
基于音系学模型的手语理解
2018-04-04 01:12姚登峰江铭虎阿布都克力木阿布力孜李晗静哈里旦木阿布都克里木
中文信息学报 2018年1期
姚登峰,江铭虎,阿布都克力木·阿布力孜,李晗静,哈里旦木·阿布都克里木
(1. 北京市信息服务工程重点实验室(北京联合大学),北京 100101;2. 清华大学 人文学院 计算语言学实验室、心理学与认知科学研究中心,北京100084;3. 清华大学 计算机科学与技术系 智能技术与系统国家重点实验室,北京100084)
正如语音识别需要语言计算理论一样,手语识别也需要手语计算的知识,因此它是手势动作识别和手语含义识别理解的综合。长期以来,手语识别理解缺乏手语语言学家的参与,并未取得较大的进展。本文深入研究了手语理解的问题,从语言学的角度,提出在音系学层面上进行手语理解,基于此提出了基于音系学模型的手语理解算法。
1 基于语言学特征的手势理解综述
目前手势识别研究基本都参考了Stokoe理论。1960年Stokoe提出手势(同时)由三个部分(参数)组成,包括手势位置、手形,及运动[1]。20世纪70年代初期语言学家给这三个参数增加了一个要素: 方向,之后语言学者大都采用这四个参数的说法。
Vogler与Metaxas在Stokoe模型的基础上提出了PaHMMs[2]。此后手语识别文献使用Stokoe提出的语言学特征,主要是基于少量样本来学习新手势。Lichtenauer等人为未登录手势提出一种自动构建分类器的方法[3],通过收集很多手势者的手势特征,与新手势的特征进行比较,从而为目标新手势构建分类器模型。这种方法依赖于大量的基础特征训练集(75人打出的120个手势),并允许使用一次性学习来训练一个新手势分类器。Bowden等人还提出使用一个训练样本就能正确分类新手势的手语识别系统[4],并给出了一个单一的训练例子。他们的方法使用了二级分类器,其中一级使用硬编码分类器来检测手形、布局、运动和位置。在应用动态分类手势前,二级使用了ICA(independent component analysis)从一级得到的34维特征向量消除噪声,在少量训练实例和缺乏语法知识的情况下获得了很好的效果。Kadir等人扩展了前述工作,并基于Boosting级联弱分类器以躯干为中心的描述特征(将运动规格化为二维空间)来检测头部和手部,然后使用二级分类器,其中一级分类器生成语言学特征向量,二级分类器在马尔可夫链上使用Viterbi算法来获取最高识别概率[5]。Cooper 与Bowden延续了这项工作,使用了分类器集合来检测训练样本和分类样本的手势特征[6],将这些特征组合作为二级分类器的输入,使用了一阶马尔可夫假设。
这些文献表明: 基于Stokoe的语言学特征,其手语识别率等同于基于图形学特征的识别率。这显然有违于引进语言学特征的初衷,其根本原因在于Stokoe模型认为包括手形、运动、位置等在内的音系参数是同时出现的。也就是说手形、移动、位置、方向和非手动特征是同时表达出来的,这样一个手势就可以立即表征出来。然而在有声语言中声音是线性连续的,因此手语也应与有声语言一样,是手势的序列性表达(sequential presentation)。我们认为手势可同时结合序列性和同时性,这就需要一个合适的音系学模型来表达手语的序列性和同时性。大量跨手语语言的语料证明手语中存在音节结构[7]。为此,我们先进行音韵参数感知加工,在此基础上提出改进的音系学模型,即增强运动—保持模型。
