
多核共享资源冲突延迟上限优化方法*
2017-08-16 11:10张吉赞苑雅娟
计算机与生活 2017年8期
张吉赞,苑雅娟
1.北京理工大学 计算机科学与技术学院,北京 100081
2.沧州医学高等专科学校,河北 沧州 061001
多核共享资源冲突延迟上限优化方法*
张吉赞1,苑雅娟2+
1.北京理工大学 计算机科学与技术学院,北京 100081
2.沧州医学高等专科学校,河北 沧州 061001
嵌入式多核结构的共享资源冲突是硬实时任务最差情况执行时间(worst-case execution time,WCET)估算的难点,而且通过减少共享资源冲突延迟的估算可以减少硬实时任务的WCET估算值,提高硬实时任务的可调度性。针对带有冲突感知总线(interference-aware bus arbiter,IABA)的嵌入式多核结构,提出了一种基于bank-column缓存划分的访存请求冲突延迟上限优化方法,根据bank冲突次数和冲突延迟上限的关系,该方法通过优化bank到核映射来减少bank冲突发生次数,从而减小冲突延迟上限和WCET估算值。实验结果表明,与现有冲突延迟上限界定方法相比,提出的方法能减少约29%的WCET估算值。
多核结构;硬实时任务;bank冲突;bank-column划分;bank到核映射
1 引言
硬实时嵌入式系统对硬实时任务的执行时间有着严格的要求,每个硬实时任务必须在它的截止期前完成,否则就可能发生灾难性事故[1]。硬实时系统通常依据硬实时任务的最差情况执行时间(worstcase execution time,WCET)对硬实时任务进行调度,以确保硬实时任务能在截止期前完成执行[2]。为保证硬实时任务在任何情况下的执行时间不会超过估算的WCET,分析并估算硬实时任务的WCET是至关重要的。
对于硬实时任务在单核系统中的WCET估算,前人提出了各种不同的WCET估算方法[3],然而,多核结构在硬实时系统中的广泛应用,给硬实时任务的WCET估算带来了新的挑战。这些多核结构往往存在核间可以共享使用的片上共享资源,如片上高速缓存和片上总线等,硬实时任务在同时访问这些共享资源时会发生资源访问冲突,给硬实时任务带来不可预测的额外执行时间,为保证WCET估算是安全的,不得不考虑这些资源访问冲突给硬实时任务的执行时间带来的影响,而现有单核系统的WCET估算方法无法估算这些资源访问冲突带来的冲突延迟[4]。
片上共享缓存(L2缓存)是多核系统的一个重要共享资源,与之相关的任务间共享资源冲突包括:(1)storage冲突,该冲突是指使用相同缓存块的硬实时任务在交替访问该缓存块时,一个任务会将其他任务的内存块从该缓存块中置换出去;(2)bank冲突,该冲突是指当多个任务同时申请访问共享缓存的同一个bank时,只能有一个任务被允许访问该bank,其他任务必须等待。目前,多bank结构已成为共享缓存设计的主要方向,一个多bank结构的共享缓存由多个bank组成[5]。在此基础上,Yoon等人提出了bank-column缓存划分机制[6],共享缓存由多个bank构成,每个bank又被均匀划分成多个column,其中核向bank作映射,硬实时任务向column作映射且独占分配的column以消除storage冲突。
由于硬实时任务在共享缓存上的冲突延迟受到片上总线仲裁机制的影响[7],现有方法通常结合片上总线的仲裁机制对硬实时任务的共享缓存冲突延迟进行分析,如结合时分多路复用(time division multiple access,TDMA)总线分析storage冲突和总线冲突[8]、结合冲突感知总线(interference-aware bus arbiter,IABA)或和谐轮询总线分析bank冲突和总线冲突[6,9]等。在估算bank冲突延迟时,现有方法主要使用访存请求可能遭受的bank冲突上限最大值来估算硬实时任务的bank冲突延迟[6,9],这种粗放的bank冲突延迟估算方法虽然能简化WCET估算且能保证其安全性,但使WCET估算过大,影响了嵌入式多核实时应用的适用范围。
本文重点研究嵌入式多核结构中任务间共享资源冲突,旨在通过优化bank-column缓存划分来减小请求的冲突延迟上限,从而减小WCET估算。其中嵌入式多核结构带有IABA总线和bank-column划分的L2缓存。鉴于现有缓存划分或缓存锁技术能够消除storage冲突[9],本文注重于共享缓存的bank冲突分析,主要贡献如下:(1)基于IABA的bank-column缓存划分,分析了请求的冲突延迟上限,并给出了计算方法。(2)设计了一个基于bank-column缓存划分的冲突延迟上限优化方法,该方法通过优化bank到核映射来减少bank冲突次数,从而减小bank冲突延迟上限。
2 相关工作
对bank冲突、总线冲突和storage冲突的处理,现有研究成果主要集中在如下几方面:
