
语篇信息分析视角的个人话语风格潜在说话人鉴别力研究
2016-12-02 07:44关鑫
中原工学院学报 2016年5期
关 鑫
(肇庆学院, 广东 肇庆 526061)
语篇信息分析视角的个人话语风格潜在说话人鉴别力研究
关 鑫
(肇庆学院, 广东 肇庆 526061)
目前,说话人司法鉴别所采用的鉴别参数都是语音听觉和声学特征,受司法实践环境影响巨大,不可避免的语音变异现象大大削弱了语音资料证据的效度,已经成为制约说话人司法鉴别技术发展的最主要原因。交叉印证法从理论上论证了通过语音分析与个人话语风格分析交叉印证削弱语音变异影响的可行性。本文采用语篇信息分析法分析自然会话,提取了体现说话人个人话语风格的说话人鉴别参数,验证了这些参数的潜在说话人鉴别力,同时也证明了交叉印证法的实践可行性。
个人话语风格;语篇信息;说话人鉴别
说话人司法鉴别交叉印证法建议以个人话语(Idiosyncratic Speech)整体为研究对象,个人语音比对分析与个人话语风格比对分析相互印证,以克服语音变异现象对声纹鉴定技术的负面影响,增强录音资料证据的信度,并提出采用话语分析方法分析个人话语风格[1],但并没有提出具体的提取特征参数的分析方法。
鉴于此,本文首先阐释了交叉印证法中的话语风格与言语识别中的个人言语风格的异同,明晰交叉印证法中提出的个人话语风格的性质,进而提出适合个人话语风格分析的方法——语篇信息分析法,并通过实验初步验证个人话语风格的潜在说话人鉴别力。
1 个人话语风格的界定和性质
1.1 个人言语风格与个人话语风格的异同
说话人司法鉴别是对比分析说话人的语音和个人言语习惯,并鉴别涉案语音材料和怀疑对象的语音材料是否源于同一说话人的鉴定过程。现有说话人鉴别方法主要通过比对体现说话人的生理解剖学特征的独特的嗓音特点的语音学特征和体现说话人的社会属性与自然属性的后天习得的独特的言语习惯特征进行鉴别。很多学者把个人言语习惯的鉴别称为个人言语风格(Individual Language Style)司法鉴别[2-4],主要体现在用字、用词、句法和修辞等个人言语特征方面。
依据Sapir E的定义,个人话语风格(Individual Speaking Style)指个人遣词造句和谋篇布局的方法、策略,是构成话语行为的5个层面中的最高一层。其他4个层面依次是声音、言语动态特征、发音和词汇[5]。
不难看出,个人话语风格与个人言语风格既密切相关,又有本质上的区别。首先,就涉及的语式和应用范围而言,个人言语风格司法鉴别对象涉及书面语言和口语录音材料,多数情况下指书面语言作者同一认定过程[2-4,6],这些特征在现有说话人鉴别方法中主要是作为辅助识别参数[1]。而说话人识别中的个人话语风格则指连续性话语行为(Speech Act)的风格,不涉及书面语言。
其次,仅就口语而言,个人言语风格强调说话人的社会团体属性对说话人言语表现方式的影响;言语鉴别中个人言语风格比对重点考察能反映说话人时代、地域、民族、性别、年龄、职业、文化程度、环境、言语社区等差异的语言特征差异[7]。而Sapir E定义的说话人个人话语风格强调的是移除了社会影响因素后的使说话人区别于社会团体中其他成员的说话人的个性话语风格特征。
