
基于后验知识监督的噪声鲁棒声学模型研究*
2018-03-12 08:53:02徐海青吴立刚余江斌
湘潭大学自然科学学报 2018年6期
赵 峰, 徐海青, 吴立刚, 余江斌, 黄 影
(1.安徽继远软件有限公司,安徽 合肥 230000;2.中国电力科学研究院,北京 100000;3.国网安徽省电力有限公司,信息通信分公司,安徽 合肥 230000)
随着语音识别、深度学习等技术的发展和市场需求的不断深化,语音交互产品的研发与应用成为热点.由于场景的复杂性,语音交互系统常处在低信噪比环境,且由于人机交互系统的抗干扰能力不足,交互过程中常会出现语音识别率低或人机交互混乱等情况,导致服务对象的交互体验感不佳,因此如何提高语音交互系统的噪声鲁棒性是现阶段急需解决的问题.
如今,学者对声学模型噪声鲁棒性开展了广泛研究并提出了多种改进策略.其中特征与模型补偿是通过自适应算法对声学模型进行优化处理的噪声鲁棒性方法.例如Leggetter[1]等利用最大似然回归算法进行模型自适应.鲁棒性特征提取是指从语料中提炼出对于噪声不敏感的特征参数,构建抗噪能力强的特征序列,从而提高噪声鲁棒性.倒谱均值归一化法和均值方差归一化方法[2-3]是最常见的两种鲁棒性特征提取方法,另外刘长征等[4]以MFCC特征作为CNN网络的输入,采取监督学习的方式提取出高层的语音特征.语音增强常用的方式是通过噪声更新与噪声消除相结合的谱减法对语音和噪声独立处理,从带噪语音谱中减去预估的噪声谱得到语料的干净谱;Xu等[5]提出了谱减法与DNN网络相结合的方式,将谱减法处理后的特征与噪声估计参数作为基础样本输入DNN网络中,通过噪声依赖训练得到深度声学模型.
上述四种方法虽然可以有效提升声学模型鲁棒性,但是存在两个问题:一是上述方法并未充分挖掘干净语音的隐含知识;二是上述方法中声学特征提取模块与后续的训练识别过程是相互独立的,提取出的语音特征中包含冗余信息,而冗余信息通常不具备噪声鲁棒性.
针对上述问题,本文提出了一种基于后验知识监督的噪声鲁棒声学建模方法,以干净语音训练的模型作为老师模型,带噪语音训练的模型作为学生模型,提炼老师模型的后验概率分布知识用于监督学生模型的训练,达到提高声学模型环境鲁棒性的要求;在学生模型的设计上,提出了一种CNN与DNN相结合的声学模型训练网络结构,其中CNN模块用于提取带噪语音的不变性特征,DNN用于声学建模,整个网络参数的训练通过CNN与DNN模块联动调整与优化.本文构建的模型在CHIME数据集上进行了不同信噪比下的语音识别性能验证与对比,测试结果表明该模型具有较强的环境鲁棒性,表现出优越的抗噪性能.
1 基于后验知识监督的声学建模
1.1 后验知识监督
本文提出的后验知识监督是指通过老师模型的训练挖掘出干净语音的后验概率分布知识,并以此作为标准来监督学生模型的训练,从而通过学生模型逼近老师模型的后验概率分布,达到提升声学模型噪声鲁棒性的效果.对于两种模型的后验概率分布差异性,本文使用KL散度(相对熵)[6]进行量化.本文假设Pt为老师模型的后验概率分布,QS为学生模型的后验概率分布,QS相当于对Pt后验概率分布的近似估计,因此二者的相对熵可表示为:
(1)
式中:i表示三音素状态集合中的次序;phi为三音素状态集合中的第i个状态;xt表示用于训练老师模型的干净语音特征;xs表示用于训练学生模型的带噪语音特征;Pt(phi|xt)表示特征xt被识别为第i个三音素状态的后验概率;Qs(phi|xs)表示特征xs被识别为第i个三音素状态的后验概率.该式通过变形可简化成以下形式:
(2)
(3)
一般来说,经验概率分布通常是以0-1向量硬标注来进行描述,而老师模型与学生模型的相对熵是对两种模型的后验概率分布进行差异性比较,相当于将“硬标注”替换成了“软标注”.
