
越南语短语树到依存树的转换研究*
2017-04-17 01:39郭剑毅余正涛毛存礼线岩团
计算机与生活 2017年4期
李 英,郭剑毅,2+,余正涛,2,毛存礼,2,线岩团,2
1.昆明理工大学 信息工程与自动化学院,昆明 650500
2.昆明理工大学 智能信息处理重点实验室,昆明 650500
越南语短语树到依存树的转换研究*
李 英1,郭剑毅1,2+,余正涛1,2,毛存礼1,2,线岩团1,2
1.昆明理工大学 信息工程与自动化学院,昆明 650500
2.昆明理工大学 智能信息处理重点实验室,昆明 650500
依存句法分析是自然语言处理的一个关键环节,目前对于越南语短语结构树的研究比较多,而依存结构树的研究就显得十分薄弱。提出了一种新的方法,尝试结合越南语的语言特点和语法特征,利用中心子节点过滤表的思想与统计的方法将越南语的短语结构树转换成依存结构树。首先依据中文依存关系标注体系与越南语的语法规则,制定出依存关系列表;然后结合越南语的语言特点,制定出中心子节点过滤表,利用中心子节点过滤表的思想进行初步转化;最后使用依存关系标注器来进行依存关系标注。基于转换后得到的依存结构树,利用MSTParser工具进一步训练得到更多的越南语依存结构树。对实验结果进行了抽样评估,树库转换的准确率达到了89.4%,较好地解决了越南语由短语树到依存树的转换问题。
句法分析;中心子节点过滤表;短语结构;依存结构;树库
1 概述
句法分析是指遵循给定的语法分析出句子的语法结构,其在自然语言处理、信息抽取和机器翻译等方面的研究中有着至关重要的作用。目前所使用的句法分析主要有两种形式:短语结构分析法和依存结构分析法。短语结构分析法就是将句子切分成短语,分析出句子短语之间的层次关系。短语结构树主要由终结点、非终结点和短语标记构成,其中最基本的成分是句法标记,也就是非终结点(例如名词短语NP、动词短语VP)。依存结构分析就是分析出句子短语之间的依存关系[1],其可以明确地表明词语间的支配关系(例如“我喜欢喝茶”,我和喜欢之间就是主谓关系)。由于依存关系的广泛应用,这些年也越来越受学者的重视。
当前国内外已有的树库可以分为两大类:一类是体现句子的语法信息的依存结构树库,比较著名的有捷克的布拉格依存树库,英语的PARC树库[2]等。另一类是体现句子短语之间的层次关系的短语结构树,目前比较著名的是美国的宾州树库Penn Treebank[3]。宾州树库在句法分析等方面具有较高的准确性,已经成为句法分析所公认的训练集合测试集。虽然目前关于越南语的树库建设已经有了一些进展,如在宾州树库中目前存在有10 000句的越南语短语结构树[4],但是在规模和质量上,和其他语言例如英语、汉语和德语相比,研究工作基础较弱,还有许多工作尚待开展。对于越南语依存树的研究目前主要包含两方面的工作:一个是Phương等人[5]利用MSTParser(maximum spanning tree parser)训练了450句语料库;另外一个是词汇化树链接文法对越南语树库子集进行训练[6]。对越南语树库建设来说,标注树库是一件费时费力的工作,需要完善标注体系和规范标注流程,从而保证标注的质量。
短语结构和依存结构虽然在表现形式上不同,但是它们都是对句子语法结构的描述,因此在结构上存在一致性。将短语结构树库转化为依存结构树库的研究方面,国外已有相关研究,如Magerman[7]提出了核心节点映射表,通过优先序列来确定一个组块中的核心节点;Collins[8]修改了Magerman的规则,将这种依存关系作为短语结构句法分析中的中间表示。Yamada和Matsumoto[9]重新定义了一个核心节点映射表,并且给出了一套转化程序,现已成为最流行的转化程序,被大量学者在研究过程中采用。Nivre[10]重新实现了Yamada和Matsumoto的方法,定义了一套启发式规则来确定弧的依存关系类型。其程序提供了宾州树库Penn Treebank和宾州中文树库Penn Chinese Treebank的核心节点映射表。Johansson和Nugues为了充分挖掘Penn Treebank标注的信息,提出了一套更加完善、细致的转化策略。
上述工作都是直接将短语树库转化为依存结构树库,其中依存句法关系类型一般都根据短语结构树库中的短语类型获得。但是由于语言之间存在一定的差异,这种方法在使用的时候还存在一定的局限性,主要是处理由语言本身带来的一些语序上的问题,这就需要结合语言本身制定中心子节点过滤表。
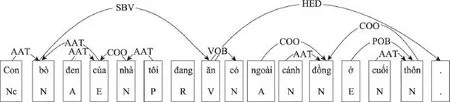
