
融合Fisher判别分析与波动序列的音乐推荐方法*
2017-08-16 11:10:19薛董敏赵志华
计算机与生活 2017年8期
薛董敏,赵志华
山西水利职业技术学院 信息工程系,山西 运城 044000
融合Fisher判别分析与波动序列的音乐推荐方法*
薛董敏+,赵志华
山西水利职业技术学院 信息工程系,山西 运城 044000
现有的音乐推荐方法多是采用不同的历史偏好相关性度量方法直接为用户生成推荐音乐列表,而不考虑用户历史喜好音乐行为所体现出的用户兴趣的波动性,影响了推荐音乐的准确率。针对这个问题,提出了一种融合Fisher线性判别分析与波动序列的音乐行为偏好获取方法。首先获取音乐的社会化标签与音频特征,采用Fisher线性判别分析对两类样本数据进行特征融合,通过投影变换并引入Fisher判别准则,获取具有最大类间离散度,最小类内离散度的音乐特征分类方向。然后结合用户的历史喜好音乐获取音乐类型基点、类型波动幅度,再以音乐类型基点为中心,以类型波动幅度为半径获取用户的喜好音乐类型,并据此为用户生成推荐音乐列表。在真实数据集LFM上的仿真实验结果表明,所提出方法能够取得更好的P@R值与覆盖率,提升了音乐推荐精度与推荐质量。
Fisher线性判别分析;波动序列;音乐类型基点;社会化标签;音乐推荐系统
1 引言
音乐自出现以来,就以其美妙的旋律伴随着整个人类社会文明进程的发展,在各种社会文化里,音乐被普遍地用来表达情感、舒缓压力、激发情绪等。音乐的类型、数量、展现形式等都随着其他相关技术的发展而逐渐发展起来,特别是近年来,随着数字多媒体技术的发展,音乐能够以更加灵活的形式出现在人们身边并影响着人们的生活,例如移动电话等几乎所有的智能终端都能够成为音乐的载体。承载工具的多样化可以让用户便利地享受音乐,却无法解决随着音乐库的整体规模不断增长与新音乐产生速度的加快,用户需要花费大量的时间和精力去获取自己喜欢的音乐的问题,这种时间和精力的开销会在一定程度上影响用户的音乐体验。该问题已成为各大音乐及其周边服务的提供商需要解决的关键问题。
在这种情况下,能够根据用户的历史音乐行为建立用户的兴趣音乐模型,并为用户推荐能够满足用户兴趣音乐的音乐推荐系统[1-2],成为缓解这个问题的主要解决方案。音乐推荐系统相比于传统的基于搜索的音乐获取模式,提高了音乐服务的智能程度,高准确率的音乐推荐系统能够大幅提升用户享受音乐的便捷性。因此,音乐推荐系统在近年来所扮演的角色及其应用广度与日俱增。
目前主要的音乐推荐系统实现策略包括:融合内容过滤的音乐推送方法[1-4]、考虑图模型的音乐推送方法[5]、基于语境信息的音乐推送方法[6]等。融合内容过滤的音乐推送方法主要采用相关的音频分析技术,提取出音乐本身的特征信息,并采用标签来描述音乐特征,再进一步地通过这些特征采用相关的相似度度量方法,将与之在内容特征上相似的音乐加入到用户的播放列表中[6]。基于图模型的音乐推荐系统主要将用户的历史音乐记录转化成图模型上的边和节点,用户对音乐的喜好行为被转化成边的权重,那么为用户生成喜欢的音乐列表,就转化成根据已有信息去度量用户节点与音乐节点间的相关程度,将相关度高的节点加到用户的偏好音乐列表中[5]。基于语境信息的音乐推荐系统是在传统的推荐系统的基础上,通过加入一些相关的上下文信息来达到推荐的目的。语境指的是所处的环境与在其使用过程中所产生的相关数据,从用户的角度而言主要包括:用户的性别、年龄、职业等个人信息;从音乐的角度而言主要包括:音乐的类型、时长、歌手、曲调等;从行为的角度而言主要包括:音乐的播放次数、用户的评价等[6]。
