
基于多维特征的Android恶意应用检测系统
2018-02-28 02:51陈泽峰李抒霞
信息安全研究 2018年2期
陈泽峰 方 勇 刘 亮 左 政 李抒霞
1(四川大学信息安全研究所 成都 610065)2 (四川大学网络空间学院 成都 610065)
近年来随着移动设备的普及,Android系统市场占有率排名第一[1].与此同时,恶意应用程序数量持续增长,黑产已经利用移动病毒为多种业务服务[2].
当前针对Android恶意软件的检测方法分为静态分析检测和动态分析检测[3].结合机器学习技术和数据挖掘算法检测恶意软件被证明是可行且卓有成效的[4-5].基于动态执行特征的恶意软件检测方法,通过在沙箱中(应用程序可以安全监控的环境)运行应用程序提取运行时特征,其中存在2个主要问题:首先是需要的时间,分析每个应用需要10~15 min(取决于沙箱中触发的模拟事件数量),然而google play每个月超过6万个新增应用,使用这种检测方法无疑需要大量的开销;其次是代码覆盖率低,只能在分配的时间内发生,而且,最新的恶意软件可以通过在检测到当前执行环境是沙箱时隐藏恶意行为或结束进程.当前的恶意软件检测方法很大程度上依赖于研究者的认知来选定最终有效特征,并传递给机器学习模型作出预测.
基于以上研究,本文提出一种基于多个级别的不同分类器实现对未知样本快速和精确的检测方法.从apk文件中提取的多种类型的特征(例如权限、API调用),随着未知样本的增加,提取权限特征所需的时间比提取n-gram编码的操作码序列特征所需的时间大幅减少,尽管操作码序列更能反映应用的真实行为.并且单独对每个特征使用机器学习要比将其作为一个整体具有更好的检测效果.本文提出的方法仅当级别1分类器的置信度低于某一阈值时,才执行级别2的检测.实验表明级别2的访问频率只有10.4%.
1 研究现状
Zhang等人[6]提出了DroidSIFT检测系统,通过构建上下文API依赖图,提供恶意软件可能行为的抽象视图,并采用图相似性和机器学习来检测恶意应用程序.王聪等人[7]提出了基于权限关联特征的Android恶意软件静态检测技术,通过对提取的权限进行预处理,然后使用数据挖掘算法构造权限关联特征集.在最终形成的特征库中去除掉恶意软件中共存的频繁项集,使用贝叶斯分类器可以达到92.1%的准确率.Saracino等人[8]提出了一种基于宿主的恶意软件检测系统,该系统分为4个层次:内核层、应用层、用户层和软件包.通过动态分析提取系统调用、敏感API调用和和SMS之类的特征,同时通过静态分析提取权限、元数据和市场渠道等特征,并使用机器学习技术检测恶意软件.孙伟等人[9]提出一种重打包恶意软件静态检测方法,使用质心算法对应用之间的相似性进行检测,并使用数据挖掘算法进行恶意代码检测,并得出良好的检测效果.Yang等人[10]提出一种基于良性样本特征的恶意软件检测模型,首先使用Android 接口获取已安装软件的权限,去除冗余信息后量化为特征向量,最终反向生成恶意软件的特征向量,具有较高的检测率.Sato[11]提出了一种基于清单文件提供的信息(申请的权限和权限数量、应用程序名称、组件类别和优先级)来检测应用程序是否包含恶意行为,作者对365个样本的数据集进行了分类,得到了90%的检测率.Aafer等人[12]提出了一种DroidAPIMiner的分类模型,使用应用程序源代码中的API调用来确定应用程序是良性或恶意的.作者通过分析大量的恶意软件,从恶意软件中提取恶意代码序列.使用KNN分类器得到了99%的检测率.Arp等人[13]提出了名为Drebin的分类器,通过提取清单文件中申请的权限和申请权限相关的硬件(例如GPS、摄像头、麦克风),并使用SVM机器学习算法作为分类器,检测率达到了94%,每一次检测平均所需时间为10 s.Yerima等人[14]通过静态分析提取应用的权限特征,组件信息和API调用序列,并结合集成学习检测恶意软件,在2 925个恶意软件和3 938个良性软件的数据集上验证了方法的有效性.
2 特征提取
通过分析apk文件,提取多个独立的特征集用于静态分析.权限特征用于级别1,操作码特征用于级别2.
