
面向专业文献知识实体类型的抽取和标注
2018-04-04 01:12伍思杰蔡瑞初郝志峰
中文信息学报 2018年1期
温 雯, 伍思杰, 蔡瑞初, 郝志峰,2
(1. 广东工业大学 计算机学院,广东 广州 510006;2. 佛山科学技术学院,广东 佛山 528000)
0 引言
有数据显示[1],截至2013年年底,国家数字图书馆数字资源总量已达到874.5TB,其中自建数字资源量为737.9TB,网络信息采集量达45.7TB,外购中外文数据库共计273个,文津搜索汇集的元数据已达2.9亿条。随着互联网的快速普及和硬件存储技术的发展,人们可以轻松地在不同的设备上浏览、获取各类数字资源,也可以通过众多的学术数据库或学术搜索引擎获取所需的专业文献,如Google Scholar、百度学术、CNKI、万方数据等。由此看来,从互联网上获取海量的电子资源的确成为了一件轻松简单的事情,但是随之出现的问题是,现有的知识服务已经无法满足人们对信息“快速、简单、准确”的获取需求。面对这样的知识服务需求,我们需要针对专业文献文本进行实体识别并抽取出实体的类型信息,建立结构化的专业知识体系,以辅助用户进行文献检索。在这类专业领域的文献中有着非常多的核心知识点和关键术语,且这些知识点和术语随着时间不断演进。譬如在计算机领域中,这类术语表达的是该文献的研究问题、核心算法或关键模型等,而用户最关心的也正是这类术语,它们能告诉用户这篇文献研究的核心问题及其解决方法。相对于一般的实体而言,这类具有专业领域特性、能概括表达文献中核心知识点的术语,我们将其定义为知识实体。专业文献上的知识实体抽取是一类特殊的实体抽取问题,有助于实现专业文献信息的结构化描述。而实体类型的标注则是实体抽取的一个重要组成部分,对后续实体关系的识别也具有重要的意义[2]。
专业文献中的知识实体具有其独特性。我们发现,与传统的人名、机构名等实体需要借助外部信息来进行类型判断不同,知识实体的类型往往会以名词短语的形式出现在知识实体的内部,例如“条件随机场模型”作为一个知识实体,出现在内部的“模型”正是我们所需抽取的类型,我们把这类出现在实体内部并可以明确判断实体类型的词,称为类型指示词。根据这个特点,我们对知识实体做了一系列的统计实验,发现知识实体中出现的类型指示词具有以下的特性: (1)大部分知识实体的类型词都存在于实体内部,大多数知识实体都会以“专业知识名称+类型指示词”的方式来准确描述。(2)类型指示词的词性绝大部分是名词,样本数据中约有94.6%的类型指示词被分词工具判定为名词词性。(3)类型指示词有明显的位置特征,大部分类型指示词都位于知识实体的末端。在上述分析实验的基础上,我们提出了一种结合启发式规则的多标签加权传播的方法(简称 HRA+MLW-LPA),以实现知识实体类型的抽取和标注。该方法结合了无监督的启发式规则方法与半监督的标签传播算法方法,利用类型指示词的独有特性实现了大部分知识实体的无监督类型标注,再用多标签加权的标签传播算法对剩下的未标注数据进行标签传播,既减少了人工标注的工作量,又增加了类型定义的灵活度。实验证明,这种方法较传统的类型抽取方法有更好的效果。
本文其余章节结构如下: 第一节综述相关的研究;第二节给出问题定义;第三节是知识实体在类型抽取上的一些特性分析实验;第四节给出基于启发式规则的类型标签抽取方法和多标签加权传播方法,包括方法的思路和详细算法步骤;第五节是针对提出方法的对比实验和实验结果分析。最后第六节总结全文和讨论将来的工作。
1 相关研究
1.1 实体类型抽取的相关研究
在实体类型抽取方面,主流的方法主要包括四种: 基于已有知识库的方法、基于模式匹配的方法、基于机器学习的方法和基于词语分布相似度的方法。
基于已有知识库的方法主要是利用人工构建的知识库资源对实体进行类别标注或者类型标签传播,常用的知识库主要包括WordNet、Wikipedia、Freebase、Linked Open Data(LOD),以及国内的“百度百科”和哈工大的“同义词词林”[3]等。基于这类方法的研究已经有很多,得到的效果也相当不错,例如,2008年,Suchanek等人[4]结合Wikipedia和WordNet,利用WordNet过滤掉Wikipedia中较差的类别标签,准确率达到95%以上。相类似的还有2010年Ni等人[5]利用LOD资源库对未知实体进行开放分类,Dojchinovski等人[6]利用维基百科的类别体系对命名实体进行分类和消除歧义。这些方法由于借用了人工构建的已有知识库,因此准确率比较高,但是此方法的缺点是无法处理维基百科之外的实体,例如专业领域文献的实体往往无法从通用知识库查询获得。
