
基于单目视觉的实时手语识别系统设计与实现
2017-03-27 10:25王丽光张根源刘子龙
电子科技 2017年3期
王丽光,张根源,刘子龙
(1. 山西省交通厅 定额站,山西 太原 030006;2. 上海理工大学 光电信息与计算机工程学院,上海 200093)
基于单目视觉的实时手语识别系统设计与实现
王丽光1,张根源2,刘子龙2
(1. 山西省交通厅 定额站,山西 太原 030006;2. 上海理工大学 光电信息与计算机工程学院,上海 200093)
针对目前单目手语识别系统存在检测效率低、识别速度慢的问题。文中提出了基于YCrCb空间的肤色模型与背景差分模型融合的高效检测算法,从而提高了手势的检测效率;且为了提高识别手势的速度,采用交叉相关算法计算特征相关度识别手势。通过进行8种常用手势测试模型与标准模板库的对比实验,结果验证了本系统具有较高的识别速度,且识别率达到85%以上。
手语识别;人机交互;运动轨迹;模式识别
随着将人与人姿态的交流方式引入人机接口,使得手势识别技术成为了热门研究技术[1]。手势是一种非语言的使用部分身体交流的形式。手势识别是通过计算机识别人类的手势来进行人机互动的技术,从开始简单的人手形态分辨,到复杂场景中的移动物体,发展到如今实现复杂情感的交流[2-3]。
手势识别技术主要包括图像处理技术、机器学习技术以及模式识别技术等[2]。所以,手势识别包括了如图像检测和分析、图像纹理、图像轮廓模型 ,特征提取、目标检测、聚类和分类等应用技术,且应用前景广泛[4]。为实现能够在穿戴设备上应用的实时手语识别系统,提出高效而快速的检测算法和模式识别算法,并以手势的运动轨迹特征建立了手势样本数据库,从而用实时采集到的手势视频与数据库对比,便可获得手势的语义并输出到视频窗口上[5-6]。最后,根据实验结果验证了系统的有效性和实用性,系统总流程如图1所示。

图1 系统总流程图
1 系统总设计
根据图1所示,整个识别系统分为3个子系统部分,所有细分子系统与主系统的关系框架如图2所示。其中子系统1,首先用摄像机获得手势视频序列,并通过IEEE1394协议端口与计算机连接,采用OPENCV计算机视觉库捕捉视频帧,根据背景差分法分割出前景目标,并通过肤色检测模型输出只有手部区域的二值图像[7];子系统2,该部分从二值图像中提取手部轮廓形状,然后计算手部质心与运动速度,紧接着通过跟踪质心前后两帧图像的坐标位置变化,得到手势的运动速度和角度,集合所有这些信息形成动态手势运动轨迹。最后为了数据库样本的一致性,对运动轨迹特征进行归一化和内插值处理;子系统3,该部分主要对实时获得的测试手势模型与数据库里的样本进行匹配对比,最后实时输出匹配模式的手语语义到视频窗口[8]。

图2 主系统的框架图
2 手部区域检测
本部分主要利用OPENV库实现摄像机与计算机的连接,并通过调用其中的优化函数对采集到的图像进行了归一、降噪、增强等初步处理工作,为后续的手部分割提供了高质量输入[9]。
2.1 改进的背景差分法
背景差分法亦称背景减除法,是目前研究最多一种运动目标检测方法,该方法适用于静止摄像机条件下的运动目标检测。其思路是在进行检测时,使用当前图像与背景图像进行差分完成运动区域检测,与背景图像存在明显差异的区域,即运动目标所在区域[10]。假设It(x,y)为t时刻待检测图像;B(x,y)为背景图像;差值图像以D(x,y)表示,则数学表达式为
D(x,y)=|B(x,y)-It(x,y)|
(1)
通过对差值图像进行阈值化处理,即可实现运动目标区域的分割,设阈值化后结果图像为 ,则有
(2)
通过将摄像头采集的视频序列图像与背景图像进行比较,提取出二者区别较大的区域,即可获取该帧图像中运动的前景目标区域[4]。
本文通过两个条件要素来改进背景模型:(1)该背景模型像素存在的时间长短;(2)此像素与当前帧的差异值大小。此算法的具体步骤如下描述[11]。
(1)建立初始背景模型。首先假设视频序列从没有前景对象开始,为实现背景模型初始化,在图像背景像素稳定之前,运用简单的时间帧差法来计算背景模型。且该时间帧差法在t时刻当前帧可用ft(x,y)表示,且其求解公式可定义为
ft(x,y)=|It(x,y)-It(x,y)-It-1(x,y)|
(3)
其中,It(x,y)表示t时刻帧图像中像素(x,y)的值。
然后根据经验设定前景图像ft(x,y)的二值图像阈值T1为20,然后通过与阈值比较得到前景二值模板图像FGt(x,y)。即当其中一个像素在比较中有明显的数值变化并且该变化值大于阈值T1时,就被标记为前景像素
