
语义约束和时间关联LDA的社交媒体主题词链提取
2018-04-13 10:03万红新
小型微型计算机系统 2018年4期
万红新,彭 云
1(江西科技师范大学 数学与计算机科学学院,南昌 330038) 2(江西师范大学 计算机信息工程学院,南昌 330022) E-mail :wanhongxin@126.com
1 引 言
随着互联网的发展和普及,网民规模及社交媒体呈现爆发式增长趋势.截至2017年6月,中国网民规模达7.51亿,半年共计新增网民1992万人,互联网普及率为54.3%,各类论坛/bbs和微博社交媒体的用户规模数达到4.23亿[1].由于互联网信息传播具有迅速、便捷的特点,人们愿意在网络上通过多种途径发表自己的观点和看法.一些事件在社交媒体传播过程中会引起公众的极大关注和热烈讨论,在网络上快速形成评论文本大数据,其中蕴含着大量的主题信息.如何从不断涌现的海量非结构文本数据中,尤其是具有复杂语法和语义表达的中文文本,有效地发现热点主题以及捕捉热点主题演变趋势,是社交媒体主题发现和提取所面临的挑战.本文提出的模型可以进行动态主题词链的提取,即不仅仅发现评论对象(评论主体),同时可以提取与之匹配的评论词(情感词),而且可以获取其随时间的变化情况.将以国内知名微博、论坛等的实际社交媒体文本为数据源,在对中文评论文本的语法结构、语义特征进行分析的基础上,提出语义约束和时间关联的SCTA-LDA(semantic constrained and time associated LDA)模型,在改善LDA的语义理解能力的同时提高LDA的时间敏感度,以有效提取动态的主题词链.
2 相关研究
一些研究利用机器学习的方法进行文本主题词语的发现和提取.文献[2]定义了社交媒体文本之间语义和内容等复合关联关系,从这种关系中发现网络文本的主题热点;文献[3]针对微博信息噪音大、新颖度难以判断的问题,在动量模型的基础上进行优化,提出了基于时序分析的微博突发话题检测方法;文献[4]基于网页聚类生成的主题关键词进行组合生成子话题,并以吸收马尔可夫链对子话题进行吸收衍化,进行重排序提取热点子话题;文献[5]提出主题词频数进行加权的共现分析方法,利用词语对的最大信息系数来度量主题词聚类的相似性,并识别网络社交媒体文本中的热点主题;文献[6]构建基于老词生命值计算的热词间相关性词语共现网络,并引入多标签传播方法解决话题间重叠热词以及时效性等问题,设计聚类算法获取热点主题集;文献[7]提出了一种网络社交媒体预测模型,通过主题分割、热点提取和数据聚合获取原始数据,然后利用相空间重构社交媒体的时间序列,最后将时间序列输入支持向量机进行建模和预测;文献[8]指出热点发现在于提取社交媒体文本的特征,提出了结合粗糙集和最大熵的模型系统来发现社交媒体热点主题.
