
K邻域分块自动加权的单样本人脸识别算法*
2017-09-18 00:28魏明俊许道云秦永彬
计算机与生活 2017年9期
魏明俊,许道云,秦永彬
贵州大学 计算机科学与技术学院,贵阳 550025
K邻域分块自动加权的单样本人脸识别算法*
魏明俊,许道云+,秦永彬
贵州大学 计算机科学与技术学院,贵阳 550025
在人脸识别问题中,当每类训练样本有且仅有一个时,由于类内缺乏足够的特征变化信息来预测人脸复杂的特征变化,从而导致常用分类算法的识别准确率急剧下降。目前最好的解决方法大致可分为两类:一是生成虚拟的训练样本以扩大训练集;二是学习稀疏变化字典以表示复杂特征变化。针对此问题,在引入稀疏变化字典来表示人脸复杂特征变化的基础上,提出一种基于K邻域分块自动加权的单样本识别算法。通过对测试样本进行分块,然后对每一个子分块求K邻域分块,以组成虚拟的同类别测试样本集;同时提出了一种自动加权策略,对这些分块在分类中的比重进行加权,最后通过一种改进的投票机制确定分类结果。通过与已有的单样本识别算法进行比较,并在公共人脸数据库AR、CMU Multi-PIE和ORL上进行实验,结果表明该方法有助于提高单样本识别问题的分类准确率。
单训练样本;人脸识别;稀疏变化字典;K邻域分块;自动加权;投票机制
1 引言
人脸识别是一种经典的模式识别问题,虽然经过国内外学者近几十年的研究已取得较多的研究成果,但如何保证人脸存在复杂特征变化时的准确识别仍是一项挑战。解决该问题的通常做法是:扩大训练样本集中每类样本的规模。但在一些实际应用中,如自动判定护照、身份证、驾驶证等持有者是否为本人持有,根据某段监控中截取的面部图像跟踪或搜索犯罪嫌疑人时,可获得的图像有且仅有一个,称这类问题为单训练人脸问题(single sample per person,SSPP)。单训练样本识别问题会极大地影响常用人脸识别算法的效率[1],导致一些基于线性子空间学习的算法,如线性判别分析(linear discriminant analysis,LDA)及其改进算法[2]的效率大打折扣,即使是鲁棒性较强的稀疏表示分类(sparse representation based classification,SRC)算法[3],表现效果也较差。
针对此问题,国内外学者从不同角度提出了一些解决方法。文献[4]从图像梯度方向提出一种子空间学习算法,通过提取鲁棒的局部特征来进行识别;而文献[5]则通过在图像分片中学习判别特征来进行识别。尽管这两种算法能提高识别率,但对光照、表情变化较敏感。文献[6]通过引入视觉子空间的混合特征空间(hybrid-eigenspace)方法来生成虚拟训练样本,提出了对姿态变化、光照变化较为鲁棒的单训练样本人脸识别算法;文献[7]在基于人脸具有对称性这个理论前提下,利用对称原则生成对称的虚拟样本,达到增加训练样本的目的;文献[8]则使用奇异值分解产生虚拟训练样本;文献[9]将两个原始样本的均值作为虚拟训练样本。虽然生成虚拟训练样本可在一定程度上解决单样本问题,但由于虚拟样本与原始样本类内间距较小,无法表示人脸图像复杂的类内变化。因此在实际应用中,当人脸特征变化较复杂时,此类算法效果普遍不理想。
