
国外区域和城市经济学实证研究进展及其对中国的启示
2018-03-05 06:23
现代财经-天津财经大学学报 2018年3期
(1.南开大学 经济学院,天津 300071; 2.南开大学 经济与社会发展研究院,天津 300110)
一、引言
区域和城市经济学实证研究主要是依据相关的理论并结合经济现象,聚焦于探索空间经济活动分布的规律,这就决定了其研究重点是如何将空间变量引入到一般线性模型,进而拟合空间数据,解释空间数据所隐藏的区域和城市经济活动的分布规律与内在决定因素。区域和城市经济学早期的实证研究重点,在于将计量经济模型简单地引入到区域和城市经济分析中,并未对实证模型的方法论进行深入的研究。此阶段实证研究在处理可获得数据时不是灵活地调整传统模型和技术,而是常常“刻意加工数据”,使之符合过于苛刻的模型和技术。然而,随着区域和城市经济学实证研究的深入,逐渐开始注重实证研究方法论的探讨,尤其是对数据的因果关系、空间数据的非随机性等实证方法进行理论研究。这使得区域和城市经济学实证研究不仅注重通过计量模型来估计相关参数,分析数据的因果关系,解释空间经济活动现象;还注重对实证研究方法的探讨,完善实证研究的理论体系。区域和城市经济学实证研究已经能够使用复杂且精确的模型来对空间经济活动做出科学合理的解释,增加了学科的可操作性和实践性。
通过对国外区域和城市经济学实证研究的梳理,本文重点论述了以下几个方面:一是分析空间数据的属性,揭示经济活动分布的客观规律;二是探究国外区域和城市经济学如何将空间变量引入一般线性模型,以及如何通过空间权重识别空间相互关系;三是具体分析实证研究内容与研究方法;最后总结自20世纪70年代以来的研究趋势,并提出了对我国区域和城市经济研究的启示。
二、空间数据——实证研究分析的起点
对地理空间上社会和经济相互作用模式的解释和预测一直是区域和城市经济学家感兴趣的议题,随着区域和城市经济学将微观经济学的研究工具应用到区域和城市经济分析中,同质空间经济假设逐渐被打破,区域和城市经济学理论和实证研究逐步转向对异质空间的解释。在实证研究中,这种异质性更多地表现为空间数据的非随机性,如个人与企业在地理上会集中于城市区域。区域和城市经济学实证研究就是要通过对数据的挖掘、分析与应用,解释这些集聚会如何影响产出且为什么有些城市表现的比其他城市要更好?在多大程度上特定产业的企业会在地理上集聚?为什么这些集聚会发生,以及这些集聚会如何影响企业的行为等。
正确判断数据的维度,即区分观察到的数据是否具有随机性,是实证研究的前提条件。所有的空间数据构成了可以被确定在空间上的观察单位的基础,对每一个观测值而言,当区位只是一个额外的信息时,其并未增加分析和理解空间现象原因的难度,即具有完全的空间随机性,其假定空间是同质的,空间数据点在任何位置上分布的可能性是相等的(Diggle,2003)。然而,当个体间发生相互影响时,给定的空间数据可能会发生对随机性的偏离,即表现为非随机性,空间往往被假定为异质的(杜兰顿和奥弗曼,2005),如图1所示。

图1 空间数据的随机性与非随机性 注:该图来源于《Handbook of Regional and Urban Economics(Volume 5)》,Chapter 2.(2015)。
空间数据非随机性的挖掘已成为区域和城市经济学主要的研究方向之一。然而,在许多情况下,研究者仅能获得观测单位在区域而非个体层面的空间加总数据。杜兰顿和奥弗曼(2005)将这一加总的过程称为“将地图上的点移动到盒子中的单位”。任何这种离散化和相应的加总过程都意味着信息的损失。很多应用研究只能基于地区(社区、区位等)数据的特征指数来描述空间数据,如Herfindahl-Hirschman 指数,克鲁格曼/差异化指数,或者“全局空间联系指标”——如Moran’s I或者Getis-Ord 统计量(Moran,1950;Getis和Ord,1992)。随着计算机技术的发展,大量的研究者设计出检验非随机性的指标,这些指标可以用于具有详细区位信息的非加总数据。此外,适合于调研和专门探索性数据分析的现代统计与计量经济学软件的开发与应用,如Arcgis软件、Geoda软件和ENVI软件等,能够更容易对大量的微观数据进行探索性分析。如离散选择模型传统上是用跨部门的抽样调查数据来进行估计的,某些情况下,研究人员可以得到更丰富的纵向数据从而用它来建立个人选择行为的动态模型,并确定这种行为对经济、社会和环境变化的影响。这种影响的判定要求了解许多内在相关的变化源泉,特别是对异质性、不稳定性和跨时间的状态依赖性的了解。不仅仅是对城市缺乏微观区位特征的横向数据的分析,这也使得对城市内部更细致的研究得到深化。
