
MPOPTM:一种基于热量模型的微博舆情预测模型
2018-05-07 03:27谢凯梁刚杨文太杨进许春
现代计算机 2018年9期
谢凯,梁刚,杨文太,杨进,许春
(1.四川大学计算机学院,成都 610065;2.四川大学网络空间安全学院,成都 610065)
0 引言
随着Web 2.0的快速发展与广泛的应用,越来越多的新兴社交媒体的出现对人们的日常生活以及互联网产业都产生了巨大的冲击。得益于网络交流的便利性、平台的开放性、终端的可扩展性,使用的便利性与原创性,微博逐渐成为人们获取信息、分享个人信息与观点的主流媒介。與情是较多群众关于某个社会现象或事件的观点、态度以及情绪等等表现的总和。然而,某一些微博與情的传播可能会对社会或企业造成危害。例如,2011年3月,日本福岛核电站发生核泄漏,导致中国一些地区发生“抢盐潮”。其原因为微博上有人发布消息称食盐在将来可能会受到核污染;黑龙江延寿县3名在押犯人“越狱杀警”事件在微博上快速传播,造成了哈尔滨等周边地区民众的恐慌。在这些事件中,微博作为一个重要的信息传播渠道,可能影响事件的走向或对事件的结果造成影响,进而对有关部门对事件的处理造成影响。因此,监控并预测微博與情能够有效地减少有关部门在处理类似事件时的压力、快速对事件做出反应,并掌控事件的发展方向,防止其对社会产生危害。
1 相关工作
微博不同于传统的文档,大多数微博服务提供商仅允许用户上传较短的文本(140字),并且微博信息数量巨大且用语不规范,这些特点为微博的與情监控带来了新的挑战。與情预测是基于话题检测与追踪(TDT)之上的,TDT已经具有了许多经典的话题检测模型。例如,隐马尔可夫模型(HMM)、老化理论、时间序列分析以及LDA(Latent Dirichilet Allocation)模型。但是以上传统的话题检测算法均适用于长文本文档,而在微博这类短文本文档上的性能就要大打折扣。近几年来,一部分研究者尝试去找到一些新的與情检测算法并且取得了一定的成果。例如,Ritter等人[3]使用了开放域事件提取来解决推特的短文本和噪音数据的问题。Nip等人[4]通过研究回复与原文以及用户喜好之间的不同来发现微博與情的形成规律。Jiang等人[5]提出一种基于LDA主题模型的微博重要话题发现方法,但其在实时检测话题上表现欠佳。Cui等人[7]提出了一种通过推特上的Hashtags来发现突发话题的方法,但是其不适用于没有Hashtags的微博,并且在用户使用有多种意义的Hashtags的时候其检测结果不理想。Du等人[8]提出了一种基于用户关系的微博突发话题检测算法。其使用基于用户关系的改进的PageRank算法来计算关键词的权重。但是当微博回复量很小的时候,其同样不能够快速地发现目标话题。
综合上述研究,针对舆情发现中的“冷启动”问题,本文基于热传导的原理,描述了微博舆情检测中介质的相关定义,提出了微博的热量以及热传导率的概念,并建立了微博舆情发现中有关微博热量传播的模型(MPOPTM,Microblog Public Opinion Prediction based on Thermodynamic Model),根据其计算出微博的热量以及热传导率,来判断微博是否可能形成新的舆情。解决了传统舆情发现领域中不能在舆情产生初期及时发现微博舆情的问题。本文基于真实数据集进行了实验以及与传统方法进行了对比实验,结果显示MPOPTM较传统方法具有更优的检测效率。
2 系统模型
与热力学中热传导的过程类似,與情的形成过程与时间有关。随着时间的推移,微博话题将经历形成、发展、高潮、回落,然后消亡的过程,微博的关注度随着时间变化而变化,具有一个完整的生命周期。将会形成與情的微博具有两个特征:1)在一个时间窗口内,该微博话题的热度将会快速增长;2)该微博传播非常迅速。这一个过程与热量传播的过程类似,一个高热量的物体将会迅速将热量往四周传播。因此,本文根据热量模型来计算一个话题是否可能形成與情。
2.1 问题定义
