
基于集成学习的电网用电量预测系统研究
2018-05-07 03:27张春梅魏俊锋
现代计算机 2018年9期
张春梅,魏俊锋
(广东电网有限责任公司中山供电局,中山 528400)
0 引言
随着经济的不断发展,我国居民及工业对电力的需求逐渐变大。对同一行业的不同用户,其用电行为的差异日益明显,仅以行业总体特征进行用电模式识别已无法客观挖掘足够的信息,用户用电特性的多样化对传统的用电预测方法提出了挑战,因此,将用户用电特性进行多维度分解,对隶属于不同用电模式的用户群体采用差异化建模方法,分别建立有较强针对性的预测模型,可以提高用电量预测精度。本文使用CART决策回归树、AdaBoost算法进行规则挖掘,并针对不同用户用电特点,融合随机森林(Random forest)、XGBoost等多个算法匹配用户最优算法进行用电量预测。
1 数据预处理
首先进行特征工程,特征工程包括特征选择和特征提取[1],对于特征过多的一些数据要做降维处理。现有数据中现成的只有时间这一维特征,所以需进行特征构造。在原始数据中,以15个月为一个划分区间,在区间内采取前三个月的值、总和、方差、平均值以及后三个月的值、总和、方差、平均值作为特征向量,形成的其中一组特征向量的值如表1所示,并把月份采用了独热码[2](one-hot)的编码,在一定程度上起到了扩充特征的作用。
2 CART算法原理
CART决策树[3]是一种有监督的学习算法,以树状图为基础,对特征空间进行二元划分。采用自上而下的方法,在每一步选择一个最好的属性来分裂。“最好”的定义是使得子节点中的训练集尽量的纯,对于分类问题可使用Gini系数进行特征选择,对于回归问题用平方误差最小化准则进行特征选择,生成二叉树,即最小二乘偏差(LSD)生成决策树。
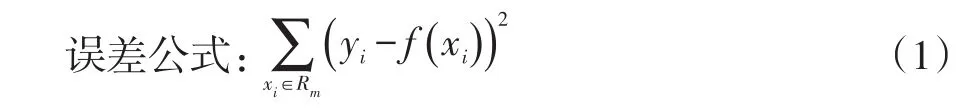
该算法流程如下:
输入训练集D={(x1,y1),(x2,y2)......(xm,ym)}
(1)CART树生成,采用启发式方法,选择第j个变量x和它的取值s作为切分变量和切分点,定义两个区域:

表1 特征向量值表
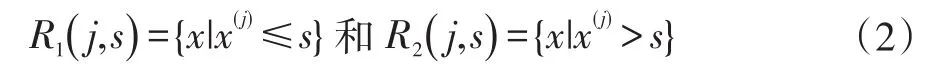
遍历所有变量,找到最优切分变量j和最优切分点s,即寻找最优特征划分点,接着对两个区域递归操作,算法停止条件是结点中样本个数少于给定的阈值(切分最小样本数)、不纯度指标下降的最大幅度小于用户指定的幅度(误差允许下降值)或这切分后某个子集大小小于给定的阈值。
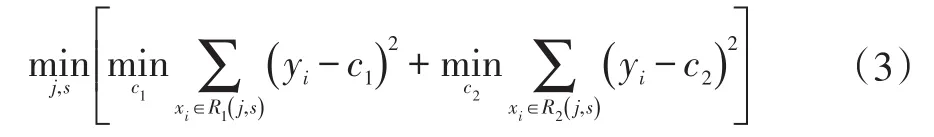
