
微信文本会话的语言风格统计与分析
2017-05-09 12:17余一骄
华中学术 2017年2期
余一骄
(华中师范大学语言学系,湖北武汉,430079)
一、前 言
微信是当前国内最具影响力的移动网络社交平台,每天都有数以亿计的中国人在微信中聊天、互动。微信中产生了大量的汉语会话文本,这些文本既不属于正式的书面语,又不同于传统的汉语口语。微信好友大多是生活中的熟人或朋友,因此微信言语交际模式与网络论坛、博客、微博的言语交际模式存在显著差异。微信语言具有哪些特征,将会对汉语未来的使用习惯产生何种影响,越来越受到学术界的关注。最近五年已有多篇论文讨论过微信语言的风格,已有的研究具有以下特点:第一,对微信新闻标题的语言特色研究较多,但对会话文本的研究较少[1]。第二,关注如何提高微信文本的受追捧程度,或如何缩小微信谣言的传播范围,而对语言风格的研究较少[2]。第三,对少量微信文本进行主观考察的居多,却对大样本语料进行定量统计的极少。我们仅查阅到一篇论文使用了LIWC(Linguistic Inquiry and Word Count)软件对7116篇新闻文本进行了词频统计,但该文未对统计指标和过程作详细说明[3]。
关于微信语言的研究,有必要在以下两个方面进行改进:第一,要加强对微信文本会话的语言风格考察。如今主要的研究对象是微信新闻,但微信新闻大多是由专业写手撰写,从作者向读者单向传播。微信新闻的语言风格只能反映新闻写作者的语言风格,难以代表数亿微信用户的汉语使用风格。第二,利用专门的计算机软件对大规模的微信语料进行统计,根据定量的统计结果来分析其语言风格。语料少虽有利于语言研究者对其进行深度分析,但不利于全面、客观地描述微信语言的特点。
本文致力于建立大规模微信文本会话语料库,利用中文文本语言风格分析软件来统计语料,最终实现定量地描述微信会话的语言特征。本文结构安排如下:第二部分介绍语料采集与统计方法;第三部分分析会话方式、会话长度的统计结果;第四部分研究该语料库的高频字及其覆盖率;第五部分对高频词统计结果进行分析;第六部分总结全文。
二、语料采集及统计方法
微信会话主要分为微信群和微信好友两种类型。微信群支持多人共享会话,微信好友则是一对一会话,私密性强。有些微信群中的成员具有真实的社交联系,例如亲友群、同事群、同学群、班级家长群等;有些群则是因关注某个特定的话题而建立的,例如追日剧群、出国英语考试群等,该类群成员之间的社交联系不如前者紧密。微信群中的发言者需要为自己的不当言论承担后果,通常多数微信群会话者发言前要考虑自己的表述是否恰当。不同微信好友的会话风格与会话者之间的关系、个人的语言习惯紧密相关。例如情侣之间的会话未必以文本方式为主,而是有较多的语音、视频会话。考虑到两类会话都很普遍,我们既采集微信群会话文本,也采集微信好友会话文本。
