
多核处理器发展趋势及关键技术
2018-03-16 06:17胡海明
计算机工程与设计 2018年2期
周 楠,胡 娟,胡海明
(1.中国航天科工集团第二研究院706所,北京市 100854;2.中国电子科技集团公司第十五研究所,北京 100083)
0 引 言
多核技术相关的研究已成为当前处理器研究领域的重点,例如多核处理器的架构设计、低功耗设计、片上互连与通信技术等。多核技术仍处于发展阶段,因此多核处理器的发展还具有极大的潜力。本文尝试从多核处理器发展趋势的分析着手,进一步分析多核处理器研究领域的五大关键技术,最后基于上述分析提出了多核处理器技术所面临的三大问题。
1 多核处理器发展趋势分析
1.1 处理器由单核向多核的发展
在单核处理器时期,为维持处理器性能的增长速度,主要采用两种方法:
(1)改进处理器制造工艺以提高CPU主频;
(2)提高指令执行效率,即增加每周期执行指令数(instruction per cycle,IPC)。
然而,这两种方法却会产生两方面的问题[1]。一方面,通过改进制造工艺,可以在芯片上集成更多的电路从而获得更高的时钟频率,但芯片的功耗与整个芯片的密度和运行时钟频率成正比,因此必将以增加整个芯片的功耗作为时钟频率提升的代价。如图1所示,到2005年左右,处理器芯片的功耗达到顶峰,其原因是当芯片的总功耗达到100瓦时,计算机降温系统不再能够轻易地对芯片进行冷却。因此,为了将芯片的功耗限制在一个可以接受的范围内,不能再简单地提高芯片时钟频率以提高芯片性能。
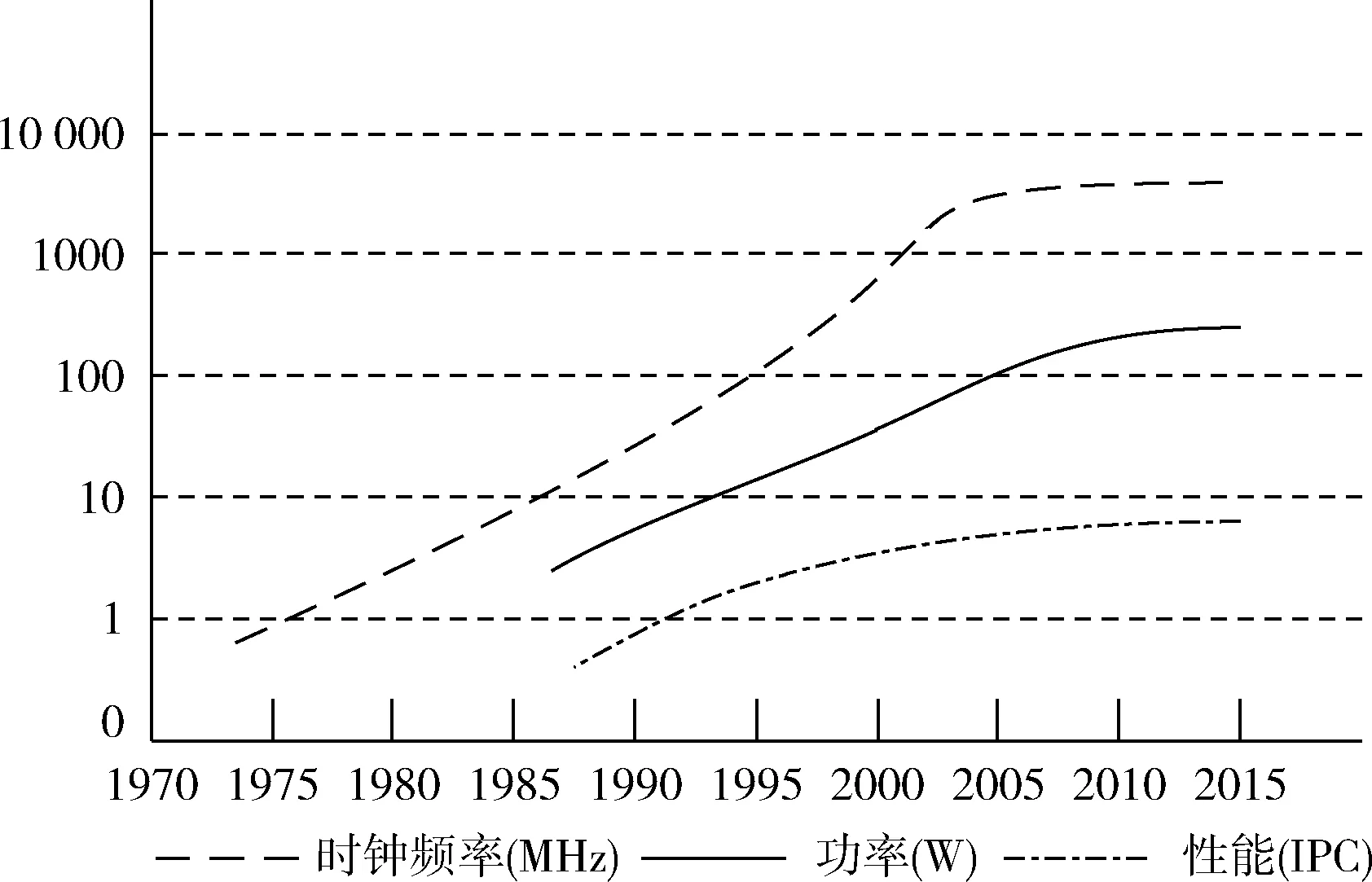
图1 芯片时钟频率、功耗及性能发展趋势
另一方面,为提高指令执行效率,目前的单核处理器广泛使用指令流水线、超长指令字、超标量结构、超线程技术等。但受限于单核处理器的执行能力,并没有从本质上显著提升处理器系统的性能。随着技术的发展,处理器核设计的复杂度已经停止增长,单芯片上可以集成的晶体管数量的不断增加,使得系统设计者可以在单个芯片上放置更多的处理器核,从而可以利用应用程序的线程/任务级并行来提高处理器性能。如图1所示,在2000年左右时钟频率到达极限时,处理器核的性能也趋于饱和。而由图2可知此时单个芯片上集成的核数开始迅速增长,且其增长速度甚至比摩尔定律所提出的速度(每两年翻一番)更快。这是因为设计者已经倾向于使用优化过的简单核而不再是功耗巨大的复杂核。基于上述两个问题,在单核处理器性能提升遇到瓶颈的情况下,处理器开始朝着多核方向发展。
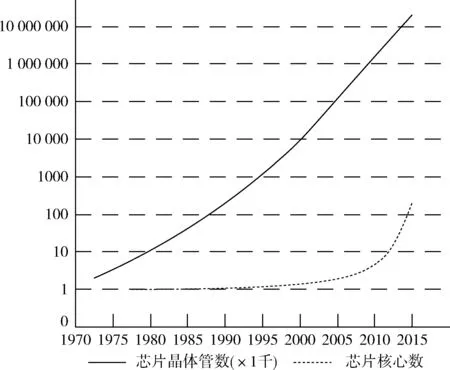
图2 芯片晶体管数、核数发展趋势
1.2 多核处理器由同构向异构的发展
根据同一芯片上集成的各个处理器核的结构是否一致,可将多核处理器划分为两类,即同构多核处理器与异构多核处理器
1.2.1 同构多核处理器
同构多核处理器内部由相同结构的核心构成,每个核心的功能完全相同,没有层级之分,可以看作传统SMP在单芯片上的实现。就功能/性能比同构多核处理器还可以分为:低功耗处理器和高性能处理器两种类型[2]。
(1)低功耗同构处理器
低功耗同构处理器的设计目标是使用小型的、同类的处理器核来降低处理器整体功耗。低功耗同构处理器按照应用侧重点还可以进一步细分为两类:面向低延迟的处理器的和面向高吞吐量的处理器。
1)面向低延迟的处理器
