
面向多语料库的通用事件指代消解
2018-04-04 01:12陆震寰周国栋
中文信息学报 2018年1期
陆震寰,孔 芳,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
作为信息的一个重要的载体,事件是人、物、事在特定时间和特定地点相互作用的事实。同一篇文章中通常包含多个相互关联的事件,而同一个事件在不同的上下文中会采用不同的表述,当多个事件表述指向一个自然事件本体时,则认为这些事件表述间具有同指关系。
图1给出了具有同指关系的事件表述示例。例1中的“会晤”和“会谈”都指向同一个真实事件,这两个表述具有同指关系。例2中的“killed”和“hacked”也指向同一个真实事件,它们之间也是同指关系。
一般情况下,对于某一事件的报道,往往是先进行大致说明,然后对事件发生的时间、地点、参与者等进行详细说明,最后分析该事件造成的影响。通过事件同指消解将这些事件表述指向同一个自然事件,能够更好地去理解自然事件。
正确识别事件表述间的同指关系,不仅有助于理解事件本身,对事件间的逻辑语义关系分析、篇章理解、信息抽取等任务也意义重大。本文主要处理事件同指消解问题,假设事件抽取已经完成(即事件表述及其所属的类别是已知的),基于此给出了一个完整的基于卷积神经网络的事件同指消解框架,并针对实例分布不均、对特定标注方案依赖性强和全局信息利用不够等问题进行了分析,给出了相应的解决方案。在KPB2015和ACE2005语料库上的实验均验证了所提方案的有效性,事件同指消解的性能也得到了极大的提升。

图1 事件同指示例
1 相关工作
事件同指消解最早在Ahn[1]研究事件抽取问题时被提出,借鉴Florian[2]研究实体同指消解的思想,Ahn将事件同指问题转化为事件表述对之间的相似度计算问题。近年来基于机器学习的事件同指研究取得了一定的成果,主要分为有监督的事件对模型消解研究和无监督的事件图模型消解研究两个流派。
在有监督的事件对模型研究方面,Chen等[3]通过训练多个分类器对OntoNotes中不同的句法类型(例如,动词-名词同指,动词-动词同指)进行联合推理;Lee[4]、Liu[5]等人在特征工程基础上通过引入WordNet、FrameNet等知识库促进事件同指消解效果;Teng[6]针对事件间的内在联系,提出了中文事件同指消解全局优化模型;Zeng[7]首次将卷积神经网络引入实体关系分类,并证明了深度学习在关系分类任务上的有效性;Krause[8]、Santos[9]通过将词、词位置等信息嵌入到神经网络中,也在一定程度上提升了同指消解的效果;Ding[10]分别考虑事件层次的语义信息和跨事件层次有关语义信息,并将这些信息嵌入到浅层卷积神经网络中,在事件多关系分类任务上取得了一定的效果提升。
针对事件同指语料较为欠缺的问题,部分学者提出了基于图模型的无监督事件同指消解方法。Do[11]基于集中分布相似度和篇章间的联系提出了一种弱监督方法;Bejan[12-14]等基于参数贝叶斯思想分别设计了基于混合狄里克雷分布的有限特征模型、基于MIBP(Markov india buffet process)的无限特征模型及基于因果隐马尔科夫模型和隐马尔科夫模型的事件同指混合模型。
有别于已有的工作,本文主要关注基于深度学习框架的事件同指消解,并在这一框架中探讨三方面的问题: (1)引入通用的过滤策略降低数据分布不均衡的影响;(2)兼顾不同的事件标注策略,采用最小事件描述(与通用事件标注策略相关,仅考虑事件自身所包含的触发词及位置信息)和事件间关系描述(基于通用事件标注信息,结合WordNet等外部资源进行事件间语义关系的计算)相结合的特征表示方法;(3)引入全局优化的后处理。
2 事件同指消解
图2给出了事件同指消解平台的完整框架。从框架图中可以看到,与大多数有监督的机器学习方法类似,平台由训练和测试两个部分构成。在训练阶段,从训练文本中抽取标准的标注事件及其对应的上下文信息,借助事件最小描述特征抽取模块获取事件自身相关的属性,同时将事件进行配对,以事件对为单位抽取事件间关系描述的相关特征,将事件自身特征和事件间关系特征分别向量化,并交由神经网络进行建模,从而构建训练模型。在测试阶段,借助事件抽取模块自动抽取给定的测试文档中的若干事件及其对应的类别信息,与训练环节类似,抽取事件自身特征和配对后事件对的关系特征,在训练模型的指导下借助神经网络进行事件对中两个事件同指与否的预测。由于基于事件对的同指判断得到的结果是局部最优解,在此基础上需要从篇章中获取所有事件集,即从全局的角度进行优化后处理,最终获得测试文档对应的事件同指链集合。由于本文主要关注事件同指环节,事件抽取相关话题及其对事件同指性能的影响不是本文研究的焦点,因此与训练阶段一致,本文在测试阶段也使用标准的标注事件。
从平台基本框架可以看到,事件同指消解的核心包括事件配对、事件自身特征抽取、事件间关系特征抽取和全局优化算法等四个模块,下面分别进行介绍。