1.2 老师模型训练

本文中老师模型是以GMM-HMM与神经网络的混合模型为基础,基本训练步骤如图1所示.
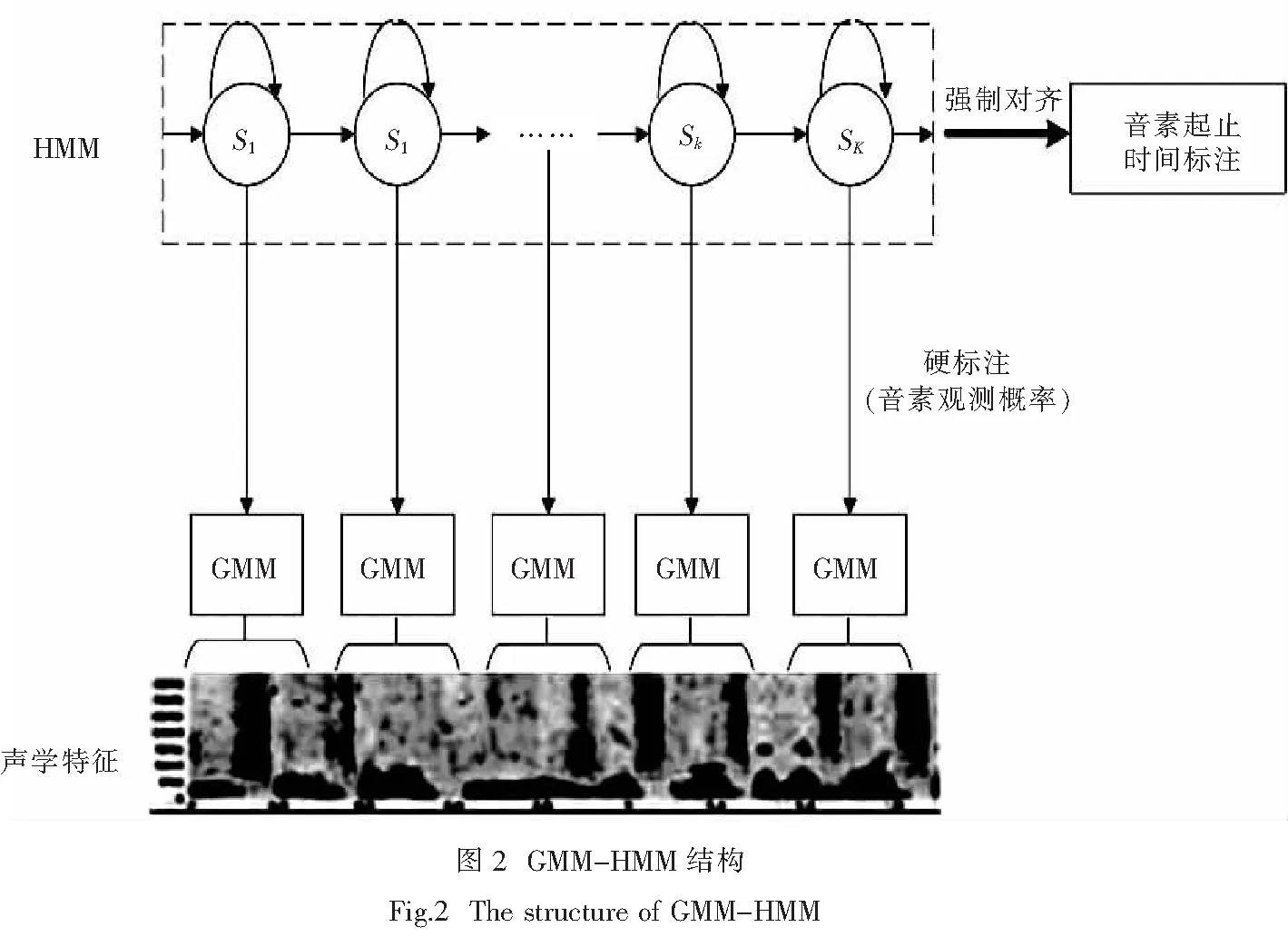
首先对干净语音进行特征xt提取,GMM-HMM模块对分窗后的特征xt进行逐帧强制对齐,并得到每一帧语音数据的硬标注,从而得到每一帧数据的三音素状态观测概率分布;在强制对齐的基础上对每一个硬标注进行时间维度上的起止点标注,该标注信息与硬标注数据作为监督信息送入神经网络模块进行声学模型的建模训练.GMM-HMM模块的结构如图2所示.
