
基于决策树分类算法异构数据的索引优化
2018-03-08 10:08:33郑博文赵逢禹
电子科技 2018年3期
郑博文,赵逢禹
(上海理工大学 光电信息与计算机工程学院,上海 200093)
异构数据索引是在异构数据空间中建立索引,进而提供高效、便捷和多样化的数据查询。随着互联网和云计算技术的飞速发展、涉及的数据量急剧增加、信息化水平的不断提升、各种各样的数据流种类和规模也持续增长的情况下,最优异构数据索引是解决在海量数据中快速查询出所需要的数据的一个最直接也是最有效的方法[1-4]。
异构数据索引已有许多研究成果,文献[5]中,Nafaa Jabeur在用CAN路由的方法来增加分布式系统的可扩展性,实现异构数据索引的建立。文献[6]中,Benjamin Shapiro利用R-tree和Bloom-Filter相结合的方法实现异构数据索引的建立并提高点查询和范围查询的效率。文献[7]中,Song Baoyan基于可变网格技术提出了VGHI二级异构索引结构,通过在每个子空间上构建M树管理自身的数据,这种二级异构索引有效地管理了分布式系统和每个子空间的索引。文献[8]中,Traversel通过在改进的MapReduce框架上构建文件索引来提高查询处理的效率,提出了结合Overlay结构和B-tree索引的二级索引结构CG-index,能够有效地支持云环境上的查询处理操作。
尽管异构数据索引的研究取得了许多成果,但还存在一些问题。(1)Song Baoyan提出的VGHI二级异构索引[9]结构和Nafaa Jabeur利用CAN路由的方法建立的索引结构太过庞大,占用过多的物理空间,无法高效地建立最优异构数据索引;(2)Benjamin Shapiro利用R-tree和Bloom-Filter相结合构建异构数据索引的方法和Traversel通过MapReduce框架构建索引的方法虽然能快速地构建索引,但运用R-tree构建的索引是通过对索引进行范围划分,其原理是非叶结点存储其所有子结点的区域范围,这种区域范围使索引结构较为简单,在海量数据中无法根据异构数据索引进行快速的精准查询。
本文主要研究在大数据的背景下快速构建索引且通过决策树分类算法准确地构建索引从而优化异构数据索引结构。最后在大量的公开数据集上进行索引优化实验,根据构建的异构数据索引提高海量数据查询的性能和可扩展性。
1 异构数据索引
异构数据索引由局部索引和全局索引两部分组成,其中,全局索引是通过分布式系统汇总的各个节点信息得到的,它是由一个分布式系统进行维护。局部索引采用R-tree[10]管理数据,整个索引采用“自下而上”的方式构建。在局部节点上建立局部索引,然后将各个局部索引的信息发布到全局索引上,通过全局索引可以得到每个集群的子空间的范围以及它的邻居空间的信息,即给定一个具体的数据信息,通过全局索引可以快速地找到该数据所属的子空间,在查询时可以快速地缩小目标空间的范围。
当用户向全局索引中的任意节点发送查询请求时,全局索引节点通过全局索引表找到与查询相关的局部节点,并将查询请求转发给相关的局部数据节点,局部数据节点通过局部索引完成其本地数据的查询处理,最后将查询结果返回。在异构数据查询中,异构数据索引起到了至关重要的作用,而在异构数据索引中的对局部索引优化成了关键。
2 异构数据索引优化的方法
