
SURVEYMEANS过程在抽样调查资料分析中的应用
2017-11-02 06:54李长平胡良平
四川精神卫生 2017年5期
李长平,胡良平
(1.天津医科大学公共卫生学院卫生统计学教研室,天津 300070;2.世界中医药学会联合会临床科研统计学专业委员会,北京 100029;3.军事医学科学院生物医学统计学咨询中心,北京 100850*通信作者:胡良平,E-mail:lphu812@sina.com)
SURVEYMEANS过程在抽样调查资料分析中的应用
李长平1,2,胡良平2,3*
(1.天津医科大学公共卫生学院卫生统计学教研室,天津 300070;2.世界中医药学会联合会临床科研统计学专业委员会,北京 100029;3.军事医学科学院生物医学统计学咨询中心,北京 100850*通信作者:胡良平,E-mail:lphu812@sina.com)
传统的统计分析方法在进行差异性分析、线性与广义线性回归分析时,基本上都是基于样本来自无限总体、完全随机抽样的基础上估计抽样误差。而调查数据往往来自于分层、整群、多阶段或不等概率等复杂随机抽样方法,此时若采用前述提及的经典统计分析方法,则不能准确估计抽样误差。本文通过具体实例,介绍如何应用SAS软件中的SURVEYMEANS过程,更好地实现对通过各种抽样方法获得的数据进行统计描述和简单的统计分析,以便达到准确估计抽样误差、对总体参数描述和估计的目的。
SAS软件;SUVEYMEANS过程;简单随机抽样;分层抽样;分层整群抽样
1 调查资料统计分析方法概述
1.1 随机抽样方法简介
调查研究是医学科学研究常见的形式之一。而无论是观察性研究如横断面研究,还是分析性研究如病例对照研究、队列研究,绝大多数时候都会采用抽样调查的形式。那么,一旦采用抽样的形式选取研究对象,研究结果就会存在抽样误差。常用的概率抽样调查的方法有完全随机抽样、系统抽样、分层抽样、整群抽样等。不同的抽样方法,抽样误差大小的估计方法是不同的[1]。
1.2 调查资料统计描述与简单统计分析方法简介
传统统计分析软件(如SAS,其MEANS、GLM过程等)中的算法,通常都是基于“无限总体、完全随机抽样”这样的假设基础上估计抽样误差的。而当抽样方法相对复杂,采用这些程序计算将不能得到正确的抽样误差估计值[2-3]。此时,SAS/STAT中的SURVEYMEANS过程就能发挥其作用了。PROC SURVEYMEANS利用Taylor扩展方法估计基于复杂抽样设计的统计量抽样误差。该方法获得统计量的一个线性近似值并用该近似值的方差估计来推断统计量本身的方差[4-5]。
1.3 调查资料回归分析方法简介
在SAS软件中,有SASREG、SASLOGISTIC、SASPHREG三个过程可被用来对各种复杂抽样调查资料进行建模。针对不同的随机抽样方法,采取相应的算法去估计方差-协方差矩阵,以便更好地估计回归系数;同时,还采用Taylor级数方法或重抽样方法来估计抽样误差。
2 采用SURVEYMEANS过程实现统计描述与简单统计分析
2.1 SURVEYMEANS过程简介
PROC SURVEYMEANS DATA=用于指定要分析的输入数据集。当调查设计包括有限总体校正因子时,可以用RATE=或TOTAL=选项指定抽样率或抽样大小;
BY 指定分组单独分析变量;
CLASS 指定作为属性变量来分析的变量;
CLUSTER 指定整群抽样设计中的群识别变量;
DOMAIN语句对亚总体或域进行分析的变量;
RATIO 计算分析变量均值或构成的比值,分子变量/分母变量;
STRATA指定分层抽样设计中的分层变量;
VAR 指定分析变量;
WEIGHT 指定包含抽样权重的变量;
RUN;
2.2 基于完全随机抽样设计的统计分析
【例1】假设从总体4 000名学生(七、八、九年级)中采用随机抽样方法抽取40名学生作为样本。研究者想通过对这40名学生的调查了解学生平均每周的冰淇淋花费,以及每周的冰淇淋花费超过10美元的学生的比例。具体数据如表1所示,表1数据存为SAS数据集,命名为IceCream。
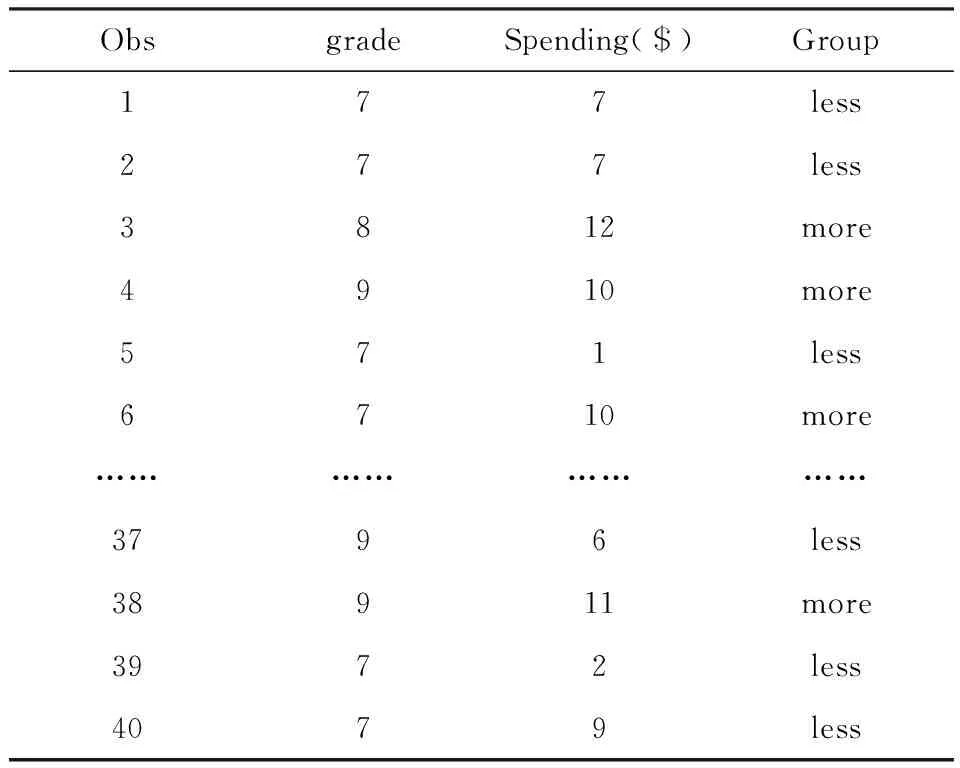
表1 40名学生每周冰激淋花费情况
注:Grade,年级;Spending,花费;less,<10美元;more,≥10美元
对应的SAS计算程序如下:

