
一种HDFS元数据分级存储策略
2018-04-24 07:58马东邵维专
现代计算机 2018年8期
马东,邵维专
(四川大学计算机学院,成都 610065)
0 引言
随着大数据时代的到来,传统的文件系统已经无法应对新时代下的大数据存储的挑战,分布式文件系统以其高可靠性、高性能以及强大的可扩展性逐渐得到广泛的使用。在主流的分布式文件系统中,大都采用元数据和文件数据分离的策略,将元数据信息存放在单独的服务器上,元数据服务器作为整个分布式文件系统的管理节点,为应用提供文件系统目录视图和数据定位服务。
作为大数据平台Hadoop的存储核心,HDFS以其良好的设计和性能逐渐成为大数据处理方向的一个标准,Hadoop2.0引入主备模式,使用StandBy NameNode作为Active NameNode的热备节点,由于整个文件系统的元数据全部存放在NameNode的内存中,当使用主备模式对NameNode进行同步备份时备份服务器需要与主NameNode同等配置,但是备份服务器并不对外提供读写服务,只是将同步应用Active NameNode的日志信息,文献表明,在一个常规的HDFS分布式文件系统中,元数据写操作仅占据所有元数据操作的5%左右,因此本文提出了一个StandBy NameNode元数据分级存储策略,将写操作较少的目录的元数据信息序列
HDFS由元数据管理节点NameNode和数据节点DataNode组成,NameNode负责管理整个分布式文件系统的元数据信息,包括目录树以及各个数据块对应的存储信息,所有的存储数据分散到DataNode上,当需要访问文件时,应用首先需要访问NameNode获得文件的存储信息,再访问DataNode获取文件数据。
我们把NameNode管理的文件系统目录树称之为第一关系链,将NameNode中数据块与对应的DataNode的关系称之为第二关系链,HDFS使用FsIm⁃age以及EditLog文件中保存第一关系链的数据信息,第二关系链的建立依赖于NameNode启动时由各个DataNode节点汇报得到。在一个小型的HDFS文件系统中,有10M文件,0.3M目录以及13M数据块,元数据占用了约9G内存。化到磁盘,这样在保持主备完全同步的情况下可以极大降低StandBy NameNode内存的使用率。
1 背景与问题分析
1.1 HDFS 元数据管理策略
1.2 元数据访问特性
现有的分布式文件系统往往采用元数据和数据的分离存储,元数据访问与典型的数据访问不同,元数据往往较小,因此通常使用将元数据存放在内存中。大量研究表明,当数据刚被存放到存储系统中时,对数据的修改和访问会十分频繁,但是随着时间的推移,这些数据的访问频率会越来越低,甚至不再被访问,这些数据往往占总数据量的80%以上。文献[1]指出文件系统的变化具有显著的空间局部性,在其对两个企业级网络文件服务器三个月的日志分析显示,超过92%的元数据变化簇集在低于10%的目录中;文献[2]统计了Spotify的HDFS集群的元数据操作,指出在Hadoop典型应用产生的负载中,写操作约占所有元数据操作的5%;基于此,本文提出了一种StandBy NameNode上元数据分级存储算法。
2 基于修改频率的目录分级存储算法
NameNode作为HDFS的核心,使用主备模式保证HDFS的高可用,并在主备机上应用相同的日志序列保证Active NameNode和StandBy NameNode的一致性,Active NameNode处理集群的读写请求,StandBy Na⁃meNode同步应用写操作的日志,考虑到大数据应用的特点和元数据变化的局部性,仅在StandBy NameNode内存中存放修改热度较高的目录,将热度较低的目录序列化后存储在本地。
2.1 冷热目录划分
本文在HDFS的INodeDirectory结构中添加了int editIndicator作为目录修改热度值,考虑到文件系统目录的修改特征,建立了一个层级的衰减模型。本文定义editIndicator的第0~1bit存储热度衰减标识,使用第2~31位记录当前目录的热度值,将第2位作为该目录的w位,同样,衰减标识为01,10,11的w位分别为ed⁃itIndicator的第 23,15,7位,当目录被修改时,会将路径上目录对应的w位置1。

图1 热度字段存储结构
(1)衰减标识
目录的热度衰减分为四个级别,当目录被创建时,级别设置为0,即衰减标识置为00,并设置当前级别的W位为1,当目录被压缩线程访问时,会根据当前的衰减标识适用对应的衰减算法并降低当前的目录热度,热度低于阈值后序列化和存储该目录。在需要加载目录树时,提升INodeLinked节点到被修改目录路径上目录的热度衰减级别。
(2)热度衰减算法
老化算法:当压缩线程访问该目录时,将该目录的热度衰减一半。
递减算法:当压缩线程访问该目录时,将该目录的热度降低1。
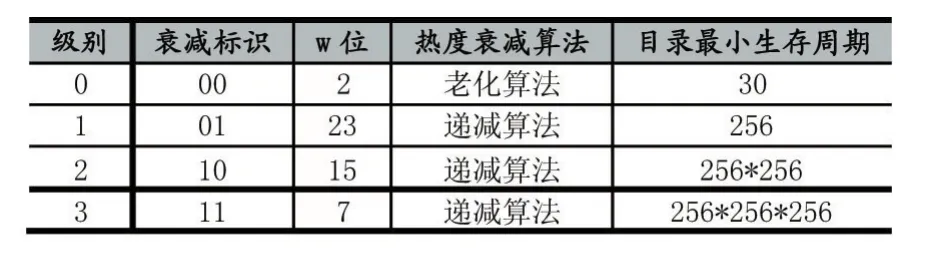
表1 热度衰减策略分类表
2.2 目录压缩
(1)节点替换
当存在子树的热度过低时,使用INodeLinked节点替换该子树根节点,然后将子树序列化,INodeLinked保存了该子树的序列化信息,其结构定义如下:

其中filePath为保存该子树信息的文件存储路径。
(2)子树序列化
考虑到NameNode元数据的组织形式,本文将目录和该目录下文件和子目录的关系抽离单独保存,使用DirEntry序列化目录与该目录下文件和子目录的映射关系,其结构如下:


HDFS NameNode使用INodeMap保存所有目录和文件的元数据。HDFS中文件(INodeFile)和目录(IN⁃odeDirectory)都是INode的子类,因此定义了INode⁃Common用以序列化文件和目录信息。INodeCommon
数据结构如下:

2.3 数据存储策略
本文使用INodeLinked保存子树的序列化信息,然后将子树元数据信息存储到文件中,文件的结构如表2所示。

表2 文件存储结构
其中,treeId为子树Id,INodeMapSection存放所有的INode信息,DirEntrySection存放所有的DirEntry信息,在序列化子树或目录时采用预分配空间的方法,每个文件预分配256KB大小,其中16KB作为DirEntry⁃Section,,其余空间作为INodeMapSection,为防止过多的文件创建,使FILE_MIN_INODE_COUNT限制每个文件最少需要保存的INode个数。当需要从文件加载子树时,首先加载INodeMapSection,将其INode放入InodeMap中,然后加载DirEntrySection重建目录子树。
2.4 目录遍历算法
每隔时间T或者内存使用量达到一定阈值时启动压缩线程遍历目录树,将热度较低的目录序列化存储到本地,算法流程如图2所示。
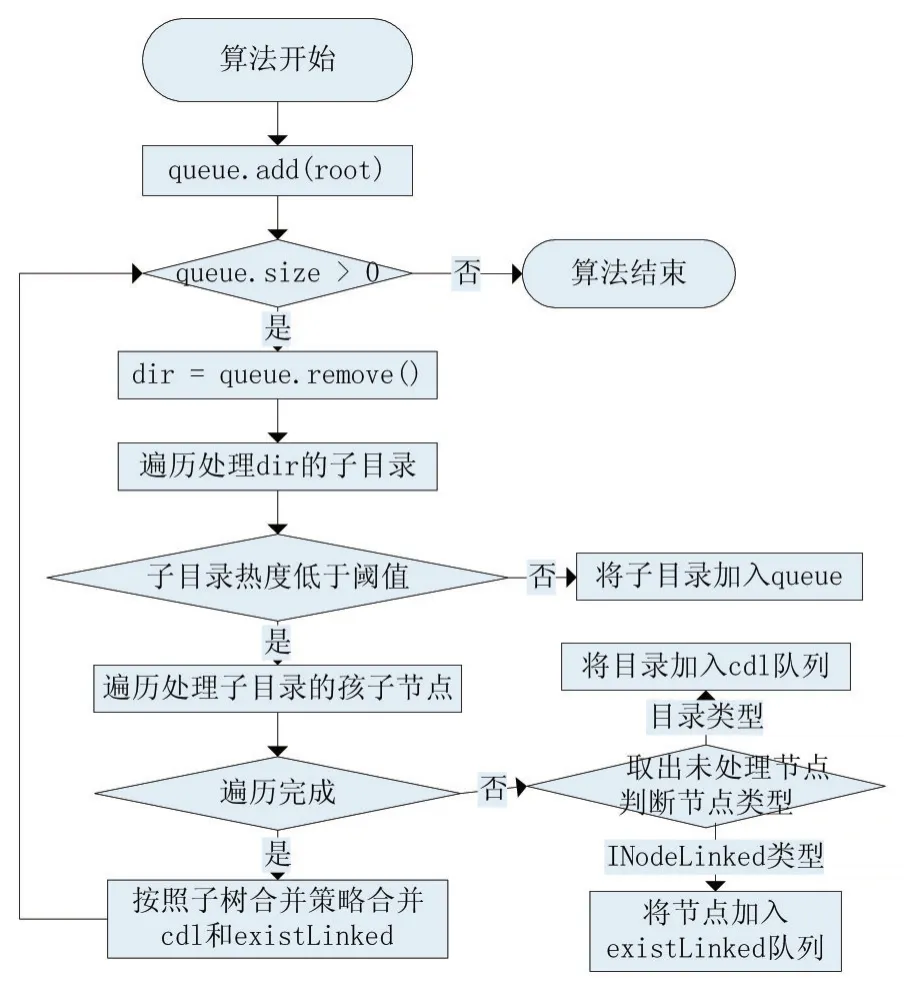
图2 目录遍历算法
2.5 子树的合并策略
定义1兄弟节点:目录或子树根节点所在的父目录包含的其他子目录称为该目录的兄弟节点。
定义2可序列化:当一个子树或目录的热度低于某一设定的阈值,则称该子树或目录是可序列化的。
定义3可合并的:如果一个INodeLinked节点的剩余空间可以存放可序列化的兄弟节点或父节点的信息,则称该INodeLinked节点是可合并的。
定义4最小序列化条件:当需要序列化的目录或子树的INode数量大于FILE_MIN_INODE_COUNT,则称该子树或目录满足最小序列化条件。
定义5孤立节点:若一个子树或目录满足最小序列化条件,且父目录是非可序列化的以及不存在可序列化的兄弟节点或者可合并的INodeLinked兄弟节点,则称之为孤立节点。
定义6不可约减节点:如果某一个可序列化目录或子树包含的所有INodeLinked节点均满足1)存在兄弟节点,该节点与兄弟节点是不可合并的,2)不存在兄弟节点,该节点与父目录时不可合并的,则称该目录或子树时不可约减节点。
若当前目录或子树是孤立节点,根据其INode个数分配存储空间,空间分配策略如下:
(1)若当前子树INode个数count小于1024,则分配256KB空间,DirEntrySection占用16KB
(2)若当前子树INode个数count大于1024,则分配((count-1)/1024+1)*256K空间,DirEntrySection占用((count-1)/1024+1)*16K
子树合并策略如下:
(1)对cdl队列中的目录进行约减:若该目录子树存在INodeLinked节点,则INodeLinked节点合并其兄弟节点以及父节点,直至该目录子树成为不可约减节点或INodeLinked节点,若该节点约减后成为IN⁃odeLinked节点,则将其加入existLinked队列。
(2)将existLinked中节点与cdl队列中的约减后的目录进行合并,直至cdl中没有可以并入existLinked的目录。
(3)将cdl剩余的目录子树合并作为孤立节点,按照空间分配策略分配存储空间。
3 结果与分析
本文使用三台虚拟机搭建了测试集群,其中两台作为Active NameNode和StandBy NameNode,配置为1核CPU,2G内存,20G硬盘,三台虚拟机均配置为Jour⁃nalNode和DataNode,NameNode中JVM内存配置为-Xms256M-Xmx1024M,使用测试程序随机创建了约400万空文件,并随机标记约20%的目录为热点目录,本文设定 FILE_MIN_INODE_COUNT为 20,同时在
参考文献:StandBy NameNode启动压缩线程。
由图3可以看出,在启动压缩线程之后,StandBy NameNode的堆内存使用明显降低。
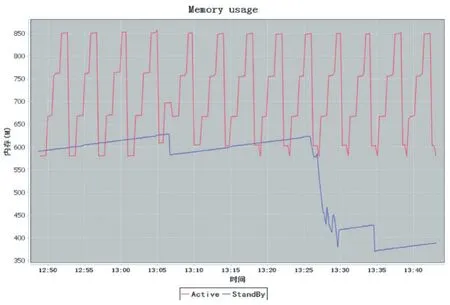
图3 主备NameNode堆内存使用
4 结语
本文针对StandBy NameNode内存占用高但是活跃元数据比例很低的问题,研究了HDFS元数据管理策略,提出了一种分级热度衰减策略,实现了StandBy NameNode元数据的分级存储算法,将StandBy Na⁃meNode的非活跃元数据压缩存储到本地,大大降低了其内存使用,同时使用初步的实验验证了算法的有效性。
[1]刘立坤.海量文件系统元数据查询方法与技术[D].清华大学,2011.
[2]Niazi S,Ismail M,Grohsschmiedt S,et al.HopsFS:Scaling Hierarchical File System Metadata Using NewSQL Databases[J],2017.
[3]孙耀,刘杰,叶丹,等.分布式文件系统元数据服务的负载均衡框架[J].软件学报,2016,27(12):3192-3207.
[4]李静.基于访问热度分类的元数据副本技术研究[D].华中科技大学,2016.
[5]陈涛,肖侬,刘芳.对象存储系统中自适应的元数据负载均衡机制[J].软件学报,2013(2):331-342.
[6]Haohui Mai,Scaling Out the Namespace Using KV Store.https://issues.apache.org/jira/browse/HDFS-8286.
[7]曾卫进.基于HDFS的分级存储功能设计与实现[D].华中科技大学,2016.
猜你喜欢
计算机应用与软件(2021年10期)2021-10-15
甘肃教育(2020年14期)2020-09-11
电子技术与软件工程(2020年4期)2020-06-10
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
火力与指挥控制(2020年1期)2020-03-27
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
启迪与智慧·教育版(2016年12期)2017-01-12
中学教学参考·语英版(2016年6期)2016-07-07
