
基于机器学习的日志解析系统设计与实现
2018-04-12 05:51郭渊博
计算机应用 2018年2期
钟 雅,郭渊博
(1.信息工程大学 网络空间安全学院,郑州 450001; 2.数学工程与先进计算国家重点实验室,郑州 450001)(*通信作者电子邮箱1183316762@qq.com)
0 引言
为了保证系统与系统信息安全,日志几乎内建于所有的系统中,它被用于记录系统运行时产生的信息,如日常操作、网络访问、系统警告、系统错误等事件的相关属性与信息。这些信息对了解系统的运行情况起着非常重要的作用,因此常用于异常检测。随着计算机系统规模与复杂性的增长,日志数量随之增加,开发者或维护者能够根据丰富的日志信息监视系统运行时的行为,并以此进一步跟踪寻找系统异常问题的源头;但是由于计算机系统庞大,并且大多数系统日志是非结构化的原始文本,当实际问题出现时,面对这些规模庞大的日志数据,测试者往往束手无策。如何在最短时间内高效又精准地对海量日志数据进行解析并提取有用信息成为一个亟待解决的重要问题[1]。
近年来,日志解析得到了越来越多的关注与快速发展[2]。在传统的日志解析方法中,开发者通常根据自己的认知手动检查系统问题或者创建正则表达式来定期维护,但是,这类方法对专家经验知识依赖性强,通常不具备从历史经验中主动学习知识的能力,当新的格式日志出现时,解析规则很容易就变得过时,因此,灵活多变的自动日志解析方法成为一种需求。近些年,越来越多的研究者致力于对日志进行自动化解析。Nagappan等[3]提出了一种具有线性运行时间与空间的离线日志解析方法;Prewett[4]提出了一种基于规则的方法处理控制台日志;薛文娟[5]提出了一种基于层次聚类的日志分析方法;马文等[6]设计了一种基于频繁模式增长(Frequent Pattern-Growth, FP-Growth)算法的安全日志分析系统。但是这些方法仍存在如下缺陷:1)只适用于严格的格式化、结构化日志,其性能严重依赖日志信息的格式与结构特征;2)依赖于源程序对日志文本的约束,适用性不强;3)日志格式的非结构性导致解析精度不高;4)对日志管理员要求较高,相关规则需要日志管理员预先写成脚本,管理员需要对系统或者代码有深刻的理解,否则难以写出有效的脚本。
针对以上问题,主要有两种主流日志解析方法:基于聚类的方法和基于启发式的方法。基于聚类的日志解析方法以日志关键字提取(Log Keywords Extraction, LKE)和LogSig(Log Signature)为典型代表[7]。它们首先计算日志之间的距离,然后采用聚类技术组成不同的日志集群(簇),最后,事件模板从每一个集群(簇)中生成。基于启发式的日志解析方法则以简单日志聚类工具(Simple Log Clustering Tool, SLCT)为典型代表。每一个日志位置的每个项被计数,然后选择出现频繁的项来组成事件候选者,最后,候选者被选择作为日志事件。以上两种方法中,LKE方法因为其自身特点不能应用于数据量较大的处理任务中;SLCT虽然也能实现高解析精度,但是在系统异常问题检测时,它处理的解析结果通常会带来更多的错误警报。