Fig.1 Example of dependency tree图1 依存结构树示例
本文提出一种新的方法,首先基于越南语言特点制定中心子节点过滤表,然后利用中心子节点过滤表的方法将越南语短语树库转化为依存树库,同时结合宾州中文树库(CTB)依存关系标注集,制定出越南语依存树的依存关系类型,最后利用online算法完成依存关系的标注。这样做的好处是可以增大目标树库的规模,无需改变句法分析模型学习策略,便可以提高依存分析器的能力。这项工作可以看作是利用多种树库学习句法知识的一种方式。经验证,本文所提方法在处理越南语树库转换以及越南语依存树库扩展上具有不错的实验效果,很好地解决了越南语依存句法分析的问题。
2 中心子节点过滤表
中心子节点在短语结构和依存结构中起着非常重要的作用。x-bar理论[5]和管辖约束理论[10]等语言理论认为,每个短语结构中都有一个中心子节点决定着这个短语的主要性质,短语中的其他节点都是该中心子节点的修饰子节点。而在依存结构中非中心子节点以某种依存关系依存于中心子节点。
依存结构树库标注体系如图1所示,其标注了句子中词语之间的依存关系及依存类型。短语结构树库宾州树库中句子的标注如图2所示,其仅标出每个句子的短语层次结构及短语类型,没有标明每个短语的中心子节点。确定短语中心子节点最常用的方法是使用中心子节点过滤表。
2.1 中心子节点过滤表的结构
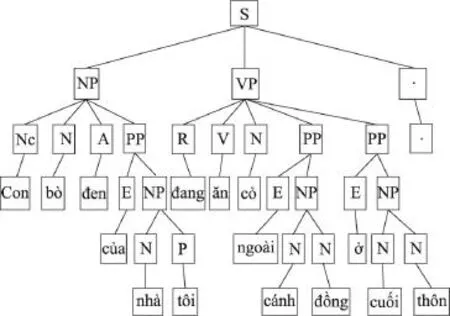
Fig.2 Example of phrase structure tree图2 短语结构树示例

Table 1 Head percolation table表1 中心子节点过滤表
中心子节点过滤表的制定是整个工作中很重要的一部分,表1为部分中心子节点过滤表,其每一行都由〈短语类型,搜索方向,优先级〉3项组成。其中,短语类型是非终端节点的短语符号;搜索方向为在非终端节点内部搜索中心子节点的方向,取值为L时从短语左侧开始向右搜索,取值为R时从短语右侧开始向左搜索;优先级为决定短语内部各类标注子节点作为中心节点的优先次序。例如,根据过滤表中的一个条目<VP,L,VP;V;A;AP;N;NP;S;.*>,可以这样确定VP短语的中心子节点:从左向右观察VP的每一个子节点,最先找到的标注为VP的子节点即为VP的中心子节点;如果没有找到VP节点,重新从左向右观察VP的每一个子节点,最先找到的符号为V的子节点即为VP的中心子节点;以此类推,如果这个VP内部没有任何标注为VP、V、A、AP、N、NP、S、.*的子节点,就默认最左侧的子节点为中心子节点。
下面举例来找到中心子节点:(VP(R không)(V còn)(NP-DOB(Nngười)(A nghèo))。首先需要在中心子节点过滤表中找到VP短语类型,可以看到VP所对应的条目是<VP,L,VP;V;A;AP;N;NP;S;.*>。第二步需要从左到右浏览VP短语中第一个标记为V就是词(V còn)。这就意味着“còn”就是这个VP短语的中心子节点。
2.2 基于越南语语言特征的中心子节点过滤表制定
2.2.1 越南语言的主要特征
越南语是一种典型的单音节、不变形、有声调的语言。词与词之间的语法关系不通过词本身的形态变化,而是靠词序和虚词等手段表示[11]。其主要特征如下:
(1)词序排列是越南语语法中最重要的表义手段。词序的改变会导致语义的改变,例如người còn、của còn不同于còn người、còn của。并且越南语句子中的词序大体上是一种具体性逐渐增强的词序,即词义越是概括性强的词汇在句中的位置就越是靠前,相反,词义越是具体的词汇在句中的位置越是靠后。
(2)语法体系高度稳定[12]。越南语受其他语言尤其是汉语的影响很大,这种影响主要体现在词汇层面,有半数以上的词汇是汉语借词或利用汉语语素创造的词。但就语法层面而言,汉语对越南语的影响不大,越南语仍保持自己的特色语法系统不变,例如“前正后偏”的词组结构规律就是永恒的。采用“前正后偏”的特色构词方式。名词性中心语表示性质特点的成分后置,或者说形容词后置,是越南语有别于汉语的最鲜明特点。人们称这种构词方式是“前正后偏”。这种前正后偏的组词方式体现在句子上就是“右侧补义”,也就是右面的词语补充说明左面的词语,越往后越具体[13]。例如对于下面的句子:
中文句子:水牛黑色我家的正在吃草 外面田野在村尾。
越南语句子:Con bò đen của nhà tôi đang ăn cỏngoài cánh đồng ở cuối thôn.