在本文中,一条微博被看作一个能够传导热量的介质,微博的关注度作为该介质具有的热量。一个具有较高关注的微博有更广的传播范围以及更快的传播速度,也就更有可能形成新的舆情。而在热力学中,高温的物体也会向低温的物体传导热量,这两个过程极其相似。在MPOPTM中,通过计算在一个时间窗口内该介质的温度、比热容、质量等值,得到其在该时间窗口内的热量Q以及热传导率c,若这两个值大于设定的阈值,则该微博有可能形成新的舆情。
热量的传播需要介质,在本文中,将总的微博作为输入数据集,其中每一条微博看作一个能传播热量的介质,对介质有如下定义:
定义1将一条微博看作热量传播的介质。微博数据集定义为 B,且 B={b1,b2,b3,…,bn},其中 bi即是一条微博,bi∈B,i=1,2,3,…,n。bi能被一个三元组模型描述:bi=(com,fo,li),其中com 是该微博的评论数,fo是该微博的转发数,li是该微博的点赞数。
对于微博的热量,我们有如下定义:
定义2在一个时间窗口内,将一条微博增长的热度看作一个介质增加的热量。在热力学模型中,在一个时间窗口内增加的热量表示为Qb,其描述了在单位时间内该介质增加的热量。热量由比热容c、介质质量m、以及温度差ΔT决定。比热容c表示该微博出现的频率;质量m表示该微博的重要程度;ΔT表示该微博的增加的关注度。
通过计算当前时间窗口内该介质所吸收的热量,我们可以再计算得到该介质的热传导率。对于微博的热传导率,我们有如下定义:
定义3将一条微博的传播速度看作一个介质的热传导率。在物理学中,热传导率k是评价一个材料传导热量的性能的指标。它描述了在该介质中热量的传播速度。其由介质长度l、接触面积A、传播时间Δt、温度差ΔT、以及吸收的热量Q所决定。长度l表示有多少微博可能在讨论相似的话题;接触面积A表示该微博传播的范围;传播时间Δt表示时间窗口的大小;温度差ΔT表示该微博增加的关注度。吸收的热量Q表示在一个时间窗口内增加的热量。
通过计算一条微博在一个时间窗口内的热量以及热传导率,我们可以判断其是否有可能形成舆情,将其看作输出数据集,定义如下:
定义 4 P={P1,P2,P3,…,Pn}定义为可能形成與情的微博数据集合。其中 pi∈P,i=1,2,3,…,n,表示一条可能形成與情的微博。
2.2 微博热量计算
一条微博被定义为一种热量传播的介质,该介质所包含的热量随着介质的温度的增长而增长。这个过程与微博关注度增加的过程类似。在MPOPTM中,使用热量的吸收来描述这一过程。介质在该过程中所吸收的热量可以由式(1)所计算出来:
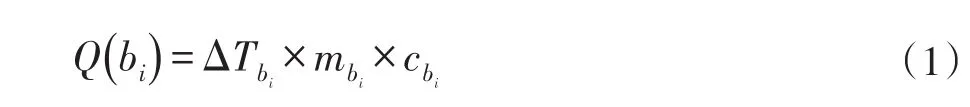
ΔTbi可由式(2)计算得到:

其中,Tt1(bi)表示在t1时刻bi的温度。温度T由微博的评论数com、转发数fo以及点赞数li来决定。其描述了bi的关注人数在该时间窗口内的增加量。T(bi)可由式(3)计算得到:
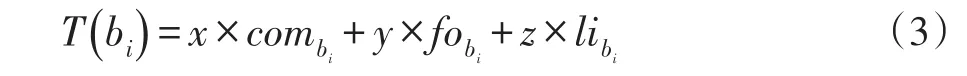
其中,x,y,z分别表示评论数com、转发数fo、点赞数li的权重,作为对应的调节参数。
质量m表示该微博在整个数据集中的重要程度,其由 TF-IDF(Term Frequency-inverse Document Fre⁃quency)所决定。

其中,tf(in)和idf(in)分别表示bi中每个词的TFIDF值。
比热容c由IDF值计算得到:
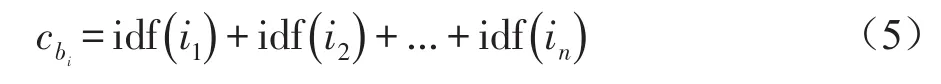
其中idf(in)表示bi的IDF值。通过计算一条微博的温度差ΔT、比热容c以及质量m等参数,最后得到该微博在一个时间窗口内吸收的热量Q,该热量即表示其在一个时间窗口内增加的关注度,热量越高,关注度也就越高,该微博便越有可能形成新的舆情。
2.3 热传导率
热量的传播需要介质。介质的热传导率越大,热量在其中传播的速度越快。热传导的过程与微博传播的过程类似,越热门的微博,传播的速度也就越快。在MPOPTM中,使用热传导率来描述微博的传播速度。其计算方式(式6)如下:
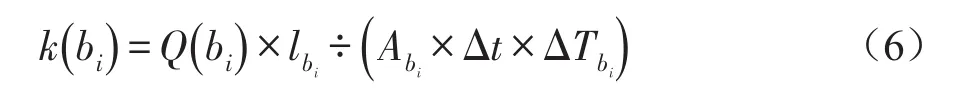
其中Q(bi)表示在一个时间窗口内传播的热量,在这里我们可将其视为在一个时间窗口内吸收的热量。因此其同样可以使用式(1)计算得到。
长度 l由 DF(document frequency)计算得到:

其中df(in)表示bi中每个词的文档频率。面积A由评论数与转发数决定:

其中com表示bi的评论数,fo表示bi的转发数。
2.4 微博舆情预测
在2.2和2.3节中,我们定义了微博热量与热传导率的计算方法。但是微博上存在大量相同的信息,因此我们需要对这些微博进行合并,多个微博共同描述同一个话题。本文使用向量空间模型结合余弦相似度的方法来计算微博之间内容的相似度。
在本文中,将数据集中的所有微博通过向量空间模型(VSM)转换为向量,并计算每两条微博之间的余弦相似度,来判断这两条微博是否描述同一个话题。余弦相似度可以由式(9)计算得到:
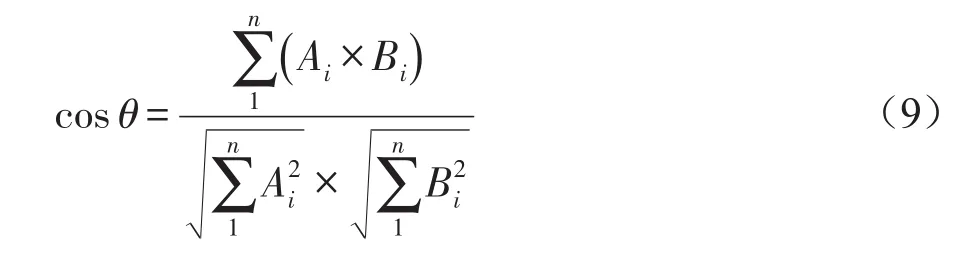
3 实验及结果分析
3.1 实验数据获取
为了测试该模型的性能,实验基于真实的微博数据集。我们选择从新浪微博上采集数据,并将其作为实验数据集。我们从工具“艾薇盒子”[13]提供的新浪微博影响力排行榜中,筛选了传媒类微博影响力排名靠前的用户微博共计55位作为数据来源。编写新浪微博爬虫获取各个目标用户发布的微博信息,作为微博输入数据集。在对其进行人工标注后,用以检测本文所以算法的性能。在新浪微博首页,每日会更新24小时内的话题排行榜,将其作为热门话题的验证数据集。
3.2 评价指标
实验计算微博的热量以及热传导率,并使用准确率(Precision,P)、召回率(Recall,R)和综合指标(F-measure,F1)[11]来对模型进行评价。

其中TP表示将正类检测为正类数,FN表示将正类检测为负类数,FP表示将负类检测为正类数,TN表示将负类检测为负类数。
3.3 实验步骤
通过爬虫采集从2017年4月1至9号,总计9天共8799条新浪微博,将此微博数据集作为模型训练样本集。使用人工标注的方法对该样本集进行标注,提取出形成舆情的微博,将其作为评价实验结果的标准。通过测试发现,采集一次样本集耗时2小时左右,将其作为最小时间窗口。输入在该时间窗口内起始和结束时刻的微博样本集,计算其中相同微博在该时间窗口内增加的转发数、评论数以及点赞数的差值,将其作为其热量Q和热传导率k的计算参数。
使用jieba分词对上一步到的微博样本集进行分词,并使用自建停用词表去停用词,使用得到的结果作为单词表。根据定义,首先计算温度差ΔT、质量m、比热容c、长度l、面积A等参数,然后计算每一条微博在每个时间窗口下吸收的热量Q以及热传导率k,筛选出大于阈值TQ以及Tk的微博。其中评论数com、转发数fo以及点赞数li的权值x、y、z的取值范围为0~1.0约束条件为x=1-y-z。将评论数com、转发数fo以及点赞数li分别与其权值x、y、z相乘,计算出在不同的参数组合下的值作为训练数据集。根据训练数据集中计算得到的分类结果的准确率P,召回率R以及综合指标F1值。选择最优的x,y,z的组合使得到的F1值最大,图1为部分参数取值示意图。

图1 部分参数示意图
经过计算,选择F1值最大的一组参数组合作为最终选择,该组的参数取值分别为:x=0.4,y=0.4,z=0.2。使用本文所提算法计算该参数组合下的训练集中被分类为舆情的每条数据的热量Q以及热传导率k,得到最小的热量与热传导率值分别为Q=15500,k=14600,将其作为热量以及热传导率的阈值。将该参数组合代入本文所提算法进行计算,得到每条微博对应的热量Q以及热传导率k。