2.1 权 限
Android是一种特权分离的系统[15],对所有进程采用强制访问控制,这意味着除非明确授予特定权限,否则无法使用设备资源或组件.每个应用程序在Android系统中都有唯一的身份,其中包含用户ID和组ID.每个应用程序必须在清单文件中声明权限才能使用相应的API,申请的权限可以在清单文件中找到.同样地,通过分析代码中使用的API调用,提取出应用程序运行时所需的权限,这可以检测应用程序申请的权限和运行时权限的差异性,恶意应用能够通过漏洞进行root提权,可以达到读取通信录等隐私数据.使用PsCount[16]工具建立API调用和所需权限的详细映射.通过分析表明,多个权限组合可以在一定程度上反映恶意软件的行为.例如,READ_PHONE_STATE权限可以获取电话信息(IMEI),然后使用网络权限访问网络,将手机信息通过网络发送出去.申请权限特征集只考虑35个权限使用情况,特征值用二进制表示,如果应用包含某一个权限,对应的特征值为1,否则,对应的特征值为0.
2.2 n-gram操作码
目前n-gram编码常用于自然语言的自动分类.研究表明,使用n-gram生成的特征序列在恶意代码检测中也有不错的效果[17].通常Android应用程序包含清单文件、资源文件和可执行文件dex.使用apktool反汇编apk文件生成的每个smali文件表示一个独立的类,其中的每个方法都遵循一套标准的语法规范,每条指令由单个操作码和多个操作数组成.在特定n下,定义操作码特征向量〈V,N〉,V表示在所有smali文件中以类中的方法为单元,丢弃每条指令的操作数,保留指令的操作码,运用n-gram编码提取的操作码序列,N表示某一个操作码序列V的个数.根据n-gram编码提取操作码序列的流程如图1所示:
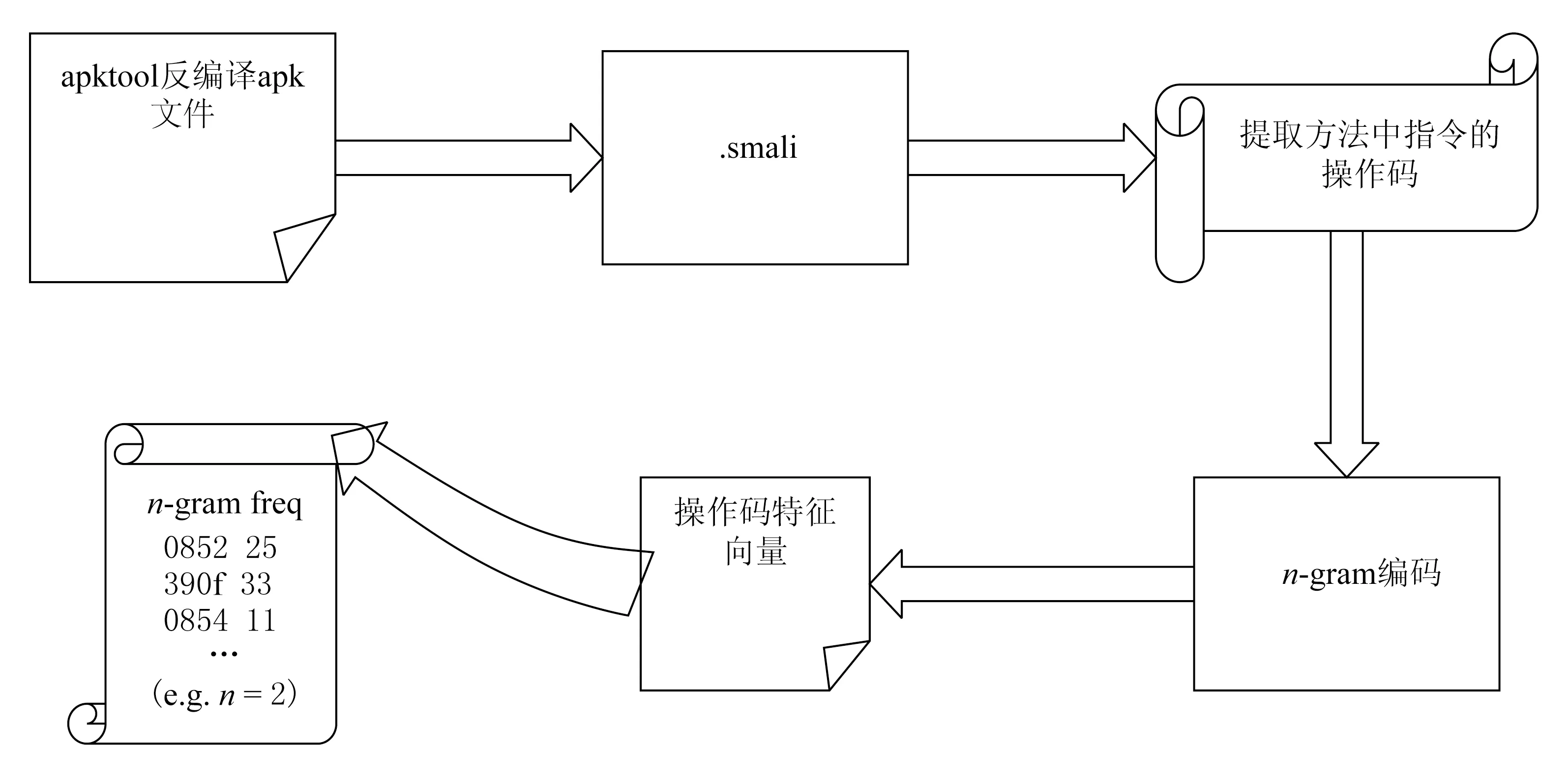
图1 n-gram操作码序列特征提取图
从dalvik字节码可以获得5个主要的操作码组:
1) move 指令集(0x01~0x1C);
2) 分支指令集 (0x27~0x3D);
3) getter 和setter 指令集 (0x44~0x6D);
4) 方法调用指令集(0x6E~0x78);
5) 逻辑和算术运算指令集 (0x7B~0xE2).
随着n的增长,操作码序列最终趋于稳定.原因有2个:1)某些方法中的指令数小于n,因此无法从这些方法中运用n-gram编码提取长度为n的操作码序列;2)较大的n可能产生较少数量的n-gram操作码序列,例如,具有8个指令的方法有7个2-gram操作码、6个3-gram操作码、5个4-gram操作码等.因此,方法的n-gram操作码序列数量与n呈反比.尽管运用n-gram编码提取的操作码序列的数量没有趋于指数增长,但是过多的操作码序列数量仍然会导致进一步处理过程中的巨大开销,解决方法将在系统设计中提到.
3 系统设计
本文提出的方法其目的是平衡精准度和系统开销,提供基于多级分类器的恶意软件检测方法,仅在级别1无法提供可靠的分类效果时才会考虑功能更强大的级别2,系统框架设计如图2所示.
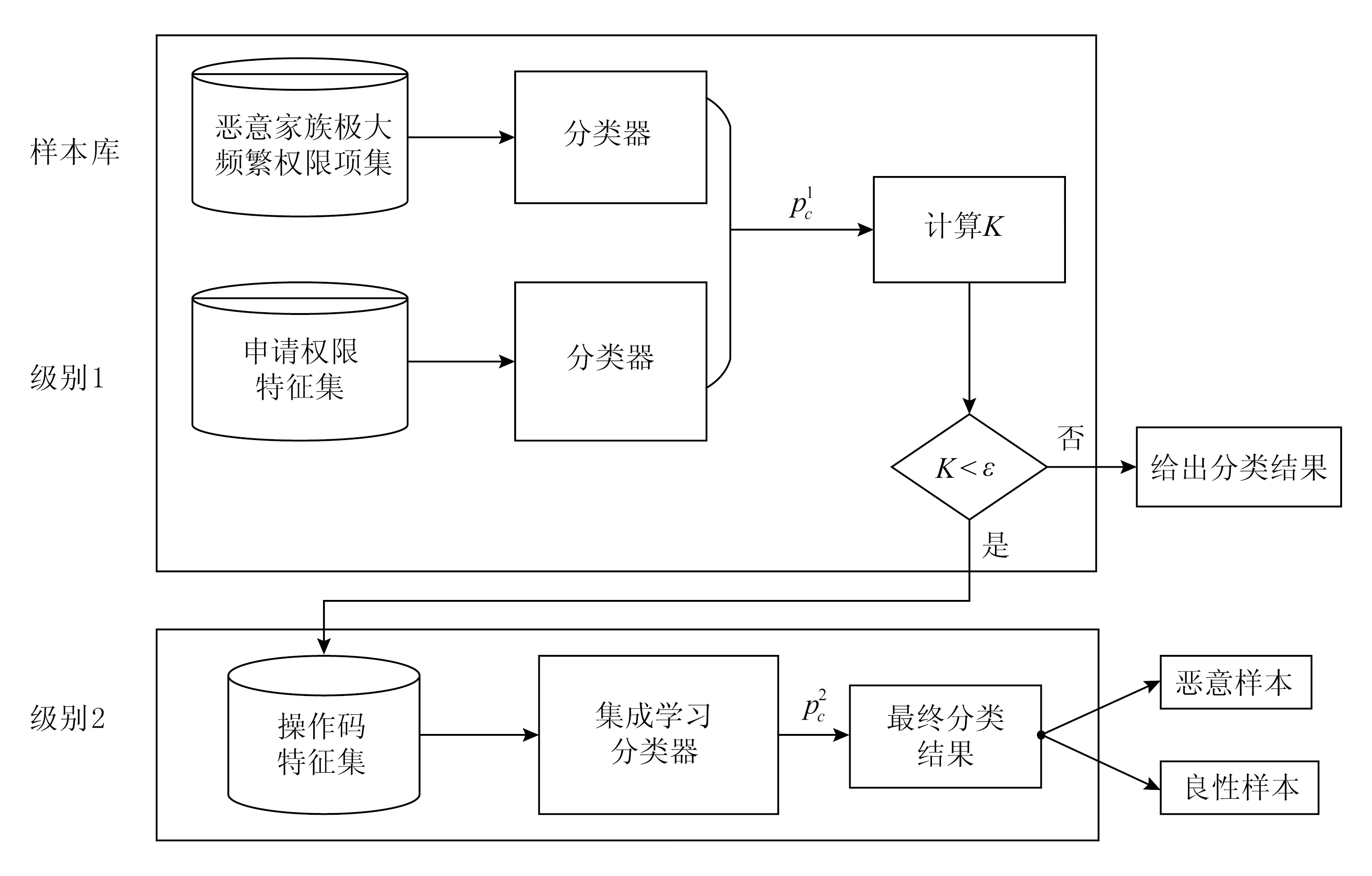
图2 多级分类器检测模型图
