
基于视觉词袋的视频检索校准方法
2016-11-30 02:07吴连亮蔡鸿明姜丽红
图学学报 2016年1期
吴连亮, 蔡鸿明, 姜丽红
(上海交通大学软件学院,上海 200240)
基于视觉词袋的视频检索校准方法
吴连亮, 蔡鸿明, 姜丽红
(上海交通大学软件学院,上海 200240)
随着互联网技术的飞速发展,视频数据呈现海量爆炸式增长,传统的视频搜索引擎多数采用单一的基于文本的检索方法,该检索方法对于视频这类非结构化数据,存在着内容缺失、语义隔阂等问题,导致检索结果相关度较低。提出一种基于视觉词袋的视频检索校准方法,该方法结合了视频数据的可视化特征提取技术、TF-IDF技术、开放数据技术,为用户提供优化后的视频检索校准结果。首先,基于HSV模型的聚类算法提取视频的关键帧集合及关键帧权值向量;接着用关键帧图像的加速稳健特征等表示视频的内容特征,解决视频检索的内容缺失问题;然后利用TF-IDF技术衡量查询语句
的权值,并开放数据获得查询语句
的可视化特征和语义信息,解决视频检索的语义隔阂问题;最后,将提出的基于视觉词袋的视频检索校准算法应用于Internet Archive数据集。实验结果表明,与传统的基于文本的视频检索方法相比,该方法的平均检索结果相关度提高了15%。
视觉词袋;加速稳健特征;TF-IDF;关键帧提取;开放数据;检索校准
随着互联网的普及,互联网终端设备信息采集能力飞速发展,视频数据量呈现海量增长,如YouTube每天需要处理十亿多的视频流[1],如此庞大的视频内容,也为可视化检索领域的发展带来了一股热潮,同时也面临着如何对如此庞大信息量的视频库进行高效检索的挑战。视频数据属于半结构化数据,检索问题的关键在于如何能有效地分析半结构化数据,并将输入的查询语句与大规模的视频库关联起来。由于成熟的文本检索技术,大量的视频搜索引擎如 Google,Yahoo,YouTube都采用传统的基于文本检索技术,利用与视频相关联的非可视化信息如视频的标题、标签、视频所在网页的文本、用户社交信息等来检索视频,该方法检索效率高,但是忽视了视频内容中丰富的可视化信息,存在着内容缺失、语义隔阂等问题,导致用户检索满意度较低。在基于内容视频检索方面现存的问题,本文拟从检索校准方面研究视频的检索优化方法。
在视频检索校准方面,根据用户提供的检索信息进行分类,视频检索校准[1]大致可分为:基于自我校准、基于实例、基于开放数据、基于用户反馈的 4类检索校准。①基于自校准的检索校准[2-4],主要是从检索结果列表中挖掘校准信息,然后进行聚类,主要的方法有视觉对象识别(object recognition)[2]和图的跳跃(graph walk)[3-4]等,但该类方法对于不准确的初步检索结果有很大的噪声影响。②基于实例的检索校准,需要用户提供输入实例,建立可视化特征映射(visual-object HashMap),主要方法有集合特征验证[5-6]等,但该方法需要预先提供输入实例,用户操作困难[7]。