正是由于利用原始训练样本生成虚拟样本的局限性,文献[10]从变化字典中学习一种姿态不变子空间,用来解决单样本识别时的面部姿态变化问题;文献[11]提出一种扩展稀疏表示分类算法(extended SRC,ESRC),通过构造类内变化字典来表示待检测样本的特征变化;文献[12]针对SSPP问题,基于训练字典和一般扩展字典之间的关系,提出了一种稀疏变化字典学习算法。通过引入稀疏变化字典可以解决待分类样本的特征变化问题,但这些字典学习算法却忽略了人脸一些重要特征部位(如眼部、嘴部、鼻子等)的独特性,而这些重要特征部位的独特性则是正确分类的关键。文献[13-15]通过对图像进行分块后,重要的特征部位则会分到某一个子分块中,而对每一个子分块进行分类则可以很好地利用这一特性。
基于此,本文提出了一种基于K邻域分块自动加权的单样本识别算法。结合稀疏变化字典来表示人脸特征变化部分,同时对所有样本进行图像分块,并在图像分块的基础上求出距离每个分块最近的K个分块,并对这些分块在分类中的比重进行自动加权,最后通过一种投票机制确定待分类样本的分类结果。在同等条件下,通过在标准人脸数据库AR、CMU Multi-PIE和ORL上进行对比实验,本文算法均获得了最高的识别准确率。
2 构造扩展变化字典及分块加权
通过原始训练样本生成的虚拟训练样本无法预测待检测样本的复杂特征变化,因此本文采用构造稀疏变化字典来模拟出人脸的各种表情、光照、姿态、遮罩等特征变化。
2.1 构造稀疏变化字典
在单训练样本人脸识别问题中,假定共有n类训练样本,则训练样本总数为n。定义原始训练集为G=[g1,g2,…,gn]∈Rm×n,m 为样本维度,gk∈Rm为第 k类训练样本,k=1,2,…,n。待分类样本y由G可表示为:

其中,e表示残差。运用稀疏表示模型,求得待检测样本y在G上的表示系数α:

其中,ε>0为残差约束;||.||k表示Lk范数约束。原始稀疏约束模型k=0,但求解L0范数最小化是NP_hard问题,因此直接求解不可行。但压缩感知理论证明了在足够稀疏的前提下可用L1范数代替L0范数进行稀疏约束[16],因此以下的稀疏模型都会用L1范数进行稀疏约束。式(2)在实际使用中,通常用下面的拉格朗日式子代替:

其中,λ为常数项约束,通过式(3)求出表示系数α=[α1,α2,…,αn],αi为由第 i类训练样本表示时的表示系数。最终y的分类结果为:
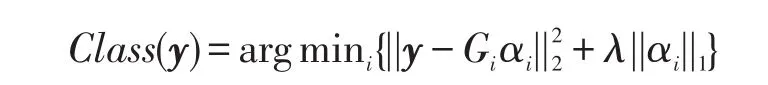
受限于每类只有一个训练样本,且待分类人脸图像特征变化不可控,直接使用SRC算法时,误分类概率较大。这是因为当待检测样本相对原始训练样本存在光照、表情、姿态、遮罩等特征变化时,字典G无法准确表示待检测样本。因此本文引入包含各种复杂特征变化的字典X,X与G类别无交集。记X=[XrXv],其中Xr为正常稳定的参考样本子集,而Xv则对应于存在光照、表情、姿态、遮罩等特征变化的变化样本子集。假定X包含M种特征变化,即,其中表示第 j种特征,j=1,2,…,M。则通过变化样本与参考样本Xr之间的差值,得到变化字典X,即:
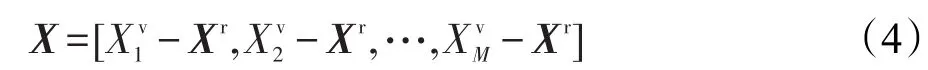
则y由训练字典G和变化字典X协同表示为:

其中,α和β分别为y在训练字典G和变化字典X上的表示系数。与式(3)原理相同,α和 β可通过下式求得:
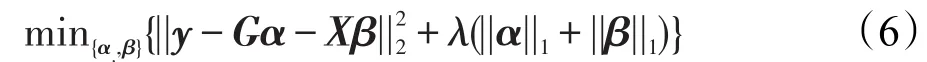
由于变化字典X是由包含特征变化的样本与其对应的特征稳定样本之间的差值构成的,从而变化字典X与具体样本无关,只包含变化特征部分。只要变化字典包含的特征变化种类足够多,则理论上可以表示任何未知分类人脸样本的特征变化部分。而特征不变部分则可以由训练字典中对应的原始训练样本表示,可以避免人脸特征变化对分类算法的干扰。
2.2 图像分块
本文引入变化字典X主要是用来表示待检测样本的特征变化部分,避免特征变化对正确分类的干扰。由于每类训练样本仅为一个,当一些训练样本相似度较高时,即样本距离较近时,容易误分类。虽然相似样本整体距离较近,但是具体到某个局部特征部位时,如眼睛、鼻子、眉毛等时,个体差异性则较大。因此可以对图像进行分块,分别求得每一子分块分类结果,然后通过某种投票策略确定最终分类结果。采用分块策略,可以将每一个分块结果当作一个弱分类器,而这些弱分类器作用在一起则构成强分类器。
对图像分块或分片是指将原始图像按照某种规则分成几块。如图1(a)为原始训练样本,对其进行平均4分块时,得到图1(b)。通过分块可以突出分块所包含的特征,而不同样本具有不同的特征则是可分类的前提,因此分块可在一定程度上提高识别准确率。

Fig.1 An example of image sub-block图1 图像分块示例
一般图像分块分为无重叠分块和带重叠分块,本文采用带重叠分块,即分块之间有一定的重叠。之所以采用重叠分块,一是为了增加弱分类器的数量,使得最终决策分类更准确;二是因为通过重叠分块可以使得面部某些重要特征(眼睛、鼻子、嘴巴、眉毛等)不被划分到不同块,同时可以预测一些人脸姿态变化。
假定原始图像大小为 p×q,分块大小为 pr×pc,分块步长为 po(即每隔 po距离取下一个分块),则可分块数记为S:
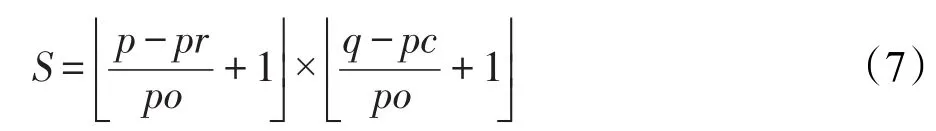
其中,“L」”为向下取整运算。
分块步骤如下:
(1)对字典进行分块。对G和X分别进行分块,G={G1,G2,…,GS},X={X1,X2,…,XS},Gi为所有训练字典的第i个分块构成的集合,Xi则为所有变化字典的第i个分块构成的集合,i=1,2,…,S。
(2)对待分类样本 y分块,y={y1,y2,…,yS},yi为y的第i个分块,i=1,2,…,S。
2.3 邻域分块及其权重系数定义
引入变化字典相当于增加了训练字典的规模,由原始训练字典G和变化字典X构成新的训练字典。而在对待分类样本y进行分块时,分别取出与每个分块距离最近的K个分块,这K个分块与原分块类别相同,相当于增加了待分类样本的个数,由于这K个近邻分块相对原分块只是发生了很小的位移,在一定程度上还可以用来预测人脸姿态变化。如图2(a)为原始图像,先分块得到图2(b),然后对其每个分块分别求4近邻分块,得到图2(c)。