随着社交媒体文本的大数据化趋势,常规的机器学习方法很难处理海量的文本数据,特别是有监督的机器学习方法,需要对大量的数据进行人工标注.一些研究利用LDA(latent Dirichlet allocation)[9]主题模型的无监督特点,在实现有效文本降维和主题词提取的基础上进行社交媒体主题发现.LDA主题模型是一种文本概率生成模型,其主要思想为:文档是主题的随机混合,而主题是词语的概率组合,利用文档-主题和主题-词语的分配过程来生成文档.LDA将表达文本的词向量转化为主题向量,大大地降低了文本维度,同时在文档的生成过程中可以提取主题词.文献[10]提出DTM(dynamic topic model)主题模型,将离散化的时间片信息加入到LDA,生成按时间片序列分布的文本语料片,从而获取随时间演化的文本主题;文献[11]提出一种基于可扩展 LDA模型的微博主题特征抽取方法,利用词语权重调整方法筛选高贡献度高频词语,基于bootstrap思想,迭代产生特征词条候选集,引入信息熵值理论筛选主题词条,并利用四维泛化分类实现对特征词条的泛化和归类;文献[12]基于话题热度和内容两方面变化建立动态主题模型,挖掘随时间变化的动态主题链,并提出主题热度计算方法;文献[13]基于LDA提取微博中的隐含主题,利用主题间的共用词汇关联将主题构成一个无向加权图,并通过PageRank算法将主题排序以获取热度主题;文献[14]针对社交网络中海量短文本信息具有高维性以及主题分布不均,提出一种基于LDA主题模型的CBOW-LDA(continuous bag-of-word LDA)主题建模方法,通过引入基于CBOW模型的词向量化方法对目标语料进行相似词的聚类,能够有效降低LDA模型输入文本的维度,并且使主题更明确;文献[15]提出基于LDA主题模型的社交媒体观点挖掘方法,分析了LDA在海量评论文本中提取社交媒体观点的优势及路径;文献[16]针对传统LDA主题模型忽视节点重要性的问题,提出一种新的社会网络主题发现算法iMLDA (importance-latent Dirichlet allocation).算法将LDA主题模型与基于Pagerank的节点重要性算法相融合,充分挖掘社会网络中蕴含的结构信息,提高主题发现的准确率;文献[17]针对目前提取主题词和评论词时,往往没有考虑它们之间关联关系,提出了主题-评论TS(topic-sentiment)主题模型,并基于Gibbs抽样过程进行模型参数推导.TS模型中同样主题的不同描述对应了不同的评论情感倾向,强调评论情感极性的分布和特定主题的关联性.模型考虑了评论对象与评论词的关联性,通过在LDA中加入情感层来实现,但没有分析低频局部评论对象和评论词的关联性;文献[18]采用LDA主题模型进行文本建模,得到所有用户内容在各个不同主题上的分布,并基于兴趣话题集合构造了一组话题相似性特征用于链路预测;文献[19]提出了一种基于加权LDA的热门主题获取方法.从提取表征话题的主题词角度,改进LDA词语分配权重,并将类别区分词方法应用于词序优化,在主题-词语的分配过程中引入文档贡献度和话题权值概率;文献[20]提出了一种词聚类LDA的商品评论对象的提取模型,利用词义相似度和上下文相关性计算词语间聚类距离,并以词语聚类簇作为先验知识影响LDA进行主题-词语分配,从而提取更符合语义要求的主题评论对象.
从上述研究现状可以看出,相对于机器学习方法,主题模型是一种无监督学习模型,不需要进行数据的人工标注,并且对文本具有降维作用,所以较适于处理大规模的文本数据.同时主题模型提取的主题词可以反映所关注的焦点内容,在分配过程中可以实现词语的聚类,即主题模型不仅能发现主题热点词,而且能发现它们之间的潜在关联性,从而实现主题词链的提取.在社交媒体文本大数据化的背景下,利用改进的主题模型进行关键词挖掘也日渐成为主题发现的研究趋势之一.由于社交媒体文本存在复杂的语义关系,同时讨论主题具有动态变化性,本文将语义获取和动态主题提取进行有机结合,提出融合语义约束和时间关联的社交媒体动态主题词链提取模型,从而有效获取社交媒体评论主题信息及其变化趋势.
3 语义关系获取
利用同义词语义关系获取同义评论对象关联关系,并利用关联关系来影响LDA的主题-词语分配,有利于提取更多的低频评论对象.以句子为单位基于依存句法分析和词性分析来发现评论对象和评论对象、评论对象和评论词之间的关联关系,并通过改进的PMI、词频关联等算法计算关联强度,最后利用这些关联关系和关联强度来影响LDA模型中词语的主题分配,以便发现更多的低频评论对象、低频评论词及其关联关系.
3.1 同义评论对象关系提取
关注评论对象的同义性,同义评论对象可以互相取代,应尽量分配到同一主题,如“罪犯”“不法之徒”“违法者”“犯罪分子”“罪人”“以身试法者”等,这类评论对象具有较强的同义语义关系,一些低频的评论对象可以通过同义性关联到高频评论对象,从而有利于LDA的识别.