(4)
当某个像素在一定数目帧图像中都没有检测到有明显的运动迹象时(例如ft(x,y)
(5)
当背景模型信息一旦可用来识别图像像素(例如,BMt(x,y)根据式(5)建立),前景目标模板就由背景减去法来替代时间帧差法来产生。背景减去算法公式定义为
Dt(x,y)=|It(x,y)-BMt-1(x,y)|
(6)
然后将背景差分图像与阈值T2进行比较,最后得到前景目标二值模板
(7)
其中,阈值T2经过实验证明设置为50时,能获取到较好效果。该背景模式初始化方法有一个前提假设:每一个背景像素都有一段时间没有被遮挡住;
(2)获取背景减去算法的自适应阈值。使用Rilder和 Calvar提出的迭代原理来获得前面提到的自适应阈值。因差分图像Dt(x,t)中的柱状图被分割为两部分。初始阈值被设置为图像灰度值的中间值(即在8-bit的灰度图像中取中间值为127),然后图像根据此中间灰度值来二值化。在每次迭代中,分别计算出前景像素的平均灰度值和背景像素的平均灰度值,然后根据这两个平均灰度值的中间值获得一个新的阈值。当此阈值不在变化时,迭代结束。求解到的自适应阈值将应用在式(8)中,该公式称为前景/背景像素分类器,其中ThAd,t为自适应阈值;
(3)基于像素灰度值的前景/背景分类器。经过前面的背景模型的初始化,下一步就是应用背景减去算法比较当前帧图像与背景模型,也就是前景/背景像素分类器。背景减去算法如式(6)所示。
该像素分类器是根据自适应阈值ThAd,t来提取图像中运动目标来生成前景模板区域[13]。此阈值完全依赖于当前的差分图像ThAd,t,具体说明如上一步所述。若当前帧与背景模型相对应两个像素的差值大于阈值 ,则该像素被定义为前景像素。最后获得二值模板FGt(x,y)
(8)
此模板记录了前景目标的像素坐标位置。这一步处理结果与式(7)基本一样,除上述公式适合整个视频序列的背景模型以外,因为该公式使用了自适应阈值ThAd,t取代了前面提前预设的阈值T2;
(4)像素级自适应背景模型更新。为了保证运动目标与背景的分割效果,本文采用的更新背景模型(由Stauffer和Grimson提出)公式为
BMt(x,y)=αIt(x,y)+(1-α)BMt-1(x,y)
(9)
上式表示使用当前帧图像 的灰度值和 的前背景模型的灰度值来更新当前的背景模型。其中 表示背景模型更新的“学习率”,该值对背景减去算法的性能起到关键作用。
2.2 肤色模型
肤色分割主要通过建立肤色模型,再根据肤色模型定义的规则判断提取的图像,将符合规则的像素区域标记为手势区域。一个适合应用于肤色检测的色彩空间,其内部肤色分布应该比较集中,能聚成一类。相对于标准RGB颜色空间只适合于计算机硬件对图形处理,YCrCb颜色空间更接近人眼对颜色的划分。依据人类的肤色在YCrCb颜色模型中能明显的聚成一类,即肤色的像素值在Cb和Cr的值很接近,并与其它颜色有明显的分界[14]。
RGB颜色空间转换到YCrCb颜色空间的公式如下
Cb(k)=
-0.169×R(k)-0.331×G(k)+0.5×B(k)+128
(10)
Cr(k)=
0.5×R(k)-0.491×G(k)-0.081×B(k)+128
(11)
(12)
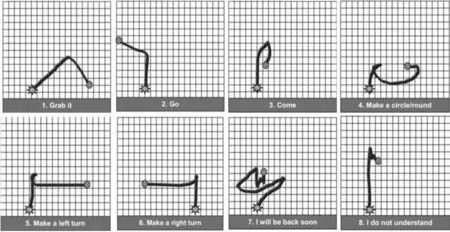
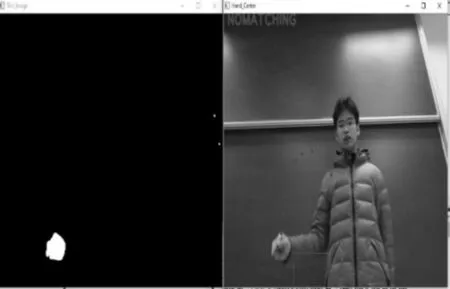
并在区间105 图3 手势检测效果图 经过手势轮廓检测得到每一帧图像手部轮廓的质心坐标,然后可根据式(13)~式(17)计算手心速度以及运动方向,进而得到运动轨迹特征[15] (13) (14) (15) (16) (17) 其中,Δt为当前与前一帧图像的时间间隔;X1,Y1是前一帧图像的手势质心;X2,Y2是当前图像的手势质心。图中θ表示质心的角度,V是手形质心的运动速度。视频序列中每个图像的手势质心坐标、速度以及角度作为一个元素组合起来就形成运动轨迹特征向量。为了来排除不同人打出的手势速度和幅度差异带来的干扰,对轨迹特征向量进行归一化和插值拟合处理,最后以txt文件的格式存储进数据库,如图4所示。图中,第1列表示视频帧计数,第2、3列表示质心坐标,第4列表示手势速度和最后一列角度。 图4 数据库数据 交叉相关算法是一种标准的估计两列数据相关程度的算法,经实验证明此算法满足本系统实时性、识别率的要求。