以上分析表明,空间数据的分析从不加批评的标准推论检验和统计模型的运用阶段,发展到广泛应用相互依赖、相互作用的空间数据阶段。其中,空间依赖概念和空间分析方法与定性统计模型的进一步整合是非常重要的研究方向。本文将在下一小节对区域和城市经济学实证研究如何基于数据分析基础上,将空间变量引入到一般线性模型进行研究与总结。
三、空间变量的引入——打破一般线性模型的“维度”魔咒
现代区域和城市经济建模是以寻求空间经济体系的系统和定量描述为特点,大量的研究重点放在体系的组成成分和体系间相互作用的界定和描述。与其他模型不同的是,区域和城市经济实证模型涉及一组地点和区域内经济发展的描述、分析、预测和政策评价,这种模型不仅关注内部结构和关系,而且关心区际相互关联。这决定了区域和城市经济学实证研究的绝大部分工作,是把一般线性模型一般化到空间模型,而这一过程要综合估计每一个区域和城市经济的空间相关性和空间异质性。因此,不仅要能够通过选择区域和城市经济实证模型,解释现实的经济活动分布现象;而且还要探究从空间数据分析经济活动分布动因的方法。区域和城市经济学实证研究在借鉴传统的计量经济学研究基础上,将空间变量纳入到一般线性回归模型,使得空间计量模型理论和方法体系逐步完善。
(一)一般线性回归模型——“空间维度”的缺失
区域和城市经济学实证研究模型主要是用来对一组地点和区域内或区际经济发展的描述、分析、预测和政策评价,其既可以反映区域和城市的静态变化,也能够对区域和城市的动态变化进行模拟。同时,空间分布、规模、形状和作为数据来源的空间单元或者格子点的组织,都影响空间过程和估计的参数。即模型结构不独立于空间数据基础——“柯里效应”(柯里,1972)。基于对空间数据的属性和模型建构的理解,里格利(1979,1985)给出了理解分析数据的范围和相互关系的一种可能的框架,如表1。

表1 依变量类型划分的统计问题分类
注:表格引自《区域和城市经济学手册》第1卷第11章。
表1给出了依据解释变量和响应变量的种类来对统计问题进行分类。实际上,变量一般被划分为连续和类别变量,而混合变量往往是前两者的组合。同时,连续性变量多采用基数来表示,类别变量则以名义尺度或序数尺度来度量。就区域和城市经济学实证研究而言,类别变量既包含传统的计量经济学中类型变量所具有的特性,还具有一定的独特的空间属性,这往往是主流经济学所忽略的。此外,从表1中可以区分出两种不同类型的统计建模,即定量统计模型和定性统计模型。定量统计模型主要包括a,然而随着计量建模技巧和大量软件的出现,在定量模型中也逐步将b和c纳入进来。模型重点放在以比率或区间比例表示的高质量的公制或定量数据的分析。定性统计模型则主要是解决d、e和f类变量的问题,这类统计模型可获得的信息经常是官方的统计或大量的抽样调查,并且通常具有非公制的特征,即定性的、不连续或是分类的。依据不同的变量类型,定量统计分析和定性统计分析已经构建了相应的模型,前者主要包括经典回归模型和虚拟变量回归模型等;而后者主要包含对数—线性模型、逻辑斯蒂/逻辑特模型、概率单位回归模型等。传统的区域和城市经济实证研究形成了一个更广泛的一般线性模型(GLM)家族,定量模型和定性模型之间的联系可以视为内尔德和韦德伯恩(1972)“一般线性模型”(GLMS)组合家族中的成员来形式化,内尔德通过构建一个“联系函数”g(即θi=g(ωi),ωi为响应变量的期望值),以及线性预测式(θi=ΣμiXik)和误差分布的组合来确定出一般线性模型中的任何特殊模型,具体如下表2。

表2 一般线性模型例子
(二)空间模型——“空间变量”的引入
空间相互作用模型是以类似于相互作用的粒子世界和万有引力为基础的;且随着学者对于合适权重、灵活的函数形式和距离及运输成本等改进,空间相互作用模型理论不断得到完善,并提出了支持空间相互作用模型的特定的统计和行为关系,如重力和潜力模型、市场区和零售贸易模型、供给-需求潜力和空间价格变化等。但是,早期的空间相互作用模型局限于静态框架中,几乎没有研究将空间相互作用的理论模型嵌入到动态分析框架;模型主要研究不同的瞬时空间现象及其决定性的战略变量,比如区位、互动流、空间结构等因素。然而,20世纪70年代中期之后,区域和城市经济学实证研究逐渐转向对区域和城市动态模型或理论的研究,试图将不可分解的时间、空间两个维度结合起来,进而构建完整的动态区域和城市空间模型。这些模型不仅涉及供给、需求、收入、投资等基本参数的动态变化,还包含变动比较缓慢的结构性质和异常迅速变化的过程(如区域间的人口、资本的流动等)。随着理论模型研究的深入,以及计量经济学建模技巧和工具的完善,区域和城市空间动态计量经济学已成为研究的新趋向,能更好地从时空维度解释区域和城市经济活动的动态变化。