图1 评论对象的同义语义关系图Fig.1 Synonymy semantic of the comment objects
候选评论对象是名词和动名词,利用《同义词词林扩展版》的层级结构可以获取候选评论对象之间的同义关系,公式如式(1)所示,其中S(wi,wj)等于1表示评论对象词语w1和w2具有同义性,l1-4表示同义词词林的前四层结构.
(1)
在获取评论对象间的同义关联集后,可构建如图1所示的语义关系图,每一个连通子图对应一个同义评论对象聚类簇,并依此构建同义关联组合集Ssoo.
3.2 低频评论词与评论对象关系提取
3.2.1 构建候选组合集
利用依存句法关系发现句子中的典型评论对象-评论词句法结构,并运用词性关系限制得到候选关联组合集,设置规则如下:
规则1.依存句法关系满足SBV(主谓关系),词性关系满足名词+形容词,其中的名词对应评论对象,形容词对应评论词.
例1.“这次车祸非常惨烈.”“车流慢但是秩序很好.”2个句子的依存句法分析及词性标注如图2所示.其中,句1的关联组合单元为<车祸,惨烈>,句2具有并列关系,关联组合单元为<车流,慢>和<秩序,好>.
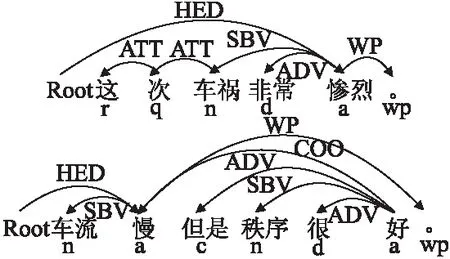
图2 例1的依存句法分析及词性标注Fig.2 Dependency parsing and POS tagging for example 1
通过规则1可以构建候选关联组合集Sor1,利用S-PMI(sentence pointwise mutual information)计算Sor1中的元素
(2)
其中,fc(wi,wj)是词语wi和wj在句子中的共现频率,f(wi)是wi的词频,f(wj)是wj的词频.低频评论词和评论对象的句式结构关系同样满足规则1,可以利用规则1提取的候选关联组合集Sor1,在此基础上计算关联度.
3.2.2 抽取低频评论对象-评论词的组合
低频评论词一般只修饰比较固定的评论对象,一些低频的评论词很难被LDA发现.为了提高低频评论词与其修饰的评论对象的关联度,从词频比与共现频率差值进行分析,即不仅考察共现频率,而且考察相互的专有性,其关联度计算如式(3).
(3)
其中,ζ1是词频阈值,p′是候选关联组合中wi和wj的词频比,f′(wi)是wi词频与共现频率fc(wi,wj)的差值.取关联度值大于一定阈值的关联组合并进行归一化后构成低频评论对象-评论词关联集合Slor.
3.2.3 评论词组合关系的提取
由于评论文本情感表达中经常使用多个词语组合的形式,如“影响很大”“影响不大”“影响不太大”“影响很不明显”等,其中的主体评论词都不同程度地和副词、否定词进行结合,形成了评论词组合,并且不同组合表达的情感语义也不相同.在主题模型的主题词提取过程中如果将这些词语分开提取的话,会影响评论词语对评论对象真实情感的表达.所以对于此类组合式情感表达可以进行预先评论词组合关系提取.利用句法分析来发现评论词的组合关系,即不仅仅提取单个主体评论词,而是将否定词和程度副词也同时提取,这样才能获得较完整的评论语义.利用以下规则来发现评论词组合关系:
规则2.一个单句中满足SBV(主谓关系) + ADV(状中结构)依存结构关系,或SBV(主谓关系) + ADV(状中结构) + ADV(状中结构)依存结构关系,对应的“副词(或否定副词‘不’) + 形容词”,或“副词(或否定副词‘不’) + 否定副词‘不’(或副词) + 形容词”构成评论词组合,其中形容词为主体评论词.

