
改进的智能家居语音关键词识别算法
2017-07-19 11:02张帅林
电子科技 2017年7期
张帅林
(兰州交通大学 电信学院,甘肃 兰州 730070)
改进的智能家居语音关键词识别算法
张帅林
(兰州交通大学 电信学院,甘肃 兰州 730070)
针对智能家居普遍采用的孤立词识别算法所带来语音识别体验效果不理想, 文中提出一种基于动态规整算法的语音关键词识别算法。在端点检测阶段将智能家居语音输入拆分为多个单音节,提取这些单音节以及单音节对应的关键词的特征参数并建立特征参数模板库;在识别阶段对用户输入的语音进行音节端点检测,将拆分的单个音节与模板库匹配,对连续匹配成功的多个音节组成“可能关键词”,并再将“可能关键词”与模板库匹配,若匹配成功则判定为“关键词”。对大量用户的输入语音进行测试,实验测试结果表明,关键词检出率可达82%,由于采用提取用户输入语音的关键词来识别用户指令而非用户严格按照孤立词发,大幅提升了用户体验。
智能家居;语音识别;动态规整;关键词识别;孤立词识别
智能家居主要用改善用户家居环境,提升生活质量。而智能家居语音识别系统是摆脱繁杂的手动遥控问题的关键[1]。
目前,智能家居语音控制系统多采用孤立词识别算法,普遍采用基于动态规整孤立词识别算法[1]和隐马尔科夫模型孤立词识别算法[2]的方法。在识别速率和识别率方面已经基本满足了系统要求。但在用户体验上,基本无法达到用户体验要求,存在的问题是用户在使用孤立词语音识别系统时候必须事先培训,熟记基本的语音命令,一旦含有命令词外的语音[3],则无法识别。例如语音命令词“打开客厅空调”,而如果用户发音诸如“请打开客厅空调”、“请给我打开客厅的空调”、“请打开空调吧”、“打开空调客厅的空调”、“把客厅空调打开”之类的语音命令,识别系统是无法识别的,严重影响了用户体验。
基于垃圾模型的隐马尔可夫模型关键词识别算法[4],要求垃圾模型覆盖全面,同时给智能家居中低端处理器带来了压力,造成识别速率的下降。为兼顾识别速率和用户体验效果两方面,本文设计的关键词语音识别系统,采用模拟人耳处理语音机制且具有较好的鲁棒性和识别区分度的梅儿倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)作为关键词语音识别系统的主要特征参数,不再采用相对复杂的隐马尔可夫模型而采用动态规整算法,提出采用单音节端点检测识别算法,该算法主要思想为:切分语音为单音节,对连续的单音节进行模板匹配,找到“可能关键词”,然后将“可能关键词”与模板匹配,辨别关键词真伪。
1 语音关键词识别的工作原理
语音关键词语音识别的基本算法框架如图1所示。包括语音信号预处理,端点检测,特征参数提取,模板库参考模板建立,模板匹配识别等基本单元[5-6]。

图1 关键词语音识别系统结构
预处理单元主要是对语音信号进行采样、量化、编码,并利用小波去噪算法实现语音增强;预加重的作用增强高频分辨率;由于语音信号具有短时平稳性,所有可以对语音信号进行分段处理,也就是加窗分帧;特征提取之前先对输入信号进行端点检测,这一步也是本文提出关键词抽取的重要一环,几乎所有的语音识别系统端点检测的目的只是检测说话者语音开始时刻和结束时刻[7-8],但本文提出按音节划分的端点检测方法,如图2所示。
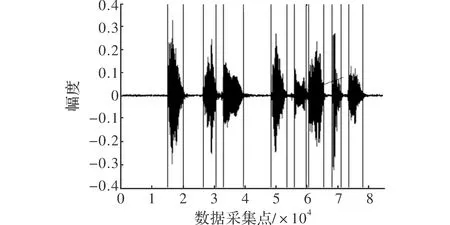
图2 按音节端点检测结果
