
基于梯度提升决策树的微博虚假消息检测
2018-04-12 07:18段大高盖新新韩忠明刘冰心
计算机应用 2018年2期
段大高,盖新新,韩忠明,刘冰心
(1.北京工商大学 计算机与信息工程学院,北京 100048; 2.北京工商大学 食品安全大数据技术北京市重点实验室,北京 100048;3.University of Liverpool, Department of mathematical Sciences, Liverpool, GB L69 7ZX)(*通信作者电子邮箱hanzhongming@btbu.edu.cn)
0 引言
微博是如今网民发布信息和获取信息的主要渠道之一。根据中国互联网信息中心(China Internet Network Information Center, CNNIC)2017年1月发布的全国互联网发展统计报告[1],我国网民规模达7.31亿,其中微博用户超过2.67亿,占整体网民的36.5%。微博的低门槛特性使得用户可以不受时间地域的限制,自由表达自己的观点,使用户之间分享信息更加迅速、便捷。微博已经逐步渗透进人们的生活,影响人们的生活方式。
微博平均每天会增加数亿条博文,这些博文中既有真实的信息,也有大量的虚假信息,而虚假信息的泛滥对群众的影响非常大。例如:2017年3月初,一篇文章在网络上引起轩然大波,该文称疫苗会损害人体健康,危害无穷,家长们应该让孩子远离疫苗,甚至声称孩子自然感染疾病比打疫苗强。该虚假消息在传播的过程中,误导了网民的思想,很多家长选择了不再给孩子注射疫苗。4月,微博上纷纷在转一条如何鉴别草莓变色催熟的文章。该文称如果草莓籽是红色的,便是用了染色剂的缘故。浙江宁波、江苏徐州等地市民也的确发现,市面上很多草莓的籽是红色的,顿时心生不安。很多市民不再食用草莓,给社会造成了巨大的经济损失。然而,真实的情况是,草莓自然成熟后,有部分草莓籽是会变成红色的。有效地识别虚假信息对营造诚信、公平、健康的网络环境以及维持正常的社会秩序是十分必要的。
现有的研究主要是通过选取文本内容、用户属性和传播特性等方面的特征,然后构建合适的分类模型,以达到识别微博虚假消息的目的。但是,这些研究中往往只选取局部、片面的特征(如选取文本内容特征的统计特征、浅层传播特征或者简单的用户属性特征),没有全面、深入地分析并挖掘影响虚假消息识别的主要因素。另外,以往的研究中只是选用单一的分类器对微博虚假消息进行检测,如朴素贝叶斯(Naive Bayes, NB)、支持向量机(Support Vector Machine, SVM)、决策树(Decision Tree,DT)等,没有考虑使用组合多个弱分类器构建强分类器来识别虚假消息,故而识别的精度不高。因此,基于微博的短文本特性,本文提取微博评论的文本内容、用户属性、信息传播和时间特性四个方面的特征,构建基于梯度提升决策树(Gradient Boost Decision Tree, GBDT)算法的微博虚假消息识别模型。实验结果表明,本文提出的识别方法能够有效提高虚假消息检测的准确率。
1 相关工作