这些音乐推荐方法的基本思想都是基于用户的历史喜好音乐行为,通过不同的相似度或相关性度量方法直接为用户生成推荐音乐列表[3-4],而不考虑用户历史喜好音乐行为所体现出的用户兴趣的波动性,影响了推荐音乐的准确率。针对这个问题,本文提出了一种融合Fisher线性判别分析与波动序列的音乐偏好获取方法。相比于直接通过用户历史喜好音乐行为,通过类型相似度算法直接获取用户喜欢的音乐类型并生成推荐,本文方法能够根据用户历史喜好音乐行为所体现出的喜好音乐类型间的波动程度,获取更多的用户喜好音乐类型集合,也就有更大的概率覆盖用户的兴趣,取得更好的推荐结果。
2 融合Fisher线性判别分析与波动序列的音乐偏好获取方法
基于音乐类型的音乐推荐系统,主要通过用户历史喜好音乐的类型与待推荐音乐的类型之间的相异程度来为用户生成推荐音乐目录,在这些音乐推荐方法中,音乐类型的判定是算法的核心部分。本文提出了一种新的音乐特征判定方法,通过Fisher线性判别分析融合音乐的音频特征、社会化标签等特征属性,通过投影变换、特征融合获取具有最佳分类效果的分类策略。
2.1 基于Fisher线性判别分析的音乐特征融合
音乐的特征描述是音乐推荐系统的最基本要素,其应体现音乐自身的特征与用户的体验和情感特征描述,本文从音乐的音频特征、音乐的社会化标签两个层面对音乐特征进行描述,并对不同的分类特征进行融合,获取最佳的音乐特征。
社会化标签指的是由社交平台上的用户自发产生的短语或者关键词,用于描述和分类一个实体、概念或者观点。在音乐描述领域的社会化标签,即是由用户根据自己的历史经验知识,结合对音乐的感受,自发地产生对于音乐的描述类信息,通常用于辅助喜好情感的表达。由此可以得出,社会化标签是基于用户的对于音乐类型的标注信息。
现有的音乐系统,例如Last.FM、虾米音乐、豆瓣电台等,所采用的描述音乐的社会化标签,主要包括事实性标签(factual tag)与文化性标签(culture tag)。事实性标签即是基于音乐的自身事实信息对音乐进行标注,包括音乐的演唱者、发行时间、语言等内容信息;文化性标签主要描述的是涉及用户情感的对音乐的主观感知,例如音乐风格、心情等。标签的数据源主要有专家标注、用户标注、机器标注,其中专家标注指的是专业的音乐家或者音乐内容提供商对音乐进行规范描述或标注;用户标注主要是音乐用户在接受音乐服务的过程中将喜好情感等转化为语义标签对音乐进行标注;机器标注指的是通过机器学习方法进行自动标注。对于社会化标签本文采用描述频次的方法进行描述,即是记录具体音乐的社会化标签的标记次数,以便进行特征提取和特征融合。图1为音乐Linkin Park在知名音乐网站Last.fm上的标签频次。
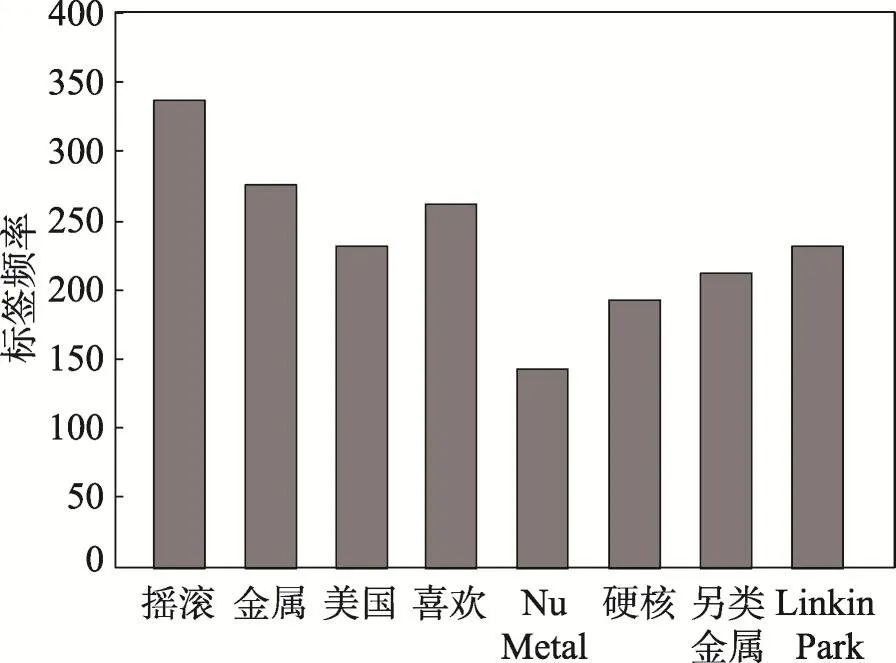
Fig.1 Frequency of Linkin Park's social tag图1 Linkin Park的社会化标签频次
音乐的音频特征指的是从音乐自身中抽取出的客观性的描述信息,例如节拍、节奏、旋律等,通过对音乐进行数字信号分析处理获取。其中最能反映音乐特征的是音乐的旋律,是音乐表述其内在特征的直观体现。本文对主要的近80个音频特征进行抽取,以最大限度地展现音乐的要素空间,具体如下:
(1)码率,描述音乐音质的主要指标,其值越大,音质越好;
(2)速率,描述单位时间内的节拍数;
(3)基准音量,描述由音乐自身波动幅度所产生的基础响度;
(4)采样率,描述音乐特征的可还原性;
(5)乐段数,描述音乐文件中表达完整乐曲的最小单元;
