
一种基于系统主题挖掘的协同过滤算法
2018-04-13 10:16高心丹
小型微型计算机系统 2018年4期
李 雪,高心丹
(东北林业大学 信息与计算机工程学院,哈尔滨 150040) E-mail:gaoxd@nefu.edu.cn
1 引 言
随着互联网信息与网络服务(如:电影、音乐)的爆炸式增长,信息过载成为一大难题,个性化推荐系统应运而生,它的出现有效地提高了信息处理效率和服务质量.当前在电子商务[1]、餐饮[2]、交通运输[3]等领域都存在着各种形式的推荐系统.协同过滤算法[3]是众多推荐系统中应用最广泛、最成功的推荐技术之一,在众多领域得到了应用.然而随着系统数据多维化、稀疏化情况的加剧,近邻寻找的复杂度急剧增加,推荐系统性能显著下降.为了解决这些问题,很多学者采用聚类算法来提高推荐效果[4,6-7].由于项目分类标签与项目内容有较高的相关性,独立于评分数据的系统本身就存在一种自然的群组,基于信息缺失的稀疏矩阵的聚类虽然能够提高推荐精度,但存在聚类结果解释性较差、聚类数量的选择带有主观性、聚类空间较大等问题.本文通过更新聚类算法、改变聚类对象,生成可解释性较高的系统主题分类以改善传统方法的不足,同时兼顾项目的时间和评分属性寻找近邻.在解决项目的主题跨度问题方面,本文引入一种主题偏重系数来衡量系统内项目的内容倾向,最后得到相应主题下用户对未评分目标项目的偏好,并依据偏好度排序得到推荐结果.
2 相关工作
2.1 项目属性对推荐的影响
传统推荐算法是基于用户项目评分矩阵计算项目相似度或用户相似度,由于用户项目评分数据是一种有缺失值的、稀疏的数据,在传统相似度计算过程中会产生一定量的误差,这种误差会降低推荐系统的性能.为了提高推荐性能一些研究者采用矩阵填充的方法来改善相似度计算的数据基础,如邓爱林等[8]通过对用户评分并集中的未评分项目进行预测评分达到局部填充的效果,在此基础上进行相似度计算.张锋等[9]利用BP神经网络算法对用户未评分项目进行预测评分,增强数据密度,基于填充矩阵进行相似度计算.然而填充过程存在预测误差并且计算复杂度较高.也有一些研究者通过降维技术增加数据紧密度,如Sarwar B M等[11]通过奇异值分解减少项目空间维数,在降维后的紧密数据上计算用户关联度,但降维会导致信息丢失,对推荐系统的影响不一定是正面的.上述文献中相似度计算是以应用填充或降维技术处理后的用户评分矩阵为基础,在项目或用户关系中仅仅考虑了用户评分的影响,计算得到的相似度是一种单一相似度,在刻画项目关联性时具有片面性、局限性,所以又有一些学者在相似度计算过程中增加了项目属性,如刘健等[10]引入项目标签,分别计算用户与标签、标签与项目的关联度,构建用户兴趣模型.张新猛等[5]在相似度计算过程中考虑了项目的评分相似性与类别相似性,提升了项目间的关联度.上述改进方案增加了项目关联的紧密度、弱化了评分数据稀疏性的影响,提升了推荐质量,可见项目属性对于提升关系描述准确度具有积极的作用.本文在相似度计算过程中融入了项目的评分与时间属性,通过平衡因子协调项目评分相似度与项目时间相似度.
2.2 基于聚类的推荐算法
聚类算法的应用有效的缩小了近邻搜索空间、提升了计算效率、增强了推荐性能,如Rashid等[12]在评分矩阵的基础上进行用户聚类,聚类中心作为聚类的代理用户,然后基于目标用户的最相似代理用户进行最近邻推荐.邓爱林等[6]采用K-means算法对评分矩阵进行项目的聚类,得到k个项目分类,然后在与目标项目最相似的几个类中通过计算评分矩阵的相似度来搜索近邻并排序产生推荐.George等[13]使用联合聚类方法基于评分矩阵对项目与用户同时聚类.
上述方法基于评分数据分别对项目、用户进行聚类,然而系统项目评分数据是一种高维的、有缺失的、信息稀疏的数据,影响聚类的准确性;同时,上述聚类算法应用时,需要事先人为确定分类数量,存在一定的主观因素,并且产生的聚类中心并非真实存在数据.为了改善上述问题,本文改变了聚类对象,引入一种低维的项目-类别矩阵,降低了聚类空间,并且在聚类阶段应用了一种较新的高效聚类算法—近邻传播聚类算法(AP聚类),该算法不需要事先指定聚类个数,聚类中心是原始数据中真实存在的值,且多次执行结果完全一样.本文利用AP算法对项目-类别矩阵进行聚类,从而生成新的分类,聚类中心作为新分类的主题描述.
3 改进的推荐算法
3.1 基于分类标签的AP聚类
3.1.1 项目分类标签相似度
分类标签指系统中实际存在的、描述性的类别标注,如果两个分类标签(如喜剧、爱情)在项目分布上趋向一致,说明这两个标签在内容表达上具有一定的联动性.
表1 项目-类别标签矩阵
Table 1 Matrix of item-genre
基于上述思想,在系统中构建与表1同样的项目-类别标签矩阵.可以使用Jaccard系数计算标签之间的相似性,设分类标签c和d标注的项目集为Ic和Id,则c和d之间的相似性sim(c,d)如公式(1)所示:
(1)
通过相似度计算得到的分类标签相似度矩阵作为AP聚类的输入.
3.1.2 AP聚类
AP聚类的基本思想[7]:给定N个数据点,计算数据点两两之间的相似度构造矩阵S.在相似度矩阵S基础上,依靠两点之间的消息传递迭代更新,即计算吸引度R(i,k)和归属度A(i,k),R(i,k)和A(i,k)值越大,点k作为聚类中心和i属于以k为聚类中心的簇的可能性越大.当迭代次数达到上限或收敛程度符合要求时,停止迭代,产生n个符合要求的聚类中心,再根据聚类中心与普通点的相似度,将普通点划分到不同的聚类中,完成整个聚类过程.
R(i,k)和A(i,k)的计算公式如下:
R(i,k)=S(i,k)-max{A(i,k)+S(i,j)}
(2)