近几年国内外关于微博虚假消息的研究逐渐增多。在国外方面,2011年,Castillo等[2]提出了对Twitter话题可信度进行评估的方法,通过提取消息特征、用户特征、话题特征以及传播特征,采用J48决策树分类方法来预测热门话题是否可信。2012年,Yang等[3]提出客户端类型和微博事件发生的地理位置两种新特征,采用SVM分类方法对谣言进行检测。实验结果表明,当微博所涉及的事件发生在国外而且使用非移动客户端时,此微博被判断为谣言微博的概率较高。2015年,Dayani等[4]通过提取用户特征和内容特征,并采用K最近邻(K-Nearest Neighbors, KNN)分类器以及NB分类器在Twitter中检测谣言中支持、反对、质疑、中性的评论。实验结果表明:对于用户特征,KNN分类器的效果并不理想;而对于内容特征,朴素贝叶斯能有效检测出谣言话题下的评论数量。2015年,Ma等[5]提出基于谣言生命周期的时间序列的社交上下文特征,包括微博内容特征、用户特征和传播特征,并采用线性SVM分类器分别在Twitter数据集与DT、随机森林(Random Forest, RF)以及SVM-RBF方法作比较。实验结果表明:该文中提出方法的精确性比DT、RF以及SVM-RBF方法高,且达到与DT、RF以及SVM-RBF相同的精确性的用时最少。2015年,Liu等[6]提出在Twitter上的实时谣言揭露,通过使用“群众智慧”和系统性方法来挖掘语言特征,并采用DT分类器、RF分类器以及SVM分类器进行实验。实验结果表明:该文中提出的方法在事件只有最初的5条Tweets以及最初的一小时内的预测结果都要高于其他方法;而选取两个实时谣言跟踪网站snopes.com和emergent.info与人工验证方法相比,结果显示该方法能将检测延迟减少25%和50%。
与国外相比,国内关于虚假消息检测的研究相对较少。2013年,蒋盛益等[7]对现有成果进行了梳理,总结了这些研究的不足,指出了微博信息可信度分析的关键问题和核心方法,并对未来进行了展望。2013年,贺刚等[8]提出利用符号特征、链接特征、关键词分布特征和时间差等新特征,将微博谣言识别形式化为分类问题,利用SVM分类算法对微博进行分类,识别结果可以辅助识别谣言。2016年,路同强等[9]在分析微博谣言传播特点的基础上,结合微博文本内容、微博用户等方面的特征构建特征集合,将半监督学习算法应用到谣言检测中,以解决人工标注语料代价高昂的问题。2016年,吴树芳等[10]在HITS(Hyperlink-Induced Topic Search)算法的基础上,提出了融合用户交互行为和博文内容的微博用户可信度评估算法,分别构建基于交互行为和基于博文内容的微博用户有向链接图,通过反复训练法获得可信度阈值,绘制不同可信度算法的用户可信度曲线,验证了算法的可行性和有效性。2016年,谢柏林等[11]提出一种基于把关人行为的微博虚假信息及早检测方法。该方法利用模型状态持续时间概率为Gamma分布的隐半马尔可夫模型来刻画信息转发者和评论者对流行的真实信息的把关行为,基于此来及早识别微博上流行的虚假信息。实验结果表明该方法具有较好的性能和较高的在线检测速度。
2 特征选取
微博虚假消息与真实消息的评论存在着很大的差异。在文本内容方面,虚假消息的评论具有语气不确定程度强、消极词汇多、内容与源消息相关程度弱的特点;在用户属性方面,虚假消息的发布者一般是非认证用户,其注册日期比较短、注册地信息不够详细,朋友数量远高于粉丝数量,并且不使用顶级域名;在传播特性方面,网络大V用户对源消息的转发和URL、@、hashtag等符号信息将会影响用户对源消息的信任程度,进而影响微博的转发量;在时间特性方面,距离源微博发布时间越久的微博,其是虚假消息的概率会越小。
