
双缀过滤的大数据相似性连接处理算法*
2017-08-16 11:10邓诗卓信俊昌聂铁铮王国仁
计算机与生活 2017年8期
邓诗卓,信俊昌,聂铁铮,王国仁
东北大学 计算机科学与工程学院,沈阳 110819
双缀过滤的大数据相似性连接处理算法*
邓诗卓,信俊昌,聂铁铮,王国仁+
东北大学 计算机科学与工程学院,沈阳 110819
相似性连接;权重相似性连接;大数据;过滤;Spark
1 引言
随着信息技术的飞速发展,各行各业的数据都逐渐信息化,数据的存储形式也由传统的纸质数据发展成为电子数据。互联网技术的发展促进了网络资源的共享与传播,数据量呈现一种爆炸式增长的模式,数据数量并不代表数据质量,如何在大量数据中找到有用的数据,如同在沙漠中挖掘钻石,这给数据清洗集成和数据挖掘带来了挑战。相似性连接技术作为数据清洗集成等技术中的重要步骤[1],同样面临着大数据的挑战。在数据清洗集成中,相似性连接技术是对不同数据源或者同源的实体记录,根据定义相似度度量函数获取记录对的相似度,将所有满足相似度阈值的记录对进行相似性连接,得到所有相似的记录对,而相似性连接搜索查询是利用相似性连接技术,对给定查询对象,查询数据集中满足相似度阈值的所有记录[2]。
随着数据量的激增,面向大数据的相似性连接技术无论是在数据大规模存储还是在数据处理速度上,实现基于相似性连接技术的应用功能都更加具有挑战性。考虑到大数据存储效率和执行效率两方面因素,基于单机计算的计算模式已经不适合处理大规模数据了,因此面向大数据的相似性连接技术由单机计算逐渐发展成为面向集群计算和分布式计算。越来越多的研究人员采用分布式存储系统和分布式计算框架作为面向大数据相似性连接的解决方案。一方面,对于相似连接,利用传统数据库中Join操作很难达到相似性连接计算的要求,这是因为连接条件并不是现有数据库中的一个易于执行的操作,需要进行相似度计算对两条记录进行近似连接。另一方面,为了保证大量数据的相似性连接的计算效率,主要解决方案是将传统的单机集中式计算替换为使用集群计算或者分布式计算,例如分布式计算框架Hadoop、Storm、Spark等。
目前相似性连接技术主要分为两个阶段,过滤阶段和确认阶段[3]。过滤阶段是通过一定的过滤规则过滤掉一定不满足相似度阈值的记录对,减少候选集合中记录对的数量,减少网络传输,提高相似性连接效率。将不能直接过滤的记录对在确认阶段进行最终确认,即可得到满足相似度阈值的记录对,进而得到相似性连接关系。因此提高过滤阶段的效率,是相似性连接技术的核心问题。
前缀过滤技术是基于元素(token)相似性连接技术中较为普遍适用的过滤算法。文献[1]对不同相似性连接技术进行了较为全面的分析,在处理大规模数据并且相似度阈值较高时,基于位置信息的前缀过滤算法PPJoin+[4]具有良好的表现。但是PPJoin+侧重于后缀位置信息的应用,针对现有过滤技术特别是使用位置信息过滤的方法不能充分利用前后缀之间token的位置信息这一不足,本文结合记录前缀与另一条记录后缀中存在共同元素的特点以及基于权重相似度计算的情况,进行如下研究:
(1)利用文本记录中共同前缀之后的第一个元素在另一条记录后缀位置的信息,提出了双缀过滤方法PSFiltering,并且基于PSFiltering实现分布式相似性连接PSJoin。
(2)结合基于权重相似度计算的特点和双缀过滤方法基本原理,利用元素本身权重大小实现过滤,提出了基于权重的双缀过滤方法WTPSFiltering,并且基于WTPSFiltering实现分布式相似性连接WTPSJoin。
(3)针对本文算法和前人算法从过滤效果、执行时间和加速比三方面进行比较和分析,从而验证本文算法的有效性。
本文组织结构如下:第2章讨论了相似性连接的相关工作;第3章介绍了过滤原理以及基于Spark的分布式相似性连接;第4章详细介绍了双缀过滤原理以及利用双缀过滤实现基于Spark的分布式相似性连接算法;第5章讨论了双缀过滤原理在权重相似度计算中的应用,并实现了分布式计算;第6章给出实验结果,并对实验结果进行分析;最后对全文加以总结。
2 相关工作
相似性连接算法的过滤方法主要包括基于特征标签(signature)和基于树(tree)。基于signature的相似性连接过滤算法有长度过滤(length filtering)、计数过滤(count filtering)、前缀过滤(prefix filtering)等。在前缀过滤基础上,结合不同的相似度度量函数,提出了很多相关算法。在Jaccard相似度方面,文献[5]提出了有序记录前缀过滤解决方案,集合所有记录中的元素都要求按照某种全局序G进行排序,计算前缀长度,根据前缀中的元素建立倒排索引表,同一个元素的倒排索引中的记录就形成候选集;文献[6]提出AllPairs利用相似字符串自身长度或者集合大小进一步进行过滤,从而达到减小候选集的目的,通常基于Jaccard相似连接时会使用到大小过滤;文献[7]提出利用有序记录中元素的位置信息估算相似度上限值,通过比较估算上限与两条记录必须满足的阈值条件来获取候选集;文献[4]在此基础上提出了PPJoin以及PPJoin+;文献[8]针对相似性连接提出了一种Adaptive框架,通过估算代价选取不同前缀长度,减少相似性连接执行时间,该方法在处理大规模数据时性能较好,但是自适应阶段构建索引代价较大,不适合应用到基于前缀过滤的分布式计算中。在编辑距离方面,文献[9]利用不匹配(q-grams)提出了位置信息过滤和内容过滤两种优化技术的Edjoin;不同于Ed-join,QChunk[10]增加了一个过滤特征(q-chunks),降低了用于估算边界值的signature数量。
