
基于神经网络的芯片表面字符检测识别系统
2018-05-07 03:27唐铭豆陶青川冯谦
现代计算机 2018年9期
唐铭豆,陶青川,冯谦
(四川大学电子信息学院,成都 610065)
0 引言
当前,在许多车间工厂需要对产品进行测试,在生产、试验的各测试环节,需要将产品编号与测试数据一一对应地记录保存,以满足质量控制、跟踪管理等方面的要求。而往往进行测试时,由于产品数量巨大以及产品失效等客观原因,产品编号和测试数据是分开管理的,在对产品进行测试前,需要先对产品进行排序,产品编号的记录工作通常采用人眼观察排序的方式,效率低下并易出错。而通过计算机视觉技术,利用模式识别及人工智能相关算法来实现器件编号的自动识别与记录,可以极大地提高测试效率,提高准确率,减少人工,且实现产品编号和测试数据同时获取与记录保存,将非常有利于测试自动化程度的提高,对生产测试过程的效率起到极大的改善作用,并降低人工失误带来的损失。
在利用计算机视觉和神经网络来进行检测和识别文字字符在近年来也取得了一些成果。在目标检测领域,S Ren等人在16年提出的Faster R-CNN[1]在ILS⁃VRC和COCO 2015比赛中检测准确率都取得了第一名的成绩,其检测速度可以达到每秒5帧。而由J Redmon等人提出的YOLO[2]方法在检测目标时速度更快,可以达到每秒45帧,但付出的代价是准确率会在一定程度上有所下降。而识别文字字符实际上是一个图像分类的过程,利用图像的HAAR,HOG,LBP特征来进行SVM分类是一种成熟的图像分类方法,但具体选取哪种特征需要人为选定,在场景迁移上鲁棒性不高。在这个领域比较著名的是Ian J.Goodfellow在2013年提出的街景多位数识别[3],是基于CNN网络,可以实现多位数字符的识别,但需要预先给出待预测的字符序列的最大长度。另外一种常用的方法是RNN结合CTC的方法,该方法不需要预先分割字符,直接对整行字符进行识别,但它的计算效率没有CNN高,并且还有潜在的梯度爆炸和梯度消失的问题。无论是RCNN还是YOLO,在进行检测时依赖于GPU的计算能力,在实际工业生产领域,考虑低功耗且由于GPU的成本过高,而直接使用CPU利用RCNN或YOLO检测又存在时间过长的问题,因此提出了一种在低配置下利用传统方法分割字符,CNN网络识别字符来进行字符提取的方法。
1 系统方案
识别系统由软件和硬件两大部分组成,硬件部分主要完成图像采集与传输,软件部分负责对图像进行处理,得到器件编号的识别结果,并将结果保存。硬件部分主要由相机、镜头、光源、支架、计算机组成。将相机固定于支架上,对器件(样本)进行成像,采集的图像通过千兆网传输给计算机。识别软件对采集的图像进行分析处理,输出并保存识别结果。系统设计图如图1所示。

图1 系统结构示意图
算法流程图如图2所示。
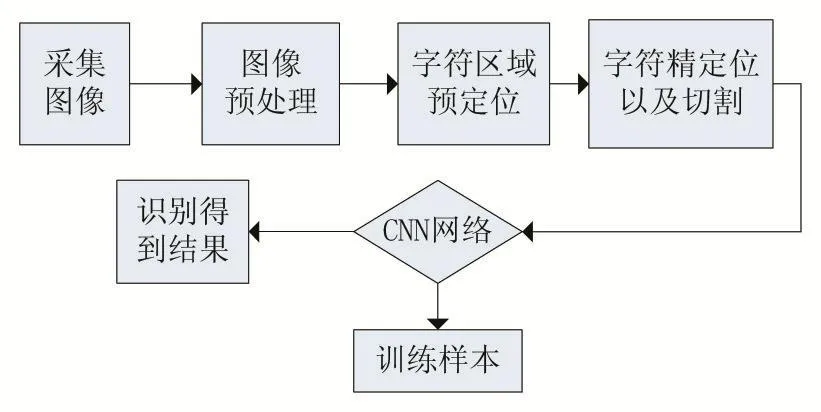
图2 算法流程图
2 图像预处理
当计算机得到相机采集的图片后,虽然相机的分辨率很高,能够获得高清的芯片字符,但由于现场灯光环境复杂,会有少量光照不均匀的现象,在一定程度上会影响后续检测和识别结果,因而需要对图像进行预处理。
直方图均衡化[4]在处理光照过亮或过暗时有很好的效果,其基本原理是将原图的灰度直方图进行拉伸,将原来直方图灰度覆盖范围扩大,使得图像局部的明暗对比度更大。首先根据式(1)求得图像的灰度直方图:

其中Pk是灰度的每一级,即0-255,rk是每一级灰度所对应的像素个数,n是整副图像对应的所有像素个数总数。在均衡化时选取灰度的累积概率作为原图到新图的映射函数,根据式(2)求得图像的累积直方图:

再根据式(3)求得变换后新图像素:

其中M为最大灰度级,Di为变换后新图像素,F(Pk)代表灰度级为k时在原图的累积概率。
预处理效果图如图 3(a)、图 3(b)所示。

图3
灰度直方图对比效果如图 4(a)、图 4(b)所示:

图4
由图可见,整幅图像的清晰度得到了极大的提高,同时也消除了一些噪点,有利于后续的检测识别字符。
3 字符定位
由于字符位于芯片区域内,所以在对字符进行定位前先进行对芯片区域的定位可以提高对单个字符定位的准确度。根据芯片具有一定范围内的长宽比,且是图片中最大的连通区域这两个特点可以很快定位出芯片区域。
首先对图片进行二值化操作,二值化是为了让目标跟背景分离,将图片像素值与阈值进行大小比较,使得图片只有黑白两种颜色,阈值大小的选取直接关系到二值化后的效果。人工选取阈值具有太多的不确定因素,而大津法二值化[5]可以自适应的确定阈值即类间方差最大的阈值。设最终选取的阈值为T,图像的高为M,宽为N,令小于等于阈值的像素点为目标像素点,大于阈值的像素点为背景像素点,设目标点的个数为N1,背景点的个数为N2,目标点占总像素点的比例为w1,目标点的平均像素值为 p1,平均灰度值为背景点的比例为w2,背景点的平均像素值为p2,图像的平均像素值为p,设类间方差为g,则有:
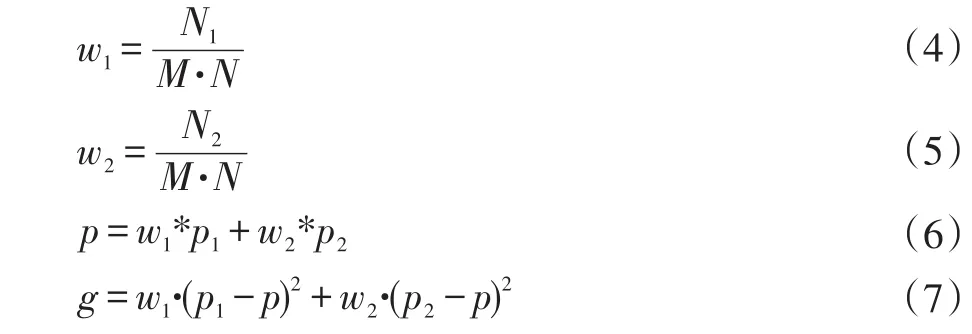
由式(4)-(7)可以推出:

对于阈值T均有对应的类间方差值gt,若灰度级为255,则当阈值T从0取至255时,gt最大时,此时阈值即为求得的阈值。二值化后效果图如图5所示。

图5 二值化后效果图
在二值化完毕后对图像进行查找连通区域[6]的操作,即查找像素值为255的连通区域。在查找连通区域时,采用一种基于路程的标记算法,只需遍历一次图像,相比轮廓搜索算法效率更高。
在定位出芯片区域之后重新对芯片区域进行二值化,二值化后并查找连通区域,再求得正外接矩形即可定出若干个字符区域如图6所示。