Fig.2 An example of 4 nearest patches图2 最近邻分块示例
记第s(s=1,2,…,S)个分块的K个近邻分块构成的集合为,其中表示第s个原始分块本身,为其第i个近邻分块,i=0,1,…,K。
引入灰度图像上像素点坐标这一概念,记为L(x,y),表示某像素点的坐标位置。x、y分别表示灰度图像矩阵的第x行y列。定义第s个分块与其对应的K个近邻分块的距离集合为,其中表示第s个原始分块与其第k个近邻分块的距离,距离定义如下:
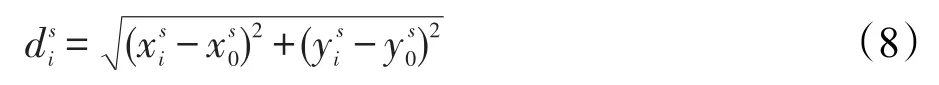

关于权重设置的说明:与原始分块ys越近的近邻分块,与原始分块越相似,权重系数设置越大;距离越远的分块,与原始分块相差较大,则将其权重系数设置越小。
2.4 分类策略
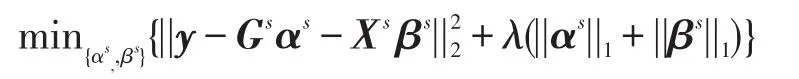

通过下式自动对每个近邻分块的残差进行加权求第s个分块由第 j类表示时的残差:

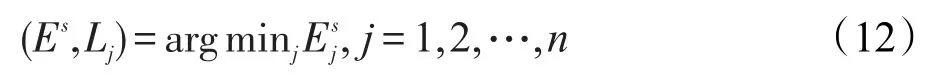
其中,Es为最小残差值;Lj为获取最小残差值的类标。
依次求得S个分块的分类结果与对应的标签集,记为:
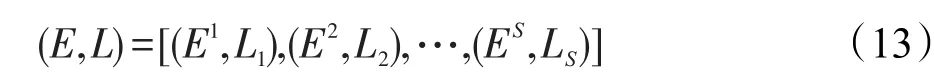
对式(13)S个分类结果进行投票,记Vi为分类结果为第i类的投票数;ei为最小残差。当Lj=i时,Vi增加1,且 ei=min(ei,Ej),其中 j=1,2,…,S ,i=1,2,…,n,记投票结果为:
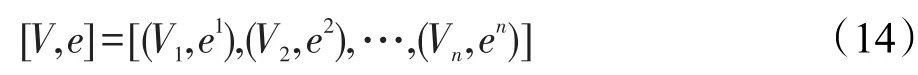
则待分类样本y的最终分类结果为:
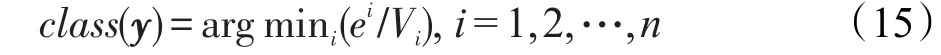
即最终分类结果为S个分块投票后获取最小残差比的分类类标。这里之所以采用残差比而不是投票数决定分类结果,是为了避免两个或两个以上的类别同时获得最大投票数的问题。
3 基于K邻域分块自动加权的稀疏表示分类算法
原始训练样本构成字典G=[G1,G2,…,Gn],由式(4)生成变化字典X。
(1)输入待分类样本y。
(2)对G、X、y分别进行分块,分块数为S,G={G1,G2,…,GS},X={X1,X2,…,XS},y={y1,y2,…,yS}。
(3)初始化变量s=1,初始化S个分块的表示残差及类标:(E,L)=[(E1,L1),(E2,L2),…,(ES,LS)]=[(0,0),(0,0),…,(0,0)]。
(4)求分块ys及其K近邻分块构成的分块集合,
(5)根据式(8)求s分块与其K个近邻分块的距离Dists,由式(9)根据距离自动设置权值
(6)根据式(10)求n类训练样本分别表示时的残差,记为,由式(11)更新(ES,LS)。
(7)若 s<S,返回(5),否则执行步骤(8)。
(8)根据式(14),计算投票结果 [V,e],然后求分类结果class(y)=arg mini(ei/Vi)。
(9)返回分类结果。
4 实验结果与分析
