
基于保持内容的变形算法的虚拟展示系统
2017-09-06 05:22:21王海鹏
杭州师范大学学报(自然科学版) 2017年4期
侯 颖,王海鹏
(杭州师范大学国际服务工程学院,浙江 杭州 311121)
基于保持内容的变形算法的虚拟展示系统
侯 颖,王海鹏
(杭州师范大学国际服务工程学院,浙江 杭州 311121)
采用基于图像渲染的算法实现了三维虚拟展示系统.该系统可以从不同角度,以不同放缩比例交互式浏览真实物体.首先基于SfM算法来重建原始摄像机轨迹和稀疏的三维点云,并拟合摄像机轨迹为三维平面圆.在两连续视点之间使用对极变换算法,将特征点集投射到新视图,最后使用基于保持内容的变形算法生成新视图图像.两视点都能生成对应的新视点图像,连续两个视点可以生成内部新视点的两幅新视图.最后新视图和原始视图合成视频.该系统通过操作视频实现放缩和旋转的交互式浏览方式,优点在于不需要对物体做三维重建,仅基于图片的方式来展示物体.和基于三维重建的三维展示系统不同的是,该系统基于图像渲染,运算量小,交互方式简洁、更真实.
基于图像的渲染;三维建模;虚拟展示系统
0 引 言
目前,基于图像渲染的虚拟展示系统能给用户图片质感的视觉体验.这种虚拟展示系统使用基于视图生成算法、离线三维建模(SfM),实时三维建模(SLAM)等技术.基于图像的渲染(image-based rendering)是20世纪90年代中期出现的图形绘制技术,根据需要几何信息的量而被分类为三类[1]:不需要几何参数的渲染、需要隐式的几何信息(比如从图像上提取的特征点)、需要显式的几何信息(粗略或者精确的几何信息).
不需要几何参数的渲染算法.该类算法包括基于光照图的渲染(lumigraph)[2]或光场(light field)[3].基于光场的渲染使用大量的图片但并不需要任何的几何信息或者图片之间对应特征点.光场渲染通过适当的过滤或者从预先获取的采样图片集中插值生成一个新的视图图片.另外一种是基于图片拼接的算法,代表性算法是同心拼图(concentric mosaics)[4]和全景图片(panorama)[5].这两种算法比较类似,其中全景图片相当于同心拼图的子类.同心拼图的数据集是从被限制在一个平面内的数个同心圆上的摄像机拍摄的.同心拼图技术能够通过拼接在每个同心圆上从不同视点拍摄的图片中摘取的狭缝图片来渲染场景.全景图片是在一个固定的视点做不完全的图片采样.
需要少量几何参数的渲染算法.该类算法包括视图插值算法(View Interpolation)[6]和视图变形算法(View Morphing)[7],Chen和Williams的视图插值算法能够根据两幅图片重建两视点间任意视点的视图.这个算法在两视点非常接近的时候效果非常好.该算法需要提取两幅图像的特征点,并利用光流算法来得到对应像素的偏移轨迹.根据新视点的相对位置参数和像素之间的对应关系对源图像做变形操作,生成新视点的图像.视图变形算法能够重建两视点连线内任意一个视点的图片.当两个视点的指向和视点连线互相垂直的时候,连线内任意视点的视图只需要做线性变换就可以生成.当两视点的指向不平行时,需要通过预扭曲(pre-warp)使视点的指向与视点连线互相垂直,该操作可以变形两幅图片,使图片之间对应的扫描线互相平行,再做线性变换,生成视点连线内新视点的视图.最后做预扭曲的逆(post-warp)操作,生成新视点最终视图.
需要大量几何参数的渲染方法.该类方法需要大量三维信息来渲染新视点的图片.通过重建视点拍摄场景得到三维点云,再把点云重投影到新视点上渲染视图.如果图片集的每一个像素点的深度信息都已知,就可以通过三维变形算法(3Dwarping)[8]渲染原始视点附近的任何一个新视点的视图.本文要用到的基于保持内容的变形算法(Content-preserving Warps,CPW)[9]生成新视点视图的算法就属于三维变形算法.首先通过基于从运动信息中恢复三维场景结构(SfM, structure from motion)算法重建真实场景,并重建原始的摄像机轨迹.因为每幅图片的内点特征点对应的三维坐标已知,那么根据这些三维信息,在轨迹上的每一个新视点的视图可以通过原始轨迹上的视图来生成.
1 系统概述
如图1所示,该系统首先使用现成的基于SfM算法的软件来重建摄像机轨迹和稀疏三维点云.然后,自动拟合一个三维平面圆作为新的摄像机轨迹.该系统在两视点之间,使用对应特征点集、摄像机内参来计算基础矩阵.基于对极变换算法,将每视图对应特征点集投射到新视图上.最后使用基于保持内容的变形算法生成新视图图像.两幅图片中的每一幅图片都能生成对应的新视图图像,连续两张原始图像可以生成内部新视点的两幅新视图.该文根据新视点与原始视点之间的角度差为权值来融合两幅新视图为一幅新视图.最后依照这一过程每两幅连续视点的视图之间生成一定数量的新视图,新视图和原始视图一起合成一个视频.操作这个视频来实现对真实物体的交互式浏览.
2 准备数据

