
基于音视频特征的新闻拆条算法
2018-03-30 07:10:30李晨杰朱允斌
微型电脑应用 2018年2期
李晨杰, 朱允斌
1(复旦大学 计算机科学技术学院,上海 201203) 2(上海视频技术与系统工程研究中心,上海 201203)
0 引言
随着大数据和网络信息传输技术的发展,用户可接触到的视频信息越来越多,新闻视频作为其中一类,充斥着用户的日常生活。用户对于新闻类视频的需求更多的是根据喜好与需要选择单个新闻条目,与实际生活中电视台播送的时间较长的整档节目并不吻合。新闻拆条算法可以自动地将较长的新闻视频节目按其内容拆分成多个新闻条目,改变目前新闻视频拆条以人工剪辑为主的状况,使新闻视频服务供应商能更快速有效地对新闻进行细分,从而进行更为精准的内容推送,在视频数据存储等方面也拥有更大的灵活性。
本文的研究内容为基于音视频特征的新闻视频拆条算法,旨在将时间较长的新闻视频按其内容进行划分,找出不同新闻条目之间的分界点。主要内容围绕着新闻视频主持人特征和音频静音段特征展开,包括特征提取及如何基于这些特征进行拆条。主要工作包含视频镜头分割、人脸识别、静音段提取和条目分界点的确定等。本文对算法进行大量实验,找到针对特定的新闻视频拆条最有效的实验参数,总结分析优劣。
1 相关工作
Anuj[1]基于主持人特征进行新闻拆条,且找出同一个主持人镜头中不同新闻播报的分界点。Misra[2]用狄利克雷分布获取主题字幕特征,并结合主持人特征来判断新闻条目的分界点。Tarek[3]以新闻节目的语境和结构特征为先验规则,找出各种场景中的主持人特征作为新闻分界点。Ma[4]从多媒体信号源中检测出关键项,并与音频特征相结合来判定新闻边界。Wei[5]将静音段在视频中所处的位置、主持人特征和镜头边界结合来判断边界。Emilie[6]结合了多种新闻视频的视觉和音频特征模型来判断新闻条目边界,通过实验得出各个特征对结果的影响,总结了各特征对新闻拆条工作而言的重要性,然而其所找出的新闻分界点允许存在前后10秒的误差。刘嘉琦[7]基于主题字幕、静音段和主持人特征来划分新闻故事边界。冯柏岚[8]采用启发式规则获取条目边界的视觉和语音候选点,用音视频融合策略对边界进行定位计算,从而确定边界。
大多算法使用了新闻视频的多种特征,以求能适用普遍情况,但提取的特征越多意味着时间复杂度越大,不利于实际运用。以秒作为视频拆分的最小单位则影响了整体算法的精确度。本文提出的新闻拆条算法仅采用关键性的主持人和静音段特征,在通过人脸识别得到主持人镜头关键帧之后,结合静音段找出新闻条目分界点。本文算法将视频拆分的最小单位精确到帧,相较于以秒为单位的算法有了较大的提升。
2 新闻拆条算法的主要内容
2.1 新闻拆条算法概述
本章将介绍新闻拆条算法的主要内容。在本小节中将介绍新闻条目的模式,阐述本文的新闻拆条算法所选取的新闻视频特征,并概述算法的思路与流程。其余小节将详细地描述算法各个步骤的具体内容。
2.1.1 新闻条目的模式
新闻视频可以分为节目片头、开场问候、主持人播报、新闻详细视频内容和结束语五个部分。除特别指明外,本文所指的新闻视频是指由若干个主持人播报和新闻详细视频内容组成的新闻视频片段,不涉及其他三个部分。新闻拆条算法需要找出正确的新闻条目分界点,根据新闻视频的内容将其拆分成多个新闻条目。结合图1可知新闻条目大致分为以下3种模式:
(1)主持人播报+详细视频内容,新闻条目1、条目2和条目4,如图1所示。

图1 中央电视台新闻联播节目的新闻条目示例
(2)主持人播报详细内容,如图1所示的新闻条目3;
(3)详细视频内容,如图1的新闻条目5。
2.1.2 新闻视频特征的选取
新闻拆条算法常用的特征包含视觉和音频两个方面。视觉特征如主持人、演播室场景、电视台标识和主题字幕等。音频特征如静音段、播报员声音和语音内容关键词等。本文仅选取主持人特征和音频静音段特征来确定新闻条目的分界点,原因如下:
(1)特征选取应首先考虑普遍性,即在大多数新闻视频中都具备的要素(如主持人和静音段),这样才能使得新闻拆条算法更具通用性。仅适用于特定新闻视频的特征(如台标和演播室场景等)不满足普遍性要求;
(2)和新闻节目内容相关的特征(如语音内容等)属于较高层的特征,其提取和分析过程较复杂,通常涉及到关键字提取或主题聚类等更复杂的问题。因此这类特征不适用于新闻拆条算法;