(3)
R(k,k)=P(k)-max{A(k,j)+S(k,j)}
(4)
其中,j∈{1,2,3,…,N,j≠k}
引入阻尼系数λ控制迭代的收敛,每次迭代都需要考虑上一次的吸引度和归属度,加权更新如下:
Ri=(1-λ)×Ri+λ×Ri-1
(5)
Ai=(1-λ)×Ai+λ×Ai-1
(6)
其中,λ∈[0.5,1).
下面给出聚类的具体流程:
Step1.计算分类标签相似度矩阵S,S作为AP聚类的输入.
Step2.选取参考度阀值P(P为点i作为聚类中心的标准,本文取相似度矩阵S的中值).
Step3.计算吸引度和归属度,根据R(k,k)+ A(k,k)的值来判断k是否为聚类中心.
Step4.若迭代次数达到上限或者聚类中心已经不在发生变化,转Step 5,否则,返回Step 3.
Step5.将其余点根据相似度划分到各个聚类中,生成新类别.
Step6.根据项目初始标签所属的新类别进行项目类别划分,允许跨类分布,聚类结束.
3.2 类内项目相似度
在计算项目相似度时考虑了项目的时间、评分属性,即认为同一主题下同时代分布的项目更加相似.
在计算项目年代相似性时,以年代作为项目时间分布的单位,由于项目具有固定的生产或发布时间,在时间分布上具有唯一性,所以在计算相似度时,相同年代项目间相似度为1,不同年代项目间的相似度为0.建立项目—时间相似度矩阵T(n,n),Tij值为0或1.
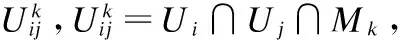
余弦相似度:
(7)
修正余弦相似度:
(8)
皮尔森相似度:
(9)

本文引入了平衡因子α协调项目时间相似性和评分相似性对项目相似性的影响,由此定义的项目间相似性度量公式作为项目i和项目j之间类内相似性度量的标准,如公式(10)所示.
simk(i,j)=αsimr(i,j)+(1-α)T(i,j)
(10)
3.3 产生推荐
3.3.1 主题偏重系数
由于存在跨主题分布项目,所以类内评分不能作为项目最终的评分,所以引入了主题偏重系数W作为项目所跨主题的系统偏重.设项目h横跨主题集合为M={M1,M2…Mn},Mk∈M,k=1,2,…n,对应的项目集合为IM=IM1∪IM2∪…∪IMn,则项目所跨主题对应的偏重系数为:
(11)
式中CMIMk为IMk在集合M中的补集.
3.3.2 预测推荐
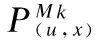
由于系统存在单一主题项目和多主题项目,所以分两种方式进行计算.
(12)

(13)