基于以上分析,本文中总共选取了11个特征,并将这些特征分为四类:基于文本内容的特征、基于用户的特征、基于信息传播的特征和基于时间的特征。其中, 基于文本内容的特征已在文献[12]中详细介绍,故在此不再多作阐述。表1列出了文中所使用的全部特征,并对特征作了简单的介绍。
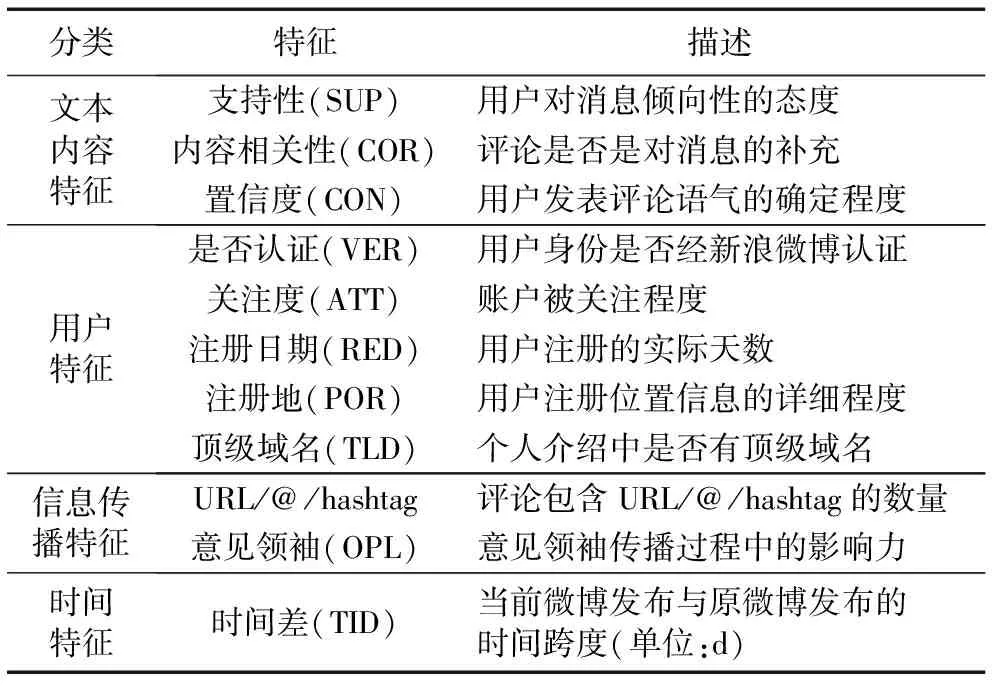
表1 特征及其描述Tab. 1 Features and their description
2.1 关注度特征
微博用户之间存在的关系有两种:关注与被关注。关注其他账户,则此账户为所关注账户的粉丝,可以看到其关注账户发表的博文。两个账户互相关注,两个账户即为朋友关系,都可以看到彼此发表的博文。郭浩等[13]指出, 积极关注别人,保持较高的发文数量,就可以吸引更多的粉丝,获得更高的关注度,使社会化网络媒体营销更加有效。这说明一些在微博上传播虚假消息的账户,可能会关注多个其他账户,以希望这些账户能够关注自己,看到自己发表的博文并传播这些消息,结果表现为朋友数量远远多于粉丝数量。正常用户的朋友和粉丝的数量一般相差不多,其微博上的关注关系一般是现实中朋友关系的映射。因此,将关注度特征计算公式表示如下:
ATTu=FOLu/(FOLu+FRIu)
(1)
其中:FOLu表示用户u的粉丝数量,FRIu表示用户u的朋友数量。正常用户的关注度值要高于虚假消息传播用户的关注度值。
2.2 顶级域名特征
顶级域名是付费服务,它具有易查找、可信度高、独立性等优点,一般来说,只有一些有需要的个人或者是公司才会使用这项服务。而虚假消息传播用户本身是为了盈利,故而只会注册一些免费的账户来传播信息,所以此特征具有明显的区分性。顶级域名特征(TLD)的取值是{0,1},0表示个人介绍中有顶级域名的用户的特征值,1表示个人介绍中无顶级域名的用户的特征值。
2.3 意见领袖特征
王永强[14]指出,所谓意见领袖,指的是人际传播网络中经常为他人提供信息、意见、评论并对他人施加影响的“活跃分子”,是大众传播效果形成过程的中介或过滤环节。意见领袖在信息传播过程中的影响是巨大的。例如,2010年12月6日,微博上爆出金庸先生“去世”的消息,当晚《中国新闻周刊》在官方微博上转发了这则微博,这则消息事后被证实为谣言。但网络大V的转发加速了消息的传播,导致此谣言在数分钟内即被转发近千条。为了衡量意见领袖在传播过程中的影响,本文中将用户分为两类:认证用户和普通用户,主要获取认证用户在传播过程中的影响。由此,将意见领袖特征的计算公式表示为:
(2)
其中:REPver表示通过认证用户微博被转发的数量,REPori表示源消息的转发数量。如果是普通用户,则意见领袖特征为0。
2.4 时间差特征
谣言的传播有四个阶段:潜伏期、变异期、爆发期和消亡期。谣言的爆发期通常时间比较短暂。在谣言微博发布后,随即会出现一系列辟谣的微博,并且其传播要比谣言微博快很多,所以,距离谣言源微博时间越久的微博,它是谣言的概率会越小。根据以上分析,用时间差特征来表示当前评论发布时间距微博源消息发布时间的间隔,其计算公式表示如下:
TIDw=TIMw-TIMm
(3)
其中:TIMw表示当前评论w的发布时间,TIMm表示源消息m的发布时间。时间差特征以天为单位。
2.5 其他特征
是否认证特征(VER)、注册日期特征(RED)、注册地特征(POR)在一定程度上反映了用户的可信度。本文中通过是否认证特征将用户分为两类:认证用户和普通用户。是否认证特征的取值是{0,1},0表示普通用户的特征值,1表示认证用户的特征值。注册日期特征是指用户注册的实际天数,通过计算用户当前评论的发表时间与用户的注册日期的差值来实现。注册地特征衡量用户注册位置信息的详细程度,其取值是{0, 0.5, 1},0表示注册位置信息为空的用户的特征值,0.5表示注册位置信息中只有省份的用户的特征值,1表示注册位置信息中既有省份又有城市的用户的特征值。
3 特征选取
本文在微博消息的评论中提取四个方面的特征,从不同的角度衡量微博虚假消息与真实消息之间的区别。与真实消息相比,在文本内容方面,虚假消息中SUP特征值为负、COR特征值较低、CON特征值较低的评论更多;在用户属性方面,虚假消息的发布者一般是VER特征值为0,且ATT特征值较低、RED特征值较低、POR特征值较低、TLD特征值为0;在传播特性方面,虚假消息的评论中URL、@、hashtag特征值较低,OPL特征值较低;在时间特性方面,虚假消息中TID特征值较小的评论更多。特征提取的目的是为了分析影响类别之间差异的主要因素。
微博虚假消息识别问题,可以看作一个分类问题。在数据量较大的情况下,需要选择一个分类速度高且准确率也高的模型。因此本文中选用GBDT算法,它是由Friedman[15]提出的组合决策树模型,是一种由多个弱分类器经过多次迭代形成的强分类器。与传统Boosting算法(如Adaboost)不同的是,GBDT算法的基分类器是回归树,其迭代的目的是通过计算上一次模型的负梯度来改进模型,然后在残差减少的梯度方向上建立新的决策树;Adaboost算法通过简单地调整正确、错误样本的权重来改进模型,二者有本质区别。
现给定微博数据样本{(xi,yi)}(i=1,2,…,n)。由于虚假消息识别是一个分类过程,故采用对数损失函数,即:
(4)
其中:xi=(x1i,x2i,…,xqi),n为样本的数量,q为虚假消息识别中特征的数量,yi为样本的实际标签,pi为样本的预测标签。GBDT算法的详细步骤如下:
1)初始化模型,估计使损失函数最小化的常数值β:
(5)
2)在上一次模型损失函数的梯度下降方向上建立模型,从m=1到M(M为迭代次数):
①计算损失函数的负梯度在当前模型的值,将它作为残差rim的估计值:
(6)
②将①中得到的估计残差作为输入,拟合一棵回归树,求得回归树的叶节点区域Rj,m(j=1,2,…,J)。
③为使损失函数极小化,对于j=1,2,…,J,求得沿梯度下降方向的最优步长βjm:
(7)
④更新模型Fm(x):
(8)
3)迭代结束,得到模型FM(x):
(9)
4)根据得到的模型,估算样本预测为正类的概率p+(x)和预测为负类的概率p-(x):
(10)
5)据以下准则预测样本标签y(x),其中c(-1,1)是代价函数,表示当真实类别为1,预测类别为-1时的代价:
y(x)=2*l{c(-1,1)p+(x)>c(1,-1)p-(x)}-1
(11)