(6)拍号,描述单位小节中节拍数目与该小节中单位拍的商值;
(7)平均分段长度,描述音乐旋律与音乐音色相符时的最小声音单元;
(8)分段长度标准差,描述(7)的标准差;
(9)12个音色均值,描述单位分段计算12-Mel倒谱系数;
(10)60个节奏值,描述数字信号处理技术所反映的节拍的信号特征;
(11)过零率,描述音乐的高频、低频变化幅度与乐曲的波动程度。
以上近80个音频特征,采集的数据都是数值型数据,用于描述音乐的音频特征。其中,音乐类型特征的另一个指标包括节拍直方图[7]、美尔频率倒谱系数[8]、过零率[9]等。因为过零率被广泛地应用于区分音乐的高频、低频变化幅度与音乐波动程度,能够有效地从音乐底层特征的角度对音乐进行区分,所以本文采用过零率作为度量音乐类型的一个主要数据,具体如下:
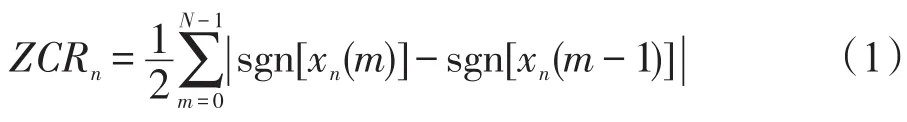
其中,ZCRn表示音乐n的过零率;sgn[]表示符号函数,表示如下:

在获取到音乐社会化标签、音频特征、过零率等数值型数据的基础上,本文采用Fisher线性判别分析对上述两种特征数据(过零率属于音频特征)进行特征融合,即根据转换后的各分类特征值的取值范围将音乐分类到不同的音乐类中。获取到的两类样本数据中,用表示获取到的社会化标签量化数据,表示获取的音乐音频特征数据,其中m1、m2分别表示MT与MP中的样本数量,则样本均值可表示为:

根据类间离散度与类内离散度定义,各类中的类内离散度矩阵可表示为:
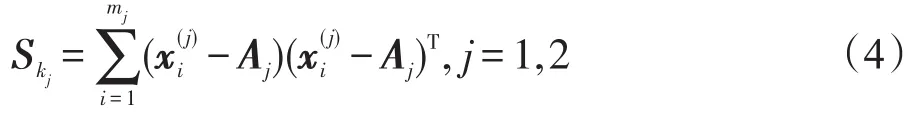
总的类内离散度矩阵可表示为:

两样本间的类间离散度矩阵可表示为:

其中矩阵(A1-A2)(A1-A2)T在数学表达上为协方差矩阵,描述了每条偏好数据与总体数据间的关联关系,对角线上的元素表示了此偏好样本与总体间的样本方差,非对角线上的元素表示了其总体矩阵的协方差。那么Aj即描述了样本总体内各类间的离散冗余程度,St即表示了各类间(即各音乐特征类)的离散冗余程度。
在获取到两类样本的类间离散度与类内离散度后,为了提高音乐特征类的准确度,即分类的精确度,需要尽可能地降低分类后的各音乐特征类间的耦合程度,增加各音乐特征类内部的聚合程度.也即是找到满足Aj尽可能小,而St尽可能大的分类准则,才能使得分类后的样本能够代表音乐本身的分类特性。为此,将原两类样本数据看作相应维度的向量,并以任一向量C为方向进行投影变换,转换规则为:

变换后的两类样本均值为:
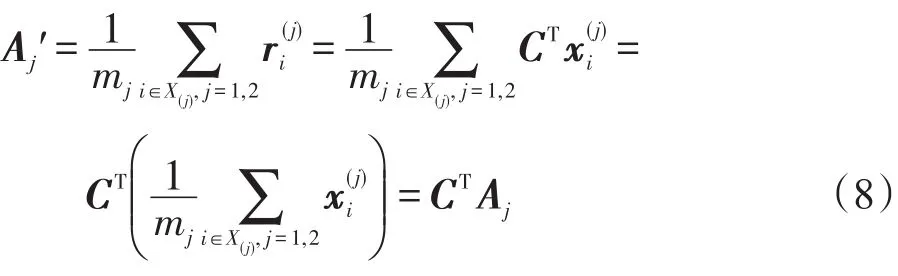
变换后的类内离散度为:
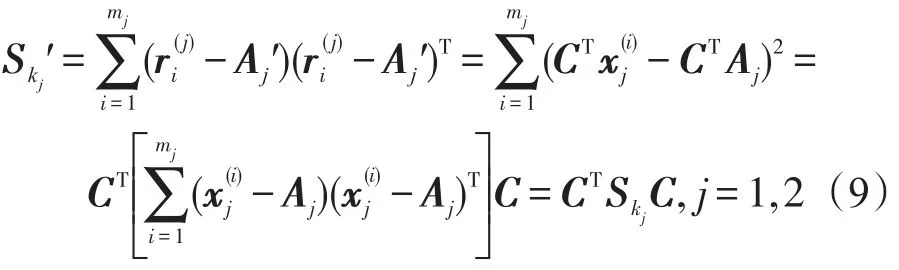
变换后的类间离散度为:
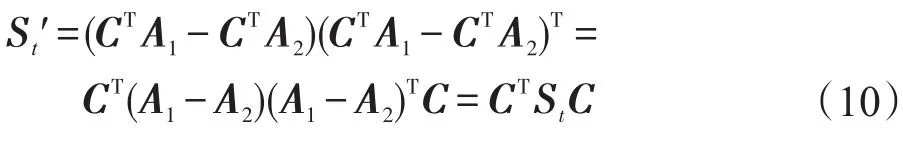
对于变换后的分类音乐集合的数据要求仍然是,需要尽可能地降低分类后的各集合间的耦合程度,增加集合内音乐特征类间的聚合程度。为此引入了Fisher判别准则,如下:

其核心思想为计算能够使JFisher取得最大值的投影方向,将前面所述投影变换代入可以得出:

采用Lagrange乘子法求解其最值,令分母为非零常数b,那么Lagrange函数定义如下:
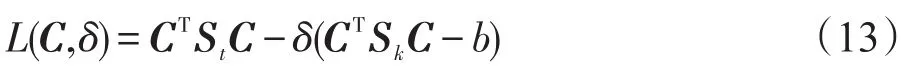
对C求偏导数可以得出:
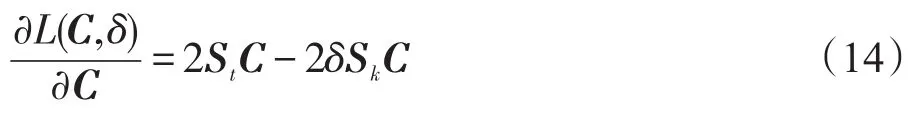
令偏导数为0,即是:


2.2 基于音乐类型波动序列的音乐偏好获取
