
阅读理解答案预测
2018-01-02 06:53李茹马淑晖张虎郭少茹
山西大学学报(自然科学版) 2017年4期
李茹,马淑晖,张虎,郭少茹
(1.山西大学 计算机与信息技术学院,太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006)
阅读理解答案预测
李茹1,2,马淑晖1*,张虎1,郭少茹1
(1.山西大学 计算机与信息技术学院,太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006)
针对高考语文阅读理解,文章通过对题干、篇章句子片段、选项三者的关系进行建模,提出一种基于题干与选项一致性判别模型的阅读理解答案预测方法。模型由篇章句子与题干的相关度和对选项的支持度进行选项置信度度量,并基于这两个度量定义了联合打分函数。其中相关度通过题干定位到的原文出处与句子片段的距离来度量,支持度通过句子相似度特征、反义匹配特征、否定特征三个语义特征来度量。同时,在近10年的高考真题和模拟题中分别进行了三组实验,实验结果给出了该方法在不同特征组合和参数设置上的答题效果。
高考语文;阅读理解;选项和题干一致性
0 引言
近年来,阅读理解受到国际与国内自然语言处理研究领域学者的广泛关注,并成为人工智能领域的一项重要研究。高考阅读理解是高考语文试卷中的一类重要试题,是863“类人智能”答题项目中的一项研究内容,其与传统基于构建语料库的阅读理解相比,具有更高层次的挑战。高考阅读理解任务答案生成的主要知识包含在篇章中,因此要正确解答阅读理解问题,必须对文章内容和问题有更深入的理解和分析。
目前,基于阅读理解的智能系统在国外已取得了长足的发展。2011年,IBM的沃森(Watson)在答题竞赛类节目《危险边缘》中战胜了该节目中最杰出的两位人类选手[1]。苹果公司的“Siri”智能助手能够理解人们通过自然语言提出的问题。2015年,日本国立情报学研究所(National Institute of Informatics)开发的机器人Todai在日本高考中取得511分的成绩,比平均分数线高出90多分。上述系统多是在问题分析和答案抽取上进行一些研究工作,但高考阅读理解的问题分析和求解过程会难度更大,不仅要对问题进行分析和答案抽取,而且需要对文本进行深层语义理解和知识推理。
在阅读理解技术的研究方面,国外学者采用许多不同的方法。1999年,Hirschman[2]团队首先开始了阅读理解任务的研究,并首次运用Hum-Sent准确率作为评价标准,利用词袋模型在60个篇章的测试集上进行实验,最终获得了36.3%的Hum-Sent准确率。在2004年美国学者Charniak E[3]针对儿童故事的问题,建立了一种关联模型,该模型通过建立故事和世界知识的联系来回答问题,并且试图通过模型生成与故事相关的问题。Richardson[4]等用改进的词袋模型在MCTest数据集上取得66.25%的准确率。Narasimhan[5]等提出一种联合概率模型,模型中加入篇章关系特征使结果较前人有显著提高。Sachan[6]等提出一种答案蕴含结构,用修改后的SVM模型(LSSVM)进行候选句选取和参数训练,最终实现答案预测。Iyyer[7]等提出深度学习的方法,将阅读理解任务看作是分类问题,运用递归神经网络(RNN)学习句子的向量表示,用逻辑回归分类器对篇章预测类别,类别标签就是问题的答案。Berant[8]等提出一种结构分析方法,分别构造材料中句子以及选项的实体关系图,实现从篇章句子到答案的推理。以上方法均是在英文语料和数据集上进行研究和测试,多为人工构建,其难度及复杂度不高。本文立足于高考语文,结合中文自然语言的特征,对汉语高考语文的自动答题进行探索性研究。
高考语文阅读理解常见的形式有问答题和选择题。综合分析选择题的题目设置特点,将选择题类型划分为五种,分别为“文意理解”、“观点支持”、“拟写标题”、“指代消解”和“补写句子”。本文主要研究选择题中的观点支持类题型,在近五年北京高考阅读理解选择题中该类题型约占31%。题型如图1所示。该题型与其它类型选择题的主要区别是题干中包含与篇章文本相关的句子,如图1中题干信息包含的“昆虫的翅膀是一个工程学奇迹”就是篇章文本中出现过的句子。

