
融合马尔可夫聚类的实体间关系消解方法*
2017-04-17 01:38:53常雨骁贾岩涛林海伦王元卓刘春阳
计算机与生活 2017年4期
常雨骁,庞 琳,贾岩涛,林海伦,2,王元卓,刘 悦,刘春阳
1.中国科学院 计算技术研究所 网络数据科学与技术重点实验室,北京 100190
2.中国科学院大学,北京 100049
3.国家计算机网络应急技术处理协调中心,北京 100029
融合马尔可夫聚类的实体间关系消解方法*
常雨骁1,2+,庞 琳3,贾岩涛1,林海伦1,2,王元卓1,刘 悦1,刘春阳3
1.中国科学院 计算技术研究所 网络数据科学与技术重点实验室,北京 100190
2.中国科学院大学,北京 100049
3.国家计算机网络应急技术处理协调中心,北京 100029
随着面向网络大数据的知识库的不断出现,它们各自都包含海量的实体以及实体间的关系。然而许多有相同含义的关系并没有统一名称,针对这种情况,提出了一种基于马尔可夫聚类(Markov cluster algorithm,MCL)的实体间关系融合方法。该方法首先计算关系间的语义相似度,然后利用关系间的语义相似度作为有边的权重,构建无向图,并利用马尔可夫聚类算法进行聚类。实验表明,该方法相比层次聚类和k-means聚类方法在聚类纯度上有一定提高,并且更加方便使用。
马尔可夫聚类;知识库;实体间关系
1 引言
近年来,随着互联网、云计算等IT技术的不断发展,网络数据快速增长,网络大数据给传统的信息处理方式带来了挑战[1]。当然,大数据也带来了更多机遇,因为大数据中包含着大量知识,其信息量远远超过纸质书籍。然而,机器要理解大数据中的知识并不容易,正如人类在学习新语言时需要“背单词”一样,机器也需要一本“字典”,因此需要构建一个“知识库”来存放静态知识,这些知识包括命名实体以及实体间关系,实体包括人、地点、机构等,关系则多种多样,如父母、同学、同事等。这些知识以三元组的形式表示,三元组(S,P,O)作为知识的基本表示形式,其中S代表主体,P是客体,O是二者之间的某种关系,本文简称关系。一个简单的三元组例子,如(美国,总统,奥巴马),其中美国、奥巴马是两个实体,总统是二者间关系。
当前比较知名的知识库有DBpedia、Freebase等,其中DBpedia包含1 900万实体和1亿关系,Freebase包含6 800万实体和10亿关系[2]。表面上看,知识库中的关系数量巨大,但实际上有相当数量的关系只是名字不同意思相同,却被当作两种不同关系,如“父亲爸爸家父”都表示“父亲”的意思,但字面不完全一致,可能被当作不同关系,因此需要对同义但不同名称关系进行消解。关系消解就是对不同关系的同义性进行判定,将同义不同名的关系进行对齐,映射到相同的标签。关系消解可以提升知识库整体数据质量,方便后续计算,如利用实体间关系进行推理,发掘实体间隐含关系等。
关系的消解实际是短文本的合并,现有的短文本合并方法主要有两类:一类是基于聚类的方法。通过聚类算法将语义相似的短语聚合到同一簇中,达到消解的目的。另一类是分类的方法。分类方法需要事先确定短语的种类,然后对每一类短语准备训练数据,通常需要大量人工标注,提取每类关系的特征,包括词语本身特征、上下文特征等,然后训练分类器再利用分类器将关系打上标签,最后达到合并的目的。聚类和分类方法都各有优缺点:分类方法的优势是只要训练数据质量好,一般分类结果准确率较高,但缺陷是必须预先确定或估计出最终关系的种类,然后进行特征提取模型训练,而当有新型关系出现时则无法处理了。另外分类方法容易出现过拟合现象,对不同数据集有不同的效果。聚类方法的优点是不需要大量人工标注,易于实施,但缺点是聚类结果受阈值、簇合并策略影响较大。另外聚类方法时间开销较大,分类方法只有模型训练的时间开销较大,但后续计算时间开销不大。
