
一种新颖的基于森林-2-串算法的语义分析研究
2018-03-05 03:37:42廖志华
邵阳学院学报(自然科学版) 2018年1期
廖志华
(湖南师范大学 教师教育学院&教师教学发展中心,湖南 长沙,410081)
语义分析器通过意义表征语言(MRL),将自然语言(NL)语句转换为逻辑形式(LFs)。最近的研究主要集中在直接通过语料库来学习这样的分析器,而这些语料库是由与逻辑意义表征配对的句子所组成[1-11],研究的目标是学习一种语法,该语法可以将新的、不可见的句子映射到其相应的意义或逻辑表达式上。
虽然这些算法在特定语义形式上通常表现很好,但它们应用于不同的语义形式时究竟能表现如何,至今仍然有待探究。在文章中,我们将提出一种使用森林-2-树算法的统计机器翻译框架来学习语义分析任务的新型监督方法,即森林-2-串算法。这种方法将词汇获取和表层意义的实现集成在一个框架中。受到森林到字符串的概率生成算法[11]和Wong[12]以及Wong和Mooney[13-15],使用统计机器翻译来学习语义分析的启发,我们的语义分析框架由两个主要的部分组成。首先,该框架包含一个词汇获取组件,这是基于自然语言句子和线性化语义分析之间的短语对齐,该短语对齐是由现有短语对齐模型给出的一组训练样本。提取出来的转换规则形成同步上下文无关语法(SCFG),为此,用一个概率模型来解决分析歧义。第二个组成部分是来估计概率模型的参数。参数模型基于最大熵,概率模型以无监督的方式在同一组训练样本上进行训练。
文章的结构如下,第2节将描述我们如何构建具有森林-2-串算法来开发语义分析器,第3节将讨论解码器,第4节将介绍我们的实验并报告结果,最后,第5节得出结论。
1 语义分析模型
现在我们介绍语义分析的算法,它使用基于降阶的λ-SCFG将自然语言句子译为逻辑形式,这是基于演绎的SCFG的扩展版本[10]。给定一组训练句及其配对的正确逻辑形式,主要的学习任务是推断一组基于降阶的λ-SCFG规则——词库,是一个用于推导的概率模型。词库定义了可能的推导集合,所以概率模型的归纳首先需要一个词库。因此,学习任务又可以分为两个子任务:(1)归纳词库;(2)归纳概率模型-最大熵模型。
1.1 词汇习得