③基于开发数据的检索校准[8],利用开放网络如WikiPedia、搜索引擎、领域知识库,引入开放数据校准检索结果,但该类方法在视频检索领域却很少见相关研究。④基于用户反馈的校准检索[9],根据用户反馈检索相关性信息来校准检索聚类,不断迭代提高检索精度,但是该方法需要用户的频繁参与,实用性较低。
因此本文提出了一种基于视觉词袋(bag of visual words,BOVW)的视频检索校准方法,并结合视频可视化特征提取技术、TF-IDF(term frequency- inverse document frequency)技术、开放数据技术,解决视频检索的内容缺失及语义隔阂问题,提高视频检索结果的相关度,为用户提供一个可扩展的、稳定的、适用性良好的视频检索方案。
1 相关研究
1.1视频关键帧提取
视频数据属于非结构化数据,在视频分析处理过程中,关键帧提取至关重要。文献[10]提出了一种根据MPEG压缩视频流字节码中的macroblock (MB)类型信息,并根据简单的压缩字节流中的MB信息来判断场景变换发生的方法,但该方法不能有效地提取出视频中关键帧。而文献[11]提出了根据颜色直方图HSV分割与合并的方法对视频进行镜头边缘检测,但是该方法同样不能很有效地提取出视频中的关键帧。文献[12]提出了内部相似性聚类分析(inter cluster similarity analysis,ICSA)的方法提取相似帧聚类特征,然后对子类做更进一步的ICSA分析,得到关键帧集合,该方法对关键帧提取效果有很大改进,但该方法并不能应用于实时的对于庞大数据量视频检索校准过程中。文献[13]在解决关键帧提取的工作中,不仅考虑了图片的颜色、形状、光强度、图片噪声的质量属性,还考虑到用户选取关键帧是带有情绪的,所以该研究引入了图片的情绪特征值的概念。文献[14]采用了一个16位的原始关系值和一个由65 536维向量表示的SIFT词袋特征直方图来表示视频帧的特征值,并利用原始关系值和词袋特征直方图的明显变化提取关键帧。该类方法虽然在视频关键帧提取中考虑了不同类型的图像特征,但是大多并不能有效地应用于实时的视频检索校准过程中。
1.2视觉词袋模型
BOVW 模型在视觉领域中可以用于图像归类,将可视化特征映射为单词,该模型建立的步骤为:特征提取、特征描述、特征索引。BOVW模型由一系列的图像特征描述符组成,如SURF、FREAK、BRISK、HOG 描述符等。在视频特征提取过程中,重要的一步是图片的视觉特征提取,文献[15]将BOVW应用到了基于内容的图片检索系统中,其检索过程采用两阶段,第一阶段采用文本检索来过滤,第二阶段采用TOP-SURF 特征值来计算检索结果相关性。文献[16-18]为了降低特征值计算的时间和空间代价,分别提出了Classeme、Meta-class等特征值表示算法来提取图片的视觉特征值。目前BOVW模型在图片检索、网页检索等领域发展迅速,但在视频检索校准领域的应用还不太完善。