基于模式匹配的实体类型抽取起源较早,在1992年Hearst[7]就提出了利用模式匹配或者是启发式规则匹配的方法,制定了一些抽取模式(pattern)和规则来抽取实体类型。随后许多学者在Hearst工作的基础上对类型抽取进行深入研究,例如Evans[8]以互联网上的数据为语料库,利用Hearst的模式匹配方法对互联网的数据进行搜索匹配,得到了不错的效果。除此以外,KnowItAll系统[9]和NELL系统[10]等也是基于模式匹配的方法,结合自然语言的模式和网页表格中的结构化信息来进行类型抽取。
基于机器学习的方法是近年来比较热门的信息抽取方法,主要是将实体通过一定粒度的分词后进行特征提取,结合词法和句法特征转换成特征向量,然后采用HMM[11-12]、SVM[12]和CRF[13]等机器学习模型比较特征向量之间的相似度,然后进行分类或标注,例如宋毅君[14]等人提取块层面特征,利用条件随机场模型实现了汉语框架语义角色的自动标注。相对于模式匹配的方法来说,这类方法特征提取简单有效,而且不需要具有专业知识的人去做大量的分析和模式发现工作。但是,基于机器学习的方法的缺点是对特征的依赖性特别强,特征应该最大限度地包含实体的信息,包括尽量多的上下文信息,以提高特征的区分度。所以,对于特征区分度不明显或者上下文较少的短文本来说,基于特征的方法效果并不是很好。因此,现在的研究又开始考虑采用将基于模式匹配和基于机器学习的方法相结合的策略来寻找效果更佳的信息抽取方案,例如张传岩等人[15]提出一种基于启发式规则的方法,结合SVM和CRF模型实现的Web实体活动抽取,实验结果显示该方法在多个领域取得较好的效果,类似的方法也可以推广到类型信息抽取。
基于词语分布相似度的方法相对前面两种方法比较少见,这种方法主要是基于一种假设: 语义分布范围越广的词,它的上下文也越广,而语义分布范围窄的词,它对应的上下文也相对较窄。基于这个假设,研究者们提出各种词与词之间的相似性度量方法,例如,Weeds的研究中[16]使用相似度度量公式比较两个词u和v的上下文的包含程度,他认为上下文包含程度和相似程度越高,那么u越有可能是v的类型概括词。类似的方法还有很多,研究者们大多数都是基于Weeds的上下文相似度度量公式进行改进的,例如Clarke[17]、Lenci[18]、Basile[19]等人的研究。在2010年,Shi等人[20]比较了基于模式匹配的方法和基于词语分布相似度的方法,实验结果表明基于模式匹配的方法更适用于名词类短语的类型抽取,而基于词语分布相似度的方法更适用于动词、形容词等其他词性的类型抽取。
1.2 领域实体的相关研究
近年来,在面向特定领域的实体识别研究方面已经开展了一些研究,如Yoshida等人针对生物医学领域实体的研究[21],毛存礼等对有色金属领域实体的研究[22],郭剑毅等对旅游领域命名实体的研究[23],还有针对商务领域产品领域实体的研究[24],等等。
专业领域的知识实体类型抽取是实体类型抽取中的一个特殊问题。目前,针对这类专业词语较多、长度较短的知识实体的类型抽取研究还很少。根据我们的统计分析,这类知识实体文本具有以下几个较为鲜明的特点: 字数较少,存在较多专业名词的英文简写。
(1) 专业性强,实体包含的专业词汇较多,分词难度相比互联网上的社交文本要难得多,但是由于具有专业性强的特性,专业文献也有相对固定的语法和写作规律。
(2) 类型较多,在人工标注的过程中,我们发现专业领域的知识实体的类型比较多,不能像ACE[25]那样明确地定义实体类型,所以知识实体的类型集需要是可扩展的。
(3) 文本规范性强,专业文献属于行业内的技术文献,行文较为规范和准确。
相比而言,已有的研究大多针对互联网上常见的新闻文本[26]、微博[27]、Twitter[28]、Facebook等进行实体抽取。这类文本一般是与人物、时间、地点、活动等常见实体相关,而且大多数文本用语趋向口语化、网络化,文本表述要求并不严格。而专业文献由于文本规范性较强,文献标题和摘要都按照某种规范进行书写,导致即使不同类型的知识实体,它们上下文也比较相似,甚至句法上大致是一样的。所以,这类知识实体我们很难通过基于上下文特征的机器学习方法进行类型标注或分类。另外,知识实体的专业性也使得我们无法进行大量的人工标注, 这样的标注需要一些专家学者花费大量时间去研究标注,因此有监督或者半监督的机器学习模型也不太适用。针对这个问题,已有的做法是分析实体及其上下文特性,识别出实体及其类型在上下文语句内的呈现关系,例如: 2011年,Zhang等人[29]基于模式匹配的方法,提出了一种证据融合和传播相结合的方法,利用such as、is-a等简单的模式从语句中提取出实体及其对应的类型词,再结合相近相似的其他语句进行证据融合和传播,最后通过计算出实体和类型之间的相关性得分抽取出类型,取得了不错的效果。这种基于模式匹配的方法可以推广到专业文献的类型抽取问题上,我们可以分析实体及其上下文的或者实体内部的类型特征,发现类型出现的频繁模式并建立启发式规则,从而实现无监督的部分知识实体类型抽取,解决了人工标注的麻烦。