如图2所示,该摄像机跟踪软件基于SIFT算法提取每幅图片的二维特征点(x,y),得到内点(图2中绿色的点)、外点(图2中红色的点).最后基于SfM算法三维重建场景的三维点云.而本系统只需要从图片中提取的二维特征点集和重建的三维特征点集、摄像机内外参.

图2 提取的二维点Fig. 2 Extracted keypoints
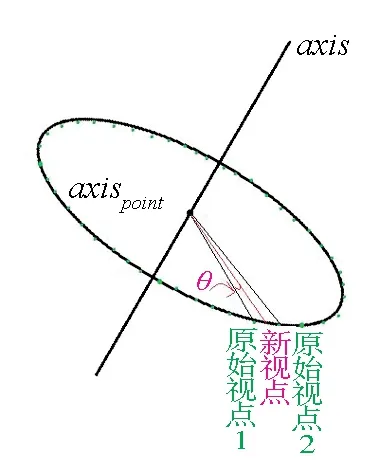
图3 求解新视点摄像机矩阵原理简图
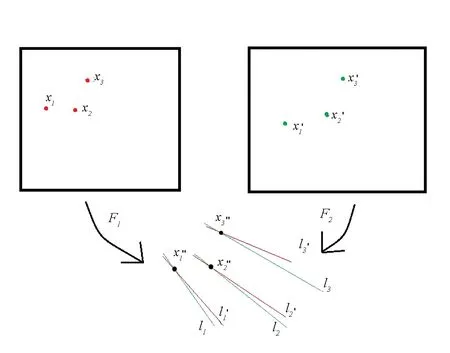
图4 对极变换原理简图Fig. 4 Method of epipolar transfer
使用KLT算法跟踪摄像机,基于相邻帧的对应特征点,并基于SfM算法估计两帧对应的视点的摄像机矩阵和三维特征点.将所有摄像机坐标拟合三维圆:首先拟合三维平面,并将所有的三维点垂直投影到平面上,再在平面内建立一个二维坐标系,将所有投影后的二维点拟合一个二维圆,最后二维圆转换为三维圆,得到三维圆方程.使用最小二乘优化算法作为拟合算法.
3 对极变换
该文测试用的数据集是绕某一物体严格拍摄一圆周的照片,每隔5°拍摄一张照片,共拍摄73张图片.假设新视点到顺时针方向原始视点1的度数差为θ.已经拟合好的平面圆的中心轴axis,中心轴axis与平面的交点axispoint.
3.1 求解新视点摄像机矩阵
如图3所示,该系统将所有的原始视点都对应到三维圆上某一点,生成两相邻视点间新视点的图片.新视点仅仅是原始视点1绕旋转轴旋转θ得到的,所以,根据原始视点的外参矩阵的旋转矩阵R求解新视点的外参矩阵的旋转矩阵.RC=Raxis×R,然后再通过原始视点1旋转θ求解新视点的三维坐标.这样就得到新视点的摄像机矩阵P′.
3.2 求解原始视点与新视点之间的基础矩阵
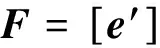
3.3 求解极线并求解极线交点
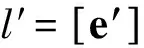
4 保持内容的变形算法
如图5所示,首先将原始图片网格化.图片大小1024×768,按照64×64大小的网格将图片分割为16×12个网格.