汉语恰好相反,是前偏后正,是左侧补义。
(3)越南语形容词与动词有许多共同的语法特点,常作句子谓语,被统称为“谓词”[14]。形容词直接后附补语的现象非常普遍,例如giỏi văn、kém toán、khỏengười、lười làm、dốtngười、sángdạ等。汉语形容词也可以带支配对象,例如“好色”、“好客”等,但不如越语普遍。
(4)状语位置灵活,前状语较汉语为多,中状语较少。汉语中的状语成分的位置比较灵活,前、中、后状语均很常见,但越南语以前状语为多,后状语次之,中状语较少,例如Ngày maitrờisẽmưa。
(5)越南语被动句式比汉语多。由于bị、được、do、bởi、do bởi等词的使用,越南语中的被动句式比汉语要多。例如:Bạnấyybịốm.Tôiđượcnghỉbangày.上述两个句子在用汉语表达时,如果硬把“被”“得”说出来,反倒别扭。
2.2.2 中心子节点过滤表制定
为了能够更好地找到每一个短语的中心节点,本文将上面所描述的越南语的特征融入到中心子节点过滤表的制定中;同时本文采用了简单的依存关系描述体系,其中包含11种依存关系类型,如表2所示。非中心子节点以表中所示依存关系类型依存于中心子节点。本文所用的越南语句子中依存关系的确定,主要是参照宾州树库的标注体系,同时在宾州树库标注体系的基础上,结合越南语语言特点做了相应调整。具体的依存关系的定义如表2所示,其中列出了宾州树库标注体系中每种短语包含的全部节点类型。
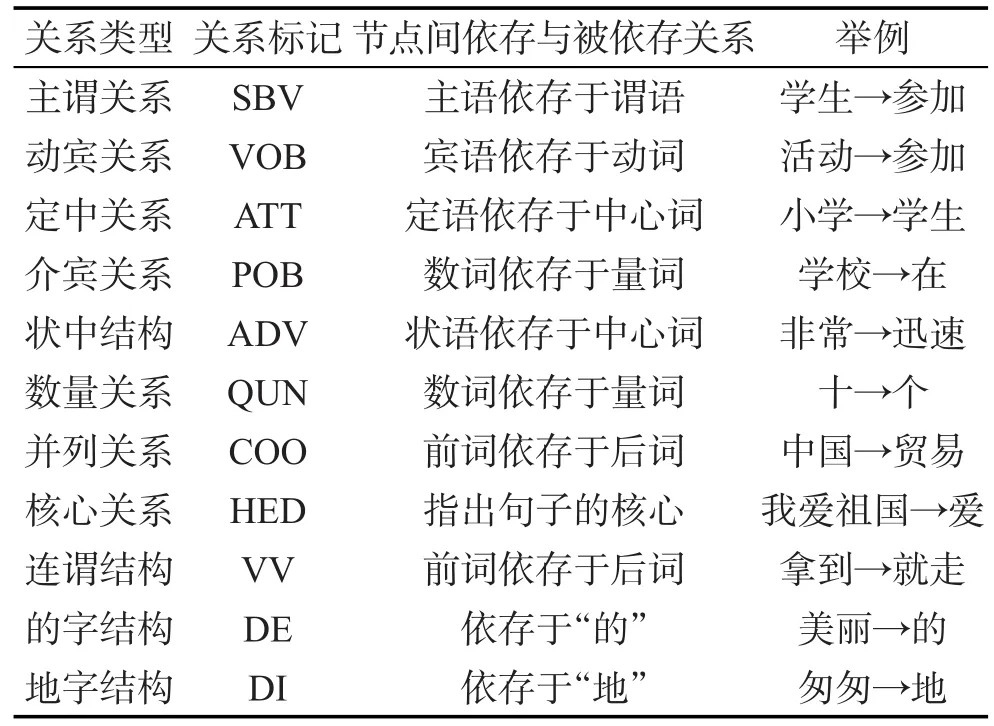
Table 2 Dependency types表2 依存关系类型
依据上述依存关系的定义,同时结合越南语的语法特点,对各类节点作为中心子节点的优先级进行排序,制定中心子节点过滤表,如表1所示。其核心子节点过滤表基本涵盖了所有的越南语短语结构类型,为越南语短语树到依存树的转换提供了较好的理论依据。
3 短语结构树到依存结构树的转换
3.1 利用中心子节点过滤表进行初步的转换
制定了中心子节点过滤表,短语结构树到依存结构树的转换就相当直接。转换采用递归算法,将短语结构树Tree constituency转换为依存结构树Tree dependency的转换算法ConvertCToD(Tree constituency,Tree dependency)为:
步骤1若根节点constituency为叶子节点,返回根节点constituency并完成转换。
步骤2査找根节点constituency的中心子节点。
步骤3转换以中心子节点为根的子树,并返回该子树的中心子节点headChild。
步骤4对于其他非中心子节点:
(1)转换以非中心子节点为根的子树,并返回该子树的中心子节点non-headChild;
(2)将non-headChild依存于headChild,并填入依存结构树Tree dependency。
