
噪声环境下稳健的说话人识别特征研究
2017-12-01 03:32:53程小伟王健曾庆宁谢先明龙超
声学技术 2017年5期
程小伟,王健,曾庆宁,谢先明,龙超
噪声环境下稳健的说话人识别特征研究
程小伟,王健,曾庆宁,谢先明,龙超
(桂林电子科技大学信息与通信学院,广西桂林 541004)
针对噪声环境下说话人识别率较低的问题,提出一种基于正规化线性预测功率谱的说话人识别特征。首先对语音信号线性预测分析和正规化处理求出语音频谱包络,然后通过伽马通滤波器组得到对数子带能量,最后对特征参数进行离散余弦变换,得到了一种说话人识别特征正规化线性预测伽马通滤波器倒谱系数(Regularized Linear Prediction Gammatone Filter Cepstral Coefficient, RLP-GFCC)。仿真结果表明,在噪声环境说话人辨认试验中,相比传统特征美尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)和伽马通滤波器倒谱系数(Gammatone Filter Cepstral Coefficient,GFCC)的系统识别率得到了明显提高,对噪声环境的鲁棒性得到了增强。
线性预测;正规化;说话人识别;伽马通滤波器组;鲁棒性
0 引言
说话人识别技术是一种重要的生物特征识别技术,应用于身份确认、信息安全、远程控制等领域[1]。如何提取有效的说话人识别特征是识别技术的关键,说话人识别特征要能够描述说话人声道特性,有较高的区分度,对外界环境具有较强的鲁棒性[2]。
线性预测理论应用于语音信号处理,能够提供说话人的声道模型[3],因此,线性预测系数(Linear Prediction Coefficient,LPC)成为比较普遍的说话人识别特征,基于线性预测理论的特征线性预测倒谱系数(Linear Prediction Cepstral Coefficient,LPCC)[4]能够用于说话人识别特征。这些特征在安静环境下能够取得很高的识别率,但对噪声环境的鲁棒性却很差。梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)[5]是语音识别和说话人识别最有效的特征之一,该特征基于听觉模型,对噪声环境具有一定的鲁棒性,但在低信噪比环境下识别率仍然较低。为应对噪声环境下说话人系统识别率较低的问题,研究人员通过对基于人耳耳蜗听觉模型伽马通滤波器的研究,提出了用于说话人识别的特征——伽马通滤波器倒谱系数(Gammatone Filter Cepstral Coefficient,GFCC)[6],经实验论证该特征在不同背景噪声环境下可取得比MFCC更好的识别率。
为了进一步提高说话人识别系统对噪声环境的鲁棒性,结合线性预测分析理论和伽马通滤波器组的特殊性质,本文提出一种新的说话人识别特征,先求出语音信号的线性预测功率谱,并对线性预测功率谱进行正规化处理[7],得到的频谱代替传统傅里叶变换功率谱,最后结合特征GFCC的提取方法,得到说话人识别特征正规化线性预测伽马通滤波器倒谱系数(Regularized Linear Prediction Gammatone Filter Cepstral Coefficient, RLP-GFCC),仿真实验表明,该特征在噪声环境下能够取得比GFCC和线性预测伽马通滤波器倒谱系数(Linear Prediction Gammatone Filter Cepstral Coefficient, LP-GFCC)更好的系统识别率。
1 语音信号短时功率谱
1.1 线性预测功率谱
传统语音信号功率谱是通过对语音信号进行加窗分帧,然后对每帧语音信号进行离散傅里叶变换得到其频谱,即通过式(1)实现:
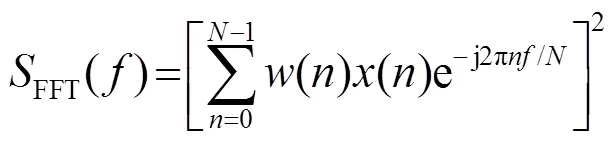
其中:为离散频率;()和()分别为加窗函数和语音采样信号;为离散傅里叶变换点数。本文实验中加窗函数()采用汉明窗。

一般通过自相关方法[12]求取线性预测系数,即通过式(2)求得:
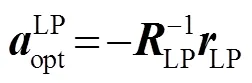

线性预测功率谱比传统离散傅里叶变换频谱更加光滑,能够较好地表示语音信号的频谱包络,同时能提供说话人的声道模型。
1.2 正规化线性预测功率谱
L. Anders Ekman[7]等在2008年提出了语音信号的正规化线性预测,正规化线性预测比传统线性预测能更好地描述语音信号的频谱包络。
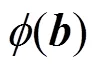