面向低延迟的处理器就是在低功耗条件下,能够快速响应应用的处理器。此类处理器通常应用在移动设备中,以同时满足设备的低功耗和应用实时性需求。例如,ARM的cortex-A9 MPCore处理器在一个芯片上就包含4个对称的核。每个处理器核包含一个乱序的八级流水线[3],可在具有功耗限制的设备中可以提供相对低的延迟,通常应用在手机、数字电视等移动设备中。
2)面向高吞吐量的处理器
对某些系统而言,系统的整体吞吐量是首要考虑因素。如在面向并行计算的大型系统中,需要大量的处理器核以同时执行多个线程。相对于较大的处理核,小型、低功耗的处理器核占用的面积更小,因此可以在同一块芯片上集成更多的小核以提升同时处理多线程的能力,从而提高系统整体吞吐量。MIT的RAW处理器和Oracle公司的SPARC T5都属于面向高吞吐量的处理器。
由MIT推出的RAW处理器[4]由一组可编程的片组成,这些片之间通过紧密集成的可编程互连结构进行连接。每个片包含一个顺序流水线以及私有的数据和指令内存。RAW处理器主要面向并行和多媒体应用,而且允许自定义操作。这种面向特定领域的处理器支持一些多媒体应用或同时执行多个线程,主要目的是提升整个系统的吞吐量。RAW处理器结构图如图3所示。
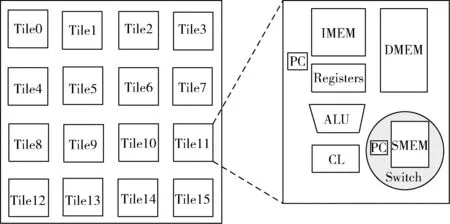
图3 RAW处理器结构
Oracle公司的片上多线程SoC处理器SPARC T5[5]在前一代T4处理器的基础上将处理器核数增加到16个,在将L3级缓存提升至8 MB的同时也将处理带宽提升了3倍。SPARC T5主要面向多线程应用,它同时最多可以执行1024个线程,最大带宽可以达到5.65 TB/s。SPARC T5相较于高性能处理器单线程性能可能相对较低,但是它支持同时执行多个线程,因而可以增加系统的整体吞吐量。此处理器适用于不需要进行大量计算的服务器,如web服务器等。
(2)高性能同构处理器
高性能多核处理器通常由几个较大的采用乱序执行模型的超标量核构成。这种处理器的主要目的是最大化单线程性能,常用于对性能要求较高的应用中。Intel研制的Core i7处理器就是典型的高性能同构处理器。它主要是针对服务器和桌面计算机设计的,因而它对于单个线程具有极高的性能。然而,其缺点是它的核数相对较少且支持较少的线程数,相较于小型的低功耗处理器SPARC T5其功耗也较大。
1.2.2 异构多核处理器
异构多核处理器架构作为一种系统设计方法,其主要目标是在严格的功耗限制下提升用户应用软件性能。
异构多核处理器通常由一个或多个通用处理器核和多个针对特定领域的专用处理器核构成,以实现处理器性能的最优化组合,同时有效地降低功耗。设计异构多核处理器系统时,主要考虑的因素有处理器核的功耗、性能和可编程性等。典型的异构多核处理器有IBM的Cell BroadBand Engine[6]和ARM推出的big.LITTLE[7]。
Cell处理器是针对特定应用的一款异构多核处理器,主要用于流媒体或类似的科学应用中。Cell处理器由一个主处理器(power processing element,PPE)和8个协处理器(synergetic processing elements,SPEs)构成。PPE是一个两路多线程通用处理器核,主要负责控制协调任务,并作为8个SPE的控制器。SPE则是单指令流多数据流(SIMD)向量处理器,其指令集主要由SIMD向量指令构成。通过将一个通用处理器核和8个小型却计算能力强大的核结合起来,使得Cell处理器具有优异的处理性能。Cell处理器结构如图4所示。
