
多维应用特征融合的用户偏好预测*
2017-09-18 00:28陈震鹏李豁然刘譞哲
计算机与生活 2017年9期
陈震鹏,陆 璇,李豁然,刘譞哲+
1.北京大学 高可信软件技术教育部重点实验室,北京 100871 2.北京大学(天津滨海)新一代信息技术研究院,天津 300450
多维应用特征融合的用户偏好预测*
陈震鹏1,2,陆 璇1,2,李豁然1,2,刘譞哲1,2+
1.北京大学 高可信软件技术教育部重点实验室,北京 100871 2.北京大学(天津滨海)新一代信息技术研究院,天津 300450
近年来,随着智能手机的飞速发展,移动应用的数目也快速增长。因此,移动应用开发者会提前预测用户对于自己开发的应用的偏好情况。选取Android应用的被卸载次数与其被下载次数的比值作为用户偏好的隐式反映,用户对应用的评价(喜爱率)作为用户偏好的显式反映。基于国内某知名手机应用市场提供的2014年5月至9月的大规模真实用户使用数据,选取9 795个活跃用户数不少于50的Android手机应用作为研究对象,进行分析。从7个维度定义了可能影响用户对应用偏好的30种特征,并对每个应用进行特征提取。基于定义的特征,使用随机森林算法训练分类器,按照卸载/下载比率或喜爱率的高低对应用进行划分,并找出显著影响卸载/下载比率、喜爱率的特征。
Android手机应用;应用特征;用户偏好
1 引言
2007年iPhone的发布开启了移动计算的新纪元,也使得软件应用的发布和使用模式产生了重大变化。时至今日,大量应用开发者将数以百万计的移动应用(App)上载到应用市场并从中获益,应用市场成为移动端用户选取和下载应用的重要入口。
开发者往往非常关心自己的应用能否从众多竞争中脱颖而出并被广大用户使用,从而从中获益。当应用已经开发完成并且投入各分发渠道供用户下载使用后,如果分发效果远低于预期(如应用卸载率很高,或者受到大多数用户的差评),将会严重影响开发者的收益。因此,如果能够从应用本身找出可能影响用户偏好的特征并进行分析,将有利于开发者及时调整,开发出更受用户欢迎的应用。
基于上述需求,本文选取了应用在一定时间段内的被卸载次数与被下载次数的比值(卸载/下载比率)和喜爱应用的用户数目与总评价人数的比值(喜爱率)作为衡量用户偏好的两个指标,并从应用的静态属性(如APK大小、代码复杂度等)中提取和定义30种特征。通过Mann-Whitney U test来验证这些特征和用户偏好之间的关系,从而为开发者提供参考,帮助其提高应用的受欢迎度。本文使用K-means算法将应用按卸载/下载比率(或喜爱率)分为高、低两类,根据应用的特征和其对应的分类,使用随机森林算法来训练分类器模型,并交叉验证模型的准确性。在此基础上,本文还探讨了显著影响这两个指标的特征。在本文定义的30种特征中,有16种显著影响用户的卸载/下载比率,有20种显著影响用户的喜爱率。
本文组织结构如下:第2章介绍所使用的数据集,以及如何预处理选出作为研究对象的应用;第3章给出两种评价指标和30种应用特征的定义与提取;第4章介绍如何训练模型来预测卸载/下载比率和喜爱率,并检验模型效果,探究显著影响卸载/下载比率以及喜爱率的特征;第5章讨论本文工作的局限性;第6章介绍相关工作;第7章总结全文。
2 数据集及预处理
本文所使用的用户行为数据(包括下载、卸载、更新)来自国内某知名手机应用市场[1]。该手机应用市场在中国Android用户中人气和活跃度很高,迄今安装量已超过4.2亿。根据这一数据集所包含的应用列表选取研究对象,并进一步收集数据进行特征提取。本章分为两部分:第一部分介绍数据集;第二部分介绍如何对数据进行预处理,选出部分应用作为研究对象。
2.1 用户行为数据集
该手机应用市场提供的数据是2014年5月至9月的用户使用数据,来自全体用户的一个子集。单条数据记载的是用户对于某个应用的下载、卸载或者更新行为。其中包含的信息字段有:
{app标识,用户id,具体行为}
(1)app标识:每个应用在该手机应用市场上都有唯一标识。标识与应用之间存在一一对应的关系,例如微信的标识为“com.tencent.mm”。
(2)用户id:在该手机应用市场上,每个设备均由一个字符串id来唯一标识。本文以设备id代表用户,即每个设备的使用行为代表一个用户的使用行为,并不考虑一个用户使用多台设备的情况。“用户”和“设备”的概念是等同的。
(3)具体行为:包括下载、更新、卸载3种。
2.2 数据预处理
根据该手机应用市场提供的2014年5月至9月间的用户使用数据,可以得出每个应用在这段时间的活跃用户数目。为了避免个别应用用户数目少,导致卸载/下载比率以及喜爱率等衡量指标不可信的情况,本文只选取活跃用户数目不少于50的应用作为研究对象。
3 评价指标和特征
本文定义了两种评价用户偏好的指标以及30种可能影响用户偏好的特征。
3.1 评价指标的定义
卸载/下载比率(ui_ratio):指应用在数据集范围内的被卸载次数与被下载次数的比值。比值越大,说明应用越容易被用户卸载,隐式反映了用户对于应用的偏好。计算公式如下:
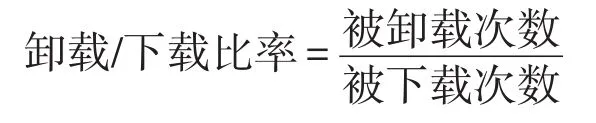
喜爱率(like_rate):指对应用表示喜欢的用户数目占总评价人数的百分比。该手机应用市场并不采用Google Play那种星级评价模式,而是简单的二元评价模式。喜爱率越高,说明越受用户喜爱,显式反映了用户对于应用的偏好。计算公式如下:

3.2 评价指标的提取
(1)卸载/下载比率
对于被选为研究对象的应用,统计出每个应用在2014年5月至9月间的被卸载次数和被下载次数,并求出两者的比值。
(2)喜爱率
该手机应用市场对于每个上线的应用生成了一份单独的JSON(JavaScript object notation)格式的文件,该格式数据中的“likesRate”字段表示用户对应用的喜爱率(百分制),值域为[0,100],对应于like_rate的值域[0,1]。like_rate值越接近于1,说明越受用户喜爱。以“爸爸去哪儿亲子宝典”为例,其JSON格式文件如图1所示,可以得出“爸爸去哪儿亲子宝典”的likesRate为80(即like_rate为0.8)。

Fig.1 Data slot of“dadwheregoing”JSON string图1 “爸爸去哪儿亲子宝典”JSON格式数据片段
3.3 特征定义
在特征定义方面,本文参考并扩展了Lo等人的工作[2],结合该手机应用市场上的特有信息,本文从7个维度定义了30种特征,分别为应用文件规模(5种)、代码复杂度(8种)、代码库依赖(4种)、UI(user interface)复杂度(2种)、最终用户要求(4种)、市场推广力(3种)、应用市场鉴定信息(4种)。每个特征的具体含义以及解释见表1。
应用文件规模:在Android应用中,APK(Android package)文件不仅包含应用的代码,还包括应用所需要的资源文件等。应用越大意味着可能包含更多功能特性,因此较大的应用很可能有较低的卸载/下载比率和较高的用户喜爱率。但是,应用越大也意味着有更高的代码缺陷风险,因此也有可能会出现较高的卸载/下载比率和较低的用户喜爱率。
代码复杂度:代码复杂度越高,应用越有可能出现缺陷,这样用户在使用应用时就容易出现闪退等问题,影响用户对应用的偏好。本文使用Chidamber和Kemerer定义的面向对象的6个复杂度标准(CK标准)[5],外加类的传入耦合数目(afferent coupling,CA)[6]和类的public方法数目(number of public methods,NPM)[7]作为代码复杂度的评价标准。
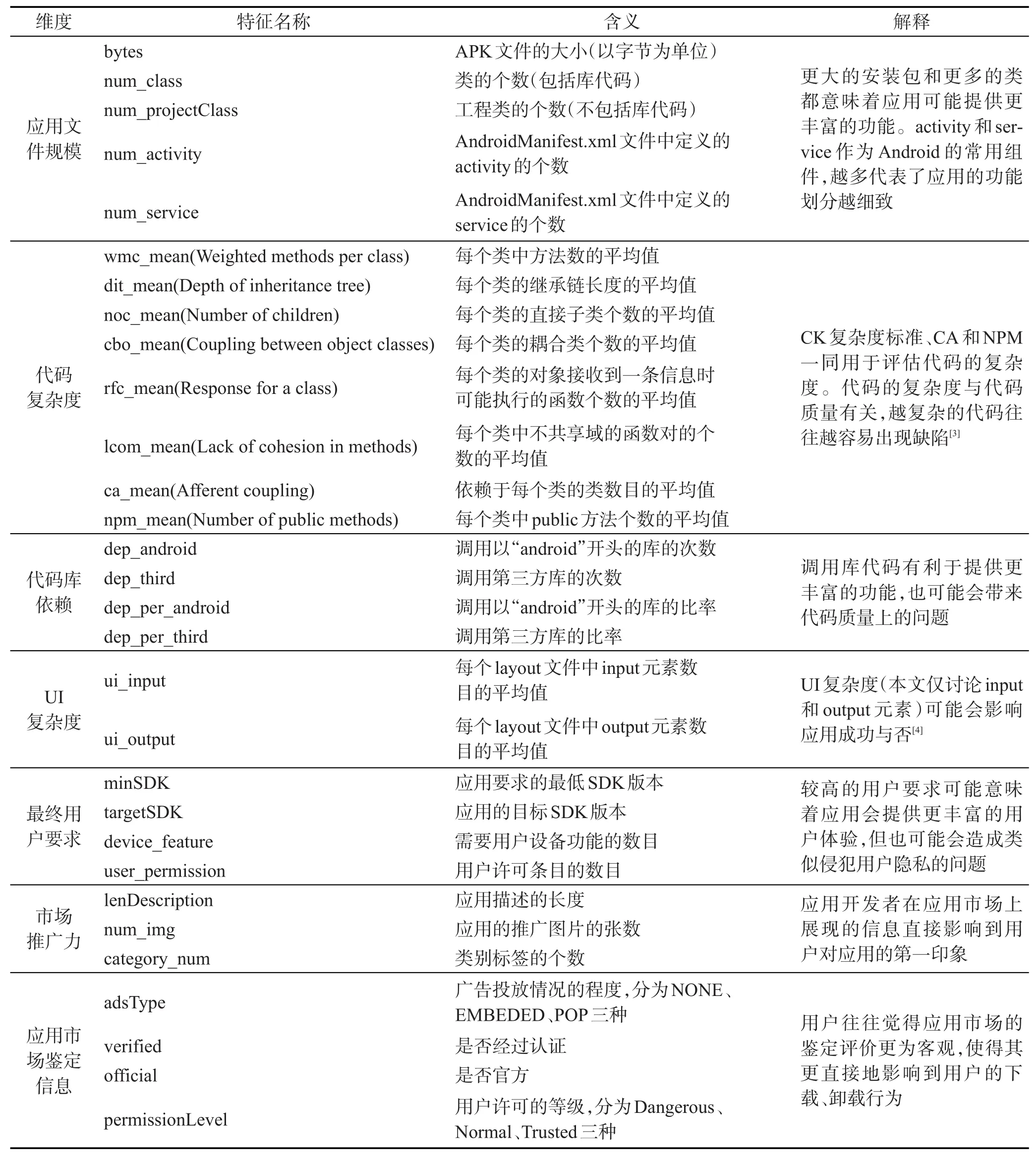
Table 1 Features that potentially affecting preferences of users表1 可能影响用户偏好的特征
代码库依赖:相比于传统的软件,Android应用更多地依赖于Android基准库和第三方库[8],这就使得Android应用的质量受到使用库的影响。如果使用的Android库和第三方库质量较低,就有可能导致应用的部分功能会受限制或者应用容易出现崩溃等现象,影响用户对应用的偏好。
UI复杂度:UI复杂度过高将影响用户的使用体验。例如,有的应用反复提醒一些信息或者总是出现弹出窗口要求用户填写信息,给用户带来困扰,严重影响用户对应用的评价。
最终用户要求:对用户的要求包括多方面,比如对用户手机系统的版本要求,很多应用会列出要求的最低SDK(software development kit)版本,要求较高的应用在低版本的系统上可能无法安装或是运行时可能会出现闪退和使用不流畅等问题。另外,部分应用会要求用户隐私方面的权限,这都可能影响用户对应用的偏好。例如,对隐私较为敏感的用户在遇到使用了其通讯录信息的应用时,很大可能会选择差评和卸载。