图5 网格化 图6 预处理Fig. 5 Gridding Frame Fig. 6 Pre-warping
4.1 预处理以及预变形算法
新视点的点集即极线的交点和原始视点相对应的特征点集之间求单应矩阵.单应矩阵对原始视点的图片做变换,得到新视点预扭曲后的图片,如图6所示.
这一步使得原始视点的图片经过单应矩阵的射影变换后,其特征点集的坐标也相应发生了变化,特征点和相对应的新视点的交点之间距离更小.最终实验证明,经过预扭曲之后的特征点集、图片与交点集作为保持内容的变形算法的输入,会使结果更好.
4.2 保持内容的变形算法
4.2.1 数据项

这一步的目的是保证新视点上的特征点不会发生太大的偏移,即这一步的能量函数是为了最小化极线交点与原始视点图片上对应的特征点的距离之和.
4.2.2 相似变换项
为了进一步约束图像不要过分扭曲,在把图像网格化的基础上,每个网格又重新分为两个三角形[13].

图7 三角化Fig 7 Triangulation

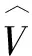

其中ws是关于三角形所在的网格的显著图属性[14].尽管不需要ws也可以得到很好的保持内容的扭曲效果,但是,一幅图片中的内容对于用户来说是有区别的.比如,大部分用户对图片中的天空等大部分留白的场景并不关心,只对色彩丰富、细节丰富的内容感兴趣[15].为了更好地做到保持内容的扭曲效果,该系统计算每个网格的视觉显著性,通过对所有像素的亮度做方差,并为了让每一个点的能量函数的约束变量都在优化中被有效约束,即每一个网格涉及到的优化不会出现ws为0时,能量函数也为0的情况,对ws再加0.5,保证不会出现ws为0的情况.
最后把数据项的能量函数Ed和相似变换项的能量函数Es合并得到关于扭曲后的网格点Vi,j的能量函数E=Ed+αEs,其中α是一个经验值.因为保持扭曲的算法最终得到的效果是图片内容既不太扭曲(Es)也能尽量保持特征点对应的位置正确[9],所以这个α就是数据项和相似变换项之间的相对权值.在该文实验中把α的值设为20.因为要在两幅原始视点中按照圆的轨迹精确地重新生成20个新视点的图片,所以把α设为20是一个在重新拟合的摄像机运动轨迹和避免图片过分扭曲之间的权衡.
4.3 纹理映射算法与两视图图像融合
经过预变形算法和保持内容的变形算法后,得到了新视点图片的所有网格的点.基于扫描线算法,把原始图片的像素对应到新视点网格的像素上.图8a是扭曲原始视点的图片生成新视点的图片的结果.图8b则是画出网格,并填上所有特征点(极线交点).即使图片边界异常扭曲,而图片内容的主体部分,比如盒子表面的复杂纹理等依然保持自然的形状.而像蓝色的转台、背景等用户并不十分关注的区域则扭曲效果明显.为了验证是否保持内容的扭曲,在扭曲图片中填上网格和特征点,实验发现特征点正常分布在显著区域,在经过变形算法的优化后,特征点对真实场景也做到了非常好的对应.
4.4 生成最终视频
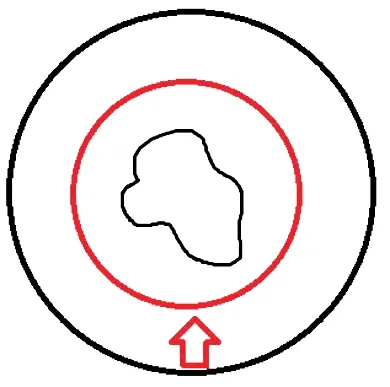
在每两视点间生成20个新视点的图片,共生成1 min的视频流.该系统实现了如图9所示的可以自由浏览的交互方式,键盘左右键可以在同一个同心圆上浏览,键盘前后键可以在不同的同心圆浏览.当要缩小视角时(即缩小当前的新视图),从摄像机轨迹来说,即新视点沿半径方向移动到外面的同心圆,此时视点沿半径方向移动到绿色的同心圆;当要放大视角时(即放大当前的新视图,以图像中心为轴),从摄像机轨迹来说,即新视点沿半径方向移动到内部的同心圆,当要移动视角时(即移动当前的新视图),从摄像机轨迹来说,即新视点沿圆周方向移动.
5 实 验
5.1 真实数据
本系统使用一个真实场景的数据,该数据是通过固定摄像头拍摄的一个转台物体.随转台的转动,连续拍摄73张照片,即每隔5°拍摄一张照片.这样的数据,保证了摄像机运动轨迹的稳定,还保证了图片的数据量.在某一个新视点邻近原始视点的视图如图10所示.