除此之外,文献[11]提出了Top-K相似性连接算法,返回K对最相似的记录对,此算法不需要设定相似度阈值;基于树的相似连接算法包括TrieJoin[12]和M-Tree[13]等。
文献[1]在进行较为全面分析的基础上总结出,在大规模数据和选取较大相似度阈值时,PPJoin+具有良好的特性。同时PPJoin+能够较好地扩展到Hadoop等分布式计算环境中[14]。
3 基于Spark计算的分布式相似性连接
3.1 相似性连接过滤原理
过滤是相似性连接算法的核心部分。过滤阶段针对不同的相似度函数选取不同的过滤方法。本文所提到的相似性连接是基于集合相似度的相似性连接。常见集合相似度为覆盖相似度Overlap和杰卡德相似度Jaccard,二者定义和关系如式(1)~式(3)所示。
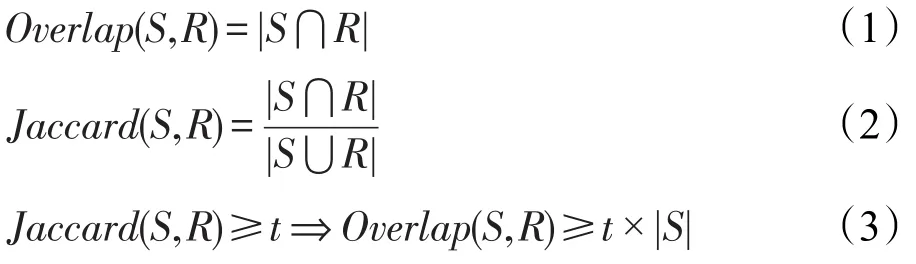
根据不同的相似度函数以及相似度函数之间的关系可以得到不同的前缀计算公式。假设α为Overlap的阈值,t为Jaccard的阈值,那么可得到记录s的Overlap前缀长度为|S|-α+1,s的Jaccard前缀长度为。前缀过滤是分布式计算的理论依据,通过建立倒排索引表,在同一个key中的记录就是满足前缀过滤条件的记录。前缀过滤计算可以进行分割计算和合并计算,满足分布式计算条件,因此相似性连接可以实现分布式计算。
3.2 基于Spark的分布式相似性连接算法
针对MapReduce等计算模型中出现的不足[15],伯克利大学推出了大数据处理框架Spark[16],其核心为弹性分布式数据集(resilient distributed datasets,RDD)。Spark每次对RDD操作后的结果,都可以存放到内存中,下一个RDD操作可以直接从内存中读取数据作为输入,省去了MapReduce计算中大量的HDFS交互。结合RDD特点,使用Spark框架实现分布式相似性连接既具有理论依据又具有应用价值。文献[14]提出基于MapReduce的相似性连接分布式算法,在此基础上,改写成为基于Spark的分布式相似性连接,其RDD转换图如图1所示。
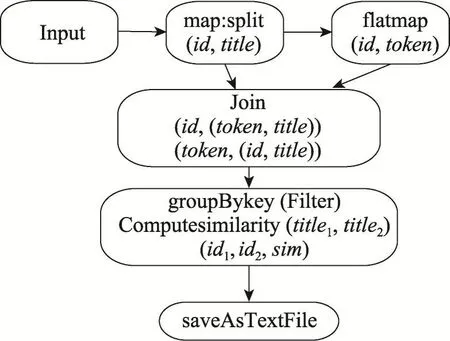
Fig.1 RDD transformations of distributed prefix filtering on Spark图1 基于Spark分布式前缀过滤RDD转换操作图
为了进一步阐释问题,假设选取论文实体中的title作为连接属性,如图1所示,从HDFS等分布式文件系统中读入数据,转化为可被Spark识别并处理的RDD数据形式,读入数据为RDD[String]类型,称之为InputRDD,对InputRDD中进行map转换,对每条记录使用split方法进行切分,获取记录唯一id以及连接属性;该阶段结束后形成mapRDD,类型为RDD[(String,String)],mapRDD通过转换操作flatmap根据每条记录的前缀建立倒排索引,形成flatmapRDD[(String,String)];此时将mapRDD和flatmapRDD进行Join转换操作,将两个形如(key,value)键值对的RDD进行连接,获得title,形成JoinRDD[(String,(String,String))];对于JoinRDD进行groupBykey转换操作,相同key值下面的记录就是满足前缀过滤条件的记录,在groupBykey中对相同key下面的记录计算相似度,得到最终结果,对结果RDD进行存储。在分布式计算基础上,对于同一个key下面的记录同样需要过滤方法来避免笛卡尔积运算,如图中虚线框所示,构造二次过滤方法,以达到减少候选集合大小的目的。
4 基于双缀过滤的相似性连接算法
4.1 双缀过滤原理
目前已有的基于集合的过滤方法中,均是在前缀过滤基础上进行再次过滤,相比较于前缀过滤等方法,这些改进方法都可以达到良好的过滤效果,如PPJoin和PPJoin+中的过滤机制。PPJoin和PPJoin+均是利用对有序记录的位置信息实现有效的过滤,分别利用前缀和前缀、后缀和后缀中元素的位置信息估计相似度上限值。但是如果一条记录前缀中的token出现在另一条记录的后缀中,那么同样基于位置信息,讨论记录s的前缀(prefix)和记录r的后缀(suffix)之间元素位置关系对估算相似度上限值的影响。因此提出基于双缀(前缀-后缀)过滤算法PSFilteringing(pefix-suffix filtering)。由于解决问题需要,方法中所提到的后缀不是真正计算得到的后缀,而是记录对中前缀最后一个共同元素之后的所有元素。