在2015年11月~2016年5月之间,两位微信文本会话采集者先后加入了42个微信群。这42个微信群包括同学群、亲友群、同事群、日剧群、出国英语考试群等。微信群中的成员所处地理位置分布较广,但以原籍湖北、河南、湖南等省的人为主。群成员受教育水平差异较大,但受过高等教育的人比例最高。由于微信好友会话的私密性太强,本文研究中仅采集到来自23对微信好友的会话语料。微信好友中的会话者都受过高等教育,年龄主要分布在20~30岁之间。
我们采用同步助手软件,把智能手机中的原始微信聊天记录导入到计算机中,并将其转换为TXT格式的文本文件。同步助手软件转换的聊天记录包括会话时间、发言者、会话方式、状态(接受/发送)、会话内容等多项信息。由于本文的研究重点是会话方式与会话内容,因此我们开发了专门的Java程序,对微信会话记录进行预处理。预处理包括以下三方面:第一,删除非文本方式的会话记录,例如图像方式会话、视频方式会话、语音方式会话等;第二,删除发言时间、发言者、状态等不必要的信息;第三,删除不做处理的英文字母串或阿拉伯数字串,如手机号码、邮箱地址等。
本文研究中所采集的原始微信会话语料超过57.6M个字节,因数据量大,难以用因特网上免费提供的字、词统计软件进行统计。我们曾在中文文本统计方面具有较长的研究经历和技术积累,独立开发了中文文本统计与检索软件[4],因此本文研究中的微信语料字统计、分词、词统计、互信息计算等均使用该软件来完成。
三、会话方式与长度
中国、日本、韩国的网络语言“颜文字”虽然均起源于英语中的表情符(emoticon)表达方式,但很快就有了显著区别,其原因是三国的民众都将英语表情符的表达方式和本国的文字进行了灵活的组合[5]。随着网络通信带宽的增加,网络终端设备的计算和存储能力增强,网络会话方式变得愈加丰富。近二十年来,中国网民在网络会话过程中,从只能输入纯粹的中英文字符,过渡到可输入丰富的“火星文”、图像、动画等多种类型的信息。微信更是提供了文本、图像、动画表情、视频、网页链接等十多种网络会话模式。

表1 各种会话方式所占会话次数的比例
本文研究的微信语料共包括475262次不同方式的会话,表1列出了十二种会话方式所占会话次数比例(本文所有的比例数据,都对小数点后第三位数据做了四舍五入处理)。文本会话一共是394261次,占总次数的82.96%,是最主要的会话方式。值得指出的是:微信软件把纯粹由微信所提供的表情符组成的会话归为文本方式的会话。动画表情、图片分别是第二、第三高频使用的会话方式。使用动画表情方式,大多是为了夸张、顽皮或戏谑地表达自己喜欢或厌恶、支持或反对的态度。