首先介绍语法,接下来介绍语法归纳的生成模型来获取语法规则。
语法归纳:我们采用Lu和Ng[11]开发的λ-混合树模型,这是从λ子表达式映射到具有联合生成过程的词序列的生成模型。
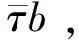
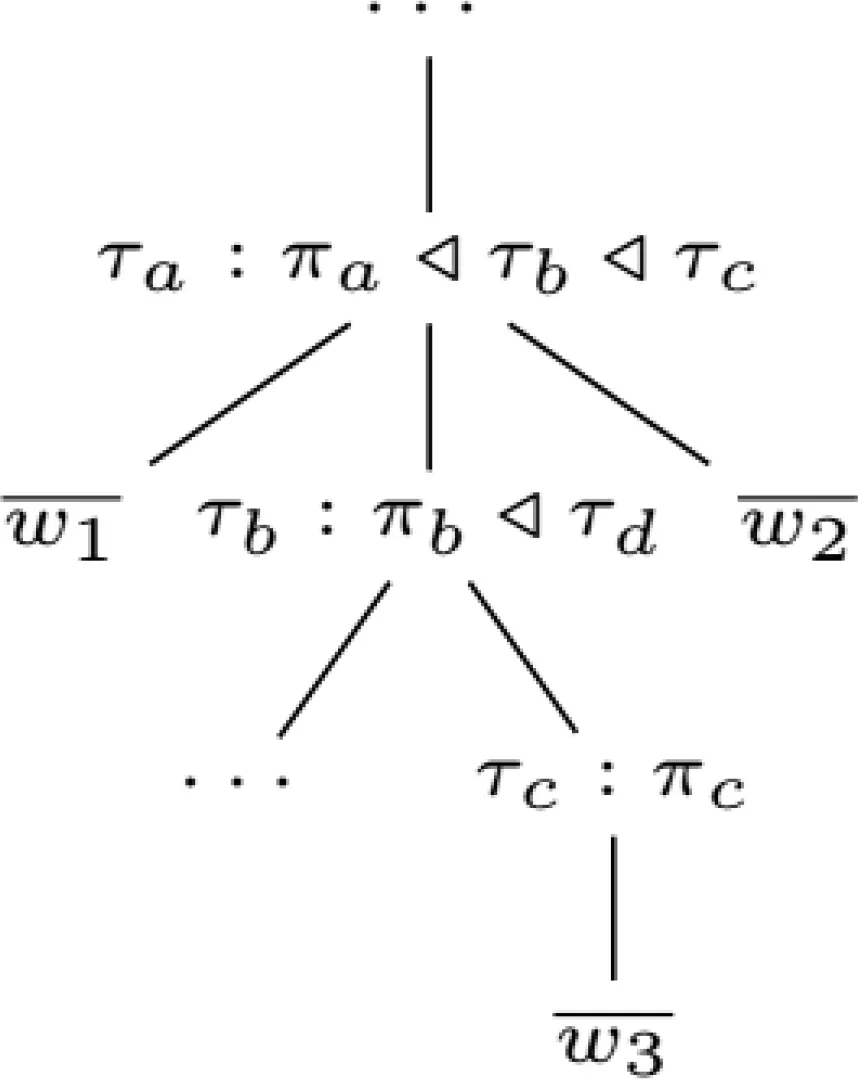
图1 λ-意义树及其对应的自然语言句子的联合生成过程Fig.1 The joint generative process of both λ-meaning tree and its corresponding natural language sentence
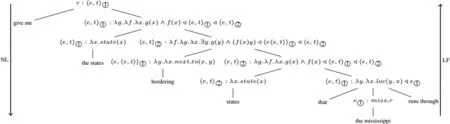
图2 “give me the states bordering states that the mississippi runs through(给我与密西西比全州接壤的国家)”的一个λ-混合树示例,及其逻辑形式“λx0.state(x0)∧∃x1.[loc(miss_x1)∧state(x1)∧next_to(x1,x0)]”Fig.2 One example λ-hybrid tree for the sentence “give me the states bordering states that the mississippiruns through” and its logical form “λx0.state(x0)∧∃x1.[loc(miss_x1)∧state(x1)∧next_to(x1,x0)]”
图2给出了一个λ混合树示例的一部分,从λ混合树中提取出语法规则,使用相同的语法进行分析和生成。由于SCFG对两个生成的字符串都是完全对称的,所以用于分析的同一个图表可以轻松适应高效分析。现在我们演示一下如何使用生成模型将自然语言句子映射到λ表达式上。首先,这个模型基于生成的λ-混合树模型的学习参数,找到所有训练实例的维特比λ-混合树。然后,该模型提取这些λ混合树顶部的语法规则。具体来说,我们提取下列同步语法规则的树类型,有λ-混合序列规则、子树规则和两级的λ-混合序列规则。示例见表1。
表1从λ混合树中提取出的同步规则示例