如图2所示,记录s和记录r的前缀分别为p1和p2,后缀分别为q1和q2,其中元素B是p1和p2中最后一个共同元素,取前缀p1中元素B之后的第一个元素C作为扫描元素scanning-token,对r的后缀进行扫描,获取元素C在q2中的位置信息。因为记录s和r都是按照统一个序G作为标准进行排序,并且记录s的长度大于r的长度,所以p1中C之后出现的元素一定是C在序G之后的元素。同理,记录r的后缀中元素C之后的元素也是排在C之后的元素,由此可知,记录r中B之后和C之前的元素不会出现在s中,因此这一部分不可能成为相似度上限upbound的一部分。而对于记录s和r中C之后的所有元素,其最大的覆盖度为两者之间token数量较小者。最终s和r的upbound如式(4)所示:
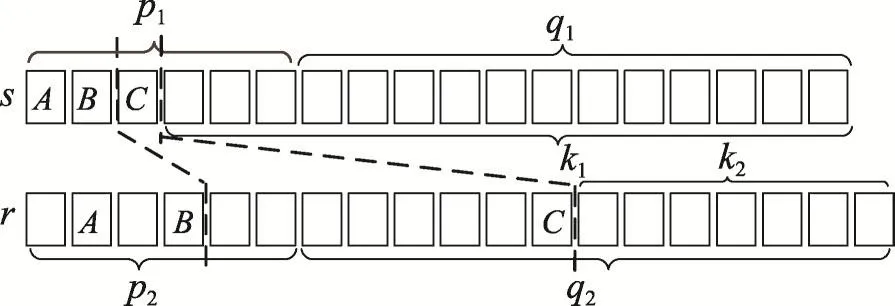
Fig.2 PSFiltering with scanning-token in recordr图2 双缀过滤(记录r中存在扫描元素)
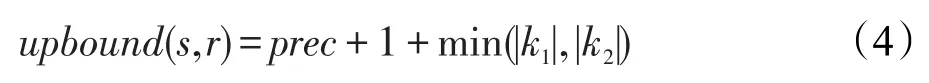
其中,prec表示前缀中共同元素个数。
s中元素B之后的部分均称为混合后缀。扫描元素也是混合后缀中第一个元素。在特殊情况下,扫描元素也有可能是后缀中的第一个元素:
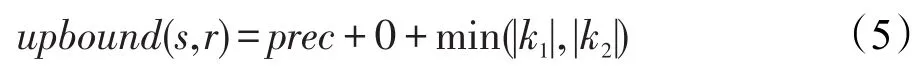
当记录s的扫描元素在记录r中不存在时,如图3所示,只需要比较s记录中扫描元素之后部分与记录r的混合后缀,选取较小长度作为上限的组成部分。式(5)计算的是该种情况下的上限。
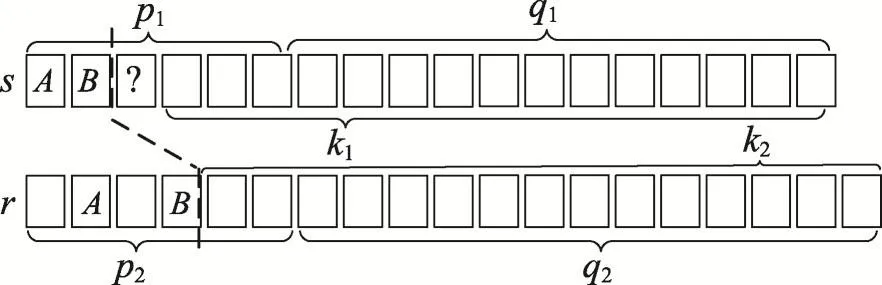
Fig.3 PSFiltering without scanning-token inr图3 双缀过滤(记录r中不存在扫描元素)
根据过滤方法描述,PSFiltering实现伪代码如函数1描述。其中函数1描述的是PSFiltering过滤算法,即描述该记录对中混合后缀部分的相似度上限估算,记录s的混合后缀为Mix1,r混合后缀为Mix2。函数1中第1行取混合后缀中的第一个元素作为扫描元素;第2~4行计算在记录r中存在扫描元素情况下的上限值;第6行计算在记录r中不存在扫描元素的上限值。其中take函数表示取该位置包括该位置之前的所有元素,drop函数表示取该位置之后的所有元素。
函数1PSFiltering混合后缀覆盖相似度上限计算upbound(Mix1,Mix2,q2)
功能:估算记录对覆盖相似度上限
输入:有序字符串Mix1,Mix2和q2
输出:估算覆盖上限upbound
1.scanning-token=Mix1.get(first)
2.pos=q2.getpos(scanning-token)
3.if(pos.exist)
4.return 1+min(Mix1.drop(first),q2.drop(pos))
5.else
6.return 1+min(Mix1.drop(first),Mix2)
7.end if
算法1描述的是过滤方法PSFiltering。第1~2行根据参数获取记录前缀;第3行获取较短记录的后缀q2;第4行取前缀共同元素个数 prec;第5行取前缀中最后一个共同元素;第6~7行分别获取共同元素之后的混合后缀;第8行计算记录s和r的覆盖相似度下限,通过比较上限值与必须满足的最小覆盖相似度大小,判断该记录对是否可以成为候选记录对,进而进行确认阶段的计算。
算法1双缀过滤PSFiltering(s,r,t)
功能:基于双缀有序记录对过滤
输入:记录对s和r,以及Jaccard阈值t输出:满足阈值相似记录对
1.p1=s.getprefix(t)
2.p2=r.getprefix(t)
3.q2=r.getsuffix(t)
4.prec=p1∩p2//取记录对s和r的前缀的交集
5.lastc=(p1∩p2).getlasttoken
6.Mix1=mixSuffix(s,lastc)
7.Mix2=mixSuffix(r,lastc)
8.up=prec.size+upbound(Mix1,Mix2,q2)
9.if(up≥(s.size+r.size)×t/(1+t))
10.verify(s,r)
11.end if
4.2 基于双缀过滤的分布式相似性连接算法
根据第3.2节中基于Spark分布式前缀过滤相似性连接RDD转换操作图,实现基于双缀过滤的相似性连接PSJoin。如图4所示,该图与图1相似,但不同之处在groupBykey阶段。该图描述了PSJoin在Spark数据流处理过程。图4通过groupBykey对记录进行聚集,实现PSFiltering过滤,在确认阶段计算实际相似度,得到最终结果并进行存储。
