
直推式网络表示学习*
2017-04-17 01:38陈维政谢正茂闫宏飞
计算机与生活 2017年4期
张 霞,陈维政,谢正茂,闫宏飞
北京大学 信息科学技术学院,北京 100871
直推式网络表示学习*
张 霞+,陈维政,谢正茂,闫宏飞
北京大学 信息科学技术学院,北京 100871
网络表示学习是一个经典的学习问题,其目的是将高维的网络在低维度的向量空间进行表示。目前大多数的网络表示学习方法都是无监督的,忽视了标签信息。受LINE(large-scale information network embed-ding)算法启发而提出了一种半监督的学习算法TLINE。TLINE是一种直推式表示学习算法,其通过优化LINE部分的目标函数来保留网络的局部特性。而标签信息部分,则使用线性支持向量机(support vector machine)来提高带标签结点的区分度。通过边采样、负采样和异步随机梯度下降来降低算法的复杂度,从而使TLINE算法可以处理大型的网络。最后,在论文引用数据集CiteSeer和共同作者数据集DBLP上进行了实验,实验结果表明,TLINE算法明显优于经典的无监督网络表示学习算法DeepWalk和LINE。
直推式;网络表示学习;结点分类
1 引言
随着信息技术的迅速发展和互联网的普及,现代社会进入了一个信息爆炸的时代,生活中处处充满着信息。信息之间的关联形成了各种各样的信息网络,例如社交媒体的各种交互形成的社交网络,学术界中论文的引用形成的论文引用网络,还有大众熟悉的万维网(World Wide Web)。网络的基本组成单位是结点,一个结点可以是一个用户、一篇文章,或者是一个网页,网络的边表示不同结点的关系,比如用户间的社交关系、论文间的引用关系以及网页间的链接关系。网络包含的大量有价值的信息有待挖掘。
网络表示学习(network embedding learning)是网络分析和学习的非常重要的一步,它依据相关优化目标,将规模大、维度高的网络映射到一个低维度的空间,用低维度的向量来表示网络中的结点,同时还尽可能地保存原始数据的网络局部特性和全局特性。将网络用低维向量表示之后,就可以进行各种机器学习任务,诸如可视化[1]、结点分类[2]、链接预测[3]等。
本文主要关注的是网络结点分类任务。传统的做法首先将网络进行表示学习,再用分类算法诸如支持向量机(support vector machine,SVM)[4]对表示学习出的向量进行分类,这是一种无监督学习的做法。直观上来看,标签信息是一种网络特性,不应该独立于网络存在。结点所带的标签,反映了结点的不同特质,在某种程度上也反映了结点间的关系。如果在网络进行表示学习的同时,也运用到结点信息,那么对表示结点的真实性质将会大有裨益。
网络的表示学习是一项很有挑战性的研究。一方面,因为真实网络的数据量非常庞大,一个好的表示学习算法,必须能够高效处理大规模的网络。现存的很多网络表示学习算法[1,5-6],在小型网络中效果很好,但由于高计算复杂度,它们难以处理大规模的网络。另一方面,如何将结点的标签信息加入到表示学习的过程中,也是研究的难点。
本文一方面受LINE(large-scale information network embedding)算法的启发,建立目标函数,通过优化目标函数,保留网络结构的局部特性。优化过程中,通过使用异步随机梯度下降(asynchronous stochastic gradient descent,ASGD)、边采样(edge sampling)和负采样(negative sampling)使得算法复杂度大大降低,能够以很小的时间代价对大型网络进行表示学习。另一方面,使用SVM作为分类训练的分类器,在采样边的同时,对边上带标签的结点进行训练,使得该结点的表示学习向量带上分类信息。