但是,这种模式匹配的方法只能对部分实体进行类型抽取,仍然还有一部分实体无法使用固定的模式进行类型抽取。针对这个问题,我们参考Lin等人在2012年的研究工作[30],他们以Freebase的1 000多个类型体系为基础,结合标签传播算法将类型信息从维基百科已有的实体传播到未标注类型实体中,大大提高了实体的类型标注率。由此看来,标签传播算法可以弥补模式匹配方法的不足,因此我们考虑结合模式匹配方法和标签传播算法的优点,提出一种融合启发式规则和多标签加权标签传播算法的类型抽取方法,对这类专业领域的知识实体进行类型抽取,其流程如图1所示。
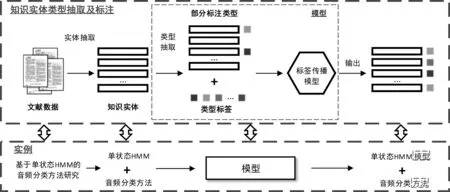
图1 知识实体类型抽取及标注流程
2 问题定义及探讨
2.1 问题定义
本节首先给出知识实体和类型指示词的定义,然后明确定义类型抽取和标注任务。
定义1(知识实体,knowledgeentity)知识实体是指在专业文献中能表达一个关键知识点的术语实体。例如,图1中的“单状态HMM” 和“音频分类方法”。
定义2(类型指示词,typeindicationwords)类型指示词是指出现在一个实体内部或上下文中且能明确指示出该知识实体类型的词语。在专业文献中,知识实体的类型往往会以短词的方式直接出现在实体内部,例如“音频分类方法”作为一个知识实体,而出现在内部的“方法”正是我们所需抽取的类型,这类出现在实体内部并可以明确判断类型的词即类型指示词。
定义3(知识实体类型的抽取,typeextractionofknowledgeentity)知识实体类型的抽取是指根据专业文献术语表达的规律,归纳并提取出类型指示词。例如 “音频分类方法”中 的“方法” ,“支持向量机模型”中的“模型”。
定义4(知识实体类型的标注,typelabellingofknowledgeentity)知识实体类型标注是指在实体类型抽取的基础上,对具体的术语实体进行类型的标注。如图1中,将 “单状态HMM”标注为“模型”;将“音频分类方法”标注为“方法”。
本文的目标是解决知识实体类型抽取和标注的问题。如图1所示,需要首先对所爬取的文献数据进行实体抽取,得到知识实体数据集。在此基础上对知识实体进行类型抽取和部分标注,获得比较完整的类型标签集与部分标注的实体集;进而将其转化为半监督的标签传播问题,设计相应的算法,最终完成知识实体的类型标注。
2.2 知识实体边界及歧义问题探讨
除了需要对知识实体类型及其任务定义以外,我们还需要探讨知识实体的边界问题和知识实体类型的歧义问题。
(1) 知识实体的边界问题。相对于其他命名实体的边界划分问题而言,知识实体是从相对较短的论文标题中获取的,而中文论文标题的命名一般遵循一定的规律性,例如出现较多的模板是: “基于XX的XX(研究)”,“一种XX的XX”,“面向XX的XX(研究进展)”等。因此,我们只需要利用条件随机场模型识别出这类模板,标记出知识实体之间的分割字符,就可以较好地解决知识实体的边界识别问题。同时,我们也在特征中加入“基于”“面向”“研究”这类前导词和后导词的标识,使得模型划分知识实体边界时更加精确。因此,抽取到的知识实体指的是同一层次的,不包含递进、修饰等关系的知识整体。这类知识整体中可能包含一个实体多个类型的情况,例如“人脸识别模型和方法”。
(2) 知识实体类型歧义问题。假设知识实体的边界已经正确划分,我们的任务是从划分好的知识实体中识别出类型指示词。我们首先对存在于实体内部的类型词进行抽取,再利用这部分抽取结果对剩下未能从实体内部抽取的实体进行进一步的类型抽取,故不考虑类型词在实体外部的情况。当类型词在实体内部时,知识实体的类型可能出现歧义问题。例如“人脸识别模型和方法”“音频分类模型与方法研究”。上述例子中,与一般的一个实体对应一种类型不同,一个实体中包含两个类型词。针对这种知识实体类型歧义问题,我们需要特别讨论,如果出现一个知识实体多个类型(同时存在于一个抽取到的知识整体)的情况,我们需要分析该多个类型是否并列关系,例如“和”“与”“及”等并列关系词,如果是并列关系,则多个类型均为该实体的类型词,该知识实体包含多个类型标签。如果类型词之间不是并列关系,例如修饰关系“一种改进条件随机场模型的方法”,则在知识实体抽取的过程中,会把“条件随机场模型”抽取出来,作为一个知识实体的最小整体,并判断为“模型”。
3 知识实体的类型抽取问题分析
本文通过真实数据的一些统计实验来论证和说明专业文献知识实体类型词指示词的具体特点。我们设计网络爬虫共爬取计算机类专业文献56 462篇,每一篇专业文献具体包含标题、摘要、作者和关键词等信息。其中,关键词信息主要用于初期的用户字典建立,标题信息用于进行初期的知识实体识别,摘要信息可以在后续标注过程中辅助提高识别准确率。接下来,我们介绍知识实体识别的具体方法,然后基于抽取到的实体进行类型指示词特性分析。