(1)bank冲突组合总线冲突。由于硬实时任务访问bank的时机影响bank冲突的发生,现有研究通过设计总线仲裁策略来分析bank冲突延迟,同时使用共享缓存划分来消除storage冲突。Paolieri等人[9]组合IABA总线仲裁器和共享L2缓存动态划分来界定bank冲突延迟上限,该方法使用的L2缓存动态划分包括bankization划分或columnization划分。其中,columnization划分可以消除storage冲突,但存在bank访问冲突;而bankization划分可以同时消除storage冲突和bank访问冲突,但要求任务独占分配的bank,不能充分利用L2缓存,受bank数目的影响,限制了多核系统的工作负荷。Yoon等人[6]组合和谐轮询总线仲裁策略和L2缓存的bank-column划分来界定bank冲突上限。在该方法中,和谐轮询总线仲裁策略将总线时槽固定地分配给不同的核,为了能够界定bank冲突延迟上限需要优化总线时槽在核间的分配,该总线仲裁策略在实质上是一种TDMA总线仲裁策略。张吉赞等人[10]组合TDMA总线和L2缓存的bank-column划分来分析bank冲突,并使用请求时间序列来估算bank冲突延迟。这种方法需要获得每个硬实时任务的请求时间序列,以用来估算每个请求遭受的bank冲突延迟。
(2)总线冲突组合storage冲突。另有一些研究成果将storage冲突分析和总线访问冲突分析结合起来进行WCET分析,但在分析时没有考虑bank访问冲突问题。Kelter等人[11]通过界定TDMA偏移量上界来分析总线冲突延迟,并使用扩展的缓存抽象解释(abstract translation)方法分析了storage冲突。Chattopadhyay等人[8]提出融合共享缓存和TDMA总线的WCET分析框架,在分析总线访问延迟时,根据执行上下文,令请求的总线访问延迟为可能遭受的最大总线访问延迟。Nagar等人[12]提出了WCIP(worst case interference placement)方法来分析storage冲突,并组合TDMA总线仲裁策略来估算多核系统的WCET。
(3)storage冲突。还有一些研究成果将分析重点仅放在storage冲突上,均没有考虑bank冲突延迟和总线访问延迟对WCET的影响。Chen等人[13]通过指令的取指时间关系,分析了进程在共享缓存上的storage冲突。Ding等人[14]提出动态锁指令缓存的方法来消除storage冲突,该方法可灵活锁定循环结构对应的缓存空间。康少华等人[15]使用缓存划分技术来减少storage冲突,从而改善并行程序的WCRT。安立奎等人[16]使用软件预取技术来减少storage冲突和WCET估算值。
本文着重研究bank冲突问题,与上述方法的不同之处在于:(1)组合IABA总线仲裁策略和bankcolumn缓存划分对bank冲突延迟上限进行分析;(2)通过优化bank到核的映射关系减小bank冲突延迟上限。
3 系统模型及亟需解决的关键问题
3.1 嵌入式多核结构
一个嵌入式多核处理器含有Ncore个支持多发射有序流水线的同构核,表示为C={c1,c2,…,cNcore}。每个核有自己私有的第一级数据缓存和指令缓存。由所有核共享使用的第二级缓存(L2缓存)采用bankcolumn缓存划分机制[6],该缓存划分机制先将L2缓存划分成Nbank个大小相等的bank,表示为B={b1,b2,…,bNbank},然后将每个bank进一步划分成相等的Ncolumn个column。L2缓存完成一次请求需要的时间为LM个时钟周期。连接L2缓存和核的实时总线是全双工IABA总线[9],总线完成一次请求所需要的时间为LB个时钟周期。请求访问L2缓存发生缺失时,需要访问主存。
IABA总线仲裁器由两层组件构成:(1)一个核间总线仲裁器XCBA(inter-core bus arbiter),对核间请求进行仲裁调度。XCBA在进行仲裁时,能判断是否有总线冲突或bank冲突发生,若有冲突,则延迟后续请求访问总线,以避免发生总线冲突和bank冲突。(2)每个核有一个核内部总线仲裁器ICBA(intracore bus arbiter),对来自同核的请求进行仲裁调度。若有多个请求同时申请访问L2缓存,ICBA选择一个请求转发给XCBA,其他请求在ICBA中等待。
3.2 多任务应用模型
一个多任务实时应用由硬实时任务和非硬实时任务组成,用Γhrt表示硬实时任务集合。所有任务已通过非抢占式调度分配到Ncore核上,用Chrt(⊆C)表示分配有硬实时任务的核集,Nhrt(≤Ncore)是Chrt中的核数,只有一个核只分配有非硬实时任务,表示为cnhrt(∈C)。在最差情况下,Chrt中的所有核都在执行硬实时任务,即最多有Nhrt个硬实时任务同时运行。