选定的单一特征对于所有类型的攻击描述不够精准,通过对多个独立性特征的分析可以获得良好的分类效果.本文方法包含2个部分:权限分类模块和操作码分类模块.整个检测框架如图2所示.给定算法分类器集合L={C1,C2,…,Cn},将可以快速分类的C放在框架中的级别1.在框架的第1层,生成未知样本的申请权限特征向量和运行时权限特征向量,基于2种特征向量使用C分类器,检测出恶意样本的概率分别为Pr和Pu.由于一些权限同时出现在申请权限和运行时权限中,为了能够更好地利用申请权限和运行时权限,提高级别1的分类精度,定义恶意软件检测率Pc如下:
为了量化概率在类之间传播的程度,使用文献[18]中定义的旁瓣比,比率定义为
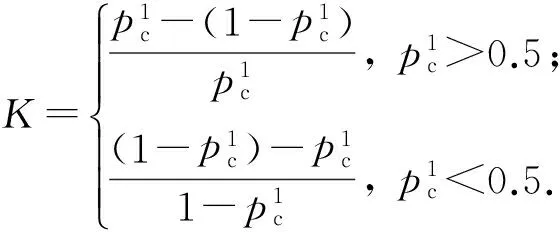
当一个类的预测概率高时,K接近于1,反之,则接近于0.如果K>ε,其中ε是通过实验分析得到的阈值,则根据级别1的检测结果作为恶意软件正确分类的概率,此时样本被正确分类的概率较高.如果K<ε,将考虑使用功能更强大的级别2来检测未知样本.而级别2提取基于n-gram编码的操作码序列,并使用集成学习得出结果所需的时间远高于基于权限得出结果所需的时间.因此,控制使用级别2的次数应该是有限的.
3.1 运行时权限关联特征挖掘
Apriori算法使用一种逐层搜索的迭代方法,通过迭代生成频繁项集并最终发现强关联规则,其中产生频繁项集的过程是由连接步和剪枝步组成[19].基于Apripri算法挖掘频繁项集,并在数据挖掘过程中加入家族的概念,挖掘出恶意家族的典型序列而不是所有恶意软件的典型序列,进行Android未知软件的恶意行为检测.基本思路是,对恶意家族的运行时权限进行提取,删除所有恶意软件很少使用的运行时权限,形成事务数据库,然后使用Apriori算法得出恶意家族的极大频繁权限项集.以此构建恶意家族运行时权限特征库.
