
云计算框架的海量数据查询技术研究
2017-09-03 06:58杨芬
吕梁学院学报 2017年2期
杨 芬
(长治职业技术学院 信息工程系,山西 长治 046000)
·计算机科学研究·
云计算框架的海量数据查询技术研究
杨 芬
(长治职业技术学院 信息工程系,山西 长治 046000)
云计算平台的一个很重要的应用就是对海量数据进行存储和查询处理,传统关系型数据库已经不能满足海量数据的存储和高效查询要求,这就促使了NoSQL数据库应运而生,如HBase.以分布式计算框架Hadoop为例,重点阐述在分布式数据库HBase中海量数据的查询方法和策略,为海量数据的查询研究提供一种新的思路.
云计算;海量数据查询;Hadoop;HBase
随着数据的爆炸式增长,各行各业中都面临着对海量数据的处理,尤其是在海量数据中定位查询到指定数据引起了广泛的研究和讨论[1].HBase数据库本身是面向列存储的分布式开源数据库,具有优异的并发读写操作性能,同时HBase数据库可以对数据实行透明切分,更加提升了HBase存储的水平伸缩性[2].HBase因其良好的性能优势,如高可扩展性、查询延迟低等,得到了很多互联网公司的大力应用实践.本文选择在Hadoop平台上对HBase进行研究,并改进HBase,为HBase中存储的海量数据建立二级索引机制,代替原有的对非主键查询的全表扫描的方式,降低查询延迟.
1 HBase二级索引的设计方案
二级索引的设计要求建立的索引表和原始数据的表必须放在同一个服务器上,从而保证通过索引提取相应的数据时,只需建立一次远程连接即可,大大提高了数据的查询效率.
1.1 索引表的构建思想

图1 使用Coprocessor实现二级索引
现阶段,HBase当中的Coprocessor可以实现对于索引表的构建任务,并且通过Coprocessor提供的实现方法还能够对HBase数据库表进行精确管理,包括对数据的插入、查询、删除等操作.如果需要为某一列簇建立二级索引,可以将索引信息单独存入一张表.原始信息表中如果键值对应的value空间开销不大,且逆向检索频繁,则可直接存储在索引信息表中.图1表示了索引表的构建方法及数据的查找方式.通过图1可看出,存储在HBase中的原始数据表是按照基于列存储的,所以在建立二级索引时,也要基于列簇进行建立.列索引的Key值由原始数据表的Key值和Value值字符串拼接而成.
二级索引设计采取的是将原始表中的Key和Value先倒置再拼接原理,换言之,将键值中的Key作为索引行对应的列值,将Value作为索引行对应的键[3].
1.2 二级索引实现
本文以某客运站的交易数据为例,进行说明.

表1 某客运站部分交易数据一览表
由表1所示,设stationId为二级索引,通过stationId(客运站编号)可找到对应的线路号和班次号等信息.
建立二级索引主要分为以下几个步骤:
(1)创建一个数据扫描器,通过扫描器来查找需要建立索引的数据.
(2)获得数据后,建立一张二级索引表,RowKey值(stationId)由原始数据表中RowKey和Value拼接组成.
(3)写入成功后需要把相应的RowKey(stationId)标识保存到 IndexMessage 数据结构中,把对应的具体数据信息保存到 IndexFile 中,数据信息包括lineNum和shiftNum等信息.
特别需要注意的是,如果创建二级索引是在创建原始表还未导入数据之前进行的,则创建的二级索引能够满足数据一致性的要求.如果原始表中已经导入了相关数据,之后再创建索引表,则无法保证数据的一致性访问要求,这就需要使用Buildlndex组件对己有的数据建立索引[4].但整个调用过程比较复杂,且耗时较长.所以建议在新建数据表后,先建立二级索引然后再导入业务数据.