在传统的数据库索引中,表的第一列通常为表的主属性,所以可以根据每张表的第一列属性构建主属性局部索引。对于数据库表的其他属性列,如果某一列与其他表中的属性列一致,则该列在很大程度上会成为条件筛选属性或关联属性,所以也挑选该属性列构建局部索引,称为非主属性局部索引。本文基于索引属性决策树分类算法来判断各个子节点上的表的属性列是否应该建立局部索引。
2.1 索引属性决策树的建立
索引属性决策树是一个监督学习的分类算法,该方法分为决策树的学习与基于决策树的分类。首先从已含有正确索引的数据库中得到主属性列和非主属性列的两个属性特征,然后统计所有属性列在数据库中的频次,该频次为属性特征值。把属性特征、属性特征值以及属性列是否是索引列汇集在一起,得到如表1所示的索引属性数据训练集。
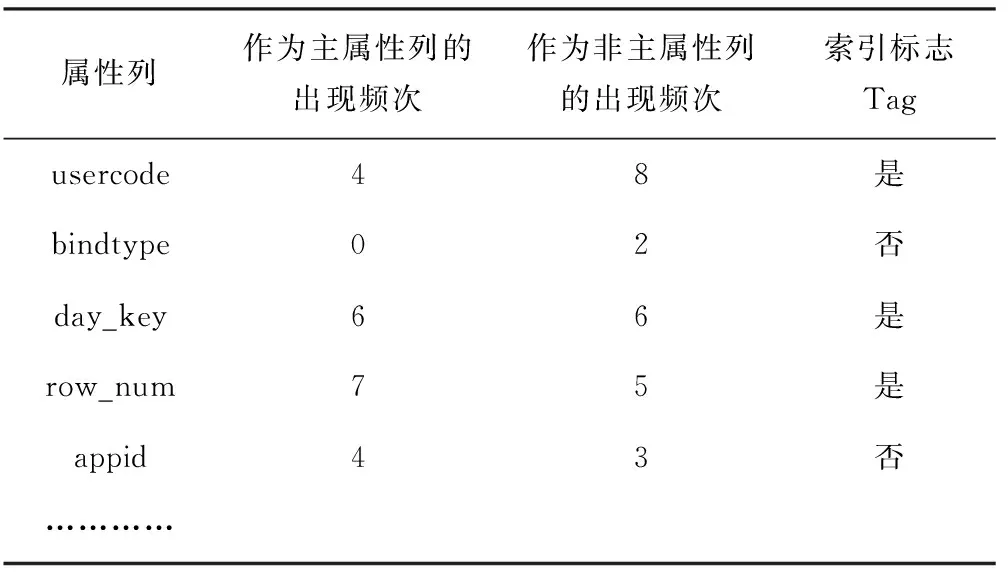
表1 索引属性数据训练集
由表1可知,索引标志取值为“是”与“否”,分别表示该属性列是否被索引,主属性列的出现频次,非主属性列的出现频次,索引标志Tag构成一个元组,所有的元组形成数据集D。基于表1中的数据,使用决策树生成算法,可以构建出索引决策树。该索引决策树给出了属性特征值的取值组合与是否是索引的关系。
2.2 基于索引决策树的索引优化
索引属性决策树建立后,就可以使用该决策树对节点上所有表的索引进行优化。首先将节点上的所有表的主属性列与非主属性列的出现频次进行分析,构建了索引属性初始数据集,如表2所示。

表2 索引属性初始数据集
然后使用生成的索引属性决策树对索引属性初始数据集执行分类,得到各个表中属性列是否应该建立局部索引。该方法有效地判断各个表中属性列是否需要建立索引,避免了索引建立过于冗余的问题,也保证了数据查询的高效性。
局部索引建立完成后,基于MapReduce框架[8]对分布式文件系统构建全局文件索引,该方法避免了基于可变网格技术的全局索引占用物理空间较大的问题,这种全局文件索引满足了海量数据能在系统中的动态线性扩展,其次也满足了分布式计算能力。通过分布式文件系统中的全局文件索引,能快速地查找到各个节点信息,在通过各个节点上的局部索引,就可以快速准确地查找到所需数据。图1所示为异构数据索引的整体架构。
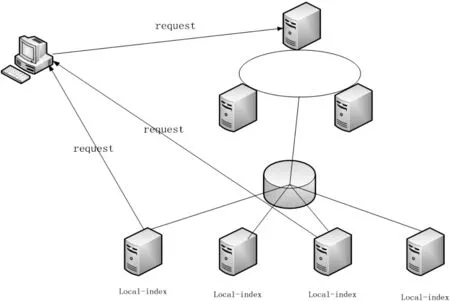
图1 异构数据索引架构图
3 算法
决策树(Decision Tree)[11-13]利用了概率论的原理,并且利用一种树形图作为分析工具。其基本原理是用决策点代表决策问题,用方案分枝代表可供选择的方案,用概率分枝代表方案可能出现的各种结果,经过对局部索引在各种结果条件下损益值的计算比较,为决策者提供决策依据。在局部索引建立方法中,采用决策树算法进行分析和调整索引结构。通过数据库表中属性列的相关信息,运用熵[14]值得到各个属性的信息增益值,然后得到分裂属性,进而通过决策树生成算法构建决策树[14-15]。
3.1 基本定义
本文采用C4.5算法来计算各个属性的信息增益率(gain ratio)。C4.5算法解决了ID3算法不能处理连续值属性的问题,而且克服了ID3算法偏向于多属性值的缺点。这点在大数据索引构建中,有效地解决了多维度、多属性值索引构建问题。
C4.5算法是以信息论为基础,用信息熵和信息增益率作为衡量标准。下面先定义要用到的概念:
定义1 若存在n个相同概率的消息,则每个消息的概率p是1/n,一个消息传递的信息量为log2(n)。
