
基于多维用户模型的数字教育服务推荐技术研究
2017-11-01 17:14李银胜
计算机应用与软件 2017年10期
姚 帆 李银胜
(复旦大学软件学院 上海 201203)
基于多维用户模型的数字教育服务推荐技术研究
姚 帆 李银胜
(复旦大学软件学院 上海 201203)
目前的数字教育推荐系统中用户建模数据来源单一,用户意图分析不深入,缺乏数字教育的针对性考虑,准确度和满意度均有所局限。提出一种基于多维用户模型的数字教育服务推荐方法,充分考虑学生知识掌握水平、学习目标、学生所在群体等因素,从客观意图、主观意图和群体性意图三个方向进行分析推理。结合项目需求,开发基于上述推荐方法的数字教育应用原型系统。实验结果表明,该方法相对于仅考虑单一用户因素的系统在准确率、召回率及排序优先度等指标上均有明显提升。
推荐系统 用户建模 数字教育
0 引 言
随着数字教育技术的发展和互联网的流行,数字教育因为其海量信息、强交互性、覆盖面广和无时空限制等特点[1],受到越来越多学生的欢迎。前瞻产业研究院提供的《2016-2021年中国在线教育行业市场前瞻与投资战略规划分析报告》指出[2],从2010年开始,我国数字教育市场规模和用户人数都以10%以上的速度增长。2010年数字教育市场规模为491.1亿元,2015年突破千亿大关,达1 171亿元,预计2016年可以达到1 375亿元。
面对海量的数字教育服务,学生个性化教育的需求也日益凸显,推荐技术在数字教育系统中发挥着越来越重要的作用。传统的推荐技术包括基于内容的推荐、基于协同过滤的推荐和混合推荐。理想情况下,针对数字教育领域的推荐技术应该在合适的时间、合适的上下文,以一种合适的方式帮助学生找到可以与自身完美匹配的数字教育服务,确保学生保持学习的动力并且高效地完成学习活动[3]。
本文依托电子商务交易技术国家工程实验室合作共建研究平台“云私塾”进行研究。“云私塾”是面向数字教育领域的下一代电子商务应用,以移动端为载体,与用户进行交互。该应用包含三种用户角色:学生、教师和数字教育服务市场,其中教师可以发布数字教育服务,数字教育服务市场以合理高效的方式将教师发布的数字教育服务整合,学生可以选择教师和数字教育服务市场提供的服务。为了应对互联网上信息可靠性难以保障的问题,使用第三方信用保障平台在线教育可信云作为数据服务提供方,该平台对数字教育服务设置相关指标并进行信誉评价。
本文课题组提出一种多维用户模型[4],从生理、性格、观念、知识、经历和环境六个维度对用户进行建模。与传统的用户模型相比,多维用户模型从更深层次刻画用户,有助于挖掘用户的真实需求。基于多维用户模型在教育领域的映射,本文逐一按照客观意图分析、主观意图分析和群体性意图分析三个不同方向分析推断,最终整合为用户推荐与个体匹配度较高的数字教育服务列表。本文实现了针对数字教育的人性化推荐系统原型,实验表明通过本文的方法可以提高数字教育领域的推荐效果。