图3显示了图2所示例句从短语结构树到依存结构树的转换。首先转换以S为根节点的短语结构树Tree IP。S不是叶子节点,查找S短语的中心子节点。参照表1中心子节点过滤表,从左向右观察S的每一个子节点,最先找到的标注为S的子节点即为S的中心子节点。由于没有找到S子节点,重新从左向右查找标注为VP的子节点为S的中心子节点。然后转换中心子树Tree VP,VP的中心子节点(Văn)为叶子节点,将其返回。继续转换VP的非中心子树Tree PP……依次确定句子每个短语的中心子节点,将短语的非中心子节点依存到其中心子节点上。
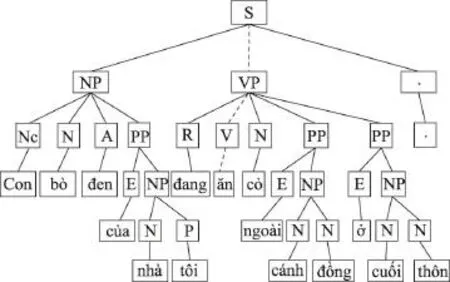
Fig.3 Conversion from phrase structure tree to dependency tree图3 短语结构树到依存结构树的转换例句
3.2 依存关系标注
在确定依存关系的过程中,主要采用了基于统计的方法来进行依存关系标注。本文利用online算法[12]来训练特征向量的权值。online算法不同于SVM,其在整个训练过程中最大化地提高整个树的准确率。同时online算法是一种基于距离最大化的学习算法,在依存关系分析、文本分类等方面得到广泛使用,并且性能很好。在实验中部分特征的选取如表3所示。
在表3中,c代表依存节点或者叫作子节点;h代表中心节点;h-word表示中心节点对应的短语;cword表示依存节点对应的短语;h-pos表示中心节点的标识;c-pos表示依存节点的标识;b-pos表示中心节点与依存节点中间的节点标识;h-pos+1表示中心节点右侧节点的标识;h-pos+1表示中心节点右侧节点的标识;h-pos-1表示中心节点左侧节点的标识。对于上面的每一类特征都采用回退的方法,将具体的特征进行了泛化,如表3所示。

Table 3 Partial features of dependency relation表3 依存关系标注部分特征集
为了能够对依存关系标注结果有一个准确的评估,本文采用3 000句人工标注的越南语依存树作为实验数据,其中前2 000句为训练语料,后1 000句为测试语料,通过分析标注器的训练测试结果,发现标注器的准确率达到了89.4%。具体的实验结果如表4所示。对依存关系标注器结果造成影响的因素主要包含两方面:(1)SBAR、MDP、AP等短语在初步转换时就发生了一些错误,直接导致标注器的准确率下降;(2)训练语料不够充足也是影响标注质量的原因之一。

Table 4 Dependency annotation results表4 依存关系标注结果
4 实验
4.1 实验数据集的准备
整个实验过程分为三部分来完成:第一步利用中心子节点过滤表的思想将短语结构树转化为依存结构树,在这个过程中使用的训练语料是来自宾州树库中的9 000句短语结构树;第二步以转化之后得到的越南语依存结构树作为基础训练集,利用Malt-Parser和MSTParser工具分别进行机器学习建模,进而生成依存结构树模型;最后在这个模型的基础上对越南语依存结构树进行扩展。为了保证实验数据的多样性,在进行依存结构树扩展的过程中使用的语料如表5所示。表5展示的语料来自于越南国内主要的新闻、百科、学术和娱乐等网站。同时对获取的文本信息进行处理,在每类文本中各自抽取5 000句,以500句作为一个子数据集。
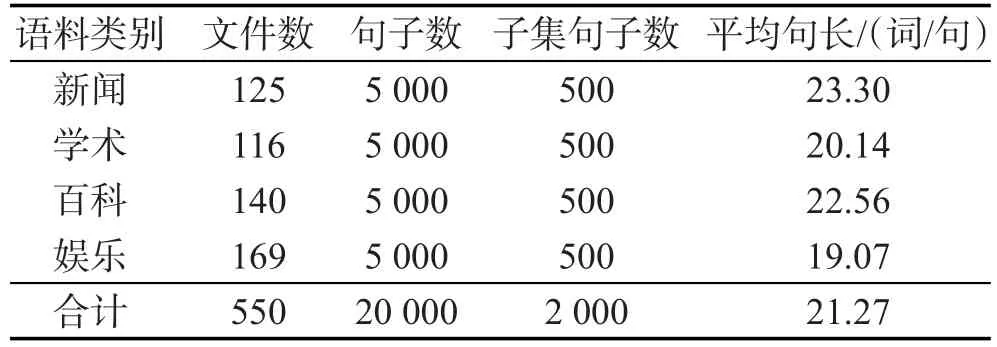