神经网络模块的训练以特征xt作为输入,音素硬标注与标注数据作为监督信息,利用前向算法得出逐帧数据的三音素后验概率分布.软标注是指每一帧数据的三音素状态后验概率分布,而非简单的0-1判断,由此得到的每一帧数据的软标注的形式类似于[0.2 0.15 0.3 0.1 0.1 0.1],其中的每个数据表示该帧数据属于不同三音素状态的后验概率.
1.3 学生模型训练
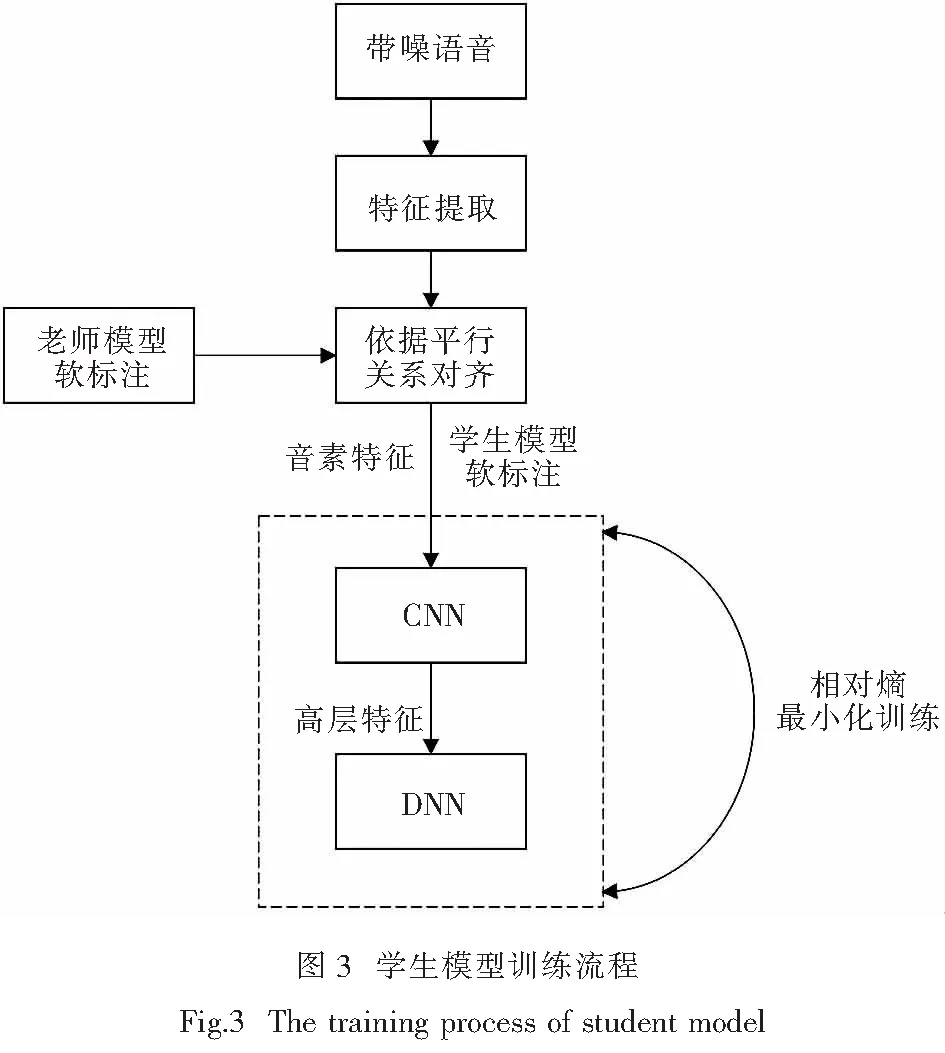
基于学生模型本文提出一种CNN与DNN网络相结合的方法,模型基本训练流程如图3所示.