Table1Examplesynchronousrulesthatcanbeextractedfromtheλ-hybridtree

类型样例type1:〈e,〈e,t〉→〈bordering,λy,λx,next_to(x,y)〉〈e,t〉→〈〈e,t〉②〈e,t〉,λg,λy,λx,g(x)∧f(x)◁〈e,t〉①〈e,t〉②〉type2:〈e,t〉→〈statesthatthemississippirunsthrough,λx,loc(miss_r,x)∧state(x)〉〈e,t〉→〈thatthemississippirunsthrough,λx,loc(miss_r,x)〉type3:〈e,t〉→〈thestatesbordering〈e,t〉①,λf,λx.state(x)∧∃y.[f(y)∧next_to(y,x)]◁〈e,t〉①〉〈e,t〉→〈statesthate①runsthrough,λy,λx.loc(y,x)∧state(x)◁e①〉
1.λ-混合序列规则:这些惯用的规则由一个λ-生成和对应的λ-混合序列组成。
2.子树规则:这些规则由λ-混合树的完整子树构成,可以从每条规则中获取子表达式和连续子句之间的完整映射。
3.两级λ混合序列规则:这些规则由一个树的片段构成,其中一个孙子子树只抽象出其类型。这些规则是通过替代和降阶来构建的,下面展示了如何通过替代和降阶来构建两级的λ-混合序列规则。
表2是一个基于图2中λ-混合树的树形片段的例子。

表2 通过树片段的替换和降阶构建两级λ-混合序列规则
注意:由e□:miss_r根下的子树被其类型e“抽象”出来。因此引入类型e的辅助变量y′以促进构建过程。
为了实现讨论,我们以图3中的短语对齐为例。
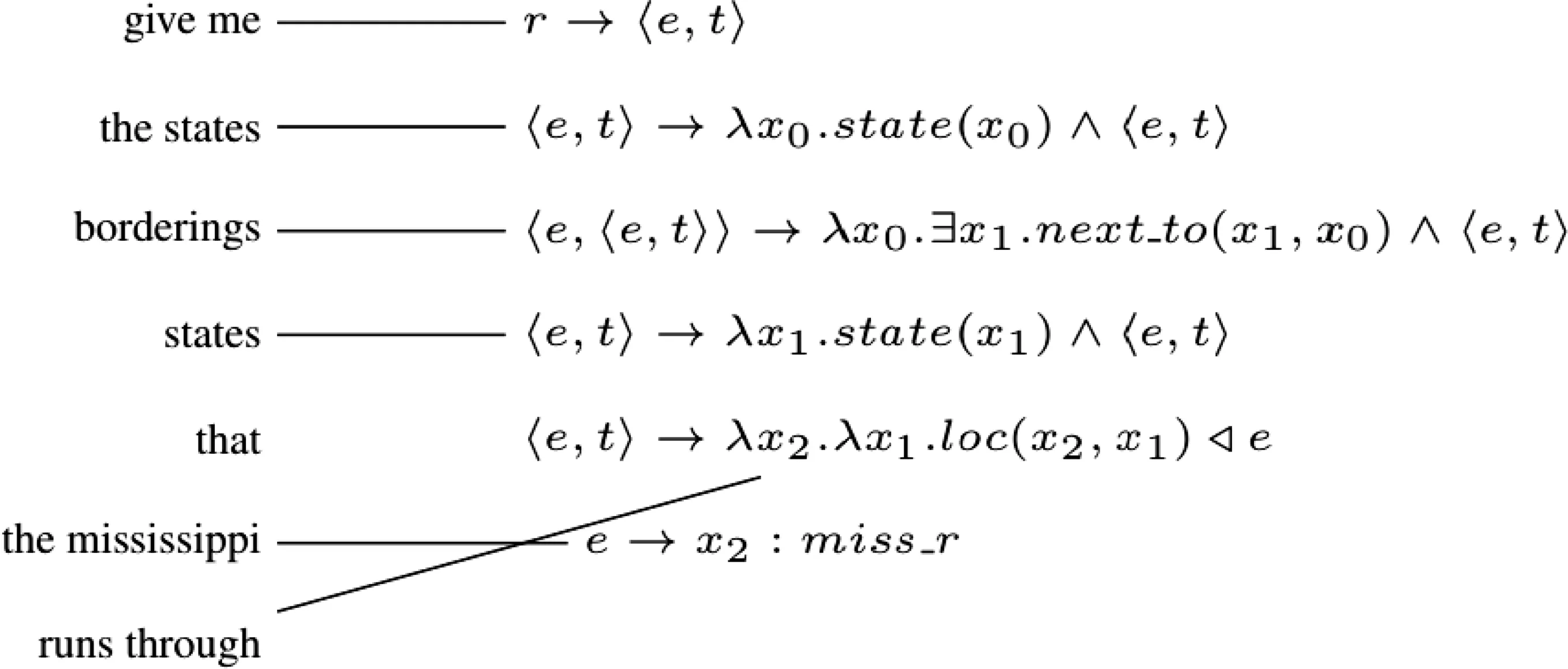
图3 基于λ混合树的短语对齐Fig.3 A phrase alignment based on aλ-hybrid tree