4 实验结果及分析
4.1 实验数据集及度量标准
实验数据采用GroupLens站点(http://www.grouplens.org/)提供的MovieLens 数据集,GroupLens项目组提供了不同大小的数据集,本文采用ml-100k数据集,该数据集包含943位用户对1628部电影的1000 000个评分,且评分范围为1-5,每个用户至少对20部以上的电影进行了评分,数据稀疏度为93.7%.
实验采用的数据集包含1682部电影、19种电影类型标签,忽略掉仅含2部电影且信息缺失的unknown类型,数据集更新为1680部电影18种类型.18个电影类型依次对应0、1、…、17,一部电影对应有1-7个类型标签.电影发行时间的时间轴为1922-1998年,横跨8个年代,以年代为单位对电影进行划分,年代类型依次对应0、1、…、7.具体实验取数据集中u.data的评分子集:随机选取400名用户作为实验数据集,随机选取80%数据作为训练集,20%数据作为测试集,训练集稀疏度为94.0%.
本文使用MAE方法[14]度量预测准确度,主要通过计算测试集中用户的预测评分与实际评分之间的平均偏差来度量预测算法的准确性,可以直观地度量推荐质量,MAE越小,推荐质量越高.MAE定义为:
(14)
式中pi为预测评分、qi为真实评分、N为测试集数量.
4.2 实验分析
算法中有2个参数需要选择:聚类算法中的参考度P、相似度平衡因子α,参考度P取项目标签相似度的中值,平衡因子α,通过实验进行选取.
表2 聚类结果
Table 2 Result of clustering

类别组 成描述1聚类中心:Action标签:Action、War、Horror、Western、Sci-Fi、Thriller、Adventure偏打斗场景2聚类中心:Children's标签:Children's、Animation、Fantasy、Musical适合儿童3聚类中心:Documentary标签:Documentary纪录片4聚类中心:Film-Noir标签:Film-Noir、Crime、Mystery社会阴暗面5聚类中心:Romance标签:Romance、Drama、Comedy浪漫、轻松
AP聚类算法对项目分类标签进行聚类,产生5个聚类集,如表2所示.
平衡因子α是调节项目相似性的参数,可以使相似性的计算更加合理,实验1设计α的取值为0-1.0,每次增加0.1,设定邻居数为20.图1表示在本文提出的协同过滤算法中不同评分相似度下α对预测性能的影响.
实验结果表明,融合评分相似度和时间相似度的算法优于单一相似度算法(α=0.0、1.0)的预测效果.随着α的增加,MAE呈递减趋势,评分越来越接近实际评分.在实验对比阶段,选择对应相似度下的最优α值进行实验.
4.3 实验对比
为验证本文算法的有效性,设计实验与传统协同过滤算法的预测性能进行对比.最早在MovieLens数据集上应用传统协同过滤算法的是GroupLens研究小组的Sarwar教授等人.

图1 平衡因子对MAE的影响Fig.1 Influence of α to MAE
在文献[14]中,Sarwar教授等人通过实验得到Item-based方法的推荐效果要略好于User-based方法的结论,并且对传统Item-based方法在MovieLens数据集上的性能进行了评估,如图2所示.

图2 传统协同过滤的预测效果Fig.2 Effect of traditional collaborative filtering
传统Item-based方法在不同相似度下预测效果不同,其中基于修正余弦相似度(AdjustedCosine)Item-based方法表现最佳.本文将与文献[14]中传统协同过滤在MovieLens数据集上的最佳预测效果即基于修正余弦相似度Item-based方法的MAE值进行对比实验,如图3所示.