Table 5 Scale of Vietnamese dependency treebank expansion corpus表5 越南语依存树库扩展语料规模
4.2 评价方法
对于句子依存句法分析的评测指标主要是从两方面考虑:依存弧准确率(unlabeled attachment score,UAS)和标识准确率(labeled attachment score,LAS),对应定义如下所示:

4.3 短语结构树到依存结构树转换实验结果分析
为了准确地评估出实验结果的准确性,首先随机选取一个含有1 000个越南语句子的子集,用已经定义好的依存关系类型人工标注这1 000个句子的依存关系。
然后使用定义的树库转换算法结合中心子节点过滤表将这些句子由短语结构树转化为依存结构树。为了准确地评估中心子节点过滤表以及转换算法的准确性,将初步得到的依存结构树与人工标注的依存树进行依存关系的比对。得到的实验结果为初步转换得到的依存树的依存关系的准确率达到了98.1%。为了能够对各种短语类型初步转换结果有一个准确的把握,本文统计了短语结构类型分类的转换结果如表6所示。通过分析表6中的实验结果,可以发现对于大多数需要转换的节点来讲,转换的准确率是比较高的,总体的转换准确率也达到了97.6%。其中WHVP、MDP、SQ的准确率比较低,这些错误也会对转换得到的依存树库的质量有一定的影响。
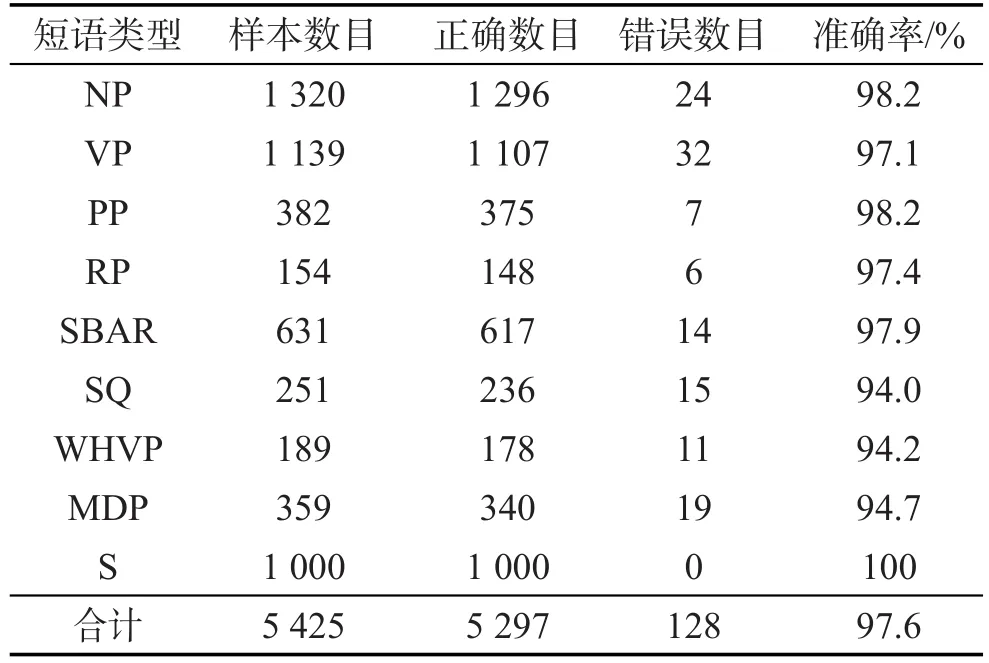
Table 6 Preliminary conversion results表6 初步转换结果
最后用转换后得到的最终依存树与人工标注的依存树作对比,得到了比较好的实验结果,其中依存弧准确率达到了97.6%,标识准确率达到了89.4%。
4.4 转化树库再利用实验结果分析
目前用于依存句法分析的工具主要包括:数据驱动句法分析工具MaltParser,斯坦福句法分析工具StanfordParser,最大生成树句法分析工具MSTParser等。MaltParser[15]是由Hall等人研究开发的比较实用的依存句法分析器,在句法分析中包含了两个过程:训练过程和分析过程。在训练过程中采用的是支持向量机算法,在分析过程中采用的是transition-based算法。StanfordParser是斯坦福大学自然语言处理机构研究开发的依存句法分析器;StanfordParser[16]基于宾州树库定义了53种英语依存关系,在英语的依存句法分析上取得了比较高的准确率。MSTParser[17]是 Mcdonald等人研究开发的依存句法分析器,主要包括两个过程:训练过程和分析过程。在训练过程中采用的是online算法,在分析过程中采用的是graphbased算法。这些分析器在目前大多数语言的依存句法分析上都取得了比较好的效果。
在实验过程中,本文利用MaltParser、Stanford-Parser和MSTParser来训练并解析越南语依存树,从而对越南语的依存树进行扩展。所用语料来自于新闻、百科、学术和娱乐网站各5 000句,以500句作为一个小的数据集进行训练。通过比对分析实验结果,挑选出进行越南语依存句法分析的分析器为MSTParser,实验结果对比如表7所示。