正规化线性预测系数通过式(5)求得:


图1运用FFT、LP和RLP三种频谱分析方法生成了频谱对比图,使用的语音来自TIMIT语音库,图1(b)为图1(a)中同一帧语音加0 dB信噪比的机枪(machinegun)噪声。LP和RLP所用阶数为=20,RLP中参数=10-10,为了便于观察,RLP频谱上移20 dB。从图1中可以看出,LP谱和RLP能够体现出短时语音信号的共振峰特性和频谱包络。正规化线性预测通过补偿方法处理非光滑部分,比传统线性预测频谱包络的估计失真低。
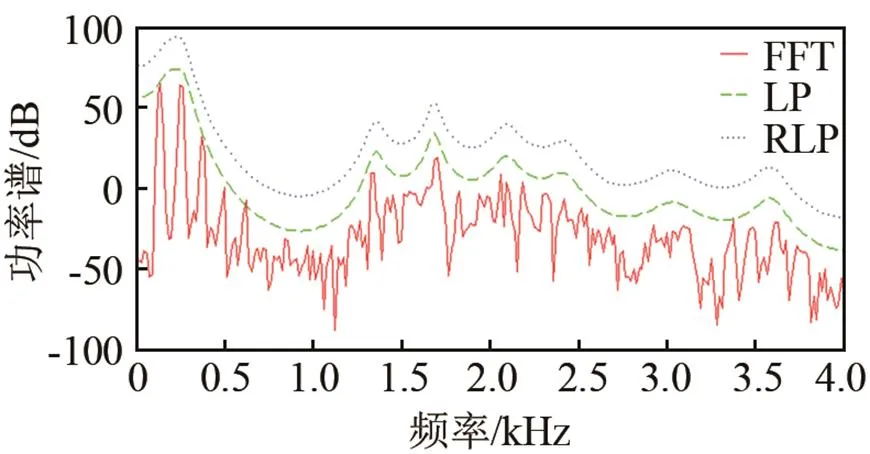
(a) 纯净语言
(b) 带噪语言
图1 纯净语音与带噪语音频谱对比图
Fig.1 Comparison of spectrum between clean speech and noisy speech
2 基于线性预测功率谱的特征提取过程
特征LP-GFCC和RLP-GFCC提取过程如图2所示:

图2 鲁棒性特征提取流程图
首先对语音信号进行预加重处理,通过高通滤波器,提升高频分量;然后利用语音信号的短时平稳性,对语音信号进行加窗分帧,本文采用汉明窗;利用上述计算方法求取LP或RLP系数,按照式(3)或式(6)对每组预测系数进行离散傅里叶变换(Discrete Fourier Transform,DFT),得到的能量谱通过64通道的伽马通滤波器组[15],对子带能量取对数,最后对子带对数能量进行离散余弦变换(Discrete Cosine Transform,DCT),得到特征LP- GFCC或RLP-GFCC。
3 实验分析
本文所用的基线系统是与文本无关的说话人辨认系统,实验使用的语音来自TIMIT语音库[16],采样率是16 kHz,单通道录音,采样精度为16 bit,从中选取85个说话人(其中男45人,女40人),每一个说话人有10句语音段,每段语音时长约3 s。训练模型使用7句语音,测试使用3句语音,总共测试语音255句。说话人识别训练模型采用高斯混合模型(Gaussian Mixture Model,GMM)。实验所用噪声来自noisex-92噪声库,语音信号信噪比设为-5、0、5、10、15、20、25、30 dB。
高斯混合模型阶数由说话人辨认样本数量决定,本次实验样本数量较少,阶数过高会造成过拟合使识别率降低,阶数过低不能充分表达说话人的特征空间。实验使用的参数直接影响系统识别率,文献[2]的实验参数在说话人辨认实验中能够取得较好的识别率,因此本文采用文献[2]的实验参数,实验1在基线系统上对GMM阶数取值做了对比实验,GMM阶数取32时,基线系统性能达到最好。语音信号预加重系数典型取值在0.92~0.97之间,本文取值0.93,采用汉明窗加窗分帧,帧长为32 ms,即512个采样点,帧移为8 ms,即128个采样点。实验中的端点检测采用基音检测算法。特征MFCCD取12阶静态MFCC和一阶动态特征,总共24维特征参数。在提取说话人识别特征GFCC的过程中,采用64通道伽马通滤波器组,依照等效矩形带宽(Equivalent Rectangular Bandwidth,ERB)频率分布在50 Hz和8 000 Hz之间,对对数子带能量进行DCT之后,24维系数作为实验所用的说话人特征。本文实验特征LP-GFCC和RLP-GFCC线性预测阶数为20,RLP-GFCC的参数取固定值10-10。
3.1 实验1 GMM阶数对基线系统影响
本文实验采用高斯混合模型进行说话人辨认实验,其中GMM阶数直接影响说话人识别系统。实验中采用高斯混合模型阶数分别为4、8、16、32、64,测试语音采用纯净语音,特征使用24维MFCCD作为说话人识别系统特征,实验结果如表1所示。