(3)在新闻视频中,主持人画面的出现往往意味着一段新闻条目的开始,因此该特征对新闻拆条算法而言必不可少。另一个广泛存在且不依赖特定新闻或播报员的特征是音频静音段,新闻条目的分界点通常都位于音频静音段内,因此静默段特征对于新闻拆条算法也具有很大的意义。
2.1.3 新闻拆条算法的思路与流程
新闻条目的边界往往是视频镜头的边界[9],因此本文仅以镜头关键帧作为切入点,整体思路围绕着新闻视频的主持人和音频静音段特征展开,通过处理新闻视频的镜头关键帧来获取主持人镜头序列和静音镜头序列,结合分析两个序列完成拆条工作,在节约计算时间的同时,能以帧作为新闻条目边界的精确度。
算法1 基于音视频特征的新闻拆条算法
输入:离线新闻视频
输出:新闻条目分界点(视频中的帧号)
主要步骤(a和b并列进行):
1a.对输入视频进行镜头分割得到镜头关键帧集合;
1b.运用短时能量及短时过零率特征提取音频段;
2a.镜头关键帧集合经由主持人分析阶段得到该新闻视频的主持人镜头序列;
2b.静音段中音频帧号定位转换为镜头图像帧号,筛选静音段,生成静音镜头序列;
3.结合主持人镜头序列和静音镜头序列进行新闻拆条分析,得到该新闻视频条目的分界点。
2.2 镜头分割阶段
镜头分割旨在寻找镜头之间的分界点。镜头由若干个图像帧构成,镜头分割阶段需要找出每一个镜头的起始帧作为关键帧,并将起始帧号集合输出,如图2所示。
在新闻视频中,绝大多数的镜头转换为切变,尤其在不同新闻条目之间,这意味着前一个镜头的末尾帧和下一个镜头的第一帧之间存在巨大的差异。因此本文选取传统的基于颜色直方图的镜头分割方法。进行镜头分割之后得到一个集合,其保存了新闻视频中每一个镜头的起始帧号。
图2 某新闻视频的部分镜头分割结果
2.3 主持人分析阶段
主持人分析阶段根据镜头起始帧号从视频中获取镜头起始帧图像集合,并对该集合中的图像进行人脸识别,判断其是否为主持人,并生成主持人镜头序列。
2.3.1 人脸识别
算法对镜头起始帧图像集合中的每一幅图像进行人脸识别,人脸识别具体分为人脸检测、面部特征点定位和人脸特征提取等三个步骤进行。
人脸检测的方法基于多层神经网络实现,其采用漏斗型级联结构[10],专门针对多姿态人脸检测而设计,可以实现准正面人脸的准确检测。面部特征点定位采用了一种由粗到精的自编码网络[11]来解决从人脸表观到人脸形状的复杂非线性映射问题,实现人脸对齐,从而解决由人的不同姿态、表情及环境光照或人脸遮挡等因素产生的影响。判断每一张图像中是否包含人脸,若有,则记录该人脸所属的镜头号,并进行人脸特征的提取。特征提取基于深度卷积神经网络VIPLFaceNet[12]实现,得到人脸的2048维特征向量。
2.3.2 序列生成
比较人脸特征向量的欧几里得距离,即可得到相似的人脸特征,基于这些相似结果以及人脸所属的镜头帧号,若满足以下3个条件则认为该人脸为主持人:
(1)该人脸出现在画面中央;
(2)该人脸在镜头关键帧序列中多次出现;
(3)出现的位置分散在整个视频节目之中。
具体判断步骤为:给定阈值τ,找出出现在画面中央且次数大于τ的全部人脸,针对不同的人脸分别计算其最后一次出现的画面帧号与第一次出现的帧号的差值,差值越大则人脸分布越广。
经上述步骤后,针对每一个镜头起始帧可以判定其是否含有主持人,从而生成主持人镜头序列。假设某新闻视频共被分割成N个镜头,则生成一个长度为N的数值序列,每一位数字代表对应图像帧是否含有主持人。针对图1所示的新闻视频构造的主持人镜头序列,结果为10…010…0110…00…0,共N位。其中1表示该镜头关键帧含有主持人,省略号省去的皆为0。
2.4 静音段分析阶段
2.4.1 静音段的图像帧定位
对视频采取基于短时能量和过零率的端点检测方法[13]来获取语音段落,并根据结果获取静音段集合。随后需要将静音段集合中的音频帧号定位转换为新闻视频中的图像帧号,才能与镜头关键帧位置相对应,生成静音镜头序列。已知静音段集合为M,则有式(1)。
M={si,ei|1≤i≤K,i∈Z}
(1)
其中K表示静音段落总数,si和ei分别表示第段静音段的起始音频帧号和结束音频帧号。对于si,其所在的位置对应视频中的图像帧号pi为式(2)。
(2)