其中:l{}是将布尔值转换为{0,1}函数。
4 实验结果与分析
4.1 实验数据
本文实验数据集有两个:数据集1选自文献[16],其数据采集自新浪微博社区管理中心和新浪微博API接口,总共包含2 313个谣言和2 351个非谣言,内容包括旅游、球赛、娱乐、生活、常识等话题。数据集2是在文献[17]中数据集的基础上,采集新浪微博社区管理中心中的不实信息作为谣言数据,然后在新浪微博上爬取与谣言微博具有相同时间跨度的微博作为非谣言数据,保留原微博字数超过10,评论数超过200条的微博。处理后的数据集2总共包含447个谣言和455个非谣言,内容主要是2013年和2014年的热点新闻。两个数据集的统计情况见表2。相比数据集2,数据集1包含的特征的相关信息更多,本文在数据集1中提取了表1中介绍的所有特征;而数据集2则缺少表1中某些特征的相关信息,最终在数据集2中提取了SUP、COR、CON、URL、@、hashtag和TID特征。本文中提出的虚假消息识别模型是一个综合模型,如果需要针对具体某个事件进行识别,可以结合本文中的模型,并使用和事件本身相关的特征进行识别。实验按照8∶2的比例随机划分数据集,即数据集的80%作训练集,余下20%作测试集,均采用十折交叉验证。
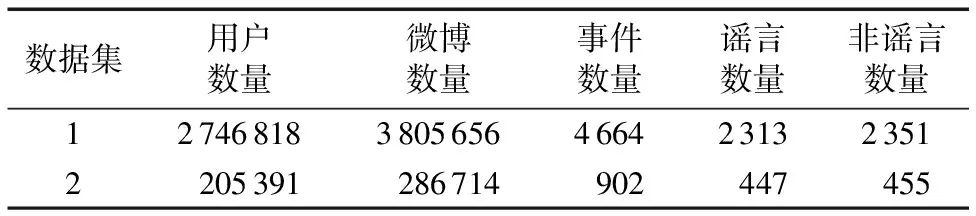
表2 数据集的统计情况Tab. 2 Statistics of the data set
4.2 特征归一化
从评论中提取的特征如果直接用于分类,其相差过大的权重范围将会影响分类器的准确性。为此,对特征进行归一化处理是十分有必要的。本文使用式(12)对特征进行归一化处理,归一化后特征权重限定在[0,1]区间,可以消除离群数据对分类的影响,也可以使计算过程收敛得更快。
(12)
其中:min(x.j)表示第j列特征权重的最小值,max(x.j)表示第j列特征权重的最大值。
4.3 评价指标
为了评测微博虚假消息检测的结果,本文选用查准率(P)、查全率(R)以及F1值作为评价标准。
P=TP/(TP+FP)
(13)
R=TP/(TP+FN)
(14)
F1=2PR/(P+R)
(15)
其中:TP是被正确判别为谣言的微博数,FP是被错误判别为谣言的微博数,FN是被错误判别为非谣言的微博数。另外,为了衡量总体的分类效果,采用下面的公式计算总体分类正确率:
Acc=识别正确的微博数/总微博数
(16)
4.4 结果分析
微博虚假消息的评论存在着语气不确定程度强、消极词汇多、重复源消息等的特点。基于此,通过统计微博消息中被模型判定为虚假消息评论的比例,可以得到一个阈值,当微博消息中的虚假评论达到这个阈值的时候,则此微博被判定为虚假消息。
为了比较不同分类器分类的结果,本文选择Castillo等[2]使用的J48决策树分类器、 Yang等[3]使用的SVM分类器以及Kwon等[18]使用的RF分类器。其中,SVM核函数选择径向基核函数(Radial Basis Function, RBF),使用LIBSVM[19]中的grid来寻找最优的参数c和γ。
4.4.1实验阈值
实验以正确率Acc为基准,使用不同分类器获得使正确率Acc最高的阈值,称为最佳阈值,它可以最好地将虚假消息与真实消息区分开。两个数据集的最佳阈值统计结果如表3所示。