为了表示图3中的逻辑形式,我们使用其线性化分析——以自上而下和最左顺序生成逻辑形式的MRL生成列表。由于MRL语法没有歧义,每个逻辑形式都有一个独特的线性化分析。假设对齐方式为n到1,其中每个单词最多可链接到一个MRL生成。基本上,从λ混合树中可以提取出基于降阶的λ-SCFG语法规则和短语对齐[3],其中逻辑变量受到λ运算符的明确约束,且这些语法规则以自下而上的方式提取,从λ混合树叶子的MRL生成开始。规则提取以这种方式进行,直到提取到达λ-混合树的根。
1.2 最大熵模型
一旦获得了词库,下一个任务就是学习语义分析器的概率模型。我们提出最大熵模型,它定义了给定观察到的NL字符串ω的导数d的条件概率分布。在此,最大熵模型是指数模型:
条件概率Pλ(d|ω)与分配给每个特征fi的权重的λi乘积成比例。特征表示导数的某一特性。这样的话,特征就是推导中使用每个变换规则的次数。称为分区函数的功能Zλ(ω)是归一化因子,是条件概率与产生w的所有导数相加之和。得到的结果是,特征权重λi可以是任何正数。在最大熵模型中,使用额外的特征f*(d)来建立不可见词的生成,得到的值是所有被跳过的词的数量。对应于域特定词类的其他功能可用于更细粒度的修匀,这些功能可能相互交互并不成为问题。
2 解码
最大熵模型的解码可以这样进行:
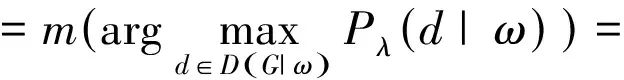
关于句子长度,可以使用维特比算法在三次方时间内完成。Earley图表用于跟踪与输入一致的所有导数,最大条件似然准则用于估计最大熵模型中的参数λi。这意味着给定ω,条件似然fi将最大化。选择这个准则是因为它更易于使用,并且允许判别学习形式,集中在能将好的分析与不好的分开。高斯先验((σ2=1))用来规范模型,由于黄金标准推导在训练数据中不可用,所以正确的推导必须视为隐含变量。为了找到局部最大化条件似然性的一组参数λ*,用改进的迭代缩放(IIS)版本与已经被用于估计基于概率统一语法的EM相结合。与完全监督的情况不同,条件似然性相对于λ来说不是凹型的,所以估计算法对初始参数很敏感。尽可能地假设,λ初始化为零。估计算法需要依赖于句子或句子MR对的所有可能的推导统计。虽然列举所有推导不可行,但可以使用Inside-Outside算法的变体来有效地收集所需的统计数据。只有在训练集的最佳分析中使用的规则才会保留在最终的词库中,其余所有规则都将舍弃[12-15]。假设在最佳分析中使用的规则是最准确的,这个通常被称为维特比近似的启发式,可以用来提高准确性。