本文主要结合LogSig算法相关理论知识,设计并开发了一个可从非结构原始日志文本中生成系统日志事件的日志解析系统。该系统包括原始数据预处理、日志解析、聚类分析评价和聚类结果散点图显示四大功能,系统处理的结果可转换为日志数据挖掘任务与网络入侵检测所需的日志事件序列。该系统在VAST 2011挑战赛的开源防火墙日志数据集上进行了测试,结果显示其日志解析平均精度可达85%以上。实验表明,对原始LogSig算法增加数据预处理步骤后,与原始LogSig算法相比,解析精度提高了60%;同时,通过与聚类结果评价模块相结合,用户能够更加直观地观察本系统日志解析效率。
1 日志解析系统
1.1 日志解析
日志是由不变部分与可变部分组成的纯文本,大多数系统日志是非结构化的原始文本。日志解析的主要目的是把原始日志文本中的不变部分从可变部分分离出来并形成一个良好的结构化日志事件。图1为日志解析的一个实例。

图1 日志解析实例Fig. 1 Example of log parsing
1.2 聚类分析
聚类分析又称群分析,是一种无监督学习方法。它按照事物的某种属性,将一组样本对象划分成簇,使簇内样本对象具有尽可能高的相似性,而簇间对象具有尽可能小的相似性。其主要目的是将若干无标记对象进行划分,使之成为有意义的聚类。聚类分析预先不知道目标数据集存在多少类,需要以某种距离度量为基础,对所有的对象进行聚类,使得同一聚类之间距离最小,而不同聚类之间距离最大。聚类分析可在几乎无任何相关数据先验信息可用的情况下分析数据点的内在关系以作进一步研究。如图2中以二维空间的来表示样本对象,图2(a)表示的是一组输出对象,图2(b)则是所期望的聚类。
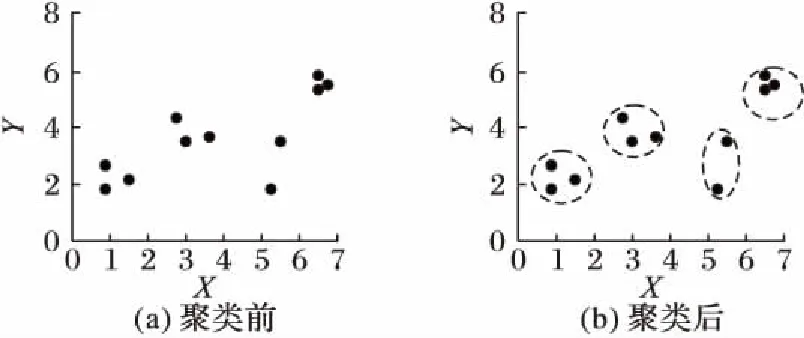
图2 聚类示例Fig. 2 Example of clustering
1.3 聚类结果评估
聚类评价包括聚类过程评价和聚类结果评价两个方面。前者主要考察聚类算法的属性,后者只需要考虑给定的聚类结果是否合理与有效。一般比较常见的聚类结果评价(聚类评价指标)分为外部度量、内部度量和相对度量三大类。内部度量利用数据集的固有特征和量值来评价聚类算法结果,通常用于数据集结构未知、无标签的聚类评价;相对度量侧重于聚类算法的有效性。本文中数据集结构已知,且侧重聚类算法的精度,故采用外部度量作为聚类评价指标。外部度量假设聚类算法的结果是基于一种人工预先指定的结构,这种结构反映了人们对数据聚类结构的一种直观认识,对每个数据项进行人工标注,聚类结果与人工越吻合越好。外部度量的常用指标有F_measure和Rand index。
1.4 LogSig日志解析算法
LogSig日志解析算法由Tang等[7]提出,其目的主要是选取文本日志信息中具有代表性的签名组成系统事件模板,进而将日志分成不同类。算法能处理各种类型的日志数据,并实现较高的解析精度。
2 日志解析系统设计
基于规则匹配的方法是最常见的日志解析方法[8-9],操作者主要通过正则表达式从日志中提取模式,而后对抽取模式进行简单的分类。此类系统维护较为困难,但相比传统文本模式,它在一定程度上提高了解析效率与精度。研究发现,LogSig算法并没有明确原始日志文本的处理,这样导致日志项对生成与遍历日志项对的时间开销较大;同时,日志信息中个别无关日志项会影响日志分类,降低日志解析精度。
因此,本文考虑将模式匹配与LogSig算法相结合,在其基础上基于机器学习原理进行扩展,改进日志解析算法,增加数据预处理功能和聚类结果评价,并设计开发了一个日志解析系统。为了便于用户使用与后期维护,该系统分为原始数据预处理模块、日志解析模块、聚类结果评价模块和聚类结果散点图模块,它们的主要功能如下:
1)数据预处理模块主要对原始日志数据进行相关处理以提高解析效率与精度;
2)日志解析模块主要实现LogSig算法,完成日志项对生成、日志聚类和日志模板生成;
3)聚类结果评价模块则利用聚类的评估指标精度(Precision)、F_measure、Rand index对本系统功能进行评估;
4)聚类结果散点图模块则采用散点图形式直观反映日志解析的外部度量参数。
2.1 数据预处理模块
数据预处理是数据挖掘前的准备工作,它既能保证挖掘数据的有效性和正确性,又能通过对数据格式和内容进行调整,从而使数据更符合挖掘的需要[10]。其主要任务是根据背景知识中的约束性规则对数据进行检查,通过清理和归纳等操作,生成供数据挖掘算法使用的目标数据。
随着存储技术的发展,收集到的日志与实际有效日志之间的矛盾日渐突出;同时,未处理的原始日志必然导致日志解析代价增加,因此,本文将数据预处理与LogSig算法相结合。数据预处理模块是提高解析精度的关键,也是本文系统的创新点。
2.1.1位置固定无关项的去除
原始日志数据中通常有一些固定不变的项,且它们在每条日志中出现的位置一样,如日志数据集中代表日志产生日期的2011- 04- 14;或者虽然变化,但是属性一样,如08:00:00与08:00:06虽然不同但都是时间。这些项不仅对日志分类没有帮助,而且会造成代价的增加。
2.1.2位置不定无关项的去除
日志中还有一些项,它们的属性一样,但是出现位置并不固定,因此不能通过去除位置固定无关项的方法去除,如IP地址、端口号等。所以,本文考虑通过拆分每一条日志,利用匹配子串的原理采用正则表达式来去除。
2.2 日志解析模块
日志解析模块是本系统的核心部分,也是主要难点。一个好的同类事件评判标准往往能达到一个好的聚类结果。该模块采用具体函数值作为评判划分同一类事件的衡量标准,通过不断迭代提高分类精确度。基本步骤包括项对的生成、日志聚类以及日志事件模板的生成。
2.2.1项对的生成
日志以空格为拆分符可拆分成N个字符串,每一个字符串为日志的一个项,每两个项组成一个项对,一条日志的所有项对为第1项依次与后面的第2,3,…,N项组合为N-1个项对(1,2)、(1,3)、(1,4)、…、(1,N),第2项依次与后面的第3,4,…,N项组合为N-2个项对(2,3)、(2,4)、(2,5)、…、(2,N),……,第N-1项与后面的第N项组合为1个项对(N-1,N)。
将每条日志信息转换成多组项对。具体来说,基于预处理部分每条日志,文中采用遍历方式,日志中每两个项组成一个项对。
2.2.2日志聚类
日志聚类是日志解析的核心步骤。聚类的目的是将原始日志文本中同一类日志事件分为一类,从而用一个日志事件模板来描述它。查阅相关文献发现,机器学习中聚类方法的中心思想能满足本文研究的需求(详见本文1.2节)。根据聚类算法原理,首先将原始日志分成k组,然后基于日志的项对,计算每条日志从一个组到另一个消息组后的潜在函数的值,其计算公式为:
(1)
其中:在日志文本C中,对于一个项对r∈R(C),N(r,C)指的是C中包含项对r的日志数量,p(r,C)=N(r,C)/|C|表示在C中含有项对r的日志部分所占比率。