3.1 知识实体识别
在第2节中,我们对知识实体进行定义,并对每一篇专业文献的标题进行实体识别。前面的大量工作[13-14,23]表明条件随机场对实体标注有较好的效果,因此我们考虑使用条件随机场模型来识别标注出标题中的知识实体。具体方法如下: 首先以关键词数据作为用户词典,对标题数据进行中文分词和特征抽取(词性和位置特征)。然后抽取部分样本进行人工标注,作为模型的输入数据。特征模板定义并利用条件随机场模型进行训练得到标注结果。最后,由于条件随机场标注模型是概率模型,出现频次较少的特殊样本容易出现误标和边界出错问题。因此,我们利用半监督迭代优化的方法,即筛选出准确率较高的样本继续迭代,重复训练及标注过程,以提高最终准确率,降低标注错误发生的概率,最后共抽取出77 364个知识实体。
3.2 知识实体的类型指示词特性分析
我们从77 364个知识实体中随机抽取500个知识实体作为样本数据来进行实体类型的人工标注,并进行统计和实验。可以发现,知识实体类型指示词(以下简称“类型词”)具有以下独有的三个特点。
(1)类型指示词大部分包含在实体内部。样本数据的统计结果见表1。可以看出,样本数据的类型词有74.8%是包含在实体内部的,例如“支持向量机模型”或“模拟退火算法”的类型分别是“模型”和“算法”,这类知识实体的类型词直接出现在实体内部;而剩下25.2%的样本数据的类型指示词并不出现在实体内部,这是由于部分知识实体的表述可以省略类型词但不影响理解,例如“CRF”和“HMM”,类型词不出现在知识实体内部,但是我们通过其他文本的学习可以得知“CRF”和“HMM”的类型都是属于“模型”。 因此,我们考虑可以首先对存在于实体内部的类型词进行抽取,再利用这部分抽取结果对剩下未能从实体内部抽取的实体进行进一步的类型抽取。

表1 样本数据统计结果
(2) 类型指示词词性大多数是名词。本实验使用ICTCLAS2016中文分词工具对样本数据中人工标注的类型词进行词性识别,实验结果如图2所示,可以看出,有94.6%的类型词是名词,而极少部分(5.4%)词汇属于其他词性。在这名词以外的词性中,还包含着3.2%的未定义词性,通过观察发现这部分未定义词大部分也是一些专有名词。
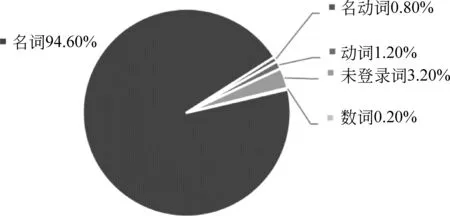
图2 类型词词性统计饼图
(3)类型指示词位置往往在实体的末端。我们对类型词包含在实体内部的374个实体进行实验,结果如图3所示。从图3可见,大部分类型词(318个)都位于实体的最末端位置。由此可以判断,如果知识实体内部存在类型词,那么知识实体的最后一个词很有可能是所需抽取的类型词。
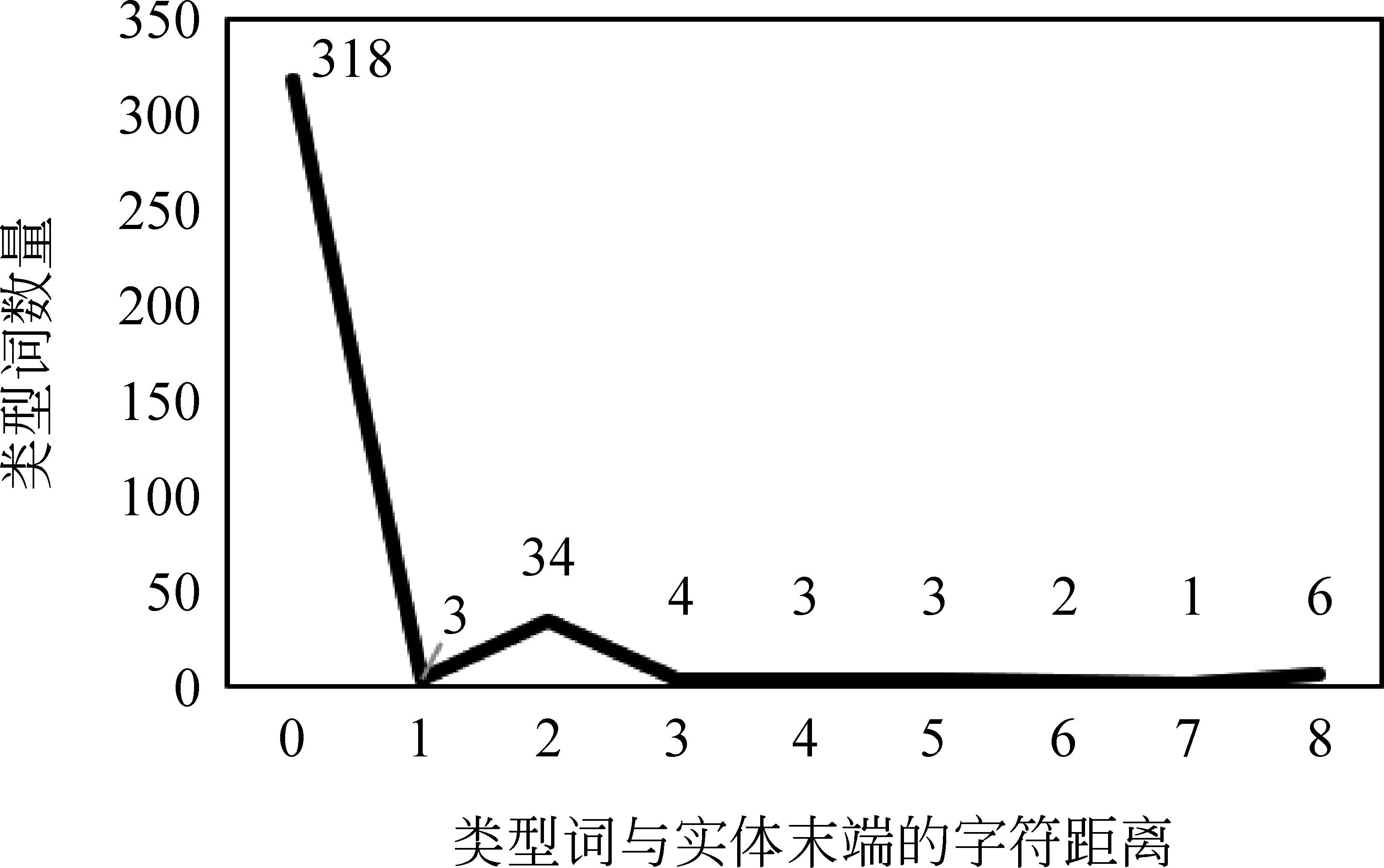
图3 类型词位置统计图
4 结合启发式规则的加权多标签传播类型抽取及标注方法
4.1 方法思路
前面的实验分析统计了知识实体类型词的特点,从实验结果可以看出,知识实体类型词在词性、位置上有明显的特征。本文希望通过这些明显的特征建立启发式规则,然后基于这些启发式规则进行无监督的类型词自动抽取,得到知识实体类型的初步抽取。但是,这种基于启发式规则的方法只能抽取到在实体内部出现的类型词,从3.2节的实验我们可以知道,还有很大一部分的类型词并不在实体内部。因此,我们在启发式规则部分标注数据的基础上,提出一种基于多标签加权的标签传播算法,简称MLW-LPA(label propagation algorithm based on muti-label weighted),对未成功抽取类型的知识实体进行类型标签传播及标注。接下来,我们将在4.2节和4.3节分别介绍基于启发式规则类型抽取方法和基于多标签加权标签传播的类型标注方法。
4.2 结合摘要的基于启发式规则的类型抽取方法
方法的第一步是利用无监督的基于启发式规则的方法识别并抽取出知识实体中显式出现的类型词,得到标签集合和部分已标实体数据,这也将作为后续的半监督标签传播方法的输入数据。由于基于启发式规则的方法是无监督的自动抽取方法,它不需要传统半监督标注方法中的大量人工标注,大大优化并减少了整体抽取时间和资源。另外,基于规则的方法抽取到的类型标签集是作为整个方法的标签输入,所以必须具备足够的可靠性和准确率才能确保后续半监督标签传播方法的输出结果良好。为了提高基于规则方法的准确率,我们增加了对文献摘要数据的类型抽取。首先,对文献的摘要数据进行知识实体模糊匹配识别,具体方法是先对抽取到的知识实体进行类型词去除,然后把去除掉类型词的知识实体作为用户词典,再对摘要数据进行中文分词,再利用编辑距离计算相似度的匹配方法去匹配摘要中的知识实体,并分析该知识实体位置后面紧接着的词,得到的就是该知识实体在摘要中对应的类型词。然后是基于启发式规则的方法对摘要得到的知识实体进行类型词抽取,得到摘要知识实体的类型词标签输出。结合摘要的基于启发式规则的类型抽取方法的具体流程如图4所示。
