
基于支持向量机的微博水军账号识别
2018-05-07 03:27王淑琪王未央
现代计算机 2018年9期
王淑琪,王未央
(上海海事大学信息工程学院,上海 201306)
0 引言
网络技术深入千家万户,互联网社交平台随之蓬勃发展。不管是国外的Twitter、Facebook,还是国内的微博、QQ,这些社交应用已成为每个互联网用户的必备软件。在闲暇时,人们登录社交软件,或与亲朋好友联系感情,或观察网络中发生的各种事件。人们享受于社交平台便捷性和及时性。然而,网络水军的发展却使得社交平台信息的真实性发生转变。网络水军是一群网络中针对特定内容发布特定信息的、被雇佣的网络枪手。他们混迹于贴吧、论坛、微博等各个社交平台,当受到有心人士雇佣,他们便会伪装成普通用户对目标内容进行回复、评论和传播,以此对正常用户产生影响。
社交网络平台上广大的用户群体所隐藏的巨大商机,催生了网络水军这一灰色产业的发展。他们利用微博舆论,发布广告,传播虚假信息,劫持热门话题,更有甚者带动敏感话题,刺激激动的网络用户造成恶劣的社会影响。时至今日,由网络水军策划、炒热的微博事件屡见不鲜。为遏制网络水军的发展,及时制止网络水军造成的恶劣影响,识别出隐藏在数以万计的普通用户中的网络水军已成当务之急。
本文主要对微博网络水军账号的识别做出研究。网络水军作为大量水军账号构成的群体,其基础就是账号本身,故此本文提取出所有微博账号信息,划分出粉丝数、关注数、粉丝关注比,平均微博数、信息完整度、勋章数、阳光信用度等七大特征属性,利用支持向量机进行模型建立,从而将模型用于微博网络水军识别。
1 相关研究
识别网络水军的方法主要有基于内容特征、用户特征、环境特征和综合特征四个方向的研究。在网络水军发展早期,网络水军主要利用邮件进行运作,其产生的邮件内容易于识别、容易处理,主要采用文本分类[2]、文本情感分析[3]以及文本倾向性[4]等方法。随着网络技术的发展,用户意识开始提高,传统的网络水军不再能给网络用户造成影响,新型网络水军开始滋生,他们的行为趋向于正常用户,发布内容不再有显著特征,这使得传统的依靠内容特征识别方法不再有效,相关学者基于此事实开始对网络水军的用户特征进行分析。Ghosh等人[5]通过在Twitter中识别一组垃圾邮件账户并监控其链接创建策略来分析当前垃圾邮件发送者在线社交网络中采用的策略。除了对网络水军的用户特征分析外,相关学者另辟蹊径,从网络自身环境特征来分析网络水军特点。Las-Casas等人[6]提出了一种在源网络中检测垃圾邮件发送者的新方法,使用从巴西宽带ISP收集的实际数据集采用监督分类计数来进行水军识别。基于综合特征的网络水军识别的方法是为了弥补特定类型网络水军识别方法无法全面分析而诞生的。
目前,国内对微博平台网络水军的识别方法研究有限。张良等人[7]利用累计分布函数提取用户特征属性,利用逻辑回归算法建立识别水军模型。袁旭萍等人[8]使用熵值法确定指标权重,采用综合指数和熵值法确立微博水军自动识别模型。程晓涛等人[9]利用水军用户无法改变与网络中正常用户的链接关系,采用了基于用户关系图特征的微博水军账号识别方法。诸如以上研究均是从对用户账号信息的特征属性提取入手,但其算法对用户账号信息提取不全面,在网络水军行为逐渐趋于正常用户的条件下,仍然不能全面识别微博水军。
2 特征属性定义
通过对以往微博网络水军识别方法的对比研究发现,这些研究一般从用户信息和用户行为信息两方面提取特征属性,用户信息方面简单提取基本信息,用户行为信息一般提取微博内容的URL率和文本自相似度。在特征提取这方面,以往研究用户信息提取不全,用户行为信息提取单一,而随着网络水军运转方式转变,不再单纯的以发布广告和恶意链接的方式运营,其账号背后有水军操作而变得越来越隐藏化、用户化,提取URL率和文本自相似度这两条属性已不再适合。故此,本文将提取出用户账号所具有的全部累计信息,经过相关整理筛选得出有效的网络水军特征属性。