市场推广力:市场推广力维度的特征来自应用开发者展示在手机应用市场上用以引导用户下载的信息。这些信息直接影响了用户对应用的第一印象,从而可能影响用户对应用的评价。本文选用了推广图片的张数、文本描述的长度以及类别标签的个数来表征这一维度。
应用市场鉴定信息:该手机应用市场会对每个应用给出概要性的鉴定评价,这些鉴定信息较应用开发者自己的描述来说,更具有客观性。本文选取是否官方,是否经过认证,广告投放情况以及涉及用户隐私的程度这4个评价标准进行探究。
3.4 特征提取
提取特征的流程如图2所示。整个过程分为四部分:爬取APK和相应信息;处理网页信息和JSON信息;处理AndroidManifest.xml和布局文件;处理class文件和libraries。
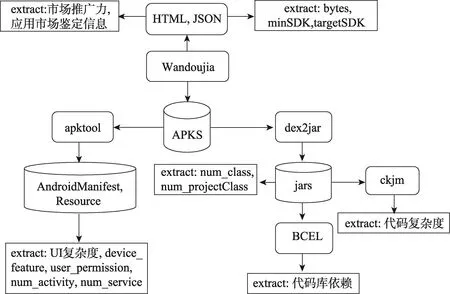
Fig.2 Process of extracting features图2 特征提取流程
(1)爬取APK和相应信息
对于每个应用,需要爬取它的APK文件、网页信息和JSON格式信息。该手机应用市场提供了一系列的url规则可供人们方便地爬取。对于第2章选出的9 795个应用,能够成功爬取的合计5 992个。
(2)处理网页信息和JSON信息
以“爸爸去哪儿亲子宝典”为例,其网页信息如图3所示,其JSON格式信息如图1所示。结合网页信息和JSON格式信息,可以提取出应用的市场推广力和应用市场鉴定信息等方面的特征。
(3)处理AndroidManifest.xml和布局文件
本文使用经典的APK反编译工具“apktool”(https://code.google.com/p/android-apktool/)来反编译APK文件,得到AndroidManifest.xml和布局文件。AndroidManifest.xml文件是每个Android程序必须包含的文件,位于整个Android项目的根目录中,会声明程序中的activity、service等构件,并且会在usespermission中列出程序需要的权限,在uses-feature中声明程序会用到的设备功能。本文使用python中的xml.dom.minidom包解析AndroidManifest.xml后统计得到num_activity、num_service、user-permission和device-feature这4项特征。反编译得到的/res/layout文件夹中包含的若干XML(extensible markup language)文件称为Android工程的布局文件。布局文件决定了布局的结构,应用展现给用户所有的元素(包括本文特征中涉及的input和output元素)就定义在布局文件中。本文对input和output元素的定义参照ICWE 2014中Taba团队[4]的做法。同样采用python中的xml.dom.minidom包来解析布局文件,然后逐个查找input和output元素,统计出两者在布局文件中的平均数目。
Fig.3 Asample page of anApp图3 应用页面示例
(4)处理class文件和libraries