1.3基于开放数据的检索校准
在基于开放数据的检索校准领域,文献[8]将微软Bing图像检索引入到了网页检索校准之中,根据比较网页检索结果类表中的图片集合和用Bing搜索得到的TOP-N的图片集合的视觉特征值的相似度,校准网页检索列表。文献[19]将开放知识库Wikipedia引入到视频检索中,并建立起层级概念树,改善了视频检索的语义隔阂问题。但是该方法需要预先建立一个完整的知识库,并且不是所有查询关键字都能映射到一个Wikipedia的页面,所以该方法有一定局限性。
上述提到的视频关键帧提取算法大多关注于追求结果的精确性,并不能很有效地应用于实时的视频检索校准过程中。而且BOVW模型在视频检索校准领域的应用目前也不太完善。基于开放数据的检索校准是一种新颖独特的检索模式,但同样很少被应用于视频检索校准领域。
本文提出的基于BOVW视频检索校准方法的主要贡献为:
(1) 利用加速稳健特征(speed up robust features, SURF)等可视化特征有效地解决了视频检索的内容缺失问题。
(2) 利用开放数据(Bing图像检索,Wikipedia)获得查询语句的可视化特征值和语义信息,间接有效地解决了检索语义隔阂问题。
(3) 结合 TF-IDF、关键帧提取、检索校准等技术优化了视频检索结果,提高了视频检索结果相关度。
2 基于视觉词袋的检索校准方法
2.1方法框架
为了改善基于文本的视频检索结果, 可利用BOVW 模型解决视频检索过程中内容缺失的问题。同时利用开放数据库获得查询语句的可视化特征值和语义信息,解决检索语义隔阂问题。最后,运用检索校准算法校准检索列表。
本文框架的实现流程为:
(1) 将视频的可视化特征转化为图像的可视化特征,其需要提取视频的关键帧集合,并且得到各关键帧的权值。
(2) 利用开放数据(Bing图像检索,显示语义分析方法ESA)获得查询语句的图片检索列表与语义信息,然后获取查询语句的可视化特征值与相似语义关键字,消除查询语句的可视化特征隔阂与语义隔阂。
(3) 离线为所有的视频关键帧创建了一个BOVW,最后再利用第 2步获得的开放图片数据和校准算法来校准检索结果。
该框架的方法流程如图1所示,图1(a)表示传统的基于文本的视频检索方法根据“ferrari”返回的视频检索排列表 r1;图 1(b)表示基于文本的图片检索方法根据
“ferrari”返回的相关图片列表 r2;图 1(c)是本文提出的校准算法应用于r1上得到的校准结果列表r3。
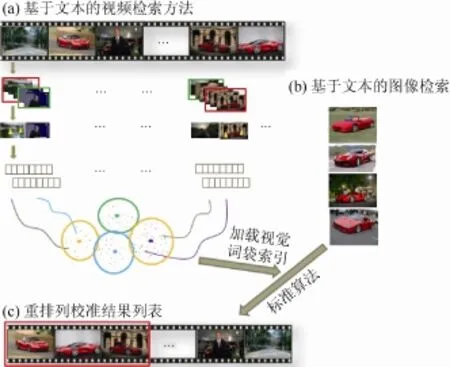
图1 方法示意图
该框架的关键点是如何解决视频检索的内容缺失问题和语义隔阂问题,其可用于大型的视频数据仓库的检索管理应用中。