2 性能测试与分析
2.1 测试环境与测试数据
本次实验需要配置HBase集群:包括一台主机为master,三台为slave,操作系统选择CentOS 5.0.整体需要安装的软件是:Hadoop-1.0.2,Zookeeper-3.3.4 ,HBase-0.4.0 .测试数据为某客运站三个月的售票交易记录.
2.2 测试过程与性能对比
本小节将通过测试来对比未建立二级索引与建立二级索引的海量数据的查询效率.
测试数据以Json形式进行返回,如下所示.
"returnCode":"OK","returnMsg":null,"data":"[{"stationId":"1233334567","sendDate":"2016-02-09","lineNo":"123","shiftNo":"1234","re7alSell":35,"remainSeat":6,"realSend":34,"sendStatus":"1"}]"}
测试步骤:
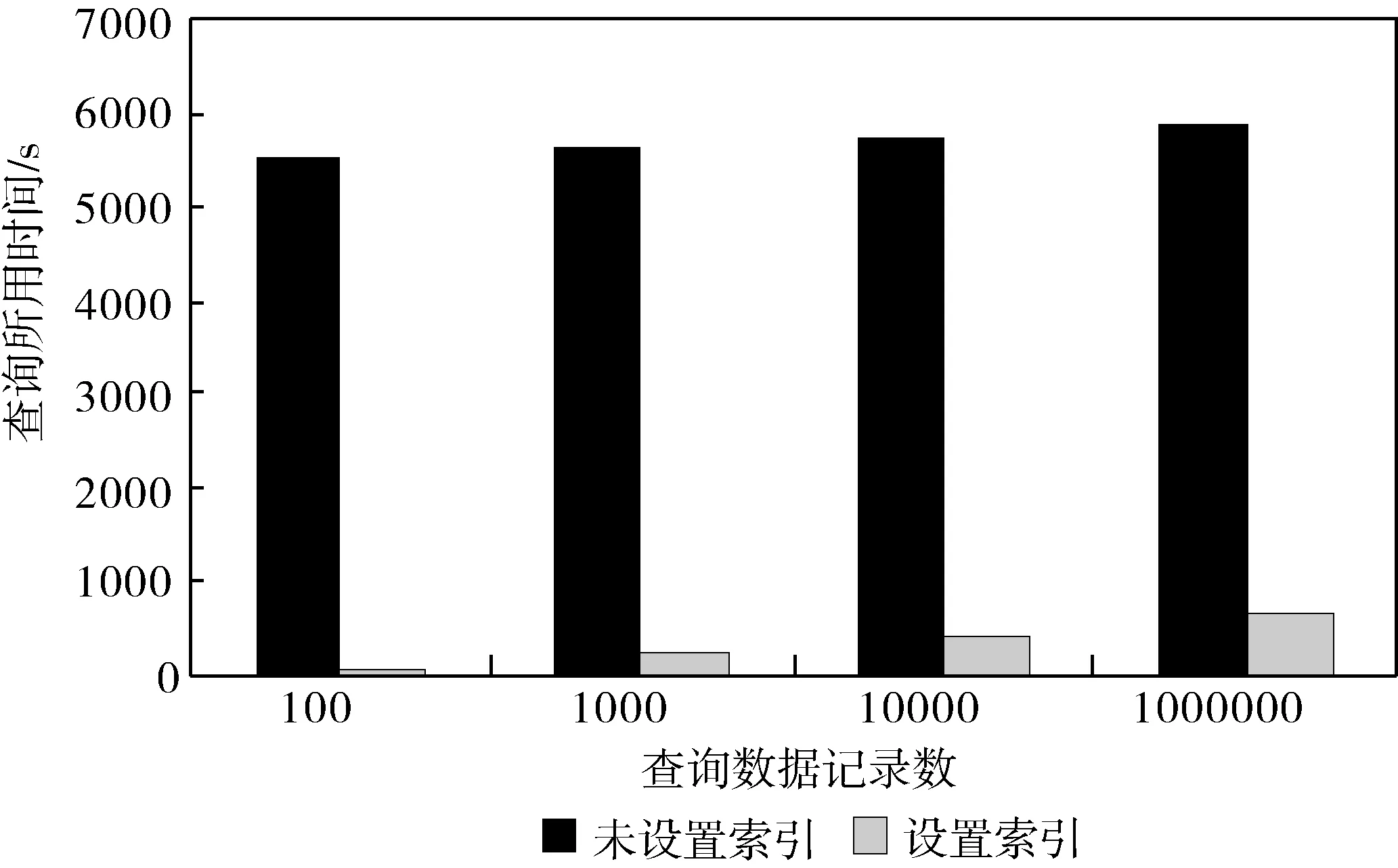
图2 建立二级索引性能比较图
(1)在master上进行查询;
(2)在未设计二级索引的基础上,对实际售票量进行查询,并记录数据的查询时间;
(3)在设计二级索引stationId(客运站编号)的基础上,对实际售票量进行查询,并记录数据的查询时间;
(4)在测试过程中,通过多次测试,来统计每次测试的平均值;
通过以上测试步骤得到性能对比图2.