title1‘AnalysisofIceCreamSpending’;title2‘SimpleRandomSampleDesign’;procsurveymeansdata=IceCreamtotal=4000;varSpendingGroup;run;
【程序说明】proc surveymeans调用surveymeans过程。TOTAL=4 000,指进行一个样本量为4 000的有限总体校正的方差估计
【输出结果】

TheSURVEYMEANSProcedureDataSummaryNumberofObservations40

StatisticsVariableLevelNMeanStdErrorofMean95%CLforMeanSpending408.7500000.8451397.0405453910.4594546Groupless230.5750000.0787610.415689940.7343101more170.4250000.0787610.265689940.5843101
【结果说明】数值变量Spending的结果显示,学生总体中平均每周冰淇淋花费为8.75美元,95%置信区间为(7.04,10.46)美元。属性变量Group的结果显示,学生总体中平均每周冰淇淋花费少于10美元的比例约为57.5%,置信区间为(41.6%,73.4%),多于10美元的比例约为42.5%,置信区间为(26.6%,58.45%)。
2.3 基于分层抽样设计的统计分析
【例2】 沿用例1的背景资料。假设上例中4 000名学生是来自分层抽样设计,按年级分层,各年级抽取的学生人数见下表2。试对数据进行分析。
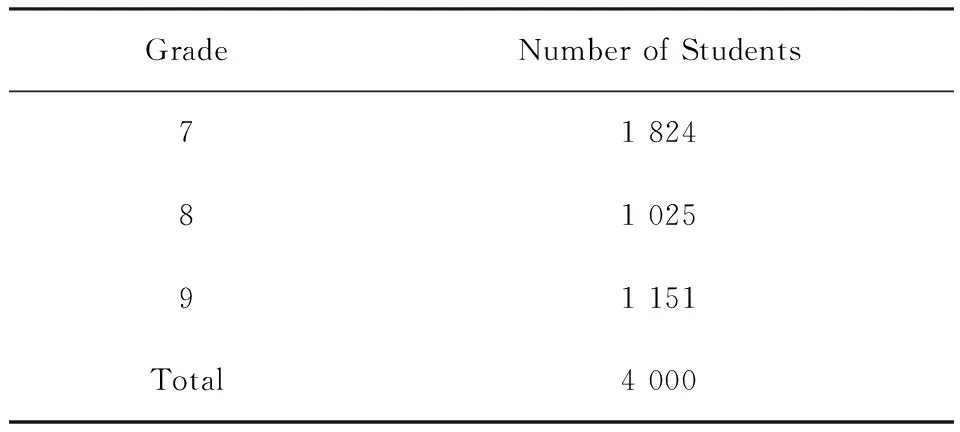
表2 各年级抽取的学生人数
对应的SAS计算程序如下:

dataStudentTotals;inputGrade_total_;datalines;718248102591151;dataIceCream;setIceCream;ifGrade=7thenProb=20/1824;ifGrade=8thenProb=9/1025;ifGrade=9thenProb=11/1151;Weight=1/Prob;title1‘AnalysisofIceCreamSpending’;title2‘StratifiedSimpleRandomSampleDesign’;procsurveymeansdata=IceCreamtotal=StudentTotals;stratumGrade/list;varSpendingGroup;weightweight;run;
【程序说明】Grade是分层变量,变量_total_表示各层总体大小,该名称为程序中固定格式。程序方差估计时利用每层总体观测量大小来校正有限总体抽样的影响。若不提供各总体的大小或抽样率,则
系统假定样本中包含总体的率非常小,此时不做有限总体校正。在分层抽样设计中,当各层抽样概率不同时,需要定义样本的权重以便做到对均数无偏的估计。在本例中,采用按比例抽样的方式,每层抽样概率的倒数作为样本权重(即用Weight命令设置权重)。List命令要求输出每层的信息。每个年级中抽取的样本数为事先按一定规则,如等比例抽样规定的样本数。
【输出结果】
(1)生成的IceCream SAS数据集截图如下:

(2)Output结果:

StratumInformationStratumIndexGradePopulationTotalSamplingRateNObsVariableLevelN1718241.10%20Spending20Groupless17more32810250.88%9Spending9Groupless0more93911510.96%11Spending11Groupless6more5
上表显示按三个年级分层、各层的总人数、抽样率、抽取的各层总样本数、对应的变量及细分组样本数信息。

StatisticsVariableLevelNMeanStdErrorofMean95%CLforMeanSpending409.1412980.5317998.0637705210.2188254Groupless230.5445550.0584240.426176780.6629323more170.4554450.0584240.337067690.5738232
对Spending分析的结果显示,学生总体中平均每周冰淇淋花费为9.14美元,标准误为0.53,95%置信区间为(8.06,10.22)美元。对Group分析的结果显示,学生总体中平均每周冰淇淋花费少于10美元的约为54.5%,置信区间为(42.6%,66.3%),多于10美元的约为45.5%,置信区间为(33.7%,57.4%),标准误为5.8%。
2.4 基于分层整群抽样设计的统计分析
【例3】沿用例1的背景资料。假设从总体4 000名学生中采用分层整群抽样获取40例样本。4 000名学生的总体情况如下表3所示:

表3 4 000名学生各年级及学习小组构成情况
4 000名学生来自七、八、九年级。各年级有对应的人数(表3第3列)和若干学习小组(表3第2列)。每个学习小组中有2~4个学生。
在本例中,抽样单位(或“群”)是学习小组。以年级为分层单位,对学习小组进行随机抽选,选中的学习小组中的所有学生作为样本。假定从七、八、九年级分别抽取了8、3、5个学习小组。
对应的SAS程序如下:

①dataIceCreamStudy;inputGradeStudyGroupSpending@@;if(Spending<10)thenGroup='less';elseGroup='more';datalines;7347734774124927147342923015927157501292308923077501385920740347403118591385917814312814316859189235981431093128923569235119312107321681561981561473213732112748927489977817781074892715617786741267156293018;②dataStudentGroups;inputGrade_total_;datalines;760882529403;