完成任务向核的分配后,需要确定核需要的L2缓存的大小。首先,为带有硬实时任务的核分配L2缓存,设HTi是分配到核ci的硬实时任务集合,任务τj(∈HTi)需要的L2缓存的大小为 Sj个column,则核ci需要的L2缓存的大小为Sz(ci)=max(Sj|1≤j≤ni)个column,其中ni为集合HTi中的任务数,分配给ci的L2缓存由HTi中的任务独占使用;其次,为只带有非硬实时任务的核分配缓存,若cnhrt≠∅,则将剩余的column分配给该核,供该核的非硬实时任务独占使用。这种分配方式具有如下特点:(1)任务独占分配的column,不存在storage冲突;(2)一个bank可由多个核共享使用,当多个请求同时申请访问同一个bank时,发生bank冲突;(3)Nbank×Ncolumn个column在Ncore个核间的不同分配对应着不同的bank到核映射。
另外,采用Li等人[17]提到的方法处理任务间的共享代码和任务间的通信。如果多个任务共享使用某个函数或程序段,则为每个任务复制一份以取消任务间代码共享。若任务间需要通信则采用邮箱机制来取消由同步带来的影响。
3.3 亟需解决的关键问题
Paolieri等人[9]提出了用请求可能遭受的冲突延迟最大值UBD来估算冲突延迟的方法。在该方法中,多核结构带有IABA和动态缓存划分机制。L2缓存的动态划分技术采用columnization划分或bankization划分,其中columnization划分将片上L2缓存划分成多路(way),每个硬实时任务独占分配的路,不存在storage冲突,但硬实时任务共享一个bank,存在bank访问冲突,若只有硬实时任务,UBD=(Nhrt-1)×LM,否则,UBD=(Nhrt-1)×LM-1;ba-nkization划分将片上L2缓存划分成多bank,每个硬实时任务独占分配的bank,不存在storage冲突和bank访问冲突,若只有硬实时任务,UBD=(Nhrt-1)×LB,否则,UBD=(Nhrt-1)×LB-1。受L2缓存容量的限制,若bankization划分不能满足硬实时任务的需求,则采用columization划分。
虽然bankization划分能使UBD最小,但要求硬实时任务独占分配的bank,不能有效使用共享缓存。而在bank-column划分中,L2缓存能在核间被灵活地分配,当bankization划分不能满足硬实时任务的需求时,使用bank-column划分,并适当调整bank到核映射,能够减小UBD。如在图1所示的例子中,图1(a)是columnization划分,在一次XCBA调度中,HRT4(c4)的请求遭受的冲突延迟最大,12个时钟周期,UBD=12个时钟周期;图1(b)是bank-column划分的一个bank到核映射,在一次XCBA调度中,HRT4(c4)的请求遭受的冲突延迟最大,8个时钟周期,UBD=8个时钟周期。

Fig.1 Example of interference delay on XCBA图1 请求在XCBA上的冲突延迟举例
综上所述,缓存的bank-column划分能够减小UBD的值,在不同的bank到核映射中,UBD的值也不尽相同。为此,本文拟通过优化bank到核映射来减小UBD的值,从而减小WCET的估算值。
4 利用bank到核映射优化UBD
4.1UBD分析
在最差情况下,Chrt中的Nhrt个核都在执行硬实时任务,设同时运行的Nhrt个硬实时任务为{HRT1,HRT2,…,HRT(Nhrt)},对应的核为 {c1′,c2′,…,c(Nhrt)′},当 Nhrt个硬实时任务同时请求总线时,来自HRTi(1≤i≤Nhrt)的请求是第i个被XCBA选中访问总线。为了方便描述,用c0′表示只带有非硬实时任务的核cnhrt。在XCBA的一次调度中,Nhrt个硬实时任务都有请求申请总线,来自HRT1,HRT2,…,HRT(Nhrt)的请求分别用q1,q2,…,q(Nhrt)表示,qi(1≤i≤Nhrt)可能遭受的最大任务间冲突延迟分别用di表示。若c0′≠∅,用q0表示来自c0′的请求。分两种情形分析UBD。
(1)c0′=∅。q1不遭受任务间冲突,d1=0。请求qi(1≤i≤Nhrt)可能遭受的最大任务间冲突延迟可表示为式(1):
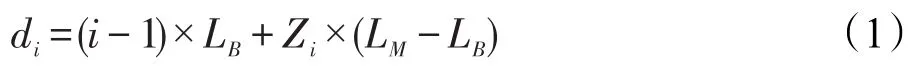
其中,Zi表示前i个请求之间发生bank冲突的次数。
例如,在图2所示的例子中,Z3=1,来自HRT3的请求遭受的最大任务间冲突延迟为2×LB+1×(LM-LB)=6个时钟周期。请求q(Nhrt)可能遭受的任务间冲突延迟最大,为(Nhrt-1)×LB+Z(Nhrt)×(LM-LB)。由此,在无非硬实时任务时,UBD可表示为式(2):
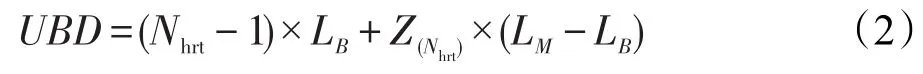