2.2基于HSV模型聚类算法的视频关键帧提取
在视频关键帧提取过程中,需采用更高效的HSV模型作为特征描述符。HSV颜色空间由hue、saturation、value组成,可以由RGB颜色空间通过如下公式转化而来,r,g,b分别代表图像中RGB的值:
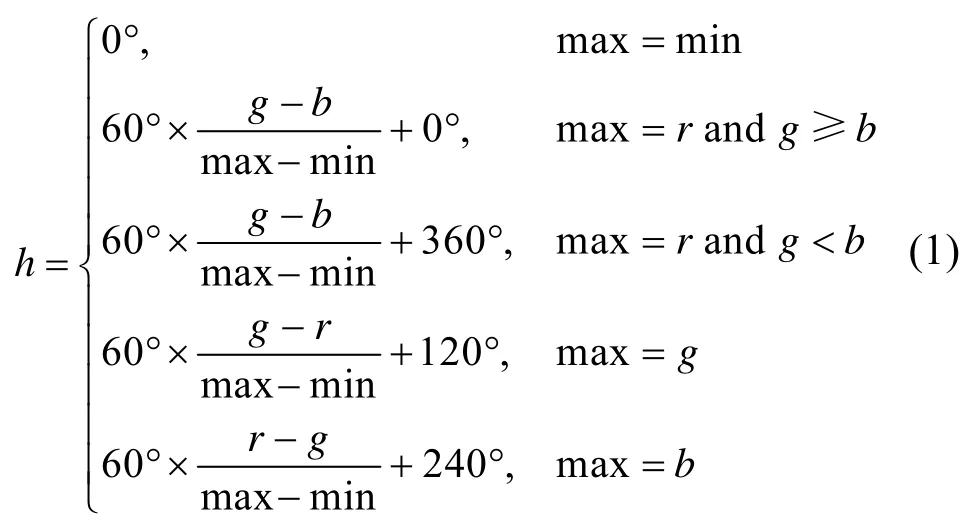
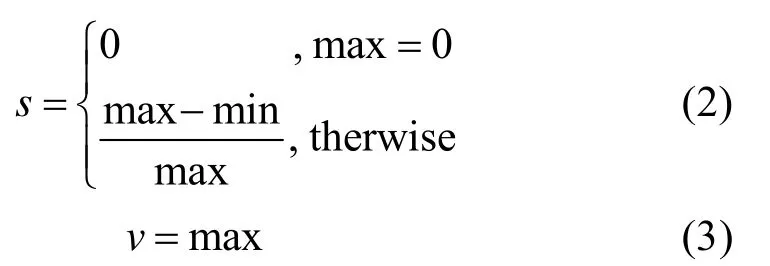
在获取了HSV值后,需采用聚类方法对视频帧集合进行聚类,如图 2所示。经过迭代的聚类过程,然后得到聚类的视频帧集合以及该类的质心,最后选取距离质心最近的帧为关键帧。关键帧的权值设为该类的帧数量占视频总帧数的比值,权值。获得关键帧以及关键帧的权值。假设某视频的关键帧集合为,fn为该视频的第n个关键帧,为关键帧的总数量。算法的基本流程如表1所示。
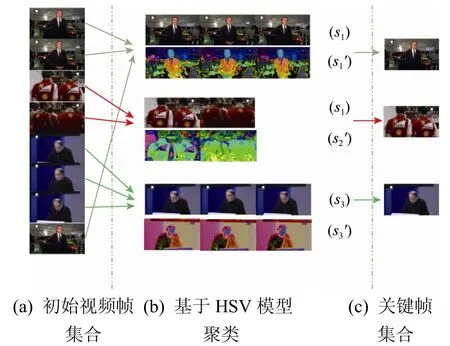
图2 关键帧提取示意图

表1 关键帧提取聚类算法
在关键帧提取过程中,需注意阈值的设定。本文阈值设为HSV平均值的5.2倍,如果设置过大,最后的聚类结果类别数目偏少,提取的关键帧数目也少;如果设置太小,聚类结果类别偏多,关键帧数目多,会造成信息冗余。该方法基于HSV模型,关键帧提取计算效率高,但是对于部分场景如不存在镜头切换、内容过渡平缓的长视频,该方法由于相邻帧的相似度高,聚类数目过少,存在关键帧提取过少的局限。
2.3基于开放数据的语义隔阂处理
本文在视频检索校准过程中,采用传统的基于文本的视频检索结果, 利用BOVW模型解决内容缺失的问题。但当出现初始文本检索结果为空时,如视频库中存在标题名为“龙眼”的视频,但若用“桂圆”检索时,并不能检索出有关“龙眼”的视频。此时出现检索语义隔阂问题,计算机检索过程中不能理解“龙眼”与“桂圆”的相同语义。针对语义隔阂问题,本文采用基于开放数据Wikipedia的显示语义分析方法(explicit semantic analysis,ESA)[20],以解决检索语义隔阂问题。首先基于Wikipedia网站内容,获取检索语句关键字的语义信息。每个关键字的语义表示为一个带权值的高维向量,每一维对应Wikipedia中的一个语义概念。然后通过计算检索关键字(如:“龙眼”和“桂圆”)的语义向量的余弦相似度判断两者的相关性。最后将相关性高的视频结果也纳入初步的文本检索结果,解决检索校准过程的语义隔阂问题。
2.4基于视觉词袋的视频检索校准模型
用一个特征向量来表示对于查询语句返回的第i个视频的特征向量,需要实时计算出传统搜索引擎的检索列表中第i个视频的特征相关度向量,然后根据TOP-N视频的特征相关度向量重排列视频列表。接下来介绍相关度向量f(q,i)的组成。
2.4.1文本特征相关度