通过比较当前日志移动前后潜在函数的值以确定日志是否移动,若函数值增大,则更新日志分组消息,通过不断迭代,选择更大的潜在函数值,直到最后一次迭代中,没有任何一条日志有日志潜在值的增加,则可将当前分组确定为日志事件归类的最终分组。
2.2.3日志事件模板生成
消息签名是在每组中每条日志都具有高匹配得分的序列项。日志事件模板生成操作中,首先需要构建日志信息签名。具体实现方法为:保存日志信息划分组中每条日志每个项出现的频率,选择每组中出现次数超过一半的项作为候选项,即消息签名;然后,将每条日志中含有的候选项组成日志事件候选,每组中出现频率最高的日志事件候选为当前组的最终日志事件模板输出。
2.3 聚类结果评价模块
聚类的典型形式化目标函数是为了实现高的集群(簇)内相似性(群(簇)内的文件是相似的)和低的集群(簇)间相似性(不同集群的文件不一样)。这是聚类质量的一个内部标准,但良好的内部标准分数并不一定是转化成应用中良好效果的必要条件。内部标准的另一种选择是直接评估应用程序的利益。最直接的聚类搜索结果评估方法就是衡量用户采用不同聚类算法找到答案所花费的时间,但它的花费很大,特别是在需要大量研究时更为突出。
因此,在聚类结果评价模块采用外部度量作为聚类评价指标,这里主要选取:准确率(Precision)、综合评价标准F_measure和Rand index。本文实验中通过运行程序50次来避免聚类自身性质带来的误差。
2.3.1Precision
准确率是检索出的相应文档占检索出的总文档数量的比率,衡量的是系统的查准性。采用信息检索与统计学分类的准确率与召回率(Recall)思想,数据所属的类t可以看作集合Nt中等待查询的项,Nk是簇Ck的大小,Ntk是簇中类t的数量[11]。对于类t与簇Ck的准确率计算公式如下:
Precision(t,Ck)=Ntk/Nk
(2)
结合本文研究的任务要求,此处将其转化为:
Precision=TP/(TP+FP)
(3)
其中:TP(True Positive)为被正确划分正例的个数,即两个相似样本划分到同一集群(簇);FP(False Positive)为被错误划分为正例的个数,即两个不同样本划分到同一集群(簇)。
2.3.2F_measure
簇索引与统计任务中,准确率与召回率越高越好,但是两者通常情况下是相互矛盾的,这就需要综合考虑它们,最常见的方法就是F_measure,它是Precision与Recall的加权调和平均[12]。其计算公式如下:
(4)
其中Recall的计算公式为:
Recall(t,Ck)=Ntk/Nk
(5)
同样按任务要求可转换为:
Recall=TP/(TP+FN)
(6)
其中,FN(False Negatives)为被错误划分为负例的个数即两个相同样本划分到不同集群(簇)。
2.3.3Rand index
Rand index[13]通常用来衡量聚类结果与样本数据外部标准类之间的一致程度,其计算公式如下:
Rand_index=(TP+TN)/(TP+FP+TN+FN)
(7)
其中,TN(True Negatives)为被正确划分为负例的个数,即两个不同样本划分到不同集群(簇)。Rand_index范围为[0,1],其数值越大,代表两种划分的一致性越高,聚类准确性越高,聚类结果与真实情况越吻合。
2.4 聚类结果散点图模块