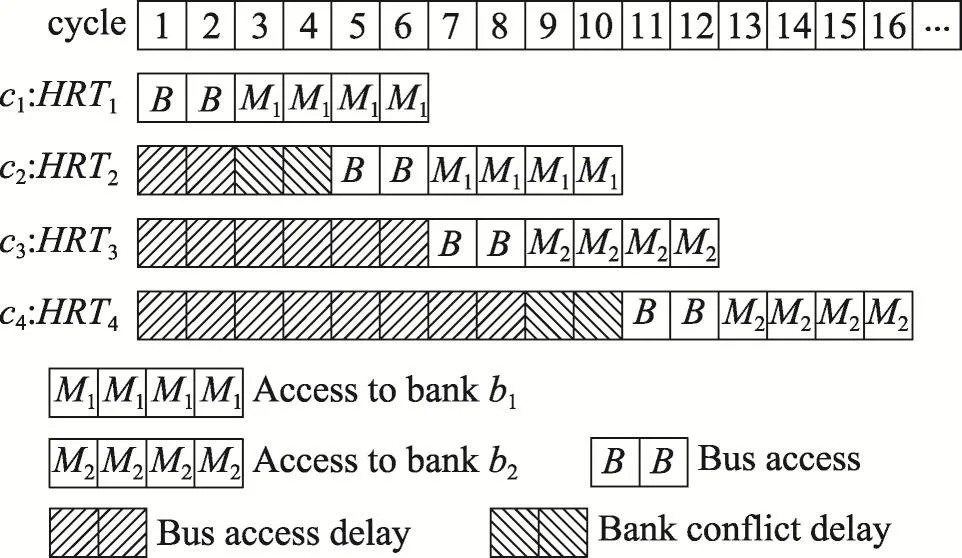
Fig.2 Example of inter-task interference delay without non hard real-time tasks图2 无非硬实时任务时请求遭受的任务间冲突延迟举例
(2)c0′≠∅。q1可能遭受的最大任务间冲突延迟为(LB-1)+Z1×(LM-LB)。请求qi(1≤i≤Nhrt)可能遭受的最大任务间冲突延迟di为(LB-1)+(i-1)×LB+Zi×(LM-LB),可表示为式(3):
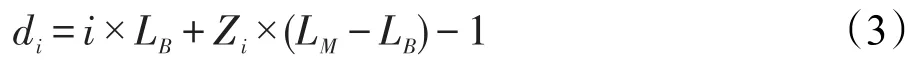
例如,在图3所示的例子中,Z2=1,来自HRT2的请求可能遭受的最大任务间冲突延迟为2×LB+1×(LM-LB)-1=5个时钟周期。请求q(Nhrt)可能遭受的任务间冲突延迟最大,为 Nhrt×LB+Z(Nhrt)×(LM-LB)-1。由此,存在非硬实时任务时,UBD可表示为式(4):
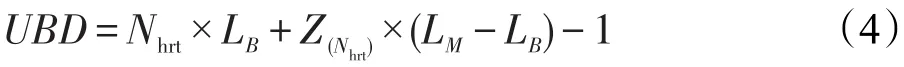
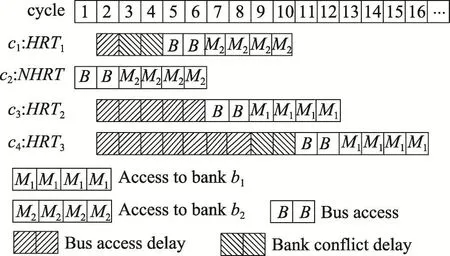
Fig.3 Example of inter-task interference delay with non hard real-time tasks图3 存在非硬实时任务时请求遭受的任务间冲突延迟举例
4.2 优化问题描述
从式(2)和式(4)可知,减少请求发生bank冲突的次数能减小UBD的值,从而减小WCET的估算值。用xik表示bk(∈B)是否有column分配给ci(∈C),若有,则xik=1;否则,xik=0。用ncik表示bk分配给ci(∈C)的column数目,如果xik=1,则 ncik>0;否则,ncik=0。由于任务独占分配给它的column,ncik是整数。以xik和ncik为决策变量,优化bank到核的映射关系使请求的冲突延迟上界最小的形式化描述如下。
(1)优化目标
根据式(2)和式(4),优化目标可表示为min(Z(Nhrt))。
(2)约束条件
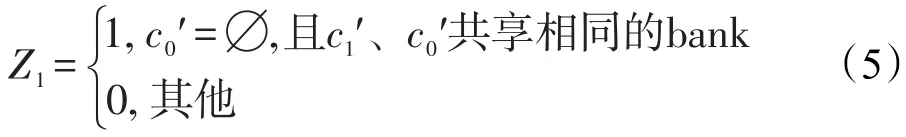
当1≤i≤Nhrt,前i个请求之间发生bank冲突的次数Zi可表示为式(6):
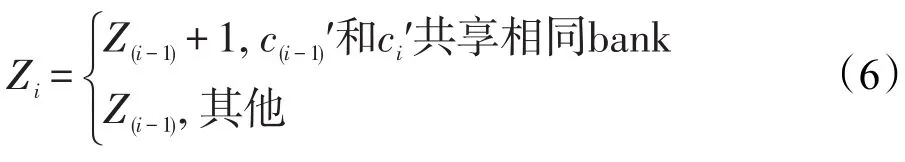
L2缓存容量应满足硬实时任务的需求,即:

若c0′≠∅,则将剩余的column分配给c0′,如式(8)所示:

分配给每个硬实时任务核的column数应满足该核的需要,即:
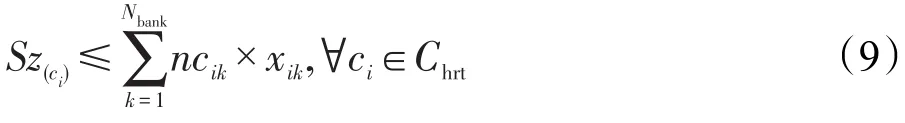
在分配L2缓存时,应满足每个bank的容量限制,即:
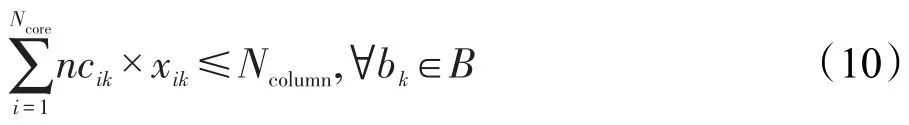
4.3 求解算法
前面描述的优化问题是一个资源分配问题,是NP难的。该问题的求解过程如下:
(1)为 Ncore个核分配L2缓存。Nbank×Ncolumn个column在Ncore个核间进行分配,可以形成多个bank到核映射。
(2)对于每个bank到核映射,根据式(5)和式(6)计算Z(Nhrt)。
(3)输出最小 Z(Nhrt)。
该优化问题的一个递归回溯算法如算法1所示。在该算法中,第2~18行定义函数FindMinMapping(n),第4行根据核次序Cseq[Ncore]作bank到核的映射,第5行计算bank冲突次数,第6~9行更新结果,第12~17行回溯搜索解空间。
算法1寻找一个bank到核的映射关系使Z(Nhrt)最小
输入:C,Ncore,Chrt,Nhrt,cnhrt,B,Nbank,Ncolumn,Sz(ci),∀ci∈C
输出:最小的Z(Nhrt)及对应的bank到核的映射MinMap[][]
1.Z(Nhrt)=infinity,used[i]=FALSE;
2.FunctionFindMinMapping(n)
3.If(n>Ncore)then
4.根据Cseq[]作bank到核的映射BtoCMap[][];
5.根据式(5)和式(6),计算在映射 BtoCMap[][]中的bank冲突次数(TempZ);
6.If(TempZ<Z(Nhrt))then
7.Z(Nhrt)=TempZ;
8.MinMap[][]=BtoCMap[][];
9.End if
10.Return
11.End if
12.For(i=1;i≤Ncore;i++)do
13.If(!used[i])then
14.Cseq[n]=ci;used[i]=TRUE;
15.FindMinMapping(n+1);used[i]=FALSE;
16.End if
17.End for
18.End function
19.调用FindMinMapping(1);