本文在 AR[17]、CMU Multi-PIE[18]和 ORL[19]3 种人脸数据库上进行实验,并与现有的单样本识别算法进行对比。对比算法包括基本分类算法NN(nearest neighbor)[20]、SVM(support vector machine)[21],基于生成虚拟训练样本的文献[8]中的算法,基于稀疏字典学习的算法 ESRC[11]、SVDL(sparse variation dictionary learning)[12]。同时为体现K邻域分块自动加权(automatic weight,AW)的效果,分别对比无分块、不求邻域分块的基本分块(patch)、K邻域分块平均加权(average weight,AVG)的SRC[3]算法。
4.1 参数设置
常量参数设置:稀疏约束模型中稀疏约束参数λ设置为0.05;3个人脸数据集上的分块大小均设置为20×20,分块步长设置为10,邻域分块数K=4。
4.2 变化字典X的生成方式
实验中,选择人脸数据库中的部分样本集共m类,每类n张图像用来生成变化字典X,选择每类样本的第一张图片作为Xr,剩余的n-1个样本用来构成Xv,生成变化字典规模为m×(n-1)。其中m的数量根据不同人脸数据库在实验中具体设定,n与具体的数据库有关。
4.3 AR人脸数据库上的实验结果
AR人脸库大约包含类别数为126,每类样本数约为26,每类包含不同的光照、表情、遮罩等特征变化。本文选取其中的100类,男女各占一半作为实验样本,选择其中的20类用来生成稀疏变化字典X。剩下的80类中,每类的第一张无明显特征变化的人脸构成训练集,测试集分为3类:光照变化、墨镜、口罩(或围巾)。样本集每类样本数大小均为6,实验中所有图像尺寸统一处理为80×80像素。
从表1中可以看出,在光照、墨镜、口罩3种特征变化下,本文算法SRC(AW-KPatch)均获得最高识别准确率。相比K邻域平均分块算法提高1.3%、3.3%、3.0%,相比SRC(Patch)平均提高10%~15%,相比SRC则提高明显;同时对比字典学习算法SVDL以及ESRC也有所提升,相比其他算法则提升效果明显。且采用稀疏变化字典以及分块后,在墨镜和口罩这两种遮挡条件下,算法识别率提高明显。
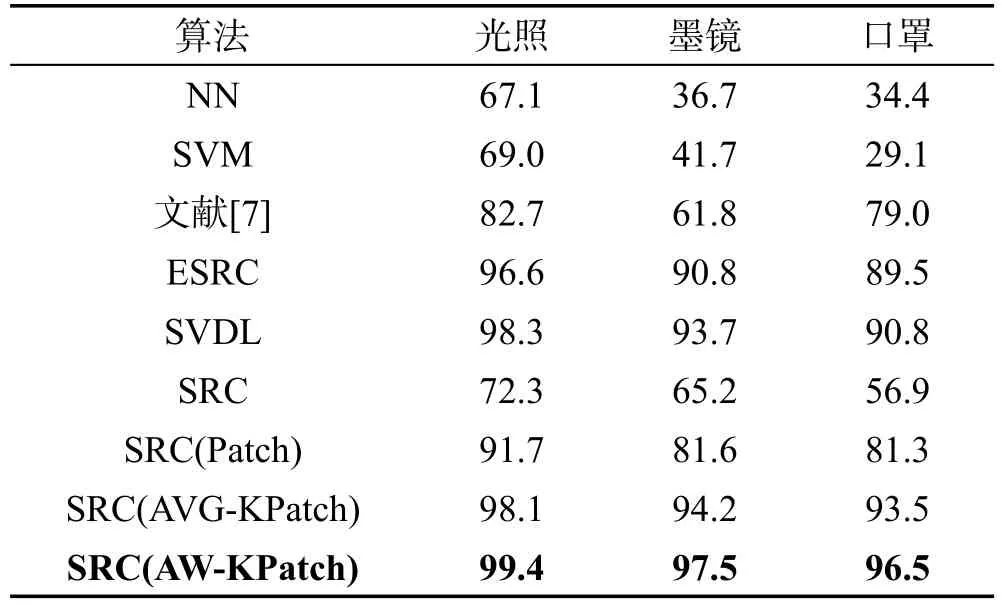
Table 1 Recognition rate of different algorithms onAR database表1 不同算法在AR数据库上的识别准确率 %
4.4 CMU Multi-PIE数据库上的实验结果
CMU Multi-PIE数据库中人脸种类数多达337类,包含光照、表情、姿态等特征变化。本文实验选取160类,其中120类用作训练集,40类用来生成变化字典。使用不包含姿态变化的中立人脸每类选择一个作为训练集;测试集主要为表情变化,分为笑脸(S1-smile)、惊吓(S2-surprise)和眯眼(S2-squint)3类,测试样本集每类样本数为6。所有图像的尺寸使用Matlab自带函数resize统一处理为80×80像素。
