
云存储环境下的多关键字密文搜索方法
2018-04-12 05:51杨宏宇
计算机应用 2018年2期
杨宏宇,王 玥
(中国民航大学 计算机科学与技术学院,天津 300300)(*通信作者电子邮箱yhyxlx@hotmail.com)
0 引言
随着大数据和云计算技术的日益发展,隐私保护问题愈发重要。在云存储环境下,数据拥有者向云服务器上传数据及用户搜索所需数据时,都涉及隐私保护。目前,云存储环境下的传统密文搜索算法搜索效率低,针对多关键字的搜索方法还不完善,高效的多关键字密文搜索方法已经成为目前的研究热点。
文献[1]提出加密的云数据多关键字排序搜索(Multi-keyword Ranked Search over Encrypted cloud data, MRSE),通过坐标匹配的方法衡量关键字与文件之间的相似性,由内积相似性评估坐标匹配方法。由于该方法的索引采用布尔量化表示,具有相同数量关键字的文件其相关性分数相同,导致该方法对于多关键字搜索的精确度低。文献[2]提出一种在公共信道传输的基于公钥加密的多关键字搜索方法,但该方法在模糊匹配关键字和公钥加密时时间开销较大,导致该方法效率较低。文献[3]针对文件关键字的相似性对文件聚类并形成聚类索引,在离线的阶段完成聚类和聚类索引的生成;但用户无法根据自己需要调节关键字权重值,导致实际应用时缺乏自适应能力。文献[4]在密文搜索方法中加入加密搜索插件,基于词频-逆向文件频率(Term Frequency-Inverse Document Frequency, TF-IDF)方法对即将上传的关键字排序,在一定程度上减少了云服务器的搜索时间,但该方法要求用户与数据拥有者必须使用指定加密搜索软件。文献[5]提出一种基于层次聚类索引的加密数据多关键字排序搜索(Multi-keyword Ranked Search over Encrypted data based on Hierarchical Clustering Index, MRSE-HCI)方法,该搜索方法在构建索引时需要扩展维度,导致计算开销过多。
针对上述方法搜索准确度较低、搜索效率低且不支持用户自定义关键字权重等问题,本文首先提出一种改进质量层次聚类(Improved Quality Hierarchical Clustering,IQHC)算法,并在此基础上提出一种基于IQHC的加密云数据多关键字排序搜索(Multi-keyword Ranked Search over Encrypted cloud data based on IQHC, MRSE-IQHC)方法来提高多关键字密文搜索时的搜索效率和准确性。
云存储环境下多关键字密文搜索方法的研究目的是在加密数据上进行多关键字密文搜索并保护隐私,通过MRSE-IQHC方法主要实现以下目标:
1)支持多关键字密文搜索。在云存储中,可支持多关键字的密文搜索,并将符合用户要求的前k个最佳匹配结果返回给用户。
2)提高搜索效率。通过TF-IDF[4]与向量空间模型(Vector Space Model,VSM)[6]的结合,以及IQHC算法聚类,提高搜索效率,缩短搜索时间。
3)满足用户对关键字权重的定义[7]。通过用户对关键字赋予的权重值,在搜索时根据用户需求进行多关键字搜索,优先返回符合用户要求的文件,提高搜索准确性。
4)隐私保护。保护数据拥有者和用户的隐私,攻击者和云服务器无法获取明文数据。
1 系统模型
MRSE-IQHC方法涉及三个实体:数据拥有者、用户和云服务器。这三个实体和密文搜索方法组成一个系统模型,其中,数据拥有者和用户是诚实可信的,云服务器是半可信的。系统模型的结构如图1所示。
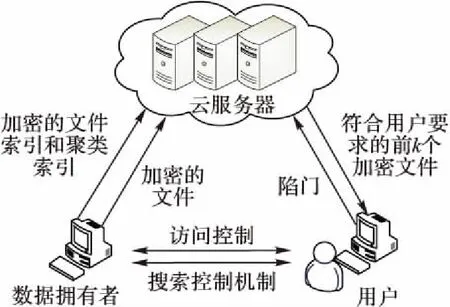
图1 系统模型Fig. 1 System model
数据拥有者是拥有文件的实体,能够提取文件关键字,采用本文提出的IQHC算法对文件向量聚类生成聚类索引和文件索引,然后将索引和文件加密后上传至云服务器。
用户身份是经过认证的,其身份真实可信,是执行搜索操作的实体。用户搜索时定义关键字的权值并产生搜索请求,在数据拥有者的协助下生成加密的搜索向量(即陷门)。将陷门上传至云服务器,等待云服务器返回搜索结果。