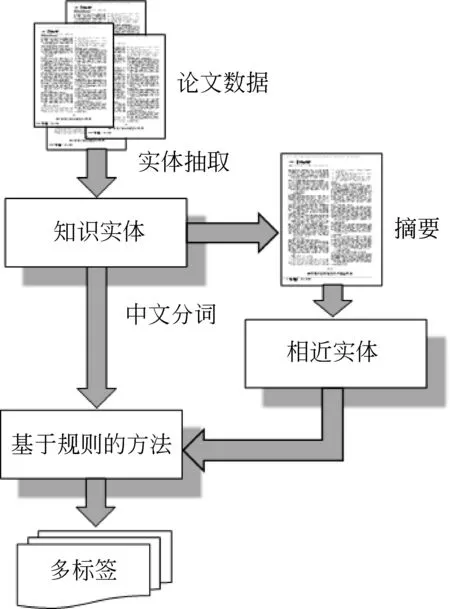
图4 基于启发式规则的类型抽取方法流程图
通过知识实体的类型信息抽取特性分析实验,我们可以得到以下启发式规则:
启发式规则1: 设知识实体ei=(w1,w2,w3,…,wn-1,wn),n≥1,组成词wi的词性为ci。如果ci为名词,则把wi加入类型词候选集Ti。
启发式规则2: 设知识实体ei=(w1,w2,w3,…,wn-1,wn),n≥1,wn是ei的最后一个词,那么把wn加入类型词候选集Ti;如果wn前存在一个或多个wk与wn为并列关系,那么把wk也加入类型词候选集Ti。
基于上述启发式规则,对于同时满足规则1和规则2的候选词,则加入类型标签集合,具体方法步骤如表2所示。

表2 基于启发式规则的类型抽取方法
基于规则的方法是无监督的方法,因此标注的结果不一定准确,有可能会出现错误或不存在的类型标注。为了提高基于规则方法标注的准确度和保证抽取到类型的合理性,我们提出了一种基于频次的类型标签筛选方法。
首先,我们来定义不可靠类型标签,它应该符合以下几个特征:
(1) 该类型在知识实体中出现的频次很少;
(2) 属于该类型的知识实体的数量很少,一般指一个类型只对应一个知识实体;
(3) 在该类型的知识实体中,知识实体也只包含该类型的标签,不包含其他类型的标签。
如果符合以上几个特征,那么我们可以认为这个类型标签是不可靠的,应该进行筛选。为此,我们对类型词的频次进行统计,具体的统计结果如表3所示。从统计结果可以发现出现频次越多的类型词数量越少,大量的类型词只出现1~2次,而只有少数的类型词出现频次极高,这说明了专业领域里的大部分知识实体集中归类在少数的几个类型里。而出现频次1~10次的类型词的数量高达2 826个,占了类型总数的89.40%,我们认为这个分组(类型词出现频次1~10)符合特征1的要求。所以,以这个分组的类型为初始筛选类型集合,筛选出同时符合特征(2)和特征(3)的类型,也就是类型和知识实体是一一对应的类型。最后,我们对这些不可靠类型和对应的知识实体从数据集中进行清理,以保证类型标签的可靠性和合理性,从而进一步提高基于规则的类型抽取方法的准确度。
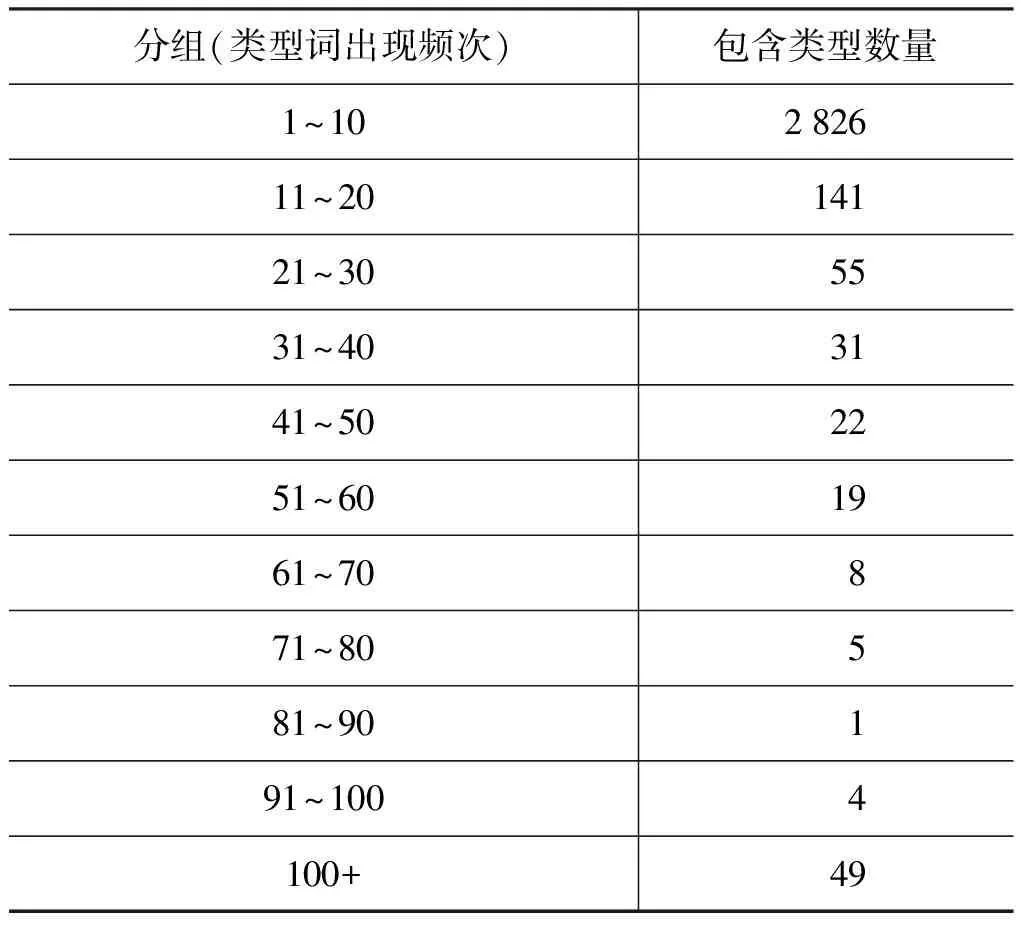
表3 基于类型词频次的统计结果
4.3 基于多标签加权的标签传播算法
本节主要以4.2节中的基于规则的类型抽取方法输出的多标签数据为输入,提出一种基于多标签加权的标签传播算法,根据知识实体间的相似度把4.2节中的已标知识实体的类型标签传递给未标知识实体,从而解决4.2节中基于规则的方法的召回率偏低的问题。
标签传播算法[31](LPA)由Zhu等人于2002年提出,它是一种基于图的半监督学习方法,其基本思路是用已标记节点的标签信息去预测未标记节点的标签信息。标签传播算法把标签信息从任意一个节点通过加权的各边循环地传递到附近的其他节点,最终达到全局稳定的状态,从而推导出未标签节点的标注信息的目标。节点之间边的权重越大,标签信息越容易在节点间传递。因此,样本节点越相似,它们拥有同样的标签的可能性就越大[32]。
为此,我们首先给出如下定义:
定义1转换概率矩阵T:
在公式(1)中,Tij表示从节点xj转移到节点xi的概率,也就是知识实体ej转移到知识实体ei的概率。这里转移概率Wij可由公式(2)计算得到:
其中,Sij是知识实体ei和ej的相似度度量,本文中使用编辑距离作为度量方法,∂参数用于调整Sij的比例。这里我们设∂为Sij的均值。
定义2编辑距离编辑距离又称Levenshtein距离,也叫做 Edit Distance,是由苏联科学家 Vladimir Levenshtein于1965年提出的,它是一种常用的距离函数度量方法,且在文本相似度检测领域得到了广泛的应用,编辑距离算法的具体步骤可以参考文献[33]。
文本相似度计算: 编辑距离越大,相似度越小。假设源字符串s与目标字符串t长度的最大值为Lmax,编辑距离为LD,相似度为S,则利用公式(3)可以计算出S:
定义3类型标签矩阵Y设第一层抽取中成功抽出类型词的知识实体个数为l,未能抽出类型词的知识实体个数为u,则定义类型标签矩阵Y是一个(l+u)×R矩阵,R为已抽取类型标签的去重个数。设知识实体ei在第一层类型标注后有k个类型标签,Cik是第i个实体的k标签的出现频次。
其中,Wik是知识实体ei拥有类型标签k的权重,以标签k在ei中出现的频率来度量。当知识实体ei拥有类型标签k时,则Yij=Wik,否则Yij=0,表示无该标签。
