
基于混合采样的患者投诉中安全事件的自动识别
2018-03-21 08:11:46,,,,,
中华医学图书情报杂志 2018年8期
,, ,,,
患者投诉是在医疗活动过程中,医务人员及机构未能满足患者的预期而导致患者产生的抱怨[1]。医院收到的患者投诉过多将会影响医院的形象,及时处理患者投诉一方面可以发现容易导致医患纠纷或医院暴力事件的原因,从而对可能发生的医疗纠纷事件进行早期预警;另一方面医疗机构可以根据患者投诉有针对性地改进医疗服务质量,提高患者满意度。因此对患者投诉进行分析和解读十分必要[2-3]。
患者安全是评估医疗服务质量的重要指标,旨在将与医疗保健相关的不必要伤害风险降低到可接受的最低水平。患者安全事件是可能导致或已经导致对患者不必要伤害的事件或情况[4]。患者投诉中涉及安全事件的投诉表明患者及其家属认为患者经历了不该遭受的痛苦。患者安全事件容易导致医患矛盾进一步恶化,甚至引起医疗纠纷事件或医疗暴力事件[5-6]。
医疗机构每天都会收到大量的患者投诉,涵盖医院各个方面。人工分析这些投诉文本并将其分类,不仅成本高且效率低。其中大量投诉涉及医患沟通、医务人员服务态度和医院环境等问题[7]。患者安全的投诉在所有患者投诉中占比较少,不均衡的文本会导致分类器性能下降。因此,如何在患者投诉类别分布不均衡的情况下,提高文本分类的性能是一个亟待解决的问题。
本文拟采用混合采样方法改善患者投诉语料分布不均衡的状况,对某医院的患者投诉进行文本分类,以有效识别患者投诉中的安全问题。
1 患者投诉及不均衡分类的相关研究
1.1 患者投诉分类
研究者利用自然语言处理的方法分析患者投诉。Gillespie[8]根据患者投诉的主题将患者投诉分成临床、管理、关系3个大类,细分为质量、安全、环境、管理制度、倾听、沟通和尊重患者权利7个子类,并在此基础上形成了分类框架体系(Healthcare Complaints Analysis Tool,HCAT);Elmessiry[9]搜集了来自范德比尔特大学及相关机构的患者投诉,使用6个分类器对投诉进行分类,用以判断投诉内容是否与医生相关,找出需要医生改进的患者投诉意见;Harrison R[10]通过对患者投诉进行主题分析,发现投诉主要存在临床、管理和关系3个领域(表1)。
1.2 不均衡数据的处理方法
患者投诉的不均衡分类主要有算法改进和数据处理两种解决方案。数据处理易实现,是处理不均衡数据的主流方法。数据处理是对数据集进行重新采样,使不均衡比达到期望比例,以提高分类器的性能,处理方法有欠采样、过采样和混合采样。欠采样是对多类样本进行有选择的删减操作未降低数据的不平衡程度,方法有Ramdom Under Sampling,Tomek Links Removal以及Edited Nearest Neighbor等。欠采样使得训练集规模变小,训练时间更短,但舍弃样本易导致模型无法捕捉数据特征造成欠拟合。过采样是人工合成少数类样本平衡数据集,过采样生成新样本后训练时间变长,容易造成过拟合。Chawla提出了用SMOTE算法[11]合成样本,后来的学者对SMOTE算法容易造成过拟合的缺点进行了改进。如Han[12]提出了Borderline-SMOTE1和Borderline-SMOTE2算法,对边界样本进行处理。
混合采样是同时运用过采样和欠采样方法,解决单独使用欠采样和过采样的不足,常用方法有SMOTE结合Tomek Links Removal与SMOTE结合Edited Nearest Neighbor。

表1 患者投诉分类体系
2 实验数据
2.1 语料来源
本文选用了来自医院随访系统及微信应用程序搜集到的某医院2012-2017年的患者投诉文本,去除内容重复、投诉无明确意义、投诉文本不完整等语料后,得到实验语料7 009条。
2.2 纳入标准
根据患者安全事件的定义及Heather Sherman等的分类标准[4],结合实际使用的投诉语料,本文将涉及以下4类主题的患者投诉视为患者安全事件投诉(表2)。

表2 患者安全事件投诉纳入标准
2.3 语料标注
根据患者安全事件投诉纳入标准进行人工标注,得到“患者安全”类的投诉文本660条,其他投诉6349条,二者不均衡比为1∶9.62。其中将“患者安全”投诉列为小类,“非患者安全”投诉为大类。