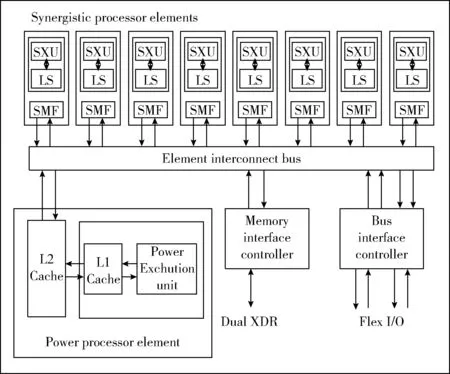
图4 Cell 处理器结构
ARM推出的big.LITTLE异构多核处理器由两个执行相同指令集的处理器:高性能的大型超标量处理器(ARM Cortex-A15)和高能效的小型顺序处理器(Cortex-A7)构成。在某些应用中,两个核可能不是同时保持着运行态,应用程序可以透明地在两个核之间切换,使用Cortex-A15以获得高性能,或使用Cortex-A7以降低功耗。如果有多个应用程序需要运行,则两个核都将保持运行态。一般而言应用程序都是预先静态地映射到它们最适合的核上,以获取性能最大化。big.LITTLE架构如图5所示。
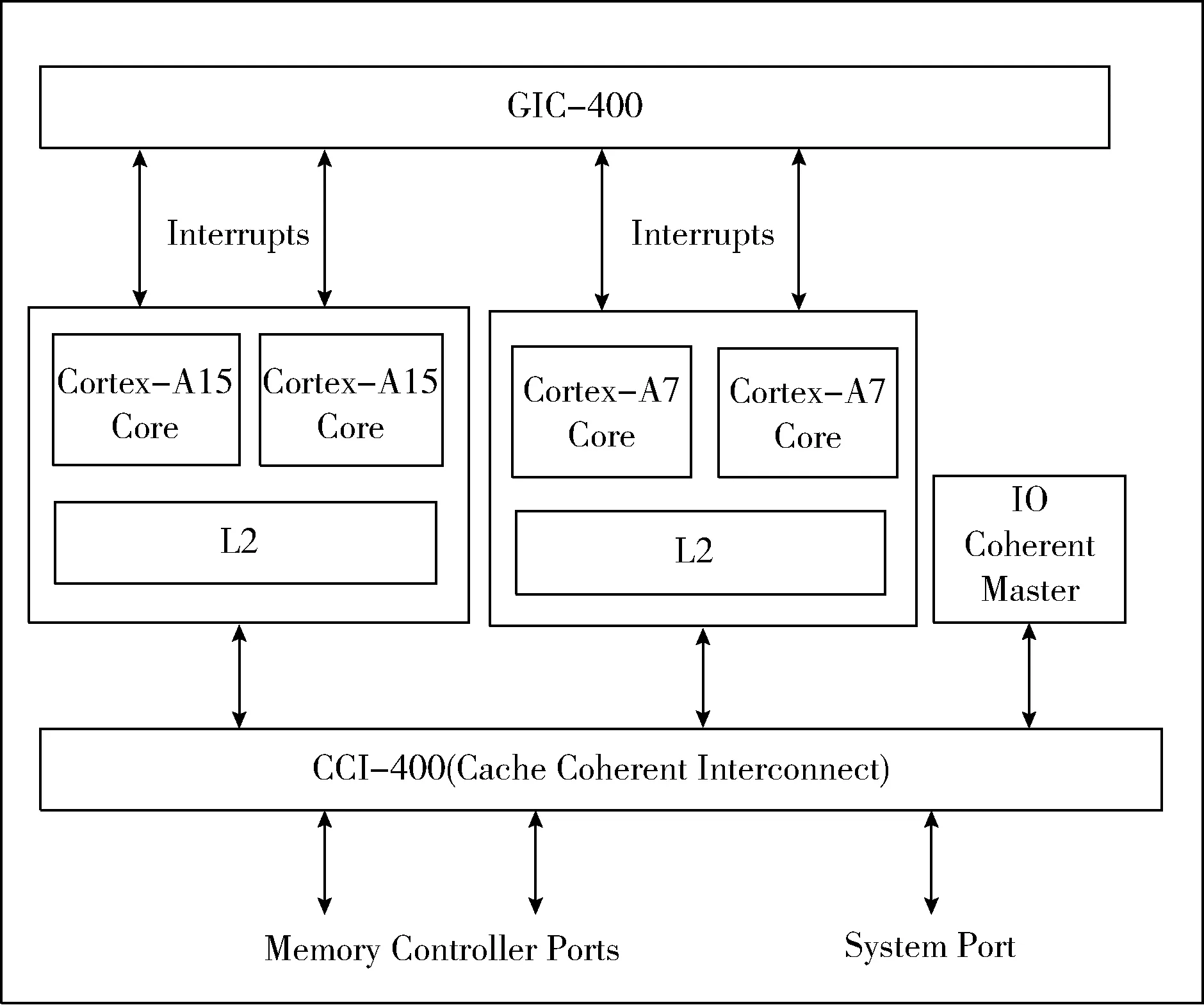
图5 big.LITTLE架构
由上述分析可知,异构多核处理器集成了多个功能、结构与运算性能都不相同的处理器核心,每个处理器核心分别负责各自的任务。因此可以更加灵活高效地均衡资源配置,提升系统性能,可有效降低系统功耗。同构多核处理器的发展却受制于Amdal[8](阿姆达尔)定律:不断增加同种类型CPU核心的数目虽然可以增强处理器并行处理器的能力,但程序中必须串行执行的部分却会制约整个系统处理性能的提升。因此,在同构多核处理器内部核心数目达到某一极限后,将无法再通过增加处理器核心数目来提升其性能。异构多核处理器的诸多优点都符合未来计算机系统发展的要求,因此异构多核处理器将成为未来多核处理器发展的趋势。
2 多核处理器关键技术分析
随着异构多核处理器的异军突起,其在传统的操作系统、并行计算方法以及多线程技术等领域都带来了较为深远的影响。就当前的多核环境而言,处理器的核间通信、任务调度、Cache一致性、核间同步与互斥、核间中断处理机制等技术都极为重要。下面分别对上述5点进行分析。
2.1 核间通信
随着单芯片上处理器核数的增多和计算复杂性的增加,处理器核间的互连和通信将会成为多核处理器系统的性能瓶颈,这需要更有效的处理器核间通信来提高性能,而不仅仅是它的处理速度。
目前主要使用的核间通信机制有3种方式:共享缓存的总线结构、共享总线结构和基于Noc的结构。
(1)共享缓存总线结构
该结构的特点是每个处理器核通过互连总线共享一个L2 cache或L3 Cache,以实现数据共享和互连通信。这是多核处理器领域最早的片上通信模式。图6、图7所示为共享缓存的总线的架构,其中图6(a)是统一缓存存取架构(uniform cache access,UCA)。在UCA架构中,所有处理器核统一共享L2 Cache,并拥有相同的存取延迟。这种架构可以平衡内部负载,具有更高的设备利用率。其缺点是,如果L1 Cache缺失,则会在处理器通过内部总线存取L2 Cache时造成较大的存取延迟和总线竞争。图6(b)是非统一缓存存取架构(non-uniform cache access,NUCA)。在NUCA架构中,每个处理器拥有一个本地L2 Cache。这种结构可以降低存取延迟和总线竞争,但是其缺点是,在L2 Cache中存在数据副本,因此设备利用率(容量利用率)较低。其次,这种架构预先划分了L2 Cache的容量,所以会导致负载不均衡。随着集成度提高,可以将L3 Cache集成到单个芯片中,这可以极大地解决处理器核之间的互连和通信问题,如图7(a)、图7(b)所示。