定义2 若有n个消息,其给定概率分布为p=(p1,p2,…,pn),则由该分布传递的信息量成为p的熵,记为
(1)
定义3 若一个记录集合T根据类别属性的值被分成互相独立的类C1,C2,…,Ck,则识别T的一个元素所属哪个类所需要的信息量为Info(T)=I(p),其中p为C1,C2,…,Ck的概率分布,即
p=(|C1|/|T|,…,|Ck|/|T|)
(2)
定义4 若先根据非类别属性X的值将T分成集合T1,T2,…,Tn,则确定T中一个元素类的信息量可通过确定Ti的加权平均数来得到,即Info(Ti)的加权平均值为
(3)
定义5 信息增益是两个信息量之间的差值,其中一个信息量是需确定T的一个元素的信息量,另一个信息量是已得到的属性X的值需确定的T一个元素的信息量,信息增益公式[3]为
Gain(X,T)=Info(T)-Info(X,T)
(4)
再取得分裂信息度量
(5)
所以信息增益率为
(6)
在表1的属性数据训练集中,取表中前5行数据为构成数据集D,候选属性集合A={“作为主属性列的出现频次”,“作为非主属性列的出现频次”},其中D中索引标志“是”有3个,属于索引标志“否”有2个,则通过上述公式(1)分别计算其信息熵
下面对候选属性集中每个属性分别计算信息熵,要注意的是,本文将候选属性值划分为离散的区间集合。这里假设将频次大于等于4的区间值都归为高频次类,将频次小于4的归为低频次类,所以可得其信息熵为:“作为主属性列的出现频次”的熵
同理可得“作为非主属性列的出现频次”的熵
根据得到的熵值,可以用式(4)计算第一个根节点所依赖的信息增益值Gain(A1)=Info(D)-Info(A1)=0.971-0.649=0.322Gain(A2)=Info(D)-Info(A2)=0.971-0.887=0.084
根据式(5)可得各候选属性的分裂信息度量
然后带入式(6)可得信息增益率为
根据计算得到的各候选属性的信息增益率,选取信息增益率最大的“主属性列的出现频次”作为决策树分裂节点。
3.2 索引属性决策树构建算法
决策树是以自顶向下递归的方法构成,从属性数据训练集中通过信息增益计算得到决策树分裂节点来构建决策树。随着树的构建,训练集递归地划分成较小的子集,最终生成索引属性决策树。具体算法描述如下:
算法 决策树生成generate_decision_tree。
输入
(1)数据训练元组集合为D;
(2)attribute_list={“作为主属性列的出现频次”,“作为非主属性列的出现频次”}为候选属性的集合。
输出 一个决策树。
方法
(1)创建树的root节点;
(2)If 索引标志相同(假设D.Tag==“是”) then 返回root,root.value=(”主属性列的出现频次”,”非主属性列的出现频次”),root.child=”是”,转步骤(7),否则转步骤(3);
(3)计算attribute_list 中各属性的信息增益率,选择attribute_list 中具有最高信息增益率的属性作为splitting_criterion,计算该属性的频次期望值,并把该值赋给root.ave;
(4)root.value=splitting_criterion;
(5)设d是D中root.value=splitting_criterion的数据元组的集合。//数据集的一个划分;