Fig.1 2013 Beijing college entrance examination sample show about Point of view support multiple choice questions (The italicized black option is the correct answer)
图1 北京2013高考题中观点支持类选择题样题示例(斜体选项是正确答案)
本文提出一种无监督的选项和题干一致性的答案预测模型,用带隐含变量的判别式框架来捕获篇章句子、题干、选项三者之间隐藏的关系。同时将方法在历年高考真题和模拟题上进行了多次实验,并采用平均准确率得分(AAS)指标对模型进行评价。
1 题干结构化表示
阅读理解问题的正确解答建立在正确理解题干信息的基础之上。本文利用LTP句法分析器[9]进行题干句法分析,形成答题三元组
●V: 昆虫的翅膀是一个工程学奇迹
●D: false
●N: 1
题干分析得到的题干观点V是题干中与篇章相关的信息,但题干观点由有限几个词汇组合而成,其语义信息较少,所以我们基于同义词词林[10]对观点词汇进行了扩展,找到在语义层面上与观点词汇具有语义相关性的词汇加入到观点词汇集合中。同义词词林是五层结构,第四层和第五层分类更加细致[11],可以为词汇扩展任务提供支持。在同义词词林扩展版中检索观点词汇,取与其具有公共父节点的词作为扩展词汇。
2 选项和题干一致性模型
为了实现高考阅读理解问题的自动解答,我们提出一种无监督的答案预测模型,对篇章的题干、篇章句子片段进行建模。模型从两个层面对选项置信度进行度量。第一个层面,需要度量选项是否与题干观点相关,即选项与题干的相关度[5],以排除与题干无关联的选项。第二层面,需要度量选项是否与篇章语义层面保持一致,即篇章中的句子对选项的支持度。基于以上两个层面的度量定义联合打分函数对选项置信度进行打分,预测得分最高的选项为正确答案。
2.1 模型定义
篇章句子作为中间桥梁,可以勾连题干、正确答案之间的关系。选项与题干观点的相关度和篇章文本对选项的支持度都是通过篇章句子来刻画的。我们用A表示选项集合,用D表示篇章中的句子集合。对于给定的选项ai∈A和题干观点v,定义了关于篇章中的单个句子sj∈D、选项和题干观点的联合打分函数:
score(ai,sj,v)=R(sj,v)+S(sj,ai)
(1)
其中,篇章句子sj是隐含变量。联合打分函数由两部分组成。其中R(sj,v)是单个句子与观点的相关度(Relevance Degree),反映的是句子与该题干观点的相关程度,相关程度越高,句子对于该题目越重要。S(sj,ai)是单个句子对于当前选项的支持度(Support Degree),反映的是句子对于选项的支持程度,支持程度越高,选项的正确度就越高。
用两个特征函数以及相对应的权重来分别刻画联合打分函数中的相关度函数和支持度函数:
R(sj,v)=θ1φ1(sj,v)
(2)
S(sj,ai)=θ2φ2(sj,ai)
(3)
其中,θ1和θ2是权重。φ1是相关度特征函数,φ1是支持度特征函数。具体的特征函数的计算方法将在2.2节和2.3节介绍。
根据公式(1),基于篇章中所有的句子对选项置信度进行打分,打分函数表示如下:
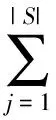
(4)
其中,S是篇章文本的所有句子集,|S|表示篇章中的句子总数。
最终,模型基于以下目标函数(公式5)预测答案:
(5)
其中,A是选项集合。
依据选项置信度得分对选项排序,按题目要求输出答案。
2.2 相关度特征函数(φ1)