选择图片方式进行会话的原因则较为复杂,例如有些图片能传达文本不能表达或难以表达的信息,有些图片能起到惊悚或吸引其他人注意力的效果。是否选择语音方式进行会话,既与会话人之间的亲密程度相关,也与发言者是否便于输入文字相关。通常关系越亲密的人,使用语音方式的概率越高;所处环境不便于打字或手写输入,则使用语音方式的概率较高。总之,微信强大的信息输入功能,使得文本会话不再是唯一选择,可以预见未来文本会话所占比例会进一步降低。
394261次微信文本发言共使用了2525301个汉字,因此,平均每次文本发言仅包含6.4个汉字。若是用一次发言所包含的汉字数量来简单地度量文本会话的长度,可知微信会话大多是很简短的。表2列出了在39.4万余次的文本会话中,不同长度发言的次数、比例分布情况。根据表2左半部分所列数据可知,70.83%的发言所包括的汉字数不超过7个。微信会话如此简短,存在主客观两个方面的原因。首先,网络实时交流的环境决定了发言者必须高频使用一些简短的句子,例如会话刚开始时,用“你好”或者“大家好”来打招呼;确认信息时,用“好的”或“行”来表明态度;用“再见”、“拜拜”来终止会话。其次,微信用户似乎不大乐意写长句子,而是用多个短句来描述一件事情或某种观点。微信会话中,大家更趋向于以较快的速度发出一条讯息,以减少对方的等待时间。所以,一旦有个相对独立的句子,用户就会立即发送出去。出于这种心态,本来可以用一个较长的句子来完整表达的会话,最终被分解成了多条简短的讯息。
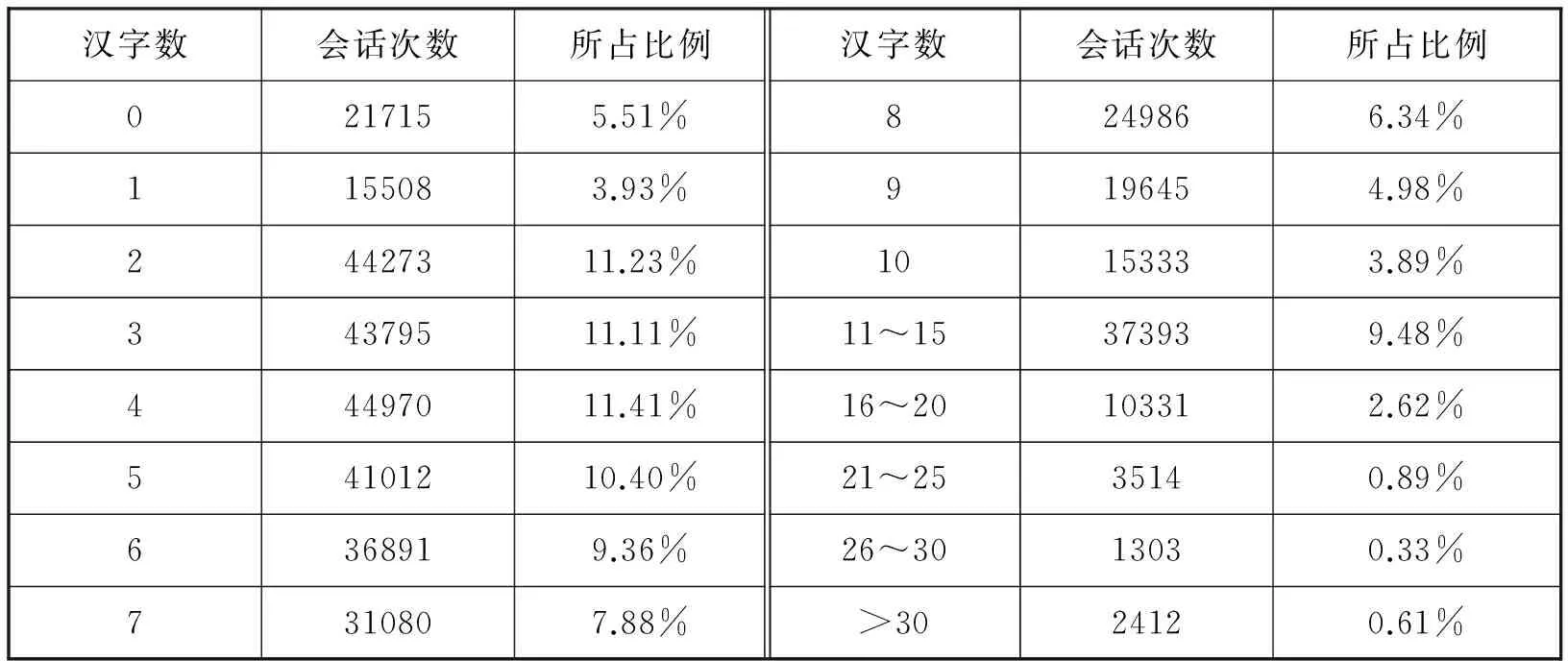
表2 不同长度的文本会话次数与比例分布
语料中全体会话者的母语都是汉语,表2却显示有21715次文本会话(占文本会话次数的5.51%)没有使用汉字。细致考察这21715次会话,发现这些非汉语表达的会话主要分为四种类型:第一,有8347次会话是纯粹利用微信表情符来进行会话;第二,用英文单词、英语句子打招呼或表示肯定或否定,例如OK、Bye、hi、baby、perfect、I love you等;第三,使用英语网络词,如“THX”(表示thanks),或中国人创造的网络语言字母词、数字词等,例如2B、6666666等;第四,对其它人所提问题的有效回答,例如阿拉伯数字形式的手机号码、QQ号码,英文字母和数字混合的邮箱地址、网页地址等。第四类会话与用户的语言使用习惯无关。从积极的角度来看,如今受过高等教育的年轻人对语言使用的态度越来越开放和包容,能做到汉语、外语、表情符融合使用。但另一方面,中外文、表情符混杂使用,且缺乏明确的语法规则,这对汉语的纯洁性具有负面影响。
四、汉字频次及覆盖率分析