在分析分类算法、聚类算法的各种优缺点后,本文提出了一种“基于马尔可夫聚类的实体间关系消解方法”。马尔可夫聚类(Markov cluster algorithm,MCL)是一种基于图的聚类算法。该算法由Dongen[3]提出。
具体的讲,本文的创新点是提出了融合词法和语义的相似度计算方法,然后给出了基于MCL的关系聚类方法。该方法与层次聚类方法相比,聚类纯度指标有了一定提高,在两种聚类算法簇数相同的情况下,在不同规模数据集上,MCL聚类纯度平均能够提高7%、20%。
本文组织结构如下:第2章介绍相关工作;第3章研究中文短语语义相似度计算;第4章讨论基于MCL的关系融合方法;第5章是实验和评价;第6章总结全文。
2 相关工作
关系消解通常采用基于短文本的分类和聚类两大类方法。基于分类的关系消解方法的代表性工作有文献[4-6]。例如范小丽等人在文献[4]中针对语料集不平衡情况下分类效果差的问题,通过调整正相关和负相关互信息特征的比例,区分相关特征,给出了改进的互信息特征选择方法,提高了分类效果。在文献[5]中,台德艺等人为了提高在同类中频繁出现,类内均匀分布的具有代表性的特征词的权重,引入了特征词分布集中度系数改进IDF函数,用分散度系数进行加权,提出了TF-IIDF-DIC权重函数,在实验中证明了基于TF-IIDF-DIC的K-NN文本分类算法宏平均比基于TF-IDF的算法提高了6.79%。
基于聚类的关系消解方法的代表性工作有文献[7-11]。在文献[7]中,Song等人为了解决在缺少上下文时短文本语义难以理解的问题,通过使用一个包含大量概念的知识库,提升了算法对短文本的理解能力,开发了一个贝叶斯推理机制来概念化单词和短文本,在聚类实验中提升了聚类效果。在文献[8]中,Yates等人提出了一种领域无关并且基于无监督学习的关系消解方法。此方法通过概率模型计算关系之间以及包含关系的断言式之间的相似度,依据相似度将具有相同含义的关系聚合在同一簇中,在TREC语料集上,此方法取得了97.3%的准确率和94.7%的召回率。在文献[9]中,金春霞等人针对中文短文本特征词词频低,存在大量变形词的特点提出了一种基于《知网》扩充相关词集构建动态文本向量的方法,利用动态向量计算中文短文本的内容相似度,提升了聚类效果。
总的来说,若采用基于分类的关系消解方法需要事先知道类别种类,然后选择合适的特征训练分类器,当特征选择不恰当的时候,分类效果就会有所下降。基于聚类的关系消解方法在计算关系之间的语义相似度时,如何快速、简单地计算语义相似度并且得到高质量聚类结果是一个问题。
针对上述情况,本文提出了基于马尔可夫图聚类的关系消解方法,并且给出了一种基于《同义词词林》的中文短语语义相似度计算方法。通过在不同规模数据集上实验,证明了本文方法与传统层次聚类方法相比,在聚类结果簇数相同时,纯度有所提升。
3 词语相似度计算
词语相似度是两个中文短语语义相似性的度量值,本文在利用MCL方法进行词语聚类时,也需要计算词语相似度。本文采用的是基于语义字典的词语相似度计算方法,语义词典选择的是《同义词词林》,本文主要介绍词语相似度计算。
3.1 同义词词林
《同义词词林》由梅家驹等人于1983年编纂而成,这本词典不仅包含了一个词语的同义词,也包含了一定数量的同类词,即广义的相关词[12]。哈尔滨工业大学利用众多词语相关资源,完成了一部具有汉语大词表的同义词词林扩展版。同义词词林扩展版收录词语近7万条,全部按意义进行编排。本文的词语相似度计算使用同义词词林扩展版本。
