
结合用户活跃度的协同过滤推荐算法
2017-10-18 00:49曲朝阳宋晨晨任有学刘耀伟独健鸿
东北电力大学学报 2017年5期
曲朝阳,宋晨晨,任有学,刘耀伟,牛 强,独健鸿
(1.东北电力大学 信息工程学院,吉林 吉林 132012;2.国网吉林省电力有限公司 吉林供电公司,吉林 吉林 132000;3.吉林市丰满发电厂,吉林 吉林 132108)
结合用户活跃度的协同过滤推荐算法
曲朝阳1,宋晨晨1,任有学2,刘耀伟2,牛 强2,独健鸿3
(1.东北电力大学 信息工程学院,吉林 吉林 132012;2.国网吉林省电力有限公司 吉林供电公司,吉林 吉林 132000;3.吉林市丰满发电厂,吉林 吉林 132108)
为了解决协同过滤推荐算法中存在的流行偏置问题,提出一种结合用户活跃度的协同过滤推荐算法(UACF)。该算法考虑用户活跃度对推荐结果的影响,通过对用户活跃度进行聚类分析,针对不同聚类结果中的用户进行分类处理,并引入到相似度计算过程中,以提高相似度计算的可靠性。典型数据集上的对比实验表明该算法能够较好的提高推荐准确率。
用户活跃度;聚类;协同过滤;Top-N推荐
传统的搜索引擎无法做到千人千面,不能根据用户的兴趣爱好提供个性化的服务。信息的爆炸使得信息的利用率反而降低,这种现象被称之为“信息过载”[1]。信息过载导致人们难以快速、准确地从浩瀚的信息资源中寻找所需的信息。为解决信息过载问题,互联网技术经历了导航、检索和推荐三个阶段。
推荐系统[2-4]是为解决Internet上的信息过载问题而提出的一种智能系统,能从Internet的大量信息中向用户自动推荐出符合用户兴趣偏好或需求的项目,从而更好地解决互联网信息日益庞大与用户需求之间的矛盾。目前,推荐技术被广泛应用到电子商务[5]、数字图书馆[6]、新闻网站[7]等系统中。
协同过滤(collaborative filtering)是迄今为止应用最成功的个性化推荐技术[8]。在当前大数据时代下,协同过滤技术显得尤为重要[9]。协同过滤推荐算法主要通过利用用户的历史行为信息为用户建模进而做出推荐的一类算法。最初的协同过滤推荐算法是基于用户的协同过滤推荐算法[10,11]。该算法认为,一个用户会喜欢和他有相似爱好的用户喜欢的项目。因此,他们利用相似用户的信息进行近邻搜索,然后基于近邻用户的行为信息预测用户兴趣,向用户推荐项目。基于项目的协同过滤算法是另一种经典的协同过滤算法,它认为一个用户会喜欢和他之前喜欢的项目类似的项目[12]。该算法主要利用相似项目的信息进行近邻搜索和用户行为预测,然后依据预测结果向用户推荐项目。
由于项目的相似度相对用户的相似度稳度,所以基于项目的协同过滤算法是目前业界应用最多的算法。无论是亚马逊网,还是Netflix、Hulu、YouTube,其推荐算法的基础都是该算法[13]。尽管协同过滤在个性化推荐方面取得较大成功,但其存在着诸多亟待解决的问题和挑战,主要包括:数据稀疏性、流行偏置、动态性和冷启动等。
现有解决流行偏置问题的方法均是针对基于用户的协同过滤推荐算法,利用项目流行度进行调节处理,本文是针对基于项目的协同过滤推荐算法,利用用户活跃度进行调节处理。
1 相关工作
1.1 基于项目的协同过滤Top-N推荐算法主要过程
基于项目的协同过滤推荐算法是利用项目间的相似度,给用户推荐与用户历史项目相关度高的前N个项目。主要包括相似度计算和推荐两个过程。
相似度计算方法有多种,本推荐算法采用的是修正的余弦相似度

(1)