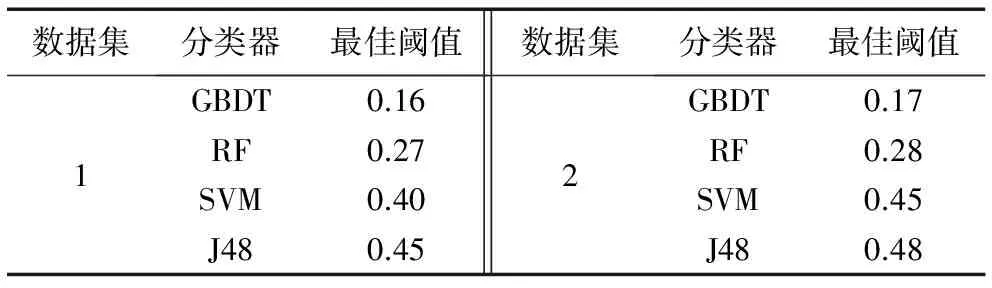
表3 数据集的最佳阈值Tab. 3 The best threshold of the data sets
4.4.2特征重要性
为了验证特征在分类过程中的影响,以正确率Acc为基准,用GBDT分类器的默认参数来对不同的特征进行训练,数据集1使用表1中的全部特征,数据集2使用SUP、COR、CON、URL、@、hashtag和TID特征,两个数据集的训练结果如表4所示。其中,特征前面的“-”符号表示不包括该特征的特征集,Acc中的“—” 表示实验没有使用该特征集。
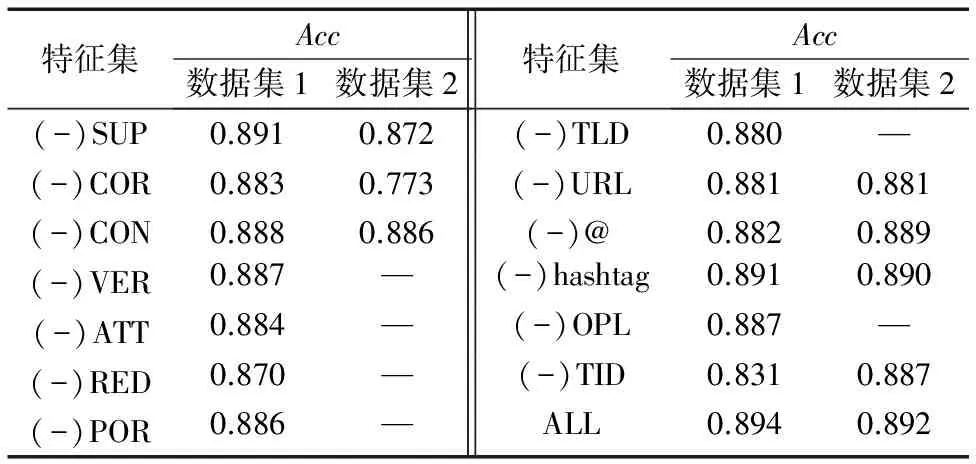
表4 不同特征对分类的影响Tab. 4 Influence on classification with different features
从表4中可以明显看出,实验中用到的所有特征都有助于提升微博虚假消息的检测效果。其中,数据集1使用所有特征(ALL)的正确率Acc是0.894,高于数据集2(0.892)。这是因为数据集1使用了表1中的全部特征,数据集2只使用表1中的部分特征。在数据集1中,时间差特征(TID)和注册日期特征(RED)对总体分类结果影响是最大的;在数据集2中,内容相关性特征(COR)和支持性特征(SUP)对总体分类结果影响是最大的。这是因为数据集1中的话题,例如生活、常识等,其讨论的时间会比较长,所以在数据集1中,关于时间特征的重要性会比较高;数据集2的话题是热点新闻,其评论内容比数据集1更加规范,所以在数据集2中,起重要作用的主要是基于文本内容的特征,而新闻的时效一般都比较短,故时间差特征(TID)在数据集2中体现的重要性没有在数据集1中的重要性高。
4.4.3分类结果
为了便于比较,实验将GBDT、RF、J48中决策树的最大深度统一设定为15,SVM核函数选择RBF,使用LIBSVM寻找最优的参数c和γ。两个数据集的实验结果如表5所示。其中,F表示虚假消息,T表示真实消息。
从表5中可以看出,GBDT分类器的正确率Acc要明显高于SVM和J48。这是因为GBDT是一种由多个弱分类器形成的强分类器,其效果要好于单一的分类器;GBDT分类器的分类效果要好于RF, 这是因为GBDT的输出是所有结果的累积,RF采用多数投票原则决定最终结果,且RF训练调参时依赖于决策树的最大深度,而GBDT只需很小的深度就可以达到很高的精度,实验中为了提高分类速度,没有给RF增大深度。数据集1中GBDT分类器的正确率Acc要高于数据集2中GBDT分类器的Acc,因为数据集1中使用了表1中的全部特征,数据集2只使用表1中的部分特征,且数据集1比数据集2数据量大,故分类模型加精确。

表5 不同分类器的分类结果Tab. 5 Classification results of different classifiers
5 结语
本文从微博评论的角度在文本内容、用户属性、信息传播和时间特性四个方面分析影响分类的因素并提取分类特征,并基于GBDT算法设计微博虚假消息识别模型。通过在两个微博数据集上的对比实验分析可以看到,模型在数据集1上的实验结果要好于在数据集2上的实验结果;在数据集1中,起主要作用的是基于时间的特征,在数据集2中,起主要作用的是基于文本内容的特征。两个数据集上的实验均表明,本文提出的基于GBDT的方法能够有效提高微博虚假消息检测的准确率。