诸如代码复杂度、代码库依赖等特征需要代码分析后才能得出。本文先使用python中的zipfile包解压缩APK后提取出classes.dex文件,然后使用“dex2jar2”(https://code.google.com/p/dex2jar)来反编译classes.dex文件得到应用的字节码文件(即class文件)。将class文件分成两类,将包名与AndroidManifest.xml中的package属性一致的称为工程类,其余的称为库类[9]。统计可得num_class(类的数目)和num_projectClass(工程类的数目)。为了正确得到代码复杂度等特征,需要先使用经验性方法去除有代码混淆的应用,查找是否有以“a.class”命名的工程类,如果有则说明代码混淆过[9]。爬取成功的5 992个应用中,反编译成功并且无代码混淆的合计3 180个,这些应用将作为接下来的研究对象。
为了计算代码复杂度,本文选用“ckjm”工具[10],综合考虑工程类和库类,在class的级别上分析代码复杂度。为了计算库依赖相关的特征,需要提取出工程代码和库代码之间的依赖关系。本文采用BCEL(http://commons.apache.org/proper/commons-bcel/)来将字节码文件转化为一条条JVM(Java virtual machine)指令,然后从JVM指令中识别出方法调用,并区分调用的是Android库还是第三方库。调用方法如果以“android”开头,则认为是Android库,否则如果不是自身定义的函数,即认为是第三方库[2]。
4 模型训练和验证
本文旨在帮助应用开发者在早期预测未来用户对于该应用的偏好(卸载/下载比率及喜爱率),从而有针对性地做出调整。基于前文已经得到的研究对象及其特征,本文训练出预测模型,并且检验模型的效果。
对于卸载/下载比率以及喜爱率的模型训练,整体上方法相同,将比率值用K-means算法分为高、低两类,选用随机森林算法训练分类器模型,并用五折交叉验证模型的效果。本文并未采取将比率值按从低到高排序,然后选取头部和尾部的若干样本作为高、低两类样本的做法[2],而是采用主流的原型聚类方法K-means算法,主要是为了保留样本的原始分布情况。
本文接下来将介绍评价模型的标准,然后分别以卸载/下载比率和喜爱率作为预测目标,训练模型,得出各自模型的效果,并且分析出显著影响卸载/下载比率以及喜爱率的特征。
本文使用二类分类器区分比率值是高或低。假设将比率值分为{high,low}两类,对应的混淆矩阵见表2,预测结果共分4种情况:
(1)实际为low类,预测为low类,假设这样的情况有TL(true low)个;
(2)实际为low类,预测为high类,假设这样的情况有FH(false high)个;
(3)实际为high类,预测为low类,假设这样的情况有FL(false low)个;
(4)实际为high类,预测为high类,假设这样的情况有TH(true high)个。
本次实验选取了acc、acc_high、acc_low、g共4个评价标准来评判模型的效果,下面介绍每种评价标准及其计算方法。
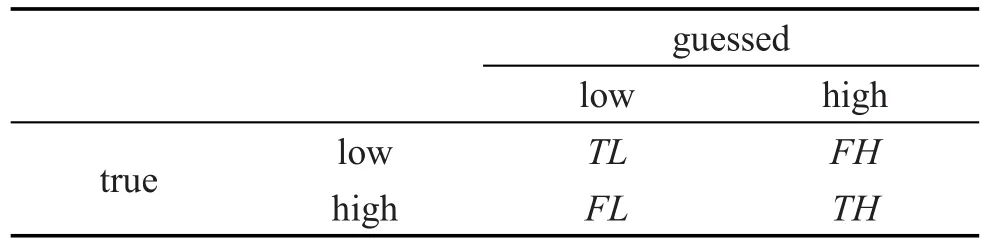
Table 2 Confusion matrix表2 混淆矩阵
(1)acc表示整个模型的准确率(accuracy),值域为[0,1],越接近于1说明整个模型的准确率越高。计算公式为:
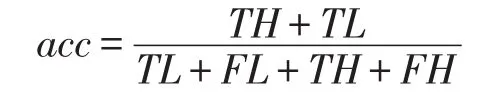
(2)acc_high表示对于实际分类为high的样本的预测准确率(accuracy of high examples),值域为[0,1],越接近于1说明整个模型对于实际分类为high样本的预测能力越强。计算公式为:

(3)acc_low表示对于实际分类为low的样本的预测准确率(accuracy of low examples),值域为[0,1],越接近于1说明整个模型对于实际分类为low样本的预测能力越强。计算公式为:

(4)g表示acc_high和acc_low的几何平均值,即代表了整个模型在实际分类为high的样本和实际分类为low的样本上的总体表现。如果一个模型只是在一种样本上预测准确率很高,在另一种样本上预测准确率很低,那么g值也会偏低。g的值域为[0,1],越接近于1说明整个模型对于high和low两类的均衡预测能力越强。计算公式为:

4.1 卸载/下载比率
本节选用卸载/下载比率作为衡量用户对应用偏好的指标。对于上文去混淆后得到的3 180个应用,获得其卸载/下载比率(ui_ratio),使用R语言中自带的K-means函数将其分为高、低两类,具体分布见表3。此时存在两个类别的样本数目相差较大的情况,即存在类别不平衡,会对学习结果产生不良影响。假设训练得到的分类器永远将新样本预测为低ui_ratio,虽然达到接近90%的准确率,但是这样的分类器却没有价值,因为它不能正确预测出任何应为高ui_ratio的样本。本文采用两种处理类别不平衡问题的方法:“欠采样”(undersampling)和“过采样”(oversampling)[11]。

Table 3 Distribution of ui_ratio表3 ui_ratio的样本分布情况
4.1.1 欠采样
欠采样,即去除样本数较多的类(低ui_ratio)中的部分样本,使得两类样本数目接近。本文采用WWW 2016中一篇论文的做法[12],去除低ui_ratio的样本中的噪音点、边界点和冗余点[13],从而使两类样本数目达到均衡。将筛选后得到的样本集分成5个子集,进行五折交叉验证,即每次选用4个子集投入随机森林中进行训练,用剩下的1个子集来验证,重复5次。使用本文定义的评价标准进行评估,5次结果数据如表4所示,对应的箱线图如图4所示。
模型的整体准确率acc和两类样本的均衡准确率g达到了80%至85%之间,模型的预测效果较好。
4.1.2 过采样
过采样即增加一些高ui_ratio的样本,使得高、低两类样本数目接近,然后再进行学习。本文将高ui_ratio的样本重复拷贝直到与低ui_ratio的样本数大致持平。五折交叉验证后得到的实验数据如表5所示,对应的箱线图如图5所示。

Table 4 Result of ui_ratio after undersampling表4 ui_ratio欠采样后实验结果
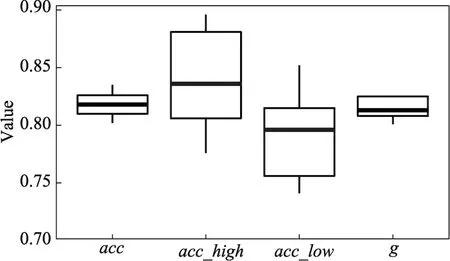
Fig.4 Boxplot of ui_ratio after undersampling图4 ui_ratio欠采样实验结果箱线图
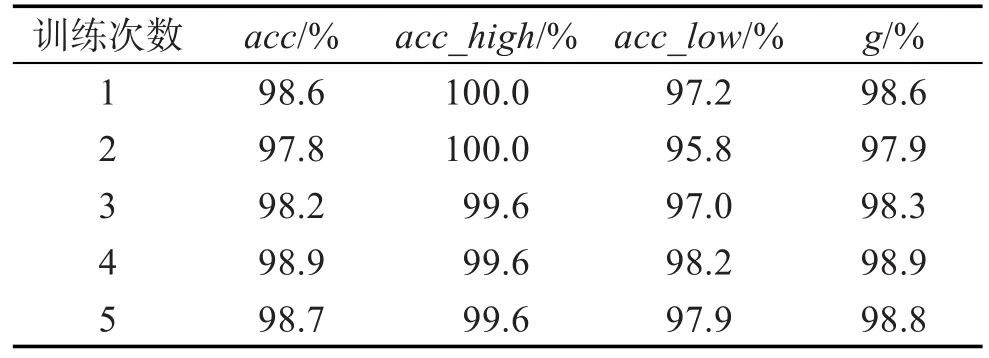
Table 5 Result of ui_ratio after oversampling表5 ui_ratio过采样后实验结果
模型的整体准确率acc和两类样本的均衡准确率g能达到了98%至99%之间,模型的预测效果很好。
4.1.3 显著影响的特征
本文为了找出显著影响卸载/下载比率(ui_ratio)的特征,选用Mann-Whitney U test找出在p-value=0.01时,两类样本在哪些特征上有显著区别[2]。检验结果如表6所示,共有16种特征对卸载/下载比率有显著影响(p-value<0.01)。

Fig.5 Boxplot of ui_ratio after oversampling图5 ui_ratio过采样实验结果箱线图

Table 6 Result of Mann-Whitney U test based on ui_ratio表6 基于ui_ratio的曼惠特尼U检验结果
4.2 喜爱率
本节选用喜爱率(like_rate)作为衡量用户对应用偏好的指标。对于上文去混淆后得到的3 180个应用,为了保证评价结果的可靠性,按照评价人数进行筛选,只选取评价人数不少于5人的应用作为研究喜爱率的对象,合计1 453个。获得其喜爱率(like_rate),用K-means算法将其分为高、低两类,分布见表7。其中高、低两类也存在较明显的样本数目不平衡的现象。和上文做同样处理,使用欠采样和过采样两种方法来改善样本中各类的占比。

Table 7 Distribution of like_rate表7 like_rate的样本分布情况
4.2.1 欠采样
采取和4.1.1小节同样的做法,去除噪音点、边界点和冗余点直到两类样本数目大致相同。将欠采样后得到的样本集分成5个子集,进行五折交叉验证。使用本文定义的评价标准进行评估,5次结果数据如表8所示,对应的箱线图如图6所示。

Table 8 Result of like_rate after undersampling表8 like_rate欠采样后实验结果
模型的整体准确率acc和两类样本的均衡准确率g均处于65%以下,模型的预测效果欠佳。
4.2.2 过采样
采用和4.1.2小节同样的方法,将低like_rate的样本重复拷贝直到与高like_rate的样本数大致持平,以此作为实验数据集。五折交叉验证得到的结果数据如表9所示,对应的箱线图如图7所示。
模型的整体准确率acc和两类样本的均衡准确率g达到了85%左右,模型的预测效果较好。