将上一步计算得到的微博样本集计算每两条微博之间的余弦相似度,相似度大于0.8的微博看作相同的话题,最后得到可能形成舆情的微博集合P。将实验计算得到的微博集合P与验证数据集比较,计算得到MPOPTM的各项评价指标。通过训练得到MPOPTM的 参 数 取 值 为 :x=0.4,y=0.4,z=0.2,TQ=15500,Tc=14600。在测试集上使用该参数组合测试,得到相应的评价指标为P=85.01%,R=86.92%,F1=85.96%。
3.4 对比实验
使用通过网络爬虫所采集2017年4月1日至2017年4月9日共9天总计8799条微博作为数据集。对本文提出的基于热量模型的微博舆情预测模型以及话题发现领域较有代表性的算法TF-IDF和UFITUF[12]算法进行了对比实验,用以说明本文所提算法在解决微博舆情发现问题的有效性,得到如图2所示的结果。
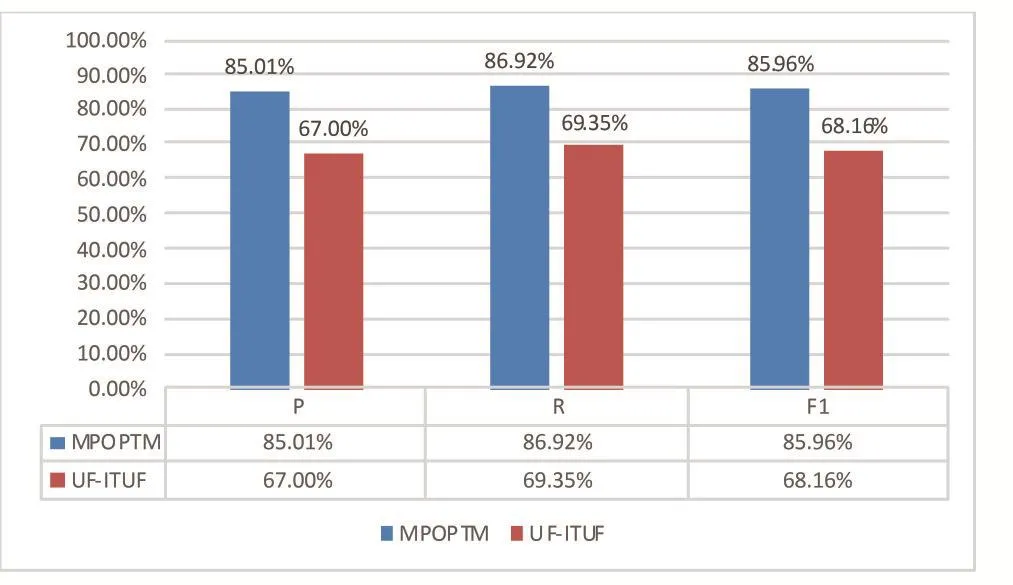
图2 实验结果对比
从实验结果中可以看出,MPOPTM在准确率、召回率以及F值上明显优于TF-IDF和UF-IUF模型。实验表明,MPOPTM能够在微博舆情形成初期快速地检测到可能形成舆情的微博。
图3是从2017年4月1日至4月9日MPOPTM和UF-ITUF模型两种方法的准确率分布情况,其中横轴表示日期,纵轴表示准确率。从图上可以看出,本文所提方法的准确率变化波动较小,检测结果相对更加稳定。在4月1日以及4月4日这两天,由于话题数量较多且较集中,两种方法的检测结果准确率都相对较低,但是MPOPTM的准确率下降幅度较小,算法的稳定性更高。因为本文使用微博首页每日更新的24小时话题排行榜作为验证数据集,将其与本文所提方法的最小检测时间作比较。通过每日随机选取20条使用本文所提算法计算出为可能形成舆情的微博,将该微博出现在微博话题排行榜上的最早时间和微博发布时间的时间差与使用本文方法能够检测出该话题的最小时间窗口作对比。计算两种方法的每日平均检测时间,计算结果如图4所示,其中横轴表示日期,纵轴表示平均检测时间。从图4中可以看出,本文所提方法所需平均检测时间更少,能够较微博话题排行榜更快地发现可能形成舆情的微博,即微博舆情形成初期检测可能形成舆情的微博,解决了微博舆情发现的“冷启动”问题,反映了本文利用热量模型来检测微博舆情的思想的有效性以及准确性。
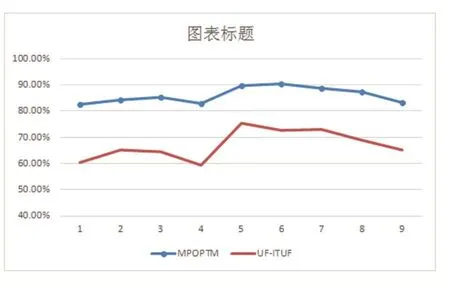
图3 准确率对比
4 结语
在本文中,我们使用了热力学模型进行建模来检测微博舆情。该模型主要着眼于解决现有技术中的“冷启动”问题,快速地发现可能形成與情的微博或刚刚产生的新舆情。在我们的模型中,我们将一条微博看作热量传播的介质,将微博的传播过程映射为热量的传播过程。通过计算微博在单位时间窗口内增加的热量Q和热传导率k,当其达到阈值时,我们认为该微博即可能形成新的與情。实验结果显示,该算法不仅能有效的检测出在微博中广为流传的微博舆情,而且也能够检测出刚刚产生的新舆情,克服了现有的微博舆情发现技术中的“冷启动”问题。

图4 平均检测时间
参考文献:
[1]Rabiner L R.A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition[J].Proceedings of the IEEE,1989,77(2):257-286.
[2]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet Allocation[J].Journal of machine Learning Research,2003,3(Jan):993-1022.
[3]Ritter A,Etzioni O,Clark S.Open Domain Event Extraction from Twitter[C].Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2012:1104-1112.