北京大学开发的CCL中文语料库是有重大影响的书面语语料库。它的语料规模大(现代汉语语料库近5.1亿个汉字)、来源广泛、代表性强,且公布了该语料库的汉字频次数据[6]。CCL语料库能比较全面、定量地反映现代汉语书面语的汉字频次使用特征。以下通过与北京大学CCL语料库的汉字频次统计结果做对比,来分析微信会话中的汉字频次特征。
微信文本会话语料库共包括2525301个汉字,4957种不同的汉字。CCL语料库中共出现了10645种不同的汉字。表3列出了微信会话语料库与CCL语料库的高频字集对比结果。“的”、“一”、“是”、“了”、“不”、“有”等6种汉字是微信语料库和CCL语料库共同的最高频的10种字,因此两个语料库最高频10种汉字集的重合率为6/10=60%。从表3中的重合率数据可知,两个语料库的最高频汉字集有较大区别。对比两组覆盖率数据可知,微信语料库最高频的10种、20种、50种、100种、200种汉字的覆盖率都显著高于CCL语料库。在微信语料中,有581种汉字(占字种数的11.72%)仅出现了1次,388种汉字(占字种数的7.83%)仅出现2次,有1857种汉字(占字种数的37.46%)的使用频次低于10次。因此,微信中的汉字使用更集中。
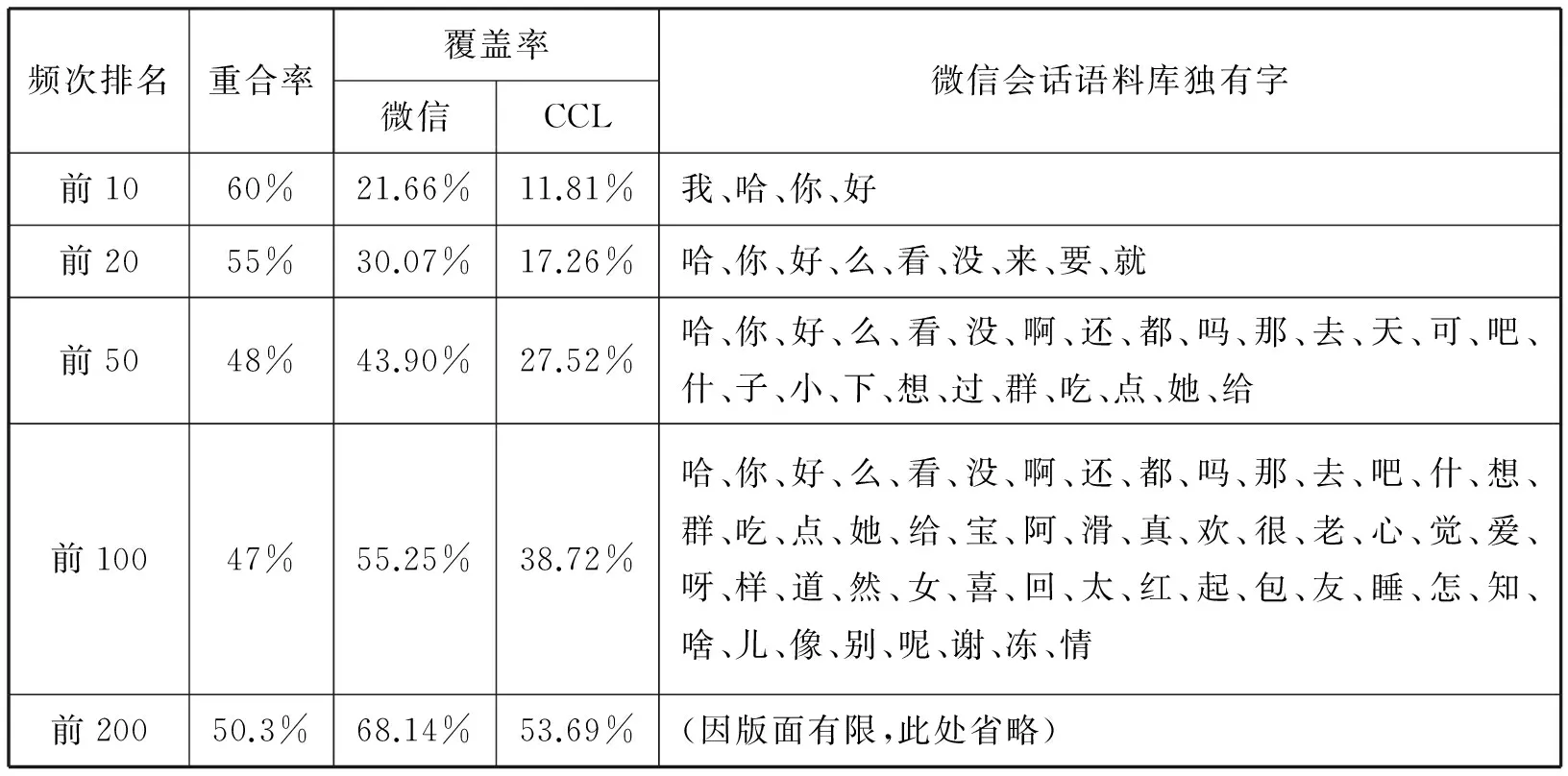
表3 微信语料库与CCL语料库的高频字对比
由表3所列的微信语料高频独有字,可知微信会话用字具有以下三个特点。
第一,部分口语交际常用字频次极高。表3显示“我”、“你”、“好”、“哈”等字的频次位于前10名。“哈”字在微信语料中频次排序第4,而在CCL中排名第698,二者相差694位。“哈”字在微信会话语言中的使用既高频又不符合常规。在CCL语料库中,检索到“哈”字连续使用的最长串是8个“哈”字连用(仅4条语料)。CCL中比例最高的是“哈哈”或“哈”。在被统计的微信文本会话语料库中,十个或十个以上的“哈”字连用的现象出现了数百次,最长的竟然达到了89个“哈”字连用。数十个“哈”字连用的例子,在传统的语料库系统中极为罕见。
第二,涉及日常生活的汉字频次高,涉及国家、社会、经济、政治等领域的汉字频次低。“睡”、“爱”、“吃”、“群”、“红”、“包”属于微信中最高频的100种汉字。“工”、“国”、“政”、“民”属于CCL语料库中最高频的100种汉字,而在微信中却排在第268名之后,“政”字更是位于第1605名。有研究者认为中国政府执行的网络信息过滤政策,对网络用户的语言产生了极大影响[7]。在39.4万余次的文本会话中,很少涉及国内外政治、经济问题的讨论,众多的讨论主题持续集中在娱乐、美食、购物、学习、考试等方面。年轻人更关注个人生活,可能才是导致“工”、“国”、“政”、“民”等字低频出现的主要原因。