传统的一般线性模型难以解释数据的非随机性,这主要在于其变量是单向联系的,即变量之间属于单边依赖关系。相反,区域和城市空间计量经济学中,变量之间是多边依赖的即关系是多向的。“空间变量”的引入可以将标准的一般线性回归模型应用到空间分析中,但这需要能够在模型中加入能够明确说明个体位于空间中的哪个地方、所处空间的任何特征以及个体间的相互影响的额外信息或区位信息。这主要体现为两方面:一是地区特征对个体的影响,二是相邻个体之间的相互影响(Angrist,2009)。一个能够涵盖研究者们利用线性回归所能做的几乎所有事情的框架,是基于一般线性模型的拓展形式。
(1)
或者可以用矩阵表示为
y=Xγ+Gγyβ+GxXθ+GzZδ+GvVφ+ε
(2)
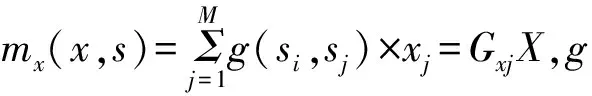
学者Anselan早在20世纪80年代,对包含不同的空间变量的一般线性模型做出了区分,后继学者如杜宾(1989)、Kelejian和Robinson(1993)、Lesage和Pace(2009)、Baltagi等(2010)等等对空间计量模型做了进一步的细分与扩展。依据对不同空间变量间相互影响的识别,区域和城市经济学常用的空间模型主要具有以下类型,如表3。

表3 依空间相关关系划分的空间模型
因此,与一般线性模型相比,这些表达式可以捕捉被动或者主动的外部性与交互性,空间模型打破了“维度”魔咒,其中空间相关关系的识别则是其中的关键。
(三)空间权重——“空间交互关系”的识别
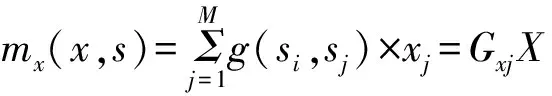
根据交互作用的性质不同,矩阵G可以是对称的,也可以是非对称的。如果任意两个单位存在双边的影响,那么矩阵G就是对称的;如果交互作用被假定为单向的,那么矩阵G是非对称的。对于空间权重矩阵的选择,要根据所研究具体问题的需要;不同的空间加权变量G的构建,能够反映空间相互关系的程度并提供相对灵活的处理方式。目前,区域和城市经济学实证研究常用的空间权重的构造方法主要基于物理距离、邻接矩阵、距离权重的倒数和某些网络的联系指标等方式。利用这些权重来反映空间相互关系,权重矩阵可以被定义为邻近观测值的空间均值或者加总值。其中,加总过程会将相邻个人、企业或者区域的效应进行相加,因此考虑了被权重结构所说明的群组内部的个体的数量。相反,平均过程将相互邻近的个人、企业或者区域数量的影响消除了。平均过程在大多数领域中是一种标准方法,包括在邻里与同辈效应的研究(Epple和Romano,2011)。加总过程通常在集聚经济、交通可达性的研究中更为恰当,此时其研究的重点是经济总体或者“市场潜力”(Graham,2007;Melo等,2009)。因此,如何科学合理的选择空间加权矩阵,消除空间模型参数估计的困难,是进行空间模型运用的关键前提。
总之,区域和城市经济学实证研究一直不断地通过对线性模型的完善,来解释区域和城市经济活动的空间分布;尤其是近年来随着空间面板模型的发展,区域和城市经济学实证研究能够更加准确的对空间数据的非随机性做出科学的解释,并能够揭示区域和城市经济活动空间格局的动态变化及其原因。
四、空间模型估计、检验与应用——实证研究的核心
区域和城市经济实证研究与传统计量经济学都遵循如图2所示的一系列分析阶段。本文按照这一分析阶段对相关内容进行总结,具体如下。
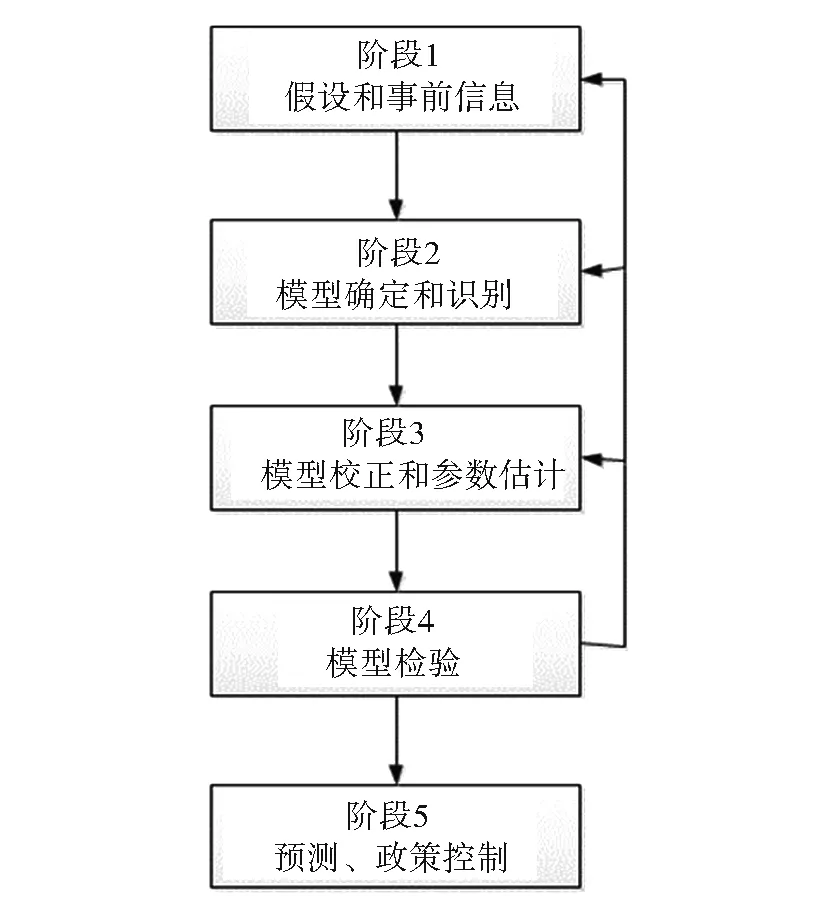
图2 区域与城市计量经济学分析阶段
(一)提出假设和事前信息分析
对于任何成功的实证研究而言,关键是能够识别出感兴趣参数的数据中变异的来源,即能够发现数据中的因果关系。那么,所有可获得的事前信息都可以用来事先确定模型中选择的重要变量和联系方向。同时,对于这些事前信息的搜集能够更好地对空间经济现象进行描述,即能够从最终数据中推导出基本空间过程结构;而这些数据又是以基本空间过程的演绎理论为基础(海宁,1980)。这属于区域和城市经济学实证研究的描述和变量识别阶段,主要为计量模型的确定和变量的选择做准备。对于用来估计感兴趣参数的处理变量而言,考虑其变异的来源是至关重要的。通过对这些变异来源的分析,能够确定现实的经济变量之间可能存在的交互影响关系,这就为在一般线性模型基础上,引入何种空间变量提供了理论基础。因此,事前信息的搜集和假设的提出,对区域和城市实证研究至关重要,在一定程度上决定着计量模型的选择和具体参数识别与确定,从而避免因变量的缺失和模型的误设造成选择性偏差和识别问题。同时,对于实际的描述要注意映像模式、空间自相关和面积单位等问题,这些问题的深入分析能够为模型的正确选择提供指导,避免模型的错误选择,进而导致实证研究失败。