云服务器是半可信的服务器,可存储数据拥有者加密后的文件和索引,并根据用户发送的陷门执行搜索操作,向用户返回所需搜索结果。
本文研究的密文搜索方法主要针对系统模型中的三个实体。在该系统模型中,对密文的搜索可分为两个阶段:离线阶段和在线阶段。在离线阶段,数据拥有者采用IQHC算法对文件向量聚类,根据聚类结果产生文件索引和聚类索引。在在线阶段,数据拥有者采用不同加密方式对文件索引、聚类索引和文件加密后上传至云服务器。用户根据需求产生搜索请求,通过搜索控制机制将搜索请求发送给数据拥有者。数据拥有者由搜索请求构建搜索向量,加密后生成陷门并通过搜索控制机制将陷门返回给用户;用户上传陷门至云服务器等待搜索结果;云服务器经计算后返回给用户满足要求的加密文件;用户通过搜索控制机制从数据拥有者处获得解密密钥并对文件解密,完成整个密文搜索过程。系统模型中的搜索控制机制和访问控制机制均不在本文的研究范围之内。
2 质量层次聚类算法的改进
2.1 TF-IDF与VSM
以往的密文搜索算法MRSE-HCI[5]仅根据关键字是否存在构建文件向量,没有考虑关键字出现的频率及其重要性,在进行多关键字密文搜索时只能返回给用户存在该关键字的文件,却无法根据该关键字在文件中出现的频率及整个文件集合中的重要性排序后返回给用户,导致搜索结果与用户期望有很大偏差。因此,本文将TF-IDF和VSM相融合构建文件向量,可有效解决上述问题。
TF-IDF是一种常用于信息检索与数据挖掘的统计方法,能够衡量一个关键字对于一个文件或一个文件集合的重要程度。在TF-IDF中:TF为词频,表示某个关键字在某个文件中出现的频率大小;IDF为逆文件频率,表示某个关键字在整个文件集合中出现的频率大小,是关键字普遍重要性的度量。TF-IDF方法可计算每个关键字的权值,在密文搜索时可通过关键字权值计算出用户所需的文件。在本文研究中,选取关键字作为特征,采用TF与IDF的乘积作为关键字的权值,在构建文件向量时表示出每个关键字在文件中出现的次数及在文件集合中的重要程度,以提升改进算法的聚类效果。
VSM是一种文本表示方法,常用于信息检索领域。假设文件由多个不相关的特征组成,该特征可以是字、词、短语等,每个特征之间没有先后顺序关系,VSM通过一些方法对每个特征赋予权值,以权值作为坐标值将一个文件转化为空间中的向量[6]。VSM将文件向量化,把文本语义处理的问题转化为向量之间的数学运算问题。通过向量之间的数学运算,如向量距离、向量夹角等方法可精确衡量文件内容的相似度。本文算法选取向量距离作为相似度的衡量标准,将VSM应用于改进算法中,以提高文本聚类效果。本文方法中,通过TF-IDF与VSM的结合,可将密文搜索结果排序,提升搜索的准确性。
2.2 IQHC算法
在云存储环境下的多关键字密文搜索方法中,文件向量的向量维度高、冗余维度多,且数据分布稀疏,导致计算开销大、密文搜索效率低。本文将主成分分析(Principal Component Analysis, PCA)[8]与质量层次聚类(Quality Hierarchical Clustering, QHC)[5]算法相结合,通过降低文件向量在向量空间模型中的维度,保留其中最重要的多个特征再聚类,在此基础上对QHC算法进行改进,提出IQHC算法。IQHC算法的步骤设计如下:
步骤1由TF-IDF和VSM生成样本数量为n的文件向量D1,D2,…,Dn,其中Di=(d1,d2,…,dp)T(i=1,2,…,n)为p维向量,当n>p时,构造样本矩阵,对矩阵元素作如下变换得到标准化样本矩阵Z:
(1)
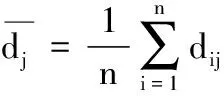
步骤2求Z的协方差矩阵C,公式如下:
C=(ZTZ)/(n-1)
(2)
其中ZT是矩阵Z的转置矩阵。
步骤3使用奇异值分解(Singular Value Decomposition, SVD)法求解样本协方差矩阵C的特征方程|C-λIp|=0,得到p个特征根,将p个特征根按照从大到小排列,并依据式(3)中贡献率η确定主成分个数,即m可由以下公式计算:
(3)