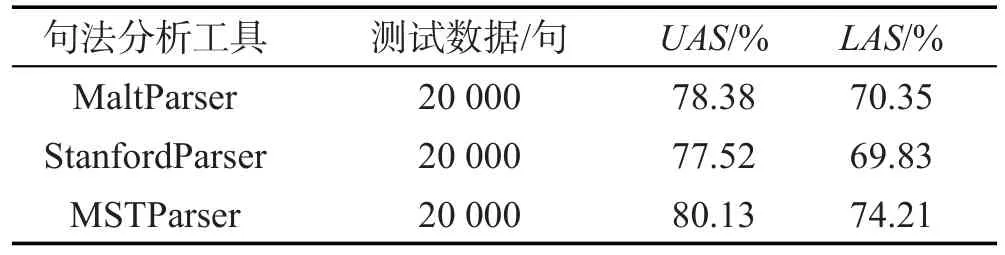
Table 7 Comparison of MaltParser and MSTParser on Vietnamese treebank expansion results表7 MaltParser与MSTParser越南语依存树库扩展实验结果对比
由表7可以看出:利用MSTParser进行越南语依存树库训练和解析的实验结果为UAS=80.13%,LAS= 74.21%;StanfordParser进行越南语依存树库训练和解析的实验结果为UAS=77.52%,LAS=69.83%;而MaltParser进行越南语依存树库训练和解析的实验结果为UAS=78.38%,LAS=70.35%。通过对比发现,在对于越南语依存句法分析方面,MSTParser的实用性更强。
使用MSTParser对越南语进行句法分析的详细实验结果如表8所示。对于4类语料,采用随机抽取的方式进行实验,每次从4类语料中抽取一个数据集进行实验。
从表8的实验结果中会发现,随着测试语料的不断增加,对于越南语依存树的解析的准确率也都有下降的趋势。导致实验结果的准确率并不是太高的原因主要包含两方面:MSTParser并不是针对越南语的句法分析器,在进行越南语依存句法分析时难免会出现偏差;同时也由于越南语语法规则的特殊性,虽然对中心子节点过滤表做出了改进,但依然存在不够完善的地方,需要进一步的改进来提高对整个越南语句法分析的准确率。
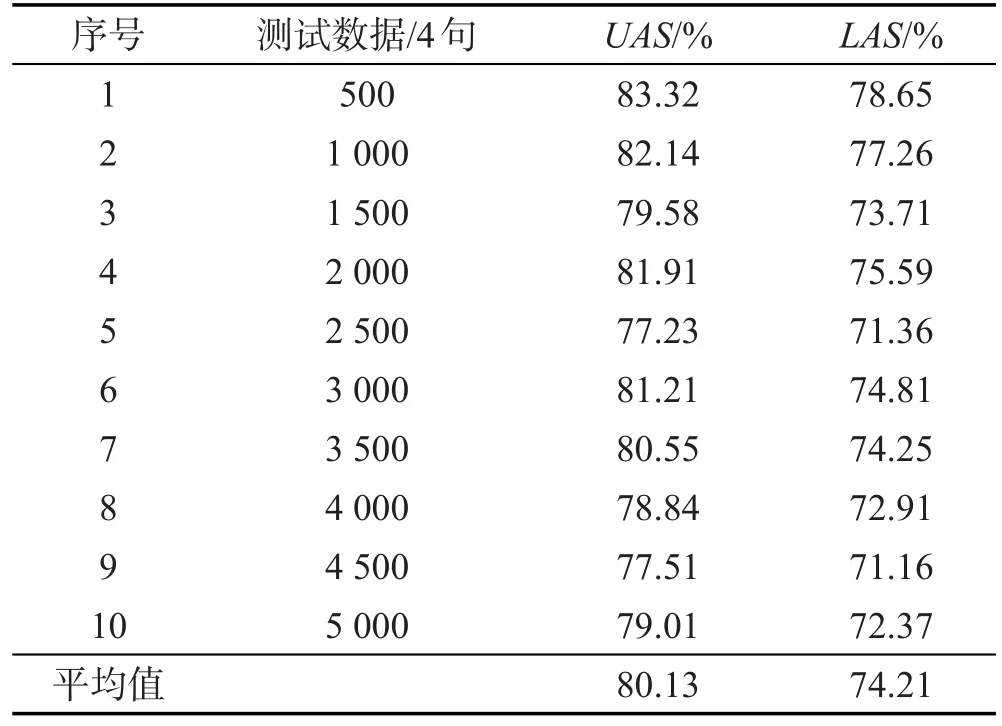
Table 8 Accuracy of using MSTParser to extend Vietnamese dependency tree表8 利用MSTParser进行越南语依存树扩展的准确率
5 结束语
本文结合越南语的特点制定了中心子节点过滤表,同时利用已有的宾州树库的短语结构树库的语料上进行了实验,使得越南语的树库转换的准确率达到了89.4%,很好地解决了越南语依存树短缺的问题。同时本文也对越南语的依存树做了进一步的扩展,利用MaltParser、StanfordParser和MSTParser进行对比实验,获取更多的越南语依存树库。下一步,将转换得到的依存结构树库融入到通过双语映射得到的越南语依存树库中,提高对越南语依存树分析的准确率,进而促进越南语机器翻译的研究。
[1]Bosco C,Lombardo V.Dependency and relational structure in treebank annotation[C]//Proceedings of the 20th International Conference on Computational Linguistics Workshop on Recent Advances in Dependency Grammar,Geneva, Switzerland,Aug 28-29,2004.Stroudsburg,USA:ACL,2004: 1-8.