(二)模型的确定和识别
任何利用空间数据的研究者都会遇到一个根本性的挑战,即空间模型的识别与估计是一个很困难的实证研究过程。正如辛普森和范德维恩(1992)对计量模型的构建问题指出,“……主要的绊脚石可能不是模型的发展,而是模型的建立和检验……”。这主要在于空间经济因素之间存在多向的复杂联系,即使最精炼的数据集和最复杂的计量技巧也不可能考虑影响结果变量的所有细节。这就可能会有变量的遗漏带来的空间自相关、异方差以及边界和数据丢失问题,从而导致估计出现偏差。斯诺和费雷拉(2015)指出区分这个“识别到的变异”允许研究者考虑两个核心问题。首先,是否存在同时影响结果以及与处理变量中识别到的变异相关的不可观测变量。如果这样的缺失变量存在,那么估计得到的处理变量系数是有偏和不一致的,即存在“内生性问题”。其次,如果将总体视为存在这种识别到的变异数据的子集,这会有多强的代表性。如果对这种变异的明确识别仅存在于总体一个小的不具代表性的子集中,那么表明估计得到的处理变量系数的适用性有限且很难推广到其他总体。
随着空间计量经济学理论的发展,20世纪70年代中期之后,关于如何将空间变量引入到一般线性模型中的讨论逐渐增多,越来越多的学者更加关注将空间因素引入到一般线性模型中。尤其是空间面板数据模型从传统的面板数据模型扩展而来,因纳入区域或者截面维度的空间交互效应(Spatial Interaction Effects)才形成了空间面板模型。如果将时间维度的动态变化项引入,即时间滞后项,则又演变成了动态空间面板数据模型(Dynamic Spatial Panel Data Model)。面板数据模型结合以上4个不同的空间变量可以构建出相应的滞后和误差模型。在实际应用中,空间面板模型更多地考虑空间个体特征的异质性,往往使用空间面板的随机效应和固定效应模型。如布罗克和杜劳夫(2001b)提出使用面板数据通过差分来消除邻里固定效应;钱德拉和汤普森(2000)估计了包括县区固定效应的城市间分布滞后模型等。因此,随着区域和城市经济理论以及相关的计量方法的改善,空间交互效应—内生性交互效应(Endogenous Interaction Effects)、外生性交互效应(Exogenous Interaction Effects)和误差项之间的交互效应(Error Interaction Effects)—已被成功地引入到模型中来,并被运用到具体的实践中。
(三)模型的校正和参数估计
区域和城市经济学实证研究中发现了空间依赖性和空间异质性两种主要的误设问题(安瑟兰,1988)。前者主要在于个体之间的空间组织是非独立,即存在空间交互效应;而后者则在于个体之间在行为上普遍存在的不稳定性。这会导致在模型的识别和估计中可能存在三大问题:一是反映问题,即当不可观测因素在群组层面上变动,无法单独估计β(群组的行为或者结果对个体结果的影响)和(群组特征的影响)θ;二是出现具有相关性的不可观测变量或者一般冲击;三是分类效应,即存在与区位决策和结果相关的缺失变量。具体来说,不可观测变量中可能存在空间自相关,这主要在于个人在不可观测的维度上相互影响,如因组员接触到了相似的不可观测因素而产生,不同的群体也会受到来自所在区域冲击的影响,而这些冲击与群体的表现并没有直接联系。曼斯基(1993)将其称为“关联效应”,群组专属的不可观测因素的出现,尽管与个人可观测变量不相关,但也会影响个人和群组的行为。其他领域的应用经济学者通常将其称为“共同冲击”,这主要是为了说明位于同一空间或者同辈群体中的个体会受到共同的不可观测因素的影响。当估计是基于观测性的调查、普查或者官方数据以及没有明确的试验或者政策构造数据的时候,这种群组专属的在不可观测变量上的差异几乎是不可避免的。学者已对该问题进行了深入的研究,提出了反映问题的可能解决方法——利用函数形式变换、施加排除性约束、利用非完备交互矩阵以及利用网络数据处理同辈效应识别与估计等(Kelejian和Prucha,1998;Gaviria和Raphael,2001;Goux和Maurin,2007;Bramoullé等,2009;Lee等,2010)。此外,当组员是内生的,相关也可能会由于具有不同特征x的个体进入拥有不同的GoV区位导致的。例如,在研究城市工资与城市教育关系的集聚经济文献中,这一问题会由于教育回报高的城市会具有能够鼓励个体来获取更多教育的不可观测因素出现,这在人力资本模型中也是相同的(Moretti,2004)。在大多数情况中,当组员是内生的时候,“分类效应”是应该得到优先考虑的。换句话说,GxX、GzZ和GvV与之间的相关性是因为Gx、Gz和Gv的内生性导致的。目前关于该问题的解决方法是采用空间差分法和“边界断点”设计。