1 相关工作
用户模型是推荐系统的基础,它包含和用户自适应系统应用相关的信息,比如偏好、兴趣、行为、知识、目标等[5]。合理的用户模型对于推荐系统效果有重要的影响。用户模型是推荐系统的重要组成部分,提供给用户的个性化服务在很大程度上依赖于用户模型,比如用户模型数据是否完整、数据是否过时、数据真实性等。
针对数字教育服务推荐进行调研,文献[6-7]基于学生的偏好、知识和浏览历史记录推荐合适的教学活动和学习路径。Verbert等人讨论了上下文信息在推荐过程中的重要性[8]。文献[9]指出在数字教育推荐系统中的上下文是指学习环境、位置、时间、身体状况、活动、资源和社会关系。文献[10]指出应该根据学习者的学习风格提供合适的学习材料。文献[11]认为一个好的推荐系统需要考虑学习者的以下因素:学习目标、前置知识、学习者性格、学习者分组、对之前学习活动的评价、学习路径、学习策略等。
调研结果表明,目前的数字教育领域的推荐系统主要存在以下不足:1) 用户建模数据来源单一。大量的数字教育系统利用用户的历史数据和注册信息提供推荐服务,然而大部分学生在背景、目标、能力和性格方面都有很大不同[11],单纯利用上述信息难以反映学生的真实需求。2) 面向推荐的用户分析不深入,缺乏用户本质需求的挖掘。3) 数字教育领域针对性不足,与书籍电影推荐相比,数字教育推荐中更应该考虑学生知识掌握水平并且其是随着时间而变化的[12]。
针对上述问题,本文从生理、性格、观念、知识、经历和环境六个维度建立针对人性化数字教育的多维语义模型。借鉴文献[11]中数字教育服务推荐中需要考虑的因素,基于多维用户模型从客观意图、主观意图和群体性意图三个方向分析用户本质需求,充分利用六个维度的用户信息进行推理,提高推荐系统的准确性和用户满意度。
2 针对人性化数字教育的多维用户模型
从人性化用户建模的角度出发,将用户的多维用户模型投影在数字教育领域中,包括生理、性格、观念、知识和经历五个内生维度和环境这一外生维度。公式化表示为A::=
2.1 用户模型定义
2.1.1 生理维度
数字教育用户模型的生理维度是与学习过程相关并能影响学习效果的生理属性集合,生理维度定义见表1。很多生理因素都对学生的学习过程有着重要的影响,比如视力、听力、营养水平、疲劳程度等[13]。更为重要的是,在学习活动中,学生的智力水平对学习内容的选择及学习策略的制定都有着重大的影响。

表1 生理维度定义
2.1.2 性格维度
目前接受度比较高的三种人格特质集合是16项人格因素[14]、大五人格理论[15]和心因性需要[16]。本文使用大五人格理论来描述用户的性格维度,分别为开放性、尽责性、外向性、亲和性和情绪稳定性,见表2。

表2 性格维度定义
2.1.3 观念维度