图2 事件同指消解的基本框架
2.1 事件配对
考虑文本中同一事件的多个表述可能侧重表达事件某一个或几个方面的特性,而且事件描述是一个动态变化的过程,仅考虑同一事件的两个表述间的关联关系,很难追踪事件变化的过程。与实体同指不同,我们将任意一个事件表述与其他所有事件表述均进行配对形成事件对实例,若两个事件表述在同一个指代链上则为正例,否则为负例。这样同一个事件表述可以生成多个正例,也同时形成多个负例。
上述配对策略,避免了描述同一事件的两个表述间由于追踪的事件侧重点不一致造成的低相似度问题,但也引入了大量负例,造成了正负例的不均衡问题。在KBP2015和ACE2005语料上分别采用上述事件配对策略,形成的正负例比例分别为1∶15和1∶13,这必将影响后续机器学习算法的性能。
解决正负例不均衡的常规方法,一是借助随机采样方法调节正负例比例,二是引入过滤规则,在配对过程中将不可能具有同指关系的事件对直接滤去。事件配对过程中我们引入了以下两类过滤策略。
(1) 类型过滤策略。将事件所属类型两两配对,在训练数据集中统计该类型事件对出现的频数及它们以正例出现的频数,若以正例出现的比例低于某一阀值,则认为这两类事件是不相容事件,配对环节将其滤去(训练阶段)或直接作为负例(测试阶段)。
(2) 时态过滤策略。与类型类似,将事件所属时态两两配对,根据其在训练集中的情况确定它们是否为不相容事件。
引入过滤策略后,训练阶段,在KBP2015和ACE2005语料上形成的事件对实例的正负比例降到了1∶3和1∶4,达到了较好的状态。
2.2 最小事件自身描述特征
已有研究将事件相关的词汇、类别、时态、语义、句法等特征,以及事件所在句子的相关特征引入事件同指消解,取得了一定的效果。但事件标注是一个非常耗时耗力的工作,目前事件标注的语料较少,而且采用了不同的事件标注体系,如何使用已有的多个事件标注语料是需要关注的问题之一。本文在分析KBP2015和ACE2005事件标注体系时发现,事件表述中关于事件触发词的定义是比较统一的。因此本文使用事件表述所在的句子和事件触发词来最小化描述事件本身,并从中抽取相关特征。
抽取的事件本身特征包括: 事件所在句子中的词及其对应的词性,每个词与触发词的相对位置。其中,词S=(w1,w2,…,wn),词性POS=(p1,p2,…,pn),相对位置RP=(i1,i2,…in)(句子中每个词相对于触发词的位置in=indexn-indextrigger)。 使用Google预训练的词向量Ww=dw*|Vw|对每句话进行初始化(dw为词向量维度,采用的维度为300,|Vw|为词表的大小)。词性向量Wp=dp*|Vp|和位置向量Wi=di*|Vi|采取随机初始化策略(其中dp、di分别为词性维度、位置维度,设置为9和8,|Vp|为词性表的大小,|Vi|为相对位置表的大小)。
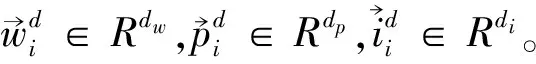


为了进一步提取事件潜在特征,我们采取了全局池化的方法来进行特征降维。一方面,池化后的输出更能突出表示当前输入的隐式特征;另一方面能够防止模型在训练集上过拟合。本文主要采取全局最大池化策略,如式(4)所示。
具体向量化的过程如图3所示。
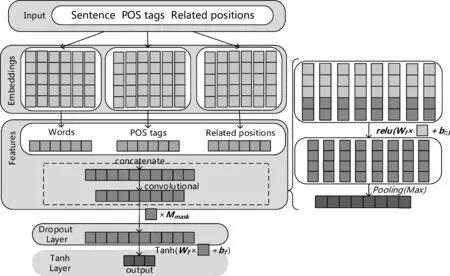
图3 事件自身的向量化过程
2.3 事件间关系的特征
从事件表述的定义来看,多个事件标注语料库都认可事件触发词,且对事件都进行了归类,因此事件配对后,我们通过事件触发词之间的距离间接描述事件间的关系,具体包括:
(1) 事件对之间类型、子类型、时态是否一致;
(2) 基于WordNet的事件对触发词距离;
(3) 基于WordNet的事件对触发词词根距离;
(4) 事件对触发词在句法树中的深度是否一致。