图6 字符定位效果图
对于字符中宽度异常的字符如图中的629矩形框,需要进行字符分割处理,分割时,求得该区域的上下轮廓边界,如图7所示。

图7 “629”外轮廓示意图
在参照其他已定位字符宽度的同时,对于上边界轮廓,求得轮廓Y坐标的极小值,对于下边界轮廓,求得轮廓Y坐标的极大值,而分割字符线就即为轮廓的极小极大值所在点的纵向切线,这样就将原来的粘连字符分割为3个单独的字符,通过以上方式即可完成字符的检测定位。
4 卷积神经网络训练和识别
在图像分类和图像识别领域,卷积神经网络已经取得了许多突破性的研究成果。卷积神经网络[7](CNN)由生物学家Hubel和Wiesel于20世纪60年代在研究猫的脑皮层时发现在对于神经元的选择时具有独特的网络结构,并且可以使前反馈网络的复杂性得到有效降低。卷积神经网络的最大优势是可以减少在前期对图像的各种提取特征,而直接将原始图像输入到网络中。用卷积神经网络来进行识别和分类数字可以使得特征提取和模式识别两个过程同时进行,且提取的特征是非线性的,意味着特征更复杂更符合,另外,输入图像可以通过监督自学习进行特征的提取和计算。LeNet5[8]结构的卷积神经网络是Yann LeCun设计的用于手写数字识别的卷积神经网络,在图像分类和识别方面效果显著,利用其网络来进行手写体识别,准确率可以达到99%以上,结构图如图8所示。

图8 结构图
LeNet5结构由卷积层conv,池化层pool和全连接层组成。卷积层由多个特征平面组成,特征平面又称作特征图,特征平面里由一系列排列为矩形的神经元构成,权值由每个特征平面里所有神经元共享,而这里共享的权值即为卷积核,卷积核初始化时会赋予随机小数矩形,经训练后得到合适的权值。池化层又称作子采样层,子采样可以看作一种特殊的卷积过程,通常有均值子采样和最大值采样两种形式,通过池化层可以简化模型复杂度,减少模型参数。卷积层和池化层并作一起,共同构成了特征抽取层,从原始图像中提取合适的特征。卷积神经网络的训练过程与传统神经网络类似,和普通神经网络类似,分为两个阶段。第一阶段为向前传播阶段,首先从样本集中取一个样本(X,Yp),X为输入向量,Yp为理想输出结果,将X输入网络,从输入层经过逐级的变换,传送到输出层。在这个过程中,网络执行的是输入与每层的权值矩阵点乘,如式(9)所示:
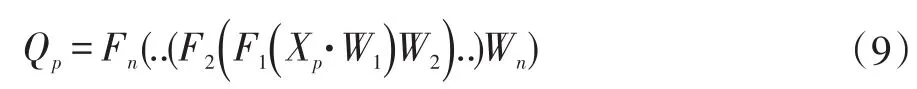
其中Qp为实际输出,训练的第二阶段为向后传播阶段,当算出实际结果后,计算Qp与Yp的差,再按极小化误差的方法反向调整权值矩阵。
在卷积层中将卷积核与前一层的所有特征图(Fea⁃tureMap)进行卷积求和,再加上偏置量,输入激活函数生成当前层的神经元,即构成该层不同局部特征的特征图。卷积层的计算公式如式(10)所示:

在式(10)中,⊗为卷积操作,l为当前层,l-1为上一层,为第l层的第j个特征图,为上一层的第i个特征图,Wi,j为当前层第j个特征图与前一层第i个特征图之间的卷积核,为当前层的第j个特征图的偏置量,M为当前层所有特征图的数量,θ(·)为激活函数,这里可以使用Sigmoid或者ReLU来实现,激活函数使得训练后得神经网络具有稀疏性,可以很好地解决参数调整过程中梯度消失的问题,从而加速网络收敛。
随着层数增加,特征图的个数也随之增加,使得维度变大,网络的计算成本增大,为了解决此问题,通常对特征图进行下采样降维,这就是池化层的作用,相当于选取了部分具有代表性的特征来代替原来全部的特征,通常采用最大池化(Max-pooling)操作来进行下采样,若下采样的窗口的大小为n×n,则经过一次池化层后,特征图大小为初始特征图的1/n2,其计算公式如式(11)所示:

在经过最后一次池化层后,接入全连接层,由于要求此时输入必须是一维数组,在完成池化操作后的特征图转换为多个一维向量,再以串联形式连接起来,形成的特征向量作全连接层的输入。全连接层上的每个神经元的输出计算公式如式(12)所示:

其中,hw,b(x)为神经元的输出,x为神经元的输入的特征向量,w为权值向量,b为加性偏置。
经全连接层输出后接入最后的分类层,在分类层中,每一个神经元输出待测样本所属类别的概率值,最终选取概率值最大的神经元作为待测样本的分类结果。
从以上可知,训练过程就是神经网络的向前传播以及反向传播过程,而测试过程就是只包括神经网络的向前传播过程。
5 分类结果对比分析
在定位字符时,与扫描线检测字符以及Faster RCNN定位方法进行了对比,结果如表1所示:

表1
将CNN分类方法与利用LBP、HOG特征来进行SVM分类方法进行了对比,结果如表2所示:

表2
测试环境均为Windows 10操作系统,CPU型号为Inter i5-4200U,内存4G,样本总数为33070个,其中训练样本为23149个,待测试样本为9921个,将样本分为37类,其中包括数字字符10类、英文字符26类以及其他字符1类。从表1、表2可以看出,连通区域法在时间性能上是较优的,CNN在性能上是较优的,两者结合能达到快速且高精度的效果。当字符历经检测分割识别后,字符间根据坐标对应关系可整理成多行字符,并输出结果。
6 结语
OCR一直是图像处理领域的热点,有着十分广泛的应用场景,本文采用轮廓方法检测字符,用深度学习的方法识别字符,既保证了时间上的快速性,又保证了极高的准确率。经大量测试,在Intel i5处理器的计算机配置下,平均检测识别准确率大于95%,平均识别时间小于0.1秒,单个字符最小识别尺寸为1.5mm×1.5mm,能够在实际生产线中稳定工作运行。
参考文献:
[1]Ren S,Girshick R,Girshick R,et al.Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2017,39(6):1137.
[2]Redmon J,Divvala S,Girshick R,et al.You Only Look Once:Unified,Real-Time Object Detection[C].IEEE Conference on Computer Vision and Pattern Recognition.IEEE Computer Society,2016:779-788.
[3]Goodfellow I J,Bulatov Y,Ibarz J,et al.Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks[J].Computer Science,2013.
[4]任艳斐.直方图均衡化在图像处理中的应用[J].科技信息,2007,(4):37-38.
[5]李了了,邓善熙,丁兴号.基于大津法的图像分块二值化算法[J].微计算机信息,2005(24):76-77.
[6]高红波,王卫星.一种二值图像连通区域标记的新算法[J].计算机应用,2007,27(11):2776-2777.
[7]周飞燕,金林鹏,董军.卷积神经网络综述[J].计算机学报,2017,40(6):1229-1251.
[8]Zhao Z H,Yang S P,Zeng-Qiang M A.License Plate Character Recognition Based on Convolutional Neural Network LeNet-5[J].Journal of System Simulation,2010,22(3):638-641.
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
北京航空航天大学学报(2022年6期)2022-07-02
集装箱化(2021年1期)2021-04-12
天津医科大学学报(2021年1期)2021-01-26
计算机应用(2020年11期)2020-11-30
汉字汉语研究(2020年2期)2020-08-13
中国信息技术教育(2020年2期)2020-02-02
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