高考阅读理解综合考察理解篇章句子,分析题目,综合梳理信息的能力。了解题目设置错误选项的方法,有助于掌握答题方法。命题者设置错误选项的方法有八种:以偏概全,张冠李戴,无中生有,曲解原意,强加因果,答非所问,偷换概念,改变性质[12]。其中与观点支持类选择题选项对错判断直接相关的设置错误选项的方法有“答非所问”、“无中生有”等,即选项与题干无关联通常是选项错误的一项重要原因。以2005年山东高考语文真题第7题为例进行说明,篇章标题为《你利用花,花也利用你》,文章从两方面对人类和花之间的利用关系进行阐述,其中题目信息如图2:

下列各句中,不属于“花也在利用你”的一项是A花卉可能利用了其能激发人积极的情感和其他深层心理变化这一影响来不断进化。B花可用来表达抚慰之情或柔情蜜意,也可用于恭喜庆贺或请求宽恕。C开花植物利用花儿给人带来的感情奖赏不断进化。D我们人类就是花卉进行繁衍战略的一部分。
Fig.2 2005 Shandong college entrance examination questions
图2 2005山东高考真题题目信息
经分析,A、C、D三选项是“花也利用你”主题的原文信息复述,而B是对“你利用花”主题的原文信息的复述。显然B与题干无任何关联,为正确答案。
针对这种问题,本文提出一种基于篇章句子的相关度计算方法来度量句子与题干观点的相关度。
相关度是一个模糊的概念,没有一个标准的定义和客观的标准可以衡量[13-14]。相关度一般用于信息检索中,用来描述文档和查询之间的相关程度[15]。本文相关度用来衡量篇章句子与题干观点的相关程度,相关度越高,篇章句子对于本题目越重要。而篇章中句子是题干观点和选项的中间件。这就从另一个角度反映了与篇章句子相关联的选项与观点的相关程度。
相关度计算的基础是对题干观点进行篇章原文出处定位,将定位到的原文出处句子表示为si。篇章中句子sj与题干观点v的相关度计算转化为篇章中句子与观点原文出处句子的相关度,如公式(6):
φ1(sj,v)=φ1(sj,sv)
(6)
篇章的组织结构一般是句子间空间距离越近,相关性越高。相邻的句子块表达相同的主题。简单的衡量句子相关性方法是通过篇章中句子的物理空间距离。这里的空间距离的概念是句子的相邻距离,如,篇章的第5句和第7句的距离是2,而第5句和第12句的距离是7,所以第7句与第5句的相关度一定比第12句与第5句的相关度高。基于此,本文将相关度函数定义为

(7)
其中,sj表示篇章中的句子,sv为题干观点定位到的原文出处句子,d(sj,sv)为句子距离函数,取值范围为(0,N)。N为篇章中的句子总数。这样定义函数,既保证了取值范围在(0,1)区间,又确保了句子物理距离越近相关度越高的设想。
2.3 支持度特征函数(φ2)
支持度特征反映的是篇章句子与选项之间的语义蕴含关系,篇章句子对选项的支持度越高,从篇章句子到选项的蕴含关系越强。本文从句子相似度、反义匹配、否定匹配三方面语义特征来刻画篇章句子对选项的支持度。
2.3.1 基于核心语义句子相似度
句子相似度计算是对句子间的相似性给出一个度量[16]。一般而言,两个句子的相似度越高,其相互支持的程度就越高,因此,本文利用句子相似度来度量句子与选项的相互支持度。词汇作为句子的最小意义单元,其相似度计算应作为句子相似度计算的基础。本文利用Hownet[17]语义资源,采用基于知网的词汇语义相似度计算[18]方法,计算词汇间的语义相似度,最终得到句子之间的语义相似度。
在句子相似度计算中,一些虚词、介词语义意义不大,因此在计算句子间相似度之前先提取句子语义核心词,将名词、形容词、动词、数词等实词作为句子的语义核心词汇。如高考语文中选项的句子片段“分布在鼻腔黏膜上”,提取得到的语义核心成分为“分布鼻腔黏膜”。如此将选项a和篇章中的句子s看作两个核心词汇集合,分别包含n和m个语义核心词汇。可以表示为:
a={Wa1,Wa2,…,Wan}s={Ws1,Ws2,…,Wsm}
经语义核心词汇提取之后,得到的是无序的词汇集合。但这些核心词汇对于选项的重要度是不相同的,本文基于词汇在篇章中出现频率为选项词汇赋予不同的权重。一般词汇在文中出现的次数越多,那么该词汇对于判断选项正确与否重要度就越低。如“分布鼻腔黏膜”中,“分布”和“鼻腔”在篇章中出现的次数要比“黏膜”多,“黏膜”对于篇章中别的词汇来说就比较稀缺,那么相对于另外两个词汇,“黏膜”对于选项来说其重要度是更高的,应赋予比较高的权值。基于以上分析,对选项中的语义核心词赋予不同的权值。本文参考Matthew et al.2013[4]中的反词频,将词汇的反词频作为词汇的权重。其中选项a第i个核心词汇的权重计算公式如下:
(8)
其中count(wai)为词汇Wai在篇章中出现的次数。
在此基础上,计算句子s与选项a的句子相似度sim(s,a),方法表示如下:
Step1: 核心词汇之间的语义相似度计算。从选项a中的核心词汇中选出一个词分别与篇章句子s中m个核心词汇计算语义相似度,循环直至a中词集为空。设选项a中第i个词汇和篇章句子s中第j个词汇之间的相似度记为sij。得到相似度矩阵为:
取选项a中第i个词汇与篇章句子s词汇集合的最大语义相似度为si=max(si1,si2,…,sim)。得到词汇语义相似度向量g=
Step2:基于公式(8)对选项a中的核心词汇进行权重计算。得到选项的权值向量ω=<ω1,ω2,…,ωn>。

表1 反义词对示例Table 1 Examples of antonyms
Step3: 求得选项和篇章句子的相似度,sim(a,s)=ωτg/n。
2.3.2 反义匹配
在真实的试题实例中也存在一些特殊现象,有些篇章中的句子和选项共同出现的词汇比较多,导致按上面的句子相似度计算方法得到的句子相似度比较高,但实际上两个句子中包含了一对反义词。Hownet[15]知识库在词汇相似度和相关度方面表现比较好的计算性能,但对于具有对义和反义的词汇之间的关系刻画比较不够准确。为此课题组从网站在线反义词查询(http:∥fyc.5156edu.com)以及新华反义词词典[19]中收集整理得到8 390多条反义词对,来捕获句子之间的反义词汇。表1给出收集到的反义词对列表实例。
当选项和篇章句子中有互为反义的句子存在,即使它们之间的句子相似度高,篇章句子对选项的支持度也是很低的。如选项句子片段为“在大众传播上微信的传播能力很强”,篇章中句子片段为“微信的大众传播能力较弱”。两个句子片段很多词汇重叠出现,其句子相似度很高,但发现因为有反义词对“强”和“弱”的出现,篇章句子对选项的支持度是很低的,换言之,篇章句子对选项是不支持的。
反义匹配特征主要针对与选项相似度最高的句子。当篇章中与选项相似度最高的句子与选项之间出现反义词对,就将句子对选项的支持度φ2置为0。否则φ2为句子与选项的2.3.1句子相似度。
2.3.3 否定匹配
当篇章句子或选项中出现否定词汇时,系统性能就会大大下降。例如,选项“昆虫翅膀柔软性可比碳纤维的复合材料”,篇章句子片段为“就连碳纤维复合材料都无法与昆虫的翅膀相比”。按本文句子相似度计算方法,该句子片段是篇章中与选项句子相似度最高的。但篇章句子中出现否定词汇“无法”,使语义和选项完全相反。我们使用简单的启发式方法来解决否定问题,通过规则匹配检测否定词汇的出现。课题组参考《现代汉语词典》[20],结合高考阅读理解的特点,收集整理了汉语中常用的否定词,得到30个否定词,见表2。本文定义的否定词是含有否定意味的词汇。其中有汉语中否定字“无”、“没”、“非”、“不”、“否”这样的否定词种子。也有基于这些否定词种子扩展得到的词汇,如“没有”、“无法”、“不能”等。

表2 高考阅读理解否定词表Table 2 College entrance examination reading comprehension negative vocabulary
否定匹配特征与反义匹配相似,也是针对篇章中与选项相似度最高的句子的。当篇章中与选项相似度最高的句子或选项其中一个包含否定词汇,另一个不包含,就将该句子对选项的支持度φ2置为0。否则φ2为句子与选项的2.3.1句子相似度。
3 实验及结果分析
3.1 实验数据及预处理
实验所用的高考语文阅读理解观点支持类题目来自于近10年各省市高考真题以及高考模拟题。根据题干答题要求选取“正确”(true)还是“不正确”(false)的答案,将数据集分成两类。针对False类型的题目,我们的模型转换预测规则,预测置信度得分最低的选项为正确答案。本文使用哈尔滨工业大学社会计算与信息检索研究中心的语言处理集成平台LTP[8]对篇章文本、题干信息、选项进行分词、词性标注以及句法分析预处理。