在教育领域,观念维度指个人教育观念和教育服务消费观,见表3。文献[17]指出个人教育观念包括什么是真正的教育,教育的作用,如何接受教育以及针对不同的学习风格哪种类型的教育是合适的。教育消费观包括对于教育服务的评价标准以及不同类型教育服务的重要性排序。

表3 观念维度定义
2.1.4 知识维度
学习的过程是知识传授过程,因此知识维度在人性化教育服务推荐过程中起着重要的参考作用,本文也着重从用户的知识掌握水平方面去考虑推荐问题。知识维度包括用户对某一类知识的掌握程度,获得时间,以及该知识与其他知识的关系等。
2.1.5 经历维度
经历维度主要抓取和教育活动相关的信息,这些信息可以帮助更好地理解学生的真实需求。教育活动的基本信息主要包含教育活动涉及的学科或知识,活动的持续时间,活动的开始时间等。其中预期的教育活动是本文考虑的另一个重要因素,包括预期教育活动的时间、涉及知识以及重要性。比如学生在一个月后有大学生英语六级考试,并且该学生认为这个考试很重要,具体记录见表4。

表4 经历维度举例
2.1.6 环境维度
环境维度是用户模型中的外生维度,内生维度与外生维度关系密切,相互影响。数字教育用户模型中环境维度主要包括家庭成员和同学朋友的受教育程度、教育观念、教育服务消费观,以及社会学习热点及学习风气等。
2.2 用户模型构建
本文课题组曾经提出过基于人性化建模的用户模型具体构建方法,本文沿用其方法,用户模型构建方法如表5所示。

表5 各维度数据构建方法
3 基于多维用户模型的数字教育服务推荐方法
基于上一节介绍数字教育用户模型,本节将从用户的客观意图、主观意图和群体性意图三个方面逐一分析,并整合为最后的Top-K推荐列表。推荐方法的总体流程如图1所示。

图1 推荐方法总体流程
3.1 客观意图分析
3.1.1 数字教育服务语义模型构建
对数字教育服务构建语义模型是为了薄弱知识点与候选服务及预期教育活动的语义相似度计算。语义词典作为语义技术的基础,定义了计算过程中概念以及概念之间关系的知识库。本文课题组前辈对服务类产品语义建模有深入的研究,并且取得了较好的效果[17],本文借用其提出的语义建模方法。
数字教育产品语义特征数据源来自:
1) 数字教育服务通用属性,如服务名称、涉及知识、服务类别等;
2) 将所有数字教育服务作为语料库,提取其特征。
使用中文词法分析器IK Analyzer对服务描述信息进行分词,利用TF-IDF对服务中的特征词进行提取。通过选取销量较高的作为语料库,用于IDF值计算,将特征词前K个TF-IDF值最显著的作为语义特征。主要流程如图2所示。
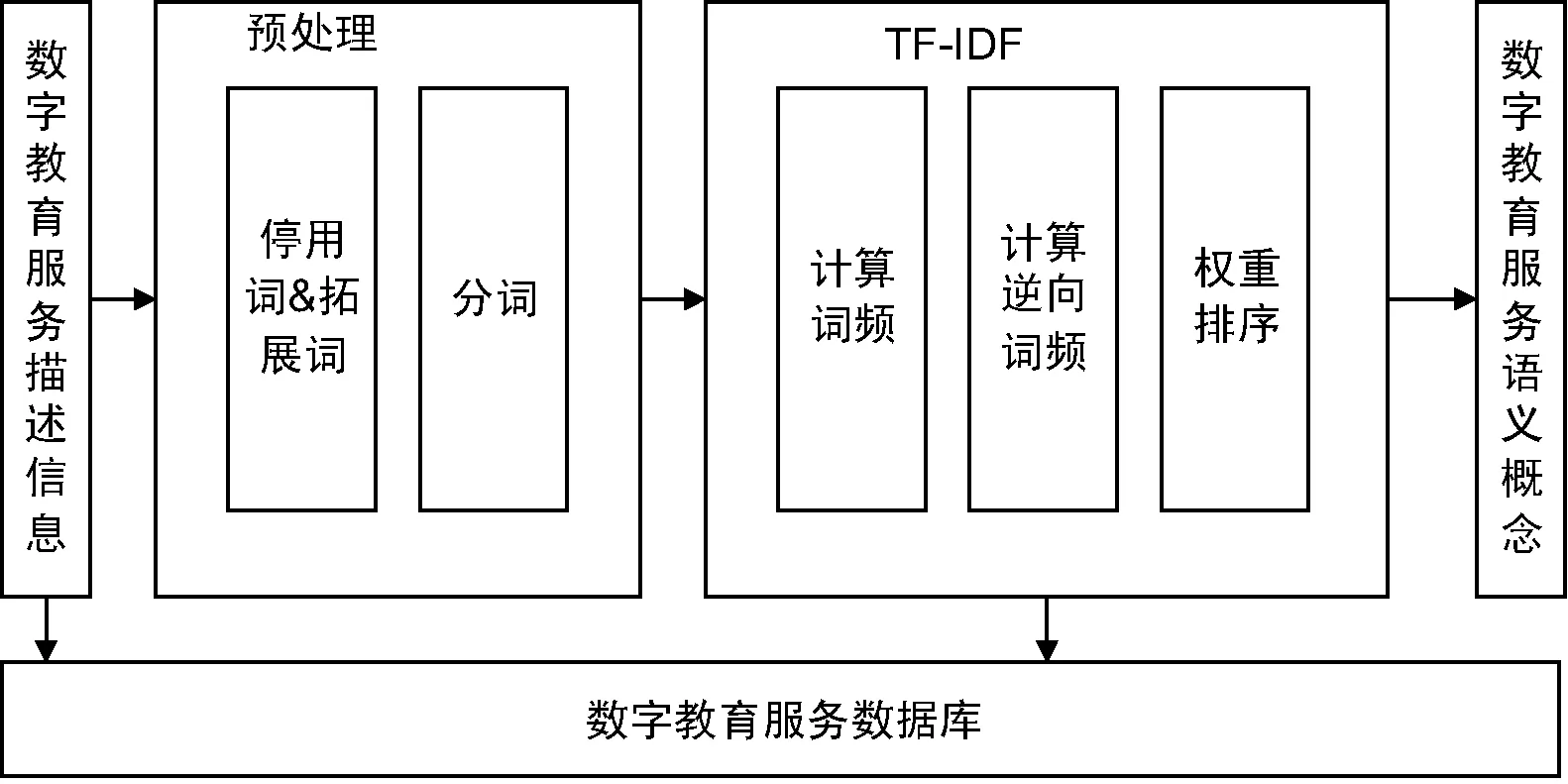
图2 数字教育服务语义特征提取过程
提取出概念之后需要为概念之间添加关系,考虑到数字教育领域的特殊性,部分、相关等关系可以减少计算相似度时的误差,达到更好的推荐效果。概念关系见表6。