2 音韵参数感知加工
最近涌现出的3D体感设备为手势感知创造了可能,这种设备是利用3D体感摄像头来获取目标的图像信息,通常是目标的深度和红外图像信息。它借鉴了人眼的认知原理,将传统的2D物体转换到3D空间。通过这种3D体感设备可以计算出位置、手形、方向、运动、非手动特征五个参数,这五个参数本身就是手语语言学里的音韵特征,相比较口语的语音识别,这些物理特征可凭视觉直观感受到。感知阶段,体感设备在计算音韵特征时,可先计算手部位置、方向、运动等手动特征,再计算眉毛、眼睛、嘴部、头部等非手动特征,这是一个从粗粒度音韵特征到细粒度特征的计算过程,符合人脑对图像特征加工的认知机理。
手势的手形音韵参数,则由Leap Motion给出的每个手掌关节点的3D坐标值计算得到,这里总共统计了69个手形。粗粒度的音韵参数如位置、方向、运动三个特征可由Kinect或Leap Motion计算得到,以Kinect为例,位置是根据Kinect给出的深度信息和3D坐标返回的两个参数确定的,第一个参数是判断手部是否与身体接触,分别有接触、正常位置、远离身体三个值;第二个参数是判断手部在身体的位置,通常有头顶、太阳穴、耳部、头额等28个值。其中眉毛是根据Kinect给出的深度信息和3D坐标来判断眉毛是否上扬,分别有三个值,以此来判断手势者的情绪,由于眉毛变化通常伴随着眼睛、嘴部、头部和肢体的变化,为减少计算工作量,我们只将眉毛作为主要特征,其他作为次要特征。在判断主要特征眉毛上扬时,还需要验证次要特征,如眼睛是否变宽变大,头部和身体是否前倾,亦或肩部是否提起,在确认为疑问句后,再判断是否有双眼斜视(反问句没有双眼斜视)、头部是否摆动(一般疑问句没有头部摆动)等特征。
为了减少计算工作量,以Leap Motion为例,实际每秒只计算三个帧,即编号为1、145、289的帧,以帧为单位返回原始数据,以这些原始数据计算每一帧的返回参数为(LA,LB,LC,LD,RA,RB,RC,RD,T),其中具体参数值见图1,这样手势“你”某一时刻返回的帧参数为(0,0,0,0,1,7,1,4,64320),即某一时刻该右手手势位于中性空间(不与胸部接触的空间),为数字1手形,正从后向前运动,手掌方向从左到右,该帧的时刻为00:01:43:20,其中四个0表示Leap Motion未检测到左手,返回左手的四个音韵参数均为0。为了切分方便,M音段的第一个音韵参数位置以中间帧的位置为准,第二个音韵参数手形以最后一帧的手形为准,第三个音韵参数运动可用当前帧(F)与上一帧(F-1)的差值表示当前帧的变化量,具体以手掌中心坐标(Palm Position)的变化来表示,第四个音韵参数是手掌方向,需计算M音段最后帧的手掌,由六个点组成的平面垂直向量(Palm Normal)来表示。

图1 感知阶段音韵特征的具体值
3 基于音韵参数的手势理解算法
上个阶段得到的标注文本就是手语的音韵信息,本阶段任务是从这些音韵信息得到手语文本(以中文作为编码系统,按照手语语法得到的文本)。根据这五个参数得到手势文本,本质上属于从拼音到汉字、从英语音标到英语单词的转换。因此从第一阶段自动标注好的音韵信息推断出手语文本类似于从连续的汉语拼音推断出汉语句子文本,或者从连续的英语音标推断出英语文本。手语音韵信息到文本转换的流程,与有声语言的传统标注技术相反,有声语言标注是先得到文本,再对文本进行拼音、词性等标注工作。
