
爬虫算法在淮北职业技术学院就业指导系统中的应用研究
2017-09-18 03:14:50宋夏
淮北职业技术学院学报 2017年5期
宋 夏
(淮北职业技术学院 建筑工程系,安徽 淮北 235000)
爬虫算法在淮北职业技术学院就业指导系统中的应用研究
宋 夏
(淮北职业技术学院 建筑工程系,安徽 淮北 235000)
目前,由于高校扩招,高校毕业生逐年增加,就业难的问题逐渐凸显。淮北职业技术学院每年面临20%的学生难就业的问题。另外,该校的就业指导系统不完善,无法满足就业处进行就业预测,制定科学就业指导方案的需要。运用决策树算法构建就业分析模型,并进行进一步的验证,可以改进就业指导系统,提高就业指导工作效率。
爬虫技术;就业指导系统;决策树算法
0 引言
海量信息的涌现和科学技术的不断进步,越来越多的行业开始运用爬虫技术进行数据挖掘。网络爬虫也叫网络蜘蛛,是一个从互联网中自动抓取网页的程序。[1]2016年高效毕业生人数达到765万,大学生就业压力大、找工作难成为一大困境。[2]对于高校来说,毕业学生信息数据庞大,利用简单的搜索、查询难以满足大量信息的处理需要。爬虫技术能够按照一定的顺序爬取相关的信息,并且能够对所搜集的信息进行数据处理。因此,很多高校也在逐渐引进数字挖掘技术并运用到学校的日常管理工作中,利用数字挖掘技术有针对性地分析学生和用人单位的信息,为高效人才培养计划的制定提供数据支持。目前,数据挖掘技术的不断发展,爬虫策略的广泛应用,相关研究人员开发了一系列的算法。其中,决策树算法能够实现对于数据的自动归类,以树形的形态进行呈现。该算法具备其他算法所不具有的直观性、易学性以及快速性等优点。利用决策树算法进行数据预测,可以帮助高职毕业生规避就业风险,正确认识自身价值,同时能够为高校专业设置、培养方案制定以及就业指导提供科学的依据。[3]
淮北职业技术学院是1999年7月经国家教育部批准的公办全日制普通高等学校。学院高度重视毕业生就业工作,以社会就业形势为风向标,以人才的高质量输出为己任,对于学生的实习、技能培训以及就业指导等提供全方位的支持和帮助,为学生高质量就业创造良好的条件。尽管淮北职业技术学院的就业工作取得了很大的进展,但是由于各种主客观原因的影响,每年仍有20%以上同学处于待就业或者“慢就业”状态。
1 淮北职业技术学院学生就业情况和存在的问题
1.1 淮北职业技术学院就业情况
1.1.1 毕业生概况
淮北职业技术学院2016届毕业生共有3067人,其中高职(统招)毕业生人数2892人,中专部(“3+2”及五年一贯制)毕业生人数175人,分属41专业。2016届毕业生男女比例约为1:1.47,女生人数偏多,主要集中在适合女生性别优势的专业,如护理、空乘、财会、服装等,这些专业所在系部的招生规模也比较大。该院毕业生以汉族生源居多且多为省内生源,省内省外比例约为59:1,省内生源以淮北市生源最多,占省内生源的36.77%,淮北与省内其他城市生源比例约为1:1.72,省内其他城市的生源也多为淮北周边城市,如宿州、亳州、阜阳等。由此可见,淮北职业技术学院生源多来自以院校所在地——淮北为核心的皖北地区。2016届毕业生具体情况如表1所示。