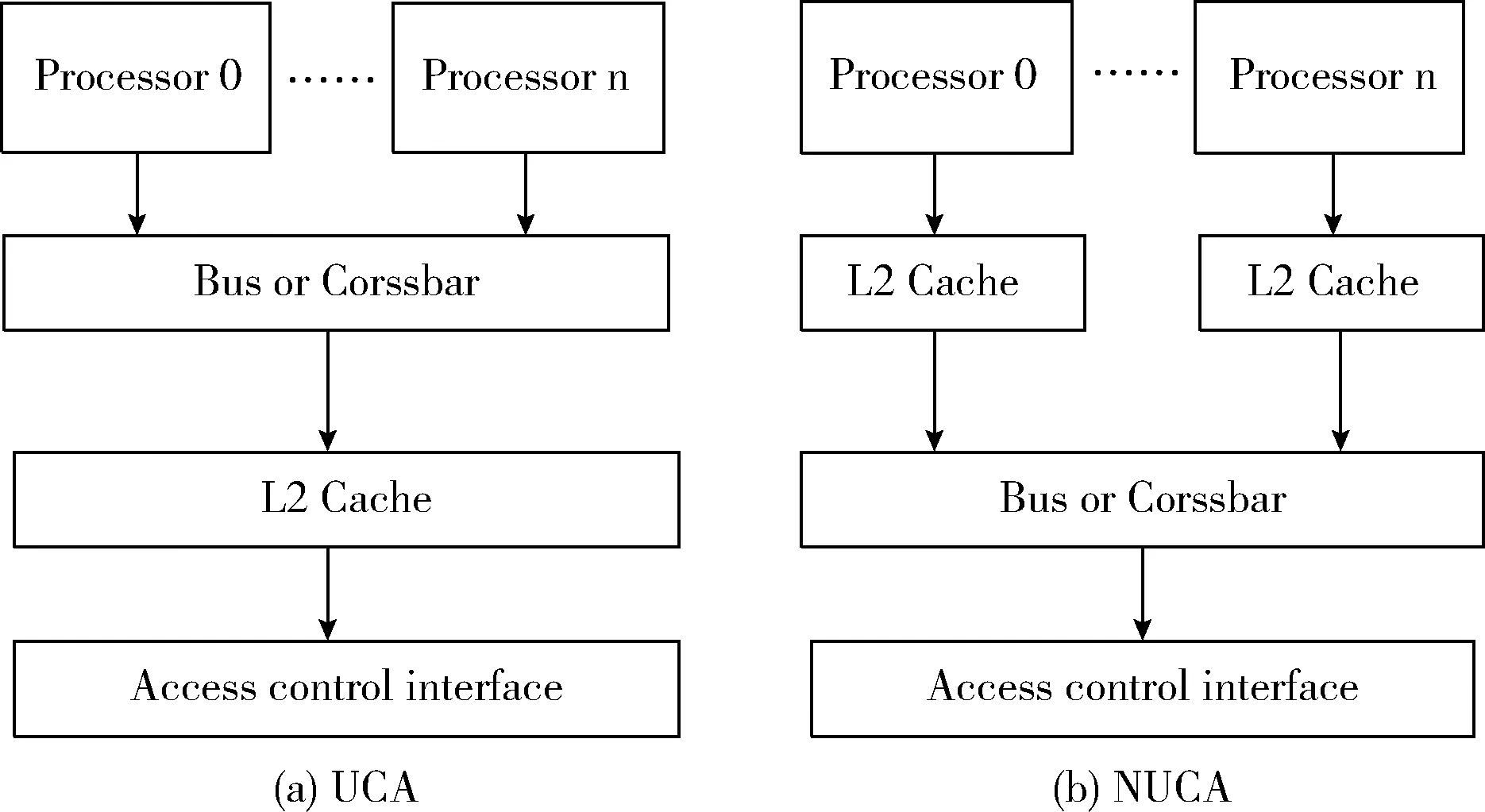
图6 UCA及NUCA架构
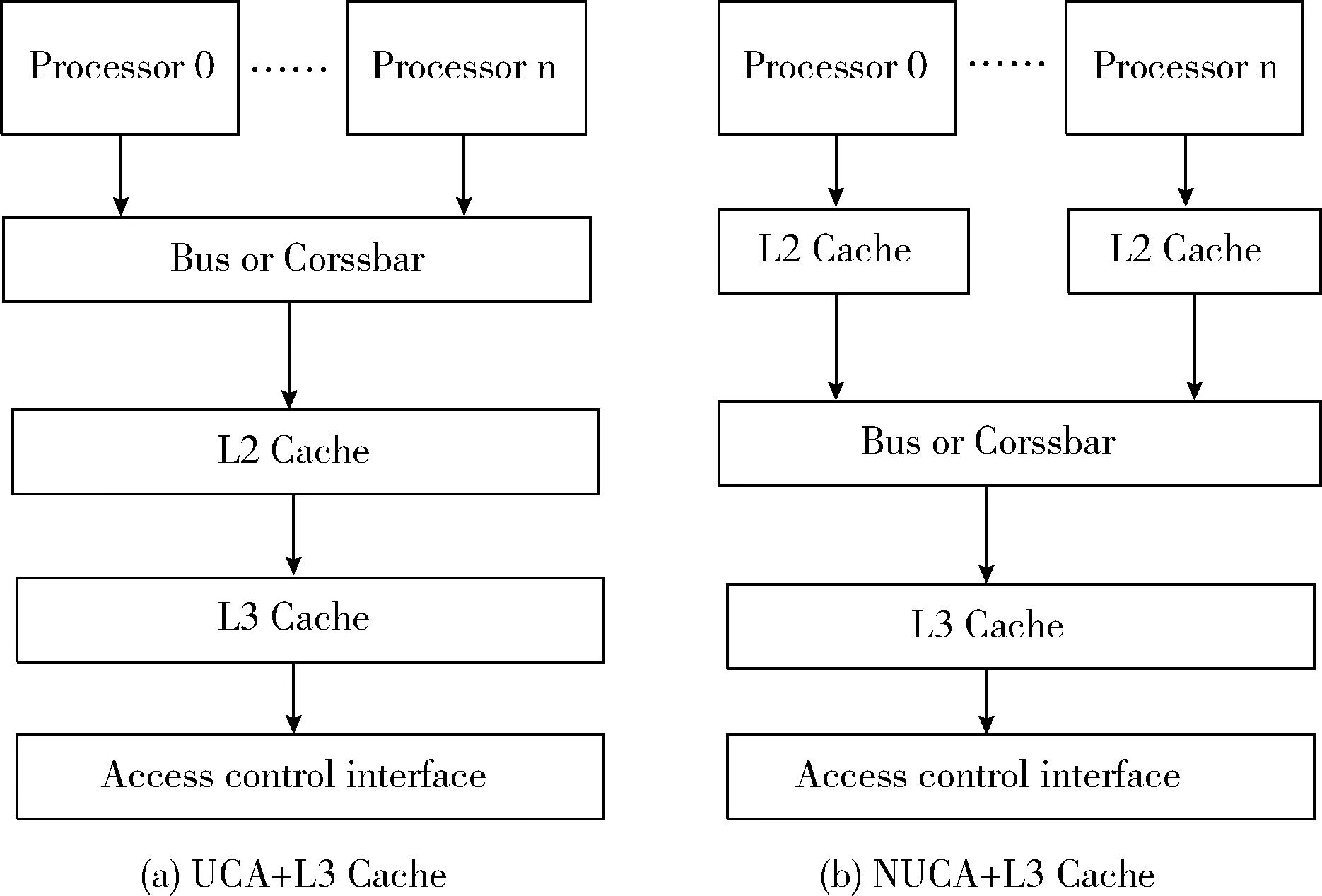
图7 带有L3 Cache的UCA及NUCA
共享缓存的总线结构的优点是结构简单、通信速度快等;其缺点是可扩展性差、延迟高,容易出现竞争和通信瓶颈。因此,这种结构适用于拥有少数处理器核的同构处理器。
(2)共享总线结构
共享总线意味着每个处理器核拥有单独的处理单元和存储,每个核通过交叉开关处理器核间的片上总线相连。其通信模型基于mailbox(邮箱),每个处理器核通过访问一个公有邮箱相互通信。
前述IBM的Cell处理器所使用元件互连总线(element interconnect bus,EIB)就是典型的共享总线结构。图8给出了其架构,作为片上互连的12个元件之间传输指令和数据的互联总线,它有4个数据环、一个共享的命令总线和一个中央数据仲裁器,这些部件一起连接起12个Cell BE元件。EIB允许每个SPE分段使用总线。每个环能够处理3个并发非重叠转移,允许此网络在EIB上同时支持12个数据转移。
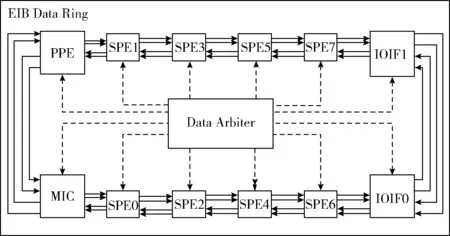
图8 元件互连总线
共享总线结构的主要优点包括简单的拓扑结构,低开销和高可扩展性,但其缺点是具有复杂的硬件架构,需要较大的软件改动,所以它主要应用在异构多核处理器中。此外“RISC+DSP”的架构同样采用这种通信模式。随着单芯片上处理器核数的增多,共享总线结构可以随之扩展并适应。然而,一些新问题随之出现,如,互连线延迟问题,系统全局同步问题,设计效率和重用问题等。因此,这种架构仅仅满足小规模处理器核间通信的需求。
(3)基于Noc的结构
Noc[9]意味着在单个芯片上基于网络通信实现了一个超级系统;它的主要思想是将网络技术移植到芯片设计上,以解决通信瓶颈问题和全局时钟问题。
典型的基于Noc结构的多核处理器是4*4的mesh-based RAW处理器,Inter的80-tile Noc连接的Tera-scale处理器,Tile64处理器等等。由前述可知RAW处理器主要由16个计算单元(Tile)和片上网络构成,每个Tile是RAW的一个基本功能单元。在Tera-Scale处理器中,每个核有两个独立的算术单元,2 KB数据缓存和3 KB的指令缓存。80个核按照8*10矩阵进行排列,使用2D自路由方法连接每个核。在Tile64处理器中,它使用称为imesh的网络来连接64个计算节点,每个节点有一个RISC和两个能够访问其它缓冲器的缓冲器构成。基于Noc的结构可以减少芯片面积,降低功耗,改善性能和提高可扩展性。它已经成为一种提供更高可扩展性、可靠性和更高带宽的解决方案。
2.2 任务调度设计
多核处理器上的任务调度技术已经十分成熟,比如简单的调度算法RR(round robin)、Linux经典调度算法DP(dynamic priority)、Linux2.6.23之后采用的完全公平调度算法CFS(completely fair scheduler)等。但这些传统的调度算法是基于以下两个前提的:
(1)处理器核是同构的,不存在结构与性能差异;
(2)处理器核的数目是固定不变的。