3 实验
本节将介绍实验设置和结果的比较。遵循Zettlemoyer和Collins[16-18],以及Kwiatkowski等人[5-6]包括如下所述的数据集、初始化以及系统等方面的设置,最后,得出实验结果。
数据集:对两个基准封闭域数据集进行估算。GeoQuery由对地理信息数据库的自然语言查询组成,ATIS包含对航班订票系统的自然语言查询[16-18]。Geo880数据集分为600对的训练集和280对测试集,Geo250数据集是Geo880的一个子集,并使用与该子集相同分割的10倍交叉验证实验。ATIS数据集分为5000个样本开发集和450个样本测试集。
初始化:算法学习使用的是Och和Ney[19-20]的IBMModel5的GIZA++实现,来训练单词对齐模型。IBMModels1-4在训练期间用于初始化模型参数。
系统:比较这些最近公布、直接比较的结果。GeoQuery包括ZC07[16],λ-WASP[12-15],UBL[5]和FUBL[6]。报告的ATIS的结果来源于ZC07,UBL和FUBL。
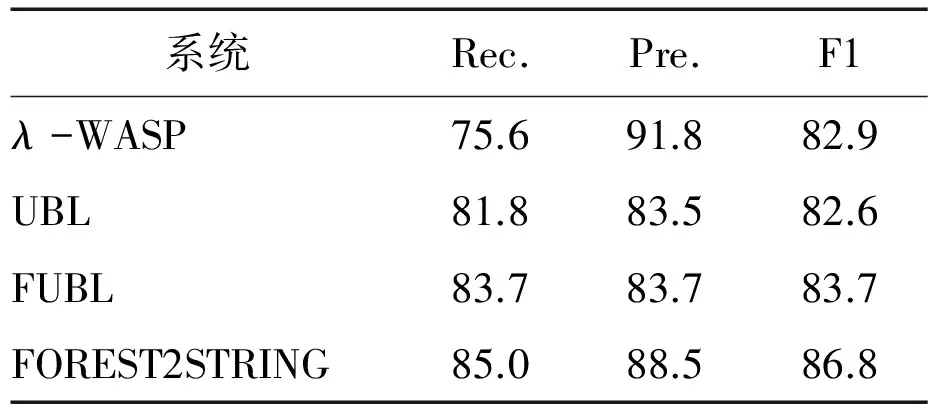
表3 不同GeoQuery测试集之间的完全匹配性能
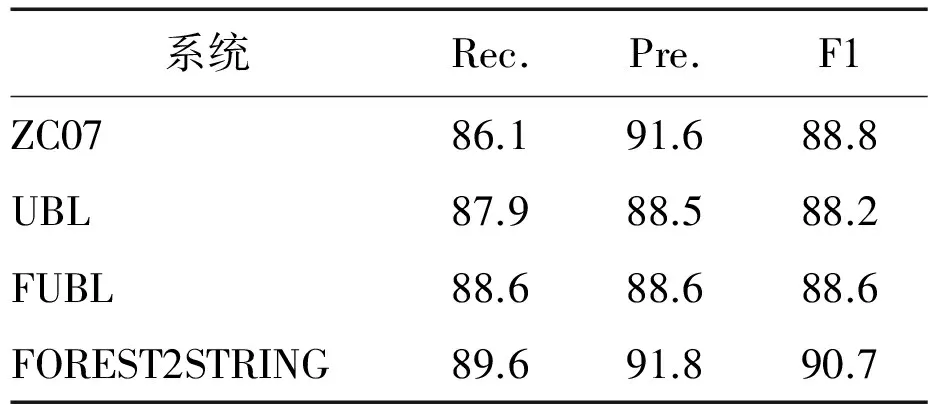
(b)Geo880测试集
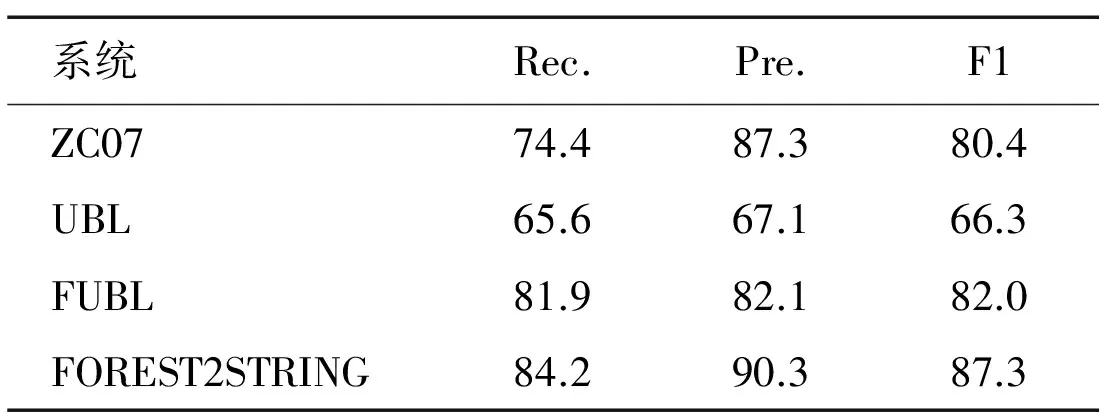
表4 ATIS开发集的完全匹配性能
表5ATIS测试集上的精确和部分匹配的性能
Table5PerformanceofexactandpartialmatchesontheATIStestset
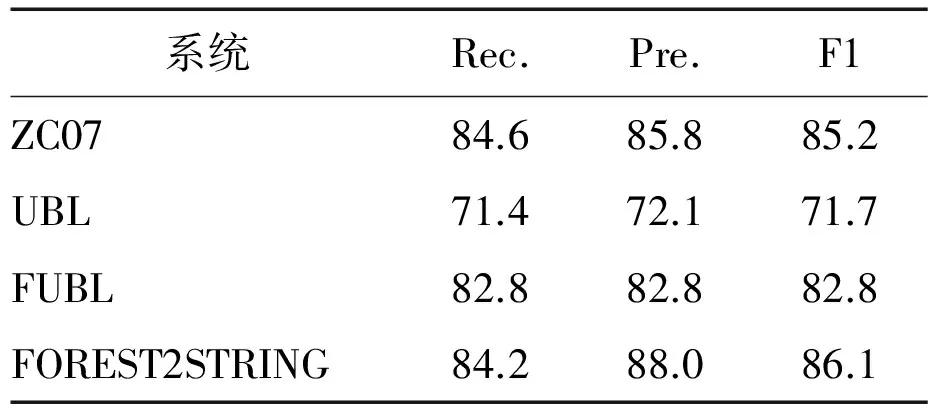
(a)精确匹配
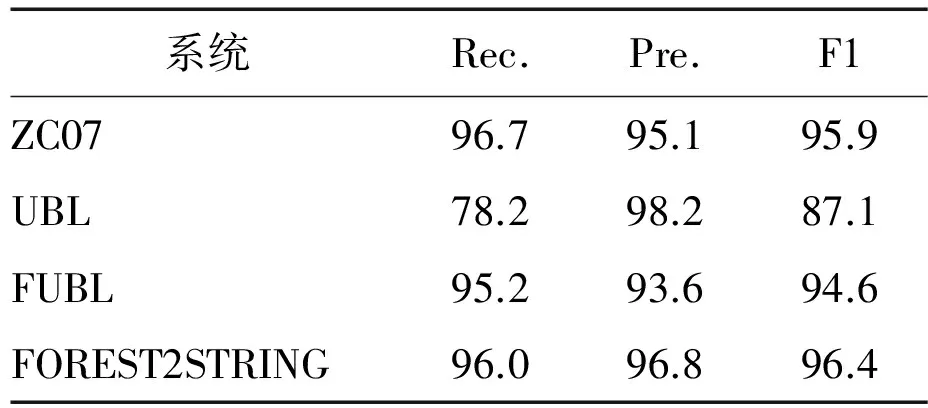
(b)部分匹配
结果:表3-5显示了GeoQuery和ATIS域中的所有结果。与直接比较的系统相比,我们的系统达到了最高水平的召回率和精确度,并且显著优于ZC07,λ-WASP,UBL和FUBL。对比其他三个系统,我们算法的主要优点是不需要任何自然语言句法的先验知识。因此,该算法可直接应用在其他自然语言句子的训练数据上。
4 结论
文中提出了一种新颖的基于森林-2-串算法的语义分析器模型。该模型是采用从森林-2-树算法的统计机器翻译框架来进行语义分析的新型监督方法。两个基准点数据集(即GeoQuery和ATIS)上的实验表明,我们的方法可获得合适的性能。
[1]YOAV A,LUKE Z.Bootstrapping semantic parsers from conversations[C]//In the Conference on Empirical Methods in Natural Language Processing(EMNLP).Singapore:ACL Anthology,2011:421-432.
[2]YOAV A,LUKE Z.Weakly supervised learning of semantic parsers for mappinginstructions to actions[J].Transactions of the Association for Computational Linguistics(TACL),2013,1:49-62.
[3]PHILIPP K,FRANZ O,DANIEL M.Statistical phrase-based translation[C]//In the Conference of the North American Chapter of the Association for Computational Linguistics(NAACLHLT).Singapore:ACL Anthology,2003:48-54.
[4]JAYANT K.Probabilistic models forlearning a semantic parser lexicon[C]//In the Conference of the North American Chapter of the Association for Computational Linguistics(NAACL-HLT).Singapore:ACL Anthology,2016:606-616.