特征参数提取单元采用梅儿倒谱系数提取代表语音基本特征的参数;根据特征参数建立参考模板库;模式匹配单元,对用户输入的语音按音节端点检测之后再进行特征提取并逐个与模板库中的特征参数相似度计算,若匹配到相似度P
算法将智能家居中的关键词分成多个音节(字),模板训练阶段每个音节建立参考模板,同样对所有语音关键词训练建立模板。 识别阶段将按音节端点检测划分的字进行模板匹配,当匹配到关键词的第一个音节之后再进行下一个音节匹配,如果在匹配到连续的几个字可能是某个关键词里面的音节,再将这连续的几个音节切取与关键词模板匹配,若匹配成功则确认此连续音节为关键词。
2 语音关键词识别算法
2.1 语音音节端点检测原理
传统的端点检测仅仅检测语音开始时刻和结束时刻[9],这种方法并不适合本文提出的关键词识别方法。本文在改进的短时能零差分法(短时能量和短时平均过零率差分阈值相互结合)的基础上,利用语音信号各音节之间的停顿间隔对音节进行端点检测。
用En表示第n帧信号xn(m)的短时能量,如式(1)所示
(1)
一帧语音信号中波形通过零电平的频率称之为短时过零率,如式(2)所示
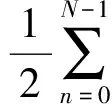
(2)
式中,sgn[·]为符号函数,即
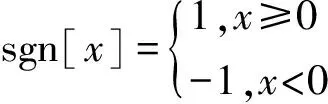
(3)
语音信号帧的非语音部分,短时能量Mn和短时平均过零率Zn变化缓慢,而在非语音和语音部分的过渡部分这两个参数急剧变化,因此通过判断这两个参数就可以找到语音信号起始点和结束点。由于语音信号的浊音短时能量和短时过零率变化明显,而清音只有短时过零率变化明显。
短时能零差分法的检测步骤如下:
(1)对输入语音信号预处理,并根据语音信号的短时平稳性进行分帧,每帧长度为32 ms;
(2)分别计算前5帧语音数据的平均短时能量En和平均短时过零率Zn;
(3)假设短时能量差分的高,低阈值分别为ε2和ε1,短时平均过零率差分的阈值为δ;
(4)从语音信号的第6帧数据开始,每5帧组成一组,把每组最后一帧的短时能量与En求差分,得差分值m。将m与短时能量差分的低阈值相比较,若m<ε1,则说明还未进入有效语音部分,重复执行步骤(4);若差分值m>ε2(高阈值),则表明该帧已经是有效语音帧,接着执行步骤(5)寻找改组中具体有效语音部分的正真起始点;若ε1 (5)向前搜索。将步骤(4)中找到的语音信号起始点所在组的每一帧数据的短时能量与En求得差分m,与ε1相比较,若m>ε1,则认为进入语音的段。同时,为了防止漏检,将每帧的短时过零率与Zn的差分值n,与阈值δ比较,若n<δ的帧为Hz,则认为该帧为本次输入的语音起始点。若改组中每帧的n值均大于δ,则需要继续向前搜索,直至语音信号的真正起始点为止; (6)向后搜索。查找语音音节信号的结束点。继续向后计算每组数据最后一帧的短时能量与En的差分值m,若m (7)根据以上步骤得出的数据计算语音信号的长度L=Y-X,然后与预先设置的语音信号段的最小长度Lmin相比较,若L (8)循环执行上述步骤,直到将输入的语音所有语音音节端点检测完毕,将所有起始点和结束点存入数组保存。 2.2 MFCC特征参数提取 梅儿滤波器组提取的梅儿倒谱系可以有效的表征语音信号特征,并且具有良好的语音特征距离,区分度比较好。Mel频率与线性频率Hz的关系为 (4) MFCC参数提取具体计算过程如下[10]: 赛前,省联社党委副书记殷青作了热情洋溢的致辞。