为了使模型能够收敛到最佳,采取正确标签yg与预测标签yp的交叉熵作为损失函数,用来对模型进行评价,采用的优化函数是随机梯度下降法,如式(8)所示。
图4给出了在深度学习框架下事件间关系特征的引入示例。
2.4 事件关系的全局优化
基于事件对的事件关系识别忽略事件对之间的相互关系,认为事件对之间互相独立,但由于分类结果的误差,往往会造成事件链上事件间关系矛盾。由于事件对关系之间存在对称性、传递性等特点,我们对分类器的结果进行全局优化以减少上述的误差。同指关系是相互的,对于一个事件对(e1,e2),若e1与e2具有同指关系,则e2与e1也具有同指关系;同指关系是传递的,若已知r(e1,e2)且r(e2,e3),则可以推出e1、e3间也是否具有同指关系。图5给出了本系统使用的全局优化算法。
3 实验结果与分析
3.1 实验设置
本文使用了TAC KBP2015[15]、 ACE2005[16]这两个事件同指英文语料库作为实验语料。其中ACE2005包含广播新闻、网页博客等类型,共计633篇文本,由于ACE2005只针对特定类型的事件,语料中包含的事件实例较少,因此语料规模相对较小。与ACE2005相比,TAC KBP2015共计包含新闻和论坛等类型360篇文本,极大地扩充了事件实例,同时在触发词和类型的定义上也更加丰富。

图5 全局优化算法
本文使用Conll2012-scorer-8.0评价软件,按照MUC[17],B3[17],CEAF-E[18],BLANK[19]评价标准分别计算准确率(Precision)、召回率(Recall)、综合指标(F1)。最后计算四个综合指标的均值作为系统的整体性能。
3.2 实验结果及分析
本文使用以下几种实验设置分别在KPB2015和ACE2005两个语料库上展开实验。
(1) 实验1: 仅使用最小事件自身描述特征集,训练过程中使用负例下采样将正负例比例调至1∶5;
(2) 实验2: 在实验1配置之上引入事件对间关系特征;
(3) 实验3: 在实验2配置之上引入类型和时态两个过滤策略;
(4) 实验4: 在实验3配置之上引入全局优化后处理。
表1给出上述四个实验的结果,以及KBP2015事件同指评测任务[20]最终给出的评测结果,其中Team5[21]在该评测任务上取得了最佳的结果,baseline为该评测官方给出的基准系统。

表1 KBP2015上的实验结果
从表1中我们可以看到:
(1) 对比实验1和实验2,事件对间关系特征的引入在MUC、B3、CEAF-E和BLANK评测策略上均有一定幅度的提升,最终平均F1值的提升达到了约21%;
(2) 对比实验2和实验3,引入的过滤策略大大降低了正负例比例,提升了模型的性能;
(3) 对比实验3和实验4,全局优化能进一步提升系统的性能,最终在标准事件集上事件同指的性能可以达到93.35%;
(4) 对比KBP2015比赛的最好系统和官方公布的baseline系统的性能,对事件对的过滤,以及基于事件簇的全局优化工作使得我们的系统表现更为出色。
表2给出了在ACE2005语料上的相应实验结果,同时也给出了目前在ACE2005语料上事件同指研究取得的最佳性能。我们发现,与KPB2015语料上的结果类似,事件间关系特征的引入、事件配对时采用的过滤策略,以及后续基于事件簇的全局优化算法均能提升事件同指消解的性能。与目前该语料集上取得的最佳性能相比,我们的系统约有10%的优势。