但是,微博虚假消息检测的价值体现在能够及早地发现并处理,以减少对社会的危害。因此,下一步的工作重点是通过借助传播模型以及消息传播过程中用户的认知与识别能力,综合更复杂的特征来构建合适的模型,实现实时检测微博虚假消息的目的。
参考文献:
[1]中国互联网络信息中心.中国互联网络发展状况统计报告[R].北京:中国互联网信息中心,2017. (China Internet Network Information Center (CNNIC). Statistical report on Internet development in China [R]. Beijing: China Internet Network Information Center, 2017.)
[2]CASTILLO C, MENDOZA M, POBLETE B. Information credibility on twitter [C]// WWW ’11: Proceedings of the 20th International Conference on World Wide Web. New York: ACM, 2011: 675-684.
[3]YANG F, LIU Y, YU X, et al. Automatic detection of rumor on Sina Weibo [C]// MDS ’12: Proceedings of the 2012 ACM SIGKDD Workshop on Mining Data Semantics. New York: ACM, 2012: Article No. 13.
[4]DAYANI R, CHHABRA N, KADIAN T, et al. Rumor detection in Twitter: an analysis in retrospect [C]// ANTS 2015: Proceedings of the 2015 IEEE International Conference on Advanced Networks and Telecommuncations Systems. Piscataway, NJ: IEEE, 2015: 1-3.
[5]MA J, GAO W, WEI Z, et al. Detect rumors using time series of social context information on microblogging websites [C]// CIKM ’15: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. New York: ACM, 2015: 1751-1754.
[6]LIU X, NOURBAKHSH A, LI Q, et al. Real-time rumor debunking on twitter [C]// CIKM ’15: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. New York: ACM, 2015: 1867-1870.