经过激烈角逐,最终昆明代表队荣获一等奖,科技结算中心代表队、曲靖代表队、文山代表队荣获二等奖,玉溪代表队、楚雄代表队、保山代表队、昭通代表队、临沧代表队荣获三等奖,版纳、德宏、大理、丽江、怒江、普洱、红河、迪庆、省联社机关获优秀组织奖。 (1)根据式(5)将实际物理频率转化为Mel频率; (5) (2)对输入语音帧进行端点检测后做FFT变换得到其频谱,将时域信号转化为频域信号; (3)根据端点检测后信号的幅度幅度谱|Xm(k)|,确定带通滤波器组的输出; (4)对所有带通滤波器的输出做对数处理,并做DCT变换,得到MFCC特征参数 (6) 2.3 DTW关键词检出算法原理 2.3.1 语音音节识别 对每一帧语音信号提取MFCC特征参数以后,就转化成一组MFCC特征向量。语音识别就是要将测试的语音特征向量同模板库中已经存在的语音特征向量进行模式匹配,寻找距离最短的模式作为识别结果[12]。在用 DTW 算法进行识别判决时,由于测试语音与参考模式语音长短不同, 因此需要通过 DTW 动态计算两个长度不同的模式之间的相似程度, 或者叫做失真距离。假设待测语音共有N帧矢量 ,参考模板共有M帧矢量, 且N一般不等于M,则动态时间规整就是寻找一个时间规整函数j=ω(i),它将测试矢量的时间轴i,非线性地映射到模板的时间轴j上,并使该函数满足 (7) 式中,d[T(i),R(ω(i))]是第i帧测试矢量T(i)和第j帧模板矢量R(j)之间的距离测度,D则是处于最优时间规整情况下两矢量之间的匹配路径[13]。 2.3.2 语音关键词识别 关键词检测的方法首先是将测试语音通过改进的端点检测对语音按音节进行分离,将每一个音节提取MFCC特征矢量参数与模板库中每个音节进行模板匹配,如果检测到此音节与模板库中音节相似度Ps>P,则初步判断可能为某个关键词的首音节,则继续检测下一个音节,如果其相似度Ps>P,则继续检测下一个,直到检测到某个音节Ps 图3 关键词语音识别算法识别流程 实验所用到的语音信号采样频率为16 kHz,进行音节端点检测提取语音音节,使用0.95的因子进行预加重,使用14维梅尔倒谱系数作为语音特征。实验环境为ARM Linux系统、CPU为2.1 GHz、内存为1 GB的计算机。利用C++和Matlab 语言联合开发了一套关键词语音识别系统,利用Matlab语言对接收语音信号进行预处理、端点检测、模型训练以及模型匹配进行函数接口设计并封装为动态链接库DLL供C++调用,使用C++设计Linux下智能家居语音识别系统。 从智能家居环境选择了15个指令关键词,分别为:打开、关闭、电视、空调、热水器、电灯、窗帘、提高、降低、温度、洗衣机、窗户、抽湿、水温、加湿。提取所有关键词以及音节特征参数建立关键词模板。使用100句包含关键词和非关键词的句子进行测试实验。 统计结果如表1所示。 表1 关键词检出实验结果统计 随机测试了30人对孤立词语音识别系统和关键词语音识别系统的体验效果,分别在事先了解孤立词语音指令条件下和不了解孤立词语音指令条件下测试,结果统计分别如表2和表3所示。 表2 事先了解孤立词指令时的满意度测试结果 表3 不了解孤立词指令时的满意度测试结果 对比表2和表3可以发现,对于测试者测试前了解和不了解孤立词指令,关键词语音识别都能很好的满足测试者体验要求。但是对于孤立词识别系统,当不对测试者事先进行孤立词培训的情况下,满意度较差,达不到用户要求的体验效果。 