表6 概念关系
3.1.2 基于矩阵和张量分解的知识水平预测
学生知识水平预测问题是一个典型的评分预测问题,基于学生过去对知识点的掌握情况,预测学生未来对该知识的掌握情况。矩阵分解技术是解决评分预测问题最成功的技术之一。对于学生知识水平预测问题,将其映射到矩阵分解,其中学生映射到用户(user),第一次正确尝试映射到评分(rate),知识映射到(item)。
矩阵分解的任务是近似的将一个矩阵表示成两个矩阵相乘的形式[19],如X≈WHT。X是用户矩阵,W∈U×K矩阵中每一行u是表示一个包含K个用来描述学生的潜在因子的向量,H∈I×K矩阵中每一行i表示一个包含K个用来描述知识的潜在因子的向量。令wuk和hik分别代表矩阵W和H的元素,那么指定学生u对于知识i的掌握水平为:
(1)
本文使用随机梯度下降的方法进行矩阵分解,损失函数定义为:

(2)
其中λ是为了防止过拟合而引入的范数。
学生测试过程中存在“Guess”和“Slip”的情况[20],即学生不具备问题涉及的知识或技能但是猜对了答案,和学生知道问题涉及的知识但是求解过程中犯错这两种特殊情况。带偏置的矩阵分解可以将这两种情况隐式的考虑进来,因此将式(1)调整为:
(3)
其中μ是数据集中学生表现平均数,bu和bi分别代表用户偏置和物品偏置。
时间因素是学习活动中的重要的上下文,一般来讲学习的次数越多,学生对于一个知识的掌握程度就越好。为了解决时间效应,借鉴文献[21]对于时间效应问题的研究,在用户和物品的二维矩阵中引入第三个维度时间构成张量,则指定学生u对知识i在时间t时的预测掌握水平定义如下:
(4)

(5)
其中qtk表示引入的时间维度,式(5)利用过去的次表现的Tmax均值来预测当前的学生表现。
3.1.3 客观意图推理
在数字教育服务语义模型和学生知识水平预测的基础上,结合预期教育活动推理用户的客观意图。基于数字教育语义模型,利用特征相似度算法计算知识与数字教育服务和预期教育活动的匹配度,选择前K项作为匹配项。一个知识可以对应多个预期教育活动和数字教育服务。
对于用户与单项数字教育服务匹配项,其客观意图倾向为:
(6)
式中,Wi和Ti分别表示经历维度中的预期教育活动的重要性和时间权重,P表示上一步计算出的学生预期表现,学生预期表现与学生需求成反比。
3.2 主观意图分析
在数字教育服务推荐场景中,将用户对数字教育服务的喜好转化为对数字教育服务的主观意图,即用户对满足自身需求的数字教育服务的主观标准。比如,某些用户对数字教育服务信息完善度的达标标准是信息完善度达80%以上,对信息及时性的标准是信息定期更新。在用户的观念维度中,保存了用户对不同要素重要性排序。