5 基于双缀过滤的权重相似性连接算法
5.1 权重相似度过滤原理
在现有的基于覆盖相似度度量中,绝大多数计算均假设记录中的元素对于区分相似程度的贡献在数值上是相同的。例如,覆盖相似度中,每一个元素的贡献度均相等。但是,不同的元素对记录之间的相似度贡献度不一样,贡献度称为权重,文献[4]提到了基于覆盖相似度的权重相似度计算。假设对每一个token都有一个权重的赋值,定义wt(e)表示e词语的权重,式(6)表示基于覆盖相似度的权重相似度计算:

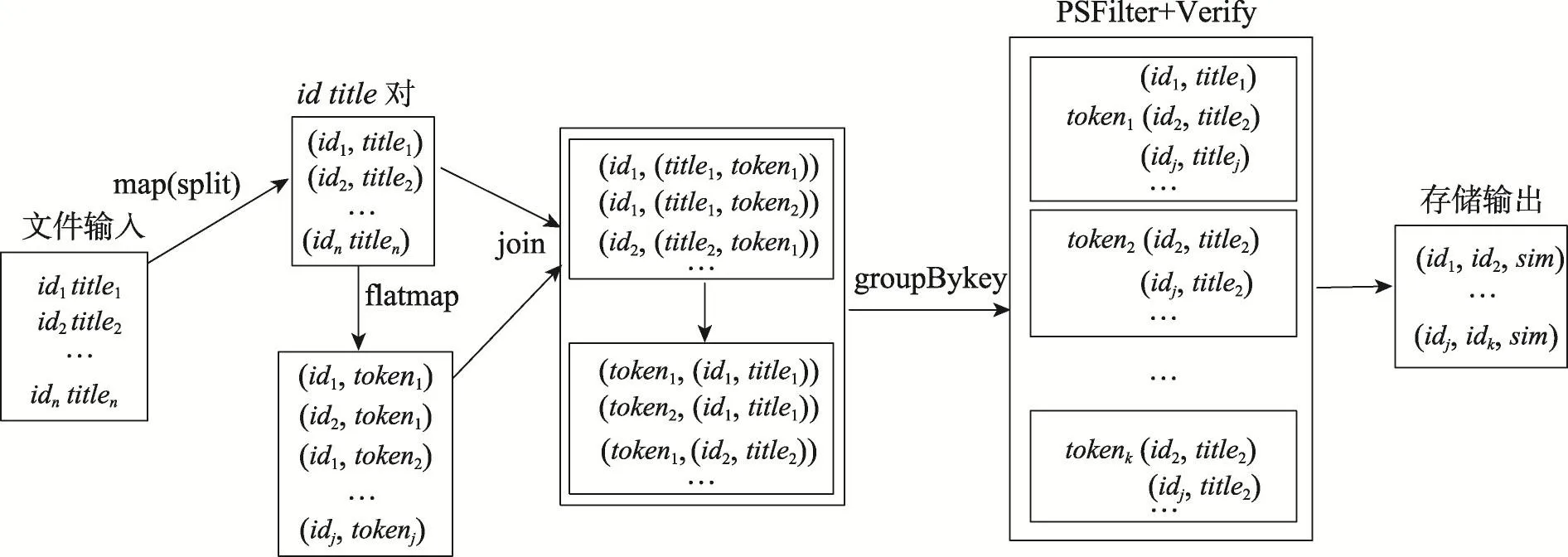
Fig.4 Data processsing in distributed PSJoin图4 分布式PSJoin数据流程图
同时文献[4]提出了基于覆盖相似度的过滤方法,如图5所示,对于记录s,设基于权重的Overlap相似度阈值为α,那么该记录的前缀权重之和最低为 β1=Wt(s)-α,因为记录中的元素分割不是以每个token作为一个分割体,而是以一个token并且附带着权重(weight)的形式出现并且划分的,所以在计算取前缀token时,前缀中所有的token的权重之和刚好大于 β1。
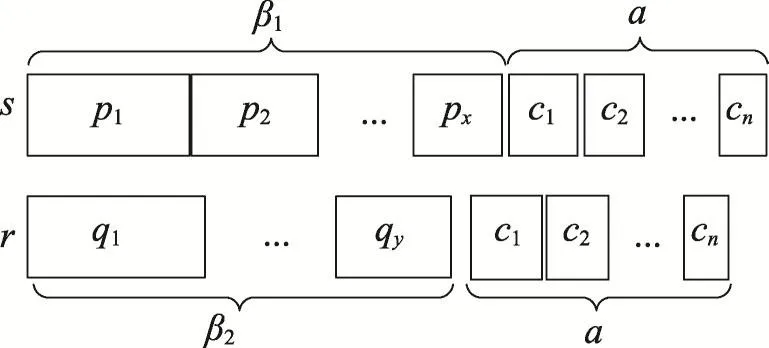
Fig.5 Weighted ordering records图5 有序权重记录
假设 prefixβ1(s)表示记录s的前缀元素token集合。如果 WtO(s⋂r)≥α,则 prefixβ1(s)⋂prefixβ2(r)≠∅。如果前缀中没有交集,即 prefixβ1(s)⋂prefixβ2(r)=∅,那么s和r记录的WtO(s⋂r)<α。
式(7)为基于Jaccard的权重相似度计算[1]。设WtJ(S,R)阈值为t,则有式(8)。其证明过程类似于Overlap阈值与Jaccard阈值关系证明[4]。
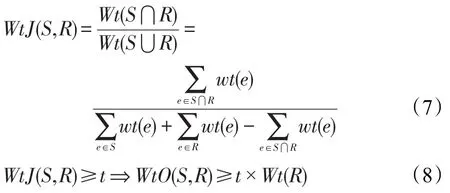
权重作为基于权重相似度计算中的重要部分,其计算具有十分重要的意义。对文本进行基于权重的相似度计算时,由于相同的词具有相同的权重值,本文使用无序过程中的权重赋值逆文本频率指数(inverse document frequency,IDF)。
5.2 基于双缀过滤的权重相似性连接原理
现有的基于权重计算的过滤算法中,文献[4]实现了基于PPJoin+的权重相似性连接。本文在第2章提出了利用前缀与后缀之间共同元素位置关系的过滤方法PSFiltering。结合权重相似度的特点,利用PSFiltering的过滤思想,本文提出双缀过滤方法的权重相似性连接WTPSFiltering(weighted PSFiltering)。
如图6所示,记录s和r分别表示带有权重的记录,并且记录中的token按照权重由大到小进行排序,获取记录的前缀集合。p1和p2分别表示记录s和记录r的前缀集合,q1和q2分别表示记录s和记录r的后缀集合。prec表示前缀交集大小,wtsumprec表示前缀交集中元素权重和,如图6,prec=1即为元素A,wtsumprec=0.7。不同于PSFiltering,为了达到更好的过滤效果,利用元素的权重而不是元素本身进行比较,也就是说,不需要考虑元素本身,仅需要该元素的权重值。权重在某种程度上也是一种“序”,权重的大小可以表示token的一种排序关系,对于权重相等的token,可能不是同一个token,但是对于同一个token,它的权重一定相等。如图6所示,A作为前缀中最后一个token,为了更加准确地估计记录s和记录r的覆盖相似度的上限upbound,需要利用A后面元素scanning-token的权重信息作为过滤条件。
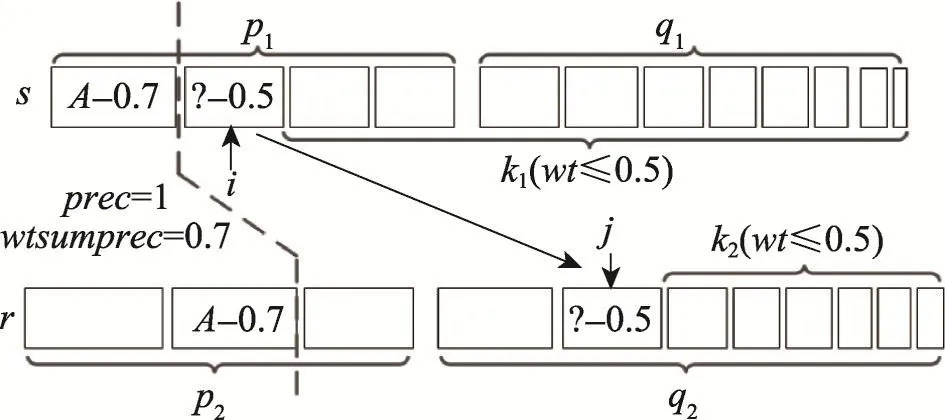
Fig.6 WTPSFiltering图6 WTPSFiltering方法
以图6为例,取记录s的前缀中最后一个common token之后的第一个元素,该元素在记录s中的位置为i,权重为0.5,此时,只需要关注该元素的权重,利用权重大小对记录r的common token之后的所有元素进行扫描,过滤出所有权重小于等于0.5的token。假设r中j位置之后的元素的权重都是小于或者等于0.5的,对于j之前和A之后的元素的权重都是大于0.5且小于0.7的,因此这期间元素是不可能对upbound有贡献的。除了前缀中的common token,另一部分就是k1和k2中权重之和较小的作为upbound的一部分。因此基于权重过滤上限由式(9)计算可得,其中wt表示元素权重或者集合中所有元素权重和。
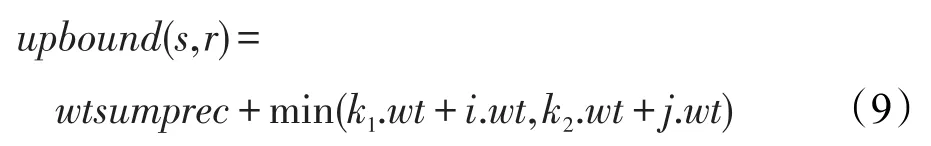