其中fs表示音频采样频率,Lf表示音频帧长,fv表示视频帧率。用同样的方法求得ei所在的位置对应的视频图像帧号qi,便最终得到基于视频图像帧号的静音段集合M′为式(3)。
M′={pi,qi|1≤i≤K,i∈Z}
(3)
其中K表示静音段落总数,pi和qi分别表示第段静音段落的起始图像帧号和结束图像帧号。
2.4.2 生成静音镜头序列
设镜头关键帧集合和结果静音镜头序列分别为式(4)、(5)。
F={fj|1≤j≤N,j∈Z}
(4)
S={sj|1≤j≤N,j∈Z}
(5)
其中N为视频被分割成的镜头数目,fj表示第j个镜头的起始帧号,sj为需要生成的整型数值。为了生成S中的每一项sj,需要遍历集合F,对于其中每一项fj,判断是否存在正整数i,使得式(6)。
pi≤fj≤qi,1≤i≤K,1≤j≤N,i、j∈Z
(6)
其中K表示静音段落总数。若满足该条件表示镜头起始帧fj处在一个静音段中,但是并不意味着该静音段一定是新闻条目镜头转换之间的停顿,需进一步判断是否满足以下条件为式(7)。
qi-pi≥τ且fj-pi>qi-fj
(7)
其中τ为事先设置好的静音段长度的阈值,单位为帧。通过判断是否满足条件qi-pi≥τ即对静音段落的长度提出要求,以舍弃说话语句之间的短暂停顿。此外,大部分新闻节目有如下特征:新闻条目开始时的静音段时长较短,且新闻稿会在视频内容播完前结束。基于这样的观察,对静音段提出如下条件限制:镜头起始帧fj将静音段落分割成了前后两个部分,要求fj-pi>qi-fj,即前一部分的长度要大于后一部分。
若上述条件均被满足,则sj=1;否则sj=0。从而最终得到静音镜头序列S。
2.5 新闻拆条分析阶段
该阶段根据已得到的主持人镜头序列和静音镜头序列确定新闻条目的分界点,从而完成新闻拆条的工作。以图1所示的新闻结构为例,在2.3.2节中已知其主持人镜头序列H为10…010…0110…00…0,将该新闻视频通过语音段检测阶段和静音段分析阶段,得到其静音镜头序列S为11…011…0110…01…0。这两个序列均为N位,省略号都省去了0。每一位数字代表其对应的镜头起始帧是否含有主持人或者是否处在满足本文算法要求的静音段中。结合分析这两个序列,在其中标定若干值,这些值所代表的镜头起始帧就是这段新闻视频中的新闻条目分界点。具体方法为:
遍历hi∈H,si∈S,1≤i≤N,若:
(1)hi=1,则新闻视频的第i个镜头的起始帧为新闻条目分界点;
(2)si=1且hi-1=0,i≥2,则新闻视频的第i个镜头的起始帧为新闻条目分界点。
条件(1)表示只要是主持人在新闻节目中出现,算法就认为其是新闻条目的分界点。条件(2)根据静音段来确定新闻条目分界点,hi-1=0的限定是为了解决毛刺问题,在本例中当i=2时就会出现毛刺问题:对于“主持人播报+详细视频内容”模式,往往在主持人播报完毕后出现一段静音,使得下一个镜头起始帧就处在了满足算法要求的静音段中,静音镜头序列中被标记为1,而上一个主持人镜头起始帧才应该是这段新闻条目的起点,于是出现了毛刺现象。
至此,本文算法找出了新闻视频中不同新闻条目的分界点,完成了新闻拆条的工作。
3 算法实验与结果
3.1 实验数据与评价标准
本文所使用的测试数据为时长3 000分钟的中央电视台新闻联播节目,其格式为MPEG-4影片,画面帧大小为640*480像素,视频帧率为25f/s。针对这些新闻视频进行人工的新闻条目分界点标注,总计得到1 309个新闻条目分界点。算法得到的新闻条目正确分界点必须精确到新闻条目的起始帧。本文通过以下三种数值来评估新闻拆条算法:
(1)新闻边界点召回率recall=算法得到的正确分界点个数/应得到的正确分界点个数;
(2)新闻边界点准确率precision=算法得到的正确分界点个数/算法得到的所有分界点个数;
(3)新闻边界点值F1=2×召回率×准确率/(召回率+准确率)。
3.2 实验结果与分析
3.2.1 总体实验结果与分析
本文算法测试上述数据集得到分界点个数为1 202个,其中正确的分界点1 121个,实验结果为:召回率0.856 3;准确率0.932 6;F1值0.892 8。
算法在实验中存在漏检情况有以下原因:
(1)由于没有绝对的标准阈值界定新闻条目间的静音段时长,新闻条目分界点所处的静音段存在长度小于阈值的情况,且占据了算法漏检的较大比重。