在上一节数字教育语义词典的基础上,结合课题组的在线教育可信云项目确定数字教育服务指标,使用AHP或其他手段对指标权重进行量化。最后通过IF-THEN语句建立面向用户喜好需求的服务达标条件计算[22]。
在进行主观意图倾向计算时,遍历需求指标下的达标条件,若满足一条达标条件,则该需求指标得分加1。最终根据不同指标的权重加权求和。对于用户与单项数字教育服务,其主观意图倾向为:
(7)
其中Ci为数字教育服务指标得分,wi为该指标的权重。
3.3 群体性意图分析
为了提高推荐结果的准确性,同时避免数据稀疏性带来的问题,将用户所在群体的意图作为考虑因素。不同用户群体对于数字教育服务评价指标有不同的偏好,即对于各指标的权重是不同的。在数字教育服务推荐场景中,群体可以按照年龄、学历、职业、所在地区等因素划分,如表7所示。

表7 用户群体划分
将用户所在群体广泛认可的服务推荐给用户,不同群体对数字教育服务指标的认可程度不同。本文课题组对于数字教育服务评价模型有过深入的研究[23],将数字教育评价指标划分为四大类,本文根据不同群体设置不同的权重,见表8。
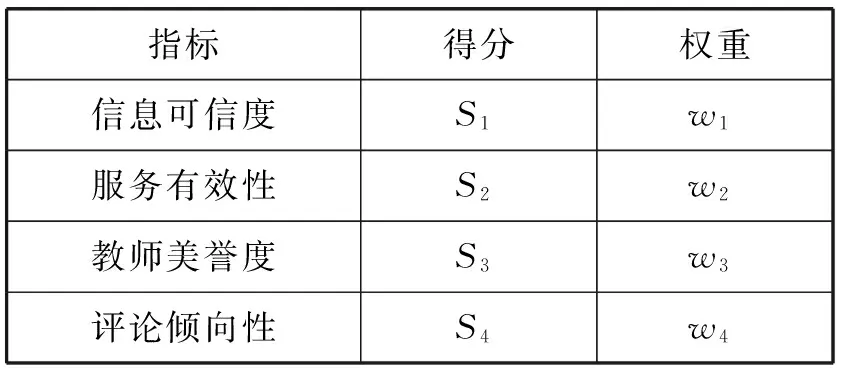
表8 数字教育服务评价指标
对于用户与单项数字教育服务,其群体性意图倾向为:
(8)
3.4 服务综合推荐
结合前三节的内容,用户与单项数字教育服务的意图倾向为:
Intentiontotal=α1×Intentionsubjective+α2×
Intentionobjective+α3×
Intentiongroup
(9)
其中Intetionsubjective、Intentionobjective和Intentiongroup分别为用户约单项数字教育服务的主观意图倾向、客观意图倾向和群体性意图倾向,α1、α2和α3为权重值。
相关文献指出[24],对于不同类型的数字教育服务,用户会有不同的考虑方式。对于正式学习,学生更加注重功利性和目的性,是在外因驱动的,而对于非正式学习,则是学生内因驱动的。比如对于提升学生学习就业能力相关的数字教育服务,学生会主要考虑客观因素,即考虑自身知识掌握情况以及长远期目标;而对于一些兴趣爱好类的数字教育服务,学生更加倾向于客观因素,即数字教育服务满足自身的需求。在本文中,仅考虑正式学习,从观念维度获取三种意图的重要性排序,使用AHP层次分析法对三种意图的权重进行量化,最终获得推荐列表。
4 人性化数字教育原型系统与实验评价
4.1 原型系统实现
“云私塾”考虑到移动平台的计算和存储能力限制,将数据和计算均放在服务端进行,客户端与服务端通过SOAP协议,以Web Service的方式进行数据交互。软件架构上使用了成熟的开发框架,包括展示层的Ionic框架,数据层的Jena OWL框架等,如图3所示。
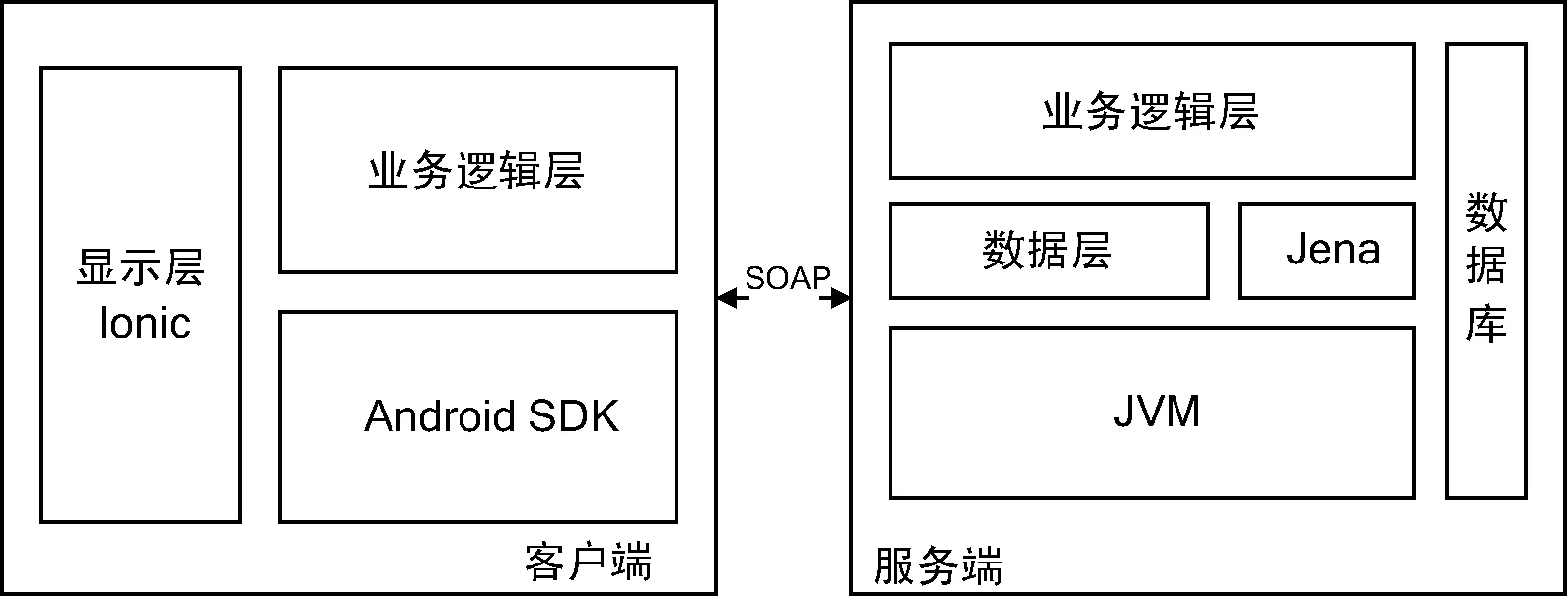