学生模型的训练先对带噪语音进行初步特征xs提取,提取出的音素特征xs与老师模型的软标注平行对齐,得到学生模型的软标注;在初步特征提取的基础上,借助CNN网络局部连接与降采样模块的功能特性,在MFCC和FBANK等初步提取的声学特征基础上提取高层特征,并对特征降维,从而提炼出对噪声语音不变性进行表征的特征序列;此外,考虑到DNN网络具有强大的分类能力,在声学模型的性能上已经超越了GMM等传统模型,最后将高层特征输入DNN层进行声学建模,整个模型网络的训练过程以相对熵最小化(式(3))作为优化准则.
2 验证实验与结果分析
2.1 实验基础
本文使用TIMIT数据集,TIMIT数据集包含630个说话人语音,每人10句,其中干净数据集取500个说话人,共5 000句作为老师模型的训练样本,剩余130个说话人,共1 300句作为老师模型的测试样本;带噪语音基于TMIT数据集随机叠加5种信噪比的背景噪声,5种信噪比分别为0 dB,5 dB,10 dB,15 dB和20 dB,取500个说话人,共5 000句作为学生模型的训练样本,剩余130个说话人,共1 300句作为学生模型的测试样本.
为了检验构建的声学模型在噪声鲁棒性上的优劣,本文使用CHIME数据集进行模型性能的验证与交叉比较,采样频率为16 kHz.本文使用Kaldi进行模型的训练、测试与性能比较.共采用两种特征:梅尔频率倒谱系数(MFCC)和梅尔标度滤波器组特征(FBANK).老师模型GMM-HMM模块输入为MFCC,神经网络模型输入为 FBANK,CNN-DNN混合学生模型输入为FBANK.提取特征窗长为25 ms,帧移为10 ms. MFCC特征13维,加上一阶和二阶差分统计量,共39维. FBANK特征为40维,加上一阶和二阶差分统计量,共120维.
本文中老师模型的训练遵循最小化交叉熵准则,损失函数为交叉熵,优化方法为随机梯度下降,神经网络声学模型采用误差反向传播算法进行训练.学生模型的训练遵循式(3)的最小化准则,即损失函数为后验概率分布相对熵,优化方法为随机梯度下降,CNN-DNN混合声学模型同样采用误差反向传播算法进行参数调整与优化.
2.2 实验设计及验证结果
本文将验证环节分为三个步骤进行设计,首先独立对学生模型的CNN-DNN网络结构进行性能对比验证,并从中选择基线模型作为后验知识监督下的学生模型对比基线;然后通过选择不同的神经网络结构(CNN、DNN、LSTM)对老师模型进行训练,从而为本文提出的后验知识监督方法提供对比验证基础;最后对基于后验知识监督的学生模型进行交叉对比与测试.
2.2.1CNN-DNN网络性能对比验证为了验证CNN-DNN学生模型结构优越性,本文使用两种方法分别对GMM-HMM模型进行训练,得到声学模型的输入硬标注:一是仅用干净语音训练GMM-HMM,表示为C-GMM;二是用带噪语音训练GMM-HMM,表示为N-GMM.C-GMM与N-GMM的三音素状态数目分别为2 234和2 190.