3 方法流程
本文的实验过程如图1所示。
3.1 人工标注
标注团队由两名医学生与1名自然语言处理专家组成。先由医学生对投诉文本内容进行标注,然后由专家对标注结果进行审核,对不一致的标注结果则由专家给出最终意见。经过反复核对与修正,使最终标注结果的一致性达到100%。
3.2 数据预处理
采用Python平台的jieba分词工具,对文本进行了分词和词性标注。由于文本中包含了一些医学术语,因此加入自定义词表以强化分词效果(自定义词表包括ICD-10疾病名称与中文MeSH主题词),最后将分词的结果利用Word2vec映射到向量空间中。
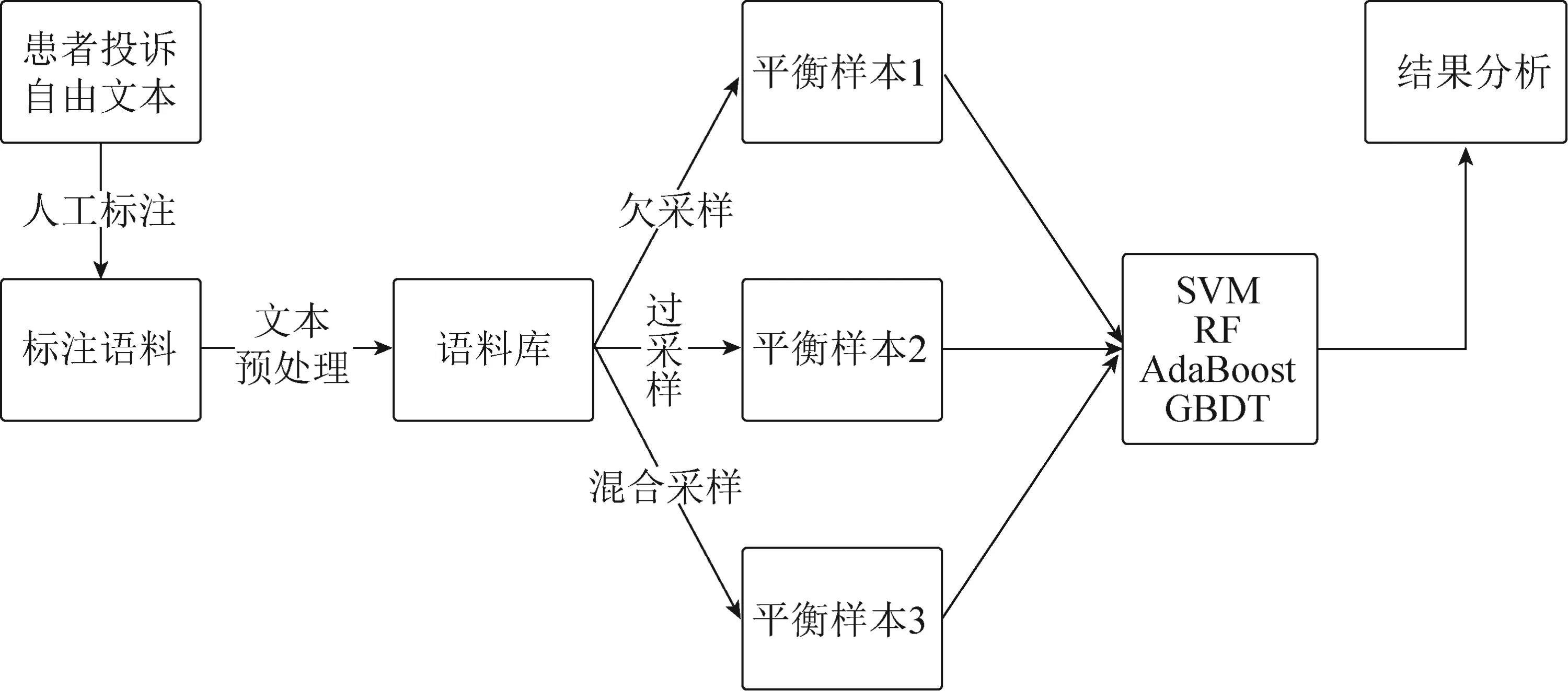
图1 实验研究过程
3.3 分类实验
考虑不同的不均衡比例会影响分类器的分类结果[13],本文设置1∶1、1∶2、1∶3、1∶4等4种不均衡比例,利用支持向量机(Support Vector Machine,SVM)、随机森林(Random forest,RF)、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)和AdaBoost 4种分类器,对利用某一采样方法平衡后的数据集进行分类。对分类结果采用十折交叉验证的方法进行评价,即将数据集分为10份,轮流将其中9份作为培训集,1份作为测试集进行试验,取10次试验结果的平均值作为最终的性能测试结果。
通过对比以下几种方法,找到最佳分类配置:方法1,对原始数据集不做任何数据的平衡处理;方法2,对数据集采用无放回的随机欠采样(Random Under Sampling)的处理,使少数类与多数类不均衡比分别达到1∶1,1∶2,1∶3,1∶4;方法3,使用过采样方法对数据集采用Borderline-SMOTE 2合成少数类样本,使少数类与多数类不均衡比分别达到1∶1,1∶2,1∶3,1∶4;方法4,使用混合采样方法采用SMOTE-ENN[14]算法,使少数类与多数类不均衡比分别达到1∶1,1∶2,1∶3,1∶4。
3.4 评估指标
本文使用精确度(Precision)、召回率(Recall)、F值(F-measure)对分类器的性能进行评价。精确度代表被正确分类的小类占所有预测为小类样本的比例、召回率代表被正确分类的小类样本占实际小类样本的比例,F值则是上面两个值的加权平均和评价分类器的常用评估指标。
考虑到不均衡问题,不能只从准确率即所有被正确分类的样本占总样本的比例来考察分类器对少数类的分类能力,因为当类别极不均衡时,分类器会倾向识别多数类。此时准确率虽然很高,但是少数类识别的准确率较低。为此引入G均值(G-mean)、受试者工作特征曲线(Receiver Operating Characteristic Curve,ROC)、曲线下面积(Area Under Curve,AUC)以及PR曲线下面积(Area Under the PR Curve,AUC-PR)[15]综合考量分类器对于少数类识别的准确性。G均值是小类和大类精确度乘积的平方根,ROC曲线下面积值用来综合考虑大类和小类的分类结果和评估分类器的整体性能,PR曲线下面积值则更多的关注小类分类结果。
6个指标值的范围都在0-1之间,分类结果高于0.8,说明分类模型性能良好,越接近1,说明分类模型性能越好。
4 结果
4.1 无处理的数据分类结果
无处理的数据分类结果见表3。4个分类器中,RF的总体表现优于其他分类器,召回率均低于50%,4个分类器的分类性能均不理想。
表3无处理的数据分类结果/%

分类器精确度召回率F值G均值AUCAUC-PRRF83.2845.3058.4866.7292.5970.52SVM100.004.097.7919.6465.8551.59AdaBoost61.5929.3839.5852.9375.5742.80GBDT77.7326.4439.0750.0981.3349.82
4.2 欠采样结果分析
欠采样数据分类结果见表4。欠采样方法中的召回率均低于70%,分类性能一般,说明随机欠采样方法不适用于本文数据。与其他不均衡比例相比,不均衡比例为1∶1时,分类结果最优。