图3 总体架构图
4.2 实验评价
4.2.1 实验指标
本文使用准确率、召回率和排序优先度作为测试指标来分析。准确率即为推荐服务列表中用户感兴趣的比例,召回率表示用户感兴趣的服务被推荐的概率,排序优先度表示用户感兴趣的服务在推荐列表的中的排序,排序优先度越小越好。
针对用户u,候选数字教育服务集合S={S1,S2,S3,…},推荐系统向u推荐的数字教育服务集合为RS={RS1,RS2,RS3,…},在RS中用户感兴趣的数字教育服务集合为RSI={RSI1,RSI2,RSI3,…},在集合S中用户感兴趣的数字教育服务集合为SI={SI1,SI2,SI3,…},则对用户u,其准确率、召回率、排序优先度的计算公式如下:
1) 准确率:
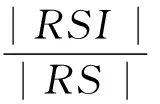
2)召回率:

3) 排序优先度:
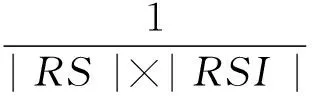
4.2.2 实验结果与分析
“云私塾”基于实验室研究平台过往实验中完善了的用户数据,选取用户模型完成度50%以上的用户,通过奖励机制邀请该部分用户参与到实验中,邀请受试者完善个人信息,并按照自己数字教育服务各项指标进行排序。最终得到的用户模型构建完成度如表9所示。

表9 多维用户模型完整度
针对张量分解,测试迭代次数与算法执行结果的关系,其余因素不变,当迭代次数分别取值20、50、100、150时的算法执行结果如表10所示。

表10 迭代次数对算法执行结果的影响
实验结果表明,在张量分解过程中,随着迭代次数的增加,算法对于学生表现张量的拟合越来越好。推荐算法准确率和召回率均有所提高,排序优先度有所下降。
同时比较了本文提出的算法与FISM[25]和基于条目的推荐方法IBR[26]之间的结果。实验结果表明,本文提出的基于多维用户模型的推荐方法确实可以提高推荐效果,提升用户的满意度实验结果比较见表11。
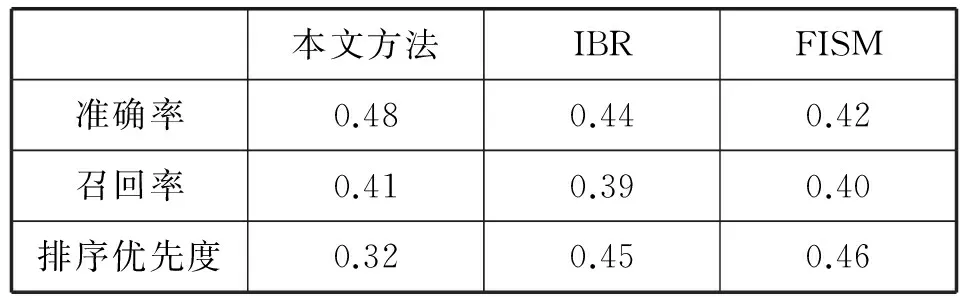
表11 不同算法实验结果比较
5 结 语
传统的针对数字教育的推荐技术学生数据来源单一,难以反映学生的本质需求,数字教育领域的针对性不足。
本文结合“云私塾”项目,提出了基于多维用户模型的数字教育服务推荐方法。人性化数字教育的多维用户模型是该方法的基础,从生理、性格、观念、知识、经历和环境六个维度出发,使用可穿戴设备、问卷调查、Web数据抓取等方式进行用户建模。基于数字教育多维用户模型,从客观意图、主观意图以及群体性意图依次分析推理,最终整合为推荐结果列表。考虑了数字教育领域的特殊性,利用张量分解技术推理学生知识掌握水平,并结合学习目标、主观偏好、学生所在群体等因素,实验结果表明准确率及满意度均有提升,具有应用意义。