基于上述两种GMM-HMM模型的训练方式,为了验证CNN模块对声学模型性能的提升效果,构建两种声学模型进行对比分析:一是使用DNN网络作为声学建模的基础结构,分别通过C-GMM与N-GMM模型得到带噪语音的硬标注,其中C-GMM是首先得到干净语音的硬标注,然后得到带噪语音的硬标注,最后以FBANK声学特征作为训练样本,带噪语音硬标注作为监督信息输入DNN网络进行声学模型的训练;二是使用CNN-DNN网络作为声学模型,同样通过C-GMM与N-GMM模型得到带噪语音的硬标注,然后结合FBANK特征作为模型输入训练CNN-DNN声学模型.本文使用的DNN有6个隐含层,CNN-DNN网络中CNN模块采用3个卷积层和7个全连接层,DNN模块6个隐含层.上述两种模型在带噪语音五种信噪比下的词错误率如表1所示.
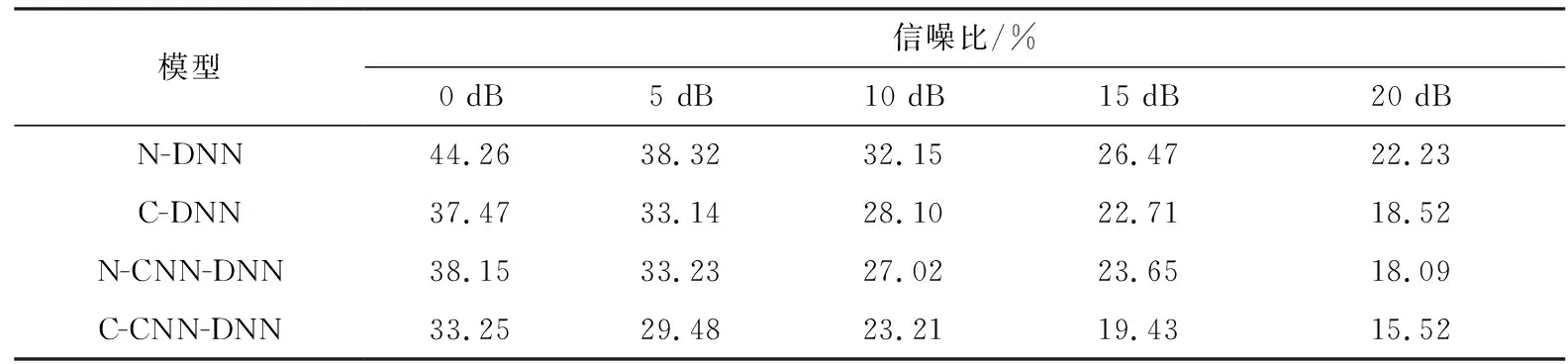
表1 带噪语音下CNN-DNN与DNN模型性能对比
如表1所示,本文设计的CNN-DNN声学模型在不同信噪比下及不同GMM-HMM训练方法下语音识别词错误率明显低于DNN模型,其中N-DNN与N-CNN-DNN相比,词错误率平均下降了5.42%,C-DNN与C-CNN-DNN相比,词错误率平均下降了4.15%,从而说明CNN-DNN网络结构相比DNN对声学模型的性能有所提升.为了在学生模型训练阶段与后验知识监督方法进行对比,选择表1中词错误率最低的C-CNN-DNN模型作为学生模型的性能验证基线(Baseline).
2.2.2老师模型训练与测试为了验证后验知识监督方法对学生模型鲁棒性性能具有提升作用,本文的实验设计策略是首先对老师模型使用不同的神经网络模块进行训练,然后通过后验知识监督训练出相应的学生模型,从而对老师模型和对应的学生模型性能差异进行相关性分析.
针对老师模型的训练,本文分别选择CNN、DNN和LSTM作为神经网络模块进行老师声学模型的构建,其中CNN包含2个卷积层,5个全连接层,DNN包含6个隐含层,LSTM包含5个隐含层.三种模型训练、测试与验证阶段的词错误率如表 2 所示.