再者,个人言语风格体现为反映说话人时代、地域、民族、性别、年龄、职业、文化程度、环境、言语社区等的用字、用词、句式、修辞等特征。个人话语风格体现为说话人谋篇布局的方式方法。换言之,个人言语风格鉴别考察言语的表层局部特征,个人话语风格考察话语的深层全局特征。
1.2 个人话语风格的性质
以上个人言语风格和个人话语风格的异同和关联显示,就口语而言,个人言语风格更加强调社会因素和说话人个性因素相互作用下的体现说话人社会属性的说话方式;而个人话语风格则关注移除社会因素影响、只由说话人个性因素决定的说话方式。
说话人的话语直接反映了说话人的认知水平和语言能力,并体现为个人的言语风格,即表层言语特征,如用字特征、句式特征等。个人话语风格则是说话人深层认知水平的反映,进而体现为说话人谋篇布局的策略。因此,个人话语风格不但和个人言语风格一样具有特殊性、稳定性和反映性[4],还具有一致性,即个人话语风格在不同时间、空间环境中呈现一致性。相对于个人言语风格而言,个人话语风格稳定性更强,更能反映说话人不同于同一社会团体中其他社会成员的特殊性。
2 个人话语风格分析方法——语篇信息分析法
早在1927年,Sapir E就指出,移除社会因素影响因子、确定个人话语风格是一个非常复杂的问题,但在理论上是可行的[5]。可是,迄今为止,个人话语风格分析研究尚未展开。其主要原因,一方面在于很难把人从社会中完全剥离开来,另一方面在于缺乏适合揭示说话人深层认知水平的话语分析方法。
源于法律语篇树状信息结构模式的语篇信息分析法不同于普通的语言分析法[8-10]。根据树状信息结构模式,信息是能够用于交际的最小完整意义单位的命题,处于语言表层和认知底层之间。相对于语言表层,语篇信息结构更加稳定,更能反映说话人的认知结构。通过分析语篇信息的宏观结构和微观结构,可以揭示隐藏于形式多变的言语表层之下的信息结构范式,进而反映说话人的认知结构。因此,采用语篇信息分析法分析说话人的个人话语,有望揭示说话人的个人话语风格特征。
3 个人话语风格潜在鉴别力研究
如果语篇信息分析法能够抽取出反映个人话语风格的特征参数,就证明个人话语风格分析的实践可行性,进而证明说话人司法识别交叉印证法的实践可行性。
在个人话语风格可分析的基础上,要证明个人话语风格的潜在鉴别力,就必须证明采用语篇信息分析法抽取的说话人识别特征参数话者之间的差异大于说话人自身语音变异性[11-12]。
依据个人话语风格的性质和说话人识别特征参数的衡量标准,证明个人话语风格的潜在说话人鉴别力必须证明以下假设为真:
假设1 语篇信息分析法能够抽取出个人话语风格特征参数,即通过语篇信息分析法抽取的特征参数在同一说话人不同时间和空间条件下的会话中具有一致性;
假设2 所抽取的个人话语风格特征参数能够区分开不同的说话人,即所抽取的特征参数话者之间的差异大于说话人不同时间和空间条件下的会话间的差异。
3.1 实验设计
从法律信息处理系统语料库(CLIPS)中分别随机选取5段说话人S1(女)和S2(女)不同时间、不同空间条件下的日常会话录音材料验证假设1。每位说话人的会话录音中会话双方和交际目的均不相同。如果假设1正确,则通过语篇信息分析法抽取的特征参数在每位说话人不同时间、不同空间的对话中具有一致性。