定义1(音乐类型基点)以用户喜好历史音乐行为集合为基础数据,获取该集合中各类型音乐的占比及相应权重系数,并基于此获取用户历史音乐行为集合的音乐类型基点。音乐类型基点即是通过用户的历史偏好音乐行为,来获取初始的用户喜好音乐类型的基础数据,其表示的是用户比较喜欢的音乐类型的量化数据。具体表示如下:
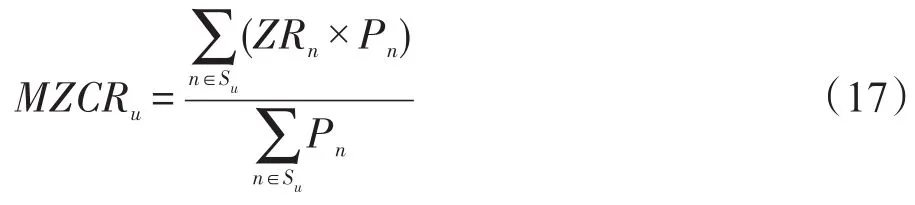
其中,MZCRu指代用户u的音乐类型基点;Su指代用户u的历史喜好音乐行为集合;Pn指代音乐n在Su中的播放数量;ZRn表示经过Fisher线性变换后的音乐分类特征。MZCRu即是用户喜好音乐类型的喜好中心位置,用户可能喜欢的音乐类型应分布在以此为中心,并距此有较短距离的集合内。
定义2(音乐类型波动序列)用户喜好音乐类型的波动数值数据。由于用户的喜好音乐通常会涵盖较多种类的音乐,并且用户对某类型音乐喜好会有较大的概率喜欢同类型的其他音乐。本文基于音乐自身属性与用户对于音乐喜好行为间的相似性,来度量音乐类型间的距离,该距离也即是音乐类型波动幅度,具体如下:
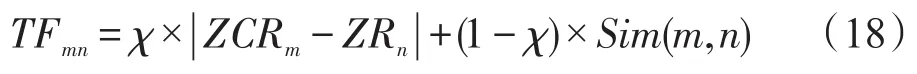
其中,TFmn表示音乐类型m与音乐类型n间的类型波动幅度;χ为度量Sim(m,n)表示音乐类型m与音乐类型n通过用户的喜好关系所表现出的相似性关系,度量方式如下:
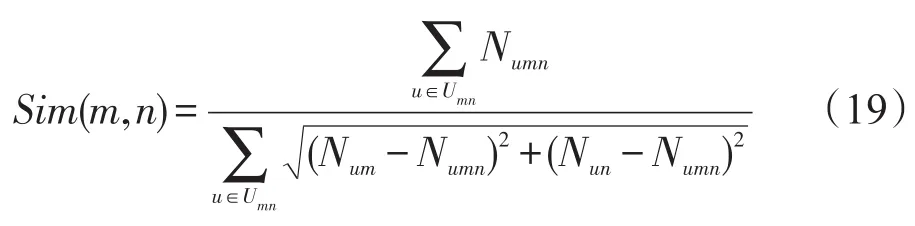
式中,Umn指代对于音乐类型m与n有过喜好音乐行为的用户集合;Num与Nun分别表示其相应集合内用户数量;Numn表示同时对音乐类型m与n有过喜好音乐行为的用户集合,其数值为Num与Nun的并集。
在获取音乐类型基点与音乐类型波动幅度的基础上,若能根据用户历史喜好音乐行为所体现出的喜好音乐类型间的波动程度,获取更多的用户喜好音乐类型集合,也就有更大的概率覆盖用户的兴趣,取得更好的推荐结果。因此本文结合波动幅度与类型基点获取用户喜好音乐的波动序列,即获取围绕喜好音乐类型基点以波动幅度为半径的音乐类型。其基本思想为,首先根据音乐类型波动幅度获取用户历史喜好音乐集合中所体现出的该用户的喜好音乐类型波动程度,再获取其喜好音乐波动序列。
那么任一用户u的喜好音乐类型波动程度取决于其历史喜好音乐集合中音乐类型波动幅度的幅度均值,具体如下:
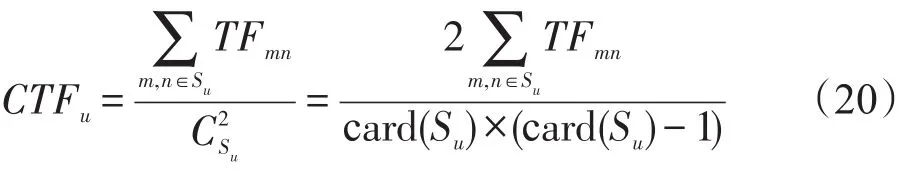
式中,Su表示用户u的历史喜好音乐行为集合;card(Su)表示Su中所包含音乐的数量。
那么用户喜好音乐类型波动序列PMu即可由CTFu与MZCRu共同表示,即:
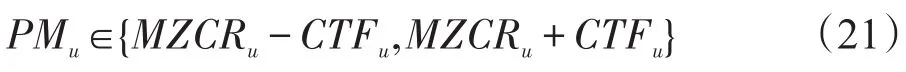
即表示用户的喜好音乐类型应分布于以MZCRu为类型基点,以CTFu为波动半径的类型集合内。其中,距离类型基点越近则说明该类型音乐有更大的概率符合用户的兴趣。
在获取到用户喜好音乐类型波动序列的基础上,将具体的音乐通过特征融合后的分类特征与音乐类型关联起来,根据音乐类型在PMu中的优先关系,为用户生成推荐的音乐列表。
2.3 算法实施步骤
本文算法的实施步骤如下:
输入:音频特征矩阵MP,社会化标签矩阵MT,用户的历史偏好音乐记录M。
输出:用户的推荐结果集。
步骤1根据式(1)与式(2)获取音频特征矩阵MP,与社会化标签矩阵MT;
步骤2将矩阵MP与MT转换为相应维度的向量表示,并以任意投影方向C进行投影变换,得到变换后的样本矩阵
步骤3获取投影后的样本均值矩阵CTSj,类内离散度矩阵CTSkjC,类间离散度矩阵CTStC;