表2 ACE2005语料上的实验结果
对比两个语料上系统性能的提升情况,我们发现:
(1) 在两个语料上,事件间关系特征和全局优化的后处理对性能提升的贡献度相当,平均F1值的提升分别为20%和3%左右;
(2) 过滤策略的引入在KPB2015语料上产生的性能影响更为明显。这主要是由于两个语料对事件同指定义的严格度有区别[22]。KPB2015语料表明,直观上两个事件可以对应于同一真实事件,则这两个事件是同指关系;而ACE2005语料则认为,一对事件中,若某个论元对间不存在同指关系,则这对事件也不同指。本文给出的事件同指消解平台能最大化地兼容不同的事件定义方案,在同指消解的过程中始终未考虑事件论元问题,提出的过滤策略也较为宽泛,这导致KPB2015语料上的过滤效果明显好于ACE2005语料,从而导致了性能提升上的差异。
此外,需要强调的是,本文给出的事件同指消解平台在KBP2015和ACE2005上运行不需要进行任何代码级的更改,这也验证了我们提出的最小事件自身描述融合基于外部资源的事件间关系描述策略,在不同语料适应性方面的有效性。
4 总结
本文主要针对事件同指消解展开,提出了一个面向多语料库的通用事件同指消解框架,并在这一框架下探讨了三方面的问题: (1)引入通用的过滤策略降低数据不均衡的影响;(2)兼顾不同的事件标注策略,采用最小事件描述和事件间关系描述相结合的特征表示方法;(3)引入全局优化的后处理。
尽管本文提出的方法在多个公共语料上均有一定的提升,但该方法的性能还是受限于事件抽取的性能,未来我们考虑设计一个端到端的事件同指消解方案。另外,该方法没有完全利用事件的部分信息,比如事件的时间、地点论元等,利用好这一部分信息也能提升事件同指消解的性能。
[1]Ahn D. The stages of event extraction[C]//Proceedings of the Workshop of the ACL on Annotating and Reasoning about Time and Events, 2006: 1-8.
[2]Florian R, Hassan H, Ittycheriah A, et al. A statistical model for multilingual entity detection and tracking[C]//Proceedings of HLT/NAACL-04, 2004.
[3]Chen B, Su J, Sinno Jialin Pan, et al. A unified event coreference resolution by integrating multiple resolvers[C]//Proceedings of the 5th International Joint Conference on Natural Language Processing, 2011: 102-110.
[4]Lee H, Recasens M, Chang A, et al. Joint entity and event coreference resolution across documents[C]//Proceedings of Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2012. Pages 489-500.
[5]Liu Zhengzhong, Araki J, Hovy E, et al. Supervised within-document event coreference using information propagation[C]//Proceedings of the Ninth International Conference on Language Resources and Evaluation, 2014: pages 4539-4544.
[6]Teng Jiayue, Li Peifeng, Zhu Qiaoming. Chinese event co-reference resolution based on trigger semantics and combined features. Workshp on Chinese Lexical Semantics 2016, 2015: 426-433.
[7]Zeng Daojian, Liu Kang, Lai Siwei, et al. Relation classification via convolutional deep neural network[C]//Proceedings of the Association for Computational Linguistics.In COLING, 2014: 2335-2344.
[8]Krause S, Xu Feiyu, Uszkoreit H, et al. Event linking with sentential features from convolutional neural networks[C]//Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning (CoNLL), 2016: pages 239-249.
[9]Cicero Nogueira dos Santos, Xiang B, Zhou Bowen. Classifying relations by ranking with convolutional neural networks[C]//Proceedings of the Association for Computational Linguistic.In ACL, 2015: 626-634.
[10]Ding Siyuan, Hong Yu, Zhu Shanshan, et al. Combining event-level and cross-event semantic information for event-oriented relation classification by SCNN[C]//Proceedings of the China National Conference on Chinese Computational Linguistics, 2016: 216-224.
[11]Do Quang Xuan, Chan Yee Seng, Roth Dan. Minimally supervised event causality identification[C]//Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing,2011: 294-303.
[12]Bejan C A, Matthew Titsworth, Andrew Hickl, et al. Nonparametric bayesian models for unsupervised event coreference resolution[C]//Proceedings of the Advances in Neural Information Processing Systems 23 (NIPS), 2009: 73-81.
[13]Bejan C, Sanda Harabagiu. Unsupervised event coreference resolution with rich linguistic features[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, 2010: 1412-1422.
[14]Bejan C, Sanda Harabagiu. Unsupervised event coreference resolution. Computational Linguistics,2014, 40(2):311-347.
[15]Joe E, Jeremy G, Dana F, et al. Overview of Linguistic Resources for the TAC KBP, 2015.
[16]LDC. ACE(Automatic Content Extraction ) English Annotation Guidelines for Events. Linguistic Data Consortium. Version 5.4.3,2005.
[17]Amit B, Breck B. Algotithms for scoring coreference chains[C]//Proceedings of LREC,1998: 563-566.
[18]Luo Xiaoqiang. On coreference resolution performance metrics[C]//Proceedings of HLT-EMNLP, 2005: 25-32.
[19]Marta R, Eduard H. BLANC: Implementing the rand index for coreference evaluation. Natural Language Engineering, 2011, 17(4):485-510.
[20]Teruko M, Liu Zhengzhong, Eduard Hovy. Overview of TAC-KBP 2015 Event Nugget Track, 2015.
[21]Sean M, Michael M, Marc T, Amy Book, Maxim Gorelkin, Kevin Crosby, Mary Brunson[C]//Proceedings of the Populating a Knowledge Base with Information about Events, 2015.
[22]Lu Jing, Deepak V, Vibhav G, et al. Joint inference for event coreference resolution[C]//Proceedings of the International Conference on Computational Linguistics, 2016: 3264-3275.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
通信技术(2021年12期)2022-01-25
家庭影院技术(2019年8期)2019-08-27
金桥(2018年4期)2018-09-26
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
中国卫生(2014年5期)2014-11-10
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