《同义词词林》按照树状层次结构把所有收录的词条组织到一起,把词汇分成大、中、小3类,小类下有很多词群,词群又进一步分成若干行。《同义词词林》共提供了5层编码:第1级用大写英文字母表示;第2级用小写英文字母表示;第3级用二位十进制整数表示;第4级用大写英文字母表示;第5级用二位十进制整数表示。如“Aa01C01=众人人人人们”,称Aa01C01是“众人”的一个义项,具体编码如表1所示。
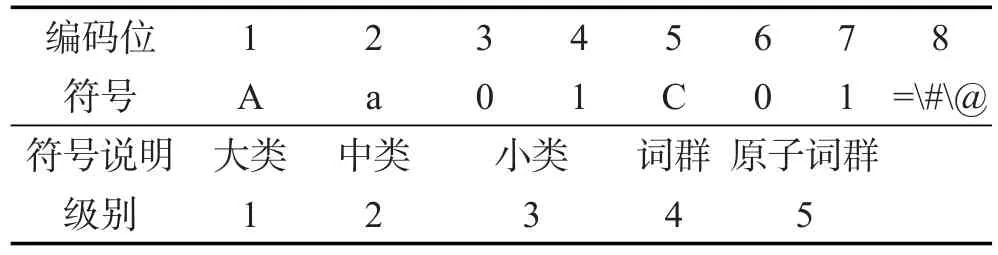
Table 1 Thesaurus dictionary encode表1《同义词词林》词语编码表
表1中的编码位是从左到右排列,第8位的标记有3种,分别是“=”、“#”、“@”。其中“=”代表“相等”、“同义”;“#”代表“不等”、“同类”,属于相关词语;“@”则表示“独立”,即表示它在词典中既没有相关词,也没有同义词。
由于汉语词语在不同语境下有不同语义,《同义词词林》的编写者也考虑到了这点,在《同义词词林》中一个汉语词语可能对应多种不同编码,称词语的每种编码方式为词语的一个义项。本文用sim(a,b)表示两个义项或两个词语a和b的相似度。具体计算方法将在下节给出。
3.2 相似度计算
本节主要介绍如何基于《同义词词林》计算汉语短语语义相似度。首先介绍义项相似度计算方法,然后介绍短语相似度计算方法。
3.2.1 义项相似度计算
前文介绍了《同义词词林》的编码方式,义项相似度计算主要是对两个编码进行比较,并得出计算结果,下面分几种情况进行介绍。
第一种情况,当两个义项编码完全一致,但是编码最后一位是“#”时,代表两个义项是同类词语,但意思不相同。如义项“Ab04A03#”有两个词语“女婴”、“男婴”,二者是同类词语,但是意思不完全一致,这种情况下,将二者相似度记为0.5。
第二种情况,某一个义项以“@”结束,则表明此义项是独一无二的,没有同义词,将这个义项和其他任何义项的相似度记为0。
第三种情况,两义项a、b不完全一致,只有部分相同,则通过式(1)计算:

其中,i的取值为[1,5],表示两个义项在第i层开始不同。举一个简单例子说明:
Ad03A01=本地人当地人土著土人土著人
Ad03A02=村里人全村人
Ad03A03@家里人
以计算“本地人”的义项“Ad03A01”和“村里人”的义项“Ad03A02”的相似度为例,因为两个义项在第5级出现不同,所以
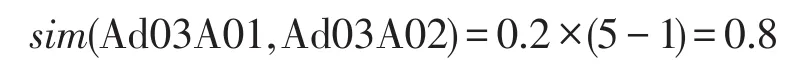
在一词多义的情况下,以两个词最相近的义项的相似度作为两个词的相似度。如词语“认真”有两种意思,既可以形容人做事情认真仔细,也可以形容某人对于某事当真、信以为真。《同义词词林》本身考虑到了这种情况,“认真”在词林中有两个义项,分别是Ee27A01和Gb14A04,因此在计算时,用最相似的义项之间的相似度作为两个词的相似度,如算法1所示。
算法1计算两个词语的相似度
输入:两个中文词语A、B
输出:A和B的语义相似度sim(A,B)
1.如果A或B在《同义词词林》中没有出现,sim(A, B)=0
2. 找出A的所有义项,记为{a1,a2,…,am}
3. 找出B的所有义项,记为{b1,b2,…,bn}
4. sim(A,B)=0
5. For i from 1 to m
6. For j from 1 to n
7. 利用式(1)计算sim(ai,bj)
8. if(sim(ai,bj)>sim(A,B))sim(A,B)=sim(ai,bj)
9. End for
10. End for
11. 返回sim
算法1只能计算两个都在《同义词词林》中出现过的词语,如果某个词语没有在《同义词词林》中出现,则它与任何其他词语的相似度都记为0。
3.2.2 短语相似度计算
上文介绍了义项相似度计算方法,这里将进一步介绍短语相似度的计算方法。《同义词词林》只是包含了部分基本词语的义项,而很多常见名词性短语在《同义词词林》中是没有的,这就需要新的方法计算相似度。