选取η的值,由m个主成分代表η以上的原始信息。针对每个特征根λj(j=1,2,…,m),求解方程组Rb=λjb得到m个单位特征向量bj(j=1,2,…,m)。
步骤4将标准化后的数据变量转换为主成分:
Ul=zlTbj;j=1,2,…,m,l=1,2,…,m
(4)
其中:U1称为第一主成分,U2称为第二主成分,……,Um称为第m主成分。将文件向量用新的主成分表示出来,得到降维后的文件向量。
步骤5设定每个聚类中文件的最大数量,记为TH,相关性值的最小值阈值记为min(S),采用欧氏距离衡量文件间的相关性以及文件和聚类中心之间的相关性。
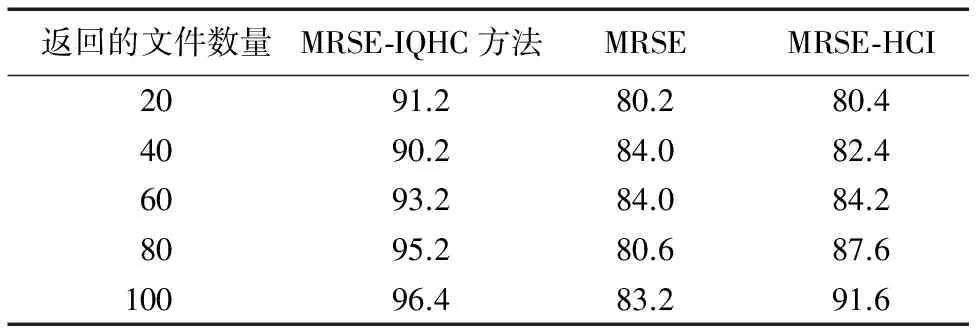
步骤6由K-means[9]聚类算法对降维后的文件向量聚类。当聚类个数k值不稳定时,添加一个新的聚类中心,则随机产生k+1个新的聚类中心进行聚类。分别取每个聚类中最小相关性分数min(St)(t=1,2,…,k,…)与相关性值最小值阈值min(S)相比较,若min(St) 步骤7将步骤6中产生的聚类中心集合作为第一级聚类中心C0,依次检查每个聚类中文件的数量,若文件数量超过了预先设定的阈值TH,则划分该聚类为多个子聚类;否则,不再划分子聚类。新划分的子聚类作为下一级聚类,重复步骤7直到所有聚类中的样本数量都满足阈值TH的限制。 步骤8重复上述步骤,直至所有聚类均满足聚类相关性和数量的要求,完成聚类过程。 本文提出的MRSE-IQHC方法中首先定义了下列符号: Dw:表示由所有关键字构成的字典,记为Dw={w1,w2,…,wm}。 Dw′:表示经过IQHC算法聚类后产生的字典,记为Dw′={w1,w2,…,wu}。 wi:表示第i个关键字。 D:表示所有文件向量的集合,记为D={D1,D2,…,Dn}。 Di:表示第i个文件。 De:表示加密后文件向量的集合。 n:表示文件向量的个数。 r:表示字典中关键字的数量。 S:表示一个ubit的随机向量,记为S={0,1}u。 M1、M2:均为u×u的可逆矩阵。 Ic:表示加密之后的聚类中心的索引。 Id:表示加密之后文件向量的索引。 V:表示数据拥有者生成的聚类索引向量。 Q:表示搜索向量。 Tw:表示陷门。 k:表示用户要求云服务器返回的文件数量。 基于IQHC算法,本文提出了MRSE-IQHC方法。首先由VSM和TF-IDF构造文件向量,然后采用IQHC算法对文件向量作降维和聚类处理,之后采用K最近邻(K-Nearest Neighbors,KNN)[10]查询算法加密索引向量和搜索向量,由用户定义关键字的权值构建搜索请求加密后进行密文搜索。在云存储环境下,MRSE-IQHC方法的密文搜索过程设计如下: 步骤1文件向量生成。数据拥有者取TF与IDF乘积作为关键字权重,在VSM中对即将上传的文件以向量形式表示,文件向量的每个维度分别由该位置上关键字的权重值表示,同时生成字典Dw并构建文件向量集合D。 步骤2索引构建。数据拥有者使用IQHC算法对文件向量进行聚类,聚类后产生ubit的字典Dw′,根据聚类的结果构建聚类索引和文件索引。文件索引向量和聚类索引向量长度均为ubit。 步骤3索引加密。数据拥有者通过KNN[10]查询算法随机生成一个ubit的随机向量S={0,1}u和两个规模为u×u的可逆矩阵M1、M2作为密钥。分割向量S的每一位由0或1随机组成,S中的0、1数量大致相同,矩阵M1、M2的每一位均为随机生成的整数。分割向量S作为分裂指示器用于分割文件索引及聚类索引,数据拥有者根据S将聚类索引向量V随机拆分成两个向量V′和V″,向量V′和V″中的第i位分别表示为Vi′和Vi″(i=1,2,…,u)。可逆矩阵M1、M2的转置矩阵M1T、M2T用于加密分割之后的向量V′和V″。当S中的第i位为0时,令Vi″=Vi′=Vi(i=1,2,…,u);当S中的第i位为1时,令Vi′=Vi-Vi″(i=1,2,…,u)。聚类索引被加密为Ic={M1TV′,M2TV″},加密的文件索引Id的生成过程相同。 步骤4文件加密。数据拥有者选择一种安全的对称加密算法对文件加密,并将加密后的文件集合De同之前生成的加密文件索引Id、加密聚类索引Ic发送至云服务器。 