3.1 手势音韵信息——手语文本转换的难点
有声语言的同音字现象很常见,以汉语为例,若不考虑声调,新华字典里有7 536个同音字,大约占10%,平均每个读音就有18.29个汉字,如此高的比例给汉字消歧带来了很大的困难[8]。关于同音手势,目前未看到有关报道。本文对自建的中国手语语料库做了统计,手语的同音手势占所有手势的46.86%,几乎占了一半。其中以词频统计,常用的同音手势占了41.37%,不常见的同音手势占了5.23%。因此手语与有声语言相比,同音情况更多、更复杂,其同音手势识别问题是音韵标注到文本转换问题的关键。
手语文本采用的中文编码是普通话的书写系统,具有表音和表意两方面的特点。而汉语拼音本身就是语音的书面符号,具有表音的作用,因此从汉语拼音得到汉字序列,虽然需要分析形、音、义等多方面信息,以及这些信息的综合判断,但毕竟存在着音的关系。而手势音韵信息是以手部为发音器官,从音系学角度得到的发音特征,它毕竟不同于国际音标或者西文的拼音文字,从手语音韵特征到口语的书面系统转换完全不存在任何关系。尤其是手语中分类词谓语(手语独有的语言学现象,有声语言里没有)不是一个真正的手势,不受手语音系学里对称性和支配性等这些限制条件的影响[9]。这样,包括分类词谓语在内的很多手势,其音韵结构较为复杂,没法用1~2个中文单词来标注。因此相对汉语口语,我们要完成的从手语音韵信息到手语文本的转换任务是一个难度更大的消歧任务。把手语的音韵信息转化为口语文本,要弄清楚手语音韵学、句法学和形态学等独有的规律和特征。汉语是聋人的第二语言,与汉语语法相比,手语句子并不规范,其手语语法尚未规范化,再加上手语本身形态变化更为复杂,且每个手势的复杂程度分布很不均匀,根据自建手语语料库统计,平均每个手势需要2~6个汉字来表述,但有些手势最多需要62个汉字才能表述其完整的意义。如前所述,在手语中同音手势的情况比有声语言更为常见,但是每个手势对应的候选词汇一般为4~8个,与汉语拼音基本相同。形态变化再加上候选词汇众多,将两者综合,使消歧难度比单纯的从拼音到汉字转换更大,因此手语本身的形态、语法是影响手语音韵信息到手语文本的转换准确率的重要因素,也是实现从手势音韵信息到汉字文本转换的根本问题所在。
3.2 手语音系学的改进模型
Liddell 等人提出了运动-保持模型(movement-hold model)[10],该模型认为手势由保持(hold)音段和运动(movement)音段(phonological segments)构成,它们按序列生成。关于手形、位置、方向和非手动特征的信息通过每个单元一系列发音特征表现出来。这些特征类似于口语发声。保持音段定义为所有发音以稳定状态呈现的时间,而运动音段则定义为多个发音变换的时间,即一次至少一个参数发生变化,可能只有一个手形或位置参数的变化,也有可能是手形和位置两个参数同时变化,这些变化就在运动音段内发生。这种说法与Stokoe认为手势参数同时生成的说法完全不同,但是与口语音段结构的说法一致。运动-保持模型解决了Stokoe模型的描述性问题。这套系统能够有效描述序列,还能提供足够多的手语描述细节,并清楚地描述和解释无数个发生在手语中的手势过程。