文本特征相关度 f(q,i){1,2}由文本相关度得分和文本检索排名得分组成,表示为 f(q,i){1}与f(q,i){2}。f(q,i){1}由TF-IDF方法计算出,表示对于检索语句q,第i个视频的相关得分tfidf(q,d,D)。f(q,i){2}表示i个视频在基于文本的搜索引擎检索结果列表中的排名的得分 Rscoarei。TF-IDF是一种统计方法,用于计算关键字对于某个文档的重要性,本文用于计算查询语句q对于第i个视频的文本描述信息的相关性。n表示关键字t在视频描述文本d中的出现次数。N表示文本搜索引擎视频检索列表需要校准的TON-N数目。表示检索结果列表中包含关键字t的文档数目。
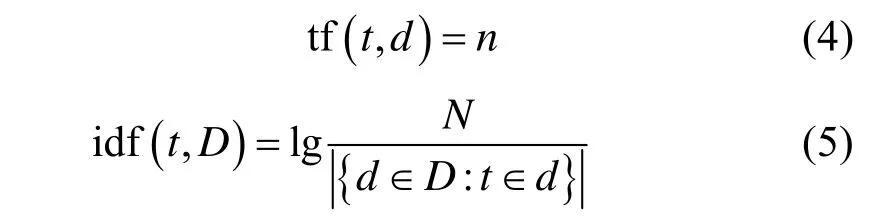

2.4.2可视化特征相关度
本文采用BOVW模型来表示对于查询语句q的第i个视频的可视化特征分别表示局部与全局可视化特征相关度。
通过对视频关键帧的提取,于是得到了查询语句q的第i个视频的关键帧集合S(q,i)=,各个关键帧的权值为,为了建立BOVW,如图3所示,首先需要提取各关键帧的特征描述值,聚类通过K均值聚类方法完成,将特征描述向量迭代聚类到K个类中。每类表示一组类似的特征组合,然后将其定义为一个视觉单词,并将所有视觉词汇汇集成一个视觉词典。图像中的每个特征都将被映射到视觉词典的某个词上,最后图像可描述为一个维数相同的直方图向量,即BOVW。下面介绍利用BOVW模型离线建立视频的局部和全局BOVW的方法。
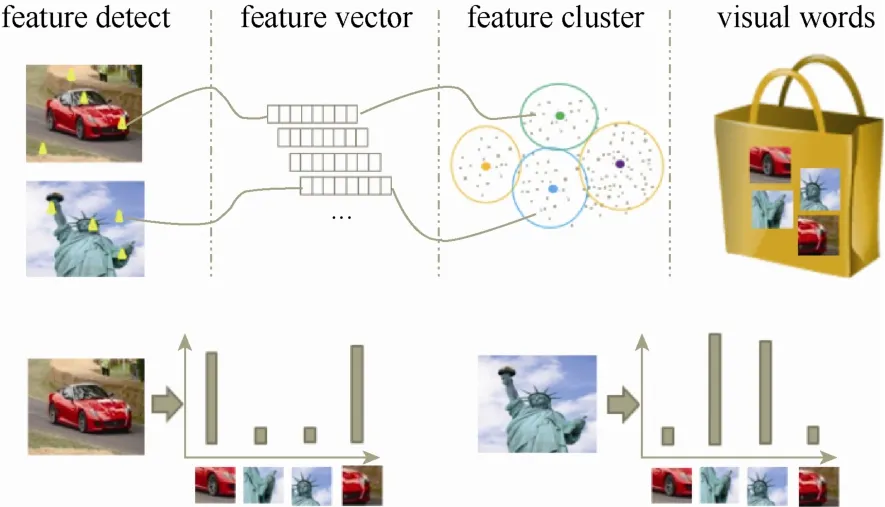
图3 视觉词袋(BOVW)模型
(1) 局部可视化特征相关度。SURF是基于近似的2D离散小波变换响应的一个稳健的图像局部特征描述算法,在本节中,采用SURF方法提取图像的局部特征。局部可视化特征相关度,在这个步骤中可利用2.2节关键帧提取方法得到结果。基于传统的文本视频检索方法,首先返回视频检索列表中的第i个视频Vi,已知其对应的关键帧集合为,权值为。然后在线下利用关键帧的SURF特征对所有视频的关键帧图像建立局部可视化特征的BOVW,该过程可以在后台预先处理。再利用开放数据库,获得 Bing图片搜索引擎根据相同查询语句 q返回的相关图片列表,并利用预先学习得出的BOVW中的单词表示列表r1中每个视频的每一关键帧,同时为其建立索引。最后再使用图片 pt在列表r1的关键帧集合中匹配相似图像,遍历计算每一个视频的每一个关键帧的相似度得分。对于图片pt,视频Vi的第j个关键帧fj的局部可视化特征相似度得分为stij,如图4所示。视频Vi的局部可视化特征相关度得分是对该视频所有关键帧的局部可视化特征相关度得分的求和。表示为Lscore(q,i)计算如下:


图4 局部可视化特征相似度匹配TOP-2结果((b) score = 0.899,(c) score = 0.032)