[4]Nip J Y M,Fu K.Networked Framing Between Source Posts and Their Reposts:an Analysis of Public Opinion on China's Microblogs[J].Information,Communication&Society,2016,19(8):1127-1149.
[5]姜晓伟,王建民,丁贵广.基于主题模型的微博重要话题发现与排序方法[J].计算机研究与发展,2013,50:179-185.
[6]贺敏,杜攀,张瑾,等.基于动量模型的微博突发话题检测方法[J].计算机研究与发展,2015,52(5):1022-1028.
[7]Cui A,Zhang M,Liu Y,et al.Discover Breaking Events with Popular Hashtags in Twitter[C].Proceedings of the 21st ACM International Conference on Information and knowledge management.ACM,2012:1794-1798.
[8]Du Y,He Y,Tian Y,et al.Microblog Bursty Topic Detection Based on User Relationship[C].Information Technology and Artificial Intelligence Conference(ITAIC),2011 6th IEEE Joint International.IEEE,2011,1:260-263.
[9]申国伟,杨武,王巍,等.面向大规模微博消息流的突发话题检测[J].计算机研究与发展,2015,52(2):512-521.
[10]Zhang X,Chen X,Chen Y,et al.Event Detection and Popularity Prediction in Microblogging[J].Neurocomputing,2015,149:1469-1480.
[11]Powers,David M W.Evaluation:From Precision,Recall and F-Measure to ROC,Informedness,Markedness&Correlation(PDF).Journal of Machine Learning Technologies,2(1):37–63.
[12]Zhu M,Hu W,Wu O.Topic Detection and Tracking for Threaded Discussion Communities[C].Web Intelligence and Intelligent Agent Technology,2008.WI-IAT'08.IEEE/WIC/ACM International Conference on.IEEE,2008,1:77-83.
[13]http://www.iweibox.com/
[14]Agresti A,Kateri M.Categorical Data Analysis[M].International Encyclopedia of Statistical Science.Springer Berlin Heidelberg,2011:206-208.
猜你喜欢
社会科学战线(2022年3期)2022-06-15
红蜻蜓·中年级(2021年12期)2021-12-19
北京大学学报(自然科学版)(2019年6期)2019-11-27
领导决策信息(2017年13期)2017-06-21
领导决策信息(2017年9期)2017-05-04
山东工业技术(2017年1期)2017-01-24
消费电子(2016年12期)2017-01-19
科技视界(2016年21期)2016-10-17
中学生数理化·高二版(2008年4期)2008-11-12