图3 词性标注和依存句法分析Fig.3 Dependency parsing and POS tagging for the examples
根据规则2,从图3中可以识别出评论词组合“很大”“不大”“不太大”“很不明显”.
4 SCTA-LDA模型设计
4.1 语义约束和时间关联机制
1)词语语义关系对主题-词语分配的约束.在对词语w进行主题分配时,首先判断是否存在于同义词关联集合Ssoo中,如果存在则尽量将该词语分配到同义词最多的主题中;否则,以句子为单位找到词语w前一位置相邻词语wp,然后判断

图4 SCTA-LDA模型图Fig.4 SCTA-LDA model
2)SCTA-LDA的时间关联主要包括2个方面:① 时间片对主题个数约束的设置;② 时间片内的主题-词语分配的约束.相对于标准LDA模型主题个数设置的不受约束,SCTA-LDA的主题个数与时间片个数形成动态关联,即由时间片的数量来决定主题个数;SCTA-LDA加入和时间片关联的主题-词语分配权重因子,使得同一时间片内的词语分配到同一主题的概率要高于非同一时间片内词语.
4.2 SCTA-LDA结构设计
在主题模型LDA中加入时间层,形成四层模型结构:文档层、时间层、主题层和词语层,可以获取随时间变化的主题词,并通过主题聚类识别主题词间的关联性,实现动态主题词链发现.SCTA-LDA模型结构如图4所示,符号说明见表1.

表1 SCTA-LDA模型符号说明Table 1 Notation of SCTA-LDA
4.3 SCTA-LDA的文档生成过程
SCTA-LDA模型的文档生成算法如表2所示.

表2 SCTA-LDA文档生成算法Table 2 Text generation algorithm of SCTA-LDA
4.4 SCTA-LDA模型参数估计


(4)
可推导,SCTA-LDA模型Gibbs抽样的概率估算公式如式(5)所示.

(5)
由式(5),可推导出SCTA-LDA四个分布参数的估算如式(6)、(7)、(8)和(9)所示.
(6)
(7)
(8)
(9)
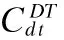
5 实验分析
5.1 数据集选择及设置
数据采集于新浪微博(http://weibo.com)的文本数据,共采集了92 427篇评论文档,共包含2 865 237个句子.分词工具采用中科院ICTCLAS,依存句法分析采用哈工大LTP[21].进行实验效果比较的主题模型分别为SCAT-LDA、DTM[10]、TS[17]和LDA[9],均采用Gibbs抽样进行参数估计.主题模型测试集和训练集评价文档数的比例设置为1:10.相关系数设置为:文档-主题概率分布参数α为50/K,K为主题个数,top-n取值为20(即在每个主题中取按概率降序排列的前top-n个词语作为主题词);主题-词语概率分布参数β为0.01,抽样次数为1 000次,采用10-fold交叉验证.比较标准使用人工标注的评论对象集合、评论词集合和评论对象-评论词组合集,采用准确率P(Precision)、召回率R(Recall)和F值来评估不同模型的主题词语提取效果.
5.2 实验比较分析
5.2.1 评论对象提取
评论对象提取的准确率和召回率如图5和图6所示.其中,横坐标为主题个数K,纵坐标为准确率P和召回率R.

图5 评论对象提取的准确率比较Fig.5 Precision comparison of comment objects extraction

图6 评论对象提取的召回率比较Fig.6 Recall comparison of comment objects extraction
从图5进行分析,SCTA-LDA在不同主题数时都具有更高的准确率.在主题数目大于等于90的时候,其他模型的准确率下降趋势较明显,而SCTA-LDA由于引入了语义约束,能够捕捉低频评论对象,所以下降趋势不明显.LDA倾向于提取全局性的高频评论对象,并且没有时间的约束,在主题数较大的时候,准确率下降更为明显.
从图6进行分析,主题数少的时候,由于提取的主题词语有限,各个模型的召回率相差不大.随着主题数的增加,SCTA-LDA的优势逐渐体现出来.在主题数较高的时候,语义约束和时间关联下的SCTA-LDA能够识别更多的低频评论对象,而其他模型难以进一步发现低频评论对象.例如,SCTA-LDA可以发现低频的同义评论对象,如与高频评论对象“罪犯”同义的“以身试法者”,而其他模型难以发现此类低频评论对象.