步骤5陷门生成。用户选择要搜索的关键字,按照需求对关键字赋予不同的权值并要求返回满足条件的前k个文件,构造搜索请求,将搜索请求发送给数据拥有者。数据拥有者收到搜索请求后,根据字典Dw′在被请求的关键字位置上赋予用户已定义的权重值,产生ubit的搜索向量Q,并用M1-1、M2-1矩阵加密Q。同样,数据拥有者根据S将搜索向量Q随机拆分成两个向量Q′和Q″,向量Q′和Q″中的第i位分别表示为Qi′和Qi″(i=1,2,…,u)。当S中的第i位为0时,Qi′=Qi-Qi″(i=1,2,…,u);当S中的第i位为1时,Qi″=Qi′=Qi(i=1,2,…,u)。搜索请求Q被拆分为Q′和Q″后被矩阵M1-1、M2-1加密得到陷门Tw={M1-1Q′,M2-1Q″},数据拥有者将Tw发送给用户。 步骤6搜索过程。用户将陷门Tw上传至云服务器,云服务器端采用计算内积方式计算相关性分数Score[5]: Score=Ic·Tw= {M1TV′,M2TV″}·{M1-1Q′,M2-1Q″}= V′Q′+V″Q″=VQ (5) 由式(5)可知,加密后的聚类索引向量Ic和陷门Tw的内积运算结果与未加密的聚类索引向量V和搜索向量Q的内积运算结果相等,因此在密文状态下搜索和明文状态下搜索结果一致,加密并不影响搜索结果的准确性。 云服务器首先计算陷门Tw和加密聚类索引向量Ic中第一级聚类中心的内积,找到得分最高的第一级聚类中心。然后,将陷门Tw与该聚类中心的子聚类中心计算内积找到得分最高的第二级聚类中心。以此类推,直至找到最后一级得分最高的聚类中心。最后,计算陷门Tw与加密文件索引向量Id的内积,找到得分最高的前k个加密文件并将结果反馈给用户。 步骤7解密过程。用户向数据拥有者发送解密请求,得到数据拥有者的解密密钥后对文件解密。 在数据拥有者、用户、云服务器间的通信过程中,攻击者可拦截通信,从所拦截的信息中推导出额外信息。根据攻击者获取的信息,多关键字密文搜索过程包括两个安全威胁模型:已知密文模型和已知背景知识模型。 已知密文模型攻击者掌握数据拥有者的加密文件、加密后的文件索引和聚类索引,以及用户提交的加密后的搜索向量。 已知背景知识模型在已知背景知识模型中,攻击者知道关于数据集中更多的统计知识信息,比如某些关键字的词频信息、关键字和数据的对应信息以及陷门的关联信息等。 在云存储环境下,攻击者拦截数据拥有者与云服务器、用户与云服务器之间的通信数据,可截获的信息包括:加密后的聚类索引Ic、加密后的文件索引Id、加密的文件集合De、陷门Tw和相关性分数Score。 在本文提出的MRSE-IQHC方法中,加密之后的聚类索引Ic、文件索引Id和用户生成的陷门Tw均是由KNN查询算法加密之后发送的,每个索引向量和陷门在加密时都被随机拆分成两个向量,相同关键字的搜索请求生成的陷门不同,因此攻击者无法推导出原始向量和搜索请求的明文信息。上传至云服务器的文件由数据拥有者使用对称加密算法加密,密钥保存在数据拥有者处,攻击者无法通过密文获取文件明文。由于索引和文件均采用不同的加密方式,在一定程度上提高了搜索方法的抗攻击能力。在搜索阶段,攻击者仅根据相关性分数也无法获取关键字信息,提高了对关键字隐私的保护能力。上述分析表明,在已知密文模型和背景知识模型条件下,本文方法可保证搜索数据的安全性。 为了便于文本聚类与效果测试,本实验采用复旦大学的中文语料库[11],该库包含艺术、历史、能源、电子、交通等20个种类的文本共9 804个文件,且该语料库训练集中每一个文件都已分类。实验的软硬件环境配置为:Intel Core i5- 3570 CPU @ 3.40 GHz CPU, 4.0 GB RAM,Windows 7(64位)操作系统, 使用Python语言编程。在相同实验环境下,对MRSE-IQHC、MRSE和MRSE-HCI这三种方法进行对比。 实验数据分为5组,分别选取100、200、300、400、500个文件,选取的文件大小均在1~50 KB。字典中关键字的数量r=5 000,搜索请求由10个关键字组成,每个关键字赋予1~3的权值,用户要求返回10个文件。针对不同文件数量测试三种方法的搜索时间,结果如图2所示。