通过相似度计算可以得到一个项目相似度矩阵,每行记录了一个项目与其他所有项目的相似度,由于算法只要取出Top-N个相关项目,所以在相似度矩阵存储时,设定近邻个数即仅存储前K个相关的项目。
推荐的总体流程如下,在对某一用户u进行Top-N推荐时,针对用户u的历史项目集C,将项目集C中的一个项目i取出,与项目i相似的项目集合记为Ti,对项目集Ti中的每个项目j,项目i和项目j的相似度乘以用户对项目i的评分记入最终推荐集T中,将最终推荐集T中包含的用户历史项目集C中的项目进行剔除,对最终推荐集T进行排序,取前N项进行推荐。
1.2 长尾分布和用户活跃度
长尾理论(The Long Tail)是网络时代兴起的一种新理论,由美国人克里斯·安德森提出[18]。互联网上的很多数据分布符合长尾理论,这个分布在互联网领域称长尾分布。很多研究人员发现,用户行为数据也蕴含着这种规律。
用户活跃度是指用户产生过行为的项目总数,符合长尾分布。用户越活跃,用户的数量越少。但这少部分的用户评分过的项目数量较多,在相似度计算时,由于该部分用户评论过大部分的项目,所以根据其进行的相似度计算结果准确性降低。本文将在相似度计算公式中构造包含用户活跃度的调节函数,降低活跃用户的影响,提升非活跃用户的影响。
不可否认,漓江画派之所以在全国产生重大的影响,其中一个重要的因素就是“依托广西艺术学院这个学术和人才培养平台”。漓江画派集中了广西各画种的代表性画家和美术评论家,他们大多数是毕业或工作于广西艺术学院,漓江画派促进会学术委员会常务理事中超过半数是学院的专业教师。可以说,作为漓江画派的主要人才聚集地, 具有80年办学历史的广西艺术学院无论在艺术创作和理论研究方面,还是在人才培养和队伍建设方面,都为漓江画派的发展做出了突出的贡献。实施画派与学院相互依托、互为平台、共同提高的策略,成为加强漓江画派人才队伍建设的重要手段。
2 UACF算法的设计与实现
在推荐系统中,存在着一种强者恒强的“马太效应”,推荐系统倾向于推荐那些流行度高的项目,导致推荐准确率降低。而用户活跃度越高,其了解流行项目的概率越大,用户活跃度越低,用户的兴趣越具有个性化,所以在相似度计算时,引入用户活跃度,调节不同活跃度用户的评分数据对相似度计算的影响,如公式(2)。

(2)
其中:F(u)为使用用户活跃度构造的调节函数。
由于用户活跃度不同对相似度计算的结果影响不同,所以对用户活跃度进行聚类处理后得到活跃度的分类结果,然后针对用户所属的活跃度分类结果对用户评分数据使用不同的相似度计算公式。采用K-Means聚类算法,设定分成3簇。使用聚类算法后,将用户活跃度分为三类。簇1表示的是活跃度较高的一类,记为Umax,簇2表示的是活跃度居中的一类,记为Umid,簇3表示的是活跃度较低的一类,记为Umin。针对不同活跃度的用户进行不同的处理,如公式(3)。
(3)
其中:m、n为常数,用于调节实验结果;f(u)为用户u的活跃度即用户u评分过的项目总数。由于长尾分布的特点为绝大多数个体的尺度很小,而只有少数个体的尺度相当大,故在设计公式时利用log(·)函数进行处理。
对于活跃度较大的簇Umax,将其活跃度增强使调节函数结果减小。对中间簇Umid,对其进行正常的调节。对活跃度较小的簇Umin,将其活跃度减小使调节函数的结果增大,增强活跃度低的用户的影响。在各个类别中,具体的活跃度f(u)是计算得出,f(u)可以更加细化的区分每个类中的用户数据,是该用户数据对相似度计算结果的影响不同。总体来说,首先是进行分类,然后针对每个类别的数据再细化处理。
UACF算法的相似度计算部分的伪代码描述如下:
Step1读取数据,计算得到用户ID及用户评分的项目ID及相应的分数。
Step2用户活跃度分类标记。利用K-Means算法对用户活跃度进行聚类,并标记每个用户所处的类别。
Step3利用公式(2)、公式(3)计算任意两个项目间的相似度。如果项目相似度集合中存在给定的项目i和项目j的数据,则直接取出其相似度,否则进行相似度计算。如果项目i和项目j的相似度小于需要的K个项目的相似度中的最小的一个则舍弃,否则存储。
3 实验及结果分析
3.1 测试数据集
数据来源MovieLens数据集,包含943名用户对1682个电影的100000条评分数据,数据包含用户ID、电影ID、评分值、时间戳四种属性值。评分值分为1-5,评分值5为最高评分。数据集的稀疏等级为1-100000/(943×1682)=93.7%。使用前,将数据集划分为训练集和测试集。训练集和测试集分别占整个数据集的80%和20%。
3.2 评测指标
本文着重点在于提高推荐结果的准确率。为了验证算法有效性,在实验中采用的指标为:准确率、召回率、覆盖率、新颖度。准确率和召回率计算公式分别如公式(4)和公式(5)所示。
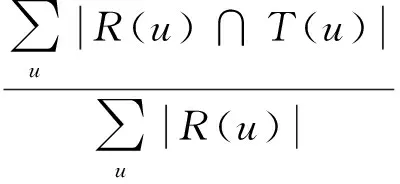
(4)