第三,有些代表性的网络用语高频字,在微信语料库中的频次并不高。例如,“囧”字是具有代表性的网络用语高频字,但在微信会话语料中,它仅出现22次,字频排序为第2603位。我们用多种品牌的智能手机做过测试,无论是手写收入,还是拼音输入,都能快速输入“囧”字。因此,输入法不是导致“囧”字使用较少的主要原因。微信软件提供了表示尴尬、困窘、汗颜的表情符,该类表情符被高频使用。随着表情符和表情包的流行,微信用户逐渐用更生动、形象的表情符和表情包取代了曾经的“颜文字”——“囧”。
五、高频词统计与分析
由于CCL没有公布词频统计结果,故无法将微信文本会话语料的词频统计结果与之对比。但在2011年至2013年期间,我们曾开发了一个约4.86亿字规模,包括现当代文学、新闻报道、政府公文、网络小说、法律法规的现代汉语语料库CICI。我们使用同一个软件对微信语料和CICI语料进行了分词处理和词频统计。
表4列出了微信语料库和CICI语料库的高频词对比情况。由表4第二列所示的一组重合率数据可知,两个语料库最高频词的重合率约为60%,因此二者的高频词集合差异明显。在两个语料库的最高频300种词中,“的”、“了”等单音节词重合较多,双音节词重合数量较少,没有重合的三音节词。“为什么”在微信语料中的词频排序是第130名,在CICI语料中的排序是第367名,仅有“为什么”这一个三音节词的词频排序同时位于两个语料库的前1000名。“为什么”、“差不多”、“一会儿”、“怎么样”、“没什么”、“干什么”6种三音节词的词频排名都在两个语料库的前2000名之内。
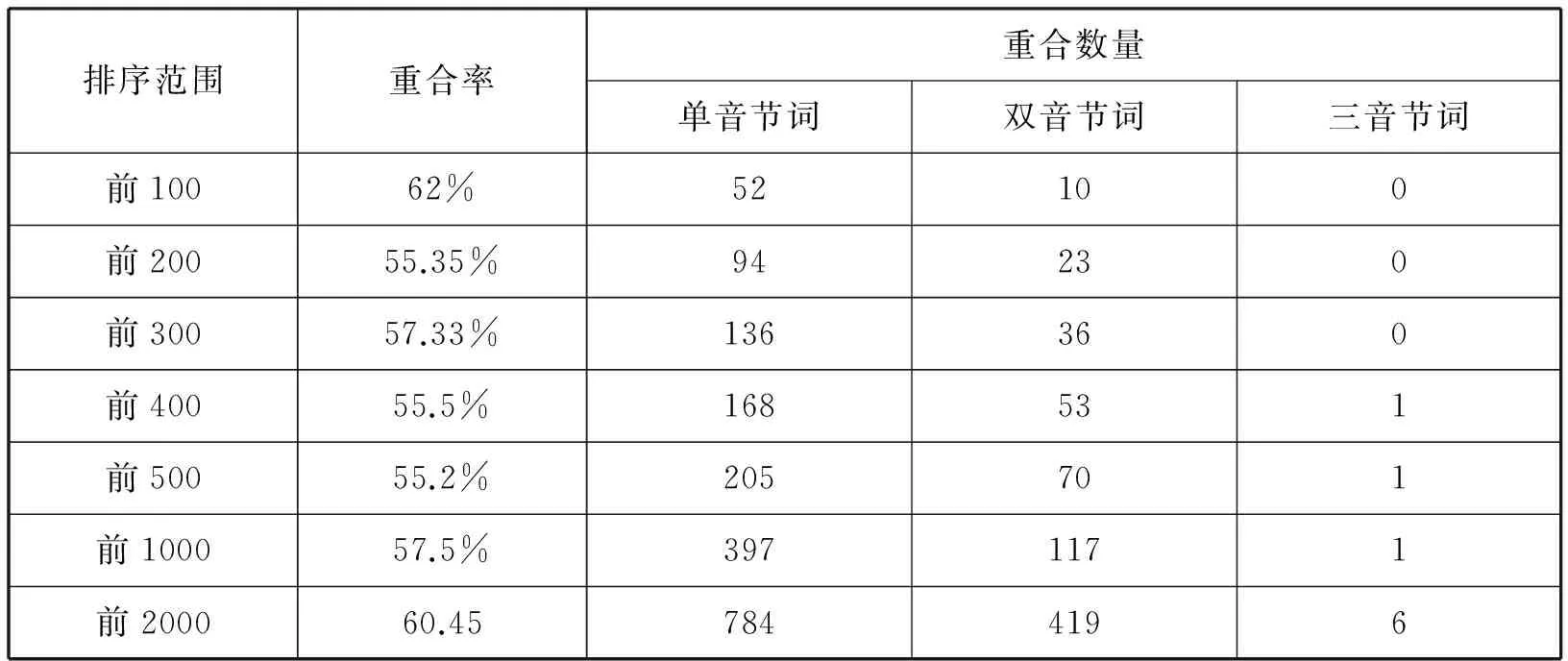
表4 微信语料库与CICI语料库的高频词对比
新词新语是网络语言研究的核心问题。本文既关心微信会话中高频使用的网络新词新语,也关心微信语料中产生了哪些新词新语。词频统计结果显示:部分网络词语在微信中频繁出现,例如“宝宝”、“卧槽”、“约炮”、“尼玛”、“我擦”等。“宝宝”的频次为2884;“卧槽”出现853次;“约炮”出现257次;“尼玛”出现253次;“我擦”出现154次。“宝宝”原本是对小孩儿的爱称。而近年来网络用户不分男女老少,喜欢自称“宝宝”或互称“宝宝”。“宝宝”的频次在微信语料中排名第100,“本宝宝”、“群主宝宝”、“吓死宝宝”等使用频繁,而作为本义使用的较少。由此可知,微信会话中卖萌化的语言风格十分强烈。但值得注意的是:微信语言和微博语言的高频网络热词不太一致。例如,“欧巴”、“欧巴桑”、“萝莉”、“草泥马”等典型的微博热词在微信会话语料库中的频次却并不高。“欧巴”出现22次;“草泥马”出现18次;“萝莉”出现15次;“欧巴桑”出现1次。由此可知,把微博语言和微信语言笼统地归为微语言进行研究,不利于描述二者的细微区别。