本文为了音节切分方便,对运动-保持模型(movement-hold model)进行了改进,命名为增强运动-保持模型(enhanced movement-hold model),不考虑运动和保持两个音位音段约各占一半时间的划分,只考虑手势者在打出手势时,最开始手部是置于躯干两侧或者放平静止不动,手势的四个音韵参数(手形、运动、位置和方向)均没有变化,这时以H音段开始,接着手部到达手势初始位置时,为M音段+H音段,即任何手势句子开始时,都是以HMH音段为开始,此后手势只要有一个参数发生变化,即可定义为M音段,运动停止时,即可定义为H音段。根据这种改进的增强运动-保持模型(nhanced movement-hold model),在中国手语中单个手势的保持和运动组合可能有: HMH、MMH、HMHMMH、HMH、MHMMH、MMHH、HMHMHMHMH等28种组合。若不考虑书空(指在空气中书写汉字,是中国手语的一种构词方式)等复杂情况,可能的组合可下降到12种。由此可见,并非所有手势都是保持-运动-保持(HMHMH)结构。在大多数情况下,HMHMH型音节在中国手语中的分布非常广泛。不同音段结构反映了意义上的差异,如快(HMHMH)和速度(HMHMMMMH)之间的音段结构差异。我们在分析中国手语音段切分时,发现中国手语与汉语口语一样,连续手势序列并不是单个音节的简单组合,手语句子里每个手势组成部分以不同顺序组织,而且相互影响。因为受协同发音、韵律等因素的影响,手语也存在音变现象,从而导致连续手势序列与单独的手势音节有很大的不同。流畅手语是每秒2~3个手势,比较慢,每句最长不超过12个手势音节。此外,手势者的表达手语的风格不同,并且手势者之间也存在音变的个体差异。本文以文献[9]为依据,目前已发现中国手语有四个音变,分别是运动增音(movement epenthesis)、保持缺失(hold deletion)、音位转换(metathesis)和同化(assimilation)。我们发现中国手语音节切分比汉语口语音节切分更为简单,至少某个手势过渡到下一个手势发生音变时,只是MH的前后序列发生了变化,并且这些变化仍能被体感设备感应到,没有超出运动-保持模型的范围。根据以上理论,我们可以根据图2得到以下例子。
汉语句子: 我自从出生以来,没去过天安门。
手语句子: 成长(指从小到大)天-安-门没。
音韵特征序列: HMHMH M HMMMMH M HMH M HMH M HMH
实际数据序列: H(0,0,0,0,26,25,21,5)M(0,0,0,0,26,25,5,2)H(0,0,0,0,24,25,21,2)M(0,0,0,0,24,25,27,2)H(0,0,0,0,4,25,49,2) M(0,0,0,0,4,25,19,5)H(0,0,0,0,5,7,21,5)M(0,0,0,0,5,7,11,5)M(0,0,0,0,5,7,11,5)M(0,0,0,0,5,7,11,5)M(0,0,0,0,5,7,11,5)H(0,0,0,0,5,7,21,5)M(0,0,0,0,16,49,19,2)H(0,0,0,0,2,49,21,2)M(0,0,0,0,26,49,26,2)H(0,0,0,0,18,49,21,2)M(18,49,21,3,18,49,21,3)H(4,49,21,3,4,49,21,3)M(2,49,10,3,2,49,10,3)H(2,49,21,3,2,49,21,3)M(2,12,21,6,2,12,21,5)H(2,12,21,6,2,12,21,5)M(26,25,26,6,26,25,26,5) H(26,25,21,6,26,25,21,5)