20.ReturnZ(Nhrt),MinMap[][];
算法1的第4行按照Ncore个核的某个次序作bank到核映射,根据核需要的L2缓存容量,分如下3种情形作bank到核的映射。
算法2给出了按照Ncore个核的某个次序作bank到核映射的算法。在该算法中,某个核序列存放在Cseq[]中,根据核序列Cseq[]作bank到核映射关系BtoCMap[Ncore][Nbank]。第2~11行处理第(1)种情形,作bank到核映射;第14~21行调整参与分配的column数;若是第(3)种情形,第17~20行调整每个bank参与分配的column数;若是第(2)种情形或第(3)种情形,第26~41行作bank到核映射。
算法2按照Ncore个核的一个次序作bank到核映射
输入:C,Sz(ci)(ci∈C),Chrt,cnhrt,Ncore,B,Nbank,Ncolumn,Cseq[Ncore]
输出:一个bank到核映射(BtoCMap[Ncore][Nbank])
//处理第(1)种情形
2.k=1;
3.For(i=1;i≤Ncore;i++)do
4.If(ci∈Chrt)then
7.End if
8.End for
9.If(k<Nbankandcnhrt≠∅)then
10.将b(k+1)~b(Nbank)分配给cnhrt;
11.End if
12.Else
14.For(i=1;i≤Nbank;i++)do
15.If(k==0)then
16.bank[i]=Ncolumn;
17.Else
//调整每个bank中参与分配的column数
20.End if
21.End for
22.nbank=1,ncol=bank[1];
23.While(i≤Ncore)do
//依照核的次序为各核分配缓存
24.将核Cseq[i]在核集C中对应的序号存放在j中,需要的column数存放在nc_col;
25.If(nc_col≥ncol)then
26.While(nc_col≥ncol)do
27.BtoCMap[j][nbank]=ncol;
28.nc_col=nc_col-ncol;nbank++;
29.ncol=bank[nbank];
30.End while
31.If(nc_col==0)then
32.i++;
33.Else
34.BtoCMap[j][nbank]=nc_col;
35.ncol=ncol-nc_col;i++;
36.End if
37.Else
38.BtoCMap[j][nbank]=nc_col;
39.ncol=ncol-nc_col;i++;
40.End if
41.End while
42.End if
43.ReturnBtoCMap[][];
上述算法需要计算在每个bank到核映射中bank冲突可能发生的最大次数,复杂性为O(Ncore!)。
5 WCET估算
根据优化后的结果,利用式(2)和式(4)可以计算出UBD的值。在支持IABA总线的多核系统中,一次L2缓存访问所需要的时间应该包括:在ICBA中的等待时间、在XCBA上遭受的冲突延迟(UBD)和访问L2缓存的时间(LM)。
请求在ICBA中的等待时间是从该请求申请总线开始到该请求被送至XCBA为止的时间间隔。由于与前一个请求(来自同一个核)之间存在时间重叠,则需要进行去重处理,此时,请求在ICBA中的等待时间是从前一个请求(来自同一个核)完成L2缓存访问开始到该请求被送至XCBA为止的时间间隔。例如,图4显示了没有非硬实时任务时请求在ICBA中的等待时间,请求在ICBA中的最大等待时间也是UBD。
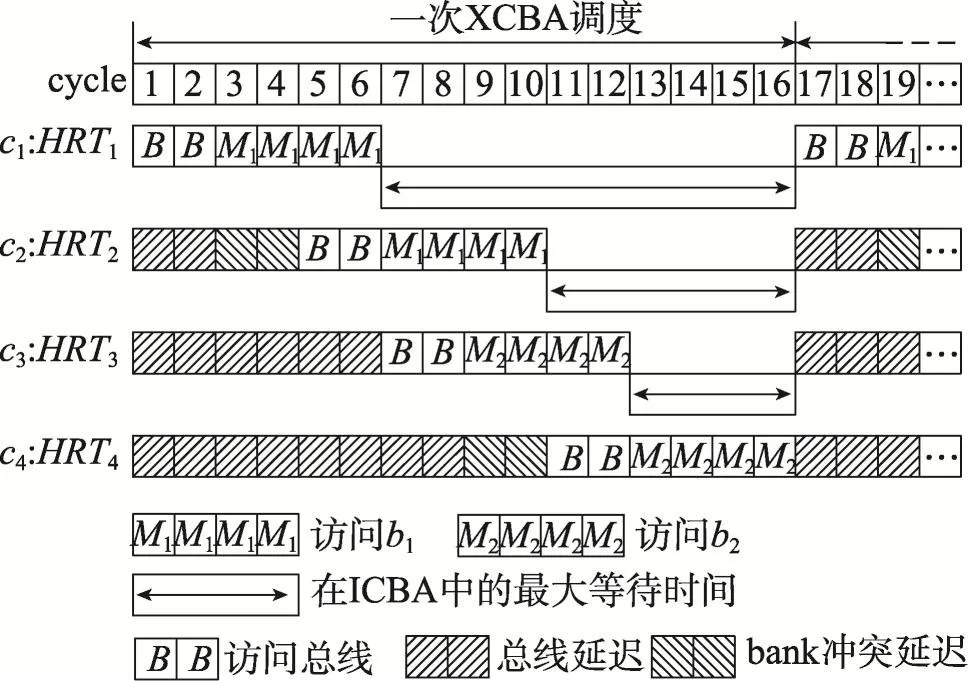
Fig.4 Example of maximum waiting time in ICBA图4 请求在ICBA中的最大等待时间举例
由此,在使用UBD估算WCET时,每个访问L2缓存的请求遭受的冲突延迟上限为2UBD。一次L2缓存访问的时间可以估算为2LB+2UBD+LM,其中2LB为请求和取回的数据通过总线的时间。在某个bank到核映射中,2LB+2UBD+LM是常数,因此可以直接用单核WCET估算工具(如Chronos[18])估算硬实时任务的WCET。
6 实验验证
6.1 实验环境和测试程序
由8个同构核{c1,c2,…,c8}组成的多核系统中,每核有一个有序5级流水线,无分支预测功能,取指队列大小为4,取指宽度为2,指令窗大小为8。每核有私自L1数据和L1指令缓存,大小均为64 Byte,1个bank,2路关联,每line有8 Byte,1个时钟周期的访问时间,采用LRU替换策略。L2缓存为所有核共享,大小为4 KB,被均匀划分成4个bank,每bank大小为1 KB,4路关联,每line有32 Byte,4个时钟周期访问时间(即LM=4),采用LRU替换策略。每个bank又被均匀划分成8个column。每个column的大小为128 Byte(即1组4路关联的line)。连接L2缓存和核的总线为IABA实时总线,一次请求通过总线需要2个时钟周期,即LB=2。主存为256 MB×16 DDR2-800C,并分为4个bank。请求访问L2缓存发生缺失时,需访问主存,使用Paolieri等人[19]的方法估算请求访问主存的时间。