a.由左视图生成的新视图

b.由右视图生成的新视图

a.缩小视角
b.放大视角

c.移动视角

a.原始视图

b.生成的新视图
图10 使用CPW算法生成新视图
Fig.10 Using CPW method to synthesize two novel views
5.2 View Morphing, Photosynth, CPW的对比实验
同样的数据,通过视图变形算法(View Morphing),Photosynth,Content-preserving Warps生成新视图.从图11中可以看出,View Morphing生成的新视图图片扭曲较大,已经和原始视图相差太远,而且需要裁剪的部分太多.而Photosynth生成的新视图仅仅是对场景的三维模型做了相应的贴图.如图11所示,线框为摄像机模型,新视点的视图就是在临近两视图之间插值生成,和Content preserving Warps的方式是一样的.不过Photosynth生成的重影过大.另外由Photosynth生成的摄像机轨迹(图12)来看,也完全和真实情况不符.所以即使能生成新视点视图,该视图也有可能是由完全不连续的两幅图片来生成,所以新视点视图非常有可能是错误的[16].从以上实验看出,Content-preserving Warps在生成新视点视图上效果非常好,缺点是计算性能要求太高,远高于View Morphing这种基于线性变换的算法,而接近于Photosynth这种也需要三维建模的新视点视图生成算法.

a.View Morphing结果 b.Photosynth结果 c.CPW算法结果图11 3种算法生成的新视图比较Fig.11 Comparison of three synthesizedviews
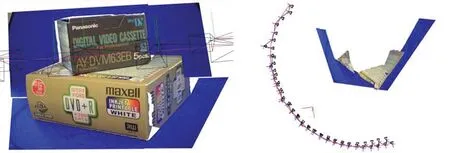
a.Photosynth生成的三维模型正视图 b.Photosynth生成的三维模型俯视图图12 Photosynth生成的摄像机轨迹Fig 12 Camera trajectory synthesized by photosynth
作者测试了View Morphing、Content-preserving Warps、Photosynth生成一张测试图片的平均时间,分别为1.6,0.7,0.2 s.因为Photosynth所使用的算法和Content-preserving Warps 非常类似,只需要在生成新视点图片前做三维建模处理,生成摄像机数据和特征点数据即可,所以这一步的时间没必要包含到生成新视点的图片的时间里.另外,Photosynth生成新视点图片的算法只是简单地把两原始视点的图片根据角度差做图片融合,所以其生成图片的时间非常少.而View Morphing使用的是简单的线性矩阵变换,这种算法非常依赖于特征点的数目,特征点数目越多,变形算法需要的时间越多.在该示例中,View Morphing需要的时间远远多于Content-preserving Warps算法.

