
基于改进聚类分裂的动态R*-树实现方法
2017-12-22 03:19彭召军
测绘工程 2017年3期
彭召军,熊 伟,柴 峥
(1.信息工程大学,河南 郑州 450001;2.61206部队,北京 100042)
基于改进聚类分裂的动态R*-树实现方法
彭召军1,熊 伟1,柴 峥2
(1.信息工程大学,河南 郑州 450001;2.61206部队,北京 100042)
在R*-树的构建过程中引入聚类技术能够有效地提高索引的性能,传统的k-means聚类算法对初始值非常敏感,聚类过程较为复杂。基于此,文中提出一种改进聚类分裂的动态R*-树实现方法,在节点分裂的过程中引进聚类技术,对R*-树的基本结构加以改进,从而获得动态的结构重组。实验表明,动态R*-树以略高的构建开销换取较高的查询效率,大幅度提高索引树的空间利用率,在批量数据动态加载和处理等方面具有较高的实用价值。
R*-树;聚类;节点分裂;空间利用率
R-树[1]作为一类平衡的多路查找树,具有自动平衡、空间利用率较高、便于外存存储等优点[2],广泛应用于大型的数据库系统中。随着索引空间维数的增加和索引数据量的增大,R-树中间节点目录矩形的覆盖与重叠迅速增加,严重影响R-树的查询性能[3]。R*-树[4]是R-树的一种变体,其综合考虑节点的覆盖、重叠以及目录矩形周长等参数优化插入和分裂算法,并通过引入强制重新插入技术使索引的检索性能和空间利用率都有较大的提升。文献[5]提出一种分割聚类的R-树结点分裂算法(C-Linear分裂算法),有效提高R-树的操作效率,但聚类分裂的过程较为复杂,分裂算法不易收敛。文献[6]中提出的LR-树,在确保索引查询性能的前提下,降低构建代价,并且大幅提高索引结构的空间利用率,但也同样存在聚类分裂过程复杂的问题。
随着“大数据”时代的到来,很多有关空间索引技术的研究重点关注R*-树的动态批量操作技术,这种技术能够有效地支持海量数据的高效处理(查询、插入、删除及更新)。由于数据在空间分布上常常具有“聚集”的特性,在R*-树的构建过程中引入聚类技术对数据集进行集簇划分,能够有效地减少节点之间的重叠与覆盖,优化R*-树的结构,大幅度提高索引的操作效率和性能[7]。基于批量动态加载空间数据的需求,本文在综合考虑节点的最小外接矩形(MBR)的形状、重叠率、面积以及周长等影响因素的基础上,通过改进R*-树的基本结构和分裂方式,实现一种基于改进聚类分裂的动态R*-树。实验证明,改进后的动态R*-树性能更优。
1 聚类算法
文献[8]中系统阐述常见的聚类技术。本文采用k-中心点轮换法[9],其时间复杂度为O(n2),n是对象的个数。在k-中心点轮换法中,优化目标函数的定义为
‖X-Vi‖p.