算法的描述如下:
1) 提取恶意家族中所有恶意样本都必需的运行时权限,加入恶意家族的极大频繁项集中.
2) 删除所有样本都出现的运行时权限.
3) 删除所有样本很少使用的运行时权限.
4) 使用Apriori算法计算极大频繁项集.
5) 在得到恶意家族的运行时权限特征库后,删除每个恶意家族中都会出现的权限特征.
算法的伪代码如下:
输入:
Di←{恶意家族的运行时权限事务数据库};
min_sup←{ 最小支持度阈值};
输出:
事务数据库的极大频繁权限项集;
Lm←{ 恶意家族的事务数据库};
Lm←Library_gen(D,min_sup).*生成恶意家族的权限特征库*
方法:
for (i=1;i<=49;i++){
Lappend=select_common_per(Di);*提取所有样本都必需的运行时权限项集*
Di=delete_common_per(Di);*删除所有样本都必需的运行时权限*
Di=delete_little(Di);*删除所有样本极少使用的运行时权限*
Lk=Library_gen(D,min_sup);*生成k项集*
添加Lappend到Lk项集;
添加Lk项集到特征库;
}
procedureLibrary_gen(D,min_sup); {
…
…
end procedure
3.2 操作码特征筛选
由于运用n-gram编码提取的操作码序列数量过多,很难在原始数据上直接运用机器学习算法.解决方案是使用信息增益计算每个特征的排名,过滤掉排名靠后的不太重要的特征.
熵在信息论中是随机变量不确定性的度量.变量X的熵定义如下:
H(X)=-∑p(xi)lbp(xi),
并且定义在确定Y的条件下X的条件熵,其中p(xi)是变量X某一取值的概率,p(xi|yi)是在观察到Y值下X的条件概率.
H(X|Y)=-∑p(yi)∑p(xi|yi)lbp(xi|yi).
X的条件熵定义为待分类的集合的熵和选定某个特征的条件熵之差称为信息增益(Quinlan,1993),定义如下:
Gain(X|Y)=H(X)-H(X|Y).
根据信息增益,如果IG(X|Y)>IG(X|Z),则特征Y相对特征Z而言,将被视为集合X更好的特征.通过信息增益对n-gram编码提取的操作码序列进行排名,并选择较高排名的特征.
为了计算信息增益,使用WEKA中的信息增益的实现.但是该程序无法处理大量的操作码序列输入,并且经常遇到内存不足的问题.由于信息增益算法单独计算每个特征的得分,将数据集分割成较小的几个块,分别计算块中的每个特征的信息增益,最终将结果结合在一起.
4 实验结果
本文使用的实验样本有2 520个,其中49个恶意家族样本由文献[20]提供,良性样本均来自Google官方下载并且经过VirusTotal分析,具有较高的可信度.使用apktool得到反汇编代码,PsCount获取API调用和所需权限的映射.从清单文件中提取申请权限,反汇编代码提取n-gram编码的操作码序列.所有的实验都是在Windows机器上执行的,在实验中,使用10倍交叉验证技术来测量分类器性能,从正确率、召回率、分类精度(ACC)、AUC(ROC曲线面积)等评价指标进行对比.
在实验的第1部分,对特征集使用不同类型的分类器:朴素贝叶斯、J48、KNN.在第2级,使用一个强大的分类器(如Adaboost和随机森林)进行更可靠的分类.表1显示了对于未知样本只使用级别1的检测结果.可以看出,J48,KNN和逻辑回归给出了较好的分类效果,证明本文提出的申请权限和运行时权限相结合,并利用机器学习的检测方法是可行的.特别地,在使用级别1对Droid Kung Fu2,Droid Kung Fu3家族的恶意样本检测率能够达到90%,尽管Droid Kung Fu恶意家族通过native代码获取更高权限.