计算二字串或三字串的互信息大小,是自动发现汉语新词的有效办法。本文研究过程中,根据N-gram串统计结果,计算了微信语料库中全体2字串、3字串的互信息值。结果显示:互信息高的新词大多为人名、地名(例如街道名)、影视剧名、商品名等专属名词,基本上没有发现频次、互信息均很高的非专属名词。由此可知,微信用户乐意在会话中使用已经流行的网络词语,而不是在微信中自造新词新语。微信会话的传播范围极为有限。用户在微信会话中自造的新词新语,既存在被对方误解的风险,又因读者太少,难以在网络上大范围传播。自造新词对凸显发言者的个性没有显著效果,使用流行的网络新词新语不失为彰显个性的可行途径。总之,高频地使用已有网络新词新语,而不是自创网络新词新语,是微信会话小范围传播语言与微博、博客等大范围传播语言的一个重要差异。所以研究微信语言时,更应该关注微信会话中的高频网络词语的种类、特点及其成因,而不是微信会话过程中创造出的新词新语。
尽管微信会话大多是熟人之间的交谈,但词频统计结果却表明微信会话仍存在用语过于粗俗的现象。以包含了“逼”、“屌”等字的词语的频次数据来深入分析该现象。“牛逼”出现240次;“傻逼”出现205次;“装逼”出现130次;“撕逼”出现58次;“懵逼”出现50次;“苦逼”出现33次;“逼格”出现27次;“逗逼”出现19次;“丑逼”出现13次;“蒙逼”出现9次;“妈逼”出现8次;“二逼”、“穷逼”各出现7次;“逼样”出现6次;“帅逼”、“狗逼”各出现5次;“抠逼”出现4次;“怂逼”出现3次。在微信语料中,“屌丝”出现了83次,“很屌”、“不屌×”等格式比较常见。“屌”字的用法比较复杂,可以用作形容词、名词、动词。与比较熟悉的人用文字进行交流都如此不文雅,未来有必要引导民众在微信中文明、规范地使用汉语[8]。2017年1月我们对部分女大学生和女研究生展开调查,想了解她们为何使用包含“逼”、“屌”等字的词语。不少被调查者反映:她们看到“逼”、“屌”等字时,只将其作为中性字,通常不会联想到这涉嫌骂人或用语粗俗。由此可见,这些过去被认为粗俗的字词,如今在微信会话中呈现出了去污名化的新趋势。
六、结束语
本文采用统计大规模真实文本会话语料的方法来研究微信语言的风格。本文的研究具有以下两个特色:第一,对39.4万余次文本会话、252万余字的真实微信文本会话语料进行了定量统计。过去关于微信语言风格研究的部分结论在大样本统计分析中是不成立的,例如微信创造了大量的网络新词新语。第二,更关注普通民众的微信文本会话的语言风格,认为文本会话语言风格更深刻地反映当前汉语的使用状况。未来应扩大语料来源,对活跃的微信群进行长时间的观察,更细致地考察微信会话风格变化的历时规律。另外,对表情符、表情包的使用模式也要做更深入的研究。