5.2.2 评论词提取
评论词提取的准确率、召回率如图7和图8所示.其中,横坐标为主题个数K,纵坐标为准确率P和召回率R.
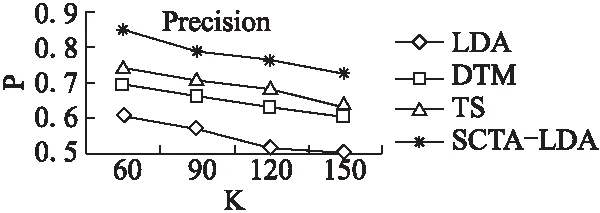
图7 评论词提取的准确率比较Fig.7 Precision comparison of opinion words extraction
从图7和图8进行分析,可以发现SCTA-LDA的准确率优势较明显,召回率优势随着K的增加也逐渐表现出来.表明语义约束可以提高低频评论词的分配概率,从而更多地发现关联于相对高频评论对象的低频评论词.由于TS考虑了主题和评论词的关联,所以评论词提取的准确率和召回率要高于DTM和LDA.

图8 评论词提取的召回率比较Fig.8 Recall comparison of opinion words extraction
SCTA-LDA的R值随着主题数的增加其上升趋势很迅速,也说明了一些低频评论词通过关联约束更好地匹配到了相对应的评论对象,随着这类评论对象的提取而提高了与其关联评论词的发现率.例如,一些低频评论词,如关联与评论对象“事故”的评论词“蹊跷”、“不可理喻”等,在LDA、DTM和TS中没有发现,而在SCTA-LDA模型中得以发现.
5.2.3 评论对象-评论词匹配组合提取
评论对象-评论词匹配组合提取的准确率和召回率可以考察模型的主题词链提取能力,应尽量将匹配程度高的词语分配到同一主题.匹配组合提取的P和R如图9和图10所示.其中,横坐标为主题个数K,纵坐标为准确率P和召回率R.
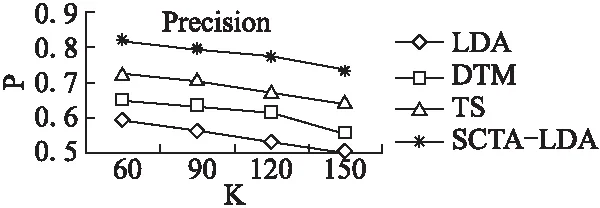
图9 匹配组合提取的准确率比较Fig.9 Precision comparison of matching group extraction
从图9进行比较分析,在各个主题数下,SCTA-LDA模型提取匹配组合的准确率都高于其他模型,表明在语义约束和时间关联情况下,LDA模型可以提取更符合语义要求的主题词语.TS模型的准确率高于DTM,说明引入主题-评论词关联的LDA相对于时间关联的LDA更能获取匹配关系.由于LDA没有加入先验知识,难以发现一些低频词语关系,所以匹配组合提取的准确率偏低.

图10 匹配组合提取的召回率比较Fig.10 Recall comparison of matching group extraction
从图10进行比较分析,LDA倾向于发现高频词语和高频共现关系,导致了词频较高的词语在各主题下被重复提取,影响了其他词语及词语关系的提取.DTM和TS引入了相应约束后,对于词语关系的发现率有了明显改善.而SCTA-LDA在语义约束和时间关联的作用下,提高了单位时间内的低频词语关系的提取率,可以发现一些LDA、DTM和TS模型难以发现的低频匹配组合,例如,<事故,蹊跷>、<以身试法者,穷凶恶极>等.
5.2.4 评论对象及评论词语提取性能比较
对只加入语义约束的LDA模型(记为SC-LDA)、只加入时间关联的LDA模型(记为TA-LDA)和SCTA-LDA模型进行比较,分析各个模型对于评论对象及评论词的提取能力,用F值进行评估,如图11所示.