后续工作中,我们将针对数字教育的特殊性,针对其他影响学习活动的因素进行扩展,比如学习风格、学习路径等,使该方法能更有效地应用在数字教育推荐中。
[1] Mallinson B,Sewry D.eLearning at Rhodes University—A Case Study[C]//Advanced Learning Technologies,2004.Proceedings.IEEE International Conference on,2004:708-710.
[2] 郑嘉宝.2016年中国在线教育行业市场现状及发展趋势分析[EB/OL]. [2016-05-25].http://www.qianzhan.com/analyst/detail/220/160524-6481830d.html.
[3] Tang T,Mccalla G.Smart Recommendation for an Evolving E-Learning System:Architecture and Experiment[J].International Journal on E-Learning,2005,4(1):105-129.
[4] 沈剑平.数字灵魂模型及其在智能推荐中的应用研究[D].上海:复旦大学,2015.
[5] Kobsa A.Generic User Modeling Systems[J].User Modeling and User-Adapted Interaction,2001,11(1-2):49-63.
[6] Lytras M,Pablos P O D.Software Technologies in Knowledge Society J.UCS Special Issue[J].Journal of Universal Computerence,2011,17(9):1219-1221.
[7] Dráždilová P,Obadi G,Slaninová K,et al.Computational Intelligence Methods for Data Analysis and Mining of eLearning Activities[M]//Computational Intelligence for Technology Enhanced Learning,2010:195-224.
[8] Verbert K,Manouselis N,Ochoa X,et al.Context-Aware Recommender Systems for Learning: A Survey and Future Challenges[J].IEEE Transactions on Learning Technologies,2012,5(4):318-335.