最后在CiteSeer和DBLP数据集上进行实验,并将TLINE算法同目前备受关注的无监督算法以及原LINE算法进行比较。实验结果表明,TLINE算法在对网络结点进行表示学习和分类的任务上,效果显著优于其他比较方法,体现了直推式学习的优越性。同时,对TLINE算法做了参数(SVM正则化项系数、LINE和SVM平衡参数)敏感度实验,并找到一组通用参数。
2 相关工作
网络表示学习是在低维度的向量表示空间内,通过对网络结构特性分析,对网络结点进行表示。表示学习的意义是缓解数据稀疏,建立统一的表示空间,实现知识的迁移。
传统的方法,诸如PCA(principal component anal-ysis)和SVD(singular value decomposition),目标都是为了能在低维度空间中尽可能地保留数据集的累计方差。一些著名的表示学习方法,诸如MDS(multidimensional scaling)[5]、LLE(locally linear embedding)[7]、Laplacian Eigenmap[8]和DGE(directed graph embedding)[9]都是基于谱因子分解的算法。传统的方法还有一类是基于概率图模型的表示方法,代表性的算法有Link-PLSA-LDA[10]、RTM(relational topic models)[11]和PLANE(probabilistic latent document network embedding)[12]。然而由于高计算复杂度,使得这一系列算法不能应用于大规模网络。
近来,词向量表示学习方法在自然语言处理领域受到广泛关注,代表算法有Skip-Gram[13]等。受此启发,研究人员提出了一种新的网络表示学习算法,通过对词向量的学习来表示学习网络。在词向量学习任务中输入的是文本语料,而在网络表示学习任务中输入的则是一个网络,看上去这是两个毫不相关的任务。DeepWalk[14]的出现将这两者联系起来。观察到在文本语料中,词语出现的频率服从幂律分布,而如果在网络上进行随机游走,结点被访问到的次数也服从幂律分布。因此DeepWalk把结点作为一种人造语言的单词,通过在网络中进行随机游走获得随机游走路径。把结点作为单词,把随机游走路径作为句子,这样获得的数据就可以直接作为word2vec算法的输入以训练结点的向量表示。
受到文本表示学习的启发而产生的DeepWalk,开拓了网络表示学习的新思路。由于对网络缺少整体的把握,DeepWalk依据随机游走而获得的训练数据,会损失掉部分的网络结构信息,因此训练出来的效果还是不够理想。唐建等人提出的LINE[15],则直接建模了网络的一阶和二阶的结构信息。
然而,DeepWalk和LINE都是无监督模型,未能对结点标签信息进行有效利用。事实上,标签信息在网络数据中十分常见,不含标签信息的模型对于表示学习结果的区分度十分有限。为了对标签信息进行有效利用,半监督学习方法应运而生。LSHM(latent space heterogeneous model)[16]和MMDW(maxmargin DeepWalk)[17]即是其中两种代表算法。LSHM通过学习结点的向量表示和训练标签的分类函数来学习模型。该算法一方面考虑到网络结构边的特性,认为相邻结点的标签尽可能地相似,另一方面考虑了分类函数对已知标签的预测能力。MMDW采用一种基于矩阵分解的算法对网络结构进行建模,这导致了极大的空间复杂度,因此MMDW依然不适用于规模较大的网络。
通过对LINE和SVM的权衡,本文提出的TLINE算法既对结点的标签信息进行了充分利用,又同时适用于大规模的网络表示学习的任务。