对于任意两个中文短语A、B,利用分词工具进行分词并去除虚词“的”“地”“得”等,分别得到短语A分词后的词序列a1a2…,an和短语B分词后的词序列b1b2…,bn。首先通过式(3)定义两个相同长度词序列的相似度,记两个词序列分别为Seq1、Seq2,其中Seq1=a1a2…an,Seq2=b1b2…bn。
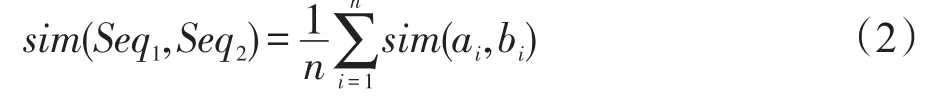
其中,sim(ai,bi)的计算可参照式(1)。
式(2)的两个词序列Seq1、Seq2必须是等长的,ai、bi是两个词,进一步的,利用算法2计算两个短语A、B的语义相似度。
算法2计算两个短语的相似度
输入:两个中文短语A、B
输出:语义相似度
1.对A、B分别进行分词得到两个词序列seqA、seqB
2.记len为length(seqA)和length(seqB)最小的一个
3.从seqA取出len个词,枚举这些词的一个排列S1
4.从seqB取出len个词,枚举这些词的一个排列S2
5.if(sim(S1,S2)>max)max=sim(S1,S2)
6.重复3~5直到枚举完所有可能的组合
7.返回max
在算法2中,利用ICTCLAS分词工具进行中文分词,通过算法2,可以计算任意两个中文短语的相似度。
4 基于马尔可夫聚类的关系融合算法
马尔可夫聚类算法(MCL)是一种基于图的聚类算法。它首先将要聚类的元素表示成赋权图[13],图中的点是聚类元素,图中的边通过计算元素间的相似度得到。具体地,当两个元素间的相似度为0时,其在图中对应的点之间没有边相连。否则,这两个元素对应的点之间存在一条边,其权重等于二者的相似度。
4.1MCL背景介绍
MCL图聚类是基于图的聚类算法,一般聚类算法是将聚类对象看作是高维空间内的点,通过一系列运算,将高维空间内的点划分成若干簇,使得同一簇内各点之间的距离较近,而不同簇间各点距离较远。图聚类算法则是将聚类对象看成是一个有向图或无向图,目标是将图内点聚成若干簇,使得一个漫游者从簇内的某个点“出发”,那么到达同一簇内点的概率大于到达簇外点的概率。通过在图上进行随机游走过程,就可以发现在图的某些区域边是比较密集的,可以聚成一簇。MCL通过计算马尔可夫链实现在图上进行随机游走。
MCL算法主要有两个过程,分别是扩展(expansion)和膨胀(inflation),这两个过程都是对状态转移矩阵进行操作。记一个状态转移矩阵为M,M的维数就是图中点的个数,M不一定是对称矩阵,M中的每一列表示某一时刻从某一个点出发,下一时刻到达其余点各自的概率。
扩展过程是模拟随机游走过程,即取正整数e,对当前状态转移矩阵自乘e次,得到新的状态转移矩阵,这一过程相当于在原状态转移矩阵上进行了一次e步的随机游走。例如一个只有两个定点的图,状态转移矩阵,状态转移矩阵中第i列第j行的元素表示如果漫游者当前从顶点i出发,则下一时刻他出现在顶点j的概率,状态转移矩阵的每列的和为1。假设旅行者在第0时刻从顶点1出发,则第2时刻,他仍然出现在顶点1的概率是0.6×0.6+0.4× 0.2=0.44。同理也可以得到他出现在其他顶点的概率,此时状态转移矩阵。
膨胀过程是一个矩阵规则化过程,是对状态转移矩阵的各列进行规则化,其处理公式如式(3)所示:

其中,M是状态转移矩阵;M*是规则化得到的矩阵;τ是松弛系数;k是M的行数;p是行下标;q是列下标。式(3)的作用是把转移矩阵的列进行规则化得到规则化矩阵M*。例如当τ=2时,向量经过式(3)规则化的结果是。
4.2 基于MCL的关系融合算法
4.1节介绍了MCL算法的相关背景,本文主要工作是利用MCL图聚类算法,解决关系融合问题,如算法3所示。