(1)
式中:E表示所有对象与其对应的簇中心之间偏差的总和;X是对象中心;Vi是簇Ci的平均值。k-中心点轮换法是一种使目标函数下降最快的方法,主要步骤为:
输入:簇的数目k,对象集S={S1,S2,…,Sn};
输出:k个簇,每个簇所包含的聚类对象集。
1)随机选择k个对象,作为每个簇的初始中心对象。在d维空间中,设一个类簇由M个矩形r1,r2,…,rM的对象中心[5],可以定义为
,
其中,(min_xij,max_xij),i∈(1,…,M),j∈(1,…,d)分别表示矩形的左下角和右上角坐标;
2)将剩余的每个对象分配给离它最近的对象中心所代表的簇,依据式(1)计算各个簇的目标函数值;
3)对于S={S1,S2,…,Sn}中的每一个对象Si(i=1,2,…,n),试图用当前对象Si依次替换已有的k个聚簇中的每一个对象中心Vi(i=1,2,…,k),通过计算替换后的目标函数值,最终选择使目标函数取得最小值的对象中心进行替换。如果替换后并没有获得更小的目标函数值,则不进行替换;
4)最终得到一个中心对象集合,根据这个集合按照最近邻原则将剩余所有对象分配到对应的簇中,所得到的k个簇是一个局部优化的聚类结果。
2 基于改进聚类分裂的动态R*-树
传统的R*-树的构造过程为:①找到待插入数据项的叶节点;②若叶节点未满,直接将数据项插入此叶节点,依次向上调整父节点的目录矩形;若叶节点已满,需要对叶节点进行分裂,同时进行“强制重新插入”操作。动态R*-树在传统R*-树的基础上,对R*-树的基本结构、插入算法和分裂算法进行改进。
2.1 动态R*-树的结构
在原有R*-树的基础上,动态R*-树对R*-树的基本结构做如下调整:①由于引入聚类算法进行节点分裂时可能存在R*-树节点不满的情况,动态R*-树的节点对数据项和索引项的填充个数的下限没有严格限制(R*-树要求至少有m个),这样做能够有效避免在空间上并不邻近的两个对象被分配到同一节点,造成索引树结构的恶化;②动态R*-树节点的数据结构中新增一个用于判断节点是否进行聚类分裂的标识m_bClusterNode,如果该节点已经参与聚类分裂,并且分裂后节点的数据项已经填充至少90%,则令m_bClusterNode=true。这样做的目的是避免已经达到局部最优的节点多次参与分裂,提高R*-树节点的空间利用率,从而提高聚类分裂的效率。
2.2 动态R*-树的构建
借鉴文献[6]中的R*-树构建算法,在插入数据项的过程中,当节点溢出时,并不像传统R*-树那样对节点立即进行分裂,而是将待插入的数据项插入到最合适的未满兄弟节点中,从而有效地减少分裂次数,提高节点的空间利用率,即动态R*-树的插入算法(R*-tree_Insert),输入:叶节点Leaf,数据项e;输出:无。具体步骤如下:
1)考虑目录矩形的重叠、目录矩形的面积等因素,利用FindLeaf函数找到适合插入的叶子节点Leaf;