3 模型与实现
3.1 大规模网络表示学习
两个结点之间的边所表示的是网络的局部特性,边的权重常常预示着两个结点在真实世界的相似度。比如说,在社交网络中,两个人如果是朋友,他们极有可能有着相似的兴趣爱好。再比如说,在万维网中指向彼此的链接往往有着相似的话题。唐建等人在LINE[15]论文中对局部特性进行如下表示,对于每一个无向边(i,j),定义关于点vi和vj的联合分布:
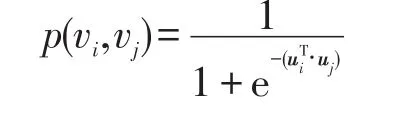
ui∈Rd是结点vi在d维空间的表示向量。此时再定义经验分布函数如下:
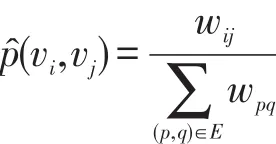
为了保存网络的局部特性,需要优化以下函数:
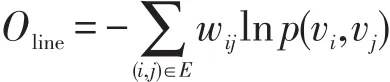
省略一些常数项,可以得到:
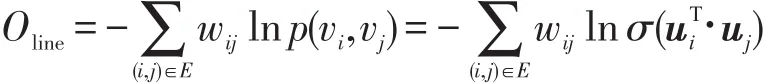
这里,σ指代的是sigmoid函数。Oline通过最小化目标函数,可以得到|v|个结点的对于网络局部特性学习得出的表示学习向量{ui}i=1…|v|。
3.2 基于SVM的分类
对于一个二元分类问题,线性分类器是对于输入空间中将实例划分为正负两类的分离超平面:在超平面的一侧的所有点都被分类为“是”,另一侧的则为“否”。线性支持向量机在二分类问题上可以转化为如下的最优化问题:
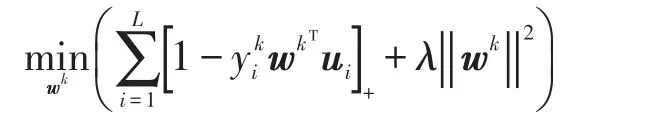
二分类问题只是多分类问题中的一个特例,而多分类问题更为普遍。也可以把上式扩展到多分类的问题上,得到新的目标函数:
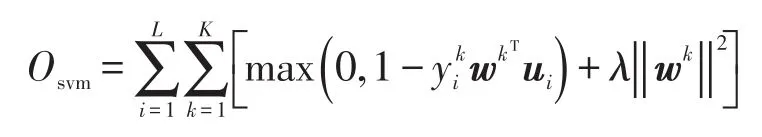
3.3 直推式网络表示学习
给定一个网络图结构,图上的部分结点带有分类信息,任务是要能够对还没有进行分类的结点进行分类。传统的表示学习和分类算法,分为两步进行,如图1所示。首先将每个结点映射到低维空间,即表示学习,然后再在这低维空间中,将带分类信息的结点作为训练集,剩下的作为测试集。用训练集的表示学习向量来训练分类器,最后对测试集进行分类判定输出。
直推式表示学习是一种半监督学习算法。在学习过程中,使用较少的有标签样本和较多的无标签样本进行学习。其与传统的学习分类算法不同之处在于,在这种混合样本的学习过程中,测试集的样本分布信息从标签样本转移到最终的分类器和无标签样本中。如图2中,图的表示学习和分类器的训练是同时进行的,这样的学习方式,使得在学习结点的表示向量的过程中,将结点的分类信息也涵盖进来。表示学习和分类的过程相互影响,使得结点的分类信息变成了图表示学习结果的一部分,而结点的表示学习向量也同样影响着分类器的参数。这样一来,结点的表示学习结果含义更为丰富,情况也更有针对性,有助于最后对无标签结点的分类。
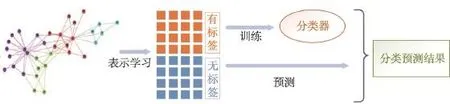
Fig.1 Traditional unsupervised embedding learning and classification图1 传统无监督表示学习和分类
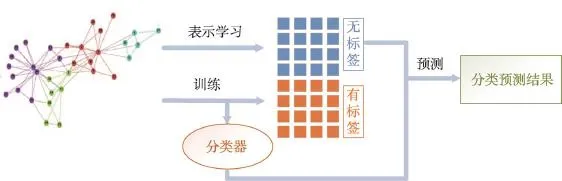
Fig.2 Transductive embedding learning and classification图2 直推式表示学习和分类
为了更好地表示网络结构的局部特性,同时提高分类的效果,本文把在网络表示学习中效果显著的LINE算法和著名的支持向量机分类算法结合起来,用直推式表示学习的方式对网络进行表示学习,即是说:
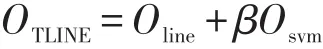
β是平衡LINE和SVM的比例参数。
对Oline和Osvm,采用负采样优化,代入上式,最后得到的TLINE目标函数如下:
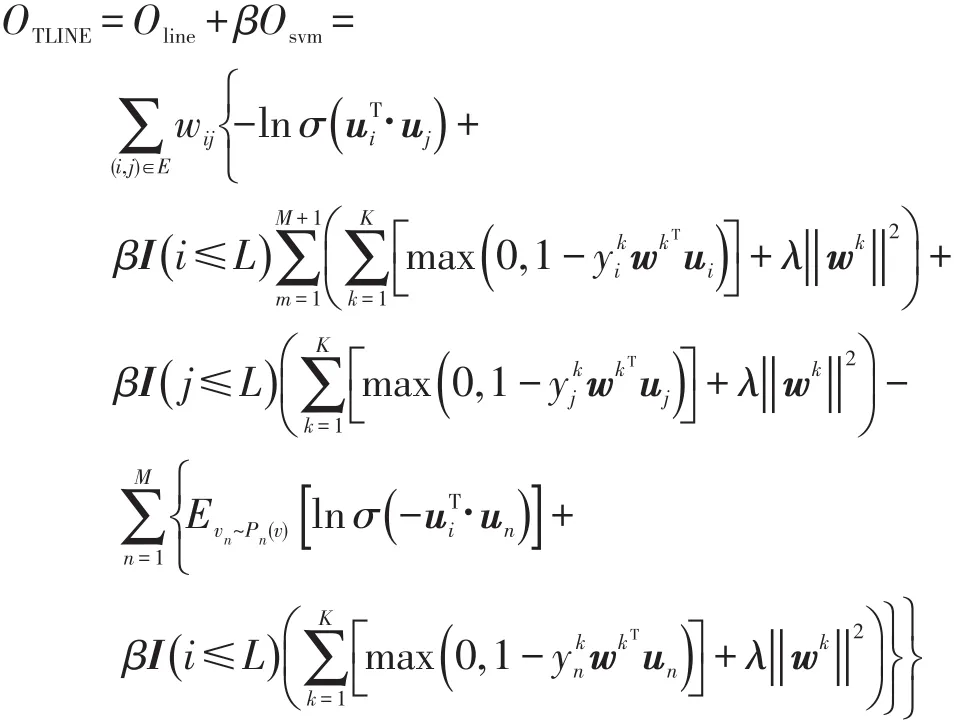
本文使用异步随机梯度下降算法来最优化目标函数。随机梯度下降是最小化损失函数的一种常用方法,其每次优化对应的是训练集中每个样本,与之相对的批量梯度下降,对应的则是所有样本。虽然随机梯度下降算法中,并不是每次迭代损失函数都是向着全局最优的方向,但是大的整体方向却是向着全局最优解进行,其结果也往往临近全局最优解。使用随机梯度下降,不仅算法复杂度相对较低,同时还可以一定程度上避免过拟合问题。在图的梯度下降中,还需要关注的问题是要找到一个合适的学习速率。
4 实验结果与分析
4.1 数据集
本文研究的是网络上的表示学习和分类,因此数据既要有网络信息,也需要部分结点带有分类标签信息。本次实验的数据集有两个,一个是取自论文max-margin DeepWalk[17]中的CiteSeer网络,另一个是论文LINE[15]中的DBLP网络。
(1)CiteSeer网络的边没有权重,包含3 324个结点,4 732条边,以及6个分类。CiteSeer(又名Research-Index)是NEC研究院在自动引文索引(autonomous citation indexing,ACI)机制的基础上建设的一个学术论文数字图书馆。CiteSeer引文索引系统提供了一种通过引文链接检索文献的方式,目标是从多方面促进学术文献的传播和反馈。该数据集以论文为结点,论文的引文链接为边,形成一个引文网络。
(2)DBLP是一个带权重的网络,其边的权重代表两个作者合作的论文数量。DBLP网络有18 058个结点,103 011条边,以及3个分类。论文LINE[15]中作者提到,数据来自3个不同的研究领域:数据挖掘领域的WWW、KDD会议,机器学习领域的NIPS、ICML会议,计算机视觉领域的CVPR、ICCV会议。网络是根据在这些会议上发布的论文进行构建的,因为这3个领域彼此之间非常详尽,所以将这3个类别进行区分十分有挑战性。
4.2 比较方法
为了验证TLINE算法的性能,本文用以下3个算法在DBLP和CiteSeer两个数据集上进行效果比较。
(1)DeepWalk[14]:DeepWalk算法是无监督的网络表示学习算法,由Perozzi于2014年提出,首次将深度学习引入到网络表示学习中。DeepWalk算法在网络图上进行随机游走,将随机游走的路径当成特殊的句子并应用于语言模型上,学习出网络结点的向量表示形式。实验中将DeepWalk的参数取如下值:滑动窗口大小w=10,结点序列长度t=40,每个结点对应的结点序列数量γ=80。
(2)LINE[15]:唐建提出的LINE算法。LINE和TLINE算法,均在CiteSeer实验中取样5万条边,在DBLP实验中取样50万条边。
(3)TLINE:本文提出的算法。参数设置为β=0.5,λ=0.02,表示向量的空间维度为10。
4.3 分类任务实验结果
本文实验了测试集占总数据集10%到90%的情况,对于DeepWalk和LINE算法,在得到结点的表示向量之后,使用SVM算法对结点进行分类。本次实验使用微平均Micro-F1作为衡量标准,取10次实验平均后的结果。在CiteSeer数据集和DBLP数据集上进行测试,表1和表2是实验结果,标黑的数据是实验中得到的最好结果。可以观察到以下现象:

Table 1 Micro-F1 of node classification on CiteSeer dataset表1 CiteSeer数据集上结点分类的微平均Micro-F1 %