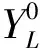

表4 基于多标签加权标签的传播算法
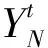
多标签加权传播的具体过程如图5所示,图左侧的是已标签的l个实体及其k个标签数据作为输入数据,每一个标签有自身对应的权值Wik,而图右侧的是将进行标签传播的n-l-1个未标实体,在标签传播之前,最右侧的输出标签是不存在的。如图5所示的例子,已标实体e1和e2同时满足对实体el+1的标签传播条件和e2同时满足对实体el+1的标签传播条件时,实体e1把标签1、2、3传播到实体el+1,而最右侧新标签1、2、3对应的新权值为Wik*Tij。 然后,实体e2把标签2、4、5传播到实体el+1,其中标签4和标签5的新权值也是Wik*Tij,而标签2中已经有权值,所以进行权值的累加,因此标签2中权值为W12*T1,l+1+W22*T2,l+1。
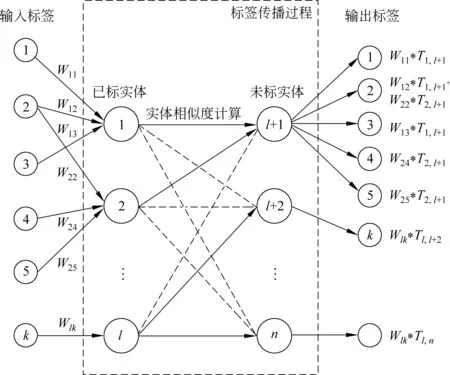
图5 多标签加权的标签传播过程
5 实验及结果分析
5.1 实验设置与评价
本文使用网络爬虫对中国知网(http://www.cnki.net/)的计算机类论文进行爬取,并以爬取到的论文题目、论文关键词及论文摘要作为实验数据,共包含56 462篇计算机类核心期刊论文。以论文关键词作为用户词典,我们对论文标题进行中文分词及知识实体抽取,共抽出77 364个知识实体。其中,将人工标注好类型的500个知识实体中的知识实体部分(未标注)作为输入数据,而其人工标注的类型只作为最终的客观评价标准,并将以准确率(Precision)、召回率(Recall)和F1系数(F1-Measure)作为评价指标。F1系数计算方法见公式(6)。
为了验证本文提出方法的有效性,并与其他传统方法进行比较,本文设计了三项任务:
任务1: 通过实验得到知识实体类型分布规律,总结并定义常见的几个知识实体类型,用作后续实验的已定义类型。
任务2: 检验文献摘要信息对基于启发式规则的方法的影响。
任务3: 验证本文提出的HRA+ MLW-LPA类型抽取方法比传统的CRF方法更适合于专业领域论文献中知识实体类型的抽取任务。
5.2 实验结果及分析
5.2.1数据基本情况统计
在第2节中,我们只给出了知识实体类型的概念定义,并没有具体定义知识实体类型有哪几种,是因为在人工标注过程中发现知识实体类型比一般文本的实体类型多,无法像ACE那样明确地归类及定义。另外,我们认为不同领域的类型定义也会各不相同,只能通过对该专业领域的大量知识实体进行初步抽取的类型词进行统计后才能确定。因此,我们对计算机领域抽取的共77 364个知识实体进行实验,统计其类型分布规律,并给出计算机领域知识实体类型的具体定义。
本实验通过无监督的启发式规则方法对知识实体的类型词进行抽取,然后对不同类型词出现的频次进行统计,结果如表5所示。其中,null是指本实验中无法抽取到类型词知识实体的标识,比率1是指包括null类型在内的所有知识实体(共77 364个)中该类型词所占的比率;比率2是指除去null类型,只统计实验中成功抽取到类型词的知识实体(共77 364-26 442=50 922个)中该类型所占的比率。
结果表明,通过无监督的启发式规则方法对知识实体的类型词进行抽取已有较好的效果,共抽取到3 160种类型,知识实体类型词的抽取率达到65.82%。从表5可以看到,“算法”类别的知识实体最多,共抽取到8 480个,占所有抽取到类型的10.96%。排在2~5位的依次是“方法”“模型”“系统”“技术”,从这些类型词可以看出,计算机领域主要研究的是算法、方法、模型和系统等,符合计算机领域算法、模型多等偏工程性的特点。

表5 不同类型词出现频次统计表
另外,通过表5还可以发现: 在专业领域的知识实体类型中,不同类型词的数量存在着极端不均衡的现象。例如,“算法”类型的知识实体有8 480个,而频次最少的“特征”类型只有436个。为了进一步考察类型词出现频次的规律,我们对类型词出现的频次进行降序排序,可以发现,类型词出现频次与类型词排名区间满足幂律分布,如图6所示。其中,x轴表示类型词频次的降序排名区间,y轴表示对应x区间类型词的出现频次。从图中拟合的乘幂曲线是一个幂律分布曲线,满足函数y=kx∂,其中k=13 021,∂=-1.254,相关系数R2=0.992。
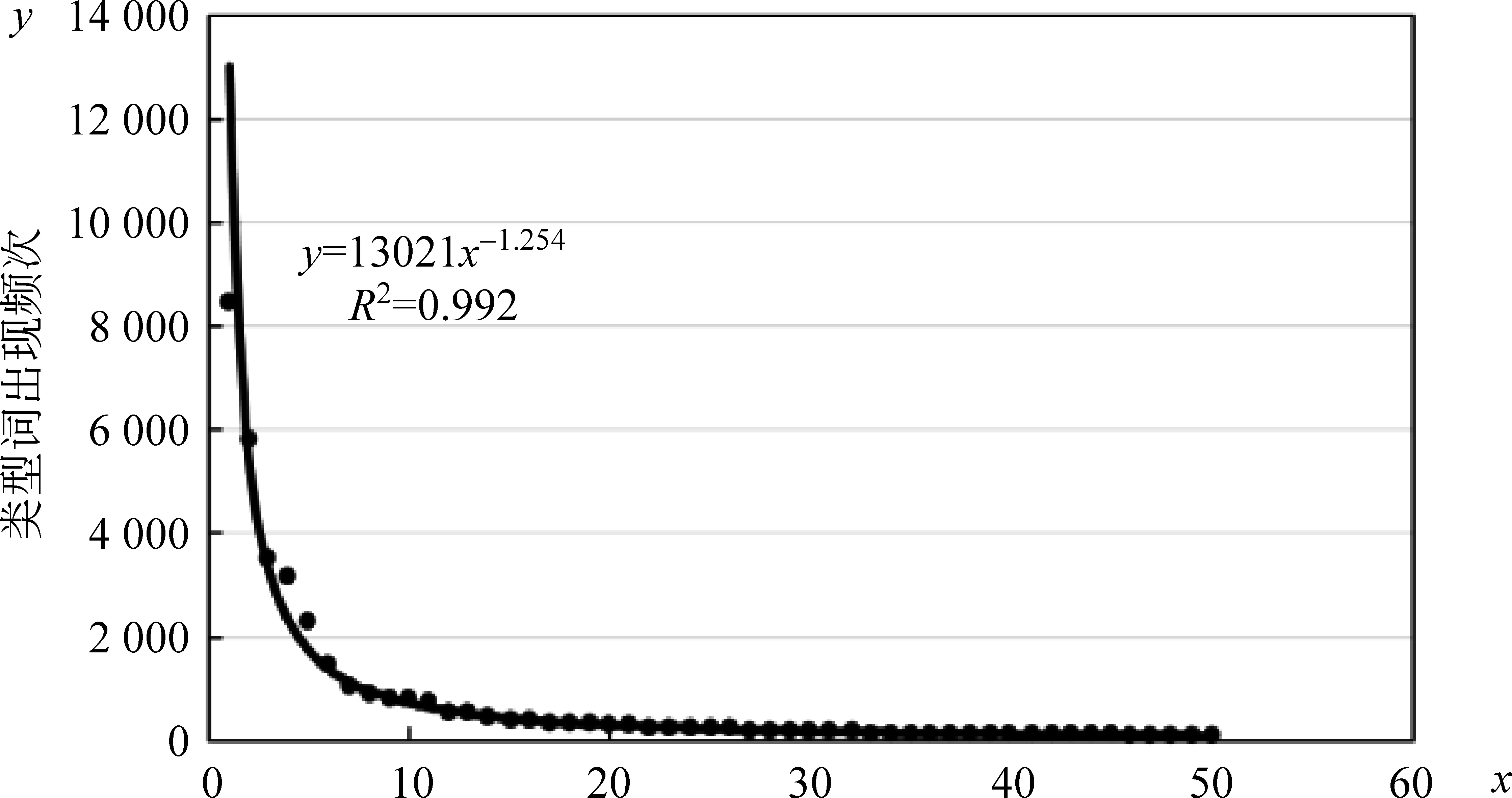
图6 类型词出现频次与排名区间幂律关系图
5.2.2实验对比
为了检验任务2中摘要信息对知识实体类型抽取的影响和任务3中的HRA+MLW-LPA方法的有效性,我们进行了一系列的对比实验。MLW-LPA和CRF的输入数据均为HRA方法中输出的多标签数据。其中在CRF方法的实验中采用CRF++工具,规范化算法选择CRF-L2,拟合参数c=1,最少特征出现次数f=1,线程数p=4。