为了更加直观地展示系统对日志解析任务的解析精度,本文设计了聚类结果散点图模块。该模块主要调用python matplotlib模块相关函数来显示解析后的Precision、F-measure与Rand index的散点图,X轴为当前实验次数,Y轴为本次实验的Precision、F-measure与Rand index。
3 系统测试
本章主要对系统结果进行定向分析,采用anaconda运行系统,利用VAST 2011挑战赛的开源防火墙日志数据集分析数据预处理部分的划分簇数、正则表达式对日志解析精度的影响。
3.1 平均解析精度
实验分别采用包含400,800,1 200条日志的三个样本数据进行实验,测量50次解析任务后的平均Precision、F_measure以及Rand index,结果如图3和表1所示。
图3显示,在本组实验中,聚类评价值数据较为集中,且基本都在85%以上。表1数据显示,不管日志数量大小,无论是使用分类指标Precision还是聚类指标F_measure、Rand index衡量,日志解析系统50次实验的平均解析精度均能达到90%以上。
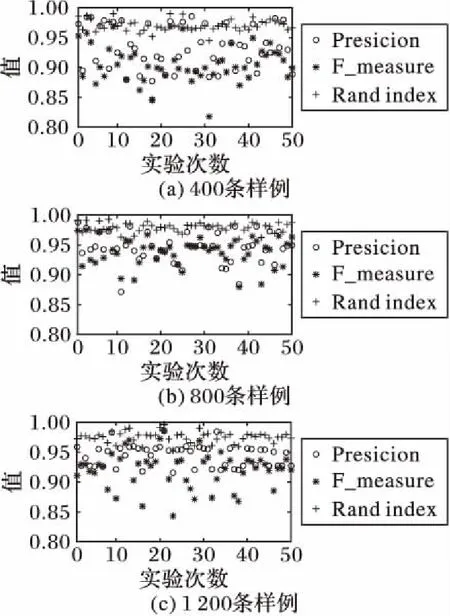
图3 不同日志数量样例实验结果Fig. 3 Experimental results of different number of log samples
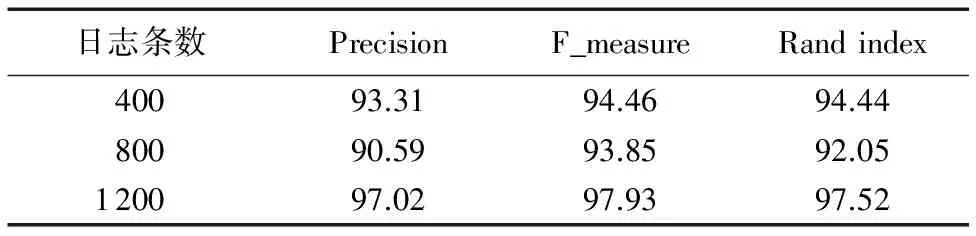
表1 50次实验的平均日志解析准确率 %Tab. 1 Average log parsing accuracy of fifty experiments %
3.2 划分簇数对聚类结果的影响
划分簇的大小决定最终日志事件模板的个数,本文通过分析真实事件个数为14的400条日志样例,分别设置明显少于真实事件个数(6)、明显高于真实事件个数(26)以及接近真实事件个数(16)的划分簇数,而其他参数项相同来研究划分簇数对解析精度F_measure、Precision、Rand index的影响。表2为不同划分簇下的平均评价。
表2数据显示,划分簇数会影响日志解析精度,尤其是当事件个数明显小于真实事件个数时,日志解析精度相比接近事件真实值的划分簇数,其三项指标Precision、F_measure、Rand index都有明显降低。日志事件明显大于真实日志事件个数时,日志的解析精度相比接近事件真实值的划分簇数的精度Precision有些许升高,这是因为随着日志事件个数的增加,同一类事件分到同一个划分簇的几率加大;但是其F_measure、Rand index都有所降低,总体而言三项指标差距不是很大。通过比较解析运行时间发现,划分簇数为26时,其平均运行时间为划分簇数为16时运行时间的1.4倍。这是因为当日志事件个数增加时,其用于日志聚类过程的花费将相应增加。所以,综合以上结果,划分簇数接近真实事件个数时能得到最好的实验效果。
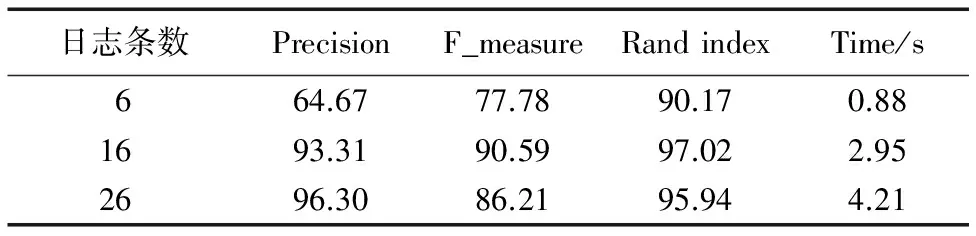
表2 不同划分簇数对日志聚类结果的影响 %Tab. 2 Impact of different cluster numbers on log clustering results %
3.3 正则表达式对聚类结果的影响