但是,对于异构多核处理器而言这些前提都不成立,传统任务调度算法在异构多核处理器上存在不足。因此,我们不能简单地将传统任务调度算法移植到异构多核处理器上。异构多核环境下的任务调度主要分为静态任务调度和动态任务调度两种类型[10]:
(1)静态任务调度适用于具有约束与依赖关系的任务,需要提前获悉任务的运行时间、任务优先级、任务间的数据承接关系以及当前处理器核的处理能力、拓扑结构等基本信息。在编译程序时就根据上述信息将任务分配到相应的处理器核上,且此任务分配过程是不可逆的。
(2)动态任务调度则无法在调度之前将任务分配到确定的处理器核上,而需要根据处理器核的实时负载情况进行任务分配,以达到各个处理器核上任务负载均衡的目的。
已有的一些采用构造任务状态图以支持关键路径的动态调度算法,需要实时获取前一阶段的整体调度信息,使得与任务调度无关的开销较大。Kallia Chronaki等[12]提出了一种支持关键路径的动态调度器,同典型的HEFT算法相比,该方法基于运行时发现的信息,可以在不使用数据库或先前调度信息的条件下完成任务调度。在具有快核和慢核的异构多核处理器上,调度器可以动态地将关键任务分配到快核上以提高性能。该调度器仍需进一步扩展调度策略,以根据运行时资源的可用性和应用的特点来灵活地进行任务调度,从而提高调度器的自适应性。
2.3 Cache一致性机制设计
Cache结构广泛应用于基于共享内存的多核处理器中。Cache用于将共享内存中的数据复制到本地处理器核上,以提升多核处理器数据访问的速度。这一复制过程会导致共享内存中的数据在各处理器核上都存在一份单独镜像的问题,因此不同的处理器核通过Cache访问同一地址时可能出现数据差异错误。为维护Cache访问的一致性,常采用如下4种典型的Cache一致性机制:
(1)监听协议;
(2)目录协议;
(3)Token协议;
(4)Hammer协议。
随着手机等移动设备的普及,移动多核处理器的需求日益增加。因为需要频繁地进行各种信号侦听与响应,处理器在维持本地Cache的一致性时需要消耗大量能量。当多核共享Cache一致性较弱时,可以利用应用程序使用内存的动态行为来调整Cache一致性协议,以降低维持一致性的功耗。基于此,Garo Bournoutian等[13]提出了一种架构以减缓维护智能手机中多核处理器的整体Cache一致性功耗。利用一种细粒度的方法,这种架构可以在较好的性能功耗比下实现较高的硬件Cache一致性。
在不同核和不同层次的共享Cache间进行数据转移和数据处理,会影响到内存访问延迟和功耗。高性能共享内存多核处理器的效率依赖于片上Cache层次结构的设计和一致性协议。Nitin Chaturvedi等[14]提出了一种优化的Cache架构,可以支持不同数量的Cache块,且各个块的容量大小可以不同。
传统的基于目录的Cache一致性协议在数据请求的关键路径上添加了额外的负载,降低系统整体性能。事实上,利用全局的共享高性能互连结构可以优化Cache一致性并降低额外的负载。Qi Hu等[15]利用多频段传输线实现了全局共享互连。利用聚合的频段资源,该互连结构可以扩展系统并行性以改善Cache一致性的效率。
2.4 核间同步与互斥
传统的单核处理器环境下,通过关中断并禁止在进入临界区时进行任务调度就可以实现互斥操作。但对多核处理器而言,实现互斥则更为复杂:对于多核处理器,由于多个处理器核独立运行代码,使得单核处理器下的互斥操作变得不再是互斥的[16]。