[7]蒋盛益,陈东沂,庞观松,等.微博信息可信度分析研究综述[J].图书情报工作,2013,57(12):136-142. (JIANG S Y, CHEN D Y, PANG G S, et al. Research review of information credibility analysis on microblog [J]. Library and Information Service, 2013, 57(12):136-142.)
[8]贺刚,吕学强,李卓,等.微博谣言识别研究[J].图书情报工作,2013,57(23):114-120. (HE G, LYU X Q, LI Z, et al. Automatic rumor identification on microblog [J]. Library and Information Service, 2013, 57(23):114-120.)
[9]路同强,石冰,闫中敏,等.一种用于微博谣言检测的半监督学习算法[J].计算机应用研究,2016,33(3):744-748. (LU T Q, SHI B, YAN Z M, et al. Semi-supervised learning algorithm applied to microblog rumors detection [J]. Application Research of Computers, 2016, 33(3): 744-748.)
[10]吴树芳,徐建民.基于HITS算法的微博用户可信度评估[J].山东大学学报(工学版),2016,46(2):1-7. (WU S F, XU J M. Evaluation of microblog users’ credibility based on HITS algorithm [J]. Journal of Shandong University (Engineering Science), 2016, 46(2): 1-7.)
[11]谢柏林,蒋盛益,周咏梅,等.基于把关人行为的微博虚假信息及早检测方法[J].计算机学报,2016,39(4):730-744. (XIE B L, JIANG S Y, ZHOU Y M, et al. Misinformation detection based on gatekeepers’ behaviors in microblog [J]. Chinese Journal of Computers, 2016, 39(4): 730-744.)
[12]段大高,王长生,韩忠明,等.基于微博评论的虚假消息检测模型[J].计算机仿真,2016,33(1):386-390. (DUAN D G, WANG C S, HAN Z M, et al. A rumor detection model based on Weibo’ reviews [J]. Computer Simulation, 2016, 33(1): 386-390.)
[13]郭浩,陆余良,王宇,等.多特征微博垃圾互粉检测方法[J].中国科技论文,2012,7(7):548-551. (GUO H, LU Y L, WANG Y, et al. Detection of spam mutual concerns in micro-blogs based on multi-features [J]. China Sciencepaper, 2012, 7(7): 548-551.)
[14]王永强.微博“意见领袖” 少数派的权利[N].中国经营报,2011- 09- 19 (C05). (WANG Y Q. Micro-blog “opinion leaders” the minority’ rights [N]. China Business Journal, 2011- 09- 19 (C05).)
[15]FRIEDMAN J H. Greedy function approximation: a gradient boosting machine [J]. The Annals of Statistics, 2001, 29(5): 1189-1232.
[16]MA J, GAO W, MITRA P, et al. Detecting rumors from microblogs with recurrent neural networks [C]// IJCAI 2016: Proceedings of the 25th International Joint Conference on Artificial Intelligence. London: dblp Computer Science Bibliography, 2016: 3818-3824.
[17]JIN Z, CAO J, JIANG Y-G, et al. News credibility evaluation on microblog with a hierarchical propagation model [C]// ICDM ’14: Proceedings of the 2014 IEEE International Conference on Data Mining. Washington, DC: IEEE Computer Society, 2014: 230-239.
[18]KWON S, CHA M, JUNG K, et al. Prominent features of rumor propagation in online social media [C]// ICDM 2013: Proceedings of the 2013 IEEE 13th International Conference on Data Mining. Piscataway, NJ: IEEE, 2013: 1103-1108.
[19]CHANG C-C, LIN C-J. LIBSVM: a library for support vector machines [J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2011, 2(3): Article No. 27.
猜你喜欢
环球时报(2022-04-13)2022-04-13
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
科学大众(2020年12期)2020-08-13
凯里学院学报(2020年3期)2020-06-28
电子技术与软件工程(2019年18期)2019-11-18
民生周刊(2017年22期)2017-12-12
电子技术与软件工程(2017年14期)2017-09-08
新高考·高一数学(2016年10期)2017-07-06
课程教育研究·新教师教学(2016年18期)2017-04-12