(5)
其中:R(u)为推荐系统为目标用户u推荐的N个项目集合;T(u)为用户u在测试集上的项目集合。覆盖率定义如公式(6)所示。

(6)
其中:I为所有项目集合;R(u)为推荐系统目标用户u推荐的N个项目集合;u为用户集合U中的一个用户。覆盖率表示最终的推荐列表中的项目占总项目集合的比例。如果任何一个项目都被推荐给至少一个用户,那么覆盖率就是100%。新颖度定义如公式(7)所示。

(7)
其中:I为所有项目集合;i为集合I中的一个项目;P(i)为所有评论过项目i的用户个数;K为项目集合I中的项目个数。

图1 不同算法的TopN推荐准确率
3.3 实验结果及分析
本文设计了三组实验进行验证。本文对协同过滤算法中的参数进行了设定,设定最近邻存储个数item Nearest Neighbor Number、最近邻使用个数TopK、推荐个数TopN。
采用上述数据集,依次对文献[12]中提出的基于项目的协同过滤推荐算法(ICF),文献[17]中提出的基于项目流行度的协同过滤TopN推荐算法(PopItemCF),使用公式(3)中中间活跃度处理方法的算法(LNCF)和本文提出的结合用户活跃度的协同过滤推荐算法(UACF)进行对比实验,选用同一数据集,TopK为50,设m=100.0,n=4.0,TopN从5开始,每次增加5,至50,对比不同TopN时的推荐准确率,结果如图1。
从图1中可以看出,本文提出的UACF算法较其他算法的推荐准确率有了明显的提高。UACF算法较ICF算法在上述实验中平均推荐准确率提高了25.79%。
为了对比以上算法在其他评测指标上的表现,作进一步的实验。设TopN为10,TopK为50,m=100.0,n=4.0,各算法的准确率、召回率、覆盖率和新颖度的实验结果数据如表1。

表1 各算法的评测指标结果
从表1中可以看出,UACF算法较其他算法,在准确率和召回率上明显得到提升。以下为m、n值的选择实验,通过调节m或者n的值,观察实验结果,最终确定m、n值的选择范围。设m=1,n从1开始,每次自增1,至100,测试推荐准确率和覆盖率,结果如图2。从图2可以看出,随着n的增加,推荐准确率先增加到达峰值后缓慢下降。这说明调高活跃度低的用户数据在相似度计算中的权重值即在一定范围内增加n的值可以提高推荐准确率。综合考虑准确率和覆盖率的分布,在确保准确率较高的情况下有较高的覆盖率,n的选取范围为17-23。
设n=1,m从10开始,每次自增10,至1000,测试推荐准确率和覆盖率,结果如图3所示。

图2 不同n下的试验结果图3 不同m下的试验结果
从图3可以看出,提高m值使活跃度高的用户数据在相似度计算中降低权重对推荐准确率影响较小,在m值大于100时,准确率和覆盖率基本围绕一个值上下震荡。在m等于510时为测试结果的最大值,而且当前结果的覆盖率也较大。
通过上述实验对比,选取m=510,n=20,评测指标结果值如表2。