3.2 评价指标
本文使用平均准确率得分[5](average accuracy score AAS)对实验结果进行评价。计算公式如下:
(9)
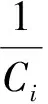
(10)
其中,|Q|为题目总数,si为第i个题目的准确率得分。Ci为系统预测的得分最高的选项集合,ai为正确答案。当集合Ci包含ai时,δ(Ci,ai)取值为1,否则δ(Ci,ai)为0。针对False类型题目,评分规则相反,Ci为系统预测的得分最低的选项集合。
3.3 确定本文的Baseline
为了验证基于选项与题干一致性模型的答案预测方法的有效性,实验将基于词袋模型[4](Bag of Word,BOW)的解答方法作为基准方法(Baseline),与本文方法进行比较。其算法如下。

算法:词袋模型Fori=1to4do S=Ai∪Q/U scorei=1λ∑j=1|s|count(wj); ∥wj为S中第j个词汇;∥count(Wj)为Wj在P中出现的次数∥1λ是正则化项EndforReturnscore1…4
形式化表示:P为篇章文本的词汇集合,Q为题干观点的词汇集合,A1…4为选项的词汇集合,停用词集为U。
根据算法得到选项的得分,进行排序,根据题目要求,True类型题目选取得分最高的为正确答案,False类型题目相反。
3.4 实验结果与分析
本文主要进行了三组实验:评估相关度和支持度的不同权值对结果的影响,获得最优的权值参数;验证不同的特征组合对结果的影响;比较两种模型的实验结果。
1)实验一:参数选择
实验比较了相关度权值θ1和支持度权值θ2对不同结果的影响。θ1和θ2的取值及其对应的实验结果如表3。

表3 不同权值的实验结果Table 3 Experimental results of different weights
表3显示,当θ1和θ2取值分别为0.6和0.4时,模型取得最好的结果,AAS达到39.19。AAS普遍较低,这不仅因为高考试题难度和复杂度较大,还因为高考真题与模拟题题目设置差异比较大,当使用最优的参数对,高考真题上的准确率为50%,而在模拟题中的准确率只有33%。
2)实验二:不同特征组合的实验比较
本文包含相关度特征和支持度特征。其中,相关度特征用句子距离来刻画,支持度特征用句子相似度、反义匹配、否定匹配三个特征来刻画。表4为不同特征的组合对实验结果的影响。
句子相似度特征作为基本特征,分别加入别的特征进行组合的实验结果显示,句子距离、反义匹配和否定匹配三种特征,其中的每一个特征的加入都有效提高了准确率。三个特征全部加入之后,准确率相比于只有句子相似度特征提高了18.39%,说明本文特征的合理性和有效性。

表4 不同特征组合的实验结果Table 4 Experimental results of different combinations of features
3)实验三:模型结果比较
本文提出的方法(option and question consistency model OQCM)与词袋模型(BOW)对比,准确率高出约5%(见表5)。相对于词袋模型只考虑词汇的表层特征,本文方法能够从句子语义角度,分析出篇章句子与选项之间的文本蕴含关系。

表5 两种模型实验结果Table 5 Two model experimental results
4 结论与展望
针对高考语文阅读理解中的观点支持类题型,通过分析考察高考语文阅读理解中篇章文本、题干信息和选项之间的关系,提出一种基于选项和题干一致性的建模方法。该方法从篇章句子片段与题干观点相关度和篇章句子对选项支持度两个维度进行建模,其中相关度特点用句子距离特征来刻画,支持度特征通过句子相似度、反义匹配、否定匹配三方面特征来描述,最终根据选项置信度得分对选项进行排序,预测正确答案。