从CLIPS中另外分别随机选取2段说话人S3(男)、S4(女)、S5(男)不同时间、不同空间的日常会话录音材料,每位说话人的2段会话录音中会话双方和交际目的均不相同;将它们与S1、S2的两段日常会话一起作为验证假设2的实验材料。如果假设2正确,则假设1中抽取的特征参数能区分开随机抽取的5位说话人。
录音材料的具体信息如表1所示。
3.2 实验步骤与方法
CLIPS语料库中的每份日常会话录音材料都包括已标注的会话音频文件和会话录音的逐字转写的文本文件。
由于说话人识别特征参数必须在语音材料中具有高出现率,因此首先需要确定要考察的语篇信息单位的值[13]。在确定语篇信息单位的值后,抽取个人话语风格特征参数,通过统计分析验证假设1和假设2。
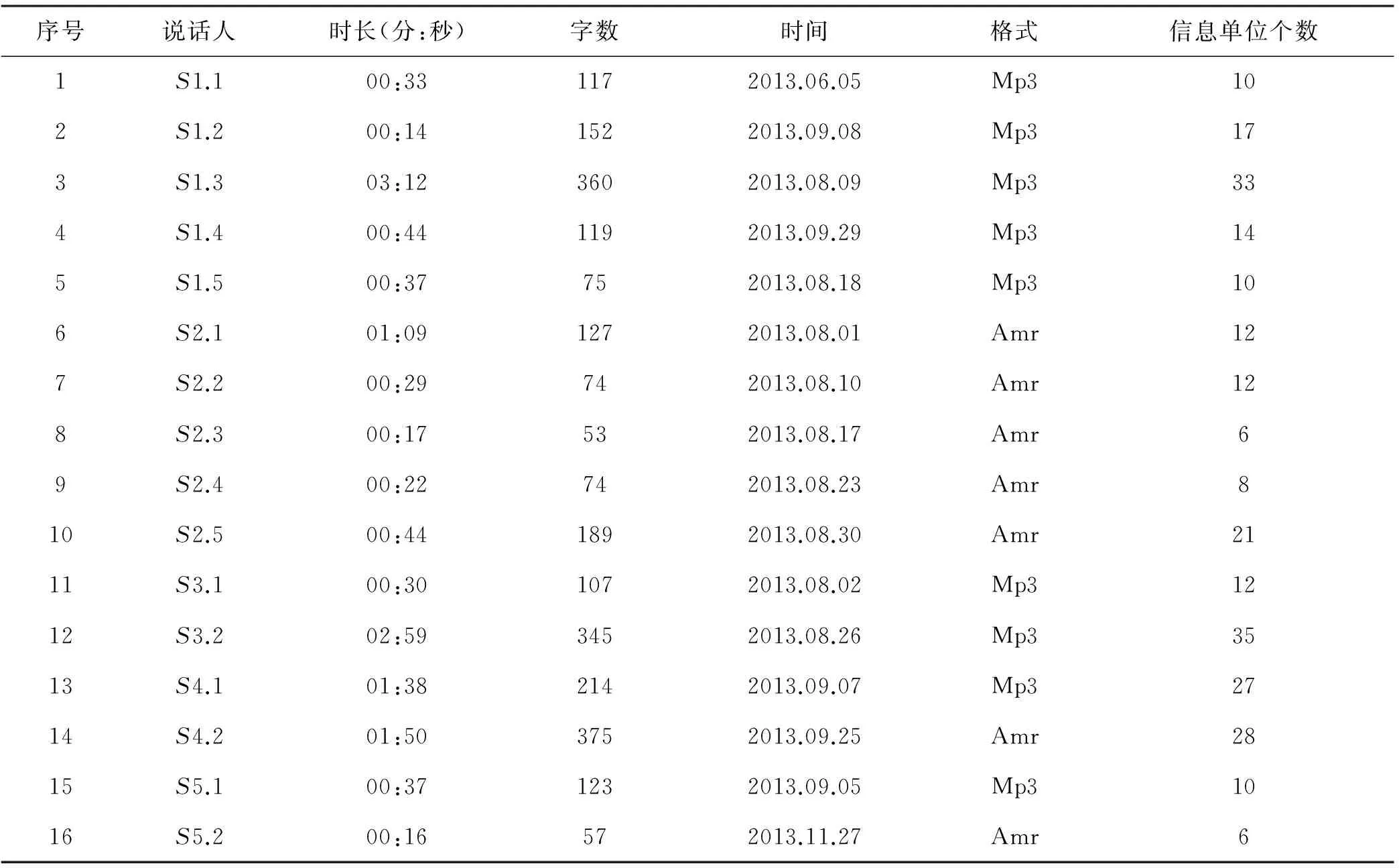
表1 实验数据基本信息
注:S1.1代表第1位说话人的第1段会话;S1.2代表第1位说话人的第2段会话;其他类似。
所有5位说话人共16段会话中的15个信息点的值的分布统计情况如表2所示。R1表示含有每一类信息点的会话数量与会话总数量的比率。例如,含有WT信息点的会话数量与会话总数量的比例为100%,表明16段会话中都含有WT信息点;含有WB信息点的会话只占会话总数量的19%,表明16段会话中只有3段会话中含有WB信息点。R2表示全部16段会话中每一类信息点的数量与15类信息点数量总和的比率。例如,16段会话中WT信息点占所有信息点数量总和的41%;WB信息点占所有信息点数量总和的1.5%;WC和WG信息点在16段会话中没有出现。

表2 会话录音中信息点的值的分布情况 %
表2显示,会话无论长短都含有WT信息点,而且所有信息点中WT的出现频率远远高于其他14个信息点。因此,把WT确定为要考察的主要信息点。
通过考察WT信息点相关参数,初步确定2个参数F1和F2。F1为位于WT信息点的信息单位的时长,单位为毫秒;F2为位于WT信息点的信息单位中的信息成分字数与该信息单位总字数的比率(语篇标志语、连词等不计为信息成分字数)。
利用统计软件SPSS 19,以假设1和假设2中的F1、F2为因变量,分别作组间单因素方差分析和多因素方差分析,验证假设1中参数F1和F2的值在S1和S2不同时间和不同空间的会话中是否保持一致,并能区分开假设2中的5位说话人。
3.3 结果与讨论
根据说话人司法鉴别研究惯例,为了保证实验数据正态分布,把抽取的参数值转换为以10为底的对数[14],初步筛选后数据满足正态分布要求。然后,进行因素方差分析运算。假设1中4个单因素方差分析的结果如表3所示。统计结果显示,相伴概率p高于0.05,说明参数F1和F2的组间差异小于组内差异。也就是说,所抽取的特征参数F1、F2在说话人S1、S2的5段不同时间、不同空间条件下的日常会话中都具有一致性,假设1成立。

表3 假设1单因素方差分析结果
注:显著水平为0.05。
假设2中,多因素方差分析的多变量检验结果(Box’s M test:p=0.000;Pillai’s trace=0.726,p=0.000)证明,以F1和F2为识别参数,可以区分开5位说话人;主体间效应的检验结果(p<0.01)如表4所示,表明参数F1、F2的组间差异大于组内差异,也就是说,两个特征参数的话者之间的差异大于说话人自身的语音变异。

表4 假设2主体间效应的检验结果
注:显著水平为0.05。