Table 2 Micro-F1 of node classification on DBLP dataset表2 DBLP数据集上结点分类的微平均Micro-F1 %
(1)在大多数实验中,直推式网络表示学习算法实验结果都比无监督网络表示学习算法的效果更好。就LINE和TLINE算法进行比较,TLINE算法在CiteSeer和DBLP上平均有7%和6%的提高。这说明标签信息对于表示学习有很重要的意义。
(2)TLINE算法对于另外两个算法有明显的优势,并且优势随着训练集比例的增大而增大。
4.4 参数敏感度实验
对于LINE和SVM平衡参数β和SVM正则化项系数λ,本文在CiteSeer数据集和DBLP数据集上对参数进行了联合分析,结果如图3和图4所示。
在CiteSeer数据集上,λ取值从0.001到10,β取值从0.001到10。随λ的增加微平均Micro-F1先略微增加,然后再减少。此数据集在λ为0.1,β为0.1到1附近取得最好结果。在DBLP数据集上,在β取值为0.001到1的情况下,λ在很大的一个范围内参数不敏感。因为扩大了参数训练的力度,可以发现在 β和λ取值较大的情况下,微平均显示训练结果很不好,且趋于一个常数。通过对 β和λ的敏感度组合训练,可以发现,两者具有一定的相关性,但在β获得较好取值的情况下,λ参数更不敏感。
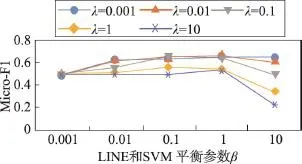
Fig.3 Parameterβandλsensitivity research of TLINE on CiteSeer dataset图3 TLINE在CiteSeer数据集上β和λ的组合敏感度实验
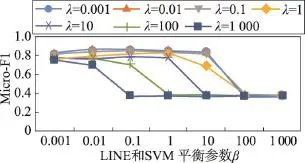
Fig.4 Parameterβandλsensitivity research of TLINE on DBLP dataset图4 TLINE在DBLP数据集上β和λ的组合敏感度实验
本文经过参数组合训练,为了能够在两个数据集上都达到较好效果,分类任务实验中取 β=0.5,λ=0.02。
5 总结和展望
本文学习LINE算法的思想对网络结构局部特性加以利用,同时利用标签信息对网络进行直推式表示学习。已有的表示学习算法大部分只能处理小数据集,并且没能将网络的标签属性很好地结合到网络的表示学习中。受LINE算法的启发,为了保持网络结构的局部特性,在TLINE算法中同样利用了两结点之间的边权重,来表示两个结点在低维空间表示学习出的向量相似度。然后在标签信息方面,使用线性支持向量机提高带标签结点的可区分度,间接影响了无标签结点的向量表示结果。最后,通过在CiteSeer论文引用数据集和DBLP共同作者数据集上的实验,可以看出,对于结点分类任务,TLINE算法的结果明显优于经典的无监督网络表示学习算法(DeepWalk和LINE)。
在今后的工作中,将放眼网络的全局特性而非单独的局部特性,来对网络进行表示学习。同时,把同构网络的学习算法扩展到更为普遍的异构网络,以及使用深度学习技术进一步优化分类算法,都是很有挑战性的研究方向。
[1]Tang Jian,Liu Jingzhou,Zhang Ming,et al.Visualizing largescale and high-dimensional data[C]//Proceedings of the 25th International Conference on World Wide Web,Montreal,Canada,Apr 11-15,2016.NewYork:ACM,2016:287-297.