表2 干净语音下不同老师模型词错误率对比
如表2所示,三种模型中LSTM的词错误率最低,DNN次之,而CNN的词错误率相对高一些.但总的来说,三种模型的词错误率整体差别不大.
2.2.3学生模型对比验证本文采用CNN-DNN的声学模型作为学生模型.其中CNN包括3个卷积层和7个全连接层,DNN包含6个隐含层,每隐含层2 048个节点,输出层2 190个节点,与老师模型的输出相同.在三种老师模型的指导下,相应学生模型在验证集上五种信噪比下词错误率如表3所示.
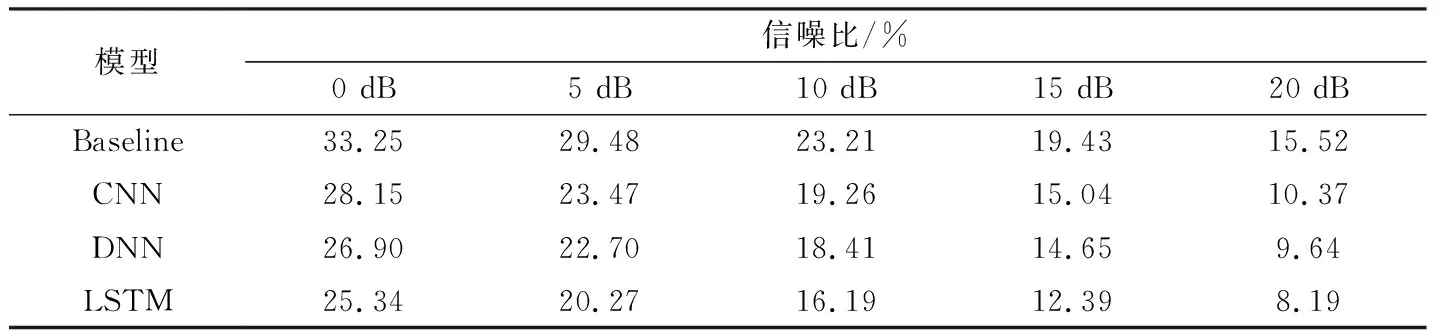
表3 带噪语音下不同学生模型词错误率对比
如表3所示,与基线(Baseline)相比,三种老师模型监督下的学生模型词错误率均有明显下降,分别平均下降了5.21%, 6.35%和7.83%,与三种老师模型的错误率差异呈现正相关,表明本文提出的后验知识监督方法对声学模型的鲁棒性具有很好的提升效果.
3 结论
本文提出一种基于后验知识监督的噪声鲁棒声学建模方法,是老师指导学生的方式,以老师模型的后验概率分布(软标注)作为监督信息对学生模型的训练进行指导,并设计出一种基于CNN-DNN混合的学生模型,通过对带噪语音的高层特征进行提炼,提升声学模型的抗噪性能.本文构建的学生模型在CHIME数据集下进行性能验证,结果显示三种老师模型监督下的学生模型词错误率与基线模型相比平均下降了5.21%, 6.35%和7.83%,表明本文提出的后验知识监督方法对声学模型的鲁棒性具有很好的提升效果.在上述研究的基础上,后续将对声学模型的端到端训练方法进行研究,拟通过知识迁移的方式对声学模型从语音数据预处理到音素分类输出的全过程进行监督训练,对声学建模的全阶段进行噪声鲁棒性提升和优化.
猜你喜欢
中国卫生统计(2023年5期)2023-11-30 01:40:14
工程数学学报(2020年3期)2020-07-06 07:38:40
农业机械学报(2020年2期)2020-03-09 07:35:30
中华建设(2019年7期)2019-08-27 00:50:18
长治学院学报(2019年2期)2019-07-24 07:14:04
教师·中(2017年3期)2017-04-20 21:49:49
雷达学报(2017年6期)2017-03-26 07:53:04
试题与研究·教学论坛(2016年27期)2016-08-11 14:57:08
项目管理技术(2016年12期)2016-06-15 20:29:33
西南交通大学学报(2016年6期)2016-05-04 04:13:11