粉丝数:该用户账号被其他用户账号关注总数。由于水军账号一般为完成雇主任务而产生,此账号上一般和其他用户不具有交互性,排除被正常用户意外关注,水军账号的粉丝数一般比正常用户粉丝数少。
关注数:该用户关注其他用户账号总数。网络水军的灰色产业链下存在粉丝数买卖的情况,即有正常用户为满足其高关注度的要求,购买僵尸粉对自身关注,从而提高用户的粉丝数。另外,由于水军接受各个雇主任务,需要关注各类热点话题,其本身就要对大量账号进行关注。综上两种情况,水军账号的关注数要远远高于正常用户的关注数。
粉丝关注比:每个用户的粉丝数同其关注数的比值。为了排除个别正常用户因为特别需要而产生的低粉丝数或高关注数的情况,采用用户粉丝数与关注数的比值可以更好地区分水军和正常用户,即粉丝关注比越高,该用户越可能是认证用户,粉丝关注比越低,则可能是水军账号。其公式如下:
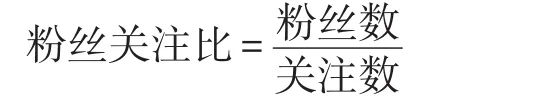
微博数:用户账号已经发布的微博总数。水军账号在进行制造和传播舆论时,会大量的发布和转发相关微博,而正常用户一般只会因为某些事件而发布微博作为倾述或吐槽需要,不会大量发布微博,故而水军用户的微博数量比正常用户要多得多。
平均微博数:自创建微博账号起,该用户账号平均每天发布的微博数。
资料完善度:此为综合评价指标,其中包括性别、生日、所在地、QQ、大学、工作经历六个基本资料,每个小指标填写则为1,不填写则为0。资料完善度为各小指标的加和总值。
是否有简介:由用户手动编写,方便其他用户了解该账号用户,具有极强的个性化。简介填写则该指标为1,没有则为0。
标签数:标签是用户为让更多志趣相同之人找到自己的个性化描述词语,如校园生活、读书分享等。标签数多少则反应该用户兴趣广泛程度和其活跃度。
微博等级:微博等级是用户活跃和荣誉的见证。随着用户在微博上的探索和成长,等级会随之增加。
勋章个数:勋章是用户参与微博上各类活动所授予的图标。其个数能反应该用户的活跃程度。
会员信息:用户为获得微博特权服务而付费开通的标志,微博会员等级为1-7级。
阳光信用:微博阳光信用致力于成为自然人网络身份的一个固有价值属性。它结合了用户的发言历史、活跃度、违规记录、商业记录、实名以及社交关系等行为,是微博用户在网络上阳光讨论、积极表达、理性交流的衡量标尺。阳光信用划分为5个等级,等级越高信用极好,等级越低信用极低。
3 基于支持向量机的水军账号识别模型
网络水军识别实际上是一个二分类问题,以微博平台所有用户为一个大集合,所有用户的行为模式基本类似,因此对单个用户账号的判别只有两种情况,一种是网络水军,一种不是网络水军。设U为微博用户集合,Uy为网络水军集合,Un为非网络水军集合,则U={Uy,Un}。设 x为用户特征向量,则 x={x1,x2,…,xi,…,xn},其中xi表示上一节提到的各个用户特征属性。存在一个目标函数F,使得,即目标函数 F→{0,1}的映射。当F(x)=1时,表示该特征向量标志的用户信息属于水军集合,反之,F(x)=0,则表示属于正常用户集合。
支持向量机是由Corinna Cortes和Vapnik在1995年提出的一种前馈类型网络的传统机器学习分类算法,它以训练误差作为优化问题的约束条件,以置信范围值最小化作为优化目标,即SVM是一种结构风险最小化准则的学习方法。
SVM的工作原理便是将原始数据通过变换映射到高纬度特征空间,这样即使数据不是线性可分,也可以对数据点进行分类,然后使用变换后的新数据进行预测分类。
从线性可分模式分类角度来理解,SVM的主要思想是建立一个最优决策超平面,使得该平面两侧平面最近的两类样本之间的距离最大化,从而对分类问题提供良好的泛化能力。
定义1最优超平面有n个线性可分样本{(x1,y1),(x2,y2),…,(xn,yn)},对于任意输入样本 xi,期望输出 yi=±1(代表两类类别标志)。用于分类的超平面方程为wTx+b=0,其中,x为输入向量,w为权值,b为偏置,则有wTx+b>0,y=+1;wTx+b<0,y=-1。