③dataIceCreamStudy;setIceCreamStudy;ifGrade=7thenProb=8/608;ifGrade=8thenProb=3/252;ifGrade=9thenProb=5/403;Weight=1/Prob;title1‘AnalysisofIceCreamSpending’;title2‘StratifiedClusteredSampleDesign’;④procsurveymeansdata=IceCreamStudytotal=Student-Groups;strataGrade/list;clusterStudyGroup;varSpendingGroup;weightweight;run;
【程序说明】数据步①中Group表示年级,StudyGroup表示学习小组,不同年级的小组编号可以相同,因为小组编号是按年级和其小组数排的顺序编号。Spending表示冰淇淋花费,Group是根据冰淇淋花费进行分组。数据步②中Grade是分层变量,变量_total_表示各层学习小组数,该名称为程序中固定格式,用于表达主要抽样单位。数据步③中,定义主要抽样单位的权重。权重为群抽样概率的倒数。过程步④中,strata定义分层变量,cluster定义群抽样单位变量。
【输出结果】
(1)生成的IceCreamstudy SAS数据集截图如下:

(2)Output输出结果:

DataSummaryNumberofStrata3NumberofClusters16NumberofObservations40SumofWeights3162.6

ClassLevelInformationCLASSVariableLevelsValuesGroup2lessmore

StratumInformationStratumIndexGradePopulationTotalSamplingRateNObsVariableLevelNClusters176081.32%20Spending208Groupless178more33282521.19%9Spending93Groupless00more93394031.24%11Spending115Groupless64more54
上表中给出了按三个年级分层,各层的总群数、抽样率、抽取的各层总样本数、对应的变量水平、细分组样本数信息和群数。

StatisticsVariableLevelNMeanStdErrorofMean95%CLforMeanSpending408.9238600.6508597.5177637010.3299565Groupless230.5614370.0563680.439660570.6832130more170.4385630.0563680.316786980.5603394
对Spending分析的结果显示,学生总体中平均每周冰淇淋花费为8.92美元,标准误为0.53,95%置信区间为(7.52,10.33)美元。对Group分析的结果显示,学生总体中平均每周冰淇淋花费少于10美元的比例约为56.1%,置信区间为(44.0%,68.3%),多于10美元的比例约为43.9%,置信区间为(31.7%,56.0%),标准误为5.6%。
2.5 SURVEYMEANS在域分析(Domain analysis)中的应用
域分析是指对亚群或域的统计计算,进行分析的亚组可以与样本抽样设计无关,该分析也称为亚组分析、亚群分析或子域分析。如下例所示:
【例4】欲对前800家公司情况进行分析,了解其概况及经济相关状况,同时了解不同公司市场类型特征下的经济情况。现有其中66家公司的样本,但该66家公司的抽取并没有考虑到市场类型这一因素,即为市场类型的非概率抽样,样本中每个市场类型中含有多少个公司是一个随机变量。此时,要对每一个市场类型作相应的分析,可采用域分析。
【SAS程序如下】

dataCompany; lengthType$14; inputType$AssetSaleValueProfitEmployeeWeight;datalines; Other2764.01828.01850.3144.018.79.6 Energy13246.24633.54387.7462.924.342.6 Finance3597.7377.893.014.01.112.2 Transporta-tion6646.16414.22377.5348.247.121.8 HiTech1068.41689.81430.272.94.64.3 Manufacturing1125.01719.41057.598.120.44.5 Other1459.01241.4452.724.520.15.5 Finance2672.3262.5296.223.12.29.3 Finance311.0566.2932.052.82.71.9 Energy1148.61014.6485.160.64.04.5 Finance5327.0572.4372.925.24.217.7 Energy1602.7678.4653.075.62.86.0 Energy5808.81288.42007.0318.85.919.2 Medical268.8204.4820.945.63.71.8 Transporta-tion5222.62627.81910.0245.622.817.4 Other872.71419.4939.369.712.23.7……;title1'TopCompaniesProfileStudy';procsurveymeansdata=Companytotal=800meansum; varAssetSaleValueProfitEmployee; weightWeight; domainType;run;
【程序说明】数据步中Type表示市场类型,Asset表示资产(百万美元),Sale表示销售额(百万美元),Value表示公司的市场价值(百万美元),Profit表示利润(百万美元),Employee表示员工数(千),weight代表权重,共66行即66家公司的数据。为节省篇幅,仅列出部分数据。
【输出结果】:

TheSURVEYMEANSProcedureDataSummaryNumberofObservations66SumofWeights799.8

StatisticsVariableMeanStdErrorofMeanSumStdDevAsset6523.488510720.55707552174861073829Sale4215.995799839.1325063371953847885Value2145.935121342.5317201716319359609Profit188.78821025.05787615099330144Employee36.8748697.787857294937148.003298
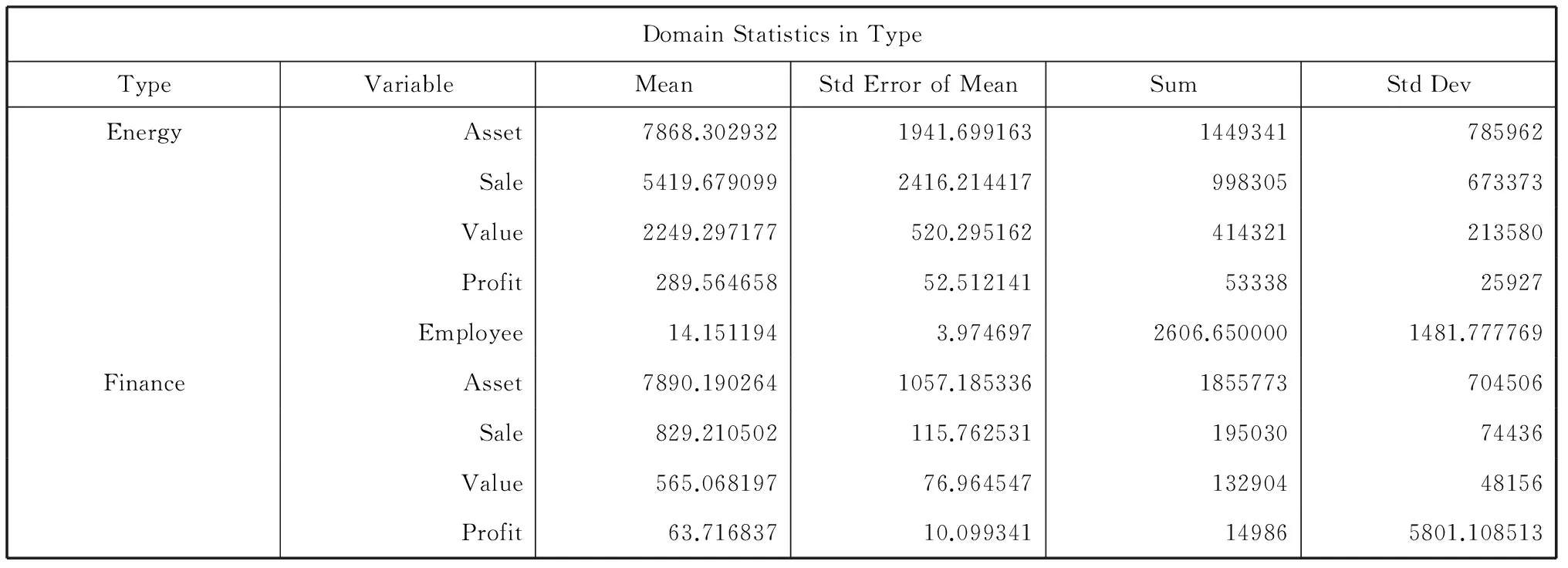
DomainStatisticsinTypeTypeVariableMeanStdErrorofMeanSumStdDevEnergyAsset7868.3029321941.6991631449341785962Sale5419.6790992416.214417998305673373Value2249.297177520.295162414321213580Profit289.56465852.5121415333825927Employee14.1511943.9746972606.6500001481.777769FinanceAsset7890.1902641057.1853361855773704506Sale829.210502115.76253119503074436Value565.06819776.96454713290448156Profit63.71683710.099341149865801.108513