2)如果Leaf未满,将数据项直接插入到Leaf中,返回;如果Leaf已满,在考虑目录矩形重叠、面积和周长等因素的基础上,找到Leaf的k个未满的兄弟节点;
3)如果k≠0,将数据项插入到kLeaf中,并返回;否则,从k个兄弟节点中找出标识符m_bClusterNode=false的m(m≤k)个兄弟节点,将Leaf与m个兄弟节点一起进行聚类分裂,从而达到数据项优化重组的目的。
2.3 聚类分裂技术
动态R*-树的构建过程中尽量避免节点分裂,避免索引树的整体结构恶化,采用聚类分裂技术将处于同一层级的多个兄弟节点进行聚类分裂,能够有效改善R*-树的结构,即叶子节点分裂算法(R*-tree_ClusterSplit),输入:叶节点Leaf及m个兄弟节点,数据项e;输出:m+1个或更多的节点。具体步骤如下:
1)确定初始中心对象。选取m+1或更多的初始聚类对象,在选取的过程中引入距离阈值(距离阈值一般可通过实验的方法得到)以避免陷入局部解,如图1所示。

(a)未引入距离阈值的聚类中心 (b)引入距离阈值的聚类中心图1 初始聚类中心
2)为聚簇分配元素。用k-中心点轮换法将剩余对象依次分配到各个聚簇中,具体过程见前文所述。
3)得到聚类分裂结果。新建一个叶子节点,将最后一个聚簇中的数据项放入此叶子节点中,同时更新Leaf及其m个兄弟节点的数据项。
对于不同的m值,k-中心点轮换法的聚类质量和稳定性比k-means算法要好很多。在索引树的构建过程中:①聚类分裂对R*-树的结构作最大限度的重组,优化了索引树的结构,减少节点的覆盖与重叠;②在叶子节点已满的情况下,将数据项插入到还未进行聚类分裂的未满兄弟节点中,减少分裂次数,提高R*-树的空间利用率。
假定总的数据项的个数为n,数据项维度为d,聚类分裂过程中的迭代次数为t,算法的时间代价主要包括3个方面:选择子树、插入数据项以及聚类分裂。聚类分裂过程的代价主要是R*-树节点的磁盘IO,分裂算法的时间复杂度为O(ndkt)。在实际过程中,分裂时的迭代次数t很小,且聚类分裂标识m_bClusterNode有效限制参与聚类分裂的邻近节点数量的增加,有效降低节点分裂的代价。
图2和图3分别为传统R*-树和改进后的动态R*-树的基本结构。由图可知,相比于传统的R*-树,改进后的动态R*-树具有更小的重叠率和更高的空间利用率,索引树的结构更为合理。
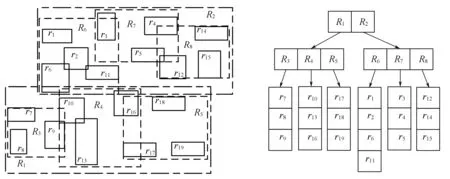
(a)平面示意图 (b)结构示意图图2 传统R*-树(最大度为5)

图3 改进后的动态R*-树(最大度为5)
综上,在数据集动态插入的过程中,对R*-树的基本结构加以调整,在节点分裂的过程中引入聚类分裂技术,能够最大限度地优化动态R*-树的结构。
3 实验与结论