图2 手势句子“成长天安门没”
3.3 手势理解与消歧
消歧的重点在于手势音韵信息及手语语法、语用信息的特征提取,我们考虑使用深层网络结构,深层结构具有较强的学习能力来获取特征,在图像识别等领域得到了广泛的应用。很多文献表明构造深层神经网络时需要注重模型的混合搭配,这样才能实现模拟大脑的工作机理,即在输入原始数据时,每处理一层,提取的概念特征便抽象一些[11]。为此,在构建底层网络时,我们采用了带噪声的自动编码器(denoise auto-encoder,DAE) ,目的是通过非线性组合高维底层特征,学习到低维抽象特征。我们希望利用DAE来提取未发现的特征,完成手势音韵信息和语法语用信息的特征提取。接着使用受限玻尔兹曼机(restricted boltzmann machines,RBM),进一步自动学习更抽象、更有效的高层特征,继而采用BP算法更新整个网络的权重,对整个网络进行微调。最终用多元Logistic分类模型(multi-class logistic classifier, MLC) 进行分类,这是因为经过前两个网络构建后数据训练已基本完成。该混合神经网络以每个待处理的手语音韵信息序列作为输入,依靠深度学习强大的无监督学习特征的能力[12-15],在多层隐层中进行逐层训练学习,以获取音韵信息的抽象表示,最后将产生的特征通过分类器得到可能性最高的手语文本,从而完成音韵信息到手语文本的转换工作。因此我们提出的模型如图3所示。
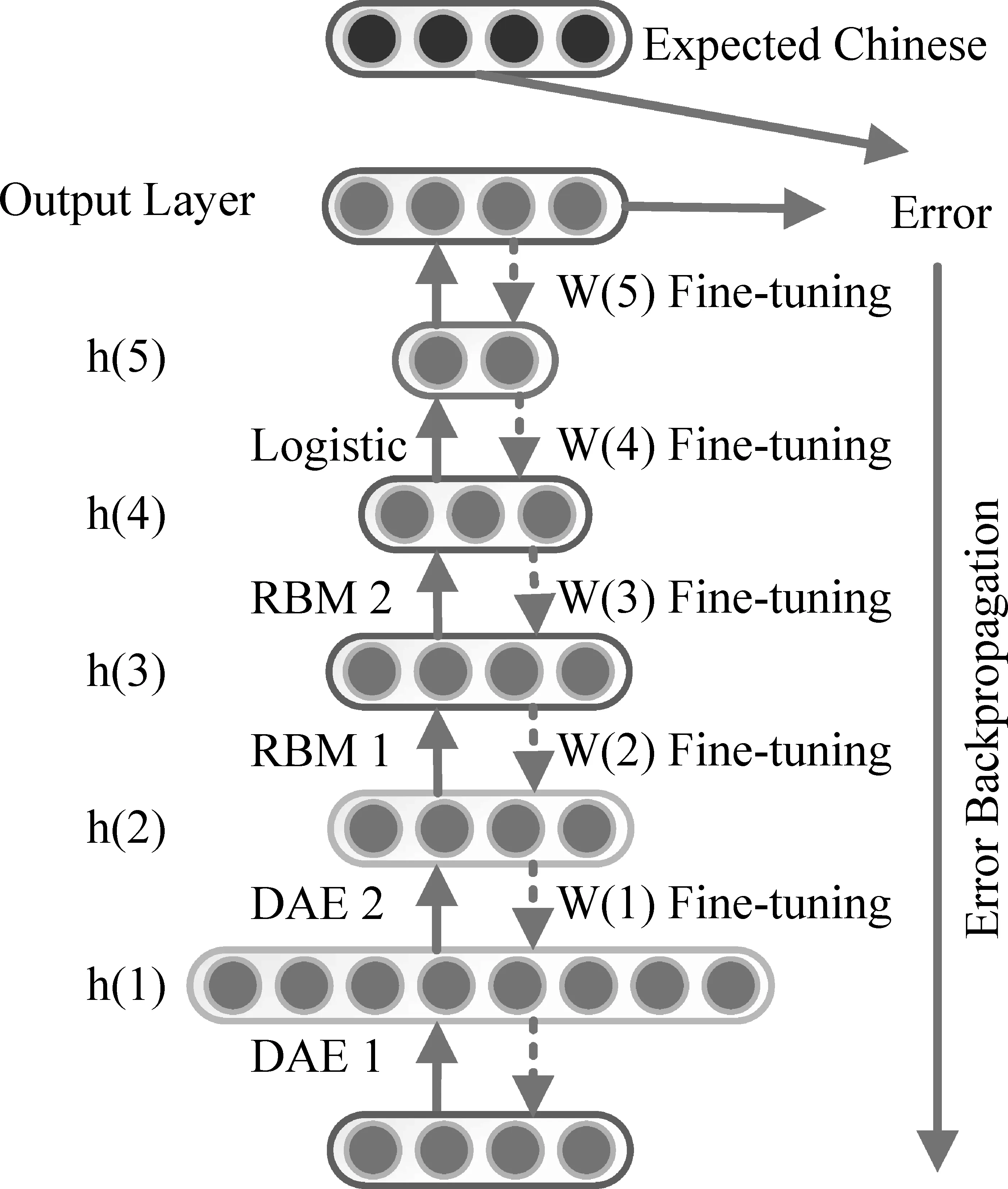
图3 智能认知的基础——混合深层神经网络
只要设计的深层神经网络结构合理,便可从感知阶段得到的音韵信息中提取出对手语文本分类帮助较大的特征,从而解决手语音韵参数到手语文本的转换问题。图3中输入层X输入感知阶段得到的手势音韵特征序列,将手语文本作为这种混合深层神经网络的输出节点。基础模块第一层和第二层均采用了常规DAE模型[16],其原型是自编码神经网络(auto-encoder,AE),该网络通过一种尽可能复现输入信号的无监督学习算法完成网络的预训练。
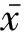
(1)
与此DAE模型不同的是,本文采取的方法除了选取部分数据强制变为0以外,也随机挑选了一定比例的数据强制变为1,目的是保证模型免受无关输入或者个性化音韵信息的影响,消除音韵信息的不规范性。
在获取特征后,我们使用了深度信念网络(deep belief network,DBN)实现去噪自编码器的输出数据的降维[17]。这里采用了两层RBM,RBM是一个基于统计力学的概率图生成模型,可以自动从训练集里提取高阶抽象的特征,并且提供较好的神经网络初始权值,这样就可以把权值控制在对全局训练最有利的范围内,从而降低对学习目标过拟合的风险。预训练时,可采取对比散度算法变形进行近似求解,即通过最小化两个散度的不同来进行预训练[18],以得到模型参数。具体是运行若干次Gibbs采样,得到足够多的样本,然后通过计算平均值来求出归一化常数。由于RBM训练过程与维度无关,所以可以利用RBM对数据进行有效的投影,之后在最顶层加上逻辑斯蒂克模型作为分类器,对输出层的结果做排序,排序靠前的手语文本即为该深层混合神经网络对手语音韵信息转换的预测结果。