表1 GMM阶数对基线系统的影响
从表1可以看出,随着GMM阶数的增加,系统识别性能逐渐变好,当阶数为32时,识别性能最好,识别率达到98.43%,随后开始降低。因此对于实验所用的基线系统,GMM阶数取值32时,系统识别率达到最好,本文实验采用32阶GMM。
3.2 实验2 平稳噪声环境识别结果
为了验证平稳噪声环境下特征LP-GFCC和RLP-GFCC识别的鲁棒性,分别用MFCCD、GFCC、LP-GFCC和RLP-GFCC做仿真实验,四种特征均为24维,平稳噪声选用白噪声,信噪比设为30、25、20、15、10、5、0 dB。系统识别率如表2所示。
从表2可以看出,特征LP-GFCC和RLP-GFCC在噪声环境下系统识别率优于MFCCD,在高噪声环境下系统识别率稍差于GFCC,在低信噪比时识别率明显优于特征GFCC,RLP-GFCC特征对噪声的鲁棒性优于LP-GFCC。在0 dB噪声环境下,四种特征在系统中识别率都很低,在15 dB白噪声环境下,特征RLP-GFCC的识别率较特征MFCC、GFCC和LP-GFCC分别提高了41.96%、8.23%和3.92%。
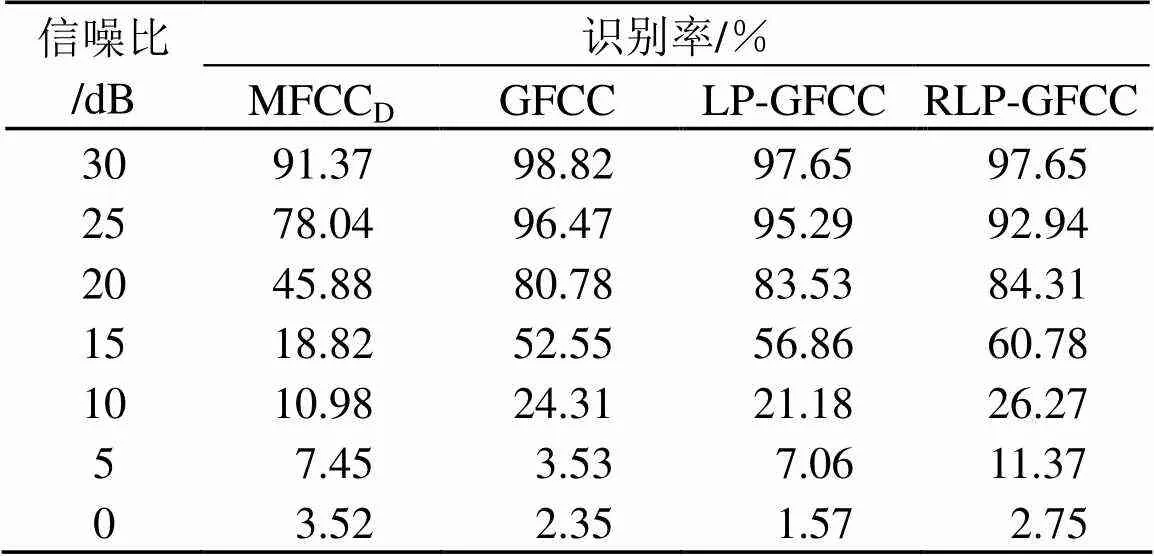
表2 白噪声环境下的特征识别率
3.3 实验3 非平稳噪声环境识别结果
为了验证非平稳噪声环境下特征LP-GFCC和RLP-GFCC识别的鲁棒性,同实验2的实验参数,从noisex-92噪声库选取pink、babble、machinegun噪声,信噪比设为30、25、20、15、10、5、0、-5 dB。说话人识别系统仿真结果如图3~5所示。
从图3~5仿真结果可以看出,在不同信噪比噪声环境下,特征LP-GFCC和RLP-GFCC系统识别率明显高于传统特征MFCCD和GFCC,特征RLP-GFCC系统识别率稍微高于LP-GFCC,在5 dB 噪声环境下,LP-GFCC平均识别率比传统特征MFCCD和GFCC分别高出39.48%和26.80%。由于本文实验在求取特征RLP-GFCC时,参数取固定值10-10,特征RLP-GFCC系统识别率稍微高于特征LP-GFCC。文献[7]关于正规化线性预测功率谱,对参数提出了一种自适应方法,参数是随基音变化的数,能够减少传统线性预测对语音信号造成的失真。