从3.2节的类型指示词特性分析可以知道,知识实体类型的分布符合幂律分布,即大量的知识实体集中归属于少部分的类型,而剩下的少量知识实体类型分布十分分散,基本上属于不同的类型。所以,为了对比不同知识实体类型分布下的实验效果,我们首先将知识实体按照类型进行分组,并按照每个类型所包含的知识实体数量进行降序排序,然后按照基于均衡知识实体样本数的规则(也就是使得每个分组所包含的知识实体数量尽可能相等)对类型分组后再进行进一步的分组,具体分组结果如表6所示。
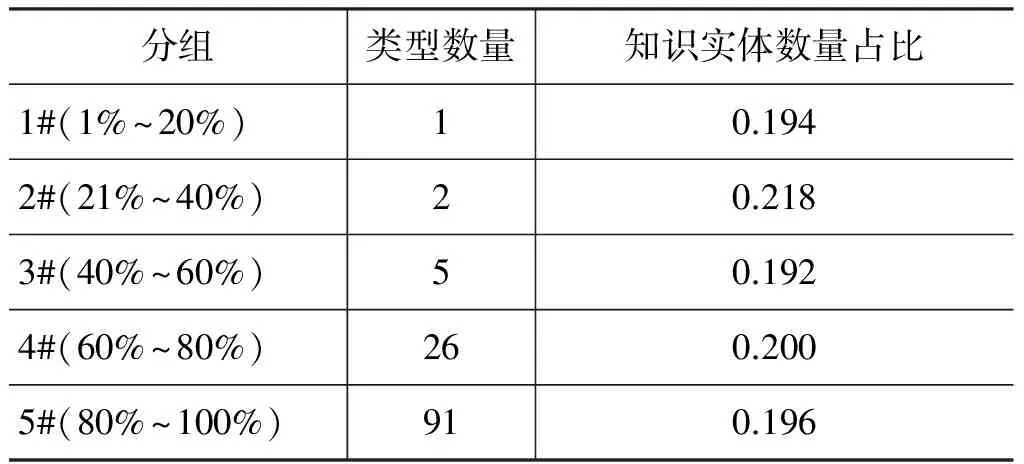
表6 基于均衡知识实体样本数的分组结果
我们设计了两个对照组来验证摘要辅助信息是否对知识实体类型抽取有影响,分别是HRA和HRA+Abstract、HRA+MLW-LPA和HRA+Abstract+MLW-LPA,结果如表7所示,从中可以看出: 结合了摘要(Abstract)的HRA和MLW-LPA方法比没有结合摘要辅助抽取的方法的效果明显要好。从表8的结果可以看出,在各个分组中,HRA+Abstract方法的F1系数均比HRA方法高,其中分组1提升最多,F1系数提高了8.3%,HRA+Abstract+MLW-LPA方法和HRA+MLW-LPA这个对照组呈现的结果也一样,结合摘要的方法对知识实体类型抽取有明显的提升效果。

表7 几种不同方法的总体效果对比
几种方法的总体效果对比如表7所示,从表中可以看出准确率最高的是HRA+MLW-LPA方法,其次是HRA+Abstract+MLW-LPA方法,略低0.14%,而召回率和综合的F1值均是HRA+Abstract+MLW-LPA方法最高,效果最好。另外,从表8和图7的分组实 验结果也可以看出,我 们 提 出的HRA+Abstract+MLW-LPA方法在分组中的效果也是最好的,在各个分组的测试结果中F1系数均是最高。从实验结果中我们可以看出,CRF方法并不十分适合于这类专业文献知识实体的类型标注,可能的原因是这类知识实体长度较短、上下文信息特征不足,导致无法准确判断标注。另外,由于知识实体类型种类较多,类型特征高达3000多维,导致CRF模型的训练过程十分缓慢,性能较差。
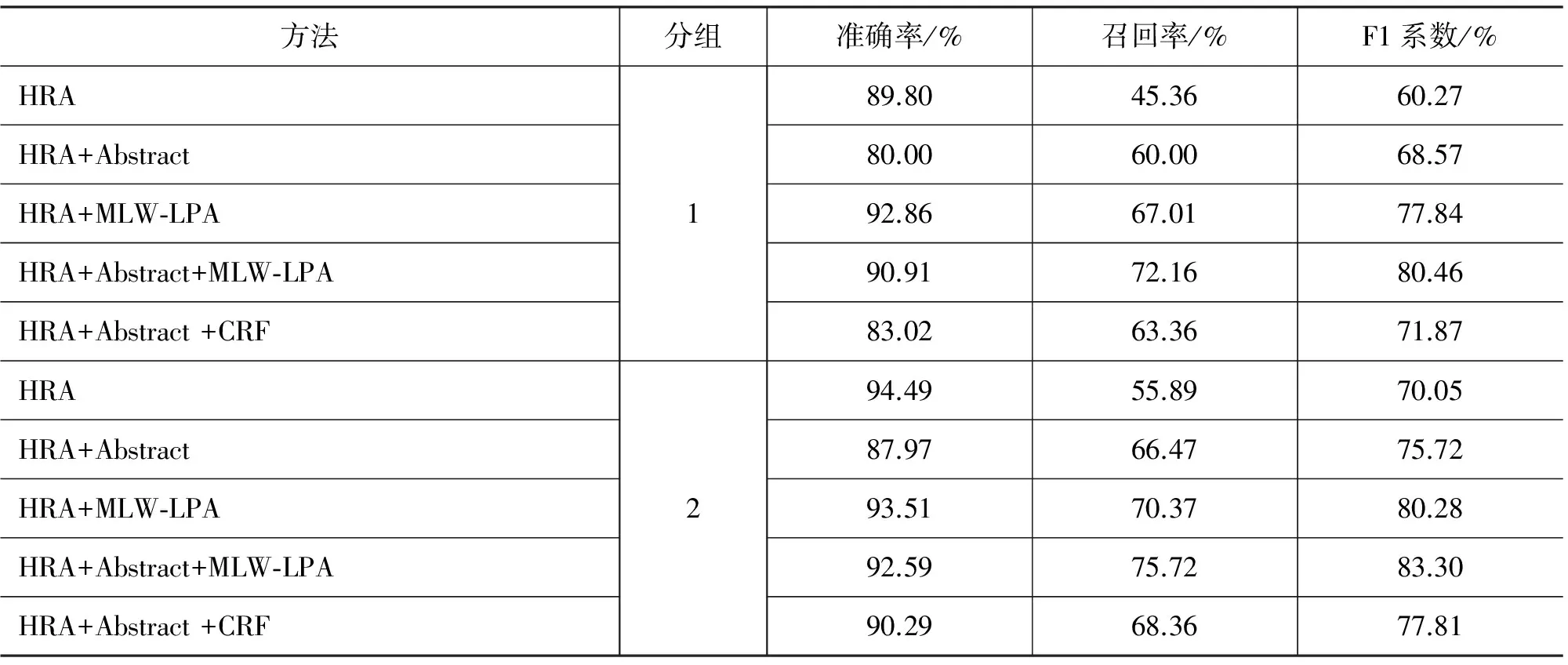
表8 几种不同方法在不同分组下的效果对比
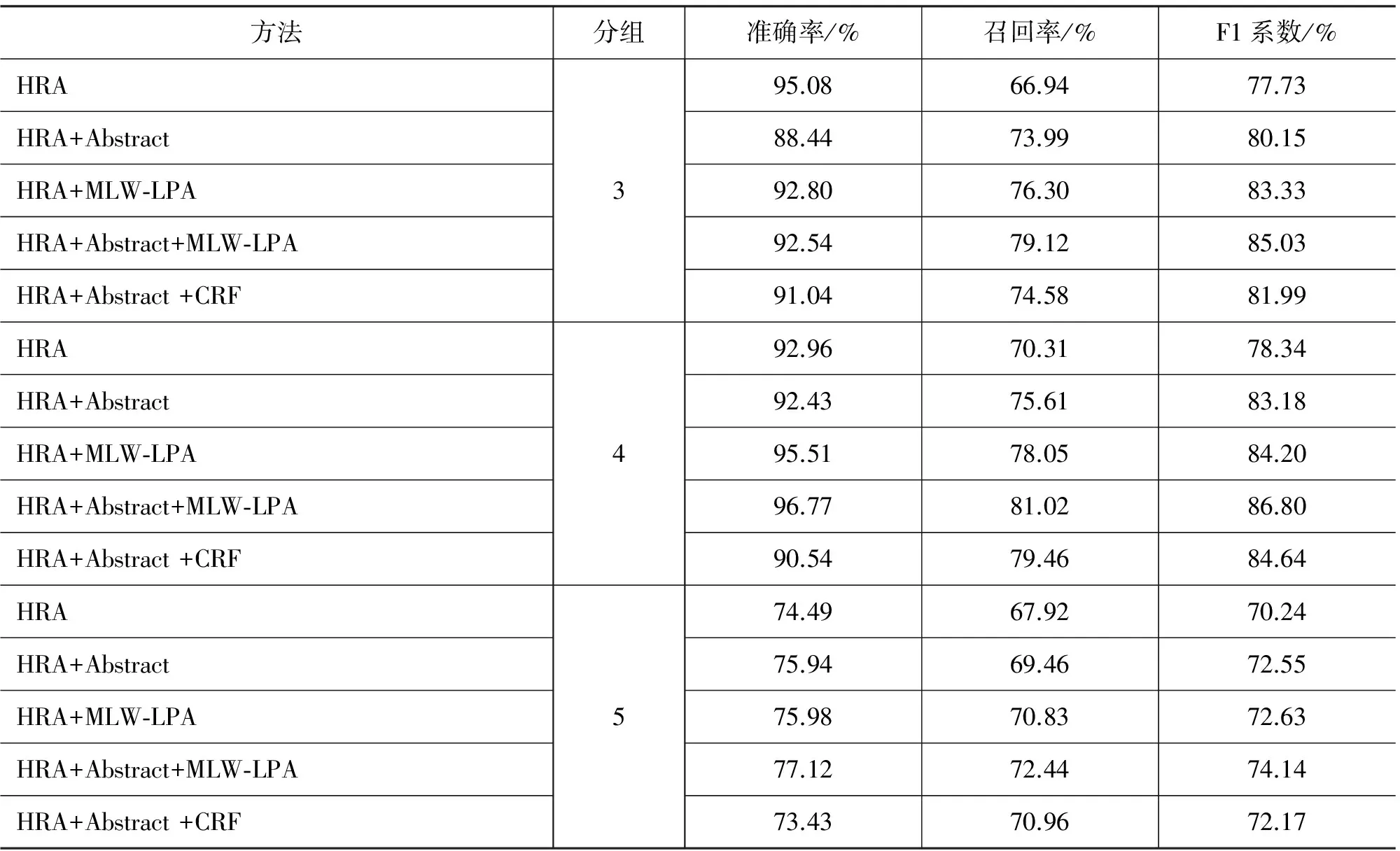
续表

图7 三种方法在不同分组下的效果对比
此外,我们还发现在在分组1~4中,在均衡知识实体样本数的条件下,随着分组包含的类型数量的增多,各个方法的效果逐步提升,但是到了分组5类型抽取效果却急剧下降。我们认为这与知识实体类型的幂律分布有关(见图6),分组1~4的类型数量都是缓慢的递增,而分组5却指数性增长,导致类型数量太多而降低了召回率,出现了相反的效果。
6 总结
随着每天都有大量的专业文献电子化和网络化,人们从网络上获取到大量的文献知识不再是难题,而新出现的难题是面对如此庞大的文献数据,现有的知识服务已经无法很好地满足人们对于文献知识快速、准确获取的要求。本文将这类专业文献中的知识实体作为研究对象,探讨该类文献独有的特点,并与一般网络文本比较。另外,在相关实验的基础上,我们总结了知识实体类型指示词的一些特性;根据这些特性,本文提出了一种基于启发式规则与标签传播算法的类型抽取和标注方法,并通过实验验证了该方法比一般传统方法在专业文献知识实体的类型抽取上有更好的效果。
本文贡献主要有以下三点:
(1) 提出了知识实体的定义及分析这类专业领域知识实体的特点;
(2) 定义了知识实体的类型指示词,并通过统计实验总结出这些类型指示词所具有的特性;
(3) 提出了一种基于启发式规则与标签传播算法的类型抽取和标注方法。由于是无监督的方法,该方法具有较高的灵活性和通用性。此外,实验结果表明该方法比传统基于特征的CRF方法在专业领域知识实体的类型抽取方面效果要好。
未来的工作,我们拟在以下几个方面展开:
(1)继续深入探讨专业领域文献在信息抽取方面的方法,进一步研究本文提出的方法在其他领域(例如医学、化学等)的通用性;
(2)尝试利用抽取到的知识实体类型建立结构化的知识模型,并以此分析知识实体之间的关系。
[1]数字图书馆迎大数据时代: 将整合资源提供深度服务[OJ].http://culture.people.com.cn/n/2014/1105/c172318-25981395.html
[2]陈宇,郑德权,赵铁军.基于Deep Belief Nets的中文名实体关系抽取[J].软件学报,2012,23(10):2572-2585.