ForD中root.value=splitting_criterion的属性频次值依次与root.ave进行比较,然后转步骤(6);
(6)由节点root长出一个条件为d.value与root.ave比较后的分枝(例如d.value > root.ave创建左分枝),然后转步骤(7);
(7)设n是D中按照root.ave分枝后的数据集合。ifn为null then节点root下增加一个叶子节点child,child.value=null,child.tag=vote(n),这里vote(n)是频次多数表决函数,取最普遍的索引标志赋值给child.tag,跳转步骤(9),否则转步骤(10);
(8)增加一个由generate_decision_tree(n,attribute_list-splitting_criterion)返回的节点(子树)//递归调用,并在attribute_list中删除已分裂的属性;
(9)end for;
(10)返回root。
3.3 基于索引属性决策树构建子空间索引
为构建子空间上子空间索引表,首先需要构建如表2所示的子空间索引属性初始数据集。然后根据索引决策树分析,索引属性初始数据集中各属性是否需要建立索引。最后得到需要建立索引的所有属性的集合,然后根据该集合中的属性分别建立索引。
4 实验步骤和结果
4.1 实验数据流
本实验采用Hadoop2.0平台以及hive,sqoop等相关插件,另外数据展示库为Oracle数据库,数据的处理时序图如图2所示。
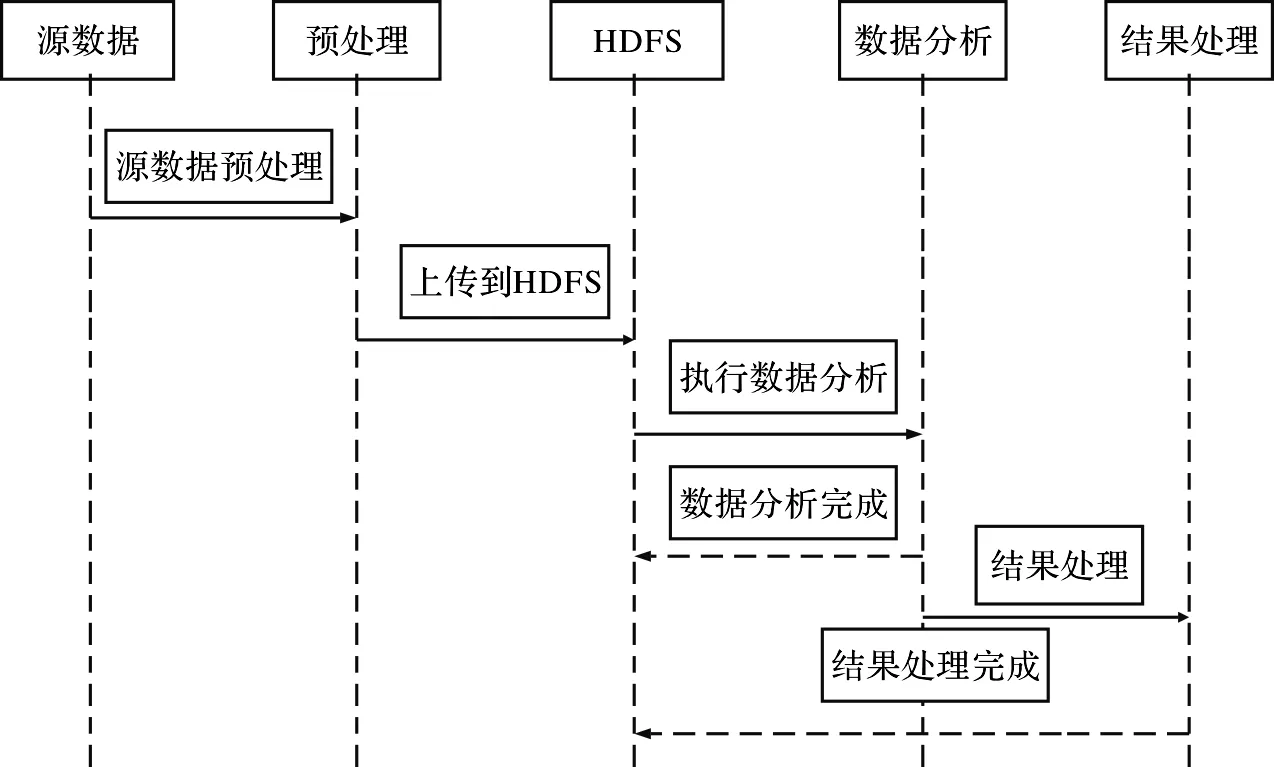
图2 数据流程图
4.2 数据集及处理
实验所采用的数据集来自开源社区某通信行业的真实数据,共有643张表。现先将643张表结构用脚本导入hive中,存入HDFS,然后再编制脚本将各节点的第一属性列和表与表之间的非第一属性列信息和字段关联信息统计入库到临时表中并通过sqoop导出至oracle展示库。属性列详情如图3所示。图中INDEX_NAME为每张表的第一属性列,TABLE_NAME为表名。

图3 属性列详情图
4.3 决策树训练
为构建决策树,需要获取子空间中实际的数据库表以及对应的索引数据。本文收集了200张表,获取这些表的索引信息和属性列相关信息,进行主属性列和非主属性列的频次统计和汇总,得到如图4所示的属性列频次统计表,表中分别存入属性列,作为主属性列的出现频次,作为非主属性列的出现频次,以及已知的索引标志。
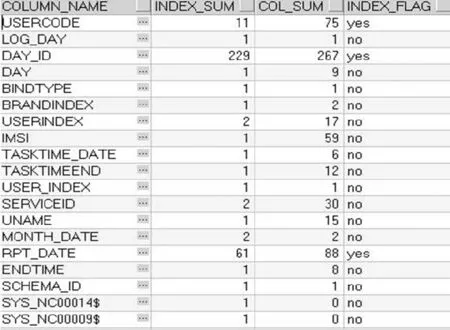
图4 索引属性数据训练集
再运用上述决策树构建算法对已有的属性数据训练集进行分析并建立决策树模型,图5为通过决策树分类对主属性列和非主属性列分别分类,构建决策树。
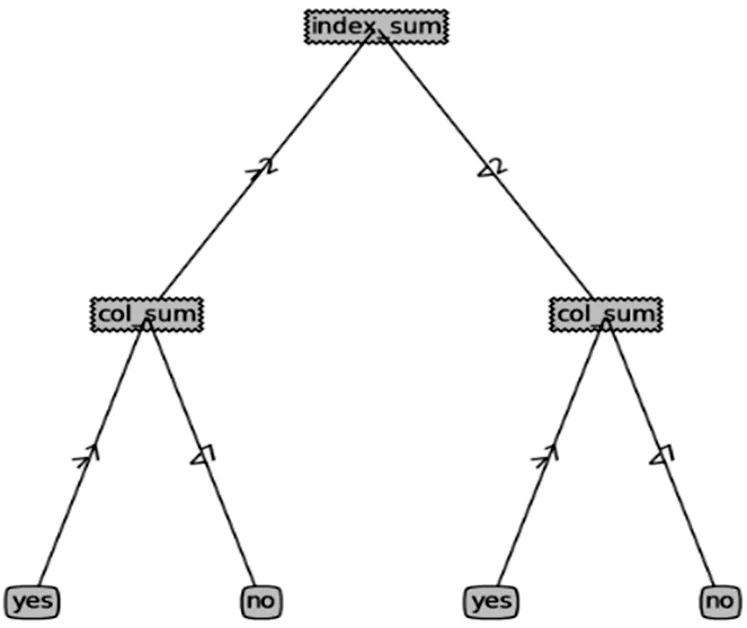
图5 决策树
决策树建立完成后,将632张表类比表2进行频次统计和汇总,如图6所示,表中分别存入属性列,INDEX_SUM作为主属性列的出现频次,COL_SUM作为非主属性列的出现频次。
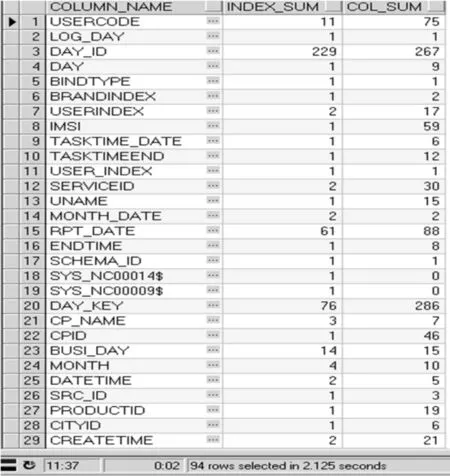
图6 索引属性初始数据集
将图6已统计完成的索引属性初始数据集带入图5生成的决策树中,最终得到相应的索引属性结果集,如图7所示。
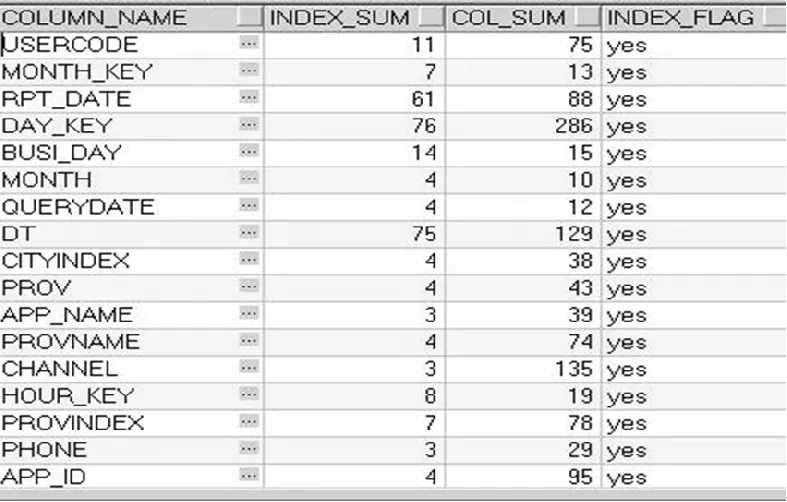