在基于对模型可能存在的问题识别与修正的基础上,选择合适的参数估计方法对模型进行估计是区域和城市经济学实证研究的重要环节。总的来说,变量参数的估计方法可以分为两种类型,即参数方法和非参数方法。其中参数方法一般是分析者选择一种具体函数形式,然后通过估测这些参数值,使所建立的函数能够“最好地拟合”原始数据。非参数方法则事先不设定函数关系,而是直接从数据中推出相关参数的估计值。但应用这种方法时需要大量的数据,严格讲按照这种方法进行估测时,随着样本容量的增加,估测值逐渐向实际值收敛。就具体的模型估计方法而言,随着区域和城市经济学实证研究理论方法与计量工具的完善,研究逐步地由仅利用截面回归方法向采用工具变量、面板数据以及非线性模型等方法转变,并使用比普通最小二乘法更为复杂的研究设计来估计因果参数。学者们总结了1980-2010年间城市经济学期刊中不同实证方法的使用程度,具体如表4。

表4 1980-2010年城市经济学期刊中不同实证方法的使用频率(%)
资料来源:该表摘抄自《区域和城市经济学手册(第5卷)》。作者是根据相应年份所有发表在城市经济学期刊上的文章计算的。
一般而言,受空间依赖性和空间异质性的影响,普通最小二乘技术在区域和城市应用中往往不成立,即存在模型参数估计的不一致等问题。对于该问题的解决,区域和城市经济学研究者一直在努力寻求解决方法,研究者提出把标准的经济计量学方法运用到联立方程系统中,起点是策尔纳(1962)的“似不相关回归法”才使得时空关系得到考虑。当前,研究中常用且比较令人满意的具有滞后内生变量和残差自回归的方法,应该是以工具变量(IV)、最大似然估计(MLE)、广义矩估计(GMM)以及相关技术为基础的方法。随着估计方法的不断完善,空间模型能够更好地对数据进行模拟,进而对空间经济现象进行合理的解释。
(四)模型的检验
模型的检验主要集中于两方面:一是检验模型参数的有效性和拟合程度,从而可以判断该模型是不是一个成功的解释工具。如果发现模型的参数估计是无效的,或者具有低质量——显著水平低或不显著、拟合性质差和残差自相关等,则需要对之前阶段的分析进行反馈,识别模型问题所在。目前,区域和城市经济分析已经引用统计分析中的各种统计量来检验模型的拟合优度,如在对数-线性模型中使用的G2统计量和逻辑斯蒂和逻辑特模型中采用皮尔逊χ2统计量等。而这些模型的选择主要是根据拟合优度做出的,并使用残差来对模型进行诊断,度量观测值与拟合值之间的差异,测算异常的或不适宜的数据点或数据中不属于模型体系的部分。在定性分析中,对残差最有用的定义是χ2分量和偏差分量。对于组合影响的诊断检验,可以采用LM统计量的零假设检验,如果拒绝零假设检验,则应利用随机效应统计量来代替最小二乘估计。二是,对于模型的检验不能仅仅通过计量指标来检验,还要通过与具体的区域和城市经济理论相结合,对于参数的符号、范围和显著性等问题进行理论的检验,避免出现与现实经济现象相违背的估计结果。如果估计得出的参数明显与现实的经济现状相反,那么就需要对模型的设定、变量的选择等重新做出检验和识别。如果模型能够接受,则可以使用模型进行预测与政策控制。
(五)模型的应用
模型的估计能够说明数据间的因果关系,即是什么导致了结果变量的变化,以及为了促进结果变量的持续变化或者改善,应该做些什么。换句话说,实证模型估计结果不仅探究了空间数据非随机性的来源,还说明未来应如何做,这就是模型的预测与政策控制作用。模型的预测与政策评价则会说明“如果……将会发生什么”,以及“为了实现一定的目标,应如何设置政策与政策工具”。区域和城市经济学实证模型对预测和控制模型的发展已经做出了重要的促进作用,尤其是在空间区位——源于具有空间演化动态方程的传统区位配置模型——城市体系中的零售业和其他存货配置、政策处理效应评估等方面做出了重要的贡献。值得注意的是,关于政策的评估也是当前区域和城市经济学研究的前沿问题。