*本文系教育部人文社会科学研究项目“基于大规模微信文本语料库的汉语会话分析”【16YJA740047】的阶段性成果。
注释:
[1]李少丹:《微信文本标题修辞特征与修辞过度显现探析》,《福建师范大学学报》(哲学社会科学版)2015年第3期,第70-75页;赵文雯:《新闻标题语言的特点及规范化探究》,《新闻世界》,2016年第6期,第40~44页。
[2]刘锐:《微信谣言元文本的召唤结构、受众期待视野与辟谣策略》,《情报杂志》2016年第12期,第34~41页。
[3]何凌南、胡灵舒、李威、张志安:《“标题党”与“负能量”——媒体类微信公众号的语言风格分析》,《新闻战线》2016年第13期,第42~47页。
[4]余一骄、刘芹:《面向超大规模的中文文本N-gram串统计》,《计算机科学》2014年第4期,第263~268页。
[5]Xiangxi Liu,TheLinguisticAnalysisofChineseEmoticon,University of Massachusetts at Amherst,2015.
[6]CCL:《现代汉语语料》。[2003年] http://ccl.pku.edu.cn:8080/ccl_corpus/xiandai_char_info.pdf.
[7]Audrey M. Wozniak,Reiver-Crabbed Shitizens,Missing Knives,“A Sociolinguistic Analysis of Trends in Chinese Language Use Online as a Result of Censorship”,AppliedPsychologyReview,1,2015,pp.97-120.
[8]吕超男:《论微信语言文字应用的规范化问题》,《北华大学学报》(社会科学版)2016年第4期,第15~19页。
猜你喜欢
中学生天地(B版)(2022年4期)2022-05-17
长江丛刊(2020年17期)2020-11-19
音乐天地(音乐创作版)(2019年12期)2019-02-09
周末·校园文学(2017年35期)2018-02-06
计算机系统应用(2017年3期)2017-03-27
中国修辞(2017年0期)2017-01-31
读者·校园版(2015年7期)2015-05-14
图书馆论坛(2014年8期)2014-03-11
心理学报(2014年4期)2014-02-02
疯狂英语·原声版(2013年2期)2013-03-18
