频,即该词在一个文档中出现的次数,理论上出现的次数越多则与文档的主题越相关,但需要排除一些停用词,如“的”“地”“了”“但”等。词频TFi,j为
( 1 )
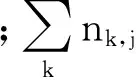
逆向文档频率IDFi为
( 2 )
式中:ki为词wi在文档集合D中相关的文档个数;N为D的大小;同理,分母加1是为了避免分母为0的情况。
将词频与逆向文档频率结合起来,即用IDFi来矫正TFi,就得到了文档dj中词wi的权重,即
Wi,j=TFi×IDFi
( 3 )
则某个文档dj可用单词权重构成向量
dj=[W1,jW2,jW3,j…Wn,j]
( 4 )
2.3 基于SVM-SMOTE的故障少数类别样本自动生成
SMOTE是一种常用的合成少数类样本数据以达到训练集数据的类别平衡的过采样技术,使得分类器的学习能力得到显著提高。其基本原理为:通过选择少数类样本xi的k个邻近同类样本,并从k个邻近同类样本中随机选取一个xj,通过随机线性插值,构造出新的少数类样本xnew为
xnew=xi+u(xi-xj) 0≤u≤1
( 5 )
由于传统SMOTE没有考虑其邻近样本的分布特点,可能在类别间发生重复。近年来有一些基于SMOTE的改进算法相继被提出,具有代表性的算法包括Borderline-SMOTE算法、SVM-SMOTE算法等。Borderline-SMOTE仅对边界上的少数类样本进行线性插值,从而起到加强边界样本的作用。SVM-SMOTE根据不同类别样本邻近比例,通过SVM构造分类边界,能够根据实际的样本数据分布进行插值,使得类别之间区分更为明显。需要说明的是,SVM-SMOTE主要利用SVM对不平衡数据分类不太敏感的特性,用于平衡数据,使分类效果更佳。因此,本文选择SVM-SMOTE算法实现少数类别数据的生成。不同SMOTE算法生成少数类样本的效果如图4所示。

图4 不同SMOTE算法合成少数类样本示意图
3 基于Voting的多分类器集成学习故障智能分类模型
3.1 基分类器

(1)LR是一种基于统计分析的分类方法,可以得到概率型的分类结果为
( 6 )
由此可以得出相应的Logistic回归模型为
gk(x)=βk0+βk1x1+βk2x2+…+βkmxm
( 7 )
参数β的计算通常通过最大似然方法进行估计。
(2)DT是一种特殊的树形结构,主要用来进行分类和决策。决策树包含3种类型的节点,分别为:决策节点,通常用矩形框来表示;机会节点,通常用圆圈来表示;终结点,通常用三角形来表示。常用的决策树生成算法有ID3、C4.5和C5.0等。
(3)SVM是通过构造一个超平面f(x),使得该函数能够表示类别y与样本向量x的关系。定义线性x不敏感损失函数为
( 8 )
如果存在一个超平面,即
f(x)=ωTx+b=0
( 9 )
式中:ω∈Rn,b∈R,使得
|y-f(x)|≤ε
(10)
则称样本集D是ε-线性近似的,f(x)为线性回归估计函数。样本点{xi,yi}到超平面的距离为
(11)
为得到最优的超平面分类,转换为一个优化问题,即使‖ω‖2最小。
针对非线性问题,SVM通过非线性映射φ(xi)将样本映射为高维特征空间,并通过核函数的方式计算内积。此时优化问题的目标函数可表示为