[2]Yang Zhilin,Cohen W,Salakhutdinov R.Revisiting semisupervised learning with graph embeddings[C]//Proceedings of the 33rd International Conference on Machine Learning, New York,Jun 19-24,2016.Red Hook,USA:Curran Associates,2016:86-94.
[3]Tang Jie,Lou Tiancheng,Kleinberg J,et al.Transfer link prediction across heterogeneous social networks[J].ACM Transactions on Information Systems,2015,9(4):1-42.
[4]Suykens J A K,Vandewalle J.Least squares support vector machine classifiers[J].Neural Processing Letters,1999,9(3): 293-300.
[5]Cox T F,Cox M A A.Multidimensional scaling[M].Boca Raton,USA:CRC Press,2000:123-141.
[6]Tenenbaum J B,de Silva V,Langford J C.A global geometric framework for nonlinear dimensionality reduction[J].Science,2000,290(5500):2319-2323.
[7]Roweis S T,Saul L K.Nonlinear dimensionality reduction by locally linear embedding[J].Science,2000,290(5500): 2323-2326.
[8]Belkin M,Niyogi P.Laplacian eigenmaps and spectral techniques for embedding and clustering[C]//Proceedings of the 14th International Conference on Neural Information Processing Systems:Natural and Synthetic,Vancouver,Canada, Dec 3-8,2001.Cambridge,USA:MIT Press,2001:585-591.
[9]Chen Mo,Yang Qiong,Tang Xiaoou.Directed graph embedding[C]//Proceedings of the 20th International Joint Conference on Artificial Intelligence,Hyderabad,India,Jan 6-12, 2007.San Francisco,USA:Morgan Kaufmann Publishers Inc,2007:2707-2712.
[10]Nallapati R,Cohen W W.Link-PLSA-LDA:a new unsupervised model for topics and influence of blogs[C]//Proceedings of the 2nd International Conference on Weblogs and Social Media,Seattle,USA,Mar 30-Apr 2,2008.Menlo Park,USA:AAAI,2008:84-92.
[11]Chang J,Blei D M.Relational topic models for document networks[C]//Proceedings of the 12th International Conference on Artificial Intelligence and Statistics,Clearwater Beach,USA,Apr 16-18,2009.Cambridge,USA:JMLR, 2009:81-88.
[12]Le T M V,Lauw H W.Probabilistic latent document network embedding[C]//Proceedings of the 2014 International Conference on Data Mining,Shenzhen,China,Dec 14-17, 2014.Washington:IEEE Computer Society,2014:270-279.
[13]Le Q,Mikolov T.Distributed representations of sentences and documents[C]//Proceedings of the 31st International Conference on Machine Learning,Beijing,Jun 21-26,2014. Red Hook,USA:CurranAssociates,2014:2931-2939.
[14]Perozzi B,Al-Rfou R,Skiena S.Deepwalk:online learning of social representations[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,New York,Aug 24-27,2014.NewYork:ACM,2014:701-710.
[15]Tang Jian,Qu Meng,Wang Mingzhe,et al.LINE:largescale information network embedding[C]//Proceedings of the 24th International Conference on World Wide Web, Florence,Italy,May 18-22,2015.New York:ACM,2015: 1067-1077.