[9] Staikopoulos A,O’Keeffe I,Rafter R,et al.AMASE:A framework for supporting personalised activity-based learning on the web[J].Computer Science & Information Systems,2014,11(1):343-367.
[10] Cox S M,Chen K.Exploratory Examination of Relationships between Learning Styles and Learner Satisfaction in Different Course Delivery Types[J].International Journal of Social Science Research,2013,1(1):64-76.
[13] Michael Brent.Physical factors that affect learning[EB/OL].[2008-01-01].http://www.ehow.co.uk/info_8210852_physical-factors-affect-learning.html.
[14] Cattell H E P.The Sixteen Personality Factor (16PF) Questionnaire[M]//Understanding Psychological Assessment.Springer US,2001:187-215.
[15] Wikipedia.Big Five personality traits[EB/OL].[2016-03-29].https://en.wikipedia.org/wiki/Big_Five_personality_traits.
[16] Xu X,Mellor D,Xu Y,et al.An Update of Murrayan Needs[J].Journal of Humanistic Psychology,2014,54(1):45-65.
[17] Li J.Mind or Virtue Western and Chinese Beliefs About Learning[J].Current Directions in Psychological Science,2005,14(4):190-194.
[18] 陈昊.服务类产品语义组合和推荐技术研究[D].上海:复旦大学,2015.
[19] Koren Y,Bell R,Volinsky C.Matrix Factorization Techniques for Recommender Systems[J].Computer,2009,42(8):30-37.
[20] Pardos Z A,Heffernan N T.Using HMMs and bagged decision trees to leverage rich features of user and skill from an intelligent tutoring system dataset[C]//Proc.Knowledge Discovery and Data Mining Cup 2010:Educational Data Mining Challenge (2011).
[21] Control A.Temporal Link Prediction Using Matrix and Tensor Factorizations[J].Acm Transactions on Knowledge Discovery from Data,2010,5(2):190-205.
[22] 周丰.面向需求的用户建模及服务推荐研究[D].上海:复旦大学,2014.
[23] 周为伟.在线教育可信云的研究与实现[D].上海:复旦大学,2016.
[24] 杨晓平.正式学习与非正式学习之概念辨析[J].贵州师范学院学报,2015,31(5):80-83.
[25] Kabbur S,Ning X,Karypis G.FISM:factored item similarity models for top-N recommender systems[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2013:659-667.
[26] Deshpande M,Karypis G.Item-based top-N recommendation algorithms[J].Acm Transactions on Information Systems,2004,22(1):143-177.
RECOMMENDATIONSYSTEMSFORE-LEARNINGSERVICESBASEDONMULTI-DIMENSIONALUSERMODEL
Yao Fan Li Yinsheng
(SchoolofSoftware,FudanUniversity,Shanghai201203,China)
Currently for e-learning recommendation systems, the user modelling data source is single, the user intention analysis is not deep, the lack of digital education's pertinence consideration, the accuracy and the satisfaction degree are limited. This paper proposes a recommendation method of e-learning services based on multi-dimensional user model, taking into account the factors such as students’ mastery level of knowledge, learning goals and students’ groups, and reasoning from objective intention, subjective intention and group intention. Based on the requirement of the project, a prototype system of e-learning application based on the recommendation method is developed. The experimental results show that the proposed method can improve the accuracy, recall rate and sort priority of the system with only a single user factor.
Recommendation system User modelling E-Learning
TP3
A
10.3969/j.issn.1000-386x.2017.10.023
2016-12-01。姚帆,硕士,主研领域:推荐系统。李银胜,副教授。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
当代陕西(2022年4期)2022-04-19
法律方法(2021年3期)2021-03-16
当代陕西(2020年22期)2021-01-18
中华诗词(2019年7期)2019-11-25
创新作文(5-6年级)(2018年11期)2018-04-23
南风窗(2016年19期)2016-09-21
小天使·六年级语数英综合(2014年3期)2014-03-15
延河(下半月)(2014年3期)2014-02-28