[2]Hajič J.Building a syntactically annotated corpus:the Prague dependency treebank[M]//Issues of Valency and Meaning. Prague:Karolinum Press,1998:106-132.
[3]Sha F,Pereira F.Shallow parsing with conditional random fields[C]//Proceedings of the North American Chapter of the Association for Computational Linguistics on Human Language Technology,Edmonton,Canada,May 27-Jun 1, 2003.Stroudsburg,USA:ACL,2003:134-141.
[4]Collins M.Three generative,lexicalised models for statistical parsing[C]//Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and 8th Conference of the European Chapter of the Association for Computational Linguistics,Madrid,Spain,Jul 7-12,1997.Stroudsburg,USA:ACL,1997:16-23.
[5]Nguyen P T,Vu X L,Nguyen T M H,et al.Building a large syntactically-annotated corpus of Vietnamese[C]//Proceedings of the 3rd Linguistic Annotation Workshop,Singapore, Aug 6-7,2009.Stroudsburg,USA:ACL,2009:182-185.
[6]Phương L H,Huyên N T M,Roussanaly A,et al.A hybrid approach to word segmentation of Vietnamese texts[C]// LNCS 5196:Proceedings of the 2nd International Conference on Language and Automata Theory and Applications, Tarragona,Spain,Mar 13-19,2008.Berlin,Heidelberg:Springer, 2008:240-249.
[7]Magerman D M.Natural language parsing as statistical pattern recognition[R].Stanford University,1994.
[8]Collins M J.Head-driven statistical models for natural language parsing[J].Computational Linguistics,2006,29(4): 589-637.
[9]Yamada H,Matsumoto Y.Statistical dependency analysis with support vector machines[C]//Proceedings of the 8th International Workshop on Parsing Technologies,Nancy,France, 2003:195-206.
[10]Nivre J,Scholz M.Deterministic dependency parsing of English text[C]//Proceedings of the 20th International Conference on Computational Linguistics,Geneva,Switzerland,Aug 23-27,2004.Stroudsburg,USA:ACL,2004.
[11]Xia Fei,Palmer M.Converting dependency structures to phrase structures[C]//Proceedings of the 1st International Conference on Human Language Technology Research, San Diego,USA,Mar 18-21,2001.Stroudsburg,USA:ACL, 2001:1-5.
[12]Žabokrtský Z,Smrž O.Arabic syntactic trees:from constituency to dependency[C]//Proceedings of the 10th Conference on European Chapter of the Association for Computational Linguistics,Budapest,Hungary,Apr 12-17,2003. Stroudsburg,USA:ACL,2003:183-186.
[13]Phương L H,Roussanaly A,Huyên N T M,et al.An empirical study of maximum entropy approach for part-of-speechtagging of Vietnamese texts[C]//Proceedings of the 17th Conference on Natural Language Processing,Montreal, Canada,Jul 19-23,2010.
[14]Phương L H,Nguyen T M H,Nguyen P T,et al.Automated extraction of tree adjoining grammars from a treebank for Vietnamese[C]//Proceedings of the 10th International Conference on Tree Adjoining Grammars and Related Formalisms,New Haven,USA,Jun 10-12,2010.Stroudsburg,USA: ACL,2010:165-173.
[15]Nivre J,Hall J,Nilsson J,et al.Labeled pseudo-projective dependency parsing with support vector machines[C]//Proceedings of the 10th Conference on Computational Natural Language Learning,New York,Jun 8-9,2006.Stroudsburg, USA:ACL,2006:221-225.
[16]McDonald R,Lerman K,Pereira F.Multilingual dependency analysis with a two-stage discriminative parser[C]//Proceedings of the 10th Conference on Computational Natural Language Learning,New York,Jun 8-9,2006.Stroudsburg, USA:ACL,2006:216-220.