图3 由反馈和前馈政策策略产生的闭环效应资料来源:该图摘自《区域和城市经济手册》第1卷(2015)。
依据图3,可以将政策分析划分为回溯性政策和前景性政策。回溯性政策分析是在样本观测期内对发生在过去的政策干预进行评价。其重要目的是估计被观测到的政策干预的处理效应,即模型估计得到的变量的实际值。而前景性分析主要针对尚未制定的政策,这种政策可以看成是对现有模型估计中出现的偏差的修正,通过政策工具的使用来缩小模型预测和政策期望之间的偏离。目前,随机试验是发现处理效应的一个重要工具,特别是基于政策评估的动机(Duflo等,2008)。随机试验(randomized experiment)和自然试验或准实验(natural experiment quasi experiment)已经被引入区域和城市经济学的政策评估分析中。如雷丁和斯特姆(2008)用第二次世界大战后德国的分裂和在1990年德国统一作为一次自然实验,为支持经济地理学的数量模型提供了证据。运用相应的计量方法,可以得出项目或政策的平均处理效应(ATE)、边际处理效应(MTE)和被处理的处理效应(TT)等,进而分析政策实施带来的影响。区域和城市经济学实证研究中处理效应的估计方法的具体使用如下表5。
表5列出了近年来关于研究随机试验对于数据因果关系的检验方法与实证工具,尤其是关于处理效应的估计方法的研究,是目前区域和城市经济学的前沿研究方向之一。正如在分析中指出的处理效应主要基于“反事实”的框架,对政策或项目实施前后的效应进行评估,与上文提到的预测评估具有异曲同工之处。卢卡斯(Lucas,1976)曾指出,利用一个内在一致的框架来评估政策变动有很多令人信服的原因。因此,可以利用这种分析框架探究政策的边际与平均效应。另外,如果对政策的非边际与一般均衡效应感兴趣的时候,结构化方法尤其有用。

表5 处理效应的主要估计方法及其应用

方法适用范围具体的应用代表文献断点回归作为一种实证研宄方法,断点回归的应用需要两个主要前提。首先,研究者需要知道选择进入处理的规则,且在处理是如何被分配的过程中存在断点。第二个前提是个体不能超过选择临界点进行分类。断点回归主要由“精确”断点回归设计(sharpRDdesign)和模糊断点回归设计(fuzzyRDciesign)在城市经济中有很多应用断点回归的例子,如研究地方政治、空气质量、教育支出、学校质量、土地利用管制、公共财政、住房等领域获得了广泛的应用Black,1999;Chay和Green⁃stone,2005;Pence,2006;Ferreira和Gyourko,2009;Saez,2010;Chetty等,2011;CardDavid和Weber,2012;Best和Kleven,2014;DeFusco和Paciorek,2014
注:本表格根据相关的文献整理而得。
五、国外区域和城市经济学实证研究的趋势及对中国的启示
区域和城市经济学与主流经济学的主要区别在于将空间因素纳入经济分析中。即其主要致力于解释各种经济要素在空间上的配置现象以及地理空间的内在本质和复杂空间经济系统的时空演化等(郝寿义等,2017)。然而,如何识别区域和城市经济现象之间的因果关系或空间相互依赖、相互作用关系,需要通过运用实证研究方法和技术工具构建能够引入、识别和检验空间因素的实证模型来实现。国外区域和城市经济学实证研究已经形成了相对完善的实证研究理论与方法体系,能够更为准确的解释经济活动非均匀分布,分析经济主体分布不平衡的结果和空间经济的效率。此外,基于实证模型对空间经济依赖或因果关系的检验,国外区域和城市经济学逐渐重视对政策的评估;其重点在于分析区域政策如何影响经济活动的空间分布,以及应该制定什么样的政策促进经济活动空间布局的合理性,促进资源在空间上的合理配置,实现财富与社会福利的持续增长,解决空间效率与公平不平衡等问题,这也增强了实证研究的应用性。
根据以上研究,国外区域和城市经济学实证研究获得了快速发展,构建了比较完整的实证研究体系,如图4。这对我国的区域和城市经济研究具有重要的启示。具体而言,表现在以下几个方面。
第一,区域和城市经济学实证研究主要借鉴传统计量经济学的研究,并与统计学、物理学、地理学、社会学、政治经济学等学科的关系日益紧密,多学科的交叉属性越来越明显。如关于邻里效应与网络效应的研究,将空间划分为地理空间与社会空间,把更多的空间因素纳入模型分析中,这样能够更加完美的拟合空间数据的特征;同时借鉴生物学的随机试验、随机田野试验等方法对政策和项目进行评估,较好地估测了政策的处理效应。因此,我国区域和城市经济学的研究要注重打破学科之间的界限,充分借鉴其他学科的先进研究方法,并结合区域和城市经济学的现实状况,研究出能够解释我国区域和城市经济活动空间分布的前沿的理论与方法。