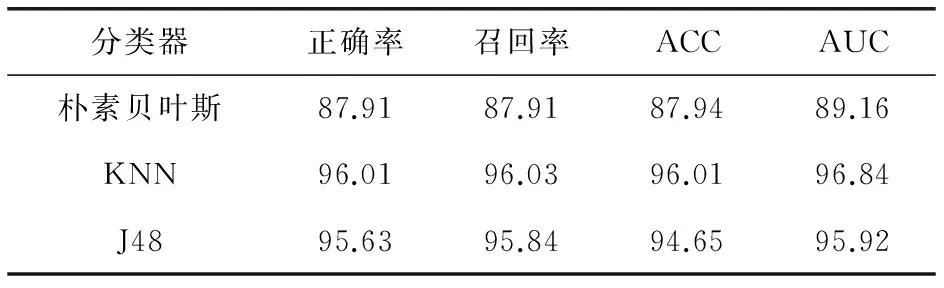
表1 级别1使用不同分类器检测结果对比 %
由于阈值用来平衡正确率和级别2访问频率,阈值取值过大会降低恶意软件的漏报,阈值取值过小会增大级别2的访问频率,增加系统开销.经过多次实验,阈值=0.75时,利用多级分类器检测系统的检测结果可以观察到,结合J48和随机森林算法给出了良好的性能,级别2的访问频率接近10%.同时提高了整体的正确率和AUC面积.
在计算n=5的操作码序列的信息增益实验中,发现大多数操作码序列只会在良性样本中出现.这表明仅仅出现在良性样本中的操作码序列对于恶意软件检测非常重要.进一步可以发现,3个4-gram编码的操作码序列(“08546e0c”,“08546e0a”,“3808546e”)和3个5-gram编码的操作码序列(“0c08546e0c”,“08546e0854”,“08546e0c08”)是3-gram编码的操作码序列“08546e”的扩展,这种扩展只会发生在良性样本中,预测在未来的研究中不同长度的操作码序列将会用于机器学习分类.
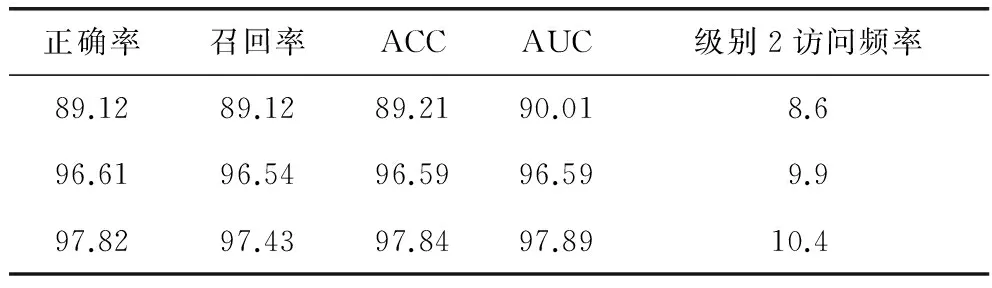
表2 多级模型的检测结果 %
考虑级别1和级别2使用的分类器时,计算了在各种分类模型中检测样本的建模和预测总时间,在级别1,选择简单分类器,同时在级别2使用集成学习检测模型,从而得到精准度更高的分类.表3给出了n=5时,单独使用级别1和级别2得出检测结果需要的时间.如果级别2访问次数减少,同时精准度不受很大影响,相对于多个特征同时作为机器学习的输入,可以提高分类模型的检测效率.

表3 单独使用级别1和级别2的检测时间
5 结束语
本文提出了一种多维特征协作的轻量级Android恶意软件检测方法,使用多个级别的不同分类器实现对未知样本的快速和精确的检测.文中使用到了应用的申请权限、运行时权限、操作码序列多个特征用作机器学习的训练模型和检测模型.级别1对于单独使用申请权限和运行时权限相结合的方法检测未知样本的效果有所提高,级别2使用n-gram编码的操作码序列作为机器学习的特征集,在级别1无法提供可靠的检测时,使用更能反映应用运行时行为的操作码序列并结合集成学习获得了较高的检测率.与以往静态检测使用API调用、组件间调用、权限等其他应用属性特征组合使用机器学习不同,通过只提取操作码和使用信息增益算法过滤掉不太重要的特征,进一步减小开销,如非必要,将不会使用到级别2.以高精度和低成本建立分类检测系统,平衡成本与精确度的冲突.后续的工作将会继续完善和设计基于多维特征的Android恶意软件检测系统,并且在此基础上能够分类未知样本所属的恶意家族.