为了评估动态R*-树的性能,将本文所构建的R*-树与传统的R-树、R*-树进行比较。在VS2010 C++环境下实现动态R*-树、传统R-树和R*-树的算法,实验的平台为Intel 2.59 G,内存8 G的华硕笔记本。
3.1 实验数据
为了使实验结果更具有代表性,实验中使用真实的全国导航图数据,利用导航图数据中具有代表性的4个数据集对3种典型的空间索引算法的性能进行测试。详细的数据集信息如表1所示。

表1 数据集信息详情
3.2 性能评估及分析
在实验中,页面大小设置为4 KB,索引树节点的最大度(MAXDEGREE)设为50,填充因子设为70%,分别对索引树的构造时间、查询时间、生成的索引文件大小和空间利用率进行评估,得到实验结果是多次测试结果的平均值,查询时间则是算法执行100次所用的全部时间。
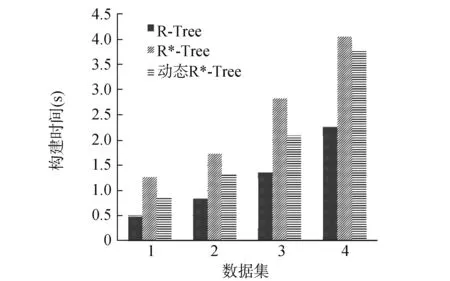
图4 不同索引树的构建时间

图5 不同索引树生成的索引文件大小

图6 不同索引树的查询时间

图7 不同索引树的平均节点访问次数(范围查询)
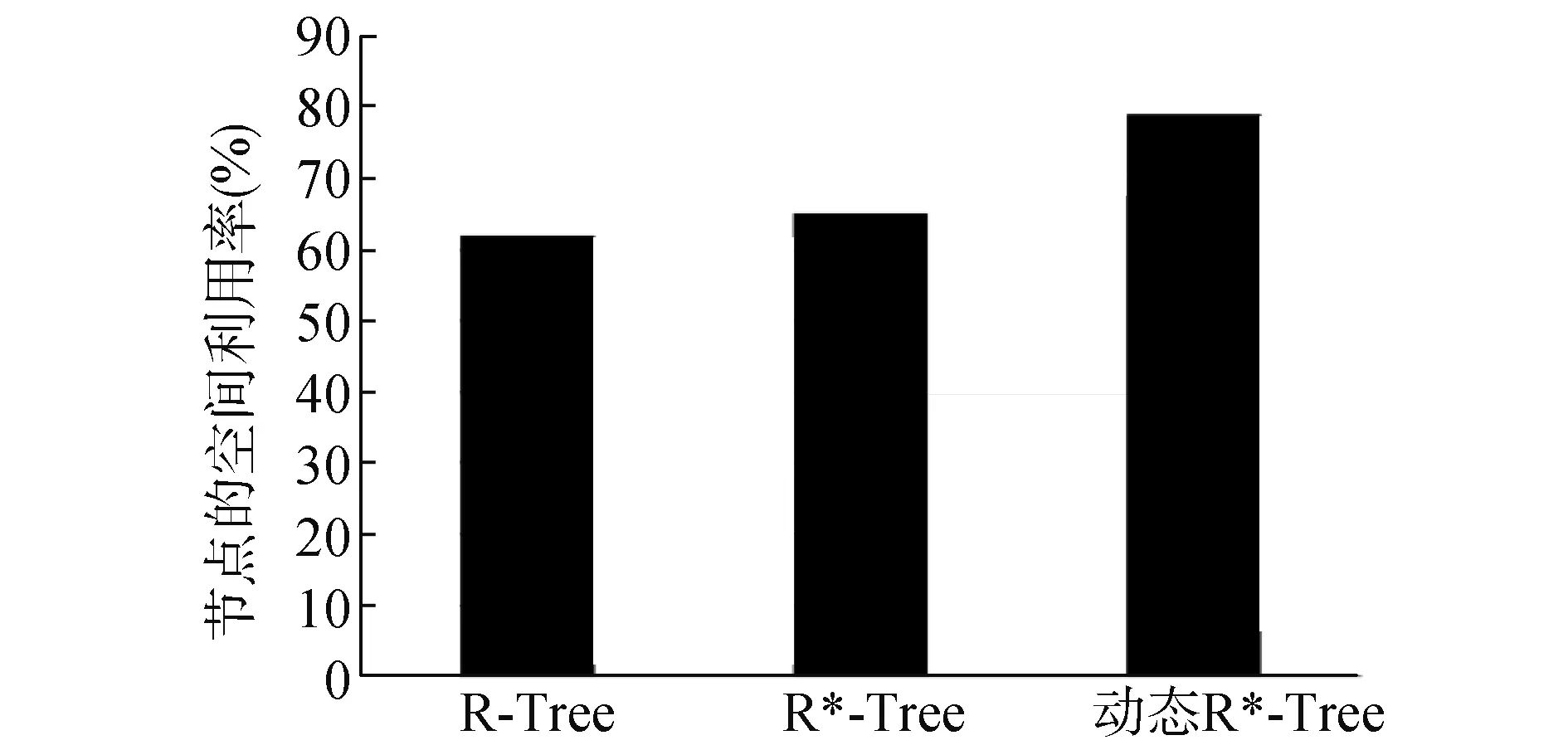
图8 不同索引树节点的空间利用率
图4所示为3种不同的索引树对于不同数据集的构建时间,可以看出,在3种索引树的构建过程中,时间消耗最少的是传统的R-树,而本文构建的动态R*-树的时间消耗比传统的R*-树要少。由图5可以得知,相比于其他两种索引树而言,动态R*-树构建完成后生成的索引文件要小,占用的空间更小。在查询(区域查询)性能上(见图6和图7),动态R*-树具有较为明显的优势,动态R*-树的查询时间较其他两种索引树明显要少,平均节点访问次数与传统R*-树相当,比传统R-树明显要少。如图8所示,动态R*-树的空间利用率得到提高,反复实验证明,动态R*-树的填充率约为79%,表明聚类分裂技术收到良好的效果。
综上所述,本文所构建的动态R*-树,以略高于传统R-树的构建代价,获得较高的查询性能和空间利用率。
4 结束语
在传统R*-树的基础上,本文对R*-树的基本结构进行改进,在节点的分裂过程中引进聚类技术对R*-树的整体结构进行动态重组,提出一种基于改进聚类分裂的动态R*-树实现方法。实验证明,动态R*-树以略高的构建开销换取较高的查询效率和空间利用率,在大批量数据动态处理等方面具有明显的优势。由于R*-树对目录矩形的重叠率、面积、周长以及目录矩形的形状等因素较为敏感,下一步仍需要研究如何利用多目标优化算法综合考虑这些影响因素,以期进一步提升动态R*-树的性能。
[1] GUTTMAN A. R-tree: A Dynamic Index Structure for Spatial Searching[C]. In Proc. of 20th Int. Conf. on Very Large Data Bases, Morgan Kaufmann, 1984.