(2)新闻视频中存在“主持人播报详细内容”模式与其他新闻的“详细视频内容”相连的情况。在2.5节中提到了主持人播报的语音毛刺问题,其解决方式为忽略主持人播报后的静音毛刺,而详细视频内容主要依靠静音段检测,因此当这两种模式相连时,算法会出现漏检“详细视频内容”模式新闻条目的情况。
算法在实验中存在错检情况的主要原因是新闻内容中存在长度大于阈值的静音段落。这类情况主要发生在新闻播报内容为人物演讲时,此时视频鲜有背景杂音,只有人说话的声音,而演讲往往抑扬顿挫,语句之间也会存在有较长停顿的情况。
3.2.2 静音段长度阈值对实验结果的影响
从上述分析中可知,算法所设的静音段阈值对新闻拆条的结果有着十分重要的影响。当阈值较高时,得到的新闻条目分界点个数会较少,即漏检情况发生较多,从而召回率较低,但准确率较高;当阈值较低时,得到的分界点个数会增多,即错检情况发生较多,从而准确率较低,但召回率较高。本算法采用不同的静音段阈值进行实验所得到的结果,如图2所示。
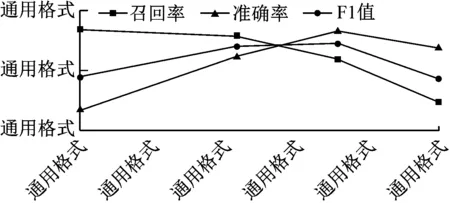
图2 静音段长度阈值对实验结果的影响
当阈值取值在50左右时,F1值处在总体较高水平。
3.2.3 静音段限制条件对实验结果的影响
在2.4.2小节中介绍了算法在静音序列生成阶段,通过条件限制筛选得到符合要求的静音段落。本节通过对比实验佐证了静音段限制条件对实验结果的影响,结果如图3所示。

图3 静音段限制条件对实验结果的影响
当有限制条件时,算法得到的召回率、准确率和F1值均高于无限制条件时的结果。
3.2.4 处理音频毛刺对实验结果的影响
3.2.1节提到了新闻视频中有主持人播报后直接连接其他新闻详细视频内容的情况,这种情况与算法所设置的处理音频毛刺现象的方法相冲突,从而导致算法产生漏检情况,影响了算法的召回率。本节通过对比实验得出处理音频毛刺现象对实验结果产生的影响,如图4所示。
在不处理毛刺现象时算法得到的召回率更高,但准确率远低于处理毛刺现象时的结果,从而在值方面要差很多。这

图4 处理音频毛刺现象对实验结果的影响
说明在新闻视频中主持人播报后紧跟其他新闻的详细视频内容情况的出现频率要比“主持人播报+详细视频内容”的常规模式低很多。尽管不处理毛刺现象可以检测出一些被漏检的新闻条目分界点,但也造成了更多的错检情况的发生。
3.3 其他算法结果对比分析
本文算法与其他算法的对比结果。所选取的数据集均为新闻联播节目,如表1所示。

表1 对比实验分析结果
[5]采用四集约128分钟的新闻联播作为实验数据集,其算法同样是基于主持人和音频静音段特征,默认主持人播报始终是单独的新闻条目,即使主持人播报后有相关新闻的详细视频报道,也认为是两个不同的新闻条目,在此前提下得到较高的召回率,但准确率较低。参考文献[7]同样对四集新闻联播进行实验,使用了主持人特征、主题字幕特征和音频静音段特征,对新闻视频中的故事单元进行切割,获得了不错的实验结果,但其新闻分界点的边界精确度为秒。
4 总结
本文提出了一种新闻视频拆条算法,主要工作体现在以下几个方面:
(1)仅采用最普遍且最关键的主持人特征和音频静音段特征来设计新闻拆条算法;
(2)以镜头关键帧作为切入点进行处理,相比于以固定时长的一小段视频为切入点进行处理,且边界精确度为秒的新闻拆条算法,本文的算法在节约计算时间的同时,提高了条目边界的准确率;
(3)针对从新闻视频中提取的音频静音段落进行筛选,对静音段落有长度和其他条件限制,同时针对静音的毛刺现象进行处理,使算法的值大有提高。
(4)针对同一类型的新闻视频,本文相比于其他算法使用了大量的实验数据,以验证算法的各项性能。
参考文献
[1] Goyal A, Punitha P, Hopfgartner F, et al. Split and Merge Based Story Segmentation in News Videos[C]//31st European Conference on IR Research. Toulouse, the 2009, 766-770.
[2] Misra H, Hopfgartner F, Goyal A. TV news story segmentation based on semantic coherence and content similarity[C]//Proceedings of the 16th international conference on Advances in Multimedia Modeling. Chongqing 2010, 347-357.