选择权重信息作为过滤条件与选择token本身相比,能够加强过滤效果。这是因为如果选取记录s中的common token之后的token本身信息作为扫描元素,需要考虑在记录r中是否存在该元素。但是对于选取权重信息作为过滤条件,可以有效地避免scanning-token不存在的情况,只需要比较大小就可以选取记录中小于等于扫描元素权重的所有元素,不需要做其他比较。
基于权重过滤改进算法WTPSFiltering描述如算法2所示。第5行描述取记录s中的最后一个common token位置,如图6中A的位置;同理第6行取记录r中的最后一个common token位置;第7~8行分别取记录s和记录r中的common token之后第一个token,scanning-token1和scanning-token2。比较 scanningtoken1和scanning-token2权重大小,选取权重较小者作为扫描元素,这样可以最大限度地降低混合后缀权重之和大小,使上限估计值更贴近真实值,过滤效果更好。
算法2双缀权重过滤算法WTPSFiltering(s,r,t)
功能:基于记录中权重信息实现有序记录对过滤
输入:记录对s和r,以及WtJ阈值t
输出:该记录对是否满足阈值限定条件
1.p1=s.getprefixw(t)
2.p2=r.getprefixw(t)
3.prec=p1⋂p2//取记录对s和r的前缀的交集
4.wtsumprec=prec.wt
5.pos1=s.getpos(prec.last)//取前缀交集最后位置
6.pos2=r.getpos(prec.last)
7.scantoken1=s.get(pos1+1)
8.scantoken2=r.get(pos2+1)
9.if(scantoken1.wt<scantoken2.wt)
10. k2=r.filter(≤scantoken1.wt)
11. up=wtsumprec+min(s.drop(pos1).wt,k2.wt)
12.else
13. k1=r.filter(≤scantoken2.wt)
14.up=wtsumprec+min(r.drop(pos2).wt,k1.wt)
15.end if
16.if(up≥(s.wt+r.wt)×t/(1+t))
17.verify(s,r)
18.end if
5.3 基于双缀过滤的分布式权重相似性连接算法
不同于双缀过滤的分布式相似性连接,权重相似性连接在计算过程中需要附加权重信息。利用Spark实现基于WTPSFiltering的权重相似性连接WTPSJoin,其RDD转换如图7所示。其中有两个输入,一个输入是需要处理的文本string,以论文的id和title为例,另一输入是所有title中token的权重。map转换动作中是将记录中title的每一个token赋予相应的权重并且按照权重值由大到小进行排序,生成(id,title-weight)形式RDD。在flatmap中应用权重信息计算前缀权重和,并且根据前缀建立倒排索引。通过 join将两个key值相同的RDD连接在一起,返回用于分组的数据形式(token,(id,title-weight)),在groupByKey阶段聚集相同的token,使用过滤算法WTPSFiltering进行过滤得到候选集。
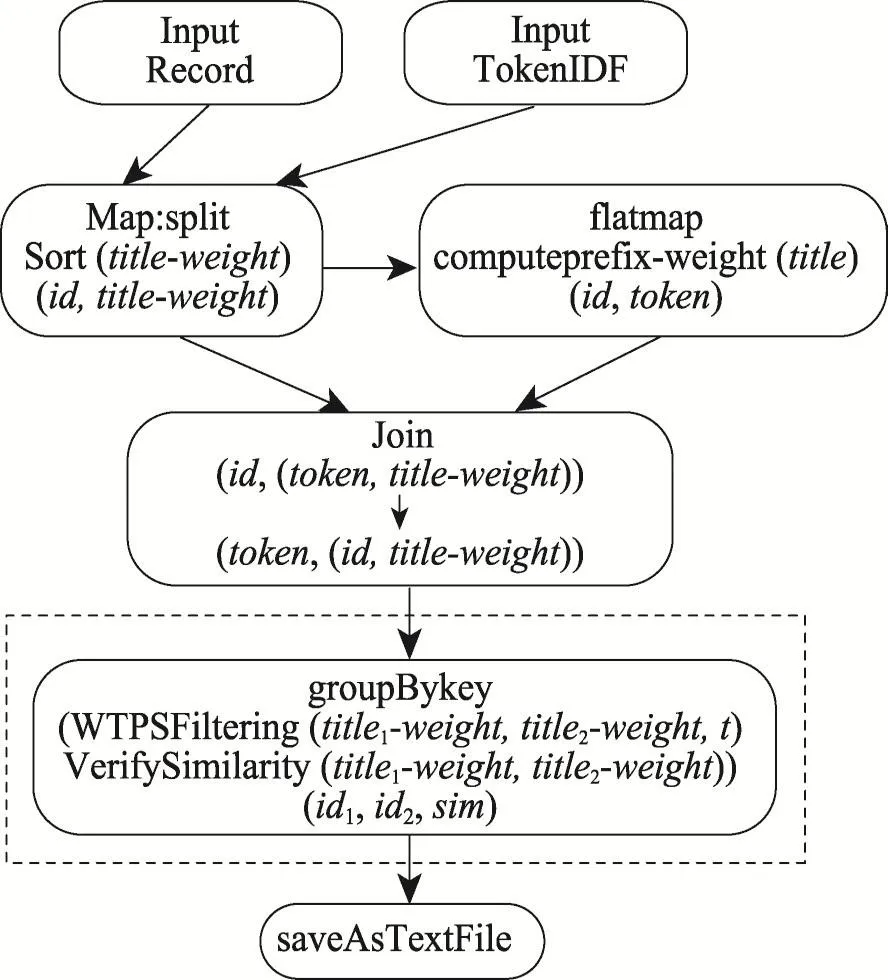
Fig.7 RDD transformations of WTPSJoin on Spark图7 基于Spark WTPSJoin的RDD转换图
6 实验结果与分析
本文所有算法的实现使用编程语言scala,满足分布式Spark编程需求。本文实验环境使用10个Slaver节点和1个Master节点的Hadoop作为分布式文件的存储环境,构建了10个Worker节点和1个Master节点的Spark集群。
节点环境如下:
(1)CPU:Intel®XeonE5-2620CPU@2.0GHz;
(2)内存:32 GB DDR RAM;
(3)硬盘:8 TB;
(4)操作系统:Fedora Linux。
集群环境版本如下:
(1)Hadoop集群版本为Hadoop-1.0.4;
(2)Spark集群版本为Spark-1.0.0;
(3)Java版本为1.6.0_43。
相对于分词技术,本文侧重于对算法效率进行研究,因此实验中所使用的测试数据集为EI论文数据集以及少量DBLP数据集和Citeseerx数据集等英文数据集。其中用于测试PSJion的数据格式为id-title文件,包括DBLP(162 MB)、EI(262 MB)、Citeseerx(100 MB)。用于测试WTPSJoin的数据格式为idabstract文件,主要利用EI(370 MB)数据集中的摘要进行权重相似性连接。本文数据集是在项目研发过程中通过网络爬取获得的,为了验证算法在大量数据下的效果,对原始数据进行了统计以及随机扩充,对数据中出现的所有词建立词表,随机抽取词表中一定数量词对原始数据进行循环扩充,扩充3种数据集的混合数据集为1.4 GB,与扩充前相比,相似记录对比例会发生变化,数据集里依然存在大量的相似数据。本文实验主要测试算法过滤效果、执行时间以及加速比。