Fig.6 Boxplot of like_rate after undersampling图6 like_rate欠采样实验结果箱线图
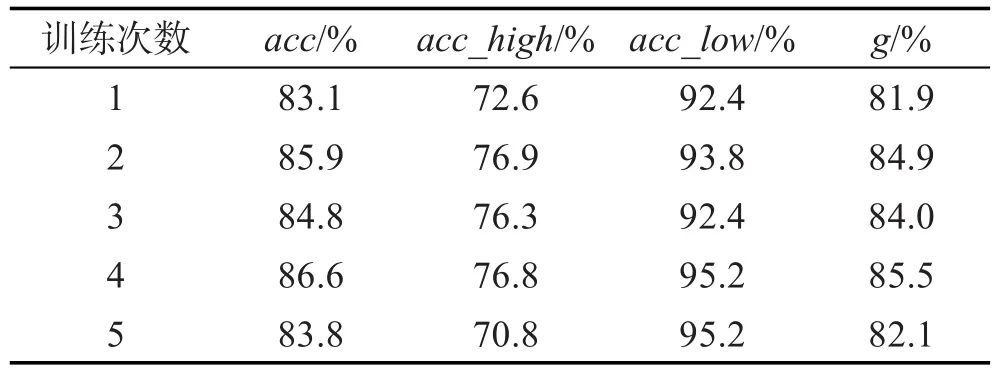
Table 9 Result of like_rate after oversampling表9 like_rate过采样后实验结果

Fig.7 Boxplot of like_rate after oversampling图7 like_rate过采样实验结果箱线图
4.2.3 显著影响的特征
采用和4.1.3小节中同样的做法,得到20种特征对喜爱率有显著影响(p-value=0.01),如表10所示。
4.3 小结
本节主要描述了模型训练和模型评价的过程,并且探究了显著影响卸载/下载比率及喜爱率的特征。
模型训练的整个过程分为:使用K-means算法将卸载/下载比率及喜爱率各自分为高、低两类;使用五折交叉验证,将数据集分成5个子集,每次选4个作为训练集,将其卸载/下载比率或喜爱率和每个应用的30种特征值放入模型中进行学习;选用剩下的1个子集作为测试集,将测试集中每个应用的30种特征值放入模型中,给出这个应用的分类结果,即属于高或低卸载/下载比率(或喜爱率);根据测试集中每个应用的真实类别和被预测出的类别,算出模型整体的预测准确率、高一类样本的预测准确率、低一类样本的预测准确率以及两类样本的均衡准确率。因为卸载/下载比率(或喜爱率)高和低的样本数目不均衡,采用欠采样和过采样两种方法来调整样本,所以共训练出4个模型,分别为欠采样卸载/下载比率预测模型、过采样卸载/下载比率预测模型、欠采样喜爱率预测模型、过采样喜爱率预测模型。4个模型中除了欠采样喜爱率预测模型预测效果欠佳以外,其余效果较好。
应用开发者除了关心用户对于自己应用的偏好外,还会关心哪些因素会对用户偏好有影响。针对这一问题,本文探究了定义的30种特征中哪些与卸载/下载比率(ui_ratio)及喜爱率(like_rate)显著相关,结果如图8所示。