第二,国外区域和城市经济学实证研究的数据描述、模型估计与检验等方法与工具不断得到提升。空间数据不仅仅局限于横向的地区或区域间的加总数据的分析,更加注重对纵向的微观的个体(具有区位特征的企业或者个人)的异质性数据的分析。通过专业的数据探索性分析软件,如Arcgis软件、ENVI软件等,构建专门的统计指标来描述空间经济活动的实际状况,分析变量之间的相关关系,如通过Moran’s I来度量空间相关性,可以对数据的特征进行可视化。此外,国外区域和城市经济学一直在对空间模型的校正和估计做出尝试,空间模型也从最初的空间截面模型延伸到空间面板模型——空间静态面板和空间动态面板模型,较为成功的将时空维度引入模型中,打破了维度的魔咒。相应的是估计与检验方法的完善,近年来非参数或半参数估计方法被广泛的运用于模型的估计。这启示我国的区域和城市经济研究要在空间数据特征挖掘与描述的基础上,更要注重对有关基本的空间过程模型的进行校正和估计,重视方法论的创新,进而形成严谨且完善的计量经济学的方法体系,而不是简单将国外的空间模型应用于国内空间经济活动的分析。
第三,区域和城市经济学实证研究注重对空间概念的研究,一直强调对空间自回归和分布滞后特征的分析,并不断地细分空间交互影响的来源。早在1981年,海宁就区分了两个层次的空间概念,即空间过程和空间模式,前者是指作为随时间的状态变动链条的,控制系统时间轨迹的法则;后者是基本空间过程的某个阶段的具体映像。在这种具体映像过程中,能够发现数据的某些特征,且通过一定的统计分析技巧找到数据之间的因果关系。对于所感兴趣参数变量变异的来源的研究,在空间模型中即为如何引入具有空间交互影响的变量,这就需要从异质性、不稳定性和跨时间的状态依赖性等方面进行全面的分析。相比于我国区域和城市经济学实证研究,很少有文献能够对空间模型变量的选择进行详细的论证,这需要进一步的改进。在未来的研究中注重模型估计和解释的基础上,更要注重对空间自相关和分布滞后因素的概念的区分,尽可能的完善空间模型的变量信息。

图4 20世纪70年代以来区域和城市经济学实证研究的演变注:本图由作者根据相关文献自己整理。
第四,模型的运用更加符合区域和城市经济研究的理论与现实需要,尤其是在预测与政策评估中获得重要的运用。如何构建并识别政策决定影响下的模型是区域城市计量经济学研究的重点,并开发出了包括随机近似法、联合方法等政策的模型评估方法。然而,实证证明,这些方法难以有效的对政策进行评估。近年来,随着研究方法的创新,随机试验方法成为政策或项目的评估的前沿理论方法,一些方法如双重差分法、三重差分法、倾向匹配得分方法和断点回归方法等被证明是进行处理效应估计的可靠方法,国外区域和城市经济学研究已经广泛地将这些方法应用到城市住房、教育、公共支出等领域的政策评估。但在我国,政策的评估更多依赖于构建指标体系,对于国外的先进理论的吸收与创新不足,这也导致了我国的政策评估研究相对稀少。因此,未来要在借鉴国外前沿研究方法的基础上,结合我国的具体实际情况,研究创新出一套适合我国政策评估的方法论体系。
[1]Cressie,N A. Statistics for Spatial Data[J].Terra Nova,1992,4(5):613-617.
[2]Diggle P J.Statistical Analysis of Spatial Point Patterns[M].New York:Oxford University Press, 2003.
[3]Getis A. The Analysis of Spatial Association by Use of Distance Statisics[J].Geographical Analysis, 2010,24(3):189-206.
[4]Moran P A P. Notes on Continuous Stochastic Phenomena”[J].Biometrika,1952,37 (1):17-23.
[5]Marcon E. Puech F. Evaluating the Geographic Concentration of Industries Using Distance-based methods[J].Journal of Economic Geography, 2003,4 (3):409-428.