(1)过滤效果
如图8所示,该图描述的是id-abstract数据集在不同阈值情况下利用权重PPJoin+、WTPSJoin过滤之后的数据集大小以及真正满足Result集合大小。横坐标为不同的相似度阈值,相似度阈值分别为0.85、0.90和0.95。纵坐标为集合大小(候选集数据对数量),包括候选集合大小和结果集合大小。
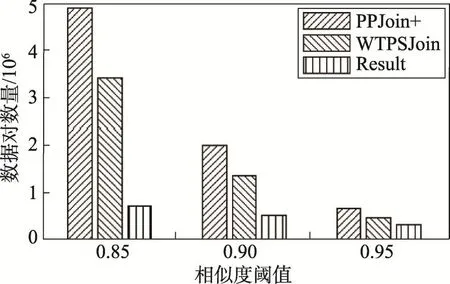
Fig.8 Candidate size in different weighted similarity join with different threshold图8 不同阈值下不同权重相似性连接算法候选集大小
图9描述的是id-title混合数据集(1.4 GB)在不同阈值情况下利用PPJoin、PPJoin+、PSJoin过滤后数据集大小。可以看出PSJoin的过滤效果明显好于其他两种算法。表1为该数据满足相似度阈值的记录对数量。
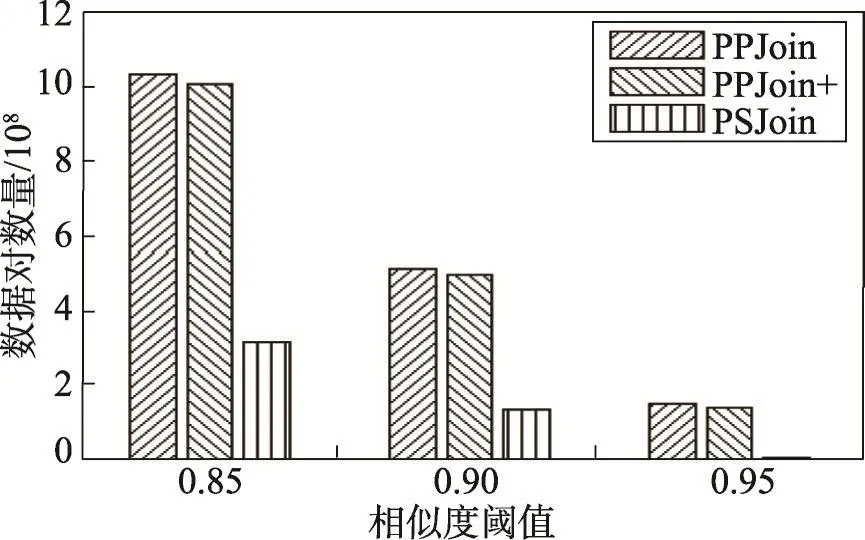
Fig.9 Candidate size in different similarity join with different threshold图9 不同阈值下不同相似性连接算法候选集大小

Table1 Record pairs with similarity over threshold表1 满足相似度阈值数据对数量
由图8、图9可知,从整体上看候选集合大小随着相似度阈值的增加会变少。无论是基于双缀过滤的PSJoin还是基于双缀过滤的权重相似性连接WTPSJoin,与PPJoin+相比均有较好的过滤效果,能将大量不必要数据对过滤掉,以降低候选集合大小,提高计算效率。
(2)不同算法执行时间
执行时间包括建立倒排索引时间、相似性连接时间、过滤时间和候选集合确认时间。
如图10所示,仅仅对比了效果较好的PPJoin+权重相似性连接与WTPSJoin。在不同的相似度阈值时,WTPSJoin的执行时间均低于PPJoin+权重相似性连接。随着相似度阈值的增加,算法之间的执行时间差异越来越小。
图11是PPJoin、PPJoin+以及PSJoin这3种相似性连接对数据量为1.4 GB的id-title文件的执行时间。同图10类似,随着相似度阈值的增加,3种连接算法执行时间均有减少,但PSJoin的执行时间始终少于其他算法。与此同时,各种过滤算法的执行时间的差异也越来越小。
(3)加速比对比
图12描述了不同算法随着节点个数增加对idtitle文件相似性连接执行时间的变化。节点个数由2个增加到10个,相似度阈值取0.90,随着节点个数增加,所有算法执行时间均降低,PSJoin执行时间始终低于其他算法。
图13为不同算法随着节点个数变化的加速比(即2节点时间/当前节点个数时间)。由图可知,随着节点数量增加,通信代价增加,与理想加速比差距增大,总体来讲PSJoin具有较好的加速比。
通过实验可以得到以下结论:
(1)双缀过滤方法可以达到良好的过滤效果,与现有的相似性连接算法相比执行时间较少。
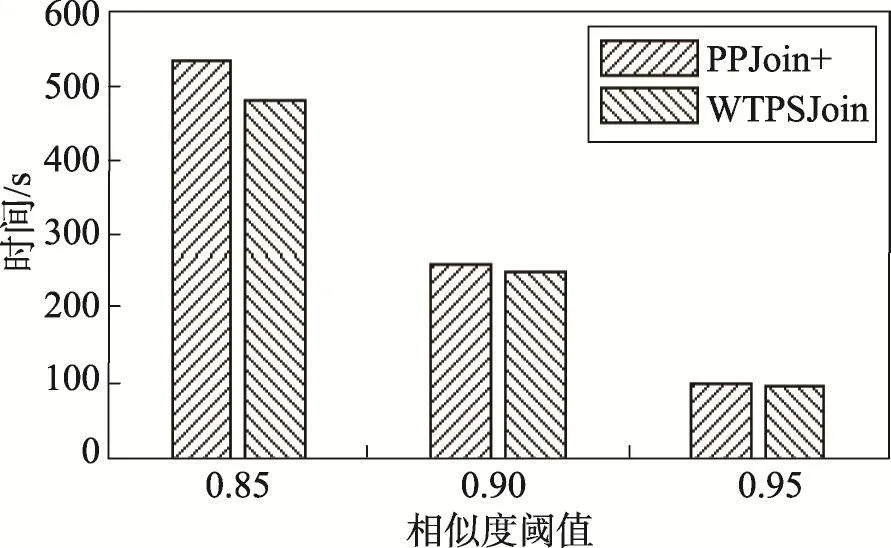
Fig.10 Time cost in different weighted similarity join with different threshold图10 不同阈值不同权重相似性连接算法执行时间对比
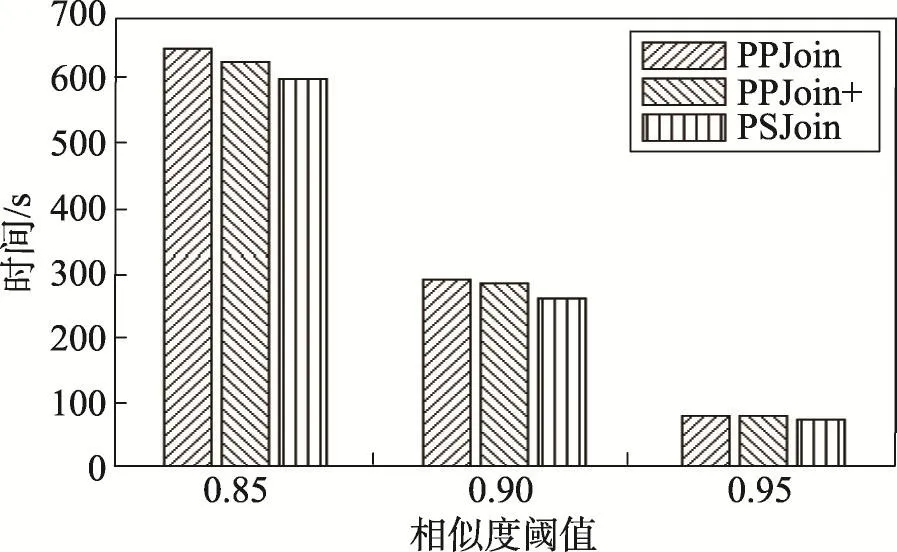
Fig.11 Time cost in different similarity join with different threshold图11 不同阈值不同相似性连接算法执行时间对比
(2)基于WTFiltering的方法具有良好的过滤效果,执行时间也少于集合相似度(区别于编辑距离等其他相似度度量)PPJoin+的执行时间。
(3)PSJoin具有良好的加速比。
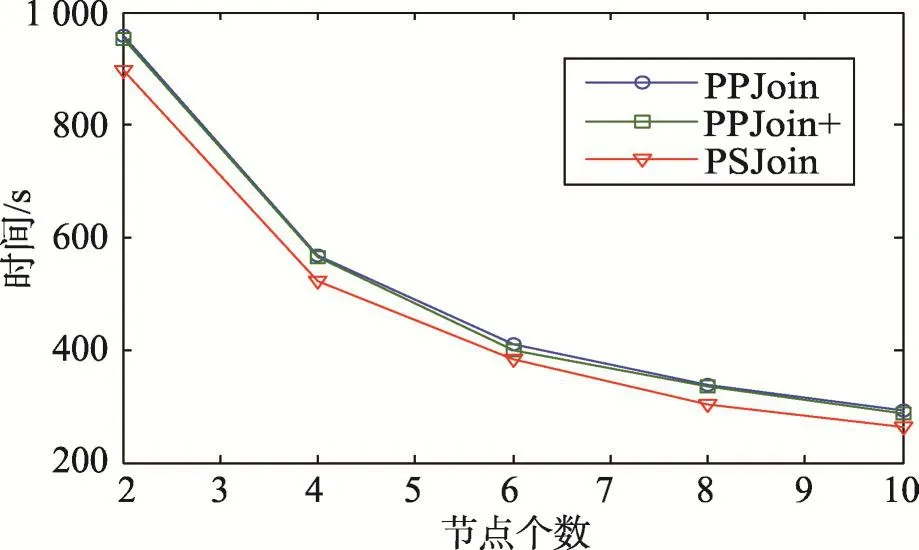
Fig.12 Time cost on different cluster size图12 不同节点数量相似性连接算法执行时间
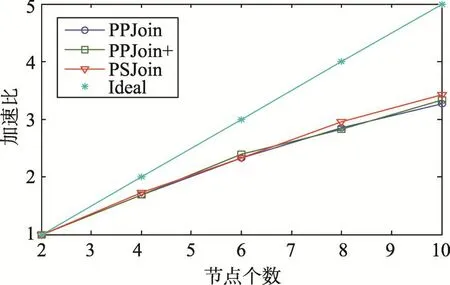
Fig.13 Speedup图13 加速比
7 总结
本文以Spark计算框架为基础,利用RDD计算实现分布式相似性连接。针对基于前缀过滤的PPJoin和PPJoin+中忽略前后缀之间的关联这一不足,提出了PSJoin相似性连接算法和基于权重相似性连接的WTPSJoin。其中,PSJoin利用不同记录前缀和后缀中第一个common token的位置信息实现过滤。WTPSJoin是利用记录对前缀之间common token之后的第一个元素的权重大小与另一条记录后缀元素权重大小之间关系实现过滤。同时,PSJoin具有良好的加速比。本文相似性连接算法中使用的过滤方法在扩充混合数据集合上性能表现良好,从理论上分析,本文过滤方法在记录前缀中共同元素之后的元素出现在另一条记录后缀中偏后位置时性能最佳,并且过滤方法可以根据原理应用到不同的计算平台。