Table 10 Result of Mann-Whitney U test based on like_rate表10 基于like_rate的曼惠特尼U检验结果
5 讨论
本文使用的特征中“是否经过认证”、“用户许可的等级”等在不同手机应用市场的评价标准有所不同,使用该手机应用市场数据的分析结论可能在其他应用市场上不完全成立。另一方面,不同国家用户在评价应用的行为上有不同的倾向,比如美国用户偏爱医疗类应用,日本和澳大利亚用户较少评分等[14]。该手机应用市场主要覆盖中国用户,故本文结论可能无法适用于其他国家或地区。
另外,本文使用的是某手机应用市场5个月内的用户使用数据,手机移动应用的更新频率较高,因此无法保证对于同一个应用,每个用户在这5个月内都是使用同一版本。同一应用的不同版本存在代码上的差异,提取出的部分特征可能有所不同;并且同一应用的不同版本给用户带来的使用体验不同,也会造成用户偏好上的差异。
最后需要强调的是,本文在甄别显著“影响”用户偏好的特征时,进行的是相关性分析(correlation analysis),而非因果分析(causality analysis)。例如,APK文件的大小与用户的使用偏好之间存在较为显著的相关性,但这并不说明APK文件大小与用户的使用偏好之间存在因果关联。换言之,本文并不能直接得出“APK文件大小是用户使用行为偏好的决定因素”这一结论。该问题同样存在于其他诸多相关工作[2,4]中。尽管如此,本文所发现的App各个特征与用户偏好之间的相关性仍然值得应用开发者关注。
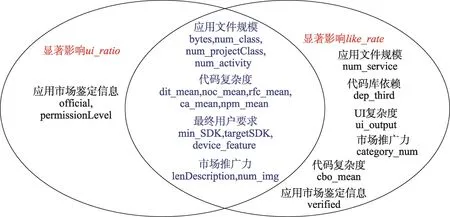
Fig.8 Features that notably affecting ui_ratio and like_rate图8 显著影响ui_ratio和like_rate的特征
6 相关工作
Fu团队在KDD 2013发表的文章[15]中探究了用户评论和应用得分之间的关系,并试图通过用户的单个评论预测该用户对于这个应用的评分。但刚上线的应用和上线很久却鲜有人评论的应用,因为缺乏评论,无法有效利用这种方法预测出用户的评分,从而不能得出用户对这些应用的偏好。而本文基于应用本身的特征来训练模型,不依赖于用户后期的使用和评论反馈,从而有效规避了这一问题。
Lo团队在ICSME 2015发表的文章[2]中,从应用本身的特征出发,对应用的评分进行预测,并探究了Google Play上的高分应用有哪些显著的特征。该文章仅仅选用用户的评分作为评价用户偏好的指标,存在一定的局限性,例如一些应用存在“刷分”现象,使得其评分并不能代表用户对它的真实态度。本文在考虑用户喜爱率的同时,综合考虑了用户对应用的使用行为,即卸载、下载情况,更为客观地表征了用户偏爱。
Liu团队在WWW 2016发表的文章[16]中选用用户行为作为客观的评价指标来反映用户对应用的实际态度,通过对下载、卸载行为建模来衡量应用的受欢迎程度。该文章考虑了用户的真实管理行为,但是与Fu团队的工作[15]一样,依赖于用户对应用的后期使用,无法帮助应用开发者在早期预测出用户的偏好。
7 结束语
近年来,随着Android手机应用数目的持续大量增长,一些学者开始研究Android手机应用的评论和评分,或是用户的使用行为和评分之间的关系,也有一些学者开始探究影响Android手机应用评分的因素。基于现有工作,本文综合考虑用户的下载卸载行为、用户对应用的喜爱率以及影响Android应用的特征,进行了一系列探究。
本文以用户对应用的偏好为切入点,选取卸载/下载比率和喜爱率作为衡量指标,利用国内某知名手机应用市场上的大规模真实用户数据,选取部分手机应用作为研究对象,定义和提取了30种可能影响用户对应用的偏好的特征,训练出预测手机应用的卸载/下载比率和喜爱率高低的模型,模型效果符合预期。
另外,本文从定义的30种特征中探究出显著影响卸载/下载比率和喜爱率的特征。对于那些被预测出高卸载/下载比率或者是低喜爱率的应用来说,开发者可以重点关注这些特征,有针对性地改进自己的应用。
[1]Li Huoran,Lu Xuan,Liu Xuanzhe,et al.Characterizing smartphone usage patterns from millions of Android users[C]//Proceedings of the 2005 Internet Measurement Con-ference,Tokyo,Oct 28-30,2015.New York:ACM,2015:459-472.
[2]Tian Yuan,Nagappan M,Lo D,et al.What are the characteristics of high-rated apps?A case study on free Android applications[C]//Proceedings of the 31st International Conference on Software Maintenance and Evolution,Bremen,Germany,Sep 29-Oct 1,2015.Washington:IEEE Computer Society,2015:301-310.
[3]Subramanyam R,Krishnan M S.Empirical analysis of CK metrics for object-oriented design complexity:implications for software defects[J].IEEE Transactions on Software Engineering,2003,29(4):297-310.
[4]Taba S E S,Keivanloo I,Zou Ying,et al.An exploratory study on the relation between user interface complexity and the perceived quality[C]//LNCS 8541:Proceedings of the 14th International Conference on Web Engineering,Toulouse,France,Jul 1-4,2014.Berlin,Heidelberg:Springer,2014:370-379.
[5]Chidamber S R,Kemerer C F.A metrics suite for object oriented design[J].IEEE Transactions on Software Engineering,1994,20(6):476-493.
[6]Martin R.OO design quality metrics—an analysis of dependencies[C]//Proceedings of the 1994 Workshop Pragmatic and Theoretical Directions in Object-Oriented Software Metrics,Oregon,USA,Oct 23-27,1994.New York:ACM,1994:151-170.
[7]Bansiya J,Davis C G.A hierarchical model for objectoriented design quality assessment[J].IEEE Transactions on Software Engineering,2002,28(1):4-17.
[8]Syer M D,Adams B,Zou Ying,et al.Exploring the development of micro-apps:a case study on the BlackBerry and Android platforms[C]//Proceedings of the 11th Working Conference on Source Code Analysis and Manipulation,Williamsburg,USA,Sep 25-26,2011.Washington:IEEE Computer Society,2011:55-64.
[9]Linares-Vásquez M,Holtzhauer A,Bernal-Cardenas C,et al.Revisiting Android reuse studies in the context of code obfuscation and library usages[C]//Proceedings of the 11th Working Conference on Mining Software Repositories,Hyderabad,India,May 31-Jun 1,2014.New York:ACM,2014:242-251.
[10]Spinellis D.Tool writing:a forgotten art?(software tools)[J].IEEE Software,2005,22(4):9-11.
[11]Zhou Zhihua.Machine learning[M].Beijing:Tsinghua University Press,2016.
[12]Qiu Jiezhong,Li Yixuan,Tang Jie,et al.The lifecycle and cascade of WeChat social messaging groups[C]//Proceedings of the 25th International Conference on World Wide Web,Montreal,Canada,Apr 11-15,2016.New York:ACM,2016:311-320.
[13]Kubat M,Matwin S.Addressing the curse of imbalanced training sets:one-sided selection[C]//Proceedings of the 14th International Conference on Machine Learning,Nashville,USA,Jul 8-12,1997.San Mateo,USA:Morgan Kaufman,1997:179-186.
[14]Lim S L,Bentley P J,Kanakam N,et al.Investigating country differences in mobile App user behavior and challenges for software engineering[J].IEEE Transactions on Software Engineering,2015,41(1):40-64.
[15]Fu Bin,Lin Jialiu,Li Lei,et al.Why people hate your App:making sense of user feedback in a mobile App store[C]//Proceedings of the 19th International Conference on Knowledge Discovery and Data Mining,Chicago,USA,Aug 11-14,2013.New York:ACM,2013:1276-1284.
[16]Li Huoran,Ai Wei,Liu Xuanzhe,et al.Voting with their feet:inferring user preferences from App management activities[C]//Proceedings of the 25th International Conference on World Wide Web,Montreal,Canada,Apr 11-15,2016.New York:ACM,2016:1351-1362.
附中文参考文献:
[11]周志华.机器学习[M].北京:清华大学出版社,2016.