对于采用共享数据结构的多核应用程序,需要使用同步技术来协调多个核之间数据访问的正确性,目前多核系统中一般采用基于锁的方式来互斥地访问数据,以实现各个核之间的数据同步,然而基于锁的同步互斥方式只能线性地访问数据,效率较低,极大地影响了多核处理器的整体性能。因此,多核处理器下的核间同步与互斥技术显得极为重要。
在高速网络中线速数据流量监控是管理网络的必要手段,为满足线速需求,可以利用多核架构来并行处理流量监控从而提升信息处理能力。随着网络容量和复杂度的不断提升,为多核处理器在网络中的应用提出了挑战。为此,Patrick P.C.Lee等[17]提出了一种无锁的、Cache利用率高的同步机制,以应用在多线程的多核流量监控应用中。他们将这种同步机制嵌入到MCRingBuffer(多和共享环型缓冲)中,MCRingBuffer一方面允许并发的无锁数据存取,另一方面可以提升线程同步变量的Cache访问局部性。
2.5 核间中断处理机制
中断机制是一种用于通知处理器处理异步事件的机制。异步事件发生后会通过硬件向处理器发出中断请求,一旦处理器响应了中断请求就将保存当前状态下的寄存器值,运行中断服务程序(ISR)将异步事件处理完成,随后处理器返回之前的处理状态。中断机制使得处理器可以在异步事件发生后才进行相应的处理,而不是一直轮询是否有事件发生。核间中断则是在多核处理器系统中用于实现核间消息同步与传递的一种特殊中断。
核间中断机制[18]的作用是通过向核间中断控制器写入相应的值,以通知其它核挂起当前的任务执行序列并跳转至ISR执行新任务。在单核处理器系统中,一般使用一个外部中断控制器来解决所有中断处理请求。在多核处理器系统中则存在中断由哪个核处理的问题,若还是由一个处理器核负责处理所有中断请求,则此核上运行的任务将被频繁地中断,这就会影响到多核系统的整体性能。因而需要核间中断处理机制来将各个外部中断高效地分配到各个处理器核上,实现系统均衡的核间中断管理。
核间中断处理系统需要尽可能降低中断处理延迟,以提高软件的可靠性。基于国防科大自主研发的多核DSP芯片M-DSP,万晓阳等[19]设计和实现了一种多核中断处理系统,相较于单核中断处理系统,该系统集成了片级中断控制器(chip interrupt controller)和片内中断控制器(interrupt controller)。运行在M-DSP上的应用程序由中断处理系统驱动,中断处理系统一方面可以完成操作系统对应用程序的调度控制,另一方面能够实现M-DSP与硬件接口之间的信息传递。
3 多核处理器面临的问题
3.1 性能功耗比
传统单核处理器通常采用提升频率的方式来提升处理器性能,然而处理器功耗会随着频率的提升而急剧增加。因此在多核处理器的设计中主要通过降低处理器核频率来达到降低功耗的目的,但是这一定程度上会影响到处理器的性能。因此,在进行多核处理器系统设计时如何在功耗和性能之间达到一个平衡以争取最大的性能功耗比,就成为了一个重要的问题。
目前,通常从时间尺度和空间尺度实现多核处理器的低功耗设计。从时间尺度上可以采用降低处理器的工作时钟频率与电压,并且在一定时间范围内根据应用程序运行情况暂停处理器的部分运算部件的工作的方法来降低处理器功耗,但这种方式是以牺牲性能为代价的,比如针对关键资源的动态功耗管理技术。从空间尺度上,可将当前功耗较高的处理器核上的任务迁移到另一个可替代的处理器核,使功耗密度在整个处理器芯片上实现均衡分布。此方式对处理器性能影响较小,但需要有冗余的处理器核作为替代核,比如动态任务分配与迁移技术。因此,可通过结合这两类方法的优势以提升处理器的性能功耗比。