算法3基于MCL的关系融合算法
输入:关系集合{r1r2…rn},θ,τ
输出:关系簇的集合{C1C2…Cm}
1.令n为关系集合中关系的个数
构造图G,G的邻接矩阵为Mn×n
初始化邻接矩阵Mn×n为对角形矩阵,其中对角线上元素都为1
2.For i from 1 to n
3.For j from i+1 to n
4.ifsim(ri,rj)>= θ Mij=sim(ri,rj)
5.elseMij=0
6.End if
7.End for
8.End for
9. 在M上进行一次随机游走,并用松弛系数τ规则化,得到M′
10. if||M-M′||2<0.05break
11.M=M′
12.repeat 9~11
13.使用广度优先遍历计算图G的每个连通分支,每个连通分支都是一个关系簇
14.返回所有关系簇
算法3中输入是一系列关系,如“父亲”、“爸爸”、“儿子”、“妈妈”等,输出结果格式为每行是一个结果簇,包含若干关系,用空格分开。本文通过设定相似度过滤系数θ对相似度矩阵M的数据进行过滤,这样做可以有效降低噪声。因为有些关系如“儿子”和“兄弟”肯定是不同的关系,但是通过前文所述的语义相似度计算,两者相似度并不会等于0,也就是在图上“儿子”和“兄弟”两个节点之间会产生一条边,虽然这条边权重不高,但是还是会给MCL的扩展过程带来干扰。因此通过设定过滤系数直接把一些较低的相似度去掉,这样可以有效提升结果质量。
为了保证可靠性,利用Dongen开发的开源工具[14]运行9~13行的MCL过程。Dongen在开发文档中提到松弛系数τ将会对聚类簇数产生主要影响,因此在实验中主要调节松弛系数τ和相似度过滤系数θ。
5 实验和结果
本文给出不同聚类方法进行比较。首先介绍本实验采用的两个关系消解数据集和实验的评价指标等。然后给出不同聚类方法在关系消解数据上的实验结果和分析。
5.1 实验准备
本文主要探讨的是MCL图聚类算法在关系融合上的效果。实验数据集是从公开采集的百度百科页面抽取得到的一系列形容人与人之间关系的短语,如“父亲”、“母亲”、“兄弟”等,并且通过人工标注,得到了其中200个关系的消解结果。通过人工标注,把这200个关系总共分成了34个类别,作为实验的一个数据集。为了测试不同聚类方法在不同规模数据集上的聚类效果,进一步地,从这34类关系中随机选择其中的11个类别,这11个类别包含了100个关系,将这些关系作为另一个小规模的数据集。表2是第一
个数据集的部分关系。

Table 2 Sample of dataset表2 数据集部分样例
本文选择的聚类结果评价指标是纯度。对于要聚类的元素集合,已知每个元素的类别标签,记为ℂ={C1C2…Cn},Ci是第i个类别所有元素的集合。经过聚类方法得到的结果集合为Ω={ω1ω2…ωm},ωi是聚类结果中第i个簇,元素是通过聚类算法聚合而成。纯度计算公式如式(4)所示:
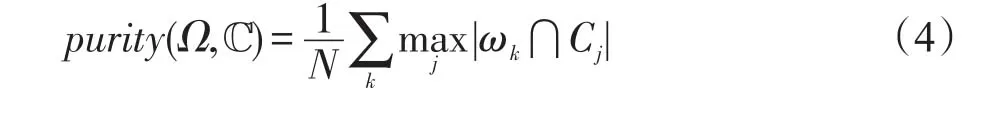
需要指出的是,必须在聚类簇数相同的情况下对不同聚类方法的纯度进行比较。这是因为不考虑聚类结果的簇个数,在聚类结果是每簇只有一个元素的情况下,利用式(4)计算得到的纯度是1。因为每一类只有一个元素,所以式(4)退化为若干个1相加,最终计算结果也是1。但是实际结果肯定不应该是每簇一个元素,在这种情况下计算得到的纯度会与实际情况相差很大。因此在下文的实验结果中,只统计聚类结果的簇数量与实际答案中簇数量接近时的聚类纯度,这样可以有效避免上述情况。
本次实验的对比方法是层次聚类算法,采用相同的词语语义相似度计算方法。在层次聚类过程中,计算簇间各点间距离的平均值作为簇间距离,通过设定阈值作为聚类终止条件。