a.原始恐龙的视图 b.生成的恐龙视图

c.原始花的视图 d.生成的花的视图

e.原始树的视图 f.生成的树的视图
5.3 通过Maya模拟生成的数据在CPW算法下的结果
如图13所示,从3个数据集中的新视点的图片可以看出,Content-preserving Warps算法的效果非常好,很好地保持了图片的主要内容.但是还必须要强调的是,这里选择的数据都通过voodoo恢复了非常好的摄像机数据,即摄像机分布均匀,基本落在一个三维圆上.因为本文使用的对极变换算法需要两个摄像机数据来计算,也就是说摄像机数据的正确性决定了对极变换算法的有效性.如果对极变换算法失败,即基础矩阵求解的结果使后面求解极线交点的数目过少甚至没有,那么Content-preserving Warps算法也无从施展.正如上面的3个数据集,需要选择细节丰富、色彩丰富的纹理,另外还要保持大部分特征点集分布均匀,这样才能更好地进行Content-preserving Warps算法来生成新视点视图.
6 总结与展望
因为生成的图片是不规则的,本文实现的虚拟展示系统对真实场景信息有所裁剪.可以通过提取更稠密特征点的算法对新视图的特征点集做扩充,从而在图片中生成分布范围更广的特征点集,使得新视点视图中的特征点集分布更均匀,生成的新视图被裁剪更少.该系统不仅保证新视点视图的完整性,还扩大了能生成视图的新视点的范围,相比其他虚拟展示系统仅以渲染图像的方式实现,计算量小、可操作性好,而且视觉体验良好.
[1] SHUM H, KANG S B. Review of image-based rendering techniques[C]//Visual Communications and Image Processing. International Society for Optics and Photonics, 2000:2-13.
[2] GORTLER S J, GRZESZCZUK R, SZELISKI R, et al. The lumigraph[C]// Conference on Computer Graphics and Interactive Techniques. New Orleans:ACM, 1996:43-54.
[3] LEVOY M,HANRAHAN P. Light field rendering[C]//Conference on Computer Graphics and Interactive Techniques. New Orleans:ACM, 1996:64-71.
[4] SHUM H Y, HE L W. Rendering with concentric mosaics[C]//SIGGRAPH 99 Conference.Los Angeles,2012:299-306.
[5] GRAU O C G, GUTHEINZ E. Virtual art: from illusion to immersion[M]. Boston:The MIT Press, 2003.
[6] CHEN S E, WILLIAMS L. View interpolation for image synthesis[C]//Conference on Computer Graphics and Interactive Techniques.New Orleans: ACM, 1993:279-288.
[7] SEITZ S M, DYER C R. View morphing: Synthesizing 3D metamorphoses using image transforms[C]//SIGGRAPH 96 Conference,1996:21-30.
[8] MCMILLAN L. An image-based approach to three-dimensional computer graphics[D]. North Carolina :University of North Carolina at Chapel Hill, 1997.
[9] LIU F, GLEICHER M, JIN H, et al. Content-preserving warps for 3D video stabilization[C]// ACM Transactions on Graphics (TOG), 2009:341-352.
[10] NIEM W. Robust and fast modeling of 3D natural objects from multiple views[C]//Proceedings of SPIE - The International Society for Optical Engineering, 1994:388-397.
[11] XU G, ZHANG Z. Epipolar geometry in stereo, motion and object recognition[M]. New York :Springer ,1996.
[12] HECKBERT P S. Fundamentals of texture mapping and image warping[R]. California:University of California at Berkeley Berkeley, 1989.
[13] IGARASHI T, MOSCOVICH T, HUGHES J F. As-rigid-as-possible shape manipulation[J]. ACM Transactions on Graphics, 2005, 24(3):1134-1141.
[14] WANG Y S, TAI C L, SORKINE O, et al. Optimized scale-and-stretch for image resizing[J]. ACM Transactions on Graphics, 2008, 27(5):32-39.
[15] ITTI L, KOCH C, NIEBUR E. A model of saliency-based visual attention for rapid scene analysis[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 1998, 20(11):1254-1259.
[16] SNAVELY N, SEITZ S M, SZELISKI R. Photo tourism: exploring photo collections in 3D[J]. ACM Transactions on Graphics, 2006, 25(3):835-846.
The Virtual Display System for the Deformation Algorithm Basing on Content-preserving
HOU Ying, WANG Haipeng
(Institute of Service Engineering, Hangzhou Normal University, Hangzhou 311121, China)
A three-dimensional virtual display system is implemented by the algorithm basing on image rendering. The system can interactively browse real objects from different angles with different zoom ratios. Firstly, the original camera trajectory and the sparse 3D point cloud are reconstructed based on the SfM algorithm, and the camera trajectory is fitted to the 3D plane circle. Antipode deformation algorithm is used between two continuous viewpoints, and the minutiae set is projected on to new images, finally new images are generated with the deformation algorithm basing on content-preserving. Two viewpoints can generate the corresponding new viewpoint images, two consecutive viewpoints can generate two new images of internal new viewpoints. Finally, the new and the original images are composited to be video. The system realizes the interactive browsing method of zooming and rotation by operating videos. The advantage of the system is that it does not need to do three-dimensional reconstruction of objects, only shows the objects with pictures. The system is different from the three-dimensional display system based on 3D reconstruction. The system is based on image rendering, the computation is small, the interaction method is simple and more realistic.
image-based rendering; 3D modeling; virtual display system
2016-11-21
侯 颖(1992—),女,计算机应用专业硕士研究生,主要从事增强现实技术研究.E-mail:m15838267459@163.com
10.3969/j.issn.1674-232X.2017.04.017
TP37
A
1674-232X(2017)04-0441-08
猜你喜欢
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
中国公共安全(2017年8期)2017-10-13 08:12:17
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
中国公共安全(2017年11期)2017-02-06 05:27:47
办公自动化(2016年18期)2016-12-17 19:32:18
河南电力(2016年5期)2016-02-06 02:11:24
新闻前哨(2015年2期)2015-03-11 19:29:25
新闻前哨(2015年2期)2015-03-11 19:29:22