(2)CART树剪枝防止过拟合,第一步中有提前终止条件作为预剪枝,但是对参数较为敏感,所以再进行后剪枝,常用方法有Reduced-Error Pruning(REP,错误率降低剪枝)、Cost-Complexity Pruning(CCP、代价复杂度)。
历史课堂教学中对学生学习兴趣的激发要注重坚持深入挖掘教材,为学生学习历史知识营造轻松的氛围,逐渐的引导学生对历史知识的学习有新的认识。教师要从历史教材着手,深入的挖掘,找到吸引学生的知识点内容进行发挥,这是激发学生的要点。激发学生兴趣要注重师生良好关系的建立,让学生对教师产生信任感,这样才能拉近师生距离,这对激发学生兴趣就打下了基础。
REP方法:
(a)如果存在任一子集是树,则在该子集递归剪枝;
(b)计算当前两个叶子节点合并后的误差、不合并的误差;
(c)如果合并后误差降低,则合并。
3 Adaboost算法原理
AdaBoost[4]基于boosting流派,属于集成学习方法。对预测来说,获得粗糙的预测估计比精确的预测估计相对容易许多,提升方法(boost)从弱学习算法出发,反复学习,得到一系列弱分类器,组合弱分类器,提升成为一个强分类器。该算法流程如下:
输入:T={(x1,y1),(x2,y2)......(xm,ym)}
输出提升树 fM(x)
(1)初始化 f0(x)=0
(a)根据rmi=ymi-fm-1(xi)计算残差
(b)拟合残差rmi学习一个回归树,得到T(x;Θm)
(c)更新 fm(x)=fm-1(x)+T(x;Θm)
4 算法应用
本文的数据取自19个用电客户68个月的月用电量数据,前60个月的数据作为样本数据,后8个月的数据作为测试数据,使用预测的8个月数据与测试数据计算误差,根据样本数据采用交叉验证训练模型,交叉验证的基本思想是把在某种意义下将原始数据(da⁃taset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。如下图1为CART算法训练出的决策树模型,测量中使用可决系数作为综合度量回归模型对样本观测值拟合优度的度量指标,R2约接近1代表拟合优度越好,表2为其中用户C的可决系数值。

表2 用户可决系数表
5 等权平均融合算法预测
不同用电行为的差异化日益明显,因此,将用户用电特性进行多维度分解,对隶属于不同用电模式的用户群体采用差异化建模方法,选取合适的数学模型进行数据建模,EW[5]是一类经常使用的组合预测方法,设yi(i=1,2,…,k)为第i个模型的预测值,如果ye代表组和模型的预测值,则EW方法得到的组合预测为,EW法不需要了解单一预测值yi的预测精度,是在对各种预测方法精度未知的情况下采取的一种方法。算法流程如下:
(1)对于每个用户,遍历算法并统计MSE,保存MSE最小的模型,并计算算法根据测试集所得出的预测结果与实际值的相关系数,即R2值。相关系数是一种比较客观的评价模型方法,本系统采用的是皮尔逊相关系数[6](Pearson Product-moment Correlation Coeffi⁃cient)进行数学统计,如下面公式(4)。

(2)对每个算法进行调优,并保存调优后的算法模型,以便下次进行预测时缩短预测所需等待的时间。
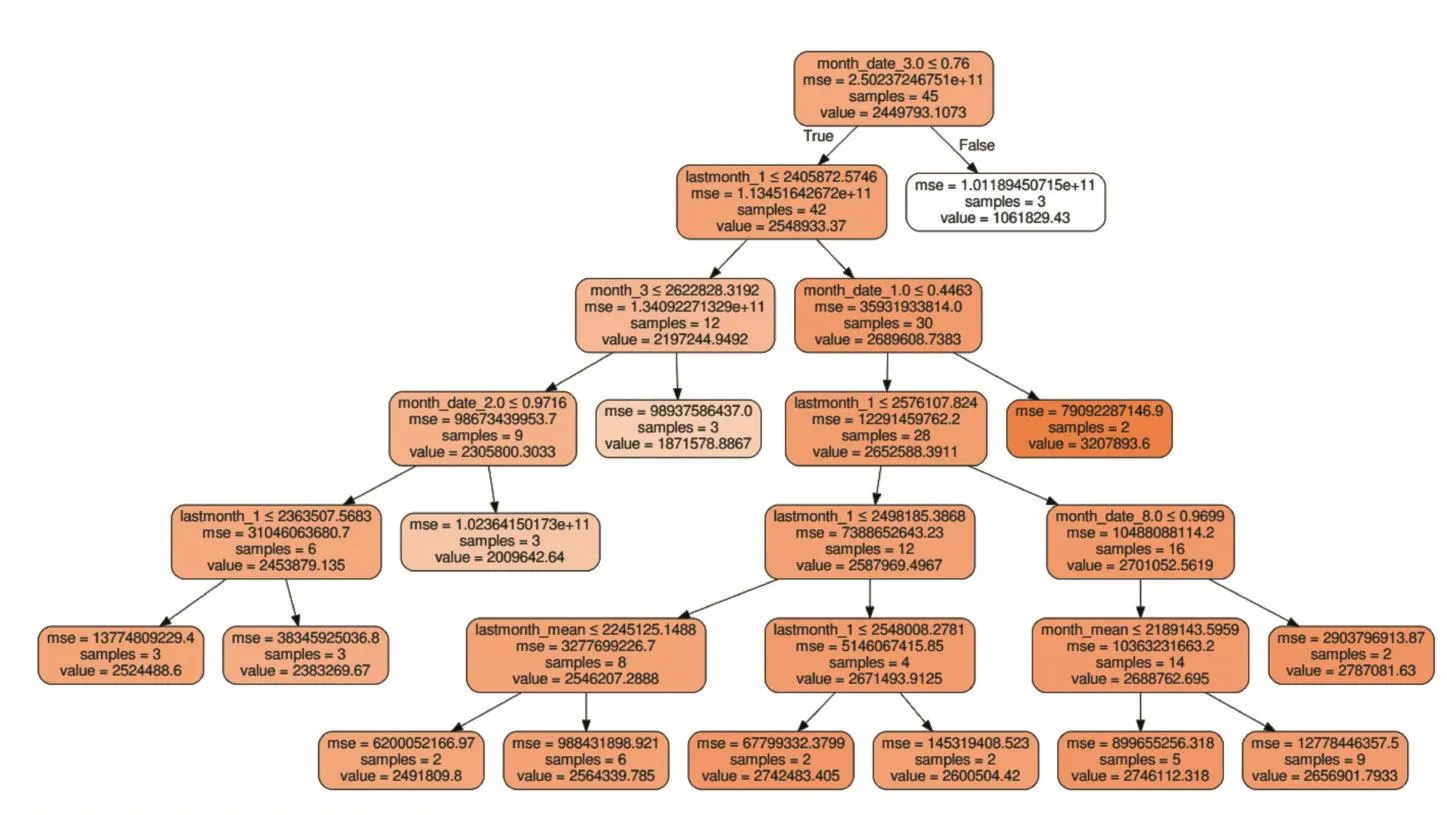
图1 CART决策树
(3)综合多个算法进行预测,即遍历所有用户,取出系统保存的用户所对应的最佳算法模型进行实际预测。表3是单一算法与多算法融合后的误差统计。
6 结语
本文采用集成学习方法对数据样本进行了规则挖掘,针对单个预测模型存在的不足,提出了权重组合预测模型,融合了多个算法进行用电量预测,对用户68个月的月用电量数据进行特征处理和分类建模,基于CATR、Adaboost等多个算法以及融合算法对用电量进行预测,为每个用户自动选择最佳模型。通过模型调优,提高了用电量预测准确率。

表3 算法误差统计(部分用户)
参考文献:
[1]陈霞,安伯义,陈广林.电力负荷预测理论与方法.电气化,2004(7):6-8
[2]唐小我.预测理论及其应用.成都:电子科技大学出版社,1992,2-27
[3]张松林.CART-分类与回归树方法介绍[J].火山地质与矿产,1997,18(1):67-75
[4]李航.统计学习方法[M].北京:清华大学出版社,,2012:138-154
[5]牛东晓,曹树华,赵磊.电力负荷预测技术及其应用.北京:中国电力出版社,1998,1-45
[6]齐志刚,王金文.电力系统中长期符合预测的新方法.电站系统工程,2002,18(6):39-42
猜你喜欢
电力设备管理(2022年8期)2022-11-25
保健医苑(2022年5期)2022-06-10
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
成都信息工程大学学报(2021年6期)2021-02-12
电力勘测设计(2020年4期)2020-12-14
计算机应用(2020年5期)2020-06-07
计算机测量与控制(2019年4期)2019-05-08
天津诗人(2017年2期)2017-03-16
科技视界(2015年24期)2015-08-22