[6]Kosfeld R, Eckey H, Lauridsen J. Spatial Point Pattern Analysis and Industry Concentration[J].Annals of Regional Science,2011,47(2):311-328.
[7]Ellison G, Glaeser E L,Kerr W R. What Causes Industry Agglomeration? Evidence from Coagglomeration Patterns[J].Amerrican Economic Review, 2010,100:1195-1213.
[8]Koch G G, P B Reinfurt D W. Linear Model Analysis of Categorical Data with Incomplete Reponse Vectors[J].Biometrics,1972,28:663-692.
[9]Andersson A E, Marksjo B. General Equilibrium Models for Allocation in Space under Interdependency and Increasing Returns to Scale[M].Regional and Urban Economics,1972,2(2):133-158.
[10]彼得·尼茨坎普. 区域和城市经济学手册(第1卷)区域经济学[M].安虎森等译.北京:经济科学出版社,2001.
[11]Nelder J A, Wedderburn R W M. Generalized Linear Model[J].Journal of the Royal Statistical Socoity A,1972,135:370-384.
[12]Batty M. Reilly’s Chsllenge New Laws of Retail Gravitation Which Define Systems of Centala Places[J]Enviroment and Planning A,1978,10(2):185-219.
[13]Angrist J,Pischke J S. Mostly Harmless Econometrics[M].Princeton: Princeton University Press, 2009.
[14]Anselin Spatial Econometrics:Methods and Models[M].Dordrecht: Kluwer Academic Publishers, 1988.
[15]Baltagi B H, Egger P, Pfaffermayr M. A Generalized Spatial Panel Data Model with Random Effects[J]. Econometric Reviews,2009,32(5-6):650-685.
[16]Elhorst J P. Specification and Estimation of Spatial Panel Data Models[J].International Regional Science Review,2003,26:244-268
[17]Duranton G, Overman H G. Testing for Localisation Using Micro Geographic Data[J]Review of Economic Studies, 2005,72(4):1077.
[18]埃德温·S·米尔斯. 区域和城市经济学手册(第2卷)城市经济学[M].郝寿义等译.北京:经济科学出版社,2003.
[19]保罗·切希尔. 区域和城市经济学手册(第3卷)应用城市经济学[M].安虎森等译.北京:经济科学出版社,2003.
[20]Kelejian H H, Robinson D P. A Suggested Method of Estimation for Spatial Interdependent Models with Autocorrelated Errors and an Application to a County Expendi Ture Model[J].Papers in Regional Science,1993, 72:297-312.
[21]Elhorst J P. Dynamic Spatial Panels:Models,Methods,and Inference[J].Journal of Geographical Systems,2002,14(1):5-28
[22]Ioannides Y. From Neighborhoods to Nations:The Economics of Social Interactions[M]. Amosterdam: Princeton University Press, 2013.
[23]Epple D. Romano R.E. Peer Effects in Education: A Survey of the Theory and Evidence[J].Handook of Social Economics, 2011,1:20.
[24]Graham D J. Agglomeration Productivity and Transport Investmen[J].Journal of Transport Economics And Policy, 2007,41 (3):317-343.
[25]Melo P C,Graham D J,Noland R A. Meta-analysis of Estimates of Urban Agglomeration Economies[J].Regional Science and Urban Economics, 2009,39(3):332-342.
[26]Liu X,Patacchini E,Zenou Y. Endogenous Peer Effects:Local Aggregate or Local Average[J].The Journal or Economic Behavio and Organization,2014,103:39-59.
[27]Haining R P. Intraregional Estimation of Central Place Population Parameter[J].Journal of Regional Science,1980:365-375.
[28]Manski C F. Identification of Endogenous Effects: the Reflection Problem[J]. Review of Economics, Studies,1993,60(3):531-542.
[29]约翰·弗农·亨德森,雅克-弗朗索瓦·蒂斯. 区域和城市经济学手册(第4卷)城市和地理[M].郝寿义等译.北京:经济科学出版社,2011.
[30]Duranton G, Henderson V j, Strange W C. Handbook of Regional and Urban Economics[M]. North-Holland,2015,5.
[31]Glaeser E, Glennerster R, Kremer M. Handbook of Development Economier, 2001, 4:3895-3962.
[32]Glaeser E, Mare D.Cities and Skills[J].Journal of Labor Economics,2001,19(2):316-342.
[33]郝寿义,马洪福. 国外区域和城市经济学研究及其对中国的启示[J]. 区域经济评论,2017(4):15-24.
猜你喜欢
社会科学战线(2022年8期)2022-10-25
小学生学习指导(高年级)(2021年4期)2021-04-29
小猕猴智力画刊(2020年12期)2021-01-07
河北理科教学研究(2020年2期)2020-09-11
炎黄地理(2019年1期)2019-09-10
英语文摘(2019年11期)2019-05-21
新高考·高二数学(2014年7期)2014-09-18
海峡姐妹(2014年2期)2014-02-27
科技传播(2011年8期)2011-08-15
小学教学参考(数学)(2006年7期)2006-12-31