[5]TOM K,LUKE Z,SHARON G,et al.Inducing probabilistic ccg grammars from logical form withhigher-order unification[C]//In the Conference on Empirical Methods in Natural Language Processing(EMNLP),Singapore:ACL Anthology,2010:1223-1233.
[6]TOM K,LUKE Z,Sharon G,et al.Lexical generalization in ccg grammar induction for semantic parsing[C].In the Conference on Empirical Methods in Natural Language Processing(EMNLP).Singapore:ACL Anthology,2011:1512-1523.
[7]LIAO Z,ZENG Q,WANG Q.Semantic parsing via ‘0-norm-based alignment[C].In Recent Advances in Natural Language Processing(RANLP).Singapore:ACL Anthology,2015:355-361.
[8]LIAO Z,ZENG Q,WANG Q.Asupervised semantic parsing with lexical extensionand syntactic constraint[C]//In Recent Advances in Natural Language Processing(RANLP),Singapore:ACL Anthology,2015:362-370.
[9]LIAO Z,ZHANG Z.Learning to map Chinese sentences to logical forms[C]//In the 7th International Conference on Knowledge Science,Engineering and Management(KSEM).Berlin Heidelberg:Springer-Verlag,2013:463-472.
[10]LU W,Ng T.A probabilisticforest-to-string model for language generation fromtyped lambda calculus expressions[C]//In the Conference on Empirical Methods in Natural Language Processing(EMNLP).Singapore:ACL Anthology,2011:1611-1622.
[11]LUW,Ng T,LEE S,et al.Agenerative model for parsingnatural language to meaning representations[C]//In the Conference on Empirical Methods in Natural Language Processing(EMNLP).Singapore:ACL Anthology,2008:783-792.
[12]WONG W.Learning for Semantic Parsing and Natural Language Generation Using Statistical Machine Translation Techniques[D].Austin:University of Texas at Austin,2007.
[13]WONG W,RAYMOND M.Learning for semantic parsing with statistical machine translation[C]//In the Human Language Technology Conference of the North American Association for Computational Linguistics(NAACL).Singapore:ACL Anthology,2006:439-446.
[14]WONG W,RAYMOND M.Generation by inverting a semantic parser that uses statistical machine translation[C]//In the Conference of the North American Chapter of the Association for Computational Linguistics(NAACL-HLT-07).Singapore:ACL Anthology,2007 :172-179.
[15]WONG W,RAYMOND M.Learning synchronous grammars for semantic parsing with lambda calculus[C]//In the Conference of the Association for Computational Linguistics(ACL).Singapore:ACL Anthology,2007:960-967.
[16]LUKE Z,MICHAEL C.Learning to map sentences to logical form:Structured classification with probabilistic categorical grammars[C]//In the 21st Conference on Uncertaintyin Artificial Intelligence(UAI).Singapore:ACL Anthology,2005:658-666.
[17]LUKE Z,MICHAEL C.Online learning of relaxed ccg grammars for parsing tological form[C]//In the Conference on Empirical Methods in Natural Language Processing and the Conference on Computational Natural Language Learning(EMNLP-CoNLL).Singapore:ACL Anthology,2007:678-687.
[18]LUKE Z,MICHAEL C.Learning context-dependent mappings from sentences to logical form[C].In Joint conference of the47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing(ACL-IJCNLP).Singapore:ACL Anthology,2009 :976-984.
[19]FRANZ O,HERMANN N.A systematic comparison of various statistical alignment models[J].Computational Linguistics,2003,29(01):19-51.
[20]FRANZ O,HERMANN N.The alignment template approach to statistical machine translation[J].Computational Linguistics,2004,2(30):417-449.
猜你喜欢
中学生数理化·高一版(2021年3期)2021-06-09 06:10:16
开放教育研究(2020年2期)2020-03-31 01:54:14
电子测试(2018年10期)2018-06-26 05:53:50
英语知识(2016年1期)2016-11-11 07:07:54
现代语文(2016年21期)2016-05-25 13:13:44
中学生数理化·中考版(2015年10期)2015-09-10 07:22:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
电脑迷(2014年14期)2014-04-29 00:44:03
电脑迷(2012年15期)2012-04-29 17:09:47
外语学刊(2011年1期)2011-01-22 03:38:33