从图2可以看出,若未对存储在HBase中的数据设计二级索引stationId(客运站编号),进行实际售票量查询时,无论查询的数据量有多少,查询耗时在5000多秒.当对数据设计二级索引stationId(客运站编号)后,查询时间有较大幅度的减少,查询100条记录,花费时间为80 s左右,查询1000条数据耗时在200多秒左右.较大幅度的提高了查询性能.满足了基于非主键快速查询的要求.
3 结束语
本文主要研究了在云计算平台Hadoop下,分布式计算框架HBase中海量数据的查询策略的研究.通过在HBase中设计二级索引来提高海量数据的查询效率,改进了HBase原有的只支持基于主键的查询方式,并保证索引数据的最终一致性.虽然建立二级索引会在一定程度上影响数据写入的性能,增加了数据写入的时间,但造成的时间代价是可接受的.通过实验的分析结果表明,对存储在HBase中的海量数据建立二级索引会使HBase的查询性能得到良好的提升.
[1]王珊,王会举,覃雄派等.架构大数据:挑战、现状与展望[J].计算机学报,2011(10).
[2]施磊磊,施化吉,束长波,宋玉平.基于Hadoop和HBase的分布式索引模型的研究[J].信息技术,2016(6).
[3]周胜群,于治楼,宋欣,李晶.基于云计算的海量数据处理系统框架研究[J].信息技术与信息化,2014(3).
[4]吴朱化.云计算核心技术剖析[M].人民邮电出版社,2011:16.
Research on massive data query technology based on cloud computing framework
YANG Fen
(Information Engineering Department,Changzhi Professional College of Technology,Changzhi Shanxi 046000,China)
Nowadays,the cloud computing has gradually become popular in all walks of life in the community are in a wide range of applications.Cloud computing platform is a very important application of massive data storage and query processing.Traditional relational database has been unable to meet the requirements of mass data storage and efficient query.This prompted the NoSQL database came into being,such as HBase.In this paper,the distributed computing framework Hadoop as an example,will focus on the distributed database HBase in the massive data query methods and strategies.The research of this paper provides a new way of thinking for the research of massive data.
cloud computing;massive data query;Hadoop;HBase
2016-11-14
杨 芬(1973-),女,山西长治人,讲师,研究方向为计算机理论与教学.
TP311
A
2095-185X(2017)02-0047-03
猜你喜欢
China Report Asean(2022年8期)2022-09-02
今日农业(2021年7期)2021-11-27
今日农业(2021年20期)2021-11-26
物联网技术(2020年12期)2021-01-27
戏剧之家(2020年17期)2020-06-22
铁道建筑技术(2019年6期)2019-11-29
城市道桥与防洪(2019年5期)2019-06-26
减速顶与调速技术(2018年4期)2018-08-27
汽车零部件(2017年4期)2017-07-12
中国铁道科学(2015年5期)2015-06-21