事后两两比较结果显示,参数F1和F2不能区分S2与S5、S3与S4、S3与S5、S4与S5。在此基础上,进一步分析没有区分开来的4组S2、S3、S4、S5的会话的语篇信息微观结构特征。分析结果显示,这4个说话人的话语都有其独特的个人话语风格特征。如下示例为转写文本,每行为一个信息单位。首先,说话人S5的两段日常会话中人称代词充当的“说明”信息成分——转写文本中用下划线标出——都是形容词性物主代词,S1、S2、S3中含有的该信息成分都是名词性物主代词,S4中则两种情况都有。
S5.1:我们的那个可选课程里面好像没有啊
S5.2: 那你有他的手机吗
S1:你来的时候你去我那个房间
S3:就是你们家那个旧的电动车
S4:你那个拜拜耳行啊
信息点开之后它底下有一个未关注的私信在那个里边
还有就是哎你这两天你关注一下你的那个私信里边有一个就是未关注的未关注人的私信
该特征可以有效区分开说话人S2与S5、S3与S5的会话。
此外,如下示例显示,就信息单位的结构而言,与S5相比,说话人S2、S3、S4构建的信息单位更加顺畅,意义与结构更加完整;同样,与S4相比,S3的信息单位结构更加齐整。信息单位的结构主要表现为一个信息单位内表达方式相同的信息成分重复出现的次数及信息单位命题意义对上下文的依赖程度。该示例中,首次出现的信息成分在转写文本中用下划线方式标出,与之重复的信息成分在转写文本中用斜体加下划线标出。
S2: 我是说你一会儿你不 不能给我打电话了嘛
我在 我在五栋
在 在哪个饭堂
S3: 一点变数都没有 一点变数都没有
结果昨天晚上它前两天老是充不满 老是充不满
今天上午最快只能骑20公里了 20公里的速度了
S4:因为我比较 我嫌麻烦
今天有两 今天又有两个然后这个就是给我私信
还有就是哎你这两天你关注一下你的那个私信里边有一个就是未关注的 未关注人的私信
S5:商英学院那儿没 没 什么都没有
我当我是前 前两天 前两天 我就是
跟上学期期末的时候 那时候是一样的
那个是刚 因为他刚才用这个电话
该特征可以有效区分开说话人S2与S5、S3与S4、S3与S5、S4与S5的会话。
以上分析证明,综合基于定量参数F1、F2的统计分析和基于语篇微观信息结构的定性分析,能够比较有效地区分开随机抽取的5位说话人,即假设2成立。
4 结 语
以上分析结果及讨论表明,语篇信息分析法可以用来分析个人话语风格,提取体现说话人个人话语风格的特征参数。所抽取的特征参数及其他反映语篇信息微观结构的特征可以在很大程度上反映说话人的个人话语风格,具有潜在的说话人鉴别能力。
更值得一提的是,该文中的实验录音材料是现实世界中的自然会话。也就是说,选取实验录音材料时并没有考虑性别、年龄、实验语音的录制环境、内容及传输信道等在嗓音分析中必须予以考虑的、并且需要人为控制的会导致语音变异的众多因素。这说明个人话语风格分析基本不受语音变异现象影响,可以和语音分析协同进行,互为补充,分析结果相互印证。也就是说,交叉印证法不但具有理论可行性,借助语篇信息分析法还易于付诸于实践。
当然,本文所抽取的参数对说话人个人话语风格的反映程度、作为说话人识别参数的效度还有待用大样本实验数据及说话人识别参数效度与信度验证方法进行进一步验证。
[1] 关鑫. 说话人司法识别交叉印证法研究[J]. 广东外语外贸大学学报,2014(5):52-57.
