
基于并行DAGSVM的网络流量分类方法
2018-03-16 06:17梁文国
计算机工程与设计 2018年2期
梁文国,王 勇,俸 皓
(1.桂林电子科技大学 信息与通信学院,广西 桂林 541004;2.桂林电子科技大学 广西云计算与复杂系统高校重点实验室,广西 桂林 541004)
0 引 言
近年来,随着智能手机和平板电脑的普及、新网络应用不断出现,网络流量呈指数增长[1,2],原有的网络流量分类方法不足以在合理的时间范围内识别出其中的应用类型,快速准确地进行流量分类已经成为一个不可忽视的问题[3]。基于端口号映射的网络流量分类方法由于动态端口技术的使用而准确率越来越低;基于深层数据包检测的分类方法由于新应用普遍使用载荷加密技术、私有协议的原因,分类越来越困难[4];基于传输层行为模式的分类方法由于地址转换技术的限制,准确率受到影响。为了解决这些问题,近年来许多学者使用基于流统计特征的机器学习分类方法来进行分类[5,6]。其中,SVM算法具有坚实的统计学理论基础,对维数不敏感、泛化能力强、分类准确率高、稳定性好,适合用作网络流量分类技术。然而,SVM算法的时间复杂度是O(n3),当处理的数据集规模增大时,其计算量急剧增加,导致训练速度变慢。
针对上述问题,本文提出一种基于Spark的并行DAGSVM网络流量分类方法。该方法利用Spark基于内存分布式计算可以加快运行速度的优势,在其上实现DAGSVM方法得到并行网络流量分类模型来提高网络流量分类的效率。
1 相关工作