[2] 郭菁, 郭薇, 胡志勇. 空间数据库索引技术[M]. 上海:上海交通大学出版社, 2006.
[3] 黄继先, 鲍光淑, 夏斌. 基于混合聚类算法的动态R-树[J].中南大学学报(自然科学版), 2006, 37(2): 365-370.
[4] BECKMANN N, KRIEGEL H P, SCHNIEIDE R, et al. The R*-tree: An Efficient and Robust Access Method for Points and Rectangles[C]. In: Proc. of ACM Intl. Conf. on the Management of Data(SIGMOD), 1990:322-331.
[5] 吴敏君,陈天滋.基于分割聚类技术的R-树结点分裂方案[J].计算机应用与软件,2007,24(10):42-44.
[6] 雷小锋, 谢昆青. 基于惰性聚类分裂的R-树实现方法[J]. 计算机科学, 2007, 34(4): 102-104.
[7] 吴钦阳. R*-树空间索引的改进[J]. 计算机应用, 2010, 30(2):419-422.
[8] HAN J W, KAMBER M. Data Mining: Concepts and Techniques[M]. U. S: Morgan Kaufmann Publishers, Inc, 2001.
[9] 陈新泉. 聚类算法中的优化方法应用[M]. 成都:电子科技大学出版社, 2014.
[责任编辑:张德福]
An implementation method of dynamic R*- tree based on improved cluster splitting
PENG Zhaojun1, XIONG Wei1, CHAI Zheng2
(1.Information Engineering University, Zhengzhou 450001, China;2.Troops 61206, Beijing 100042, China)
Clustering technologies can effectively improve the performance of R*- tree.The traditional K-means clustering algorithm is very sensitive to the initial value, and the process of clustering is very complex. Considering this, an improved clustering algorithm of the dynamic R*- tree is proposed. In the process of node splitting, clustering technologies and improved structure can obtain dynamic structural reorganization of R*- tree. Experimental results show that the dynamic R*- tree can achieve higher query efficiency and space utilization with a slightly higher construction cost, which has practical value in dynamic loading and processing of batch data.
R*- tree;clustering;node splitting;space utilization
10.19349/j.cnki.issn1006-7949.2017.03.016
2016-02-23
国家自然科学基金资助项目(41501507)
彭召军(1992-),男,硕士研究生.
P208
A
1006-7949(2017)03-0072-05
引用著录:彭召军,熊伟,柴峥.基于改进聚类分裂的动态R*-树实现方法[J].测绘工程,2017,26(3):72-76.
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
甘肃科技(2020年19期)2020-03-11
中国煤炭(2020年2期)2020-01-21
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国化肥信息(2019年6期)2019-01-19
消费导刊(2017年24期)2018-01-31
中学生数理化·八年级数学人教版(2017年4期)2017-07-08
印制电路信息(2015年6期)2015-12-30