(4)MultinomialNB是适用于离散特征的朴素贝叶斯模型。该模型将文档看作是带词频的词语集合,在计算先验概率和条件概率时,会做一些平滑处理,从而解决如果某一维的特征值没在训练样本中出现,使得后验概率为0的问题。
先验概率p(y=k)为
条件概率p(xi|y=k)为
式中:Ny=k是类别为k的样本个数;Ny=k,xi是类别为k的样本中,特征向量为值是xi的样本个数;α为平滑值。当α=1时,称作Laplace平滑;当0<α<1时,称作Lidstone平滑;当α=0时,不做平滑。
3.2 集成分类器
集成分类器是将多个基分类器按照一定策略进行组合而共同决策的分类器。主要包括基分类器间相互依赖的Boosting算法和基分类器间相互独立的Bagging算法。Boosting通过对样本集的操作获得样本子集,利用样本子集训练基分类器,最后通过对基分类器的加权融合获得集成分类器。Bagging算法是随机有放回的选择训练数据构造基分类器,进行组合得到集成分类器。本文选取基于Bagging的并行集成分类器RF和基于Boosting的串行集成分类器GBDT进行文本分类。
RF使用CART决策树作为基分类器,同时对决策树的建立做了改进。传统决策树在节点上所有的n个样本特征中选择一个最优的特征来做决策树的左右子树划分,RF通过随机选择节点上的nsub(nsub≤n)个样本特征,在这些随机选择的子样本特征中,选择一个最优的特征来做决策树的左右子树划分。RF进一步增强了模型的泛化能力,避免了过拟合现象的出现。RF主要的调优参数为Bagging框架参数和CART决策树参数,其中Bagging框架参数包括最大迭代次数等,CART决策树参数有最大树深度等。
GBDT又叫MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵CART回归决策树组成,通过梯度提升算法实现损失函数的优化,最终得到最优的回归树。GBDT需要调优的参数较多,主要分为Boosting框架参数和CART树参数,其中Boosting框架参数包括最大迭代次数、学习步长等,CART决策树参数有最大树深度。
3.3 基于Voting的多分类器集成学习
集成学习的基本原理是构造若干个分类精度不高的弱分类器,把各个弱分类器的结果按照一定策略组成一个强分类器,从而解决分类问题。多分类器集成学习的优势在于,克服了弱分类器现实分类中存在的计算和统计方面的问题,减少分类中存在的位置风险,具有更好的泛化能力。
假设分类器的错误率相互独立,随着集成中基分类器数目的增大,集成的错误率将以指数级下降,最终趋向于零。但在实际任务中,基分类器很难互相独立。为了选取尽量准确和多样的集成分类器,本文根据基分类器和集成分类器在样本数据集上的表现性能,优先选取分类效果最好的分类器进行集成学习,通过最优分类器与其他分类器的加权投票组合,选出表现性能最优的组合集成分类器。该方法的基本流程如图5所示。
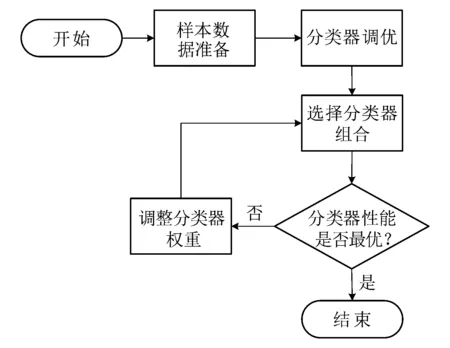
图5 基于Voting的多分类器集成学习流程
4 试验分析
本文通过选择某铁路局电务段的电务设备不平衡故障文本数据来验证所提方法的有效性和准确性。试验数据包含10种故障类别643条数据。本文采取准确率Precision,召回率Recall和F-score作为模型评价和对比的指标。
准确率计算公式为
(15)
召回率计算公式为
F-score计算公式为
式中:TPi为被正确分到此类的实例个数;TNi为被正确识别不在此类的实例个数;FPi为被误分到此类的实例个数;FNi为属于此类但被误分到其他类的实例个数;C表示所有类别的总数。
试验主要分为两部分,即不平衡故障文本数据处理试验分析;基于SMOTE处理后基于Voting的多分类器集成学习故障智能分类试验分析。
4.1 不平衡故障文本数据处理试验分析
试验使用Jieba分词工具实现电务设备故障文本的分词,并通过TF-IDF计算权重并进行归一化,得到试验文本故障数据的向量表示。为验证SMOTE处理不平衡数据的故障文本数据效果,通过SVM-SMOTE方法生成了少数类别数据。其中,TDCS设备故障数据由原来的6条自动生成为172条,闭塞设备故障由原来的6条生成为84条,微机联锁故障由原来的6条生成为133条,总数据量变为1 014条,见表2。

表2 原始数据和SMOTE生成少数类别数据
4.2 故障智能分类试验分析
试验选取了常用的传统基分类器(LR,Multinomial NB和SVM)和集成分类器(RF和GBDT),分别在原始数据集和采用SMOTE处理前后的两个数据集进行训练和测试,并通过准确率、召回率、F-score等分类性能指标进行对比分析,从而验证SMOTE处理不平衡数据的故障文本数据对分类性能的影响。为防止产生过拟合的问题,两个数据集均随机选取80%用来训练分类器,20%作为测试集。
4.2.1 原始文本数据集分类试验
集成分类器需要根据样本数据调优才能达到较好的分类效果。试验通过GridSearchCV进行调优,经过调优后,RF的最佳迭代次数为180次,GBDT的最优迭代次数为180,学习步长为0.3,最优采样率为0.8。调优后的集成分类器和传统基分类器的分类结果见表3。