步骤4如果投影方向C能够满足使得JFisher准则取得最大值,则C为最佳投影方向,并获得最佳的音乐特征分类结果矩阵ZR;
步骤5遍历音乐历史偏好矩阵M,与分类结果矩阵ZR,根据式(17)获取音乐类型基点矩阵MZCRu;
步骤6依据音乐类型距离式(18)与音乐类型相似度式(19)获取音乐类型波动序列TFmn;
步骤7依据类型基点与波动序列,遍历音乐集合,获取距离音乐类型基点最近的Top-N个音乐,并推荐给用户。
3 实验设计及结果分析
3.1 实验数据集
Last.fm是由服务领域与音乐受众遍布全球的Audioscrobbler团队开发完成的。Last.fm允许用户拥有属于自己的音乐界面、评价音乐、交流对相关音乐的理解等操作。实验所用数据集LFM是格拉斯哥大学的研究者们从音乐网站Last.fm上获取的真实用户数据[10],主要包括听过8首歌以上的用户及其相关音乐信息,里面共涵盖了3 148个喜爱音乐的用户对30 520首音乐的相关行为记录。在实验中将从Last.fm上获取的数据分为不同比例的训练集和测试集两部分,在训练集上测验算法涉及的参数,并在测试集上进行验证,具体的分类比例详见实验设计部分。
3.2 算法评价标准
本文采用P@R[11]作为推荐音乐准确性的评价标准,P@R可以根据本文提出的基于波动序列的音乐推荐算法所获取的推荐音乐序列生成R个音乐集,并将这R个音乐集与训练集中该用户最常听的R个歌曲进行对比,以度量推荐音乐的准确性[12-13]。在实验中的主要做法为隐去数据集中用户最常听的歌的听歌记录,用算法去预测它是否是用户喜欢的歌,推荐效果与P@R的数值呈正比关系,具体如下:

覆盖率(coverage rate)[14]是衡量推荐质量的另一个评价标准,其反映的是推荐算法发掘长尾效应的能力,即是为了防止推荐系统只推荐一些比较热门的资源,而无法把一些可能符合用户兴趣的冷门资源推送至相应用户。覆盖率的数值与推荐效果呈正比例关系,可表示为:

式里,R(u)指代为用户u生成的偏好列表;I指代训练集中对应的物品集合。
3.3 实验设计
本文实验目的如下:(1)验证Fisher线性判别分析能否对不同音乐有较好的区分效果;(2)针对当前数据集,研究参数对方法效果的影响程度及最优参数取值;(3)与现有方法相比,所提出方法能否取得更好的音乐推荐效果。
实验主要包括三部分:
第一部分是Fisher线性判别分析对音乐的区分实验,主要测试本文所用的音乐类型区分算法能够比较有效地把音乐区分出来。音乐类型的判断是本文的基础,好的音乐类型算法应能够反映出音乐自身的特性,并把每个音乐分类到合适的类别中。在本文所用的音乐数据集中,测试通过Fisher线性判别分析能否融合社会化标签数据与音乐的音频数据,并有效地将音乐分类。经过反复测试,根据特征融合后的数值将音乐分为200个类(音乐分类越精确,越有利于获取高准确度的用户偏好),相关实验结果见图2。
第二部分是参数检验实验,主要检验音乐波动幅度中的χ参数,也即是获取用户对于音乐喜好行为间的相似性与类型差异间的最优权重比。针对实验所用数据集LFM,分别提取10%、30%、60%、80%的数据作为训练集,其余作为测试集进行实验,对音乐类型波动幅度公式中的参数χ进行实验分析。参数χ影响的是用户对于音乐喜好行为间的相似性与音乐类型差异两种因素,实验分析了二者对于音乐类型波动幅度的影响程度。由于只有两种影响因素,参数χ的取值空间为0到1间任意数值,经过反复实验测试,选取了几组有代表性的χ取值(见表1),相关的实验结果如图3~图6所示。
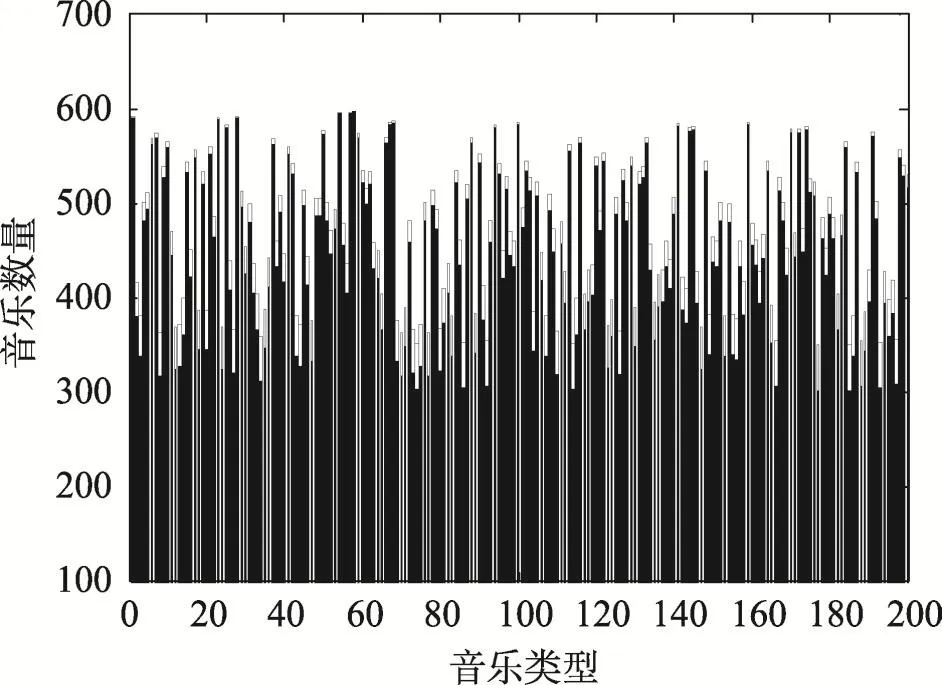