使用的所有测试程序是Mälardalen WCET benchmark测试程序集[20]的一部分,使用Chronos测量了这些测试程序在单核系统中分配给不同L2缓存大小时的WCET,根据测量结果给测试程序分配合适的L2缓存大小,如表1所示,在该表中也列出了实验中采用的任务到核的映射关系。

Table1 Allocated L2 cache size and task to core mapping表1 分配的L2缓存大小以及任务到核映射
6.2 实验结果
在表1中的任务都为硬实时任务或存在非硬实时任务(matmult为非硬实时任务)时,使用算法1得到的一个最优bank到核映射如表2所示,在该映射关系中,Zi=0(1≤i≤7)。
(1)当表1中的任务都为硬实时任务时,在表2所示的bank到核映射中,Zi=0(1≤i≤7),由式(2)可知,UBD=(7-1)×2=12个时钟周期;若使用Paolieri等人[9]的方法,只能采用columnization划分,UBD=(7-1)×4=24个时钟周期;使用本文提出的bank到核映射优化方法和Paolieri等人的方法分别估算了访存请求延迟上限,并使用Chronos估算了任务的WCET,其结果如图5所示。在该图中,所有结果都是相对于任务不遭受共享资源冲突时的WCET(用Chronos获得)。其中,“Opt_UBD”表示用优化bank到核映射估算的结果,“Base_UBD”表示用Paolieri等人的方法估算的结果。相对于Paolieri等人的方法,本文提出的bank到核映射优化方法平均减少了约29%的WCET估算值,其中对bsort100的WCET估算值改善程度最大,减少了约38%,而对select的WCET估算值改善程度最小,减少了约19%。
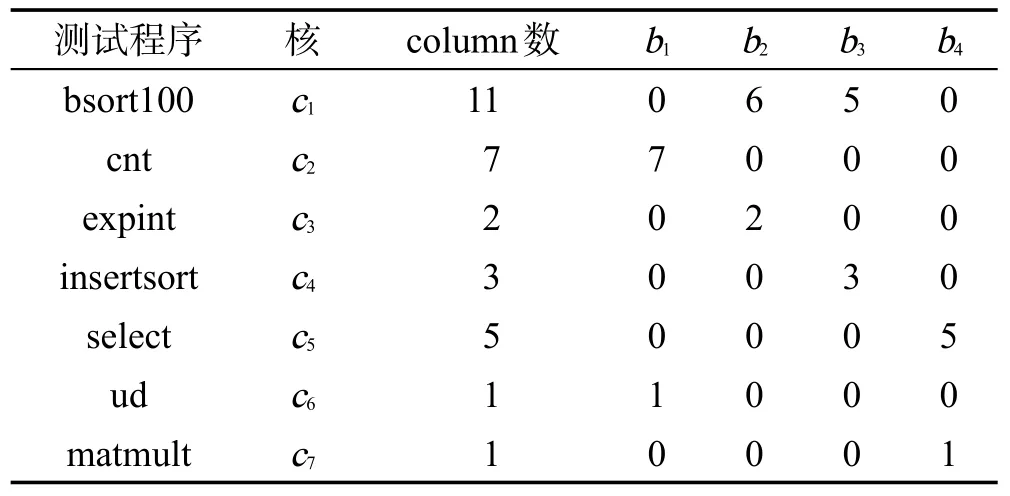
Table2 An optimal relation of bank to core mapping表2 一个最优bank到核映射关系
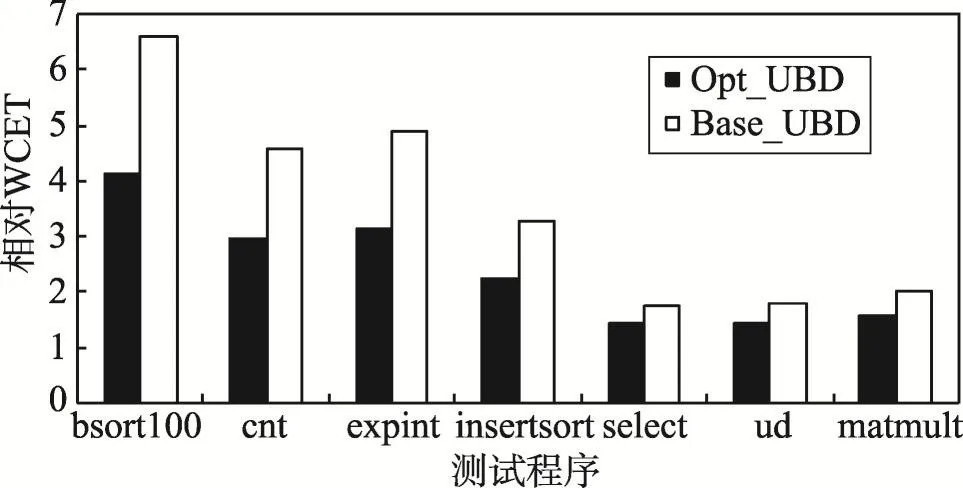
Fig.5 Estimation results without non hard real-time tasks图5 不存在非硬实时任务时的估算结果
(2)matmult为非硬实时任务,其他为硬实时任务,在表2所示的bank到核映射中,由式(4)可知,UBD=6×2-1=11个时钟周期;若使用Paolieri等人的方法,也只能采用columnization划分,UBD=6×4-1=23个时钟周期。分别使用两种方法估算的WCET如图6所示。相对于用Paolieri等人的方法,本文提出的bank到核映射优化方法平均减少了约30%的WCET估算值,其中对bsort100的WCET估算值改善程度最大,减少了约39%,而对select的WCET估算值改善程度最小,减少了约20%。
主要原因:首先,在bank-column缓存划分中,L2缓存能够在核间被灵活地分配,一个bank可以被不同的核共享使用,减小了发生bank冲突的机会,从而减小了UBD的值,通过优化bank到核映射可以得到具有最小bank冲突次数的bank到核映射关系;其次,硬实时任务WCET估算值的减小程度与该任务访问L2缓存的次数和程序规模有关,访问次数越多,减小程度越大,而程序规模越小,减小程度越大。
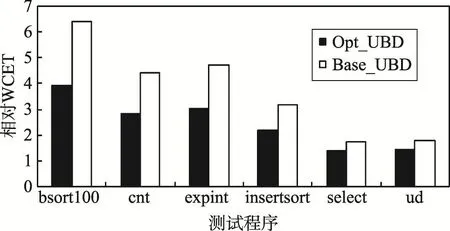
Fig.6 Estimation results with non hard real-time tasks图6 存在非硬实时任务时的估算结果
7 结束语
本文提出了一种基于bank-column缓存划分的冲突延迟上限优化方法,该方法通过优化bank到核映射来减小请求的冲突延迟上限。
对于带有IABA总线和bank-column缓存划分机制的多核系统,分析了访存请求的冲突延迟上限;在此基础上,根据bank冲突次数与冲突延迟上限的关系,利用bank到核映射优化冲突延迟上限。
实验结果表明,与现有冲突延迟上限界定方法相比,提出的bank到核映射优化方法能减小约29%的WCET估算值。
[1]Thiele L,WilhelmR.Design for timing predictability[J].Real-Time Systems,2004,28(2/3):157-177.