目前,为提高使用SVM算法进行网络流量分类的效率所做的研究可以分为算法和云平台两方面。在算法方面:邱婧等[7]提出一种基于支持向量机决策树的网络流量分类方法,该方法可以解决传统SVM算法训练时间较长和存在无法识别区域的问题,实验结果表明,该方法比OAA(one against all)、OAO(one against one)多分类SVM方法的训练时间更短,准确率更高。林海涛等[8]提出一种迭代优化SVM网络流量分类方法,通过训练SVM分类模型时不断迭代优化训练样本的参数向量达到最优分类模型,利用高斯牛顿算法预测参数搜索方向来加快训练速度,在保持较高分类精度的前提下比传统8种SVM分类方法的速度更快。在云平台方面:裴杨等[9]提出一种基于Hadoop平台的并行SVM网络流量分类方法,该方法先将训练数据集划分成多个子集,然后把这些子集分配到各个计算节点并计算得出支持向量,最后合并这些支持向量进而得到最终的分类模型,实验结果表明,在保持较高分类准确率的情况下,训练时间缩小并且可以依据实际需要近乎线性地增加计算节点以加快训练速度。Do Le Quoc等[10]提出一种可扩展的分布式SVM网络流量分类方法,该方法先使用Hadoop平台并行计算训练子集得到支持向量,然后把支持向量保存到相当于计算机缓存的Redis内存数据库中并去除重复支持向量,最后把支持向量实时地并入之前的训练子集、不断迭代直到支持向量不再变化,进而训练得到最优分类模型,实验结果表明,该方法使用19个Mapper节点时比单机SVM分类方法训练速度快9倍、分类速度快15倍。但是,Hadoop平台的分布式计算框架MapReduce在计算的过程中会把中间结果保存在硬盘中,导致其运算速度受到硬盘IO速度的制约。把中间结果保存在内存中,直到计算结束才把结果输出到硬盘可以进一步提高运算速度。
2 基于Spark的并行DAGSVM网络流量分类方法
2.1 Spark简介