表1 2016届毕业生概况
1.1.2 毕业生就业情况
截至2016年12月底,淮北职业技术学院2016届已就业毕业生为2685人,就业率为87.54%。2016届毕业生流向主要集中在卫生和社会工作、制造业、居民服务、修理和其他服务业、建筑业、信息传输、软件和信息技术服务业等行业,充分体现出学院以机械制造、金融商贸、电子信息等作为主干专业的特点。毕业生所从事的职业多为各类技术人员、业务人员、服务人员和操作人员;所从业的单位也多为城镇社区、中小微企业等,与毕业生专业和学历相吻合,充分体现国家对职业院校毕业生面向基层就业的号召。但由于各种主客观原因,有20%以上同学处于待就业或者“慢就业”状态。其中非困难生的就业率要低于困难生的就业率,占87.27%。
1.2 淮北职业技术学院学生就业存在的问题
第一,对于就业指导老师而言,信息采集工作困难,就业指导系统落后,缺乏先进的数据挖掘技术来提高就业指导工作的效率。
第二,对于学生本身而言,很多学生好高骛远、眼高手低,对工作标准要求过高,难以沟通疏导。
面对学生的信息采集工作费时费力的现状,就业指导老师很难通过人工采集的方式来全面搜集学生的信息,也无法精确地为学生匹配相应的岗位信息。因此,需要借助于有针对性、高效的计算机技术建立高效的就业信息服务平台来解决“慢就业”和“难就业”问题。
2 决策树算法在淮北职业技术学院就业指导工作中的应用
2.1 数据挖掘的决策树技术
决策树方法是数据挖掘的核心技术之一。[4]作为一种预测模型,该算法能够呈现对象属性和对象值之间的对应联系。在决策树模型当中,节点代表对象,分叉代表对应的对象值,叶节点所关联的是从根节点到叶节点对应的对象值。决策树是数据挖掘技术中的一种典型的技术,不仅能够对数据进行分析,还可以通过数据分析进行预测。
2.2 C5.0算法
C5.0决策树算法是从跟节点不断地分枝生长,该根节点包含了所有训练集数据,并最终将所有训练集数据归到某一叶节点。该算法中,最为关键的问题是选取最佳的分类变量与切分点。
在经典的ID3决策树算法中,最佳分类变量是根据信息增益来选取的。信息增益即是信息熵,用来衡量系统的不确定性大小,信息增益越大,即信息熵越小,表明系统不确定性越低,反之,信息增益越小,则信息熵越大,表明系统不确定性越高。所以,在构建决策树的时候如果选取某一分类变量时使得相应的信息增益率增大,则表明分类与预测效果越好。在本章节的研究中,采用C5.0算法来构建决策树的时候便是依据信息增益率来确定最优的分类变量。信息增益率的数学公式如下:
其中,InfoGainRation(A)即是决策树的信息增益率,而InfoGain(A)即是决策树的信息增益。一般来说,信息增益难以评估决策树分类变量选取的优劣,主要是因为容易受到分组变量划分数目的影响与干扰,如当类目数增加时会导致信息增益增加,影响分组变量选取的正确性。因此,本文中选取信息增益率来代替信息增益,保证分组变量的选取更加准确。
同分组变量的选取一样,划分点的选取也依据信息增益率。由于C5.0算法生成的是二叉树,所以优化划分点的选取时将数据一分为二。在构建决策树的过程中,计算不同的分类变量与切分点组合下的信息增益率,并将信息增益率取最大值的分类变量与切分点视作最优。
2.3 就业分析模型构建与结果分析
用C5.0算法进行分析要经过三个环节,首先是数据的选取阶段,然后就业分析模型构建,最后对模型加以验证,对结果进行评估。
2.3.1 数据选取
数据准备阶段比较重要,因为数据的质量会最终影响模型的构建及结果的输出。在大学生就业分析模型中,选取淮北职业技术学院3年来共计12450名毕业生的相关数据信息作为研究样本。
但是,在学校教学管理系统的就业管理模块中存储的原始数据的维度属性太多。考虑到不相关属性约简与冗余属性约简,最后选取了毕业生的个人基本情况、在校表现以及就业意向三个方面的16个属性,包括性别、政治情况、专业分数、期望月薪、就业单位性质等。其中,以就业单位类型为标识属性,剩下的则是决策属性。属性名和对应类型如表2所示:

表2 属性名以及类型
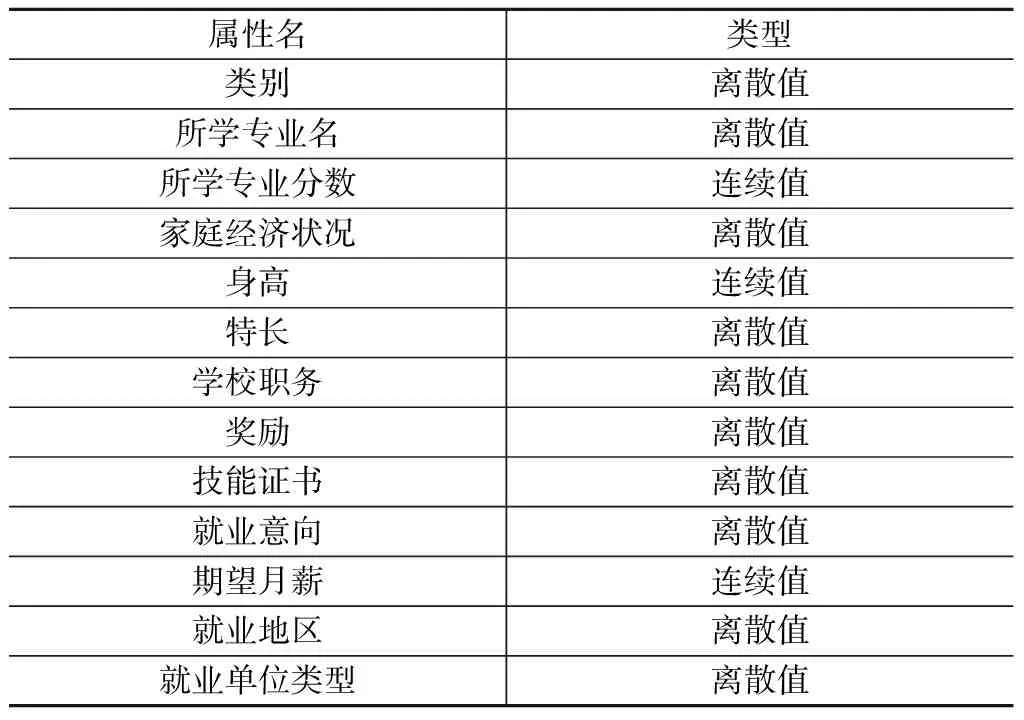
属性名类型类别离散值所学专业名离散值所学专业分数连续值家庭经济状况离散值身高连续值特长离散值学校职务离散值奖励离散值技能证书离散值就业意向离散值期望月薪连续值就业地区离散值就业单位类型离散值
其中,部分样本数据如表3所示:

表3 部分样本数据集
由于样本数据无法直接用来建模,还需要进行相应的预处理,即数据离散化与分层处理,主要采用分箱、直方图分析以及直观划分等。对专业分数、身高、期望月薪三个属性进行离散化处理后,结果如表4至表6示:

表4 专业分数离散化处理
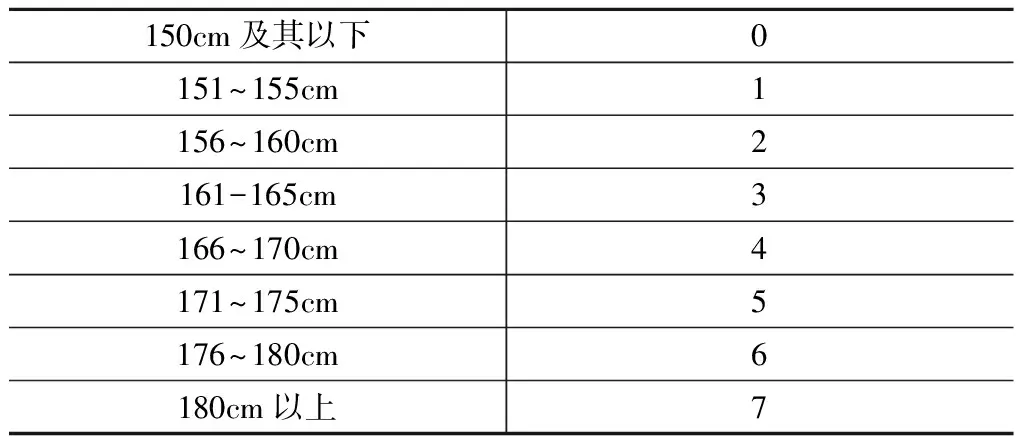
表5 身高离散化处理

表6 期望月薪离散化处理
而对于其他属性则按期不同类别来赋予相应的标签化数值,如表7至表9所示:

表7 就业单位性质离散化处理
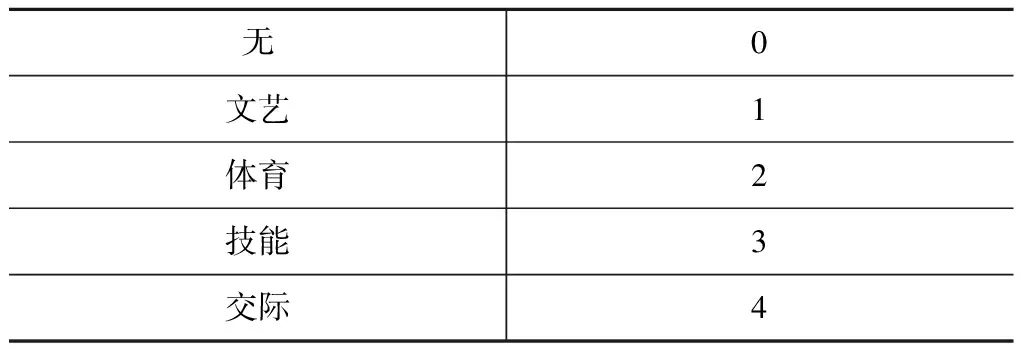
表8 个人特长离散化处理

表9 政治面貌离散化处理
采取上述方法对数据进行处理化之后,即转化为计算机语言可以识别的知识,其中部分样本数据经过数据处理之后如表10所示:

表10 离散化处理后的部分样本数据集
2.3.2 就业分析模型
本实验旨在通过升级后的决策树算法对于就业单位类型进行预测,接着对该预测模型加以测试,查看其是否准确。实验主要有三个步骤:第一,构建就业单位类型预测模型;第二,对比预测结果与实际的样本数据;第三,对预测结果进行分析。其中,将12450名毕业生的相关数据分为两份,8300份为训练数据集,用来学习与构建决策树,而4150份为测试数据集,用来评估模型的准确率。
由于样本数据维度比较大,所构建的决策树分支较多,不能一一罗列,所以这里将以专业成绩为结点的分支为例,对其挖掘的结果进行分析。其中,该决策树分支如图1所示:

图1 决策树部分分支结构
现将上述决策树得到的推理结果转换为IF…THEN的形式,其中部分结果如下所示:
IF“专业分数=优” and “所学专业名=生物工程”and“奖励=国家奖学金”THEN“读书深造”。
IF“专业分数=优” and “所学专业名=生物工程”and “奖励=无” and “个人特长=文艺” THEN “事业单位”。
IF“专业分数=优” and “所学专业名=生物工程”and “奖励=无” and “个人特长=无” and “技能证书=无” THEN“私营企业”。
IF“专业分数=中” and “所学专业名=计算机” and “期望月薪=6000以上” THEN “私营企业”。
IF“专业分数=中” and “所学专业名=计算机” and “期望月薪=6000以上”and “就业意向=区内”THEN “私营企业”。
IF“专业分数=中” and “所学专业名=计算机” and “期望月薪=3500-4000” and “就业意向=区内” THEN “国有企业”。
IF“专业分数=中” and “所学专业名=汽车服务” and “学校职务=无” and “就业意向=区内” THEN “国有企业”。
IF“专业分数=中” and “所学专业名=汽车服务” and “学校职务=无” and “就业意向=区内” THEN “合资企业”。
通过对决策树所提供的规则进行深入分析,能对学生的就业规律有清晰的认识,如专业成绩优,在校期间获得过国家奖学金,则多为选择升学深造;若成绩为良或者中,专业偏理科,就业意向为区内,则大部分选择公务员或者事业单位;若专业成绩中等,专业为工科,在校期间担任过学生干部,则多数选择了国有企业;若专业为计算机,意向月薪为6000以上,就业意向为区内,则多数选了私营企业等等。
同时从相关规则的分析中可以发现,影响学生就业单位选择的关键外因在于学生的专业分数、所学专业名、奖励、学校职务、就业意向、意向月薪等。所以,对于学生的就业率和就业质量的提高,高校应着重培养学生的专业技能,并对学生的就业观念加以引导。
2.3.3 结果评估
在上述决策树模型与相应的推理规则之后,为了验证其有效性与准确性,我们采用之前划分出来的测试集样本对上述模型进行测试。在这里用预测准确率来衡量算法的优劣,其中预测准确率=对比结果一致的样本数/测试集总样本数。首先,将得到的部分预测分类结果和实际就业结果进行对比,具体情况如表11所示:
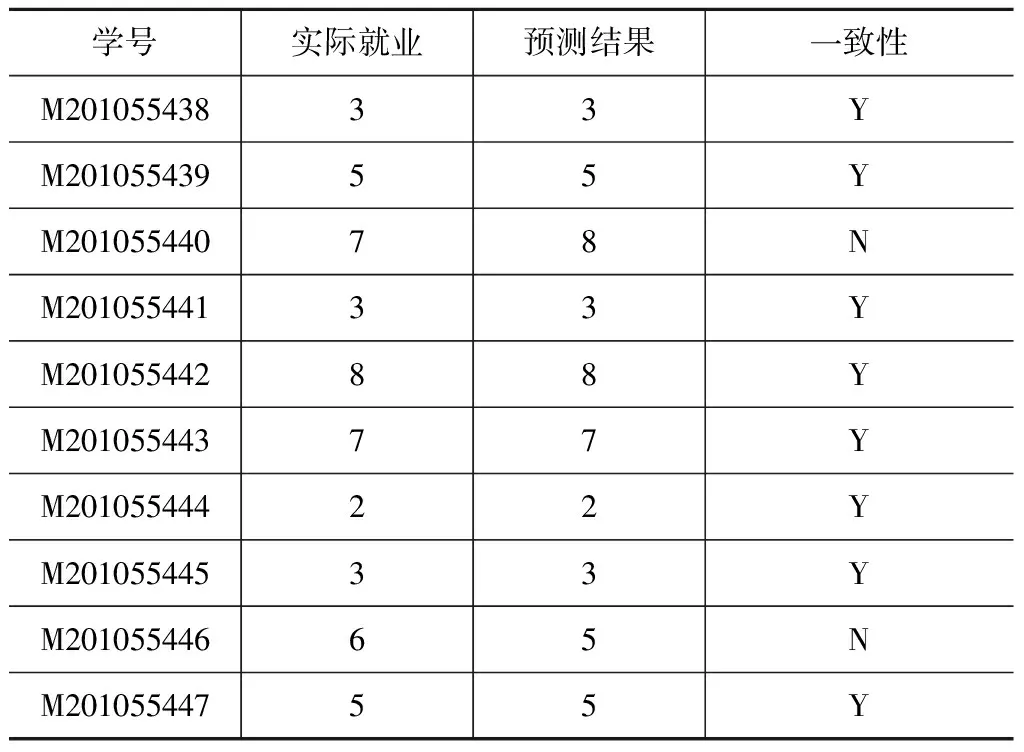
表11 部分预测结果与实际结果对比表
从上面部分测试结果来看,十位学生就业单位预测中有8位是正确的,2位为预测错误。此外,统计所有测试数据集的预测结果与实际结果,其中4150个样本数据中预测准确的共计3527,预测错误的是598,即模型的准确率为84.9%(表12):