图11 评论对象和评论词提取的F值比较Fig.11 F comparison of comment objects and opinion words extraction
从图11进行比较分析,在各个主题数下,SCTA-LDA模型的F值均高于其他2个模型,说明相对于仅仅加入一种先验知识的LDA模型,同时加入语义约束和时间关联因子的LDA模型具有更好的评论对象和评论词提取效果.SC-LDA模型的F值高于TA-LDA模型表明语义约束对于主题词链的提取更有帮助,能够提取一些低频评论对象及其关联的评论词语.加入时间关联的TA-LDA模型,虽然增加了主题词语聚类的时间区分度,但对低频词语的提取率没有明显改善.
6 结束语
由于LDA主题模型可以从大规模的社交媒体文本数据中提取主题词,并通过主题聚类发现潜在的评论对象和评论词之间的关系,许多研究利用LDA模型来实现基于主题聚类的主题词提取.但由于LDA模型语义理解能力的不足,同时对时间缺乏敏感性,提取的主题词链往往不能满足主题分析的要求,尤其是面对具有复杂语法及语义结构的中文社交媒体评论文本.
根据中文社交媒体评论的特点,充分考虑LDA主题模型文档-主题-词语的概率分配机制的基础上,通过引入语义约束和时间关联,指导LDA进行主题-词语分配.其中语义约束可以提升LDA对低频评论对象、评论词及其关系的提取率,时间关联可以提高LDA的时间敏感性,实现动态主题词语的获取.实验结果表明,提出的SCTA-LDA模型对评论对象和评论词的提取具有较高的准确率和召回率,同时对评论对象-评论词匹配关系也具有较好的聚类效果,通过这些词语及其关系的获取,可以实现大规模文本数据下的中文社交媒体主题的有效提取和分析.
[1] The 40th China statistical report on internet development [EB/OL].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201708/P020170807351923262153.pdf,2017.
[2] Zhi S,Qinke P.An opinion detection algorithm based on online posts′ relation[C].Proceedings of the 13th International Conference on Computer and Information Science (ICIS),2014:153-156.
[3] He Min,Xu Jie,Du Pan,et al.Bursty topic detection method for microblog based on time series analysis[J].Journal on Communications,2016,37(3):48-54.
[4] Wei Ming-chuan,Zhu Jun-jie,Zhang Jin,et al.An algorithm for subtopic detecting based on absorbing Markov chain[J].Journal of Chinese Information Processing,2014,28(1):41-46.
[5] Li Lei,Liu Ji,Zhang Hong-kui.Topics identification and evolution trend of network public opinion based on co-occurrence analysis[J].Information Science,2016,34(1):44-47+57.
[6] Chen Yu-zhong,Fang Ming-yue,Guo Wen-zhong.Research on multi-label propagation clustering method for microblog hot topic detection[J].Pattern Recognition and Artificial Intelligence,2015,28(1):1-10.
[7] Song L,Wu H,Zhang Z.Research on SVM prediction model based on chaos theory[J].Advanced Science and Technology Letters,2016,123(13):59-63.
[8] Devi K N,Bhaskaran V M.Rough set and entropy based feature selection for online forums hotspot detection[J].International Journal of Computer Applications,2015,117(10):37-41.
[9] Blei D,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3(3):993-1022.
[10] Blei D,Lafferty J D.Dynamic topic models[C].Proceedings of the 23rd International Conference on Machine Learning (ICML),2006:113-120.
[11] Qiu Ming-tao,Ma Jing,Zhang Lei,et al.A feature extraction method of microblog based on a scalable topic LDA model[J].Information Science,2017,35(4):22-26+31.
[12] Cao Li-na,Tang Xi-jin.Trends of BBS topics based on dynamic topic model[J].Journal of Management Sciences in China,2014,17(11):109-121.
[13] Li Feng-ling,Zhu Bao-ping.On LDA-based microblogging topic detection[J].Computer Applications and Software,2014,31(10):24-26.