图3 粉红噪声环境下的特征识别率

图4 嘈杂噪声环下的境特征识别率

图5 机枪噪声环境下的特征识别率
3.4 实验4 说话人识别特征计算时间对比
表3列举了特征MFCCD、GFCC、LP-GFCC、RLP-GFCC的平均计算时间,测试语音时长为5 s,每种特征测试20次,最后取平均时间。实验仿真软件平台为Matlab R2014a,计算机CPU为酷睿i3-2310,主频为2.1 GHz。虽然特征LP-GFCC和RLP-GFCC的计算时间较MFCC、GFCC稍长,但在性能好的计算机实验平台上计算时间还会缩短,能够满足一定的实时性。在下一步的研究工作中,需要改进特征的计算复杂度,期望能够有更好的实时性能。

表3 说话人识别特征计算时间对比结果
4 结论
环境噪声对语音信号影响很大,不仅影响语音质量以及可懂度,而且造成语音识别和说话人识别系统识别率的迅速下降。本文通过结合线性预测分析理论和伽马通滤波器的特殊性质,提出了说话人识别特征LP-GFCC和RLP-GFCC,利用TIMIT语音库和noisex-92噪声库,Matlab仿真实验表明,这两种特征在说话人识别系统中性能优于传统特征MFCC和GFCC,提高了系统的说话人识别率和对噪声环境的鲁棒性。但RLP-GFCC的识别性能稍微优于特征LP-GFCC,补偿参数对说话人识别系统的识别率影响较大,因此在后续的说话人识别研究工作中,可以引入相关文献中的自适应方法。
[1] 吴朝晖. 说话人识别模型与方法[M]. 北京: 清华大学出版社, 2009. WU Chaohui. The model and method of speaker recognition[M]. Beijing: Tsinghua University Press, 2009.
[2] 蒋晔. 基于短语音和信道变化的说话人识别研究[D]. 南京: 南京理工大学, 2013. JIANG Ye. Research on speaker recognition over short utterance and varying channels[D]. Nanjing: Nanjing University of Science and Technology, 2013.
[3] Pati D, Prasanna S R M. Processing of linear prediction residual in spectral and cepstral domains for speaker information[J]. International Journal of Speech Technology, 2015, 18(3):1-18.
[4] 周燕, 胡志峰. 基于免疫聚类的RBF网络在说话人识别中的应用[J]. 声学技术, 2010, 29(2): 184-187. ZHOU Yan, HU Zhifeng. Application of immune algorithm based RBF network to human speaker recognition[J]. Technical Acoustics, 2010, 29(2): 184-187.
[5] 林琳, 陈虹, 陈建. 基于鲁棒听觉特征的说话人识别[J]. 电子学报, 2013, 41(3): 619-624. LIN Lin, CHEN Hong, CHEN Jian. Speaker recognition based on robust auditory feature[J]. Acta Electronica Sinica, 2013, 41(3): 619-624.
[6] 王玥, 钱志鸿, 王雪, 等. 基于伽马通滤波器组的听觉特征提取算法研究[J]. 电子学报, 2010, 38(3): 525-528. WANG Yue, QIAN Zhihong, WANG Xue, et al. An auditory feature extraction algorithm based on γ-tone filter-banks[J]. Acta Electronica Sinica, 2010, 38 (3): 525-528.
[7] Ekman L A, Kleijn W B, Murthi M N. Regularized linear prediction of speech[J]. IEEE Transactions on Audio Speech & Language Processing, 2008, 16(1): 65-73.
[8] Bastys A, Kisel A, Alna B. The use of group delay features of linear prediction model for speaker recognition[J]. Informatica, 2010, 21(1): 1-12.
[9] Bastys A, Kisel A, Alna B. The use of group delay features of linear prediction model for speaker recognition[J]. Informatica, 2010, 21(1): 1-12.
[10] Saeidi R, Alku P, Backstrom T. Feature extraction using power-law adjusted linear prediction with application to speaker recognition under severe vocal effort mismatch[J]. Audio Speech & Language Processing IEEE/ACM Transactions on, 2016, 24(1): 42-53.
[11] Makhoul J. Linear prediction: a tutorial review. Proc IEEE 63: 561-580[J]. Proceedings of the IEEE, 1975, 63(4): 561-580.