图7 索引属性结果集
4.4 实验结果
从索引属性结果集中可得出对于DAY_ID, DAY_KEY, DT, USERCODE,PROVNAME等字段无论对于主键索引频次还是字段关联频次都有较高的值且索引标志为“是”,那么在这个字段上建立索引是最优索引,而对于BINDTYPE,OSINDEX等字段,主键索引频次和字段关联频次都偏低且索引标志为“否”,那么这类字段是没有必要建立索引的。然后与原始索引表进行对比,准确率达90%,有个别字段没有建立索引,通过验证,证明了索引决策树对于建立索引的作用。
5 结束语
由于互联网和云计算技术的飞速发展,涉及的数据量急剧增加,海量数据的索引优化是大数据中值得深入研究并解决的问题,而基于决策树分类算法的索引优化方法下,可以有效地预测出大量的表中字段是否可以建立索引,通过对各个子空间的表字段进行处理,得到索引表数据,根据这一数据去建立索引,不仅节省了数据库空间资源,同时可以根据全局索引和局部索引的二级索引结构,快速定位索引信息,这样也节省了索引查找时间。但本文在构建决策树时,只考虑了主属性与非主属性出现的频次,所以在创建索引上可能不够精确。在后续研究中,拟考虑加入子空间各个表的大小、属性列的取值分散度等决策属性来提高准确率,提高索引优化效率。
[1] Meng Xiaofeng.From database to dataspace, from the service to enterprises to serve the public[R].Beijing:Renmin University of China,2009.
[2] Paolo Giardullo.Does ‘bigger’ mean‘better’? Pitfalls and shortcuts associated with big data for social research[J].Quality&Quantity,2016,50(2):529-547.
[3] Franklin M, Halevy A,Maier D.From databases to dataspaces:a new abstraction for information management[J].ACM SIGMOD Record,2005,34(4):27-33.
[4] Halevy A,Franklin M,Maier D.Principles of dataspace systems[C].Chicago,USA:Proceedings of the 25th ACM Sigmod-Sigactsigart Symposium on Principles of Database Systems(PODS’06),2006.
[5] Nafaa Jabeur,Sherali Zeadally,Biju Sayed.Mobile social networks applications[J].Communications of the ACM,2013,56(3):74-79.
[6] Benjamin Shapiro R,Pilar N Ossorio.Regulation of online social network studies[J].Science,2013(339):144-145.