[2]DavisR I,BurnsA.Asurvey of hard real-time scheduling for multiprocessor systems[J].ACM Computing Surveys,2011,43(4):1-44.
[3]WilhelmR,Mitra T,Mueller F,et al.The worst-case execution-time problem-overview of methods and survey of tools[J].ACM Transactions on Embedded Computing Systems,2008,7(3):36.
[4]Guan Nan,Stigge M,Wang Yi,et al.Cache-aware schedulingand analysis for multicores[C]//Proceedings of the 9th ACM&IEEE International Conference on Embedded Software,Grenoble,France,Oct 12-16,2009.New York:ACM,2009:245-254.
[5]Kaseridis D,Stuecheli J,John L K.Bank-aware dynamic cache partitioning for multicore architectures[C]//Proceedings of the 2009 International Conference on Parallel Processing,Vienna,Austria,Sep 22-25,2009.Washington:IEEE Computer Society,2009:18-25.
[6]Yoon M K,Kim J E,Sha L.Optimizing tunable WCET with shared resource allocation and arbitration in hard real-time multicore systems[C]//Proceedings of the 32nd Real-Time Systems Symposium,Vienna,Austria,Nov 29-Dec 2,2011.Washington:IEEE Computer Society,2011:227-238.
[7]Axer P,ErnstR,Falk H,et al.Building timing predictable embedded systems[J].ACM Transactions on Embedded Computing Systems,2014,13(4):82.
[8]Chattopadhyay S,Chong L K,RoychoudhuryA,et al.Aunified WCET analysis framework for multi-core platforms[C]//Proceedings of the 18th Real Time and Embedded Technology and Applications Symposium,Beijing,Apr 16-19,2012.Washington:IEEE Computer Society,2012:99-108.
[9]Paolieri M,Quiñones E,Cazorla F J,et al.Hardware support for WCET analysis of hard real-time multicore systems[C]//Proceedings of the 36th International Symposium on Computer Architecture,Austin,USA,Jun 20-24,2009.New York:ACM,2009:57-68.
[10]Zhang Jizan,Gu Zhimin.Analyzing bank access conflict and minimizing bank conflict delay for shared cache in multicore[J].Chinese Journal of Computers,2016,39(9):1883-1899.
[11]Kelter T,Falk H,Marwedel P,et al.Bus-aware multicore WCET analysis through TDMA offset bounds[C]//Proceedings of the 23rd Euromicro Conference on Real-Time Systems,Porto,Portugal,Jul 5-8,2011.Washington:IEEE Computer Society,2011:3-12.
[12]Nagar K,Srikant Y N.Fast and precise worst-case interference placement for shared cache analysis[J].ACM Transactions on Embedded Computing Systems,2016,15(3):45.
[13]Chen Fangyuan,Zhang Dongsong,Wang Zhiying.Static analysis of run-time inter-thread interferences in shared cache multi-core architectures based on instruction fetching timing[C]//Proceedings of the 2011 IEEE International Conference on Computer Science and Automation Engineering,Shanghai,Jun 11-12,2011.Piscataway,USA:IEEE,2011:208-212.
[14]Ding Huping,Liang Yun,Mitra T.WCET-centric dynamic instruction cache locking[C]//Proceedings of the 2014 Conference on Design,Automation&Test in Europe,Dresden,Germany,Mar 24-28,2014.Piscataway,USA:IEEE,2014:1-6.
[15]Kang Shaohua,Gu Zhimin,Fu Yinxia,et al.Parallelization and WCRT analysis of space debris detector-DEBIE[J].Application Research of Computers,2015,32(11):3283-3290.
[16]An Likui,Gu Zhimin,Fu Yinxia,et al.WCET analysis of unified cache with software prefetching[J].Transactions of Beijing Institute of Technology,2015,35(7):730-736.
[17]Li Yan,Suhendra V,Liang Yun,et al.Timing analysis of concurrent programs running on shared cache multi-cores[C]//Proceedings of the 30th Real-Time Systems Symposium,Washington,Dec 1-4,2009.Washington:IEEE Computer Society,2009:57-67.
[18]Li Xianfeng,Liang Yun,Mitra T,et al.Chronos:a timing analyzer for embedded software[J].Science of Computer Programming,2007,69(13):56-67.
[19]Paolieri M,Mische J,Metzlaff S,et al.Ahard real-time capable multi-core SMT processor[J].ACM Transactions on Embedded Computing Systems,2013,12(3):1-25.
[20]Gustafsson J,BettsA,ErmedahlA,et al.The Mälardalen WCET benchmarks:past,present and future[C]//Proceedings of the 10th International Workshop on Worst-Case Execution Time Analysis,Brussels,Belgium,Jul 7-9,2010.Vienna,Austria:Austrian Computer Society,2010:136-146.