Spark[11]是基于内存计算的分布式计算框架,它采用主从架构,由一个Master主节点和多个Worker从节点构成,Master负责管理整个集群,Worker负责完成分配的计算任务。因此,Spark可以灵活改变参与计算的Worker节点数来调整计算能力的大小以适应不同计算任务的需要。Spark比其它分布式计算框架(如MapReduce)计算效率高,原因在于:Spark基于内存计算,它抽象出分布式内存存储结构弹性分布式数据集 (resilient distributed datasets,RDD)。RDD支持把外部数据源细粒度地映射到内存中,成为一个初始的RDD;在每个RDD上有如map、reduceByKey、join等功能多样的算子来实现不同的任务需要。Spark按照有向无环图的方式将一个任务分解成前后依赖的多个阶段,在每个阶段里面的RDD上实现不同的算子并把这些阶段串行或并行地执行直到任务完成才把结果输出到硬盘,在计算的过程中没有与硬盘发生交互,如图1所示。
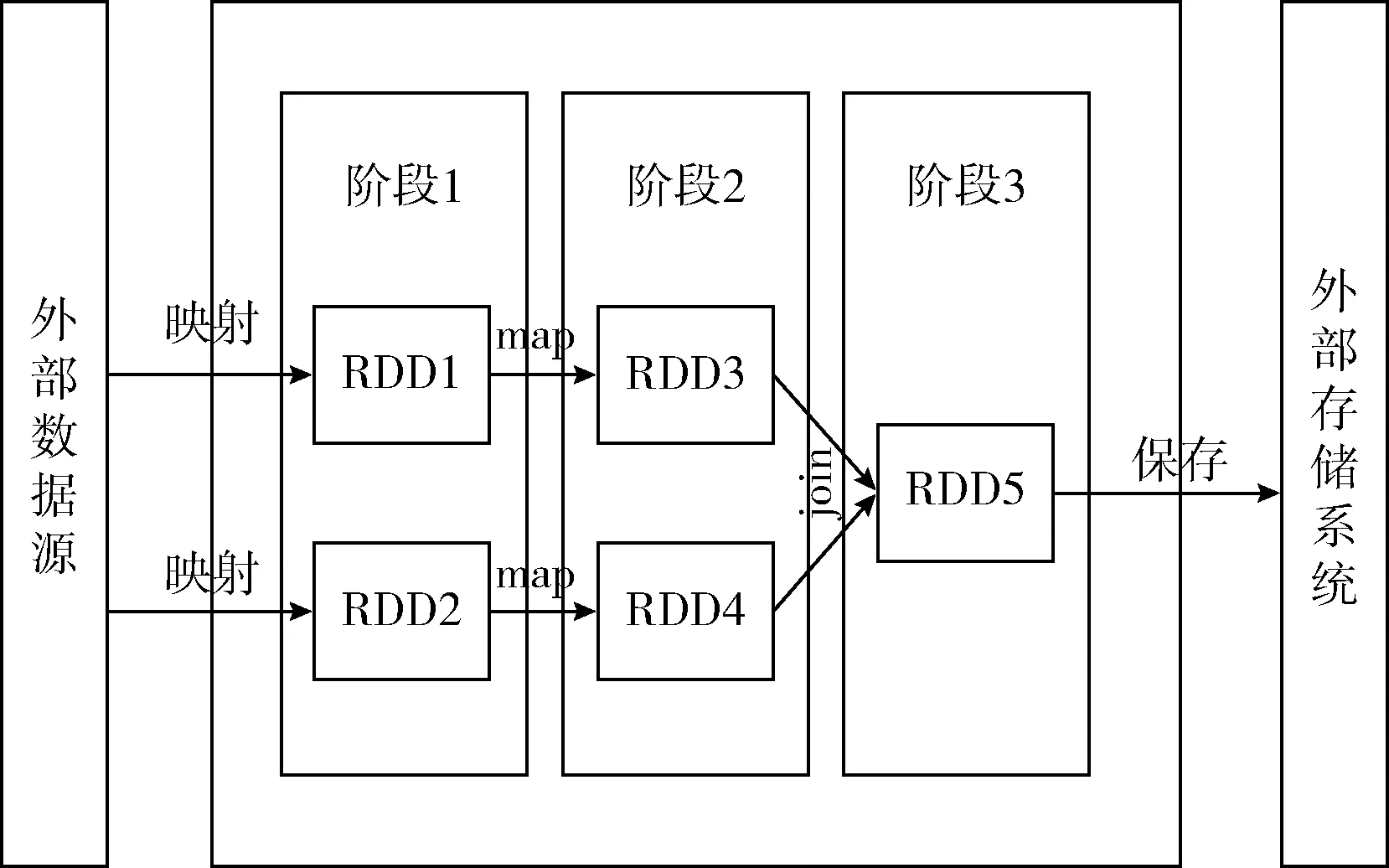
图1 Spark执行过程
2.2 基于Spark的并行DAGSVM网络流量分类模型
要得到多分类SVM分类模型,就是要把二分类SVM算法作用于训练子集,得到对应的二分类子分类器,然后通过组合子分类器得到多分类模型。OAA、OAO、DAG是把二分类子分类器组合成多分类器的方法。OAA、OAO因为存在无法识别的区域而很少使用。DAG方法通过把各个子分类器组合成为一个有向无环图,解决了这一问题。有向无环图是一个有方向的、不循环的图,如图2所示。当未知实例经过该图时,从根节点开始,只需要几次判断到达叶子节点即可完成判别。
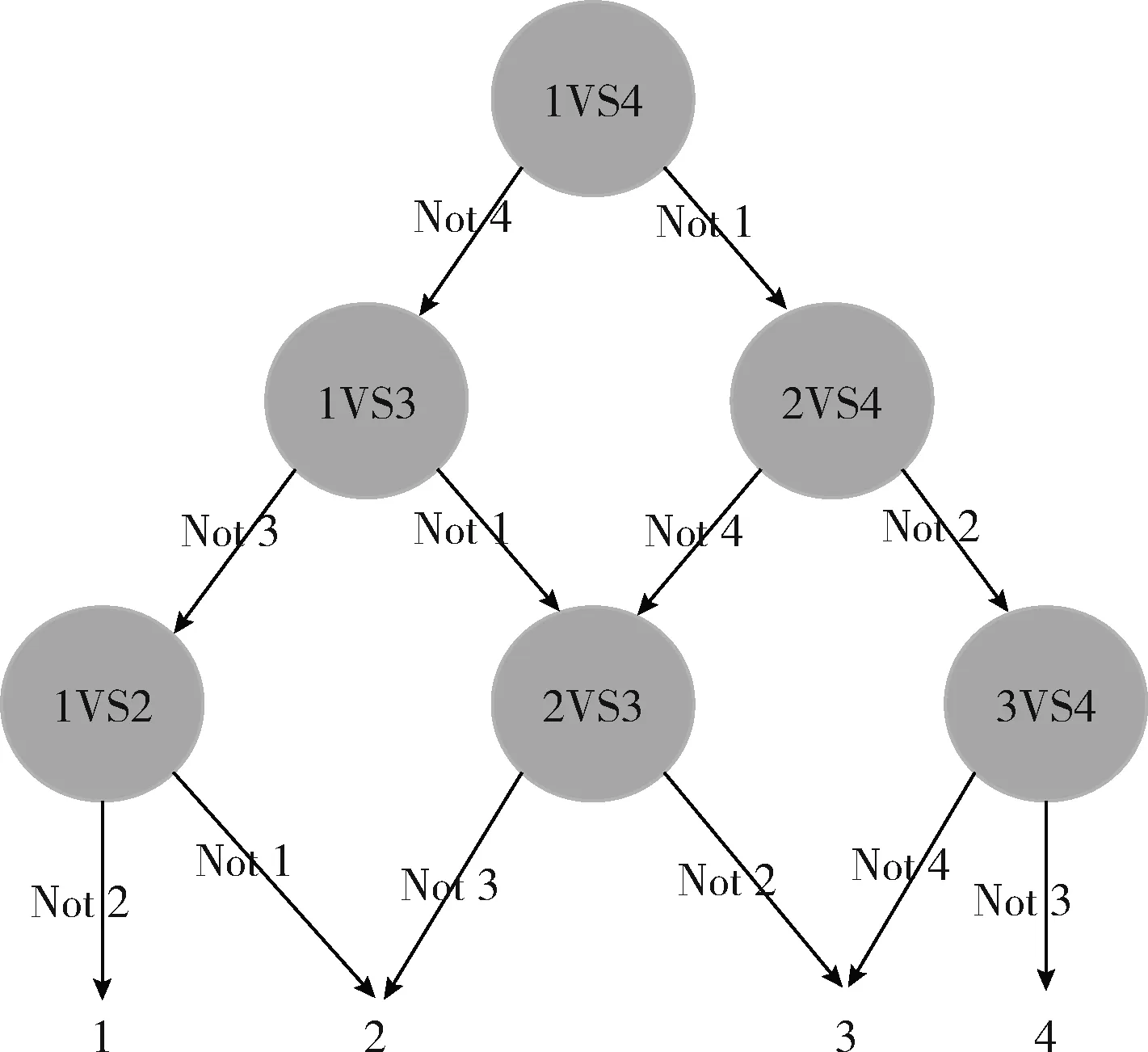
图2 DAG多分类方法