5.2 实验结果
5.2.1 参数调整
首先对MCL算法的参数进行调整。根据算法3,MCL算法有两个参数。首先看松弛系数τ对聚类簇数的影响,如表3所示。
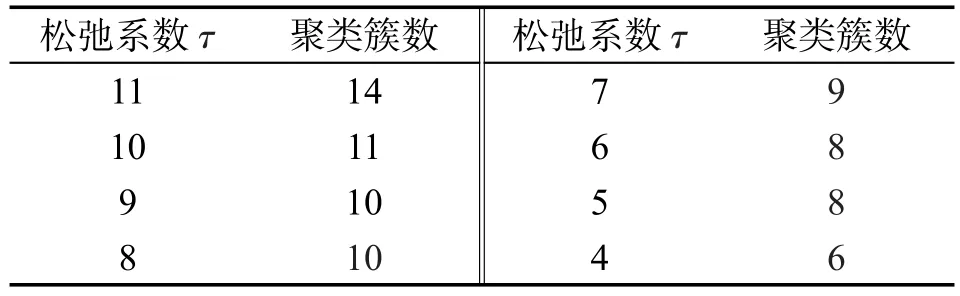
Table 3 Relationship betweenτand cluster number表3 松弛系数τ对聚类簇数的影响
可以看出τ与聚类簇数是正相关的,τ越大,聚类簇数越多。这是因为τ越大,在后续实验中,将通过调整τ,控制聚类结果簇数。
接下来,给出MCL算法中,相似度过滤系数θ对纯度的影响。测试数据集为100个关系,共11个类别,对于不同的θ取值,分别进行聚类,并且对聚类得到11簇的结果计算其纯度,结果如表4所示。

Table 4 Influence ofθon clustering purity表4 相似度过滤系数θ对聚类纯度的影响
从表4的结果可以看出,当聚类结果是11簇的情况且θ取值0.5时,聚类结果的纯度最高。也就是说,语义相似度计算得到的两个短语相似度如果低于0.5,就可以认为两者完全不同,θ起到了消除噪声的作用。而随着θ进一步加大,在超过0.5以后,无论如何调整参数,聚类簇数都不可能等于11。这是因为θ取值过大会把原图上的边去掉太多,导致有些不该独立出来的部分独立成一簇。从结果上看,在相同数据集上,当θ取值范围在0.2~0.6内,分别进行过滤并聚类后得到的结果,当结果簇数都为11时,纯度最高和最低分别是0.772 2和0.613 8,最高比最低可以提升25%左右。因此,取θ=0.5进行后续实验。
5.2.2 不同聚类方法的比较
表5是在11个类别100个关系的数据集上,MCL算法和层次聚类、k-means聚类方法的结果比较。表6是34个类别共200个关系的数据集上,MCL算法和层次聚类的结果比较。

Table 5 Comparison of clustering result with 100 relations in 11 types表5 11个类别共100个关系的聚类结果比较
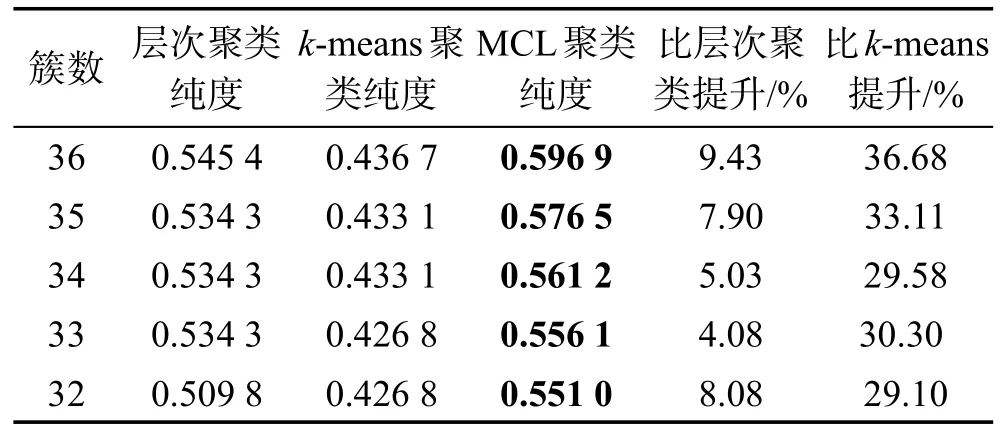
Table 6 Comparison of clustering result with 200 relations in 34 types表6 34个类别共200个关系的聚类结果比较
在表5中,数据集有11个类别共100个关系,MCL聚类结果比层次聚类结果的纯度平均提升了约20%,比k-means聚类提高约40%。在表6中,数据集有34个类别共200个关系,MCL聚类结果比层次聚类结果的纯度平均提升了约7%,比k-means聚类提高约30%。可以看出,在不同规模的数据集下,MCL算法的效果都比层次聚类以及k-means聚类效果好。
6 总结
本文提出了一种基于MCL图聚类的关系消解方法,并给出了一个简单的基于《同义词词林》的计算中文短语语义相似度的算法。在利用MCL图聚类算法的预处理阶段,通过设定相似度过滤系数θ将图上的边进行过滤,并在相同数据集上进行实验,通过调节θ,聚类纯度可以得到25%的提升。另外,实验表明,基于MCL图聚类的关系消解方法比基于层次聚类的关系消解方法在聚类纯度上可以平均提升7%、20%左右。目前,本文计算中文短语语义相似度是基于字典的方式,接下来将融合新的方法计算中文短语语义相似度,以进一步提升关系消解的准确度。
[1]Wang Yuanzhuo,Jin Xiaolong,Cheng Xueqi,et al.Network big data:present and future[J].Chinese Journal of Computers, 2013,36(6):1125-1138.