超平面与最近的样本点之间的间隔成为分离边缘,支持向量机的目标是找到一个分离边缘最大的超平面,即最优超平面,也就是要确定分离边缘最大时w和b的值。这样,分离边缘最大化等价于使权值向量范数‖w‖最小化。通过对一个复杂的最优化问题的求解简化为对原有样本数据的内积运算。在d(wTx+b)≥1的约束下,可得最小化代价函数:

该约束优化问题的代价函数是w的凸函数,且关于w的约束条件是线性,因此可用langrange系数方程解决约束最优问题。
而对于复杂的模式分类问题非线性地投射到高位特征空间可能是线性可分的,因此只要特征空间的维数足够高,则原始模式空间能变换为一个新的高位特征空间,使得在特征空间中模式以较高的概率为线性可分的,这样就可以解决非线性可分数据的分类问题。
然而,如何将低位空间向量集映射到高位空间?这边涉及到SVM的关键,核函数的选择。核函数可以巧妙地解决计算复杂度的问题,只要选用适当的核函数,就可以得到高维空间的分类函数,采用不同的核函数得到不同的SVM算法。常见的核函数类型有以下几种:
(1)线性核函数:K(x,xi)=x·xi
(2)多项式核函数:K(x,xi)=((x·xi)+1)d
(4)Sigmoid 核函数:K(x,xi)=tanh(κ(x,xi)-δ)
其中,RBF核主要用于线性不可分的情形,适用于参数多,分类结果非常依赖于参数的实际问题。根据微博数据特征属性特点,本文选择RBF核解决数据分类问题。
4 实验结果及分析
4.1 数据处理与准备
为获取实验相关数据,需要对大量用户数据进行收集处理。新浪微博用户信息可以利用新浪微博开放的API进行,但是考虑到使用API调用的用户信息不够全面,且新浪微博API调用防非法操作措施,通过API调用获取数据并不能满足实验数据要求。本文选择采用爬取程序从新浪微博开放平台采集微博用户信息。由于支持向量机本身在解决小样本识别中表现出特有的精确优势,故而使用爬取程序获取用户信息1036条。经过对数据有效性筛选,获得934条正常用户信息数据。通过网络购买水军的方式,手动获取到200条水军用户信息数据。
对上述获得的数据信息进行预处理:
数据清理:填写少量缺失值、光滑噪声数据、删除离群点。
数据变化:对某些字段进行规范化,使其适用于SVM。本文采用IBM SPSS Modeler作为本实验的软件工具。SPSS自身集成SVM功能,且提供了可视化的操纵方便,界面友好,操作方便。
4.2 实验模型及结果
(1)创建基本流,建立模型
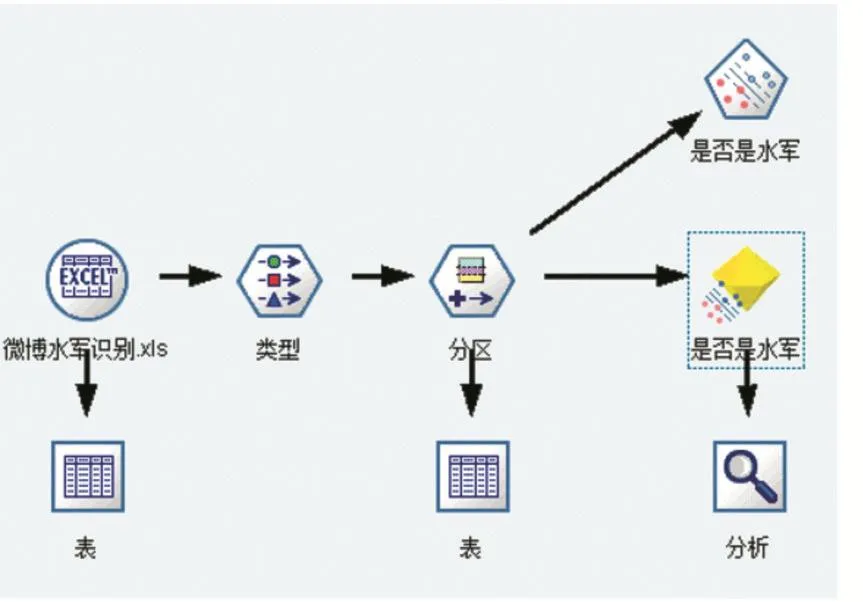
图1
(2)模型测试结果图
从图2实验结果我们可以看出,基于支持向量机的微博水军账号识别精确度达到94.22%,同文献[7]实验结果比较,本文实验结果精确度基本高于文[7]精确献度,说明相较于采用逻辑回归算法作水军检测,采用支持向量机模型具有更高的识别精确率,更加有效。
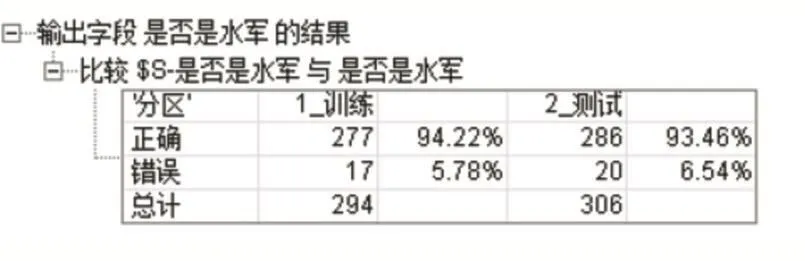
图2
5 结语
网络技术日新月异,越来越多的用户加入到互联网大军中,网络水军这一灰色产业产生了巨大的利益诱惑,要及时遏制网络水军造成的舆论误导、热点绑架等影响,就要从源头抓起,揪出隐匿在微博用户群体中的水军账号。本文采用了一种基于支持向量的水军账号检测模型,针对目前水军行为特征趋向正常用户的混同表现,收集代表用户的全部客观信息作为检测依据,实验结果表明本文的模型可以更精确的识别出网络水军。在今后的研究中,可以对支持向量机做出优化,使其能适应各种不同平台的水军检测。
参考文献:
[1]莫倩,杨珂.网络水军识别研究[J].软件学报,2014,25(7):1505-1526.http://www.jos.org.cn/1000-9825/4617.html