本文利用Spark的机器学习库(machine learning lib-rary,MLlib)包含的并行Binary Linear SVM算法训练得到对应的并行二分类子分类器,结合上述DAG方法得到并行DAGSVM网络流量分类模型,如图3所示。首先,把包含K个类别的训练集切分成K个只包含一类的训练子集并对之进行数据预处理;然后两两组合训练子集得到K(K-1)/2个训练子集并在这些数据子集上使用并行Binary Li-near SVM算法得到对应的并行子分类器;最后利用DAG方法组合子分类器对未知流量样本进行判断,即组合成多分类网络流量分类模型进行分类。
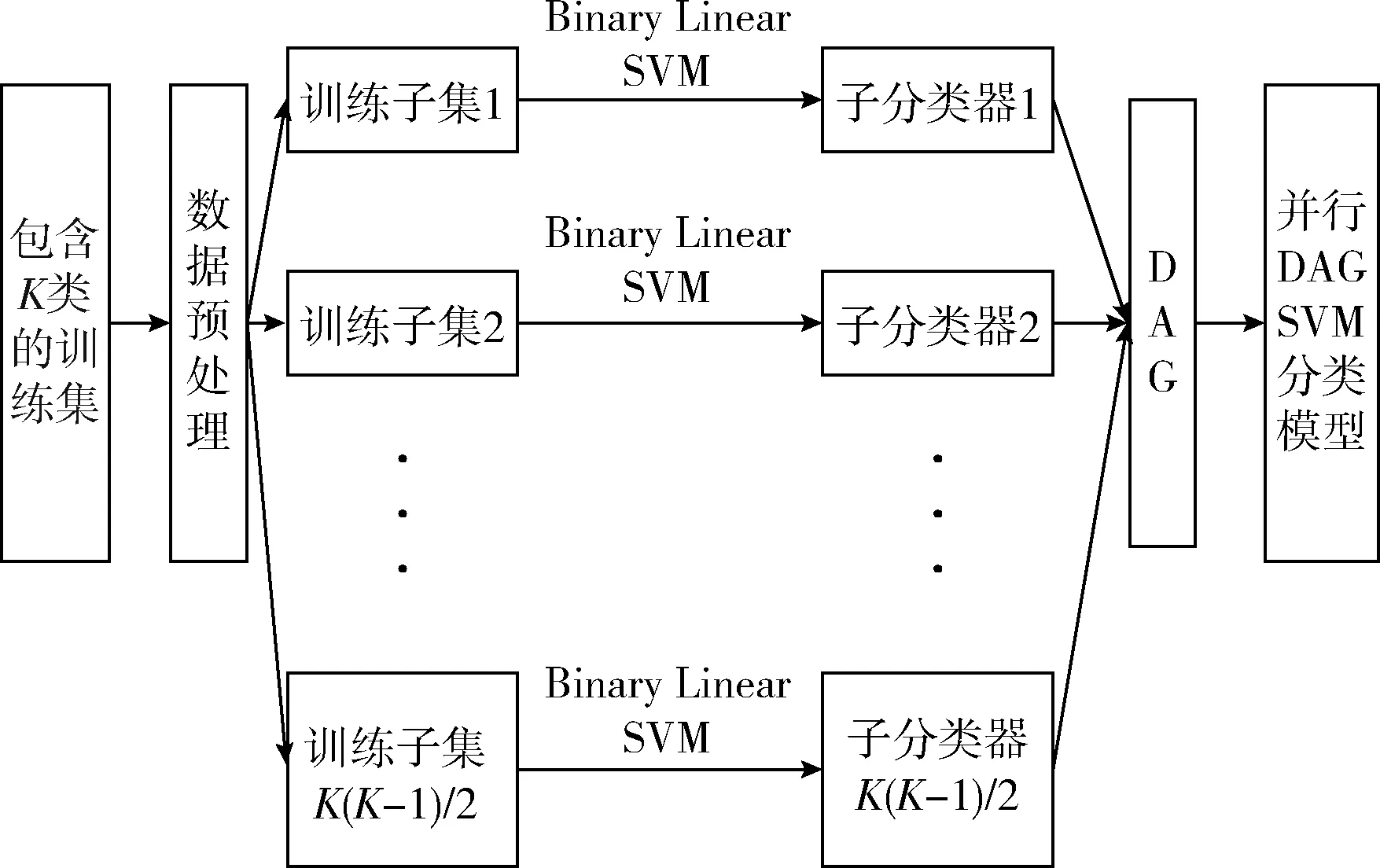
图3 并行DAGSVM网络流量分类模型
2.3 实现步骤
结合上述网络流量分类模型,利用Spark计算框架,得到基于Spark的并行DAGSVM网络流量分类方法,步骤如下:
步骤1 把训练集上传到Hadoop分布式文件系统(Hadoop distributed file system,HDFS),进行数据预处理并将训练集按类别K分成K个子集;
步骤2 把K个子集映射为RDD,每一个子集对应一个RDD,两两组合成K(K-1)/2个训练子集RDD;
步骤3 用每一个RDD训练得到一个并行Binary Linear SVM子分类器;
步骤4 用DAG方法组合每一个子分类器得到并行DAGSVM多分类器;
步骤5 对并行DAGSVM分类器,使用测试集进行测试得到分类结果。
3 实验与分析
3.1 实验环境与数据集