Fig.2 Results of music classification图2 音乐分类结果图
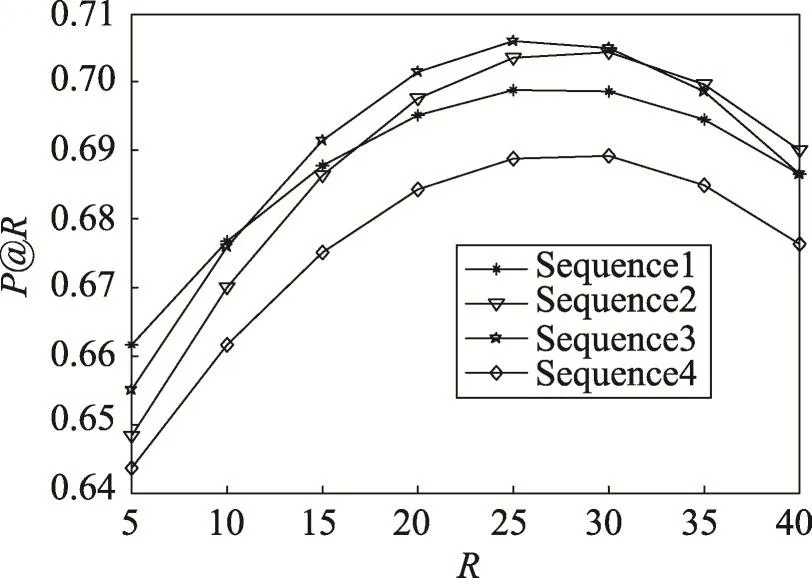
Fig.3 Results of 10%data as training set图3 10%数据作为训练集的实验结果
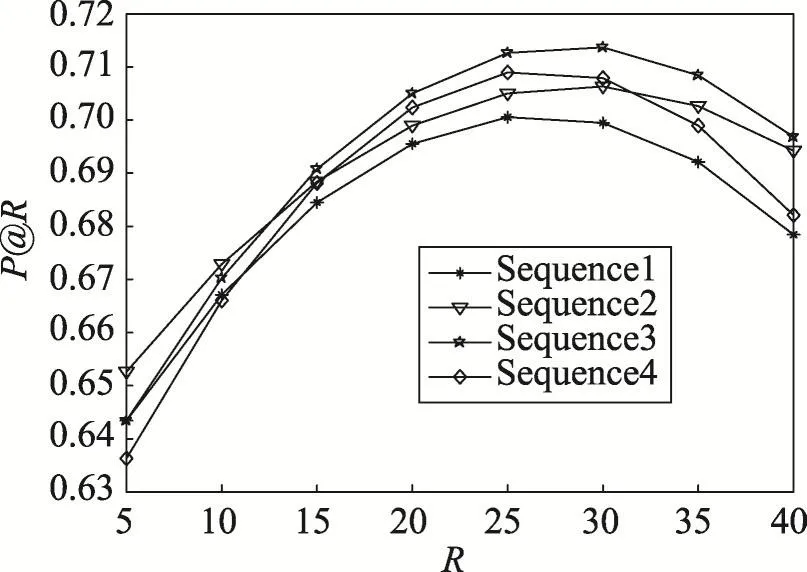
Fig.5 Results of 60%data as training set图5 60%数据作为训练集的实验结果

Table1 Value table ofχ表1 参数χ的取值表
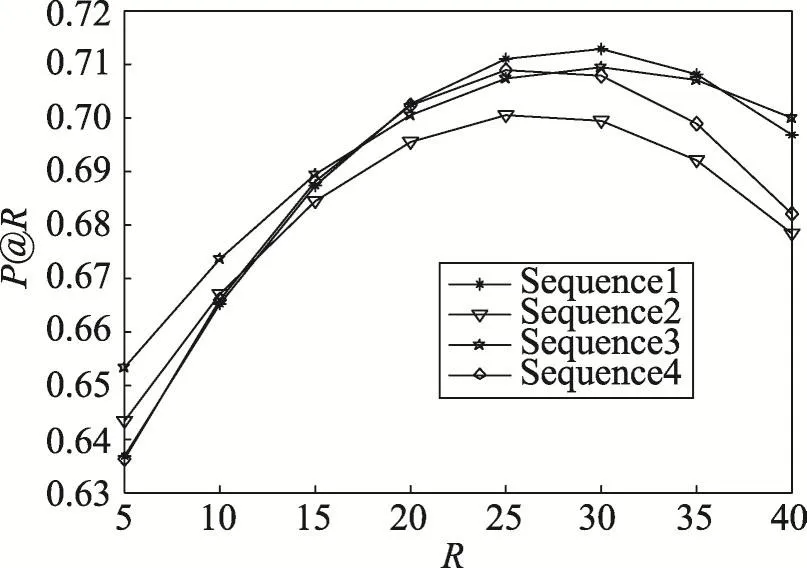
Fig.4 Results of 30%data as training set图4 30%数据作为训练集的实验结果
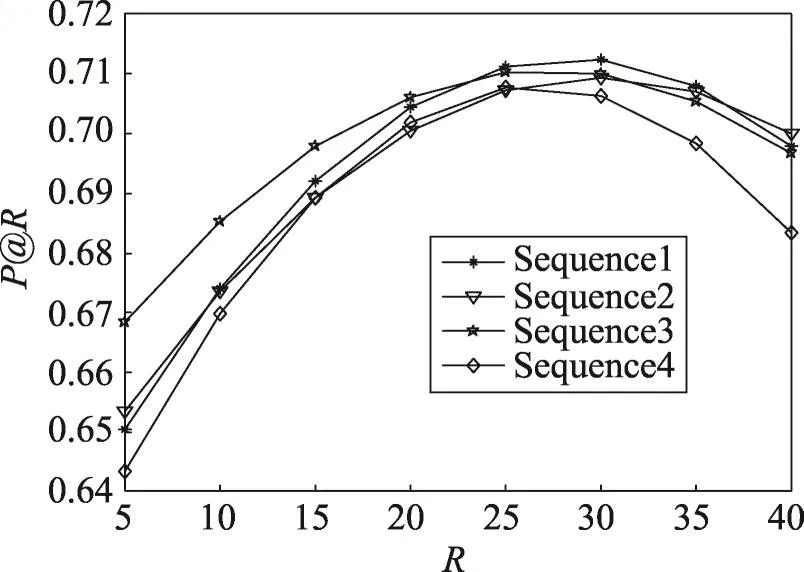
Fig.6 Results of 80%data as training set图6 80%数据作为训练集的实验结果
第三部分是对比实验,把本文提出的基于波动序列的推荐策略与现有方法展开对比。经过反复实验对比,在30%与60%两种数据集模式下,将本文基于类型波动序列的推荐算法与基于用户兴趣的MRGI[15](music data grouping and user interests)及 MFCC[6](musical feature for content context)算法进行对比分析。MRGI是基于音乐数据聚类与用户兴趣的音乐推荐方法,MFCC主要采用Mel倒谱系数提取音乐的本身特性,并基于高斯混合模型与音乐模板库为用户提供音乐推荐服务。采用P@R与覆盖率作为度量其准确率的评价标准。基于P@R的对比实验包含两部分:整体分析实验与测试实例。其中整体分析实验结果如图7~图8所示,测试实际结果见表2。
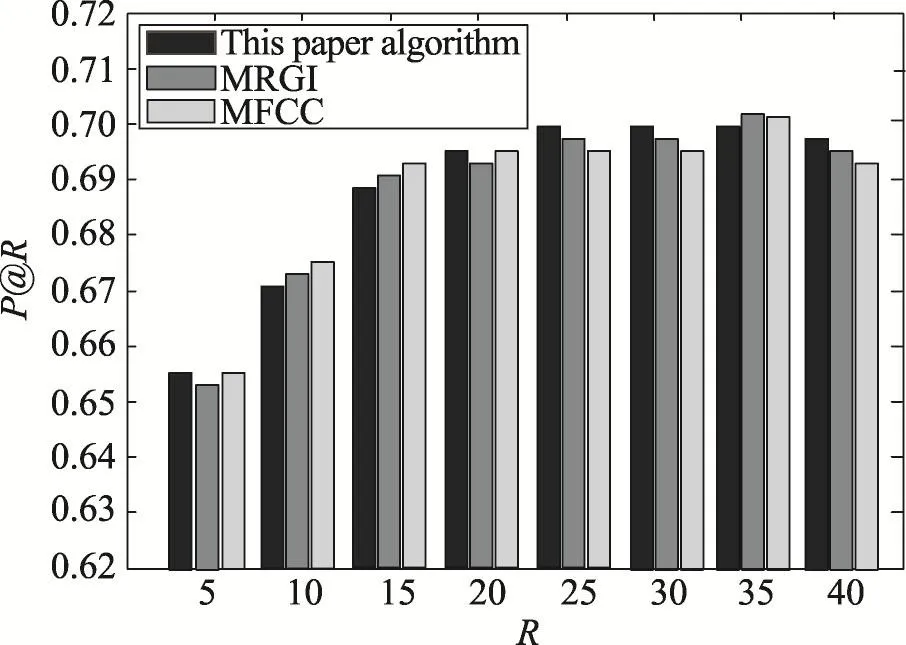
Fig.7 Comparative results of 30%data as training set图7 30%数据作为训练集3种算法对比结果
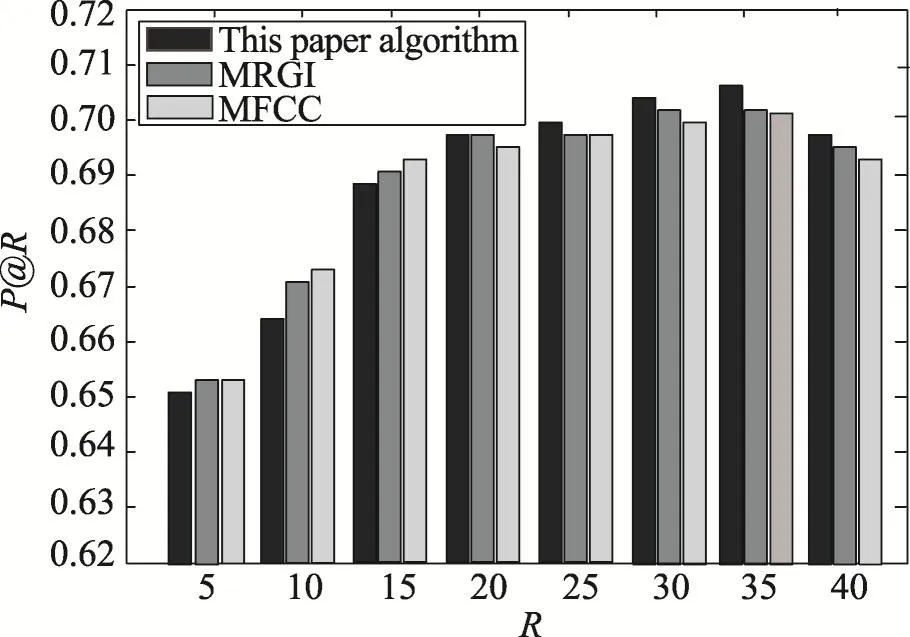
Fig.8 Comparative results of 60%data as training set图8 60%数据作为训练集3种算法对比结果
基于覆盖率的对比实验设计如下:经过反复测试,选取在60%数据作为训练集时的对比实验作为覆盖率的实验结果,相比于其他几种不同比例的数据集模式,在60%数据作为训练集的情况下,3种算法的覆盖率总体上都能够取得相对较大的值,并且降低的速度在可接受的范围内。实验结果如表3所示。
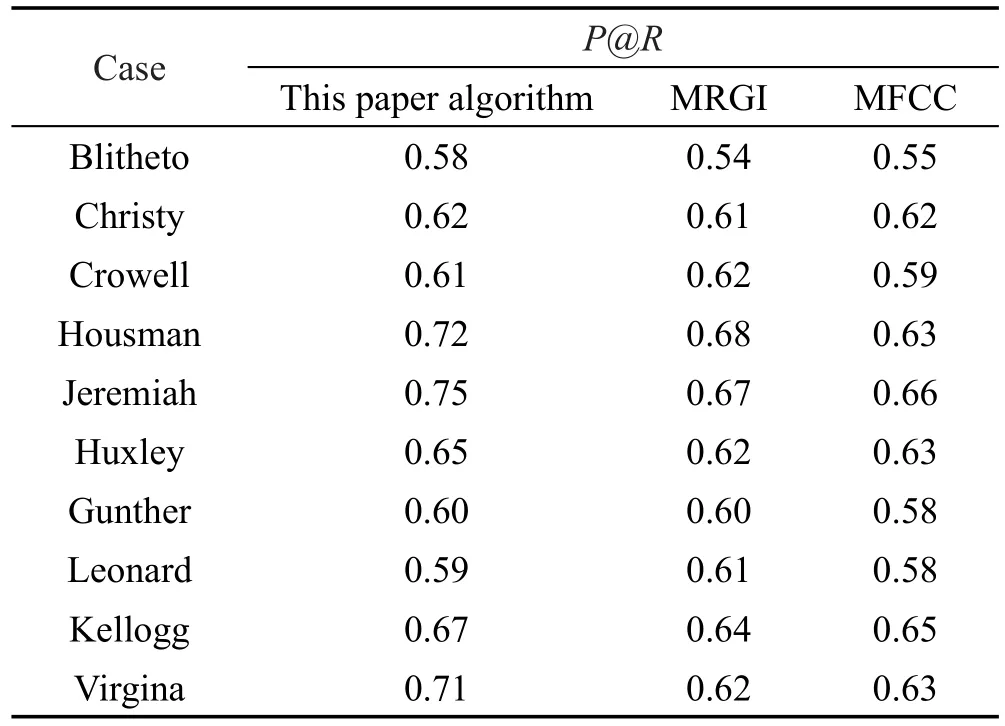
Table2 Experimental results of test cases表2 测试实例实验结果
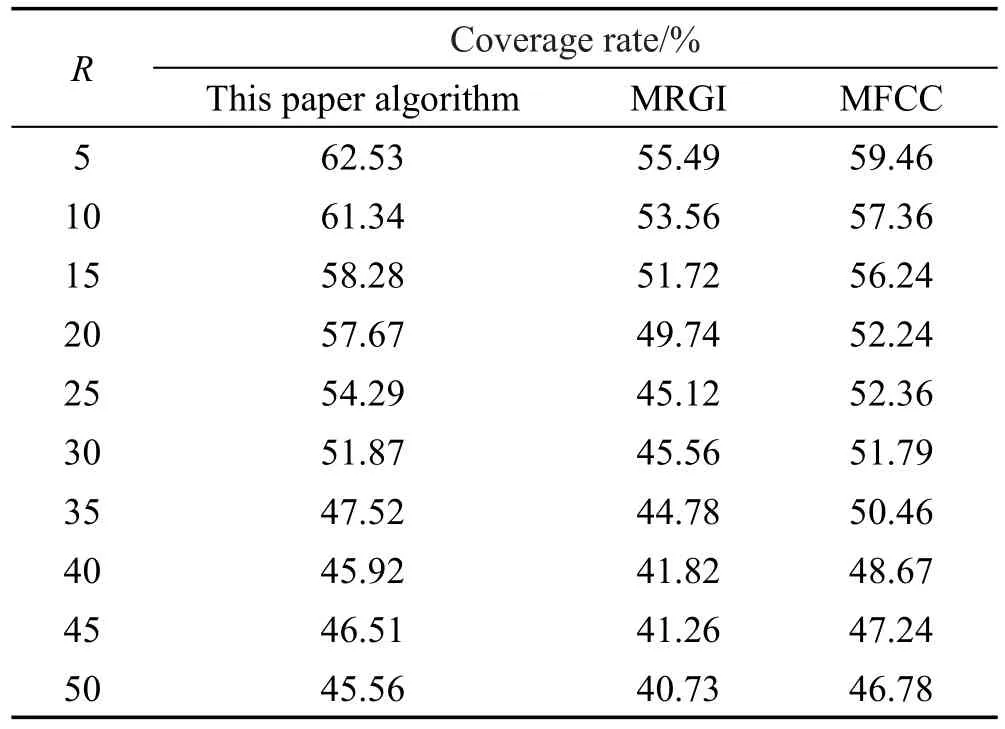
Table3 Comparative results of coverage rate表3 覆盖率对比实验结果
3.4 实验结果与分析
实验1Fisher线性判别分析对音乐的区分实验。