在未来工作中,一方面结合不同的相似度度量函数的特点,例如编辑距离等,将基于位置信息的双缀过滤以及权重过滤进行扩展;另一方面,对权重过滤中的权重获取以及权重更新问题进行研究。
[1]Jiang Yu,Li Guoliang,Feng Jiahua.String similarity joins:an experimental evaluation[J].Proceedings of the VLDB Endowment,2014,7(8):625-636.
[2]Pang Jun,Gu Yu,Xu Jia,et al.Research advance on similarity join queries[J].Journal of Frontiers of Computer Science and Technology,2013,7(1):1-13.
[3]Chaudhuri S,Ganti V,KaushikR.Aprimitive operator for similarity joins in data cleaning[C]//Proceedings of the 22nd International Conference on Data Engineering,Atlanta,USA,Apr 3-7.Washington:IEEE Computer Society,2006:5.
[4]Xiao Chuan,Wang Wei,Lin Xuemin,et al.Efficient similarity joins for near-duplicate detection[J].ACM Transactions on Database Systems,2011,36(3):15.
[5]Sarawagi S,KirpalA.Efficient set joins on similarity predicates[C]//Proceedings of the 2004 ACM SIGMOD International Conference on Management of Data,Paris,Jun 13-18,2004.New York:ACM,2004:743-754.
[6]BayardoR J,Ma Yiming,SrikantR.Scaling up all pairs similarity search[C]//Proceedings of the 16th International Conference on World Wide Web,Banff,Canada,May 8-12,2007.New York:ACM,2007:131-140.
[7]Lin Xuemin,Wang Wei.Set and string similarity queries:a survey[J].Chinese Journal of Computers,2011,34(10):1853-1862.
[8]Wang Jiannan,Li Gguoliang,Feng Jianhua.Can we beat the prefix filtering?an adaptive framework for similarity join and search[C]//Proceedings of the 2012ACM SIGMOD International Conference on Management of Data,Scottsdale,USA,May 20-24,2012.NewYork:ACM,2012:85-96.
[9]Chuan Xiao,Wang Wei,Lin Xuemin.Ed-Join:an efficient algorithm for similarity joins with edit distance constraints[J].Proceedings of theVLDB Endowment,2008,1(1):933-944.
[10]Qin Jianbin,Wang Wei,Lu Yifei,et al.Efficient exact editsimilarity query processing with the asymmetric signature scheme[C]//Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data,Athens,Greece,Jun 12-16,2011.NewYork:ACM,2011:1033-1044.