根据下面(18)~式(21)计算数据相关度xr,yr和Vr是输入手势的特征向量值,而x0,y0和V0则是数据库的手势特征向量值 (18) (19) (20) E=rx+ry+rv (21) 其中,mxr,myr和mvr分别是输入测试模型中所有xr,yr和Vr值的平均值;mx0,my0和mv0分别是手势样本库中所有x0,y0和v0值得平均值;i=1,2,…,N,表示手势视频帧数目;rx,ry与rv之和E表示了两个模型的相关度。手势模式数据库里的所有手势模型将一一与输入的手势模型进行交叉相关度计算,所有的样本模式将得到各自不同的相关度E。其中最大相关度值E的模式就是最佳的匹配模型。 本文实验环境如下:Windows10操作系统,VS2010+OpenCV-3.0,CPU:Intel I5-2410M(2.3 GHz),4 GB内存。 首先选择合适的手语动作,试验所选取的8种手势均能较好的提取为平面运动轨迹特征,如图5所示,8种手势的轨迹平面图,图中太阳为手势起点,圆点为结束点。图6显示了实时提取测试手势轨迹特征界面,图中描绘的红点线路即是轨迹路径[16]。然后将测试视频的轨迹特征与手势样本数据库模型比较匹配,其中样本库的轨迹特征由手语教学视频中提取并存储建立。 图5 采集手势动态轨迹特征 图6 提取轨迹特征界面 实验中,每种手势由5个实验者各做10次,共得到50手势视频片段,对8种手势则产生400组训练数据。然后,将每组训练数据与手势模板数据库极性匹配比较,其中测试的识别率结果表1所示。 表1 8种手语识别率 注:以手势样本为单位 表中各种手势的平均识别率为89.75%,此试验结果表明,本文的手势识别方法具有较高的精确度。本系统建立的手势样本数据库存储量小,无法测试系统实际应用环境时的运行速度,但实验结果显示平均手势的识别时间约为1 ms。因此,下一步的工作是进一步增加手势的种类,并为了实际需求,考虑加入双手手势识别。 [1] Caplier A, Bonnaud L, Malassiotis S, et al. Comparison of 2D and 3D analysis for automated Cued Speech gesture recognition [C]. Petersburg,Russia:Proceedings of 9th Conference on Speech and Computer (SPECOM’2004),2004. [2] 杨培君, 马文瑞. 智能配电监控系统的人机交互设计[J]. 电子科技, 2011, 24(4):92-95. [3] Montero J A, Sucar L E. A decision-theoretic video conference system based on gesture recognition[C]. MA,USA:International Conference on Automatic Face and Gesture Recognition,2006. [4] Fukumoto M. Real-Time detection of pointing actions for a glove-free interface[C].California:Iapr Workshop on Machine Vision Applications,1992. [5] 任海兵,祝远新.连续动态手势的时空表观建模及识别[J].计算机学报,2000,23(8):824-828. [6] 邹洪.实时动态手势识别关键技术研究[D].广州:华南理工大学,2011. [7] 魏朝龙.手势建模算法研究及其应用[D].广州:广东工业大学,2011. [8] 王久龙.基于动态实时立体匹配的立体视觉系统[D].杭州:浙江大学,2008. [9] 张强.运动目标识别视频监控系统设计与实现[D].武汉:华中科技大学,2011. [10] 张国家.手势指令的单目视觉识别技术研究[D].南京:南京航空航天大学,2013. [11] 杨舒,王玉德.基于Contourlet变换和Hu不变矩的图像检索算法[J].红外与激光工程,2014,43(1):306-310. [12] 曾祥堃.手形特征与运动轨迹相结合的动态手势识别[D].上海:上海海事大学,2005. [13] 李文生,解梅,邓春健.基于机器视觉的动态多点手势识别方法[J].计算机工程与设计,2012,33(5):1988-1992. [14] 魏朝龙.