表3 原始数据分类效果
由表3可知,针对极端不平衡的文本数据集,集成分类器的效果略优于基分类器,而基分类器中逻辑回归的分类效果最差,集成分类器中随机森林的分类效果最佳。
4.2.2 SMOTE处理后文本数据集分类试验
在用SMOTE方法对少数类数据进行补足之后,对分类器进行重新训练和测试。此时集成分类器的RF最优迭代次数为160,GBDT的最优迭代次数为180,学习步长为0.3,最优采样率为0.6。分类结果见表4。
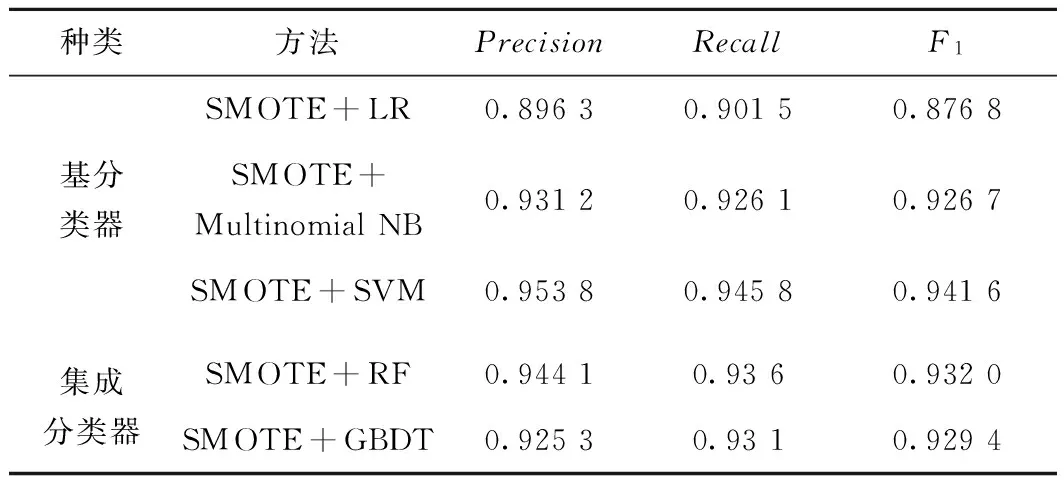
表4 SMOTE生成数后的分类效果
由表4可以看出,经过SMOTE对不均衡故障文本数据处理之后,基分类器和集成分类器的各分类指标均有明显提高。尤其基分类器中SVM的分类效果有了大幅提升。
4.2.3 SMOTE+Voting集成分类试验
在上述试验的基础上,选取基分类器和集成分类器进行Voting集成学习,其中选择表现性能最好的SVM分类器与其他4种分类器的组合,通过Voting的方式实现集成学习,得到的分类效果见表5。

表5 SMOTE+Voting集成分类效果
由表5可以看出,SVM+LR+RF、SVM+LR+GBDT、SVM+LR+Multinomial NB等的组合并没有提高整体的分类效果,而是和基分类器SVM分类效果一样。而SVM+Multinomial NB+RF、SVM+Multinomial NB+GBDT、SVM+GBDT+RF的集成学习均比SVM单个分类器的效果要好,尤其SVM+Multinomial NB+RF的性能最佳,准确率、召回率和F-score均有1%的提高。
4.3 试验总结
根据以上试验分析,以SVM分类为例,对比其在原始数据集、SMOTE处理后数据集和SMOTE+Voting方法之后的分类性能,如图6所示。