[17]Mcdonald R,Crammer K,Pereira F.Online large-margin training of dependency parsers[C]//Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics,Ann Arbor,USA,Jun 25-30,2005.Stroudsburg,USA: ACL,2005:91-98.

LI Ying was born in 1991.She is an M.S.candidate at Kunming University of Science and Technology.Her research interests include natural language processing and syntactic analysis,etc.
李英(1991—),女,河南信阳人,昆明理工大学硕士研究生,主要研究领域为自然语言处理,句法分析等。

GUO Jianyi was born in 1964.She received the M.S.degree from Xi'an Jiaotong University in 1990.Now she is a professor and M.S.supervisor at Kunming University of Science and Technology,and the member of CCF.Her research interests include natural language processing,information extraction,machine learning and pattern recognition,etc.
郭剑毅(1964—),女,河南偃师人,1990年于西安交通大学获得硕士学位,现为昆明理工大学教授、硕士生导师,CCF会员,主要研究领域为自然语言处理,信息抽取,机器学习,模式识别等。

YU Zhengtao was born in 1970.He received the Ph.D.degree from School of Computer Science,Beijing Institute of Technology in 2005.Now he is a professor and Ph.D.supervisor at Kunming University of Science and Technology,and the senior member of CCF.His research interests include natural language processing,information retrieval, machine translation and machine learning,etc.
余正涛(1970—),男,云南曲靖人,2005年于北京理工大学获得博士学位,现为昆明理工大学教授、博士生导师,CCF高级会员,主要研究领域为自然语言处理,信息检索,机器翻译,机器学习等。

MAO Cunli was born in 1977.He received the Ph.D.degree in computer science from Kunming University of Science and Technology in 2013.His research interests include natural language processing,information retrieval,machine translating and machine learning,etc.
毛存礼(1977—),男,2013年于昆明理工大学获得博士学位,主要研究领域为自然语言处理,信息检索,机器翻译,机器学习等。

XIAN Yantuan was born in 1981.He received the M.S.degree in pattern recognition and intelligent system from Shenyang Institute of Automation,Chinese Academy of Sciences in 2006.Now he is a Ph.D.candidate at Kunming University of Science and Technology.His research interests include natural language processing,information extraction,machine translation and machine learning,etc.
线岩团(1981—),男,2006年于中国科学院沈阳自动化研究所获得硕士学位,现为昆明理工大学博士研究生,主要研究领域为自然语言处理,信息抽取,机器翻译,机器学习等。
Constituent-to-Dependency Conversion for Vietnamese*
LI Ying1,GUO Jianyi1,2+,YU Zhengtao1,2,MAO Cunli1,2,XIAN Yantuan1,2
1.School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500,China
2.Key Laboratory of Intelligent Information Processing,Kunming University of Science and Technology,Kunming 650500,China
+Corresponding author:E-mail:gjade86@hotmail.com
Dependency parsing is a key part of the natural language processing.Currently,there are some researches on Vietnamese phrase structure trees,but few on dependency structure treebank.This paper proposes a novel method, which combines the Vietnamese language features and grammatical features,uses the head percolation table as well as statistical machining learning method to convert the Vietnamese phrase structure treebank into a dependency one. Firstly,according to Chinese dependency annotation system and Vietnamese grammar rules,a list of dependencies are developed;Secondly,integrating the characteristics of Vietnamese language,the head percolation table is worked out;Thirdly,using the head percolation table to carry out preliminary conversion;Finally,using dependency tagger to tag dependency.Vietnamese dependency structure treebank increases by training converted treebank with MSTParser tool.The precision of conversion reaches 89.4%.The experimental results show that the proposed method gives a better solution of converting constituent-to-dependency treebank for Vietnamese.
10.3778/j.issn.1673-9418.1603057
A
TP391
*The National Natural Science Foundation of China under Grant Nos.61262041,61363044,61472168(国家自然科学基金);the Key Project of Natural Science Foundation of Yunnan Province under Grant No.2013FA030(云南省自然科学基金重点项目).
Received 2016-02,Accepted 2016-04.
CNKI网络优先出版:2016-04-19,http://www.cnki.net/kcms/detail/11.5602.TP.20160419.1144.010.html
LI Ying,GUO Jianyi,YU Zhengtao,et al.Constituent-to-dependency conversion for Vietnamese.Journal of Frontiers of Computer Science and Technology,2017,11(4):599-607.
Key words:syntactic analysis;head percolation table;phrase structure;dependency structure;treebank
猜你喜欢
通信技术(2021年12期)2022-01-25
红河学院学报(2021年4期)2021-11-19
计算机应用与软件(2019年12期)2019-12-12
长江丛刊(2018年15期)2018-11-15
海峡姐妹(2016年2期)2016-02-27
中文信息学报(2015年6期)2015-04-12
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