正则表达式是数据预处理部分最关键的一个步骤,通过分析有无正则表达式对400条日志样例解析任务的F_measure、Precision、Rand index的影响来进行讨论。表3为有无正则表达式以及正则表达式是否合适的实验结果。从表3实验结果来看,数据预处理过程中正则表达式的选择至关重要,不应该选择日志中的敏感词作为正则表达式匹配的对象,而应该选择与其无关的词作为匹配规则匹配对象,这样才能达到显著提高解析精度的目的。
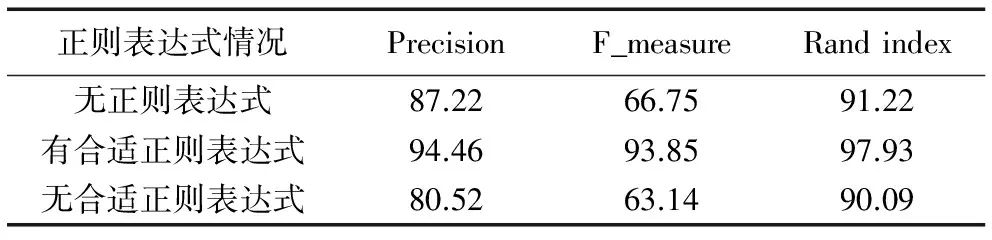
表3 有无正则表达式对日志聚类结果的影响 %Tab. 3 Impact on log clustering results with or without regular expression %
3.4 日志大小对解析时间的影响
最后,通过对比100,101,102,103,104,105KB大小日志数据的解析运行时间来讨论日志大小对本文系统运行时间的影响,结果如图4所示。从图4可以看出,日志解析运行时间随着日志大小的增加而增加,并且增长幅度逐渐增加,这主要是因为日志大小影响聚类的时间复杂度。这也为本文系统的后期优化提供了一个方向。
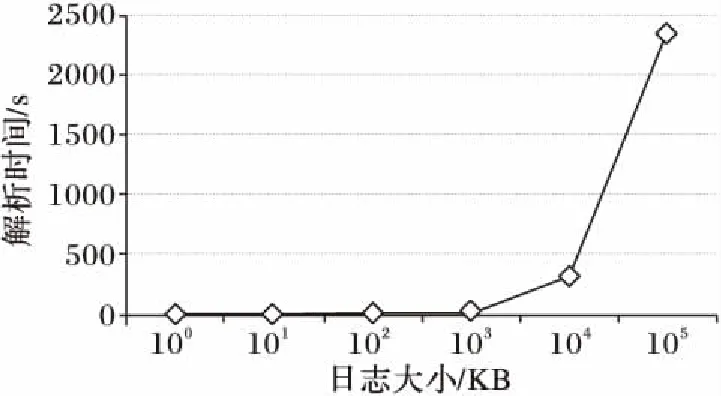
图4 日志大小对日志解析运行时间的影响Fig. 4 Impact of log size on parsing runtime
3.5 本文算法与原始LogSig算法对比
原始LogSig算法没有明确提出预处理部分的具体设计,本文采用真实事件个数为14的400条日志样例,通过设置有无、预处理部分的日志解析任务来进行对比,结果如表4所示。由表4可以看出,通过关联规则与LogSig相结合,本文系统比原LogSig算法的各项指标值都有所提高,综合评价参数F_measure提高了60%;同时,系统运行时间大大减少,仅为原先的25%,提高了解析效率。

表4 本文系统与原始LogSig算法对比Tab. 4 Comparsion of the proposed algorithm and original LogSig algorithm
4 结语
计算机系统的发展、日志数量的增加以及日志在各类数据挖掘任务中起到的作用使得自动化日志解析成为一种必然趋势[14]。目前,日志的处理方式多种多样,但是缺乏一个系统性的处理平台。本文主要设计开发了一个日志解析系统,它能高效快速地从日志文本中解析出日志事件,系统实现了原始数据预处理、日志解析、聚类分析评价和聚类结果散点图显示四大功能,集数据处理与结果分析于一体,提供了更好的用户体验。通过VAST 2011挑战赛的开源防火墙日志数据集验证了系统的可行性,并分析了数据预处理部分的划分簇数、正则表达式对日志解析精度的影响。实验中也发现,日志大小会影响聚类的时间复杂度,因此在接下来的工作中可考虑实现程序运行的并行性等。目前该系统聚类的簇数是基于小型数据集实验得到的,后续研究可以考虑结合自适应的聚类算法以提高系统性能。
参考文献(References)
[1]张宏鑫,盛风帆,徐沛原,等.基于移动终端日志数据的人群特征可视化[J].软件学报,2016,27(5):1174-1187. (ZHANG H X, SHENG F F, XU P Y, et al. Visualizing user characteristics based on mobile device log data [J]. Journal of Software, 2016, 27(5): 1174-1187.)