表4欠采样处理后数据分类结果/%

不均衡比例分类器精确度召回率F值G均值受试者工作特征曲线下面积PR曲线下面积1∶1RF75.2767.3870.7072.2482.5584.85SVM100.005.7610.7723.2467.5279.58AdaBoost70.5067.6368.8569.7276.1478.77GBDT74.3967.1870.3571.5880.7583.051∶2RF91.4841.4256.7763.5681.3975.78SVM100.006.6012.2224.9468.8272.28AdaBoost66.3154.5559.4968.3078.7572.30GBDT82.4047.1059.7966.7582.5876.131∶3RF95.6238.4454.3861.5582.3071.42SVM100.006.2411.6724.5868.3465.87AdaBoost66.6747.6655.1966.0880.2867.62GBDT89.0740.7555.6963.1882.5170.921∶4RF95.8236.4052.6060.1082.3267.66SVM100.006.1711.5224.1868.8263.95AdaBoost68.1043.6453.0764.2278.8061.51GBDT89.9938.0053.3161.1884.0569.02
4.3 过采样结果分析
过采样数据分类结果见表5,处理后的数据样本不均衡比例为1∶1时,RF的G均值为97.93%、AUC为99.07%,AUC-PR为99.34%,相较于其他分类器都达到了较好的水平。同时与欠采样数据同样印证了在不均衡比例为1∶1时,分类结果最好。
表5过采样处理后数据分类结果/%

不均衡比例分类器精确度召回率F值G均值受试者工作特征曲线下面积PR曲线下面积1∶1RF99.5396.3597.9197.9399.0799.34SVM99.9877.1787.1087.8398.7199.21AdaBoost91.5393.4192.4592.3697.4097.85GBDT97.3195.7096.5096.5298.6799.061∶2RF99.2991.8895.4395.6998.0597.76SVM99.9451.3967.8571.6797.2797.57AdaBoost86.7685.1385.9089.1795.3493.57GBDT97.2787.8692.3193.1597.4296.901∶3RF99.0184.3091.0691.6897.0295.60SVM99.8735.7652.5559.7195.7495.49AdaBoost83.0975.6179.1184.6792.7486.90GBDT96.7776.3785.3387.0095.7493.341∶4RF98.0472.1383.0884.7695.5091.81SVM100.0024.8239.6949.7493.4392.37AdaBoost80.7968.7674.2481.1991.5782.37GBDT96.6966.0178.4080.9994.0489.04
4.4 混合采样结果分析
混合采样数据分类结果见表6。不均衡比例为1∶1时,RF的精确度和PR曲线下面积相较于其他分类器基本持平,召回率96.27%、F值97.91%、G均值97.97%、受试者工作特征曲线下面积99.82%,相较于其他分类器结果最好。
表6混合采样处理后数据分类结果/%

不均衡比例分类器精确度召回率F值G均值受试者工作特征曲线下面积PR曲线下面积1∶1RF99.6296.2797.9197.9799.8299.81SVM100.0054.0470.1273.4999.7899.84AdaBoost91.9391.7491.8192.5697.9997.88GBDT97.1493.3395.1895.5199.2099.141∶2RF99.7790.5294.9095.0999.7199.55SVM100.0040.1657.2663.3499.0899.11AdaBoost91.2688.5589.8692.2197