最后是模型的微调,这里使用BP算法更新整个网络的权值,对混合神经网络的性能做调整。由于BP算法本身的缺陷,使用时需要注意训练过程,要找到合理的初始值,否则容易陷入局部极小值。
4 实验
4.1 实验准备
为了验证以上基于音系学模型的手语理解算法,我们使用体感设备LeapMotion做了先行验证,本文硬件实验环境为:Intel酷睿i7-4770s@3.7GHz四核CPU,16GB内存,IntelHDGraphics4600显卡。首先基于LeapMotion,选择Unity3D4.10作为实现平台,开发了一个中国手语手势音韵特征采集系统,可实现简单的手势识别功能,重点是采集手形、运动、位置、方向这四个参数,不采集非手动特征。
请三名聋生作为被试,以人民邮电出版社出版的《成语故事》(陈敏编)和人民文学出版社出版的《中国现代寓言故事》(安武林编)这两本书为故事来源,要求聋生阅读后,用自己的手语语言表达一遍,并要求尽量在水平方向打出手势,尽量减少握拳或垂直方向手势识别出现的误差。因此得到的龟兔赛跑、守株待兔、草木皆兵等故事视频,虽然其意思大致相同,但采集到的音韵特征序列大不相同。拍摄视频时,对于每个手势者,要求打出手势的速度为2~3个手势/秒,尽量在5min之内表达完整的句子或段落意思。这样后期就可以切割成每段5min的视频文件,每两段视频文件之间没有交集。经LeapMotion同步采集后,经过整理可得到400个音韵特征标注语料。为了完成实验,我们将这些标注后的音韵特征文件分为三部分:300个语料文件作为训练集,50个语料文件作为验证集,剩下50个语料文件作为测试集。音韵特征覆盖常用的手势音节结构,从手语句子过渡到下一个句子的短暂停用“X”表示。由于对于视频而言,成语或寓言故事是相对独立的单元,因此我们在划分三个语料集合时保证不同集合的数据来自于不同的故事。
4.2 实验设置
预训练RBM时每次更新参数都运行一次Gibbs采样,每一层迭代次数为30次,微调时反向传播算法迭代的次数上限为250次,同时权值约束系数均为0.1。DAE层数设置为两层,且第二层维数设为500,以便压缩数据,同时传送到第三层RBM网络,最后用逻辑斯特层输出手语句子的最大个数要求12个。对此,模型的参数定义如表1所示,其中L1和L2正则化权重为0.1。
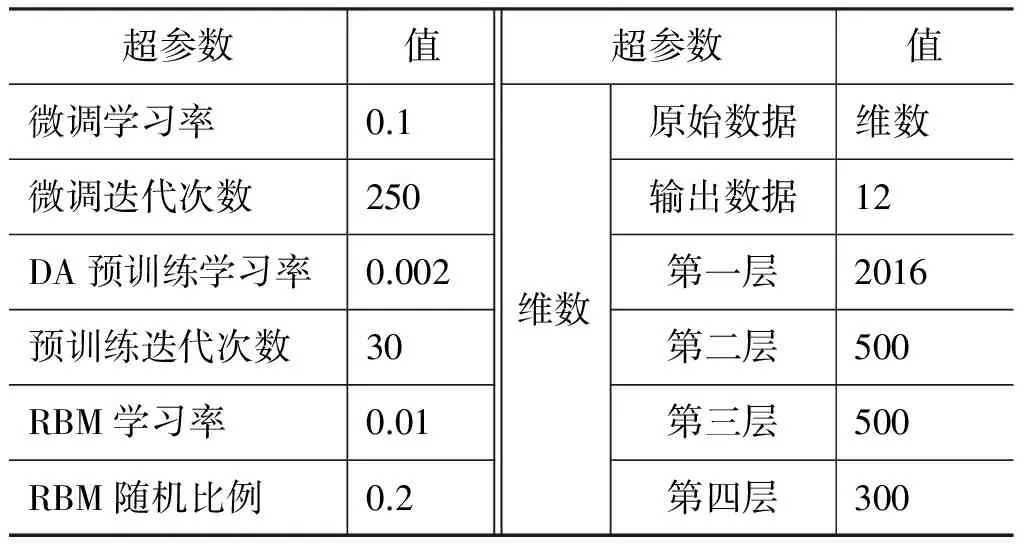
表1 模型参数列表
4.3 实验结果
模型正确率对比的结果如表2所示。
从结果上看,与预想差异不大,因为BP神经网络对语言关联模式的处理能力 不 强,因 此 效 果最差。同时与其他模型相比,条件随机场识别效果不明显,这说明提取的音韵特征对提升效果帮助不大,不是一个有效的特征。随着特征维数的增大,HMM和条件随机场的识别正确率随之上升,说明这两种模型对近距离的音韵参数处理得较好。基于音系学模型的手语理解算法通过模仿人脑认知,能够提取具有潜在复杂结构规则的手语视频等丰富结构数据的本质特征,并且用到了混合深度神经网络,综合了组成神经网络的优点,效果优于其他模型。图4分别显示了第一层隐节点数量为2 016、2 688、3 360时的预测误差曲线,可以看到,随着节点数的增大,过拟合现象较严重。