3.2 任务迁移与通信
相较于同构多核处理器,异构多核处理器的核之间存在差异性,这些差异性包括微架构、执行单元的数目和类型、执行单元的大小、本地Cache的大小、分支预测器的类型和大小,ISA等等。这将导致在其上进行高效的任务调度难度更大。高效的调度算法在进行任务调度时,需要考虑应用程序的特点、行为和相关性能,然后将这些任务正确地分配到不同类型的具有相应特性的处理器核上[20]。
此外,应用程序的行为可能随时发生变化,这就导致在一些执行阶段应用程序会有不同的行为特点,此时在不同类型的核上执行可能获得更好的性能。在某些阶段,一个线程可能在这个核上运行时具有最好的性能,在另外一些阶段则需要运行在另一个核上。虽然静态调度算法在执行之前就为核进行了固定的任务分配,从而避免任务迁移,但是动态调度更能适应负载的动态变化。动态调度可以充分利用异构系统的异构性从而增加应用程序的性能或者降低系统的能耗。此外,核之间的任务通信主要依赖核间通信机制,如何针对不同处理器架构设计相应的核间通信机制以提高处理器系统通信效率和吞吐量是一个亟待解决的问题。根据前述分析,未来处理器将朝着异构多核方向发展。因此,解决任务迁移与通信的问题应该结合异构多核环境,深入任务动态调度算法和核间通信机制的研究。
3.3 软件设计与开发
多核处理器在硬件上可以通过增加处理器核来提升整体的运算性能,但是不同的多核处理器可能具有各自的指令集架构,这就将软件设计的难题抛给了软件开发者[21]。在使用同构多核处理器时,已有的并行编程语言主要有MPI、OpenMP和Pthread等,尽管这些并行编程库的功能已经相当完善,但是仍然不能完全发挥出多核处理器的并行处理能力。当前主流的编程语言是C、Java和C++,在嵌入式领域较为流行的是C和C++。然而这些语言的编程模型都是针对统一的、共享内存的同构处理器而设计的,因此这些编程模型不适合于专用的异构多核处理器架构,这就为面向异构多核处理器的软件设计和开发带来了挑战。加强面向多核处理器的软件设计与开发,将有利于充分挖掘处理器潜力,提升应用程序的性能。然而当前针对多核处理器环境下的软件设计与开发还需要适应性更强的编程语言和并行编程模型,这将成为未来软件设计领域一个重要的研究方向。
4 结束语
多核处理器因其控制逻辑简单、整体功耗相对较低、核心数目易于扩展及具有良好的并行性能等优点,为摩尔定律的延续提供了一个新的方向并逐步成为各个处理器应用领域的主流。相较于同构多核处理器,异构多核处理器可以拥有更加灵活的处理器核配置,具有更高的性能功耗比。未来处理器将继续朝着低功耗高性能发展,在这一特点在嵌入式领域显得尤为突出。因此,处理器的发展趋势将进一步朝着异构多核低功耗高性能的方向发展。多核处理器相关技术已经经历了近20年的发展,许多技术日益趋于完善,但是多核处理器仍有巨大的潜力亟待发掘。因此,仍然需要进一步加深多核处理器核间通信、任务调度等关键技术的研究,以更完善地解决性能功耗比、任务迁移与通信及多核相关软件设计与开发等方面的问题。
[1]Tran AT.On-chip network designs for many-core computatio-nal platforms[D].Sacramento:University of California,2012:1-4.