[3] Zlitni T, Bouaziz B, Mahdi W. Automatic topics segmentation for TV news video using prior knowledge[J]. Multimedia Tools and Applications,2016,75(10): 5645-5672.
[4] Ma C, Byun B, Kim I, et al. A detection-based approach to broadcast news video story segmentation[C]//Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing. Taipei, 2009, 1957-1960.
[5] Wei W, Gao W. Automatic segmentation of news items based on video and audio features[J]. Compute Science and Technology,2002, 17(2):189-195.
[6] Dumout E., Quenot G. Automatic Story Segmentation for TV News Video Using Multiple Modalities [J]. International Journal of Digital Multimedia Broadcasting, 2012.
[7] 刘嘉琦. 基于多模态特征的新闻视频结构分析[D]. 西安:西安电子科技大学. 2011.
[8] 冯柏岚,郑荣,陈智能,等. 一种面向海量广播电视监管的自动新闻拆条. 中国专利:CN 103546667A[P],2014-01-29.
[9] Smeaton] A F, Over P, Kraaij W. TRECVID—an over-view[C]//Proceedings of TRECVID. 2003.
[10] Wu Shuzhe, Kan Meina, He Zhenliang, et al. Funnel-Structured Cascade for Multi-View Face Detection with Alignment-Awareness. Neurocomputing (under review), 2016.
[11] Zhang Jie, Shan Shiguang, Kan Meina, et al. Coarse-to-Fine Auto-Encoder Networks (CFAN) for Real-Time Face Alignment[C]//ECCV 2014.
[12] Liu Xin, Kan Meina, Wu Wanglong, et al. VIPL FaceNet: An Open Source Deep Face Recognition SDK[J]. Frontier of Computer Science.
[13] 刘波.基于短时能量和过零率分析的语音端点检测方法研究[D].武汉:武汉理工大学,2007.
猜你喜欢
文萃报·周五版(2024年11期)2024-04-09 17:59:20
橡胶科技(2022年11期)2022-03-01 22:55:23
石油沥青(2021年3期)2021-08-05 07:41:08
福建中学数学(2021年5期)2021-03-01 02:05:44
语数外学习·高中版中旬(2020年8期)2020-09-10 21:53:41
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
电子制作(2017年9期)2017-04-17 03:00:46
中学数学杂志(高中版)(2016年5期)2016-11-01 14:02:58
发明与创新(2016年34期)2016-08-22 03:01:04