针对智能家居孤立词识别体验效果差问题,提出了一种音节端点检测并关键词确认的方法。实验结果表明,此关键词语音识别算法提升了用户对智能家居语音识别系统的体验。但是此系统是建立在小词汇量语音库的前提下,随着语音库的增大,系统的识别速率会逐渐下降,错识率也会逐渐提升,下一步目标是基于此关键词抽取算法利用隐马尔科夫模型建模来提升识别率。目前设计的语音识别系统是建立在ARM Linux平台下的,在低端处理器和其他操作系统下,该识别系统的效率和识别率还未经验证,下一步将识别程序移植到Win CE系统和低端单片机上进行测试。 [1] 于俊婷,刘伍颖,易绵竹.国内语音识别研究综述[J].计算机光盘软件与应用, 2014(10):76-78. [2] Li Yunhong,Li Ziling.The improved DTW voice recognition algorithm[J].Information Technology Applications in Industry,2013(12): 263-266. [3] Li D,Ming Y,Lu H Y.Research of speech recognition for detection of program behavior Based on CDHMM[J].Journal of Wuhan University of Technology,2012,34(9): 2147-2150. [4] 彭辉,魏玮,陆建华.特定人孤立词的语音识别系统研究[J].控制工程,2011,18(3):398-404. [5] 朱淑琴,赵瑛.DTW语音识别算法研究与分析[J].微计算机信息,2012,28(5):150-152. [6] 路青起,白燕燕.基于双门限两级判决的语音端点检测方法[J].电子科技,2012, 25(1):13-15. [7] 陈孟元.基于改进型DTW算法和MFCC的语音识别[J].安徽工程大学学报,2014,29(1):54-57. [8] 文翰,黄国顺.语音识别中DTW算法改进研究[J].微计算机信息,2010,26(19):195-197. [9] 吴佳龙,李坤,刘中.孤立词语音识别算法研究与设计[J].电子科技,2015,28(2):22-24. [10] 徐子豪,张腾飞.基于语音识别和无线传感网络的智能家居系统设计[J].计算机测量与控制,2012,20(1):180-182. [11] 魏峰,胡腾,王晓明.智能控制研究的发展与应用[J].工业控制计算机,2007,20(8):1-3. [12] 俞文俊,凌志浩.一种物联网智能家居系统的研究[J].自动化仪表,2011,32(8):56-59. [13] 刘荣辉,彭世国,刘国英.基于智能家居控制的嵌入式语音识别系统[J].广东工业大学学报,2014,31(2):49-53. [14] 李克粉,王直.改进的小波阈值去噪在语音识别中的应用[J].计算机技术与发展,2013,23(5):231-234. [15] 李海东,李青.基于阈值法的小波去噪算法研究[J].