从图2可见,在初始时,本文方法MRSE-IQHC和MRSE方法的搜索时间比较接近,但本文方法的搜索时间均小于另外两种方法。随着文件数量的增加,MRSE-HCI方法和MRSE-IQHC方法的搜索时间基本呈现线性增加,MRSE方法的搜索时间则呈指数型增长,本文方法的搜索时间明显小于其他两种方法。 图2 搜索文件数量与搜索时间的关系Fig. 2 Relationship between the number of search documents and the search time 选取500个文件,文件大小均在1~50 KB,r=5 000,搜索请求由10个关键字组成,为每个关键字赋予1~3的权值。当用户要求返回5、10、15、20、25个文件时,测试搜索时间,结果如图3所示。由图3可见,MRSE-IQHC方法的搜索时间明显小于其他两种方法,当用户要求返回的文件数量改变时,对MRSE-IQHC方法的搜索时间并无太大影响。MRSE-IQHC方法在进行密文搜索时,需要比较陷门和每一级聚类中心的相似度,找到最相似的聚类后将陷门与该聚类中的每个文件进行相似度的计算,然后选取最相似的前k个文件。因此,当返回文件的数量即k值增加时,搜索计算量相同,返回文件数量对搜索时间不会有太大影响。 图3 返回文件数量与搜索时间的关系Fig. 3 Relationship between the number of retrieved documents and search time 仍选取500个文件,文件大小均在1~50 KB,r=5 000,用户要求返回10个文件。分别测试用户请求1、2、3、4、5个关键字时的搜索时间,结果如图4所示。从图4可见:MRSE-IQHC的搜索时间远小于其他两种方法;随着搜索请求中关键字数量的增加,MRSE方法搜索时间比较稳定,MRSE-HCI方法和MRSE-IQHC方法的搜索时间均呈线性增加。因为MRSE-IQHC方法根据搜索关键字数量构建搜索请求时,需要在关键字相对应位置上赋予权值,关键字数量改变时,陷门的向量维数没有减少,但搜索的计算量会随着关键字数量的增加而增加,因此搜索时间会呈线性增加的趋势。 图4 搜索关键字数量与搜索时间的关系Fig. 4 Relationship between the number of search keywords and search time 还是选取500个文件,文件大小均为1~50 KB,r=5 000,用户请求搜索10个关键字,每个关键字权值在1~3,分别测试在返回不同数量文件时三种方法的搜索准确性,结果如表1所示。从表1可见,MRSE-IQHC方法的搜索准确性明显高于其他两种方法。因为MRSE-IQHC方法将TF-IDF与VSM相结合构建文件向量,搜索阶段由用户自定义关键字权值,因此可优先选出含有重要关键字的文件,提升了密文搜索的准确率;而另外两种方法只考虑文件是否包含关键字,并未考虑用户需求,所以准确率低于本文方法。 表1 搜索准确率对比 %Tab. 1 Comparison of search accuracy % 本文提出一种基于改进质量层次聚类的加密云数据多关键字排序搜索方法MRSE-IQHC。该方法首先通过TF-IDF与VSM的结合构建文件向量,可有效考虑关键字在文件集合中出现频率和重要性;其次,利用IQHC算法对文件向量聚类,根据聚类结果构造聚类索引和文件索引,在搜索时可有效提高密文搜索效率;最后,用户在搜索时自定义关键字权值,增强了方法的自适应能力并提高了检索结果的准确性。实验结果表明,本文方法在搜索效率和准确性方面优于MRSE和MRSE-HCI方法。 参考文献: [1]CAO N, WANG C, LI M, et al. Privacy-preserving multi-keyword ranked search over encrypted cloud data [C]// IEEE INFOCOM 2011: Proceedings of the 30th IEEE International Conference on Computer Communications. Piscataway, NJ: IEEE, 2011: 829-837. [2]秦志光,包文意,赵洋,等.