本文实验所使用的网络流量分类工具是单机环境下LibSVM[12]和在云平台上搭建的CDH(cloudera’s distribution including apache Hadoop)中集成的Spark集群。在LibSVM中用径向基核函数;在Spark集群中采用Standalone模式,有一台Master节点、5台Worker节点,其参数见表1、表2。在实验时仅使用其中的8个核、10个G的内存。
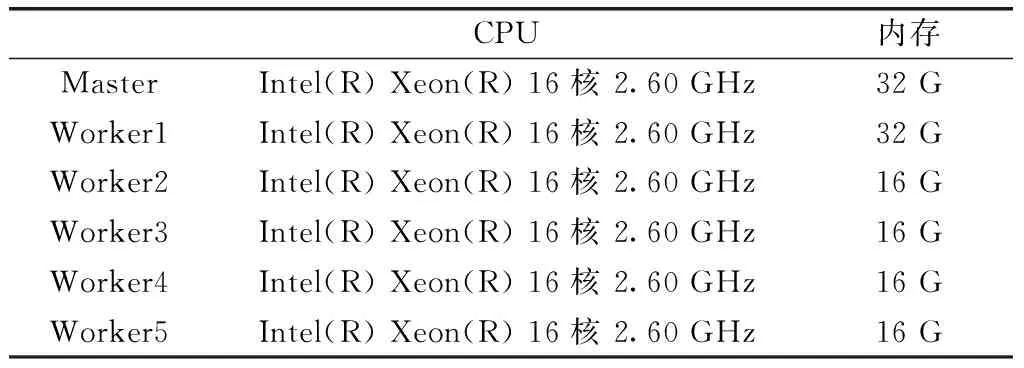
表1 Spark集群硬件配置
为了验证提出的并行DAGSVM网络流量分类方法,

表2 Spark集群软件配置
本文使用了由真实网络流量组成的Moore数据集。它包含10个取自某机构一天中不同时段的流量数据子集,是目前最权威的网络流量数据集。取其中占绝大部分比例,既能体现DAG方法实现多分类SVM的过程,又能代表Moore数据集类别数量分布的WWW、MAIL、FTP-DATA、SERVICES这4种类型组成实验数据集MooreTest_Set,共包含364 555个流量样本,其流量样本统计信息见表3。每个样本由248个流统计特征和一个类别标签组成。为了使数据集符合Spark的格式要求,数据集中的缺失值用其所在特征维度的平均值代替,数据集中的标称类型{Y,N}用数值1代替Y、0代替N。

表3 MooreTest_Set数据集样本统计信息
3.2 实验及结果分析
基于Spark的并行DAGSVM网络流量分类方法与单机SVM网络流量分类方法的比较是从时间和精度两个方面进行的。为了进行时间方面的比较,将上述数据集按类别分类且不放回随机抽取每个类别数据子集的50%合并为测试集,剩余的数据子集又按类别不放回地随机抽样每个类别的20%、40%、60%、80%、100%合并为数量不同的训练集,通过改变训练样本的数目来比较两种方法在训练时间上的性能,结果见表4。

表4 单机SVM与并行DAGSVM方法训练时间