计算机技术与发展,2009,19(7):362-368. Improved Speech Keyword Spotting Algorithm in Smart Home ZHANG Shuailin (School of Telecommunications, Lanzhou Jiaotong University, Lanzhou 730070, China) The recognition algorithm with the isolated word widely used in Smart Home fails to yield desirable result. A keyword speech recognition algorithm based on Dynamic Time Warping (DTW) is proposed. The smart home speech input is split into a number of single syllables and then matched with the template. The multiple syllables continuously matched successfully are considered as "possible key words", which are matched again with the template, and the successfully matched are judged as the "key words". Simulation and calculation of a large number of user speech inputs show a keyword detection rate of up to 82%. The keyword recognition system greatly enhances the users experience effect compared with the isolated word recognition. smart home; speech recognition; dynamic time warping; keyword spot; isolated word recognition 2016- 08- 26 张帅林(1991-),男,硕士研究生。研究方向:语音信号分析与处理。 10.16180/j.cnki.issn1007-7820.2017.07.002 TN926+.23 A 1007-7820(2017)07-005-04
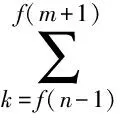
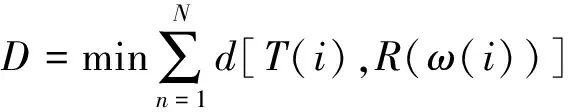
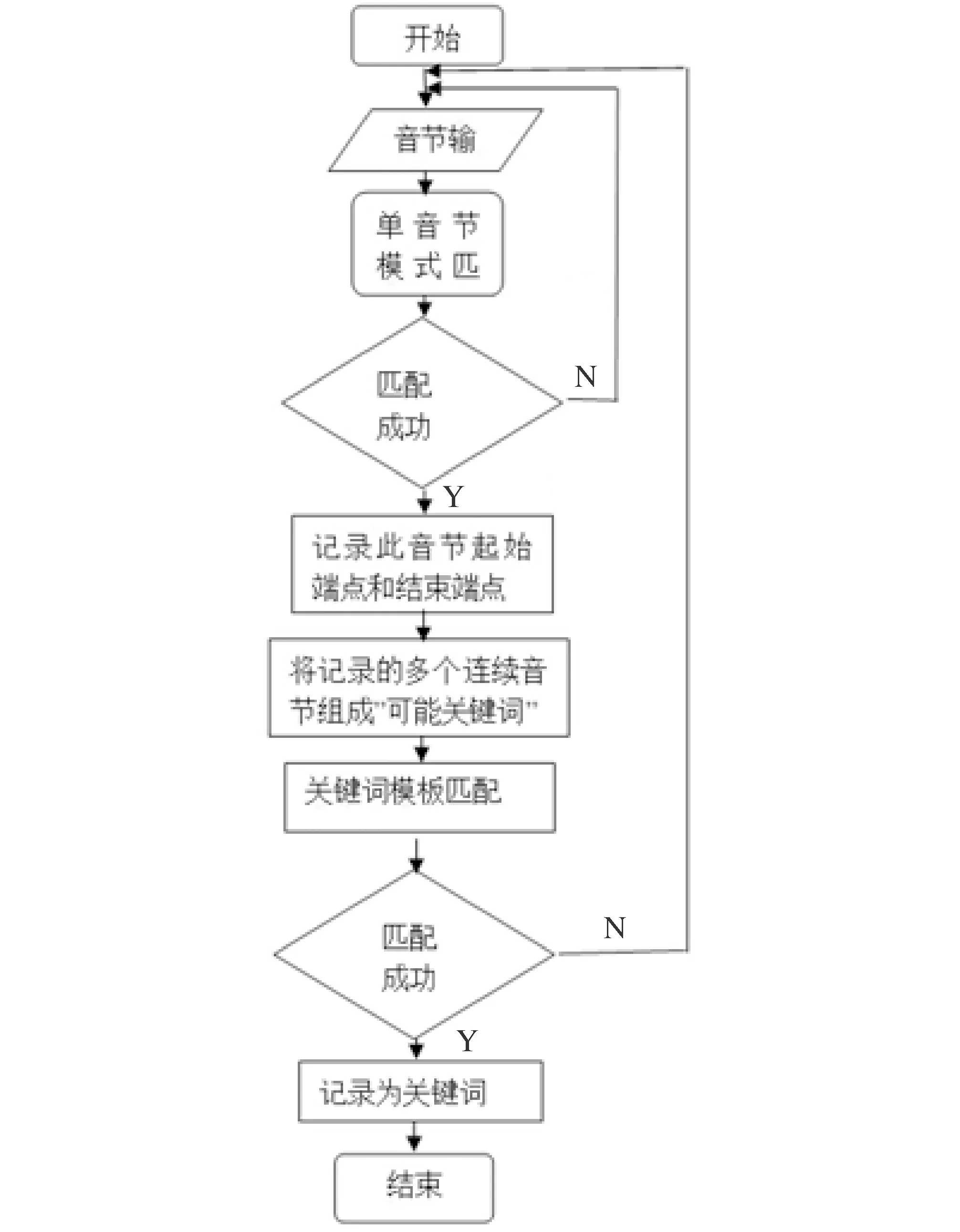
3 系统实现以及测试结果
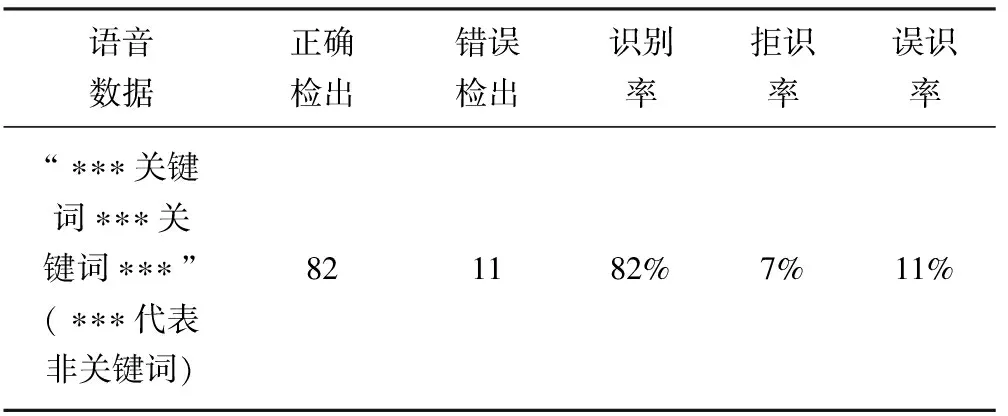


4 结束语
猜你喜欢
数学物理学报(2022年2期)2022-04-26空间科学学报(2020年1期)2021-01-14中学生数理化·教与学(2019年8期)2019-09-18快乐作文(1.2年级)(2019年9期)2019-09-10中国交通信息化(2019年12期)2019-08-13制造技术与机床(2017年11期)2017-12-18中国交通信息化(2017年8期)2017-06-06西藏大学学报(自然科学版)(2016年1期)2016-11-15北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27中国音乐教育(2014年11期)2014-05-18