表12 就业预测模型准确率
根据上面的验证结果,发现所构建的学生就业分析模型准确度较高,具有非常大的参考价值,能够为指导大学生进行职业规划提高决策支持。
3 结语
随着爬虫的研究不断深入,爬行策略与算法也在不断完善,爬虫技术对于收集信息方面的应用也日趋广泛。[5-6]利用决策树算法能够提高爬虫程序的爬取准确率。[7]本文结合了淮北职业技术学院的就业现状,运用决策树算法创建大学生就业分析模型,并以大学生成绩与就业信息为数据来源进行实证研究,验证了模型的有效性。通过该算法能够分析出专业分数、奖励、就业意向等因素对于学生的就业选择的影响最大,因此能够为高校招生就业处工作人员提供就业指导依据,提高就业指导决策的效率,促进学生就业率的提升。
[1] 田俊. 浅谈主题网络爬虫关键技术[J]. 天津职业院校联合学报,2017(3):78-85.
[2] 韩冰. 基于数据挖掘的就业困难学生认定研究[J]. 中国大学生就业,2017(1):44-50.
[3] 王彦新,王红. 用大数据助推高职毕业生就业难题化解的研究[J]. 办公自动化,2016(7):26-28.
[4] 刘哲,赵志刚. 数据挖掘技术在大学生就业分析中的实证研究[J]. 沈阳师范大学学报(自然科学版),2016(1):105-108.
[5] 于娟,刘强. 主题网络爬虫研究综述[J]. 计算机工程与科学,2015(2):231-237.
[6] Houqing Lu,Donghui Zhan,Lei Zhou,etc.An Improved Focused Crawler:Using Web Page Classification and Link Priority Evaluation[J].Mathematical Problems in Engineering,2016(3).
[7] Ali Seyfi,Ahmed Patel,Joaquim Celestino Júnior. Empirical evaluation of the link and content-based focused Treasure-Crawler[J]. Computer Standards & Interfaces,2016(44).
责任编辑:何玉付
2017-07-01
宋夏(1987—),女,安徽淮北人,助教,研究方向:计算机应用技术。
TP315;G718.5
:A
:1671-8275(2017)05-0136-05
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
现代信息科技(2021年21期)2021-05-07 02:54:12
淮北师范大学学报(自然科学版)(2021年1期)2021-03-19 08:11:58
淮北师范大学学报(自然科学版)(2020年2期)2020-06-29 11:56:02
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
学生天地(2016年10期)2016-04-16 05:14:49