手势建模算法研究及其应用[D].广州:广东工业大学,2011. [15] Pricerunner.Video camera comparison[EB/OL].(2007-08-13)[2016-01-15]http://www.pricerunner.com/cl/8/Camcorders. [16] Intel. Open source computer vision library[EB/OL].(2007-10-21)[2015-12-12]http://www.intel.com/research/mrl/research/opencv. Design and Implementation of Real Time Gesture Recognition System Based on Monocular Vision WANG Liguang1,ZHANG Genyuan2,LIU Zilong2 (1.Quota Station,Shanxi Provincial Department of Transportation,Taiyuan 030006,China;2.School of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology,Shanghai 200093, China) In recent years, as the rapid development of computer application and the popularization of the computer vision theory, human-computer interaction technology has become as a hot mainstreamtechnology and computer science .In order to establish a fast and high efficient gesture language recognition system,this paper has proposed an efficient detected algorithmwhich is composed by the YCrCb skin-color-detect model and the background difference model. And then the gesture pattern recognition is achieved based on the cross correlation algorithm, which is improve the recognition speed. Finally the experiments verify the real-time of the system, and recognition rate reached more than 85% which means thesystem is practical. gesture language recognition; human-computer interaction;trajectoryfeatures;pattern recognition 2016- 03- 28 王丽光(1972-),女,高级工程师。研究方向:信息与自动化。张根源(1989-),男,硕士研究生。研究方向:模式识别技术等。 10.16180/j.cnki.issn1007-7820.2017.03.036 TP391.41 A 1007-7820(2017)03-130-05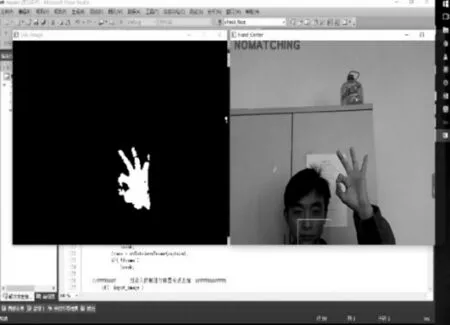
3 特征提取与建立样本库

4 交叉相关识别算法
5 实验与结论

猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
红领巾·萌芽(2019年9期)2019-10-09
红领巾·萌芽(2019年8期)2019-08-27
小学科学(学生版)(2018年12期)2018-12-19
现代装饰(2018年5期)2018-05-26
中国与非洲(法文版)(2017年10期)2017-11-23
小学阅读指南·低年级版(2017年6期)2017-06-12
中国三峡(2017年2期)2017-06-09