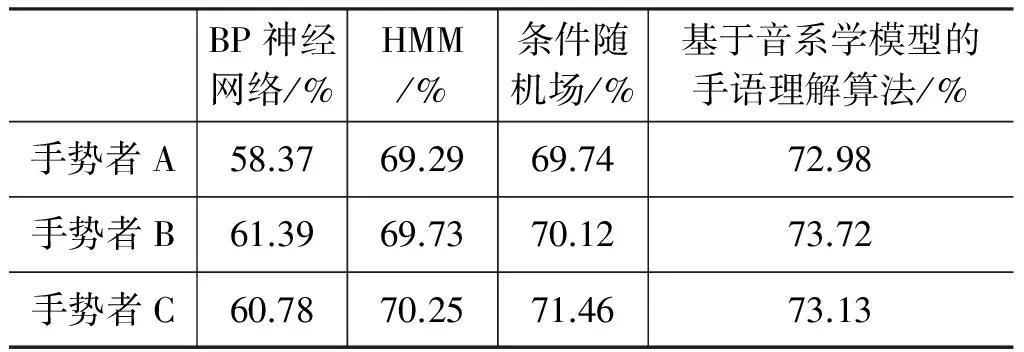
表2 各模型正确率对比

图4 误差预测曲线
4.4 参数对实验结果的影响
训练好 DAE 后,用其各层之间的权值来初始化上一节中的深度网络,然后传到RBM时,再利用BP反向传播算法训练该深度网络。由此得到每个epoch对应的训练时间如图5(a)所示,最终得到的分类效果如图5(b)所示。
图5 epoch训练时间及分类效果
网络各层之间的参数对应的参数更新平均值随 epoch 变化趋势如图6所示,由此可以看出权值更新率也是个重要的参数,不能太小,否则会导致收敛过慢;也不能太大,否则会造成网络不稳定。
图6 权值更新率变化曲线
由图可见,深度神经网络的梯度扩散问题有一定的改善。这说明把混合神经网络采用去噪自编码器的无监督学习得到的各层参数作为深度网络的初始值,能够很好地迭代收敛,从而获得很好的分类效果。在训练和测试时,记录随着混合神经网络的训练时间的增加正确率的变化规律。从图5(b)可以看出,随着训练迭代次数的增长,训练样本和测试样本的识别率都会增长,最后趋于稳定,到达80次的时候,训练样本的正确率还会继续轻微的提高;由于训练过拟合的原因,测试集正确率开始轻微下降,这也是混合神经网络,包括去噪自编码器模型的一个特点,不是训练时间越长,测试结果就越好。
根据以上分析,我们认为这种基于音系学模型的手语理解算法还有改进的空间,虽然效果优于其他对比的模型,但可能是因为手语相比口语,语法相对简单,很少见到长难句。手语与有声语言不同,汉语拼音转化为汉字时,存在着很多同音字,导致消歧困难,需要利用语境和各类知识。而手语也存在着同音现象,但手语可通过非手动特征来帮助消歧,并不需要过多的利用语境和世界知识。我们推测,手形、运动、位置这些参数在识别同音手势时并不起主要作用,而起决定作用的是非手动特征,它也恰恰是最复杂的特征。因为非手动特征包括面部表情和肢体动作,而面部表情又包括眉毛、嘴巴、脸颊等表情,当然引入非手动特征后,在这种情况下,中国手语理论上可组成无限个音韵特征,计算代价庞大,下一步需要解决这个问题。此外,手势的复杂程度分布不均匀,若能将音韵信息的频率引入到监督信息中,可提高模型的识别准确率。因此,改进神经网络的损失函数,使每一维的监督信息不再平等区分,这也是下一步要解决的问题。
5 小结
本文提出的先标注后文本的思路,是直接从语言学的角度得出手语文本,因此无论是静态手势,还是动态手势,其识别率都明显高于基于计算机视觉的识别率。我们提出的技术验证了手语智能认知的可行性与准确性,下一步的研究目标是提高识别速度,缩短响应时间。今后将继续进行手势识别训练的样本获取工作,扩充手语语料库的样本数,并将面部表情等非手动特征与手部动作结合起来,从而进行多感知机的语言认知计算领域深层次问题的研究。
[1]Stokoe W C. Sign language structure: An outline of the visual communication systems of the American deaf [J]. Studies in Linguistics: Occasional Papers, 1960, 8: 3-37.