[14] Guo Lan-tian,Li Yang,Mu De-jun,et al.A LDA model based topic detection method[J].Journal of Northwestern Polytechnical University,2016,34(4):698-702.
[15] Chen Xiao-mei,Gao Cheng,Guan Xin-hui.Extraction method of network public opinion based on LDA topic model[J].Library and Information Service,2015,59(21):21-26.
[16] Qiu Li-qing,Chen Zhuo-yan,Ding Chang-qing,et al.A novel topic discovery algorithm iMLDA based on modified LDA topic model in social networks[J].Information Science,2016,34(9):115-188+133.
[17] Dermouche M,Kouas L,Velcin J,et al.A joint model for topic-sentiment modeling from text[C].Proceedings of the 30th ACM Symposium on Applied Computing (SAC),2015:819-824.
[18] Wang Fei-fei,Yang Yang,Jiang Fei,et al.A link prediction method based on similarity of user′s topics[J].Journal of xi′an Jiaotong University,2016,50(8):103-109.
[19] Li Xiang-dong,Ba Zhi-chao,Huang Li.News topic mining method based on weighted latent Dirichlet allocation model[J].Journal of Computer Applications,2014,34(5):1354-1359.
[20] Peng Yun,Wan Chang-xuan,Jiang Teng-jiao,et al.An algorithm based on words clustering LDA for product aspects extraction[J].Journal of Chinese Computer Systems,2015,36(7):1458-1463.
[21] Che W X,Li Z H,Liu T.LTP:a Chinese language technology platform[C].Proceedings of the 23rd International Conference on Computational Linguistics (COLING),2010:13-16.
附中文参考文献:
[1] 第40次中国互联网络发展状况统计报告[EB/OL].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201708/P020170807351923262153.pdf,2017.
[3] 贺 敏,徐 杰,杜 攀,等.基于时间序列分析的微博突发话题检测方法[J].通信学报,2016,37(3):48-54.
[4] 魏明川,朱俊杰,张 瑾,等.基于吸收马尔可夫链的子话题发现方法[J].中文信息学报,2014,28(1):41-46.
[5] 李 磊,刘 继,张竑魁.基于共现分析的网络舆情话题发现及态势演化研究[J].情报科学,2016,34(1):44-47+57.
[6] 陈羽中,方明月,郭文忠.面向微博热点话题发现的多标签传播聚类方法研究[J].模式识别与人工智能,2015,28(1):1-10.
[11] 邱明涛,马 静,张 磊,等.基于可扩展LDA模型的微博话题特征抽取研究[J].情报科学,2017,35(4):22-26+31.
[12] 曹丽娜,唐锡晋.基于主题模型的BBS话题演化趋势分析[J].管理科学学报,2014,17(11):109-121.
[13] 李凤岭,朱保平.基于LDA模型的微博话题发现技术研究[J].计算机应用与软件,2014,31(10):24-26.
[14] 郭蓝天,李 扬,慕德俊,等.一种基于LDA主题模型的话题发现方法[J].西北工业大学学报,2016,34(4):698-702.
[15] 陈晓美,高 铖,关心惠.网络舆情观点提取的LDA主题模型方法[J].图书情报工作,2015,59(21):21-26.
[16] 仇丽青,陈卓艳,丁长青,等.基于改进LDA主题模型的社会网络话题发现算法iMLDA[J].情报科学,2016,34(9):115-188+133.
[18] 王菲菲,杨 扬,蒋 飞,等.面向用户话题相似性特征的链路预测方法[J].西安交通大学学报,2016,50(8):103-109.
[19] 李湘东,巴志超,黄 莉.基于加权隐含狄利克雷分配模型的新闻话题挖掘方法[J].计算机应用,2014,34(5):1354-1359.
[20] 彭 云,万常选,江腾蛟,等.一种词聚类LDA的商品特征提取算法[J].小型微型计算机系统,2015,36(7):1458-1463.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
当代陕西(2019年15期)2019-09-02
汽车文摘(2019年3期)2019-03-04
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
档案管理(2014年6期)2014-10-30
棋艺(2014年7期)2014-09-09