[2]Sawalha LH.Exploiting heterogeneous multicore processors through fine-grained scheduling and low-overhead thread migration[D].Oklahoma:The University of Oklahoma,2012:4-25.
[3]Koppanalil J,Yeung G,O’Driscoll D,et al.A 1.6 GHz dual-core ARM cortex A9 implementation on a low power high-K metal gate 32 nm process[C]//International Symposium on Vlsi Design,Automation and Test.IEEE,2011:1-4.
[4]Abellan JL,Ros A,Fernandez J,et al.ECONO:Express coherence notifications for efficient cache coherency in many-core CMPs[C]//International Conference on Embedded Computer Systems:Architectures,Modeling,and Simulation.NJ:IEEE,2013:237-244.
[5]Hart JM,Cho H,Ge Y,et al.A 3.6 GHz 16-core SPARC SoC Processor in 28 nm[J].IEEE Journal of Solid-State Circuits,2014,49(1):19-31.
[6]Zhou R,Chen H,Liu Q,et al.A server model for reliable communication on cell/B.E.[C]//International Conference on Parallel Processing.IEEE Computer Society,2013:1020-1027.
[7]Greenhalgh P.Big.little processing with arm cortex-a15 & cortex-a7[J].ARM White Paper,2011,1(1):1-8.
[8]Ananthanarayanan G,Malhotra G,Balakrishnan M,et al.Amdahl’s law in the era of process variation[J].International Journal of High Performance Systems Architecture,2013,4(4):218-230.
[9]Ganguly A,Chang K,Deb S,et al.Scalable hybrid wireless network-on-chip architectures for multicore systems[J].IEEE Transactions on Computers,2011,60(60):1485-1502.
[10]GENG Xiaozhong.Research on key techniques of task scheduling based on multi-core distributed environment[D].Changchun:Jilin University,2013:14-20(in Chinese).[耿晓中.基于多核分布式环境下的任务调度关键技术研究[D].长春:吉林大学,2013:14-20.]
[11]Barthou D,Jeannot E.SPAGHETtI:Scheduling/placement approach for task-graphs on heterogeneous architecture[M]//Euro-Par 2014 Parallel Processing.Springer International Publishing,2014:174-185.
[12]Chronaki K,Rico A,Badia RM,et al.Criticality-aware dynamic task scheduling for heterogeneous architectures[C]//ACM on International Conference on Supercomputing,205:329-338.
[13]Bournoutian G,Orailoglu A.Dynamic, multi-core cache coherence architecture for power-sensitive mobile processors[C]//International Conference on Hardware/Software Codesign and System Synthesis.IEEE,2011:89-97.
[14]Chaturvedi N,Sharma P,Gurunarayanan S.An adaptive coherence protocol with adaptive cache for multi-core architectures[C]//International Conference on Advanced Electronic Systems.IEEE,2013:197-201.
[15]Hu Q,Wu K,Liu P.Exploiting multi-band transmission line interconnects to improve the efficiency of cache coherence in multiprocessor system-on-chip[C]//IEEE International System-on-Chip Conference.IEEE,2015.
[16]KONG Shuaishuai.Communication and interrupt researches based on embedded multicore processor[D].Chengdu:University of Electronic Science and Technology of China,2011:7-25(in Chinese).[孔帅帅.基于嵌入式多核处理器的通信及中断问题的研究[D].成都:电子科技大学,2011:7-25.]
[17]Lee PPC,Tian B,Chandranmenon G.A lock-free,cache-efficient multi-core synchronization mechanism for line-rate network traffic monitoring[C]//IEEE International Symposium on Parallel & Distributed Processing.IEEE,2010:1-12.
[18]LIJiaojiao.DesignandimplementationofthemainmodulesforoperatingsystemrunningonSMPprocessorplatform[D].Xi’an:XidianUniversity,2012:47-51(inChinese).[李娇娇.面向SMP架构处理器平台操作系统主要模块的设计与实现[D].西安:西安电子科技大学,2012:47-51.]
[19]WANXiaoyang,LIYong,LUOBo.DesignandimplementationofmulticoreDSPinterruptsystembasedonM-DSP[C]//MicroprocessorTechnologyForum,2014:1-6(inChinese).[万晓阳,李勇,罗波.基于M-DSP的多核DSP中断系统的设计与实现[C]//微处理器技术论坛,2014:1-6.]
[20]HungSH,TuCH,YangWL.Aportable,efficientinter-corecommunicationschemeforembeddedmulticoreplatforms[J].JournalofSystemsArchitecture,2011,57(2):193-205.
[21]GrayI,AudsleyNC.Challengesinsoftwaredevelopmentformulticoresystem-on-chipdevelopment[C]//23rdIEEEInternationalSymposiumonRapidSystemPrototyping.IEEE,2012:115-121.
猜你喜欢
小学教学研究(2022年5期)2022-04-28
科教导刊·电子版(2021年17期)2021-08-06
中学生数理化(高中版.高二数学)(2021年2期)2021-03-19
中学生数理化(高中版.高二数学)(2021年2期)2021-03-19
数字通信世界(2020年3期)2020-04-06
制造技术与机床(2019年4期)2019-04-04
商周刊(2019年1期)2019-01-31
中国洗涤用品工业(2017年2期)2017-04-16
现代防御技术(2016年1期)2016-06-01
通信电源技术(2016年6期)2016-04-20