Employee5.8062930.8115551365.640000519.658410HiTechAsset5031.959781732.436967321542183302Sale5464.292019731.296997349168196013Value6707.8284821194.160584428630249154Profit346.40704242.2990042213512223Employee70.7669808.6835954522.0100002524.778281ManufacturingAsset7403.0042501454.921083888361492577Sale7207.6388332112.444703864917501679Value2986.442750799.121544358373196979Profit211.93358339.9932552543213322Employee83.31433331.0890199997.7200006294.309490MedicalAsset5046.5706091218.444638140799131942Sale3313.219713758.2163039243985655Value2561.614695530.8022457146964663Profit218.68279644.0514476101.2500005509.560969Employee46.51899611.1359551297.8800001213.651734OtherAsset1850.250000338.1289845883831375Sale1620.784906168.6867735154124593Value1432.820755297.8698284556424204Profit115.08993727.9705603659.8600002018.201371Employee14.3066042.313733454.950000216.327710RetailAsset2939.845750393.69236923518894605Sale7395.4535001746.187580591636263263Value2103.863125529.75640916830978304Profit157.17187531.734253125745478.281027Employee93.62400015.7267437489.9200003093.832061TransportationAsset4712.047359888.954411267644163516Sale4030.2332751015.555708228917142669Value1703.330282313.8413269674958947Profit224.76232456.168925127678287.585418Employee30.9463036.7862701757.7500001066.586615
以上结果是给出总的和各市场类型对应的各指标的均数、标准误及置信区间。
另外,在SURVEYMEANS过程中,还能对抽样调查数据存在缺失值、其它抽样方法如有放回分层整群抽样[6]等进行处理,在此不再一一介绍。对于本文中涉及的置信区间的计算方法在此不再赘述,具体计算公式参考相关文献[7]。
[1] LehtonenR, Pahkinen E. Practical methods for design and analysis of complex survey[M]. New York: Wiley, 2004: 22-37.
[2] 刘建华, 金水高. 复杂抽样调查总体特征量及其方差的估计[J].中国卫生统计,2008, 25(4): 377-379.
[3] Brick JM, Kalton G. Handling missing data in survey research[J].Stat Methods Med Res, 1996, 5(3): 215-238.
[4] Woodruff RS. A simple method for approximating the variance of a complicated estimate[J].J Am Stat Assoc,1971, 66(334): 411-414.
[5] Fuller WA. Regression analysis for sample survey[J]. Sankhya, 1975, 37(3): 117-132.
[6] Francisco CA,Fuller WA. Quantile estimation with a complex survey design[J]. AnnStat, 1991,19(1): 454-469.
[7] SAS Institute Inc. SAS /STAT 9.3 User’s Guide[M]. Cary, NC: SAS Institute Inc, 2011: 7633-7704.
ApplicationoftheSURVEYMEANSprocedureintheanalysisofsamplingsurveydata
LiChangping1,2,HuLiangping2,3*
(1.DepartmentofHealthStatistics,SchoolofPublicHealth,TianjinMedicalUniversity,Tianjin300070,China;2.SpecialtyCommitteeofClinicalScientificResearchStatisticsofWorldFederationofChineseMedicineSocieties,Beijing100029,China;3.ConsultingCenterofBiomedicalStatistics,AcademyofMilitaryMedicalSciences,Beijing100850,China*Correspondingauthor:HuLiangping,E-mail:lphu812@sina.com)
When performing a difference analysis or a linear and generalized linear regression analysis, traditional statistical methods are basically based on the sample from the infinite population or completely random sampling to estimate the sampling error. However, the survey data are usually collected from complex random sampling methods, such as stratified, cluster, multi-stage or unequal probability. At this point, the sampling error cannot be accurately estimated if the classical statistical analysis methods mentioned above are adopted. Through specific examples, this article aimed to apply the SURVEYMEANS procedure in SAS software which can better implement the statistical description and analysis of the data obtained by various sampling methods, in order to estimate the sampling error and population parameters accurately.
SAS software; SURVEYMEANS procedure; Simple random sampling; Stratified sampling; Stratified cluster sampling
R195.1
A
10.11886/j.issn.1007-3256.2017.05.005
2017-08-17)
(本文编辑:陈 霞)
国家高技术研究发展计划课题资助(2015AA020102)
猜你喜欢
现代计算机(2022年14期)2022-09-20
内江师范学院学报(2022年4期)2022-04-27
湖北师范大学学报(自然科学版)(2021年3期)2021-09-08
数学物理学报(2021年1期)2021-03-29
影像视觉(2021年3期)2021-03-24
小学生学习指导(中年级)(2020年12期)2020-12-04
中国蜂业(2019年9期)2019-09-21
铁道通信信号(2018年9期)2018-11-10
农村农业农民·B版(2017年2期)2017-03-11
足球周刊(2014年20期)2014-07-03