由表4可知,在训练样本数量较小时,并行DAGSVM分类方法的训练时间就已经远小于单机SVM分类方法的,随着样本数量的增加,并行DAGSVM方法消耗的时间几乎保持不变,而单机SVM方法的急剧增加,两者之间的差异越来越大。这是因为在训练样本数量相同时,计算量相同,并行DAGSVM分类方法的计算是在内存中进行并且多个计算节点同时参与,运算速度快、计算能力强,花费的时间就少;而单机SVM分类方法计算时不断与硬盘交互而受到硬盘IO速度的影响并且单机计算能力有限,花费时间就多;当训练样本增加,计算量急剧增大,并行DAGSVM方法的计算能力足够而花费的时间几乎不变,单机SVM方法因为其单机计算能力的限制,时间就急剧增大。
为了更直观地展示并行DAGSVM分类方法比单机SVM分类方法在训练时间上的优势,本文使用加速比指标R,即单机分类方法的分类模型训练时间(TsingleSVM)与并行分类方法的分类模型训练时间(TparallelDAGSVM)的比值,即R=TsingleSVM/TparallelDAGSVM结果如图4所示。
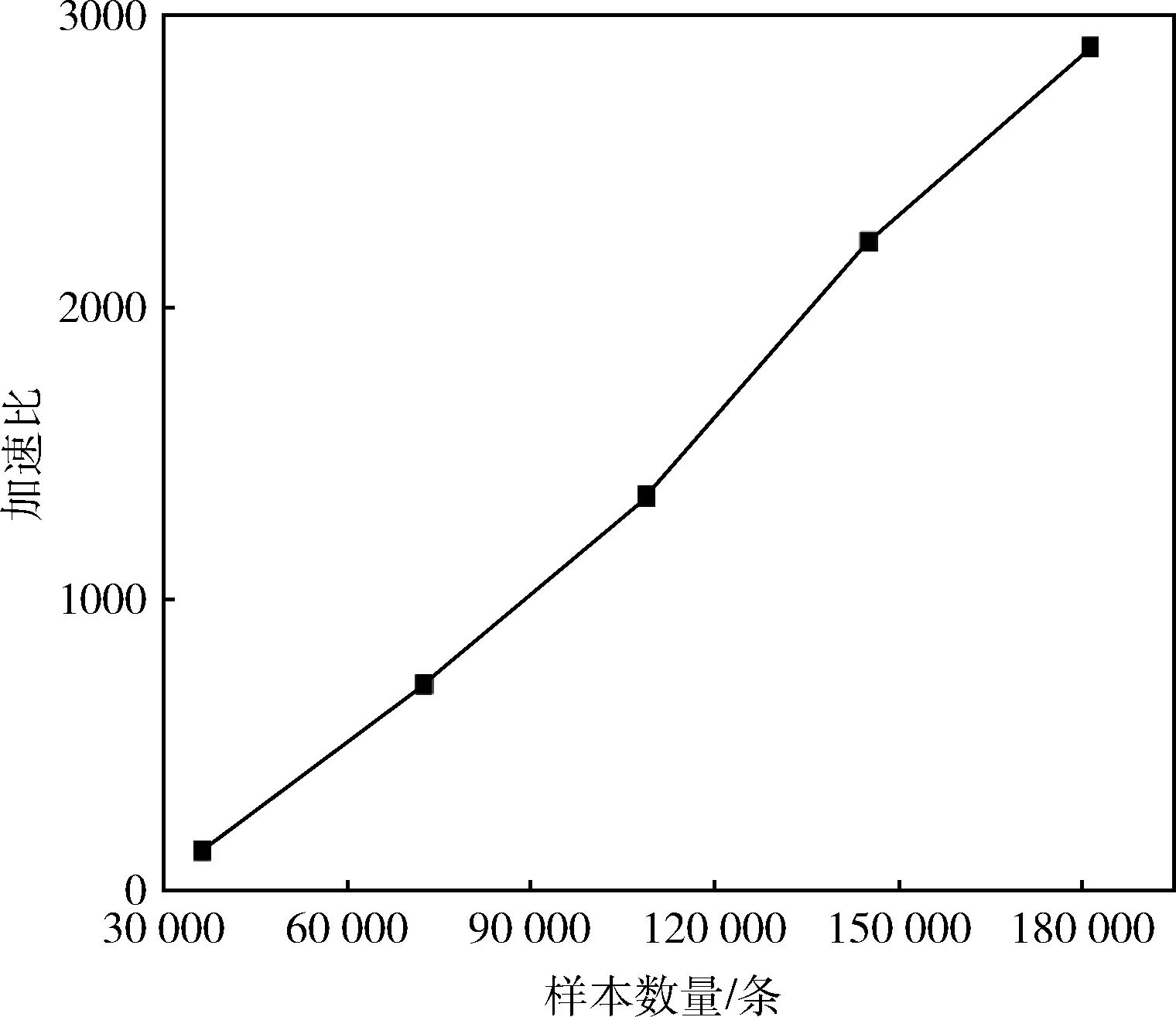
图4 加速比曲线
从图4中可以发现,随着训练样本数量线性地增加,加速比近乎线性地增大,并行DAGSVM分类方法在训练时间上的优势越明显。
为了进行精度方面的比较,本文使用整体准确率(ove-rallaccuracy)度量并行DAGSVM分类方法与单机SVM分类方法的分类精度,其定义为
其中,TP(true positive),FP(false positive)的关系见表5。
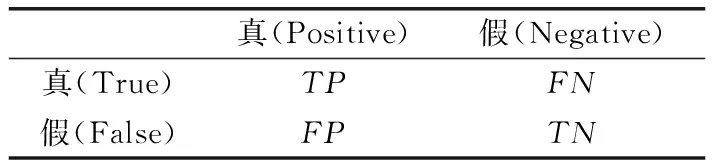
表5 TP与FP的关系