在实验结果图2中,x轴代表不同的音乐类型(只表示出数量,没有标记出类型名),每条柱状线表示该类型下所包含的音乐数量。从图2中可以看出,针对LFM数据集,采用Fisher线性判别分析能够较为平均地将音乐分类到不同的音乐类型中,各音乐类型中,每类音乐数量非常多与非常少的音乐类较少,多数的音乐类都包含数量相当的音乐,也即是能够获取到更佳的音乐分类结果。
实验2参数χ的影响分析实验。
综合对比图3~图6的4组实验结果数据,可以看出随着训练集比例的增加,本文算法的推荐效果也随之提高,这说明获取较多的用户音乐行为记录,然后训练算法所涉及参数,有利于取得更好的推荐效果。并且随着R值的增加,P@R值呈现出先增后减的趋势,4组实验结果下R的最优取值范围在25~30间,说明针对当前数据集,用户的有效音乐历史行为数量约为30个。分别对比各数据集模式下,参数χ的不同取值对于推荐效果的影响可以发现,当χ=0.4时4种比例下的实验数据能够取得总体的最优值,也即说明了用户对于音乐的喜好行为间的相似性对于音乐波动幅度的影响,要大于音乐自身的类型差异对其所产生的影响。在以下的实验中取χ=0.4。
实验3与其他算法对比实验。
从实验结果图7~图8可以看出,在LFM数据集上以P@R为评价标准,本文基于波动序列的音乐推荐算法,在两种不同数据集比例下,能够取得更大的P@R值,即推荐准确度要优于MRGI与MFCC。这一结论也在随机抽取的测试实例中得到了验证,见表2。从覆盖率的对比实验结果表3中可以看出,随着R值的增加,3种算法的覆盖率都随之减少,说明最近邻个数越少,所获取的推荐结果越有可能更大地覆盖物品空间。并且MFCC覆盖率的减少速度最慢,而本文算法整体上能够取得最大的覆盖率值。
另外由于时间复杂度是衡量推荐算法性能的另一个重要指标,若样本空间为N,3种算法的时间复杂度分析如下。
(1)本文算法:算法流程中提取音频特征时间复杂度为O(N),采用线性判别分析时间复杂度为O(N3),获取类型基点与波动序列时间复杂度为O(N2),那么整个算法流程时间复杂度为O(N3)。
(2)MFCC:算法流程中语音特征提取时间复杂度为O(N2),基于高斯混合模型生成推荐结果时间复杂度为O(N3),因此整体时间复杂度为O(N3)。
(3)MRGI:算法流程中音乐特征提取时间复杂度为O(N),基于内容的协同过滤时间复杂度为O(N2),基于短期项目热度的推荐结果部分时间复杂度为O(N2),因此整体时间复杂度为O(N2)。
也即说明基于用户的历史喜好音乐记录,在获取历史喜好音乐类型的基础上,结合音乐自身属性与用户对音乐的喜好行为为用户提供音乐推荐服务,能够在可接受的时间开销内,取得更好的推荐准确度与覆盖率,也即能提高推荐质量。
4 总结
随着数字音乐越来越深入人们的生活,音乐推荐系统的应用也越来越广泛,现有音乐推荐系统的基本思想多是通过不同的相似度或相关性度量方法直接为用户生成推荐音乐列表,而不考虑用户历史喜好音乐行为所体现出的用户兴趣的波动性,影响了推荐音乐的准确率。本文基于音乐自身的曲调特征及用户的历史喜好音乐行为,提出了一种融合Fisher线性判别分析与波动序列的音乐偏好获取方法,相比于现有方法,能够根据用户历史喜好音乐行为所体现出的喜好音乐类型间的波动程度,获取更多的用户喜好音乐类型集合,也就有更大的概率覆盖其可能的偏好所在,取得更佳的推荐结果。未来的研究工作将会探讨融合上下文信息来建立用户的喜好音乐模型,以期取得更好的音乐推荐效果。
[1]Su J H,Yeh H H,Yu P S,et al.Music recommendation using content and context information mining[J].IEEE Intelligent Systems,2013,25(1):16-26.