[2]Zhang Jing,Tang Jie.Knowledge graph:the focus of the next generation of search engine[J].Communications of the CCF,2012,9(4):64-68.
[3]Dongen S.A cluster algorithm for graphs[R].Amsterdam: CWI,Centre for Mathematics and Computer Science,2000.
[4]Fan Xiaoli,Liu Xiaoxia.Study on mutual information-based feature selection in text categorization[J].Computer Engineering andApplications,2010,46(34):123-125.
[5]Tai Deyi,Wang Jun.Improved feature weighting algorithm for text categorization[J].Computer Engineering and Applications,2010,46(9):197-199.
[6]Forman G.BNS feature scaling:an improved representation over TF-IDF for SVM text classification[C]//Proceedings of the 17th ACM Conference on Information and Knowledge Management,Napa Valley,USA,Oct 26-30, 2008.New York:ACM,2008:263-270.
[7]Song Yangqiu,Wang Haixun,Wang Zhongyuan,et al.Short text conceptualization using a probabilistic knowledgebase [C]//Proceedings of the 22nd International Joint Conference on Artificial Intelligence,Barcelona,Spain,Jul 16-22, 2011.Menlo Park,USA:AAAI,2011:2330-2336.
[8]Yates A,Etzioni O.Unsupervised methods for determining object and relation synonyms on the Web[J].Journal ofArtificial Intelligence Research,2009,34(1):255-296.
[9]Jin Chunxia,Zhou Haiyan.Chinese short text clustering based on dynamic vector[J].Computer Engineering and Applications,2011,47(33):156-158.
[10]Wu Wentao,Li Hongsong,Wang Haixun,et al.Towards a probabilistic taxonomy of many concepts,MSR-TR-2011-25[R].Microsoft Research,2011.
[11]Karandikar A.Clustering short status messages:a topic model based approach[D].Maryland:University of Maryland,2010.
[12]Tian Jiule,Zhao Wei.Words similarity algorithm based on Tongyici Cilin in semantic Web adaptive learning system [J].Journal of Jilin University:Information Science Edition,2010,28(6):602-608.
[13]Trudeau R J.Introduction to graph theory[M].Courier Corporation,2013.
[14]Dongen S.Performance criteria for graph clustering and Markov cluster experiments[R].Amsterdam:CWI,Centre for Mathematics and Computer Science,2000.
附中文参考文献:
[1]王元卓,靳小龙,程学旗.网络大数据:现状与展望[J].计算机学报,2013,36(6):1125-1138.
[2]张静,唐杰.下一代搜索引擎的焦点:知识图谱[J].中国计算机学会通讯,2012,9(4):64-68.
[4]范小丽,刘晓霞.文本分类中互信息特征选择方法的研究[J].计算机工程与应用,2010,46(34):123-125.
[5]台德艺,王俊.文本分类特征权重改进算法[J].计算机工程与应用,2010,46(9):197-199.
[9]金春霞,周海岩.动态向量的中文短文本聚类[J].计算机工程与应用,2012,47(33):156-158.
[12]田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报:信息科学版,2010,28(6):602-608.

CHANG Yuxiao was born in 1990.He is an M.S.candidate at University of Chinese Academy of Sciences.His research interests include open knowledge network and data mining,etc.
常雨骁(1990—),男,中国科学院计算技术研究所硕士研究生,主要研究领域为开放知识网络,数据挖掘等。

PANG Lin was born in 1985.She received the Ph.D.degree from Chinese Academy of Sciences.Now she is an engineer at National Computer Network Emergency Response Technical Team/Coordination Center of China.Her research interests include information security and data mining,etc.
庞琳(1985—),女,中国科学院计算技术研究所博士,现为国家计算机网络应急技术处理协调中心工程师,主要研究领域为信息安全,数据挖掘等。

JIAYantao was born in 1983.He received the Ph.D.degree from Nankai University in 2012.Now he is an assistant researcher at University of Chinese Academy of Sciences.His research interests include open knowledge network, social computing and combinational computing,etc.