实验把MooreTest_Set数据集按照前文所述的抽样方法得到训练样本数量不等的训练子集,用两种方法分别训练得到分类器并对之命名为1、2、3、4、5,用测试集测试它们得到准确率如图5所示。
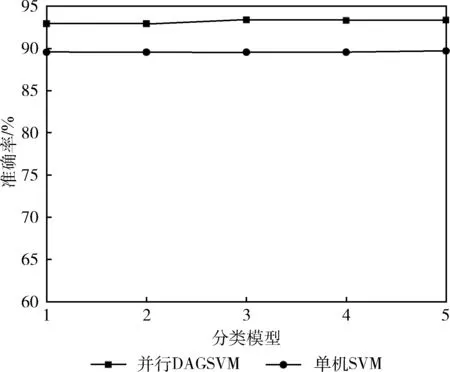
图5 两种方法整体准确率对比
从图5中可以发现,在相同的训练集上得到的两种分类器就已经获得较高的分类精度,并行DAGSVM分类方法比单机SVM分类方法的准确率高一些,这是因为并行分类方法在实现的过程中对代价函数使用了L2正则化来避免过拟合训练集的原因。
由上述实验结果可知,并行DAGSVM网络流量分类方法在确保分类精度的同时,有效减少了训练时间,适合于大规模网络流量分类。
4 结束语
本文利用分布式计算框架Spark中包含的并行二分类SVM算法结合DAG方法实现了并行DAGSVM多分类方法并把它用在网络流量分类上,通过实验验证了它的性能。在确保较高分类精度的情况下,可以加快训练速度,能够解决大规模网络流量分类效率低的问题。并行二分类SVM算法是一个线性的算法,没有使用核函数来把线性不可分问题线性化,把它用在实际的网络流量数据集得到的准确率并不是尽如人意,下一步我们要做的工作是利用Spark中包含的并行算法来设计一种有更高分类精度的网络流量分类方法。
[1]Jun Zhang,Chao Chen,Yang Xiang,et al.Semi-supervised and compound classification of network traffic[C]//32nd International Conference on Distributed Computing Systems Workshops,2012:617-621.