[2]HanB,Rho S,Jun S,et al.Music emotion classification and context-based music recommendation[J].Multimedia Tools andApplication,2012,47(3):433-460.
[3]Pedro C,Markus K,Nicolas W.Content-based music audio recommendation[C]//Proceedings of the 13th Annual ACM International Conference on Multimedia,Singapore,Nov 6-11,2005.New York:ACM,2015:211-212.
[4]Aristomenis L,Lampropoulou P,Tsihrintzis G.Acascadehybrid music recommender system for mobile services based on musical genre classification and personality diagnosis[J].Multimedia Tools and Applications,2013,59(1):241-258.
[5]Kazuyoshi Y,Masataka G,Kazunori K,et al.Hybrid collaborative and content-based music recommendation using proba-bilistic model with latent user preferences[C]//Proceedings of the 7th International Conference on Music Information Retrieval,Victoria,Canada,Oct 8-12,2006:296-301.
[6]Rubin S,Agrawala M.Generating emotionally relevant musical scores for audio stories[J].User Interface Software and Technology,2014,12(4):54-62.
[7]Tzanetakis G,Cook P.Musical genre classification of audio signals[J].IEEE Transactions on Speech and Audio Processing,2014,10(5):293-302.
[8]Gopalan P K,Charlin L,Blei D M,et al.Content-based recommendations with Poisson factorization[J].Neural Information Processing Systems,2014,31(2):128-132.
[9]Gouyou F,Pachet F,Delerue O.Classifying percussive sounds:a matter of zero-crossing rate?[C]//Proceedings of the COST G-6 Conference on Digital Audio Effects,Verona,Italy,Dec 7-9,2000.New York:ACM,2000:56-62.
[10]Li Ruimin,Lin Hongfei,Yan Jun.Mining latent semantic on user-tag-item for personalized music recommendation[J].Journal of Computer Research and Development,2014,51(10):2270-2276.
[11]Chen C M.An intelligent mobile location-aware book recommendation system that enhances problem-based learning in libraries[J].Interactive Learning Environments,2013,21(5):469-495.
[12]Kim S C,Sung K J,Park C S,et al.Improvement of collaborative filtering using rating normalization[J].Multimedia Tools andApplications,2013,6(2):1-12.
[13]Zhu Xia,Song Aibo,Dong Fang,et al.Acollaborative filtering recommendation mechanism for cloud computing[J].Journal of Computer Research and Development,2013,51(10):2255-2269.
[14]Wang Licai,Meng Xiangwu,Zhang Yujie.Acognitive psychology-based approach to user preferences elicitation for mobile network services[J].Acta Electronic Sinica,2011,39(11):2547-2553.
[15]Chen H C,ChenA L P.Amusic recommendation system based on music data grouping and user interests[C]//Proceedings of the 10th International Conference on Information and Knowledge Management,Atlanta,USA,Oct 5-10,2001.New York:ACM,2001:231-238.
附中文参考文献:
[10]李瑞敏,林鸿飞,闫俊.基于用户-标签-项目语义挖掘的个性化音乐推荐[J].计算机研究与发展,2014,51(10):2270-2276.
[13]朱夏,宋爱波,东方,等.云计算环境下基于协同过滤的个性化推荐机制[J].计算机研究与发展,2013,51(10):2255-2269.
[14]王立才,孟祥武,张玉洁.移动网络服务中基于认知心理学的用户偏好提取方法[J].电子学报,2011,39(11):2547-2553.
Music Preference Elicit Method Based on Fisher Linear Discriminant Analysis and Volatility Sequence*
XUE Dongmin+,ZHAO Zhihua
Department of Information Engineering,Shanxi Water Technical Professional College,Yuncheng,Shanxi 044000,China
+Corresponding author:E-mail:xue2015033@sina.com
XUE Dongmin,ZHAO Zhihua.Music preference elicit method based on Fisher linear discriminant analysis and volatility sequence.Journal of Frontiers of Computer Science and Technology,2017,11(8):1314-1323.
The existing music recommendation methods often use similarity or correlation to generate recommended music list,those methods don't consider the volatility of users'interest reflected by the historical music behavior,which influences the recommendation accuracy.To solve this problem,this paper proposes a music recommendation method based on Fisher linear discriminant analysis and volatility sequence.In the beginning,this method obtains the social tags and audio features of music to compute the projection direction which has the minimum within-class scatter and maximum between-class scatter,by using projection transformation and Fisher discriminant criterion.This projection direction is also the best direction of classification.Then it takes music type base point as center,type volatility range as radius to acquire users'preferred music type,and based on which to generate the recommendation list.This paper presents the empirical experiments in a real data set LFM,the results show that the proposed method can achieve better P@R and coverage rate,which means it efficiently improves recommendation accuracy and quality.
:Fisher linear discriminant analysis;volatility sequence;music type base point;social tags;music recommender systems
in was born in 1981.He
the M.S.degree in computer software and theory from Northwest University in 2011.Now he is a lecturer at Shanxi Water Technical Professional College.His research interests include intelligent information acquirement and machine learning,etc. 薛董敏(1981—),男,山西运城人,2011年于西北大学获得硕士学位,现为山西水利职业技术学院讲师,主要研究领域为智能信息获取,机器学习等。

ZHAO Zhihua was born in 1980.He received the M.S.degree in computer software and theory from Northwest University in 2009.Now he is a Ph.D.candidate at Northwest University,and lecturer at Shanxi Water Technical Professional College.His research interests include machine learning,graph and image processing,etc.赵志华(1980—),男,山西运城人,2009年于西北大学获得硕士学位,现为西北大学博士研究生,山西水利职业技术学院讲师,主要研究领域为机器学习,图形图像处理等。
A
:TP391
*The National Natural Science Foundation of China Under Grant No.11241005(国家自然科学基金).Received 2016-04,Accepted 2016-08.
CNKI网络优先出版:2016-08-15,http://www.cnki.net/kcms/detail/11.5602.TP.20160815.1659.020.html
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2017/11(08)-1314-10
10.3778/j.issn.1673-9418.1604064
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
猜你喜欢
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
今日农业(2019年12期)2019-08-13 00:50:14
当代陕西(2019年10期)2019-06-03 10:12:04
文学少年(原创儿童文学)(2019年1期)2019-05-23 09:37:26
中国化肥信息(2019年3期)2019-04-25 01:56:16
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
环境保护与循环经济(2017年2期)2017-09-26 11:52:16
公民与法治(2016年10期)2016-05-17 04:12:58