[16]Jacob Y,Denoyer L,Gallinari P.Learning latent representations of nodes for classifying in heterogeneous social networks[C]//Proceedings of the 7th ACM International Conference on Web Search and Data Mining,New York,Feb 24-28,2014.New York:ACM,2014:373-382.
[17]Tu Cunchao,Zhang Weicheng,Liu Zhiyuan,et al.Max-margin DeepWalk:discriminative learning of network representation[C]//Proceedings of the 25th International Joint Conference on Artificial Intelligence,New York,Jul 9-15,2016. Menlo Park,USA:AAAI,2016:3889-3895.

ZHANG Xia was born in 1994.She is an M.S.candidate at Peking University.Her research interests include machine learning and network embedding.
张霞(1994—),女,四川遂宁人,北京大学硕士研究生,主要研究领域为机器学习,网络表示学习。

CHEN Weizheng was born in 1990.He is a Ph.D.candidate at Peking University.His research interests include machine learning and social network analysis.
陈维政(1990—),男,山东济宁人,北京大学博士研究生,主要研究领域为机器学习,社会网络分析。

XIE Zhengmao was born in 1978.He received the M.S.degree in computer science from Peking University in 2003.Now he is a research assistant at Peking University.His research interests include distributed system,Web information crawling and large data.
谢正茂(1978—),男,湖南洞口人,2003年于北京大学获得硕士学位,现为北京大学信息学院助理研究员,主要研究领域为分布式系统,Web信息爬取,大数据。

YAN Hongfei was born in 1973.He received the Ph.D.degree in computer science from Peking University in 2002.Now he is an associate professor at Peking University.His research interests include information retrieval and distributed computing.
闫宏飞(1973—),男,黑龙江哈尔滨人,2002年于北京大学获得博士学位,现为北京大学副教授,主要研究领域为信息检索,分布式计算。发表学术论文50多篇,作为负责人承担国家自然科学基金、核高基项目、863计划等。
Learning Transductive Network Embedding*
ZHANG Xia+,CHEN Weizheng,XIE Zhengmao,YAN Hongfei
School of Electronics Engineering and Computer Science,Peking University,Beijing 100871,China
+Corresponding author:E-mail:zhangxia9403@gmail.com
Network embedding is a classical task which aims to project a network into a low-dimensional space. Currently,most of existing embedding methods are unsupervised algorithms,which ignore useful label information. This paper proposes TLINE,a semi-supervised extension of LINE(large-scale information network embedding) algorithm.TLINE is a transductive network embedding method,which optimizes the loss function of LINE to preserve local network structure information,and applies SVM(support vector machine)to max the margin between the labeled nodes of different classes.By applying edge-sampling,negative sampling techniques and asynchronous stochastic gradient descent algorithm in the optimizing process,the computational complexity of TLINE is reduced, thus TLINE can handle the large-scale network.To evaluate the performance in node classification task,this paper tests the proposed methods on two real world network datasets,CiteSeer and DBLP.The experimental results indicate that TLINE outperforms the state-of-the-art baselines and is suitable for large-scale network.
transductive;network embedding learning;node classification
10.3778/j.issn.1673-9418.1611073
A
TP391
*The National Natural Science Foundation of China under Grant Nos.61272340,U1536201(国家自然科学基金);the National Basic Research Program of China under Grant No.2014CB340400(国家重点基础研究发展计划(973计划)).
Received 2016-11,Accepted 2017-01.
CNKI网络优先出版:2017-01-16,http://www.cnki.net/kcms/detail/11.5602.TP.20170116.1702.010.html
ZHANG Xia,CHEN Weizheng,XIE Zhengmao,et al.Learning transductive network embedding.Journal of Frontiers of Computer Science and Technology,2017,11(4):520-527.
猜你喜欢
电子制作(2022年1期)2022-01-28
四川大学学报(自然科学版)(2021年6期)2021-12-27
电子制作(2021年14期)2021-08-21
唐山师范学院学报(2018年6期)2018-12-25
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
文苑(2015年9期)2015-09-10
少儿科学周刊·少年版(2015年2期)2015-07-07
新课程学习·中(2013年3期)2013-06-14