图6 SVM不同处理方法分类性能比较
由图6可以看出,针对不平衡故障文本数据,本文提出的SMOTE+Voting的多分类器集成算法在各方面的性能指标最优。说明本文提出的铁路信号设备智能分类模型算法在处理不平衡样本的文本数据上具有优势,可为铁路电务设置不平衡故障文本数据分类提供参考。
5 结束语
本文通过对铁路信号设备故障文本数据进行分词和基于TF-IDF转换为权重特征向量,实现故障文本数据的向量表示。同时,利用SVM-SMOTE实现铁路信号设备小类数据的自动生成,从而均衡故障文本数据,提高分类效果。通过逻辑回归、Multinomial NB、SVM等基分类器以及随机森林、GBDT等集成分类器,对SMOTE处理后的数据进行训练和学习,得到最优的分类模型。为提高分类模型的泛化能力,提出基于Voting的多分类器集成学习分类方法。通过对某铁路局电务段的铁路信号设备不平衡故障文本数据的试验,验证了所提模型的准确性和有效性,为铁路信号设备智能分类提供了新的思路和解决方案。
参考文献:
[1]佟立本.铁道概论[M].7版.北京:中国铁道出版社,2016.
[2]李佳奇,党建武.基于MAS电务故障诊断模型的研究[J].铁道学报,2013,35(2):72-80.
LI Jiaqi,DANG Jianwu.Study on Electric Fault Diagnosis Model Based on MAS[J].Journal of the China Railway Society,2013,35(2):72-80.
[3]DIETTERICH T G.Ensemble Methods in Machine Learning[C]//Mutliple Classifier Systems.Berlin:Springer Berlin Heidelberg,2000:1-15.
[4]TURNEY,PETER D,PANTEL,et al.From Frequency to Meaning:Vector Space Models of Semantics[J].Journal of Artificial Intelligence Research,2010,37(1):141-188.
[5]El-KHAIR I A.TF*IDF[J].Encyclopedia of Database Systems,2009,13(12):3085-3086.
[6]STACHNISS C,GRISETTI G,BURGARD W.Information Gain-based Exploration Using Rao-Blackwellized Particle Filters[C]//Robotics:Science and Systems Conference,2005:65-72.
[7]WANG G,LOCHOVSKY F H.Feature Selection with Conditional Mutual Information Maximin in Text Categorization[C]//Thirteenth ACM International Conference on Information and Knowledge Management.ACM,2004:342-349.
[8]ZHU Y,LI L,LUO L.Learning to Classify Short Text with Topic Model and External Knowledge[C]//International Conference on Knowledge Science,Engineering and Management.Berlin:Springer Berlin Heidelberg,2013:493-503.
[9]MIKOLOV T,CHEN K,CORRADO G,et al.Efficient Estimation of Word Representations in Vector Space[J].Computer Science,2013.
[10]MIKOLOV T,SUTSKEVER I,CHEN K,et al.Distributed Representations of Words and Phrases and Their Compositionality[C]//International Conference on Neural Information Processing Systems.Nevada:Curran Associates Inc.,2013:3111-3119.
[11]赵阳,徐田华.基于文本挖掘的高铁信号系统车载设备故障诊断[J].铁道学报,2015,37(8):53-59.
ZHAO Yang,XU Tianhua.Text Mining Based Fault Diagnosis for Vehicle On-board Equipment of High Speed Railway Signal System[J].Journal of the China Railway Society,2015,37(8):53-59.
[12]李解,王建平,许娜,等.基于文本挖掘的地铁施工安全风险事故致险因素分析[J].隧道建设,2017,37(2):160-166.
LI Jie,WANG Jianping,XU Na,et al.Analysis of Safety Risk Factors for Metro Construction Based on Text Mining Method[J].Tunnel Construction,2017,37(2):160-166.
[13]HE H,BAI Y,GARCIA E A,et al.ADASYN:Adaptive Synthetic Sampling Approach for Imbalanced Learning[C]//IEEE International Joint Conference on Neural Networks.New York:IEEE,2008:1322-1328.
[14]CHAWLA N V,BOWYER K W,HALL L O,et al.SMOTE:Synthetic Minority Over-sampling Technique[J].Journal of Artificial Intelligence Research,2002,16(1):321-357.
[15]HAN H,WANG W Y,MAO B H.Borderline-SMOTE:a New Over-Sampling Method in Imbalanced Data Sets Learning[J].Lecture Notes in Computer Science,2005,3644(5):878-887.
[16]AGGARWAL C C,ZHAI C.A Survey of Text Classification Algorithms[J].Springer US,2012,45(3):163-222.
[17]BREIMAN L.Random Forests[J].Machine learning,2001,45(1):5-32.
[18]FRIEDMAN J H.Greedy Function Approximation:a Gradient Boosting Machine[J].Annals of Statistics,2001,29(5):1189-1232.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
电子技术与软件工程(2019年18期)2019-11-18
铁道通信信号(2019年8期)2019-10-10
铁道通信信号(2019年6期)2019-10-08
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国惯性技术学报(2018年4期)2018-11-08
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
铁道通信信号(2018年4期)2018-06-06
初中生世界·七年级(2017年9期)2017-10-13
电子技术与软件工程(2017年14期)2017-09-08