云存储中一种模糊关键字搜索加密方案[J].信息网络安全,2015(6):7-12. (QIN Z G, BAO W Y, ZHAO Y, et al. A fuzzy keyword search scheme with encryption in cloud storage [J]. Netinfo Security, 2015(6): 7-12.) [3]HANDA R, CHALLA R K. A cluster based multi-keyword search on outsourced encrypted cloud data [C]// INDIACom 2015: Proceedings of the 2nd International Conference on Computing for Sustainable Global Development. Piscataway, NJ: IEEE, 2015: 115-120. [4]王雅山.云存储平台中加密数据的多关键字排序搜索技术研究[D].哈尔滨:哈尔滨工业大学,2015:12-38. (WANG Y S. Secure rank-ordered search of multi-keyword in cloud storage platform [D]. Harbin: Harbin Institute of Technology, 2015: 12-38.) [5]CHEN C, ZHU X, SHEN P, et al. An efficient privacy-preserving ranked keyword search method [J]. IEEE Transactions on Parallel & Distributed Systems, 2016, 27(4): 951-963. [6]孔振.基于VSM的文本分类系统的设计和实现[D].哈尔滨:哈尔滨工业大学,2014:15-17. (KONG Z. The design and implementation of text classification system based on VSM [D]. Harbin: Harbin Institute of Technology, 2014: 15-17.) [7]郭文杰,张应辉,郑东.云存储中支持词频和用户喜好的密文模糊检索[J].深圳大学学报(理工版),2015,32(5):532-537. (GUO W J, ZHANG Y H, ZHENG D. Fuzzy search over encrypted data supporting word frequencies and user preferences in cloud storage [J]. Journal of Shenzhen University (Science and Engineering), 2015, 32(5): 532-537.) [8]杨宏宇,常媛.基于K均值多重主成分分析的App-DDoS检测方法[J].通信学报,2014,35(5):16-24. (YANG H Y, CHANG Y. App-DDoS detection method based on K-means multiple principal component analysis [J]. Journal on Communications, 2014, 35(5): 16-24.) [9]彭长生.基于Fisher判别的分布式K-Means聚类算法[J].