由于CMU Multi-PIE较为复杂,面部特征变化尺度较大且复杂,从而在惊讶、眯眼测试集上各种算法的识别率都较低。但从表2中可以看出,本文算法识别效果较其他算法仍有一定的改进,在惊讶(S2-surprise)这个测试集上虽比SVDL低4.4%,但仍比其他算法准确率高;在笑脸(S1-smile)和眯眼(S2-squint)测试集上,则比效果第二好的算法识别率提高2.6%、5.7%。
4.5 ORL人脸数据库上的实验结果
ORL人脸数据库包含40类,每类10幅图像,共400幅图像。每类图像均包含各种姿态变化,同时也伴随有光照、表情以及是否带有眼镜等变化。由于样本较少,为满足SRC算法的稀疏性,随机选择其中的20类图像用来构成变化字典X;剩下的20类,选择每类第一张人脸作为训练集,剩下的9张包含各种特征变化的图像作为测试集,将所有灰度图像的尺寸处理为40×40像素。
由于ORL人脸库主要包含姿态变化,通过表3可以看出,引入稀疏变化字典X以及K邻域分块加权后的SRC(AW-KPatch)相比原始SRC识别率提升23.3%,相比平均加权的SRC(AVG-KPatch)提高0.8%,相比SVDL及ESRC提高2.1%、7.9%,相比其他算法则效果明显。同时,本文算法即使姿态变化下仍能达到90.0%的识别率,因此算法也具有一定的姿态鲁棒性。
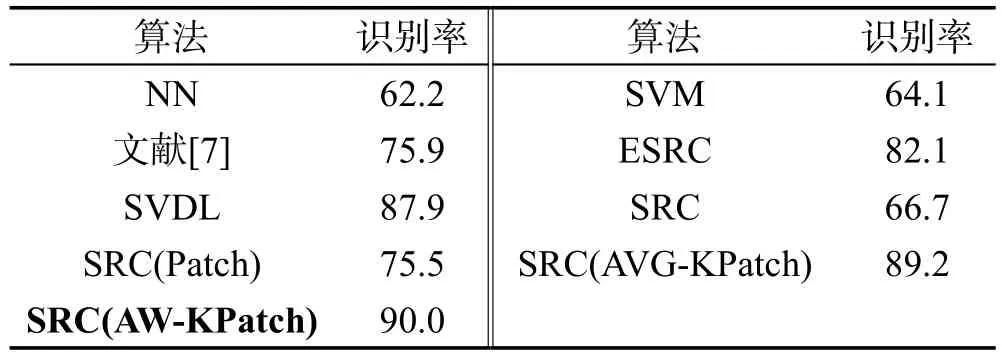
Table 3 Recognition rate of different algorithms on ORL database表3 不同算法在ORL数据库上的识别准确率 %
最后,通过表1、表2、表3的实验数据综合分析可知,引入稀疏变化字典X后,特征变化部分可以由X表示,因此可以在一定程度上提高单训练样本情况下的SRC算法识别率;同时结合K邻域自动分块加权策略,获得了最好的识别结果;并且在相同的人脸特征变化条件下,通过对比基于AVG-KPatch、Patch、无分块的SRC算法,证明了K邻域分块自动加权方法的有效性。虽然有关采用K近邻样本的方法前人文献也有叙述[22-23],但本文将其与图像分块相结合并应用于单样本人脸识别中,取得了最优的结果。
5 结束语
本文针对单训练样本识别问题,提出了一种基于K邻域分块自动加权的单样本识别算法。结合稀疏变化字典来预测特征变化,对待分类样本进行K近邻分块,根据距离自动设置不同近邻分块在决策分类中的权重系数,最后通过投票机制获取最终分类结果。同时通过与其他一些有效的单样本人脸识别算法对比,验证了本文算法在识别准确率上,相比字典学习算法、分块算法都有较大的改进。但本文没有考虑重要局部特征(眼睛、鼻子、嘴部等)所在的分块在投票中应具有更大的表决权,下一步将研究在投票分类时给予重要特征部位以较大的表决权是否有助于提高分类准确率。
[1]Tan Xiaoyang,Chen Songcan,Zhou Zhihua,et al.Face recognition from a single image per person:a survey[J].Pattern Recognition,2006,39(9):1725-1745.