.8496.47GBDT97.9787.6192.4993.1999.2198.701∶3RF99.8081.3489.5690.1399.3198.47SVM100.0031.9948.4056.5098.0797.80AdaBoost92.2486.1489.0291.8198.0795.89GBDT98.3883.8190.4791.3499.1097.891∶4RF99.6778.4887.7188.5199.2398.19SVM100.0028.2243.8452.9798.0697.63AdaBoost93.7185.0089.1191.5598.1295.73GBDT99.5480.4988.9889.6699.2497.89
实验结果说明,患者投诉不均衡比越大,分类结果越差。使用不同的采样方法与同一种分类器结合,其性能从高到低依次是混合采样、过采样、欠采样。
5 讨论
5.1 不同采样方法的影响
对于患者投诉数据集而言,过采样方法总体表现优于欠采样方法,可能是因为欠采样删除部分多类样本后,丢失了部分关键的数据特征。过采样与混合采样相比性能较差,可能是因为过采样依据现有少量样本合成少类数据,产生了过拟合问题。而混合采样同时对多类数据和少类数据进行处理,使得数据趋于均衡,避免了数据特征丢失和过拟合问题,从而能够获得较好的少数类分类效果。本文使用文本分类和混合采样的方法处理患者投诉,相对于未采用不均衡数据处理的数据,分类性能获得极大提升,召回率由45.30%提升为96.27%,F值由58.48%提升为97.91%,G均值由66.72%提升为97.97%,PR曲线下面积由70.52%提升为99.81%。
5.2 不同分类器的自动识别性能
从机器学习方法的角度看,综合对比3种采样方法4种比例的12种不同组合,根据每个组合中分类器取得最高指标的次数确定最优结果,统计得出RF分类器、GBDT分类器和AdaBoost分类器分别取得最优结果为9次、2次、1次。其中RF分类器取得最优结果次数最多,并在3种采样方法下均有最优结果。
使用混合采样方法在比例为1∶1时,性能达到最优,显著优于其他分类器,证明RF相较于其他分类器更适合不均衡下患者投诉分类。原因在于,与其他分类器相比,RF分类器更擅长处理高维数据、泛化能力更强,适合分类由高维、稠密的词向量映射成的句向量[16]。
本文利用了混合采样的算法在数据层面进行了处理,这样减少了因单一采样方法而导致的过拟合问题;使用了领域语料映射词向量,映射成的向量包含更加丰富的语义信息;采用了适合患者投诉分类的机器学习方法随机森林,从而达到了更好的分类性能。
6 结论
患者投诉中涉及安全投诉的文本少,会出现样本不均衡问题,导致分类器性能降低,无法有效识别“患者安全”类投诉。本文提出了一种基于混合采样的数据处理方法平衡原始数据集,利用多种分类器对“患者安全”类别数据进行分类的结果表明,混合采样方法可以有效提升不均衡数据的分类性能,使用混合采样法不均衡比为1∶1时,RF的分类效果可以满足实际应用的需要。
本文所使用的方法具有复杂程度低、容易实现、便于医疗机构使用等优点,可以有效识别涉及患者安全的投诉文本,提高处理患者投诉的效率。准确识别患者安全事件相关的患者投诉,便于医疗机构管理者及时干预,先于医疗纠纷或暴力事件发生前对不良因素进行防范、改正,避免医疗纠纷的发生。
猜你喜欢
现代装饰(2022年5期)2022-10-13 08:47:36
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
数学小灵通(1-2年级)(2020年4期)2020-06-24 05:47:08
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
电子测试(2018年1期)2018-04-18 11:52:35
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
作文周刊·小学一年级版(2016年23期)2017-06-05 23:27:03
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