[2]廖湘科,李姗姗,董威,等.大规模软件系统日志研究综述[J].软件学报,2016,27(8):1934-1947. (LIAO X K, LI S S, DONG W, et al. Survey on log research of large scale software system [J]. Journal of Software, 2016, 27(8): 1934-1947.)
[3]NAGAPPAN M, WU K, VOUK M A. Efficiently extracting operational profiles from execution logs using suffix arrays [C]// Proceedings of the 2009 International Symposium on Software Reliability Engineering. Piscataway, NJ: IEEE, 2009: 41-50.
[4]PREWETT J E. Analyzing cluster log files using Logsurfer [C]// Proceedings of the 4th Annual Linux Showcase & Conference. Atlanta: [s.n.], 2003: 169-176.
[5]薛文娟.基于层次聚类的日志分析技术研究[D].济南:山东师范大学,2013. (XUE W J. Research on log analysis technology based on hierarchical clustering [D]. Jinan: Shandong Normal University, 2013.)
[6]马文,朱志祥,吴晨,等.基于FP-Growth算法的安全日志分析系统[J].电子科技,2016,29(9):94-97. (MA W, ZHU Z X, WU C, et al. Security log analysis system based on FP-Growth algorithm [J]. Electronics Technology, 2016, 29(9): 94-97.)
[7]TANG L, LI T, PERNG C S. LogSig: generating system events from raw textual logs [C]// Proceedings of the 2011 ACM International Conference on Information and Knowledge Management. New York: ACM, 2011: 785-794.
[8]XU W, HUANG L, FOX A, et al. Detecting large-scale system problems by mining console logs [C]// SOSP 2009: Proceedings of the 2009 ACM Symposium on Operating Systems Principles. New York: ACM, 2009: 117-132.
[9]周平,马斌,韩冰,等.基于大数据平台的日志分析预警技术研究[J].电脑知识与技术,2016,12(32):266-268. (ZHOU P, MA B, HAN B, et al. Research on log analysis and early warning technology based on large data platform [J]. Computer Knowledge and Technology, 2016, 12(32): 266-268.)
[10]袁汉宁,王树良,程永,等.数据仓库与数据挖掘[M].北京:人民邮电出版社,2015. (YUAN H N, WANG S L, CHENG Y, et al. Data Warehouse and Data Mining [M]. Beijing: People’s Posts and Telecommunications Press, 2015: 31-34.)
[11]张惟皎,刘春煌,李芳玉.聚类质量的评价方法[J].计算机工程,2005,30(20):10-12. (ZHANG W J, LIU C H, LI F Y. Evaluation method of clustering quality [J]. Computer Engineering, 2005, 30(20): 10-12.)
[12]向培素.两种聚类有效性评价指标的Matlab实现[J].西南民族大学学报(自然科学版),2013,30(6):1002-1005. (XIANG P S. Matlab implementation of two cluster validity evaluation indexes [J]. Journal of Southwest Nationalities University (Natural Science Edition), 2013, 30(6): 1002-1005.
[13]周开乐,杨善林,丁帅,等.聚类有效性研究综述[J].系统工程理论与实践,2014,34(9):2417-2431. (ZHOU K L,YANG S L, DING S, et al. Research on clustering validity [J]. System Engineering — Theory & Practice, 2014, 34(9): 2417-2431.)
[14]赵庆永.基于数据挖掘算法的日志分析系统的设计与实现[D].青岛:青岛大学,2009. (ZHAO Q Y. Design and implementation of log analysis system based on data mining algorithm [D]. Qingdao: Qingdao University, 2009.)
猜你喜欢
温州大学学报(自然科学版)(2022年2期)2022-05-30
华人时刊(2021年13期)2021-11-27
潍坊学院学报(2020年2期)2021-01-18
心声歌刊(2020年4期)2020-09-07
铁道通信信号(2019年6期)2019-10-08
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
制导与引信(2017年3期)2017-11-02
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