江苏大学学报(自然科学版),2014,35(4):422-427. (PENG C S. Distributed K-Means clustering algorithm based on Fisher discriminant ratio [J]. Journal of Jiangsu University (Natural Science Edition), 2014, 35(4): 422-427.) [10]WONG W K, CHEUNG D W-L, KAO B, et al. Secure kNN computation on encrypted databases [C]// SIGMOD ’09: Proceedings of the 2009 ACM Special Interest Group on Management of Data International Conference on Management of Data. New York: ACM, 2009: 139-152. [11]李荣陆.文本分类语料库(复旦)测试语料[EB/OL]. [2017- 07- 06]. http://www.nlpir.org/?action-viewnews-itemid-103. (LI R L. Text categorization corpus (Fudan) test corpus [EB/OL]. [2017- 07- 06]. http://www.nlpir.org/?action-viewnews-itemid-103.) [12]JOY E C, KALIANNAN I. Multi keyword ranked search over encrypted cloud data [J]. International Journal of Applied Engineering Research, 2014, 9: 7149-7176. [13]FU Z, SUN X, LIU Q, et al. Achieving efficient cloud search services: multi-keyword ranked search over encrypted cloud data supporting parallel computing [J]. IEICE Transactions on Communications, 2015, 98(1): 190-200. [14]YAO L, GU J, GAO Y. Optimized ciphertext retrieval for cloud computing based on dynamic clustering [C]// Proceedings of the 3rd ACM Workshop on Mobile Sensing, Computing and Communication. New York: ACM, 2016: 35-39. [15]KRISHNA C R, HANDA R. Dynamic cluster based privacy-preserving multi-keyword search over encrypted cloud data [C]// Proceedings of the 2016 6th Conference on Cloud System and Big Data Engineering. Piscataway, NJ: IEEE, 2016: 146-151.3 密文搜索方法
3.1 符号定义与说明
3.2 MRSE-IQHC方法
4 安全性分析
4.1 安全威胁模型
4.2 方法的安全性分析
5 实验结果与分析
5.1 实验数据和环境配置
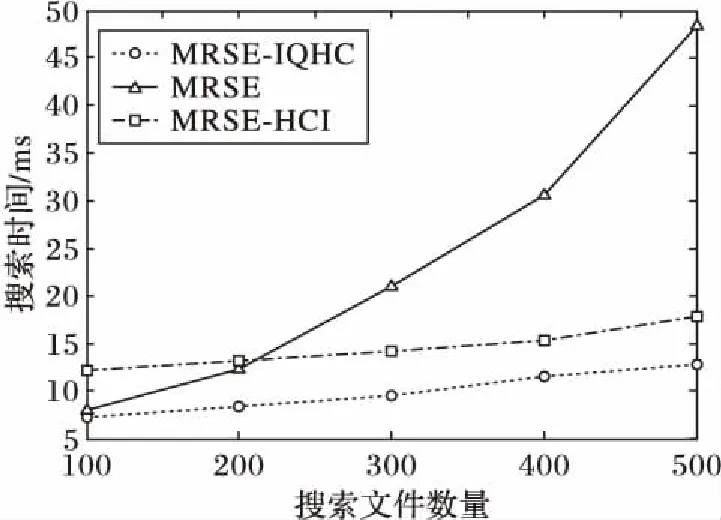
5.2 搜索文件数量对搜索时间的影响测试
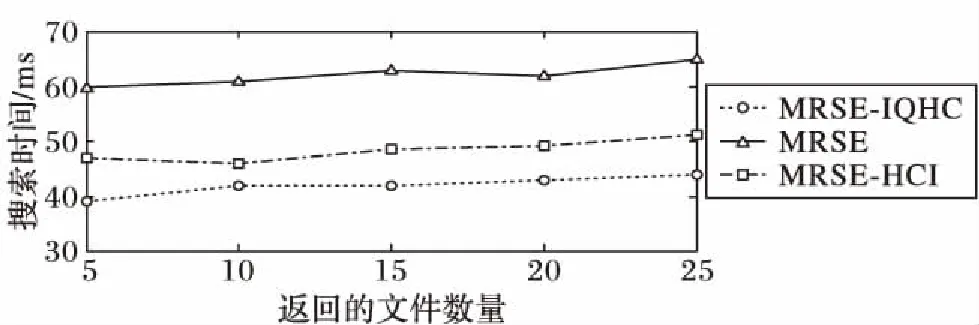
5.3 返回文件数量对搜索时间的影响测试
5.4 搜索关键字数量对搜索时间的影响测试

5.5 搜索准确性测试
6 结语
猜你喜欢
华人时刊(2022年1期)2022-04-26
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
网络安全技术与应用(2020年11期)2020-11-14
沈阳工业大学学报(2020年2期)2020-04-11
动漫界·幼教365(大班)(2019年10期)2019-10-28
环球时报(2009-11-25)2009-11-25