针对高考阅读理解任务,接下来我们将融入句子的汉语框架语义[21]特征、语义依存句法特征和百科知识库等语义资源,进一步扩展题干信息和背景材料语义知识,改进模型中两个度量的定义,提升模型的平均准确率。
致谢:本文实验用到了哈尔滨工业大学信息检索研究中心的语言云平台;知网平台提供的词汇语义相似度计算工具,在此表示感谢!
[1] Ferrucci DA,Brown E W,Chu-Carvoll J,etal.Building Watson:An Overview of the DeepQA Project[J].ArtificialIntelligenceMagazine,2010,31(3):59-79.
[2] Hirschman L,Light M,Breck E,etal.Deep Read:A Reading Comprehension System[C]∥Meeting of the Association for Computational Linguistics,1999:325-332.DOI:10.3115/1034678.1034731.
[3] Charniak E.Toward a Model of Children′s Story Comprehension[D].Chicago:University of Chicago,1972.
[4] Richardson M,Burges C J C,Renshaw E.Mctest:A Challenge Dataset for the Open-domain Machine Comprehension of Text[C]∥EmpiricalMethodsinNaturalLanguageProcessing,2013:193-203.
[5] Narasimhan K,Barzilay R.Machine Comprehension with Discourse Relation[C]∥TheAssociationforComputationalLinguistics,2015:1253-1262.DOI:10.3115/v1/P15-1121.
[6] Sachan M,Dubey A K,Xing E,etal.Learning Answer-Entailing Structures for Machine Comprehension[C]∥TheAssociationforComputationalLinguistics,2015(1):239-249.DOI:10.3115/v1/p15-1024.
[7] Iyyer M,Boyd-Graber J,Claudino L,etal.A Neural Network for Factoid Question Answering over Paragraphs[C]∥EmpiricalMethodsinNaturalLanguageProcessing,2014:218-227.DOI:10.3115/v1/D14-1070.
[8] Berant J,Srikumar V,Chen P C,etal.Modeling Biological Processes for Reading Comprehension[D]∥EmpiricalMethodsinNaturalLanguageProcessing,2014:1499-1510.DOI:10.3115/v1/D14-1159.
[9] Liu T,Che W,Li Z.Language Technology Platform[J].ComputationalLinguistics,2010,2(6):13-16.
[10] 梅家驹,竺一鸣,高蕴琦,等.同义词词林[M].上海:上海辞书出版社,1993:106-108.
[11] 田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报,2010,28(6):602-608.DOI:10.3969/j.issn.1671-5896.2010.06.011.