[2]Belhumeur P N,Hespanha J P,Kriegman D J.Eigenfaces vs.fisherfaces:recognition using class specific linear projection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1997,19(7):711-720.
[3]Wright J,Yang A Y,Ganesh A,et al.Robust face recognition via sparse representation[J].IEEE Transactions on PatternAnalysis and Machine Intelligence,2009,31(2):210-227.
[4]Tzimiropoulos G,Zafeiriou S,Pantic M.Subspace learning from image gradient orientations[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(12):2454-2466.
[5]Sharma A,Dubey A,Tripathi P,et al.Pose invariant virtual classifiers from single training image using novel hybrideigenfaces[J].Neurocomputing,2010,73(10/12):1868-1880.
[6]Lu Jiwen,Tan Yappeng,Wang Gang.Discriminative multimanifold analysis for face recognition from a single training sample per person[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(1):39-51.
[7]Xu Yong,Zhu Xingjie,Li Zhengming,et al.Using the original and‘symmetrical face’training samples to perform representation based two-step face recognition[J].Pattern Recognition,2013,46(4):1151-1158.
[8]Zhang Daoqiang,Chen Songcan,Zhou Zhihua.A new face recognition method based on SVD perturbation for single example image per person[J].Applied Mathematics and Computation,2005,163(2):895-907.
[9]Xu Yong,Fang Xiaozhao,Li Xuelong,et al.Data uncertainty in face recognition[J].IEEE Transactions on Cybernetics,2014,44(10):1950-1961.
[10]Kim T K,Kittler J.Locally linear discriminant analysis for multimodally distributed classes for face recognition with a single model image[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(3):318-327.
[11]Deng Weihong,Hu Jiani,Guo Jun.Extended SRC:undersampled face recognition via intraclass variant dictionary[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(9):1864-1870.
[12]Yang Meng,Van Gool L,Zhang Lei.Sparse variation dic-tionary learning for face recognition with a single training sample per person[C]//Proceedings of the 2013 IEEE International Conference on Computer Vision,Sydney,Australia,Dec 1-8,2013.Piscataway,USA:IEEE,2013:689-696.
[13]Chen Songcan,Liu Jun,Zhou Zhihua.Making FLDA applicable to face recognition with one sample per person[J].Pattern Recognition,2004,37(7):1553-1555.
[14]Kumar R,Banerjee A,Vemuri B C,et al.Maximizing all margins:pushing face recognition with kernel plurality[C]//Proceedings of the 2011 IEEE International Conference on Computer Vision,Barcelona,Spain,Nov 6-13,2011.Piscataway,USA:IEEE,2011:2375-2382.
[15]Zhu Pengfei,Zhang Lei,Hu Qinghua,et al.Multi-scale patch based collaborative representation for face recognition with margin distribution optimization[C]//LNCS 7572:Proceedings of the 12th European Conference on Computer Vision,Florence,Italy,Oct 7-13,2012.Berlin,Heidelberg:Springer,2012:822-835.
[16]Donoho D L.Compressed sensing[J].IEEE Transactions on Information Theory,2006,52(4):1289-1306.
[17]MartinezAM.TheAR face database[R].CVC,1998.
[18]Gross R,Matthews I,Cohn J,et al.Multi-PIE[J].Image and Vision Computing,2010,28(5):807-813.
[19]ORL database[EB/OL].(2015-10-24)[2016-05-10].http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html.