CHEN Zhenpeng was born in 1994.He is an M.S.candidate at School of Electronics Engineering and Computer Science,Peking University,and the student member of CCF.His research interests include data analysis and mobile computing,etc.
陈震鹏(1994—),男,江苏如皋人,北京大学信息科学技术学院硕士研究生,CCF学生会员,主要研究领域为数据分析,移动计算等。

LU Xuan was born in 1991.She is a Ph.D.candidate at School of Electronics Engineering and Computer Science,Peking University,and the student member of CCF.Her research interests include mobile computing and software analysis,etc.
陆璇(1991—),女,江苏如皋人,北京大学信息科学技术学院博士研究生,CCF学生会员,主要研究领域为移动计算,软件分析等。

LI Huoran was born in 1992.He is a Ph.D.candidate at School of Electronics Engineering and Computer Science,Peking University,the student member of CCF.His research interests include mobile computing,software engineering,data analysis and human-computer interaction,etc.
李豁然(1992—),男,北京人,北京大学信息科学技术学院博士研究生,CCF学生会员,主要研究领域为移动计算,软件工程,数据分析,人机交互等。
User Preferences Prediction Based on Multidimensional Features ofApps*
CHEN Zhenpeng1,2,LU Xuan1,2,LI Huoran1,2,LIU Xuanzhe1,2+
1.Key Lab of High Confidence Software Technologies(Peking University),Ministry of Education,Beijing 100871,China 2.Peking University Information Technology Institute(Tianjin Binhai),Tianjin 300450,China
In recent years,the rapid development of smartphones has brought an explosion of mobile applications(a.k.a.Apps).Thus,it would be of App developers’interest to predict user preferences of their Apps in advance.This paper leverages the uninstallation/installation ratio as an implicit indicator and the favorable rating as an explicit one of user preferences.User-activity data involved in this research is collected from a popular App store in China,spanning five months from May to September,2014.9795 Apps are selected,each covering no less than 50 active users.This paper employs 30 features from 7 dimensions that might be correlated with user preferences,and extracts these features from the 9795 Apps.Then,this paper builds Random-Forest classifiers to distinguish Apps between high and low uninstallation/installation ratios,and Apps between high and low favorable ratings.In addition,this paper finds the variables,which can notably influence uninstallation/installation ratio and favorable rating,out of the 30 features involved.
the Ph.D.degree from School of Electronics Engineering and Computer Science,Peking University.Now he is an associate professor at Software Institute,School of Electronics Engineering and Computer Science,Peking University,and the member of CCF.His research interests include mobile computing,Web system,big data and program analysis,etc.
2016-08, Accepted 2016-10.

A
TP311
刘譞哲(1980—),男,甘肃兰州人,北京大学信息科学技术学院副教授,CCF会员,主要研究领域为移动计算,Web系统,大数据,程序分析等。发表学术论文50余篇,承担过国家973计划、863计划、自然科学基金等多个项目,获教育部科技进步一等奖。
+Corresponding author:E-mail:liuxuanzhe@pku.edu.cn
CHEN Zhenpeng,LU Xuan,LI Huoran,et al.User preferences prediction based on multidimensional features ofApps.Journal of Frontiers of Computer Science and Technology,2017,11(9):1405-1417.
10.3778/j.issn.1673-9418.1609029
*The National Natural Science Foundation of China under Grant No.61370020(国家自然科学基金青年-面上连续资助项目);the National Natural Science Foundation of China under Grant No.61421091(国家自然科学基金创新研究群体项目);the National High Technology Research and Development Program of China under Grant No.2015AA01A202(国家高技术研究发展计划(863计划)).
CNKI网络优先出版: 2016-10-31, http://www.cnki.net/kcms/detail/11.5602.TP.20161031.1652.026.html
Key words:AndroidApps;App features;user preferences
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
领导决策信息(2018年16期)2018-09-27
消费导刊(2018年8期)2018-05-25
数学学习与研究(2017年3期)2017-03-09
金融理财(2015年7期)2015-07-15
海外星云 (2014年21期)2015-01-14
西南学林(2011年0期)2011-11-12