[11]Xiao Chuan,Wang Wei,Lin Xuemin,et al.Top-k set similarity joins[C]//Proceedings of the 25th International Conference on Data Engineering,Shanghai,Mar 29-Apr 2,2009.Washington:IEEE Computer Society,2009:916-927.
[12]Wang Jiannan,Feng Jianhua,Li Guoliang.Trie-join:efficient trie-based string similarity joins with edit-distance constraints[J].Proceedings of the VLDB Endowment,2010,3(1/2):1219-1230.
[13]Ciaccia P,Patella M,Zezula P.M-tree:an efficient access method for similarity search in metric spaces[C]//Proceedings of the 23rd International Conference on Very Large Data Bases,Athens,Greece,Aug 26-29,1997.San Francisco,USA:Morgan Kaufmann Publishers Inc,1997:426-435.
[14]VernicaR,Carey M J,Li Chen.Efficient parallel set-similarity joins using MapReduce[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data,Indianapolis,USA,Jun 6-10,2010.New York:ACM,2010:495-506.
[15]Xia Junluan,Liu Xuhui,Shao Saisai,et al.Big data processing technologies on Spark[M].Beijing:Publishing House of Electronics Industry,2015.
[16]Zaharia M,Chowdhury M,Franklin M J,et al.Spark:cluster computing with working sets[C]//Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing,Boston,USA,Jun 22-25,2010.Berkeley,USA:USENIX Association,2010:10.
附中文参考文献:
[2]庞俊,谷峪,许嘉,等.相似性连接查询技术研究进展[J].计算机科学与探索,2013,7(1):1-13.
[7]林学民,王炜.集合和字符串的相似度查询[J].计算机学报,2011,34(10):1853-1862.
[15]夏俊鸾,刘旭辉,邵赛赛,等.Spark大数据处理技术[M].北京:电子工业出版社,2015.
Big Data Similarity Join Processing Based on Prefix-Suffix Filtering*
DENG Shizhuo,XIN Junchang,NIE Tiezheng,WANG Guoren+
School of Computer Science and Engineering,Northeastern University,Shenyang 110819,China
+Corresponding author:E-mail:wanggr@mail.neu.edu.cn
DENG Shizhuo,XIN Junchang,NIE Tiezheng,et al.Big data similarity join processing based on prefix-suffix filtering.Journal of Frontiers of Computer Science and Technology,2017,11(8):1235-1245.
Similarity join is one of the key techniques in entity identification and data integration which are significant for detecting valuable information.With the development of big data,it cannot satisfy the demand of efficiency to do the job on one machine.As a consequence,distributed computation becomes a better choice to improve the execution efficiency of similarity join.This paper gets a deeper understanding of processing algorithms for distributed similarity join based on Spark.Since the method using only suffix positional information for filtering has some shortcomings,this paper proposes a distributed similarity join processing method PSJoin,which uses the common token positional information between the prefix of one record and the suffix of another one.Also PSJoin can be applied to the weighted case with a little change for weight tokens.It compares the weight of the first token in the mix-suffix of one record with the weights of the tokens in the other record.The weighted similarity join with PSJoin is called WTPSJoin which improves the processing efficiency.The two new methods provide novel and efficient solutions for similarity join of big data.Experiments are tested on mixed datasets,and results show that the proposed algorithms have better performance in filtering,less running time cost and perfect speedup.
similarity join;weighted similarity join;big data;filtering;Spark
ang was born in 1977.He
the Ph.D.degree from Northeastern University in 2008.Now he is an associate professor at Northeastern University.His research interests include uncertain data management,big data management and analysis,etc. 信俊昌(1977—),男,辽宁辽阳人,2008年于东北大学获得博士学位,现为东北大学计算机科学与工程学院副教授,主要研究领域为不确定数据管理,大数据管理分析等。

DENG Shizhuo was born in 1990.She is a Ph.D.candidate at Northeastern University.Her research interest is big data management and analysis.邓诗卓(1990—),女,辽宁凌源人,东北大学博士研究生,主要研究领域为大数据管理与分析。

NIE Tiezheng was born in 1980.He is an associate professor at Northeastern University.His research interests include data integration,XML data management,NoSQL database system,entity resolution and data analysis for big data,etc.聂铁铮(1980—),男,辽宁沈阳人,东北大学计算机科学与工程学院副教授,主要研究领域为数据集成管理,XML数据管理,NoSQL数据库系统,大数据实体解析与分析等。

WANG Guoren was born in 1966.He received the Ph.D.degree from Northeastern University in 1996.Now he is a full professor and Ph.D.supervisor at School of Computer Science and Engineering,Northeastern University,and the member of CCF.His research interests include cloud computing,XML data management,data stream analysis,high-dimensional indexing and P2P data management,etc.王国仁(1966—),男,湖北崇阳人,1996年于东北大学获得博士学位,现为东北大学计算机科学与工程学院教授、博士生导师,CCF会员,主要研究领域为云计算,XML数据管理,数据流分析,高维索引,P2P数据管理等。
A
:TP316
*The National Natural Science Foundation of China under Grant Nos.61402089,61472069,61502215(国家自然科学基金);the Fundamental Research Funds for the Central Universities of China under Grant No.N150408001(中央高校基本科研业务费专项资金);the Natural Science Foundation of Liaoning Province under Grant No.2015020553(辽宁省自然科学基金).
Received 2016-08,Accepted 2016-10.
CNKI网络优先出版:2016-10-18,http://www.cnki.net/kcms/detail/11.5602.TP.20161018.1622.016.html
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2017/11(08)-1235-11
10.3778/j.issn.1673-9418.1608045
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
摘 要:相似性连接技术是实体识别和数据集成的关键技术之一,是挖掘数据中有价值信息的重要手段。随着大数据发展,传统的集中式相似性连接已经无法满足人们对数据处理的时效性需求,并且利用分布式计算可以提高相似性连接的执行效率。因此,深入研究了基于Spark的分布式相似性连接处理算法。针对仅使用后缀位置信息过滤方法的不足,提出了利用一条记录前缀与另一条记录后缀间共同元素位置信息来进行过滤的分布式相似性连接PSJoin,提高了相似性连接的处理效率,减少了相似性连接的执行时间。同时,针对基于权重的相似度连接算法的过滤问题,结合双缀过滤原理,通过一条记录前缀共同元素之后的第一个元素的权重与另一条记录后缀中元素权重大小的关系,提出了基于双缀过滤的分布式权重相似性连接WTPSJoin。为面向大数据的相似性连接计算提供了两种可靠的解决方案。两种算法在多数据源混合数据集上进行测试实验,实验结果表明,所提算法相对于已有的过滤算法过滤效果好,执行时间少,同时具有良好的加速比。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
中国新通信(2016年17期)2016-11-17
浙江大学学报(工学版)(2016年2期)2016-06-05
电脑知识与技术·经验技巧(2016年1期)2016-03-14
辽金历史与考古(2016年0期)2016-02-02
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