[2]Suzuki Masaki,Watari Masafumi,Ano Shigehiro,et al.Traffic classification on mobile core network considering regula-rity of background traffic[C]//International Workshop Technical Committee on Communications Quality and Reliability.Charleston:IEEE,2015:1-6.
[3]Noora Al Khater,Richard E Overill.Network traffic classification techniques and challenges[C]//10th International Conference on Digital Information Management,2015:43-48.
[4]ChaoWang,TonggeXu,XiQin.Networktrafficclassificationwithimprovedrandomforest[C]//11thInternationalConfe-renceonComputationalIntelligenceandSecurity,2015:78-81.
[5]TaoQin,LeiWang,ZhaoliLiu,etal.RobustapplicationidentificationmethodsforP2PandVoIPtrafficclassificationinbackbonenetworks[J].Knowledge-BasedSystems,2015,82:152-162.
[6]PANWubin,CHENGGuang,GUOXiaojun,etal.Anadaptiveclassificationapproachbasedoninformationentropyfornetworktrafficinpresenceofconceptdrift[J/OL].[2016-05-10/2016-12-10].http://www.cnki.net/kcms/detail/11.1826.TP. 20160510.1455.002.html(inChinese).[潘吴斌,程光,郭晓军,等.基于信息熵的自适应网络流概念漂移分类方法[J/OL].[2016-05-10/2016-12-10].http://www.cnki.net/kcms/detail/11.1826.TP.20160510.1455.002.html.]
[7]QIUJing,XIAJingbo,BAIJun.NetworktrafficclassificationusingSVMdecisiontree[J].ElectronicsOptics&Control,2012,19(6):13-16(inChinese).[邱婧,夏靖波,柏骏.基于SVM决策树的网络流量分类[J].电光与控制,2012,19(6):13-16.]
[8]LINHaitao,CHENYuan.Networktrafficclassificationbyite-rativetuningsupportvectormachine[J].JournalofNavalUniversityofEngineering,2016,28(5):10-14(inChinese).[林海涛,陈源.迭代优化SVM网络流量分类技术研究[J].海军工程大学学报,2016,28(5):10-14.]
[9]PEIYang,WANGYong,TAOXiaoling,etal.ParallelnetworktrafficclassificationmethodbasedonSVM[J].Compu-terEngineeringandDesign,2013,34(8):2646-2650(inChinese).[裴杨,王勇,陶晓玲,等.基于SVM的并行网络流量分类方法[J].计算机工程与设计,2013,34(8):2646-2650.]
[10]DoLeQuoc,ValerioD′Alessandro,ByungchulPark,etal.Scalablenetworktrafficclassificationusingdistributedsupportvectormachines[C]//8thInternationalConferenceonCloudComputing.NewYork:IEEE,2015:1008-1012.
[11]ApachesparkTM-lightning-fastclustercomputing[EB/OL].[2016-11-10/2016-12-10].http://spark.apache.org.
[12]Chih-ChungChang,Chih-JenLin.LIBSVM:Alibraryforsupportvectormachines[J].ACMTransactionsonIntelligentSystemsandTechnology,2011,2(3):389-396.
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
舰船科学技术(2022年10期)2022-06-17
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
新疆钢铁(2021年1期)2021-10-14
南京大学学报(数学半年刊)(2020年1期)2020-03-19
航天工业管理(2019年11期)2019-04-20
吉林大学学报(理学版)(2018年4期)2018-07-19
北京航空航天大学学报(2017年7期)2017-11-24
能源(2017年9期)2017-10-18
都市丽人(2015年4期)2015-03-20