[2]Sriram B,Fuhry D,Demir E,Ferhatosmanoglu H,Demirbas M.Short Text Classification in Twitter to Improve Information Filtering.In:Crestani F,Marchand-Maillet S,Chen HH,eds.Proc.of the 33rd Int'l ACM SIGIR Conf.on Research and Development in Information Retrieval(SIGIR 2010).New York:ACM Press,2010:841-842.
[3]Zhao YY,Qin B,Liu T.Sentiment Analysis.Ruan Jian Xue Bao.Journal of Software,2010,21(8):1834-1848(in Chinese with English abstract).http://www.jos.org.cn/1000-9825/3832.html.
[4]Liu B.Sentiment Analysis And Subjectivity.In:Indurkhya N,Damerau FJ,eds.Handbook of Natural Language Processing.Boca Raton:CRC Press,2010:627-666.
[5]Ghosh S,Korlam G,Ganguly N.Spammers'Networks Within Online Social Networks:A Case-study on Twitter.In:Sadagopan S,Ramamritham K,Kumar A,Ravindra MP,Bertino E,Kumar R,eds.Proc.of the 20th Int’l Conf.on World Wide Web(WWW 2011).New York:ACM Press,2011:41-42.
[6]Las-Casas PHB,Guedes D,Almeida JM,Ziviani A,Marques-Neto HT.SpaDeS:Detecting Spammers at the Source Network.Computer Networks,2012,57(2):526-539.
[7]张良,朱湘,李爱平,等.一种基于逻辑回归算法的水军识别方法[J].信息安全与技术,2015(4):57-62.
[8]袁旭萍,王仁武,翟伯荫.基于综合指数和熵值法的微博水军自动识别[J].情报杂志,2014(7):176-179.
[9]程晓涛,刘彩霞,刘树新.基于关系图特征的微博水军发现方法[J].自动化学报,2015,41(9):1533-1541.
[10]张艳梅,黄莹莹,甘世杰,等.基于贝叶斯模型的微博网络水军识别算法研究[J].通信学报,2017,38(1):44-53.
[11]杨臻,张明慧,肖汉.基于多特征的网络水军识别方法[J].激光杂志,2016(12):110-113.
[12]谢忠红,张颖,张琳.基于逻辑回归算法的微博水军识别[J].微型机与应用,2017(16):67-69.
[13]韩忠明,许峰敏,段大高.面向微博的概率图水军识别模型[J].计算机研究与发展,2013,50(s2):180-186.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
杂文月刊(选刊版)(2022年1期)2022-02-12
电脑爱好者(2021年24期)2021-09-09
华声文萃(2021年6期)2021-08-25
派出所工作(2021年4期)2021-05-17
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
方圆(2017年12期)2017-07-17
高中生学习·高三版(2016年9期)2016-05-14
CHIP新电脑(2016年3期)2016-03-10
汉语世界(The World of Chinese)(2016年1期)2016-01-10