表2 较好m和n值下的试验结果
通过测试不同的m、n值,同时选取较好的m、n测试值后,各项指标均有所提升。说明合理设置m、n值可以提高推荐效果。m值大于100后对结果影响较小,n值在大于23后可以提高结果的覆盖率和新颖度,提高长尾项目的推荐比例。
4 结 论
本文提出了一种解决流行偏置问题的新方法,该算法比基于项目的协同过滤算法的推荐准确度提高27%,可以更精准的向用户提供推荐结果。本文从不同活跃度用户的评分数据的有效性入手,提出针对用户活跃度进行聚类处理的方法,较好的提高了相似度计算的可靠性。通过对用户活跃度聚类进行用户分类的方法速度快、效果明显,可以适用于所有的基于项目的协同过滤推荐算法。
[1] A.F.Rutkowski,C.S.Saunders.Growing pains with information overload[J].Computer,2010,43(6):94-95.
[2] 郭晓利,韩啸.电网知识协同发现策略研究[J].东北电力大学学报,2014,34(1):94-98.
[3] A.Zenebe,A.F.Norcio.Representation,similarity measures and aggregation methods using fuzzy sets for content-based recommender systems [J].Fuzzy Sets and Systems,2009,160(1):76-94.
[4] G.Adomavicius,A.Tuzhilin.Toward the next generation of recommender systems:a survey of the state-of-the-art and possible extensions[J].Knowledge and Data Engineering,IEEE Transactions on,2005,17(6):734-749.
[5] 余力,刘鲁.电子商务个性化推荐研究[J].计算机集成制造系统,2004,10(10):1306-1313.
[6] 杨艳.数字图书馆中兴趣度推荐算法[J].哈尔滨工程大学学报,2009,30(6):658-662.
[7] 乔向杰,张凌云.近十年国外旅游推荐系统的应用研究[J].旅游学刊,2014,29(8):117-127.
[8] 冷亚军,陆青,梁昌勇.协同过滤推荐技术综述[J].模式识别与人工智能,2014,27(8):720-734.
[9] 曲朝阳,孙立擎,许劭庆,等.基于B+树的电力大数据分布式索引[J].东北电力大学学报,2016,36(5):80-85.
[10] P.Resnick,N.Iacovou,M.Suchak,et al.GroupLens:an open architecture for collaborative filtering of netnews[C].Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work.ACM,1994:175-186.
[11] 徐蕾,杨成,姜春晓,等.协同过滤推荐系统中的用户博弈[J].计算机学报,2016,39(6):1176-1189.
[12] G.Linden,B.Smith,J.York.Amazon.com recommendations:item-to-item collaborative filtering[J].Internet Computing,IEEE,2003,7(1):76-80.
[13] 项亮.推荐系统实践[M].北京:人民邮电出版社,2012:51-52.
[14] J.S.Breese,D.Heckerman,C.Kadie.Empirical analysis of predictive algorithms for collaborative filtering[C].Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence.Morgan Kaufmann Publishers Inc.,1998:43-52.
[15] R.Jin,J.Y.Chai,L.Si.An automatic weighting scheme for collaborative filtering[C].Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2004:337-344.
[16] G.Adomavicius,Y.Kwon.Improving aggregate recommendation diversity using ranking-based techniques[J].Knowledge and Data Engineering,IEEE Transactions on,2012,24(5):896-911.
[17] 郝立燕,王靖.基于项目流行度的协同过滤TopN推荐算法[J].计算机工程与设计,2013,34(10):3497-3501.
[18] S.Peltier,F.Moreau.Internet and the ‘Long Tail versus superstar effect’ debate:evidence from the French book market[J].Applied Economics Letters,2012,19(8):711-715.
Abstract:In order to solve the problem of popularity bias in recommendation system,we propose a novel collaborative filtering recommendation algorithm,UACF.UACF considers the influence of user activity on the recommended results.It applies cluster analysis algorithm to handle user activity and uses different activity adjustment formula to deal with different clustering results.This method is introduced into the process of similarity calculation to improve the reliability of similarity calculation.experiments on typical data sets show that the algorithm can achieve more accurate rating recommendations than the conventional methods.
Keywords:User activity;Cluster analysis;Collaborative filtering;Top-N recommendation
RecommendationsBasedonCollaborativeFilteringbyUserActivity
QuZhaoyang1,SongChenchen1,RenYouxue2,LiuYaowei2,NiuQiang2,DuJianhong3
(1.School of Information Engineering,Northeast Electric Power University,Jilin Jilin 132012;2.Jilin Power Supply Company,State Grid Jilin Electric Power Co.,ltd.,Jilin Jilin 132000;3.Full Power Plant in Jilin City,Jilin Jilin 132108)
TP391
A
2017-03-09.
国家自然科学基金项目(51277023)吉林省科技计划重点转化项目(20140307008GX)
曲朝阳(1964-),男,博士,教授,主要研究方向:智能信息处理.
电子邮箱:qzywww@nedu.edu.cn(曲朝阳);172342547@qq.com(宋晨晨);1406989666@qq.com(任有学);frqkycg@163.com(刘耀伟);qzynedu@qq.com(牛强);531146846@qq.com(独健鸿)
1005-2992(2017)05-0074-06
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
考试与评价·高一版(2020年4期)2020-11-12
学生天地(2020年31期)2020-06-01
铁道通信信号(2019年6期)2019-10-08
学生天地(2019年30期)2019-08-25
中国交通信息化(2018年5期)2018-08-21
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