[20]Duda R O,Hart P E,Stork D G.Pattern classification[M].Hoboken,USA:John Wiley&Sons,2012.
[21]Cortes C,Vapnik V.Support-vector networks[J].Machine Learning,1995,20(3):273-297.
[22]Xu Yong,Zhang D,Yang Jian,et al.A two-phase test sample sparse representation method for use with face recognition[J].IEEE Transactions on Circuits and Systems for Video Technology,2011,21(9):1255-1262.
[23]Xu Yong,Zhu Qi,Fan Zizhu,et al.Using the idea of the sparse representation to perform coarse-to-fine face recognition[J].Information Sciences,2013,238:138-148.

WEI Mingjun was born in 1991.He is an M.S.candidate at Guizhou University.His research interest is computability and computational complexity.
魏明俊(1991—),男,湖北十堰人,贵州大学硕士研究生,主要研究领域为可计算性与计算复杂性。

XU Daoyun was born in 1959.He is a professor and Ph.D.supervisor at Guizhou University,and the senior member of CCF.His research interests include computability and computational complexity,algorithm design and analysis.
许道云(1959—),男,贵州安顺人,贵州大学教授、博士生导师,CCF高级会员,主要研究领域为可计算性与计算复杂性,算法设计与分析。

QIN Yongbin was born in 1980.He is an associate professor at Guizhou University,the member of CCF.His research interests include computability and computational complexity,intelligent computing and big data management and application.
秦永彬(1980—),山东招远人,博士,贵州大学副教授,CCF会员,主要研究领域为可计算性与计算复杂性,智能计算,大数据管理与应用。
Face Recognition Based on Automatic WeightedKNearest Patches for Single Training Sample*
WEI Mingjun,XU Daoyun+,QIN Yongbin
College of Computer Science and Technology,Guizhou University,Guiyang 550025,China
Face recognition with single training sample per person,due to the lack of inner-class information to predict the complex variations,results in the recognition accuracy of commonly used algorithms declined sharply.And the best solutions can be broadly divided into two categories,one is to generate virtual training samples from original samples,the other is through learning a sparse variation dictionary to predict the variations.To solve this challenging problem,this paper proposes an algorithm based on automatic weights to theKnearest patches.Because the training dictionary which just has one training sample per class can not predict facial complex features change,this paper imports the sparse variation dictionary to represent the complex facial features changes.Then this paper divides the test sample into some sub-blocks,and picks out theKnearest patches of each sub-block to form a virtual testing set and gives automatic weights to those patches in the classification.Finally,this paper uses an improved voting mechanism to get classification results of the original test sample.Extensive experiments on representative face databases AR,CMU Multi-PIE and ORL demonstrate that the proposed algorithm is much more effective than state-of-the-art algorithms in dealing with face recognition with single training sample per person.
2016-06, Accepted 2016-08.
A
TP391
+Corresponding author:E-mail:dyxu@gzu.edu.cn
WEI Mingjun,XU Daoyun,QIN Yongbin.Face recognition based on automatic weightedKnearest patches for single training sample.Journal of Frontiers of Computer Science and Technology,2017,11(9):1505-1512.
10.3778/j.issn.1673-9418.1607031
*The National Natural Science Foundation of China under Grant Nos.61262006,61540050(国家自然科学基金);the Major Applied Basic Research Program of Guizhou Province under Grant No.JZ20142001(贵州省重大应用基础研究项目);the Science and Technology Foundation of Guizhou Province under Grant No.LH20147636(贵州省科技厅联合基金).
CNKI网络优先出版: 2016-08-15, http://www.cnki.net/kcms/detail/11.5602.TP.20160815.1659.008.html
Key words:single training sample;face recognition;sparse variation dictionary;K nearest patches;automatic weight;voting mechanism
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
房地产导刊(2022年4期)2022-04-19
计算机应用与软件(2020年5期)2020-05-16
科技创新与应用(2020年6期)2020-02-29
新生代(2019年10期)2019-10-18
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
读者(2016年14期)2016-06-29