[12] 宋知用. MATLAB在语音信号分析与合成中的应用[M]. 北京: 北京航空航天大学出版社, 2013. SONG Zhiyong. Application of MATLAB in speech signal analysis and synthesis[M]. Beijing: Beihang University Press, 2013.
[13] Shimamura T, Nguyen N D. Autocorrelation and double autocorrelation based spectral representations for a noisy word recognition system[C]// INTERSPEECH 2010, Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, September. 2010.
[14] Hanilçi C, Kinnunen T, Ertaş F, et al. Regularized all-pole models for speaker verification under noisy environments[J]. IEEE Signal Processing Letters, 2012, 19(3): 163-166.
[15] D. P. W. Ellis (2009). Gammatone-like spectrograms. http://www. ee.co-lumbia.edu/~dpwe/resources/matlab/gamatonegram/.
[16] Li Q, Reynolds D A. Corpora for the evaluation of speaker recognition systems[C]// Acoustics, Speech, and Signal Processing, 1999. on 1999 IEEE International Conference. IEEE Computer Society, 1999: 829-832.
A study of robust speaker recognition feature under noisy environment
CHENG Xiao-wei, WANG Jian, ZENG Qing-ning, XIE Xian-ming, LONG Chao
(School of Information and Communication, Guilin University of Electronic Technology, Guilin 541004, Guangxi, China)
In order to solve the problem that speaker recognition rate is low under noisy environment, a speaker recognition feature based on regularized linear predictive power spectrum is proposed. The method uses linear prediction analysis and regularization of speech signal to get speech spectral envelope and then to get logarithmic sub-band energy through the Gammatone filter group, and finally uses discrete cosine transform to compute feature parameters to get a kind of speaker recognition feature named regularized linear predicted Gammatone filter cepstral coefficients (RLP-GFCC). The simulation results show that the recognition rate of the system is significantly improved in comparison with the systems of traditional feature MFCC and GFCC under noisy environment, and the robustness of the system to noise environment is improved.
linear prediction; regularization; speaker recognition; Gammatone filter bank; robustness
TN912.3
A
1000-3630(2017)-05-0479-05
10.16300/j.cnki.1000-3630.2017.05.014
2016-12-06;
2017-04-01
国家自然科学基金项目(61461011); 教育部重点实验室2016年主任基金项目资助(CRKL160107); 广西自然科学基金(2014 GXNSFBA118273)项目。
程小伟(1990-), 男, 河南漯河人, 硕士研究生, 研究方向为语音增强和说话人识别。
龙超, E-mail: chengzai05@163.com
猜你喜欢
大学数学(2021年5期)2021-10-30 09:01:04
华东师范大学学报(自然科学版)(2021年3期)2021-06-03 09:30:10
计算机工程(2020年3期)2020-03-19 12:24:50
电子制作(2019年11期)2019-07-04 00:34:38
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
电子制作(2018年16期)2018-09-26 03:26:50
中国交通信息化(2018年3期)2018-06-13 03:27:58
系统工程与电子技术(2016年7期)2016-08-21 13:59:02
中国交通信息化(2016年2期)2016-06-06 07:28:02
火控雷达技术(2016年2期)2016-02-06 02:29:00