贾岩涛(1983—),男,2012年于南开大学获得博士学位,现为中国科学院大学助理研究员,主要研究领域为开放知识网络,社会计算,组合算法等。

LIN Hailun was born in 1987.She received the Ph.D.degree from University of Chinese Academy of Sciences. Her research interests include open knowledge network and data mining,etc.
林海伦(1987—),女,中国科学院大学博士,主要研究领域为开放知识网络,数据挖掘等。

WANG Yuanzhuo was born in 1978.He is an associate professor and M.S.supervisor at University of Chinese Academy of Sciences.His research interests include social computing,open knowledge network and network security analysis,etc.
王元卓(1978—),男,博士,中国科学院大学副研究员、硕士生导师,主要研究领域为社会计算,开放知识网络,网络安全分析等。

LIU Yue was born in 1971.She received the Ph.D.degree from University of Chinese Academy of Sciences.Now she is an associate professor and M.S.supervisor at Chinese Academy of Sciences.Her research interests include text mining,Web search,complex network analysis and social computing,etc.
刘悦(1971—),女,博士,中国科学院计算所副研究员、硕士生导师,主要研究领域为文本挖掘,Web搜索,复杂网络分析,社会计算等。

LIU Chunyang was born in 1962.He is an engineer at National Computer Network Emergency Response Technical Team/Coordination Center of China.His research interests include information security and data mining,etc.
刘春阳(1962—),男,国家计算机网络应急技术处理协调中心工程师,主要研究领域为信息安全,数据挖掘等。
Entity Relation Resolution Method by Integrating Markov ClusterAlgorithm*
CHANGYuxiao1,2+,PANG Lin3,JIAYantao1,LIN Hailun1,2,WANGYuanzhuo1,LIUYue1,LIU Chunyang3
1.Research Center of Web Data Science&Engineering,Institute of Computing Technology,Chinese Academy of Sciences,Beijing 100190,China
2.University of ChineseAcademy of Sciences,Beijing 100049,China
3.National Computer Network Emergency Response Technical Team/Coordination Center of China,Beijing 100029,China
+Corresponding author:E-mail:changyuxiao1990@163.com
Recent years,the development of knowledge bases is very fast.They store large scale of entities and the relations between entities.However,most of the relations which have the same meanings are not in the same form. It is necessary to resolute the relations.For this purpose,this paper proposes an approach based on Markov clusteralgorithm to cluster the relation with same meanings.Firstly,this paper calculates the semantic similarity between every two relations,and then it uses the relation similarity as weighted-edge to build a graph.Finally,this paper runs a Markov cluster algorithm on the graph and gets the result of relation clusters.Experiments show that the proposed approach has a higher purity than hierarchy cluster and k-means cluster.
Markov cluster;knowledge base;relation between entities
10.3778/j.issn.1673-9418.1509084
A
TP319
*The National Natural Science Foundation of China under Grant Nos.61173008,61232010,60933005,61402442,61402022, 61303244(国家自然科学基金);the National Basic Research Program of China under Grant Nos.2013CB329602,2014CB340405 (国家重点基础研究发展计划(973计划));the Science and Technology Nova Program of Beijing under Grant No.Z121101002512063 (北京市科技新星计划项目);the Natural Science Foundation of Beijing under Grant No.4154086(北京市自然科学基金青年基金项目);the Research Program on Medical Imaging of the ChineseAcademy of Sciences under Grant No.KGZD-EW-T03-2(中科院医学影像项目);the Technology Innovation and Transformation Program of Shandong Province under Grant No.2014CGZH1103(山东省自主创新及成果转化专项).
Received 2015-09,Accepted 2016-12.
CNKI网络优先出版:2016-12-14,http://www.cnki.net/kcms/detail/11.5602.TP.20161214.1122.002.html
CHANG Yuxiao,PANG Lin,JIAYantao,et al.Entity relation resolution method by integrating Markov cluster algorithm.Journal of Frontiers of Computer Science and Technology,2017,11(4):511-519.
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
高中生·天天向上(2017年10期)2018-01-18 21:51:58
现代语文(2016年21期)2016-05-25 13:13:44
知识窗(2015年1期)2015-05-14 09:08:17
大连民族大学学报(2015年2期)2015-02-27 08:28:11
Beijing Review(2012年37期)2012-10-16 02:24:10
外语学刊(2011年1期)2011-01-22 03:38:33