图3 预测精度比较Fig.3 Accuracy comparison of algorithm
从预测精度的比较可以看出,本文提出的方法在Cosine度量标准下,邻居数量大于80,MAE值较优;在AdjustedCosine度量标准下,邻居数量大于30,MAE值较优;在Pearson度量标准下,邻居数量大于30,MAE值较优,且整体预测效果最优.从对比实验可以看出,本文提出的基于系统主题挖掘的协同过滤算法对推荐效果的准确性有明显的提升作用.
5 结 论
针对传统推荐算法在近邻寻找时忽略了系统本身的群组特性的问题,本文引入了系统主题模型,充分挖掘系统项目本身的特点,改善了传统算法对评分矩阵的依赖性,缓解了新物品的初始群组问题.实验表明本文提出的方法可以显著提高推荐算法的准确性.本文方法虽然一定程度上缓解了数据稀疏问题对推荐精度的影响,但仍存在冷启动、邻居稀疏等问题,因而未来将会重点研究结合矩阵填充、图论等知识的推荐算法以降低推荐算法的局限性.
[1] Ai Dan-xiang,Zuo Hui,Yang Jun.C2C e-commerce recommender system based on three-dimensional[J].Computer Engineering and Design,2013,34(2):702-706.
[2] Xiong Cong-cong,Deng Ying,Shi Yan-cui,et al.Food recommendation algorithm based on collaborative filtering [J].Application Research of Computers,2017,34(7):1-5.
[3] Shao Kuo-yi,Ban Xiao-juan,Wang Xiao-kun,et al.Geographic information recommender system optimized by transportation network data [J].Chinese Journal of Engineering,2015,37(12):1651-1657.
[4] Li Tao,Wang Jian-dong,Ye Fei-yue.Collaborative filtering recommendation algorithm based on clustering basal users[J].System Engineering and Electronics,2007,29(7):1177-1178.
[5] Zhang Xin-meng,Li Song.Collaborative filtering recommendation algorithm considering data weight and item attributes[J].Automation and Instrumentation,2016,36(9):69-73.
[6] Deng Ai-lin,Zuo Zi-ye,Zhu Yang-yong.Collaborative filtering recommendation algorithm based on clustering [J].Mini-Micro Systems,2004,25(9):1665-1670.
[7] Hu Ji-hua,Cheng Zhi-feng,Zhan Cheng-zhi.AP algorithm for public transportation station clustering [J].Computer Engineering,2011,37(S1):223-225+232.
[8] Deng Ai-lin,Zhu Yang-yong,Shi Bo-le.A collaborative filtering recommendation algorithm based on item rating prediction [J].Journal of Software,2003,14(9):1621-1628.
[9] Zhang Feng,Chang Hui-you.Employing BP neural networks to alleviate the sparsity issue in collaborative filtering recommendation algorithms[J].Journal of Computer Research and Development,2006,49(4):667-672.
[10] Liu Jian,Zhang Kun,Chen Xuan.Personalized recommendation algorithm based on tags and collaborative filtering [J].Computer and Modernization,2016,32(2):62-65+71.
[11] Sarwar B,Karypis G,Konstan J,et al.Application of dimensionality reduction in recommender system-a case study[R].Minnesota Univ,Minneapolis Dept.of Computer Science,2000.
[12] Rashid A M,Lam S K,Karypis G,et al.ClustKNN:a highly scalable hybrid model- & memory-based CF algorithm[C].Proceeding of Web Knowledge Discovery and Data Mining(Web KDD),2006.
[13] George T,Merugu S.A scalable collaborative filtering framework based on co-clustering[C].IEEE 5th International Conference on Data Mining(ICDM),2005:625-628.
[14] Sarwar B,Karypis G,Konstan J,et al.Item-based collaborative filtering recommendation algorithms[C].Proceedings of the 10th International World Wide Web Conference(WWW),2001:285-295.
附中文参考文献:
[1] 艾丹祥,左 晖,杨 君.基于三维协同过滤的C2C电子商务推荐系统[J].计算机工程与设计,2013,34(2):702-706.
[2] 熊聪聪,邓 滢,史艳翠,等.基于协同过滤的美食推荐算法[J].计算机应用研究,2017,34(7):1-5.
[3] 邵阔义,班晓娟,王笑琨,等.基于交通网络数据优化的地理信息推荐系统[J].工程科学学报,2015,37(12):1651-1657.
[4] 李 涛,王建东,叶飞跃.一种基于用户聚类的协同过滤推荐算法[J].系统工程与电子技术,2007,29 (7):1177-1178.
[5] 张新猛,李 松.基于项目属性与数据权重的协同过滤推荐算法[J].自动化与仪表,2016,36(9):69-73.
[6] 邓爱林,左子叶,朱扬勇.基于项目聚类的协同过滤推荐算法[J].小型微型计算机系统,2004,25(9):1665-1670.
[7] 胡继华,程智锋,詹承志.一种用于公交站点聚类的AP算法[J].计算机程,2011,37(S1):223-225+232.
[8] 邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):1621-1628.
[9] 张 锋,常会友.使用BP神经网络缓解协同过滤推荐算法的稀疏性问题[J].计算机研究与发展,2006,49(4):667-672.
[10] 刘 健,张 琨,陈 旋.基于标签和协同过滤的个性化推荐算法[J].计算机与现代化,2016,32(2):62-65+71.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
河北画报(2020年8期)2020-10-27
现代计算机(2018年27期)2018-10-25
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
舰船电子对抗(2017年6期)2018-01-11
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
互联网天地(2016年1期)2016-05-04
Coco薇(2015年11期)2015-11-09