[3]刘丹丹,彭成,钱龙华,等.《同义词词林》在中文实体关系抽取中的作用[J].中文信息学报,2014,28(2):91-99.
[4]Suchanek F M, Kasneci G, Weikum G. Yago: A large ontology from wikipedia and wordnet[J]. Web Semantics: Science, Services and Agents on the World Wide Web, 2008, 6(3):203-217.
[5]Ni Y, Zhang L, Qiu Z, et al.Enhancing the open-domain classification of named entity using linked open data[M]. The Semantic Web-ISWC 2010. Springer, 2010:566-581.
[6]Dojchinovski M, Kliegr T. Entityclassifier. eu: real-time classification of enti-ties in text with Wikipedia[M]. Machine Learning and Knowledge Discovery in Databases. Springer, 2013:654-658.
[7]Hearst M A. Automatic acquisition of hyponyms from large text corpora[C]//Proceedings of the 14th conference on Computational linguistics-Volume 2. 1992:539-545.
[8]Evans R. A framework for named entity recognition in the open domain[C]//Recent Advances in Natural Language Processing Ⅲ: Selected Papers from RANLP 2003, 2004, 260:267-274.
[9]Etzioni O, Cafarella M, Downey D, et al. Unsupervised named-entity extraction from the web: An experimental study[J]. Artificial Intelligence, 2005, 165(1):91-134.
[10]Carlson A, Betteridge J, Wang R C, et al. Coupled semi-supervised learning for information extraction[C]//Proceedings of the Third ACM International Conference on Web Search and Data Mining. 2010:101-110.
[11]祝伟华, 卢熠, 刘斌斌. 基于HMM的Web信息抽取算法的研究与应用[J].计算机科学,2010,37(2):203-206.
[12]张铭,银平,邓志鸿,等.SVM+BiHMM:基于统计方法的元数据抽取混合模型[J].软件学报,2008,19(2):358-368
[13]董永权, 李庆忠, 丁艳辉,等. 基于约束条件随机场的Web数据语义标注[J].计算机研究与发展,2012,49 (2):361-371.
[14]宋毅君, 王瑞波, 李济洪, 等. 基于条件随机场的汉语框架语义角色自动标注[J]. 中文信息学报, 2014,28(3):36-47.
[15]张传岩, 洪晓光, 彭朝晖, 等. 基于SVM和扩展条件随机场的Web实体活动抽取[J].软件学报, 2012,23(10):2612-2627.
[16]Weeds J, Weir D. A general framework for distributional similarity[C]//Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, 2003:81-88.
[17]Clarke D. Context-theoretic semantics for natural language: an overview[C]//Proceedings of the Workshop on Geometrical Models of Natural Language Semantics, 2009:112-119.
[18]Lenci A, Benotto G. Identifying hypernyms in distributional semantic spaces[C]//Proceedings of the Sixth International Workshop on Semantic Evalua-tion, 2012:75-79.
[19]Basile P, Caputo A, Semeraro G. Supervised learning and distributional semantic models for super-sense tagging[M]. AI* IA 2013: Advances in Artificial Intelligence. Springer, 2013:97-108.
[20]Shi S, Zhang H, Yuan X, et al. Corpus-based semantic class mining: distributional vs. pattern-based approaches[C]//Proceedings of the 23rd International Conference on Computational Linguistics, 2010:993-1001.
[21]Yoshida K, Tsujii J. Reranking for biomedical named-entity recognition[C]//Proceedings of the Workshop on BioNLP 2007: Biological, Translational, and Clinical Language Processing. Association for Computational Linguistics, 2007: 209-216.
[22]毛存礼, 余正涛, 沈韬, 等. 基于深度神经网络的有色金属领域实体识别[J].计算机研究与发展, 2015, 52(11): 2451-2459.
[23]郭剑毅, 薛征山, 余正涛, 等. 基于层叠条件随机场的旅游领域命名实体识别[J]. 中文信息学报, 2009, 23(5): 47-52.
[24]刘非凡, 赵军, 吕碧波, 等. 面向商务信息抽取的产品命名实体识别研究[J].中文信息学报, 2006, 20(1): 7-13.
[25]National Institute of Standards and Technology,2005.ACE(Automatic Content Extraction) Chinese Annotation Guidelines for Events.
[26]吴共庆, 胡骏, 李莉,等. 基于标签路径特征融合的在线 Web 新闻内容抽取[J].软件学报, 2016,27(3):714-735.
[27]郑影, 李大辉. 面向微博内容的信息抽取模型研究[J].计算机科学, 2014, 41(2):270-275.
[28]Liu X, Li K, Zhou M, et al.Collective semantic role labeling for twitter with clustering[C]//IJCAI. 2011, 11: 1832-1837.
[29]Zhang F, Shi S, Liu J, et al. Nonlinear evidence fusion and propagation for hyponymy relation mining[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies,2011:1159-1168.
[30]Lin T, Mausam, Etzioni O. No noun phrase left behind: detecting and typing unlinkable entities[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2012: 893-903.
[31]Zhu X, Ghahramani Z. Learning from labeled and unlabeled data with label propagation[R]//Technical Report CMU-CALD-02-107, Carnegie Mellon University, 2002.
[32]Chen J, Ji D, Tan C L, et al. Relation extraction using label propagation based semi-supervised learning[C]//Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2006: 129-136.
[33]Levenshtein V I. Binary codes capable of correcting deletions, insertions and reversals[J]. Soviet Physics Doklady, 1966, 10(1):707-710.
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
中国外汇(2019年18期)2019-11-25
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
Coco薇(2017年11期)2018-01-03
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