[12] 教育部考试中心.高考文科试题分析[M].北京:高等教育出版社,2012.
[13] 许云,樊孝忠,张锋.基于知网的语义相似度计算[J].北京理工大学学报,2005,25(5):411-414.DOI:10.3969/j.issn.1001-0645.2005.05.009.
[14] 刘宏哲,须德.基于本体的语义相似度和相关度计算研究综述[J].计算机科学,2012,39(2):8-13.DOI:10.3969/j.issn.1002-137X.2012.02.002.
[15] 闫泼.信息检索中的排序与相关度计算研究[D].济南:山东大学硕士学位论文,2008.DOI:10.7666/d.y1349040.
[16] 李茹,王智强,李双红,等.基于框架语义分析的汉语句子相似度计算[J].计算机研究与发展,2013,50(8):1728-1736.
[17] 董振东,董强.“知网”[EB/OL].[2011-08-20].http:∥www.keenage.com.
[18] 刘群,李素建.基于《知网》的词汇语义相似度[J].中文计算语言学,2002,7(2):59-76.
[19] 商务印书馆辞书研究中心.新华反义词词典[M].北京:商务印书馆辞书研究中心,2011.
[20] 中国社会科学院语言研究所词典编辑室.现代汉语词典:第6版[M]. 北京:商务印书馆,2011.
[21] 李茹.汉语句子框架语义结构分析技术研究[D].太原:山西大学博士学位论文,2012.
AnswerPredictionofReadingComprehension
LI Ru1,2,MA Shuhui1*,ZHANG Hu1,GUO Shaoru1
(1.SchoolofComputer&InformationTechnology,ShanxiUniversity,Taiyuan030006,China;2.KeyLaboratoryofComputationIntelligence&ChineseInformationProcessing,ShanxiUniversity,Taiyuan030006,China)
For the Chinese reading comprehension of college entrance examination,this paper proposed a new method of Answer Prediction based on option-question consistency discriminative model, which jointly identifies the relation of a question, relevant sentences and the option. The model is based on the relevant degree between the text sentences and the question and the support degree between the sentences and the option, and then the united scoring function is defined with the two measures. In which the relevant degree is measured by the distance between the source sentence of the question and an text sentence, and the support degree is measured by three semantic features of sentence similarity,Antisense matching and negative matching. Moreover,three groups of experiments were conducted in nearly 10 years of college entrance examination questions and simulation questions,The experimental results are given to show the effect of this method on the combination of different features and the parameter setting.
Chinese college entrance examination;reading comprehension;option-question consistency
10.13451/j.cnki.shanxi.univ(nat.sci.).2017.04.014
2017-03-21;
2017-03-30
国家863计划(2015AA015407);国家自然科学基金(61373082,61502287);山西省科技基础条件平台建设项目(2014091004-0103);山西省回国留学人员科研资助项目(2013-015);中国民航大学信息安全测评中心开放课题基金(CAAC-ISECCA-201402);山西省高校科技创新项目(201505); 山西省高等学校科技创新项目(2015104)
李茹(1963-),女,博士,教授,主要研究方向:中文信息处理。E-mail:liru@sxu.edu.cn
*通讯作者:马淑晖(MA shuhui) ,E-mail:huihui387@sina.cn
TP391
A
0253-2395(2017)04-0763-08
猜你喜欢
发明与创新·小学生(2022年6期)2022-05-22
军营文化天地(2018年1期)2018-08-15
考试周刊(2017年16期)2017-12-12
时代英语·高一(2017年5期)2017-11-14
时代英语·高三(2017年4期)2017-08-11
时代英语·高一(2017年4期)2017-08-09
试题与研究·中考英语(2016年3期)2017-01-05
营销界(2015年22期)2015-02-28
甘肃教育(2014年17期)2014-09-11
清风(2014年10期)2014-09-08