[2]Vogler C, Metaxas D. Parallel hidden Markov models for American Sign Language recognition[C]//Proceedings of the IEEE International Conference on Computer Vision , Corfu, Greece: IEEE press. 1999, 1:116-122.
[3]Lichtenauer J, Hendriks E, Reinders M. Learning to recognize a sign from a single example [C]//Proceedings of 2008 the 8th IEEE International Conference on Automatic Face & Gesture Recognition (FG’08). Amsterdam, Netherlands: IEEE Press, 2008: 1-6.
[4]Bowden R, Windridge D, Kadir T, et al. A linguistic feature vector for the visual interpretation of sign language [C]//Proceedings of the European Conference on Computer Vision, 2004. Springer Berlin Heidelberg, 2004: 390-401.
[5]Kadir T, Bowden R, Ong E J, et al. Minimal Training, Large Lexicon, Unconstrained Sign Language Recognition [C]//Proceedings of the British Machine Vision Conference, London, UK. 2004: 1-10.
[6]Cooper H, Bowden R. Large lexicon detection of sign language[M]. Human-Computer Interaction. Springer Berlin Heidelberg, 2007: 88-97.
[7]Jantunen T, Takkinen R. Syllable structure in sign language phonology[M]. Brentari(ed.). Sign Languages. Cambridge: Cambridge University Press, 2010: 312-331.
[8]吴军,王作英. 一种基于语言理解的输入方法--智能拼音输入方法 [J]. 中文信息学报, 1996, 10(2): 56-61.
[9]Valli C, Lucas C. Linguistics of American Sign Language: An introduction [M]. Gallaudet University Press. 2000.
[10]Liddell S K, Johnson R E. American Sign Language compound formation processes, lexicalization, and phonological remnants [J]. Natural Language & Linguistic Theory, 1986, 4(4): 445-513.
[11]Bengio Y. Learning deep architectures for AI[J]. Foundations and trends in Machine Learning, 2009, 2(1): 1-127.
[12]Bengio Y, Lamblin P, Popovici D, et al. Greedy layer-wise training of deep networks[J]. Advances in neural information processing systems, 2007, 19: 153.
[13]Vincent P, Larochelle H, Lajoie I, et al. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion [J]. The Journal of Machine Learning Research, 2010, 11: 3371-3408.
[14]Bengio Y, Yao L, Alain G, et al. Generalized denoising auto-encoders as generative models [M]. Advances in Neural Information Processing Systems. 2013: 899-907.
[15]Salakhutdinov R, Hinton G. Semantic hashing [J]. International Journal of Approximate Reasoning, 2009, 50(7): 969-978.
[16]Vincent P, Larochelle H, Bengio Y, et al. Extracting and composing robust features with denoising autoencoders [C]//Proceedings of the 25th international conference on Machine learning. Helsink: ACM Press, 2008: 1096-1103.
[17]Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks [J]. Science, 2006, 313(5786): 504-507.
[18]Tieleman T. Training restricted Boltzmann machines using approximations to the likelihood gradient [C]//Proceedings of the 25th international conference on Machine learning. Helsink: ACM Press, 2008: 1064-1071.
猜你喜欢
红领巾·萌芽(2019年9期)2019-10-09
活力(2019年15期)2019-09-25
作文周刊(高考版)(2019年9期)2019-04-29
小学科学(学生版)(2018年12期)2018-12-19
小学阅读指南·低年级版(2017年6期)2017-06-12
北方文学·中旬(2017年1期)2017-03-15
课外语文·下(2015年9期)2015-11-28
青少年科技博览(中学版)(2015年8期)2015-10-28
长江学术(2015年1期)2015-02-27
世界文学评论(2014年2期)2014-04-12