[2] 杨旭. 个人言语风格的司法鉴定[J].上海市政法管理干部学院学报,2000,15(6):58-61.
[3] 王少仿. 个人言语风格识别应用于案件侦查[J].中国司法鉴定,2010,49(2):53-56.
[4] 王少仿. 个人言语风格识别研究[J].湖北警官学院学报,2010,114(3):104-107.
[5] Sapir E. Speech as a Personality Trait[J]. The American Journal of Sociology, 1927, 32 (6): 892-905.
[6] 贾硕果. 言语风格与言语识别[J]. 中国人民公安大学学报(自然科学版),2011,70(4):17-20.
[7] 柯移顺. 当代大学生言语风格初探[C]//个人言语特征及其司法应用研究. 北京:知识产权出版社,2013:151-170.
[8] 杜金榜. 法律语篇树状信息结构研究[J]. 现代外语,2007,30(1):40-50.
[9] 杜金榜. 语篇信息分析:法律语言学研究新视角[N]. 中国社会科学报,2011-05- 24(15).
[10] 杜金榜.语篇信息分析:多模态语篇分析难题的解决方法[J].中原工学院学报,2015,26(2):17-23.
[11] Nolan F. The Phonetic Bases of Speaker Recognition[M].Cambridge: Cambridge University Press, 1983:11.
[12] Rose P. Forensic Speaker Identification[M]. London & New York: Taylor & Francis, 2002:48.
[13] 杜金榜. 语篇分析教程[M]. 武汉:武汉大学出版社, 2013: 176-184.
[14] Aitken C G G, Lucy D. Evaluation of Trace Evidence in the Form of Multivariate Data[J]. Applied Statistics, 2004,53(1): 109-122.
(责任编辑:张同学)Study on the Potential Speaker-discriminating Power of Individual Speaking Style——In the Perspective of Discourse Information Analysis
GUAN Xin
(Zhaoqing University, Zhaoqing 526061, China)
The current parameters used in the practice of forensic speaker recognition are phonetic auditory and acoustic features that are dramatically influenced by the forensically real conditions. The common and inevitable within-speaker variability in voice casts dramatic influence on the current forensic speaker recognition research and practice, which reduces the validity of voice evidence to a great extent and becomes the primary cause to restrict the development of forensic speaker recognition technology. The newly proposed Cross-Validation method argues that in theory the effect of within-speaker variability could be reduced through the mutual compensation and cross validation between voice and individual speaking style analyses. In this paper, discourse information analysis approach is adopted to extract speaker-discriminating features representing a speaker’s individual speaking style and then the potential speaker-discriminating power of the extracted features is tested, which at the same time presents the evidence of the practice feasibility of Cross-Validation method.
individual speaking style; discourse information; speaker recognition
2016—05—04
关鑫(1974—),女,辽宁辽阳人,讲师,博士,主要研究方向为法律语言学。
1671-6906(2016)05-0014-05
D90-055
A
10.3969/j.issn.1671-6906.2016.05.003
猜你喜欢
小学教学研究·教研版(2022年3期)2022-04-08
空间科学学报(2020年1期)2021-01-14
电子技术与软件工程(2019年24期)2020-01-18
中国交通信息化(2019年12期)2019-08-13
教师·上(2019年11期)2019-02-24
制造技术与机床(2017年11期)2017-12-18
作文世界(小学版)(2017年5期)2017-06-08
中国交通信息化(2017年8期)2017-06-06
新课程·小学(2016年12期)2017-04-20
山东工业技术(2017年5期)2017-03-16