附中文参考文献:
[10]张吉赞,古志民.多核共享缓存的bank冲突分析及其延迟最小化[J].计算机学报,2016,39(9):1883-1899.
[15]康少华,古志民,付引霞,等.空间碎片探测软件的并行化及WCRT分析[J].计算机应用研究,2015,32(11):3283-3290.
[16]安立奎,古志民,付引霞,等.支持软件预取的缓存WCET分析[J].北京理工大学学报,2015,35(7):730-736.

ZHANG Jizan was born in 1973.He is a Ph.D.candidate at School of Computer Science and Technology,Beijing Institute of Technology.His research interests include computer architecture and computer network,etc.张吉赞(1973—),男,山东青岛人,北京理工大学计算机科学与技术学院博士研究生,主要研究领域为计算机体系结构,计算机网络等。
《计算机工程与应用》投稿须知
中国科学引文数据库(CSCD)来源期刊、北大中文核心期刊、中国科技核心期刊、RCCSE中国核心学术期刊、《中国学术期刊文摘》首批收录源期刊、《中国学术期刊综合评价数据库》来源期刊,被收录在《中国期刊网》、《中国学术期刊(光盘版)》、英国《科学文摘》(SA/INSPEC)、俄罗斯《文摘杂志》(AJ)、美国《剑桥科学文摘》(CSA)、美国《乌利希期刊指南》(Ulrich’s PD)、《日本科学技术振兴机构中国文献数据库》(JST)、波兰《哥白尼索引》(IC),中国计算机学会会刊
《计算机工程与应用》是由中华人民共和国中国电子科技集团公司主管,华北计算技术研究所主办的面向计算机全行业的综合性学术刊物。
办刊方针坚持走学术与实践相结合的道路,注重理论的先进性和实用技术的广泛性,在促进学术交流的同时,推进科技成果的转化。覆盖面宽、信息量大、报道及时是本刊的服务宗旨。
报导范围行业最新研究成果与学术领域最新发展动态;具有先进性和推广价值的工程方案;有独立和创新见解的学术报告;先进、广泛、实用的开发成果。
主要栏目理论与研发,大数据与云计算,网络、通信与安全,模式识别与人工智能,图形图像处理,工程与应用,以及其他热门专栏。
注意事项为保护知识产权和国家机密,在校学生投稿必须事先征得导师的同意,所有稿件应保证不涉及侵犯他人知识产权和泄密问题,否则由此引起的一切后果应由作者本人负责。
论文要求学术研究:报道最新研究成果,以及国家重点攻关项目和基础理论研究报告。要求观点新颖,创新明确,论据充实。技术报告:有独立和创新学术见解的学术报告或先进实用的开发成果,要求有方法、观点、比较和实验分析。工程应用:方案采用的技术应具有先进性和推广价值,对科研成果转化为生产力有较大的推动作用。
投稿格式1.采用学术论文标准格式书写,要求文笔简练、流畅,文章结构严谨完整、层次清晰(包括标题、作者、单位(含电子信箱)、摘要、关键词、基金资助情况、所有作者简介、中图分类号、正文、参考文献等,其中前6项应有中、英文)。中文标题必须限制在20字内(可采用副标题形式)。正文中的图、表必须附有图题、表题,公式要求用MathType编排。论文字数根据论文内容需要,不做严格限制,对于一般论文建议7 500字以上为宜。2.请通过网站(http://www.ceaj.org)“作者投稿系统”一栏投稿(首次投稿须注册)。
Optimization of Upper Bound of Interference Delay in Multicore*
ZHANG Jizan1,YUAN Yajuan2+
1.School of Computer Science and Technology,Beijing Institute of Technology,Beijing 100081,China
2.Cangzhou Medical College,Cangzhou,Hebei 061001,China
+Corresponding author:E-mail:hbdlyyj@163.com
ZHANG Jizan,YUAN Yajuan.Optimization of upper bound of interference delay in multicore.Journal of Frontiers of Computer Science and Technology,2017,11(8):1224-1234.
The inter-task interferences on the shared resources of embedded multicore are the difficulty for the WCET(worst-case execution time)estimation of hard real-time tasks.Moreover,the decrease of the delay caused by the interferences on the shared resources can reduce the estimated WCET and improve the schedulability of hard real-time tasks.This paper proposes an optimization method to reduce the upper bound of inter-task interference delay in the multicore with interference-aware bus arbiter(IABA).According to the relationship between the upper bound of inter-task interference delay and the count of bank conflict,this paper optimizes bank to core mapping to reduce the count of bank conflict,and then reduces the upper bound of inter-task interference delay and the estimated WCET.Compared with existing methods,the proposed method can reduce about 29%of the estimated WCET.
multicore;hard real-time task;bank conflict;bank-column partitioning;bank to core mapping
an was born in 1979.She
the M.S.degree in computer science from North China Electric Power University in 2007.Her research interests include embedded system and computer architecture,etc. 苑雅娟(1979—),女,河北保定人,2007年于华北电力大学获得硕士学位,主要研究领域为嵌入式系统,计算机结构等。
A
:TP302.7
*The National Natural Science Foundation of China under Grant No.61370062(国家自然科学基金).Received 2017-01,Accepted 2017-05.
CNKI网络优先出版:2017-05-17,http://kns.cnki.net/kcms/detail/11.5602.TP.20170517.0944.002.html
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2017/11(08)-1224-11
10.3778/j.issn.1673-9418.1701043
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
猜你喜欢
数学小灵通·3-4年级(2021年9期)2021-10-12
小学生学习指导(低年级)(2020年10期)2020-11-09
兵团工运(2019年6期)2019-12-13
电子制作(2018年19期)2018-11-14
电子制作(2018年11期)2018-08-04
数学大王·中高年级(2017年2期)2017-02-08
学苑创造·A版(2016年4期)2016-04-16
空间控制技术与应用(2015年2期)2015-06-05
仲裁研究(2015年4期)2015-04-17
舰船科学技术(2015年8期)2015-02-27