[7] Quinlan J R.Induction of decsion tree[J].Machine Learning,1986(7):81-106.
[8] 宋宝燕,刘字,丁琳琳.大数据环境下一种基于可变网格的高维数据索引[J].计算机与数字工程,2015,312(43):1717-1728.
[9] 管天云,侯春华.大数据技术在智能管道海量数据分析与挖掘中的应用[J].现代电信科技,2014(Z1):59-62.
[10] Tan M.Cost-sensitive learning of classification knowledge and its applications in robotics[J].Machine Learning,1993,13(1):1-33.
[11] Breslow L A,Aha W.David simplifying decision tree:a survey[J].Knowledge Engineering Review,1997,12(1):1-40.
[12] Arno J,Knobbe,Siebes A,et al.Multi-relational decision tree induction[C]. Prague:Proceedings of the Third European Conference on Principles of Data Mining and Knowledge Discovery,1999.
[13] Mehenni T,Moussaoui A.Data mining from multiple heterogeneous relational databases using decision tree classification[J].Pattern Recognition Letters,2012,33(13):1768-1775.
[14] Quinlan J R.C4.5:Programs for machine learning[M].Morgan Kauffna,1993(8):23-30.
[15] Agrawal R,Lmielinshi T,Swmi A.Database mining:a performance perspective[J].IEEE Transactions on Knowledge and Engineering,1993,5(6):914-925.
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
北京航空航天大学学报(2021年6期)2021-07-20 07:23:56
电子制作(2019年19期)2019-11-23 08:41:36
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年19期)2018-11-14 02:37:02
电子制作(2018年16期)2018-09-26 03:27:06
电信科学(2016年11期)2016-11-23 05:07:56
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
通信电源技术(2016年6期)2016-04-20 06:21:36
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