[1]Alibaba. 2016 Security report[EB/OL]. (2017-03-09). [2017-12-15]. https://jaq.alibaba.com
[2]Concert/CC. China’s Internet Network Security Report[R]. Beijiing: Post & Telecom Press, 2016: 130-150
[3]朱佳伟, 喻梁文, 关志, 等. Android权限机制安全研究综述[J]. 计算机应用研究, 2015, 32(10): 2881-2885
[4]Amos B, Turner H, White J. Applying machine learning classifiers to dynamic Android malware detection at scale[C] //Proc of the 9th Int Wireless Communications and Mobile Computing Conf (IWCMC). Piscataway, NJ: IEEE, 2013: 1666-1671
[5]Yang T, Qian K, Li L, et al. Static mining and dynamic taint for mobile security threats analysis[C] //Proc of IEEE Int Conf on Smart Cloud (SmartCloud). Piscataway, NJ: IEEE, 2016: 234-240
[6]Zhang M, Duan Y, Yin H, et al. Semantics-aware Android malware classification using weighted contextual api dependency graphs[C] //Proc of the 2014 ACM SIGSAC Conf on Computer and Communications Security. New York: ACM, 2014: 1105-1116
[7]王聪, 张仁斌, 李钢. 基于关联特征的贝叶斯Android恶意程序检测技术[J]. 计算机应用与软件, 2017, 34(1): 286-292
[8]Saracino A, Sgandurra D, Dini G, et al. Madam: Effective and efficient behavior-based Android malware detection and prevention[J]. IEEE Trans on Dependable and Secure Computing, 2016, (99): 1-1
[9]孙伟, 孙雅杰, 夏孟友. 一种静态Android重打包恶意应用检测方法[J]. 信息安全研究, 2017, 3(8): 692-700
[10]Yang T, Qian K, Li L, et al. Static mining and dynamic taint for mobile security threats analysis[C]//Proc of IEEE Int Conf on Smart Cloud (SmartCloud). Piscataway, NJ: IEEE, 2016: 234-240
[11]Sato. 基于良性样本的Android系统恶意软件检测[J]. 计算机工程与设计, 2016, 37(5): 1191-1195
[12]Aafer Y, Du W, Yin H. Droidapiminer: Mining API-level features for robust malware detection in Android[C] //Proc of Int Conf on Security and Privacy in Communication Systems. Berlin: Springer, 2013: 86-103
[13]Arp D, Spreitzenbarth M, Hubner M, et al. DREBIN: Effective and explainable detection of Android malware in your pocket[C] //Proc of the Annual Symp on Network and Distributed System Security. Chicago: NDSS. 2014
[14]Yerima S Y, Sezer S, Muttik I. High accuracy Android malware detection using ensemble learning[J]. IET Information Security, 2015, 9(6): 313-320
[15]Martinelli F, Mori P, Saracino A. Enhancing Android permission through usage control: A byod use-case[C] //Proc of the 31st Annual ACM Symposium on Applied Computing. New York: ACM, 2016: 2049-2056
[16]Au K W Y, Zhou Y F, Huang Z, et al. Pscout: Analyzing the Android permission specification[C] //Proc of the 2012 ACM Conf on Computer and Communications Security. New York: ACM, 2012: 217-228
[17]陈铁明, 杨益敏, 陈波. Maldetect: 基于Dalvik指令抽象的Android恶意代码检测系统[J]. 计算机研究与发展, 2016, 53(10): 2299-2306
[18]Mithun N C, Rashid N U, Rahman S M M. Detection and classification of vehicles from video using multiple time-
spatial images[J]. IEEE Trans on Intelligent Transportation Systems, 2012, 13(3): 1215-1225
[19]Han Jiawei, Kamber M, Pei Jian. 数据挖掘: 概念与技术[M]. 北京: 机械工业出版社, 2012: 181-185
[20]Zhou Y, Jiang X. Dissecting Android malware: Characterization and evolution[C] //Proc of 2012 IEEE Symp on Security and Privacy (SP). Piscataway, NJ: IEEE, 2012: 95-109
猜你喜欢
晚晴(2018年3期)2018-12-06
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
电子技术与软件工程(2017年14期)2017-09-08
计算机技术与发展(2017年8期)2017-09-01
计算机应用(2017年4期)2017-06-27
中学生(2017年13期)2017-06-15
航天返回与遥感(2014年5期)2014-07-31