(2) 全局可视化特征相关度。对于图片pt,视频Vi的第j个关键帧fj的全局可视化特征相似度计算与局部可视化特征相似,但需要改变特征提取公式feature(image),在本节中,采用颜色特征作为图像的全局可视化特征,所以在feature′(image)中提取图像的颜色,颜色空间分布位置作为图像的全局可视化特征描述,如图5所示。视频Vi的全局可视化特征相关度得分是对该视频所有关键帧的全局可视化特征相关度得分的求和。表示为Gscore(q,i),计算如下:
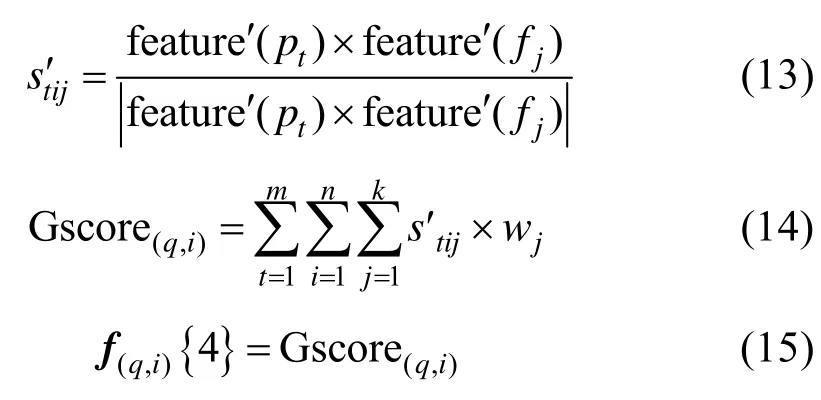
2.4.3基于训练学习的视频检索校准
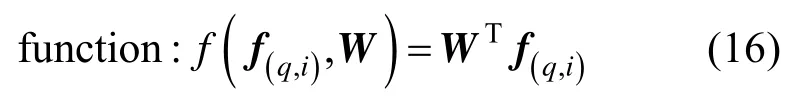
最后将初步检索结果按校准函数计算值进行降序排序,得到视频检索校准列表。

图5 全局可视化特征相似度匹配结果((b)~(f)为相似匹配结果以及全局可视化特征相关度得分)
3 实 验
本文采用的实验数据集为Internet Archive,其为非营利性的数字图书馆,免费提供丰富的数字数据(图像、音频、视频)供研究者使用,所有的视频都经过了人工文本标注,所以可通过基于文本的检索方法检索视频,适合作为本文提出的视频检索校准方法的验证数据集。在实验中,共选取了 5个典型的查询示例作为实验对象,分别为“helicopter”、“beach”、“rose”,“ferrari”,“football”,利用开放图片数据提供的TOP-20的图片结果作为特征匹配样例,系数向量采用经过大量视频数据集训练得出的值W={0.3,0.4,0.4}。在该实验中,将本研究提出的基于 BOVW 的检索校准方法(visual bag based method,TB + VB)与传统的基于文本的检索方法(text based method,TB)和基于信息瓶颈的重排列校准方法(information bottleneck method[21],TB+IB)进行对比,然后对检索返回的TOP-150视频结果手动标注相关和无关,最终使用平均检索相关度比较3种方法的检索效果。3种方法的检索结果相关度对比评估如表 2所示,柱状图对比如图 6所示。在查询示例中,查询目标如果全局特征或局部特征比较明显,查询结果较准确,TB+IB和 TB+VB方法的检索相关度普遍比TB高,主要的原因为在初步的文本查询匹配过程中,由于文本的文字标注大部分与视频内容相匹配,所以在基于文本的查询阶段,检索结果就已经具有比较高的查询相关度了。但是在少数查询示例中,如“football”,由于外部开放数据提供的图片检索样本几乎都是足球样例,而多数视频中的内容却为足球比赛,视频关键帧的背景元素和全局可视化特征会影响校准过程,从而本方法中的可视化特征相关度向量中的全局特征会对检索校准结果带来干扰。这是导致少量检索示例检索相关度较低的主要原因。
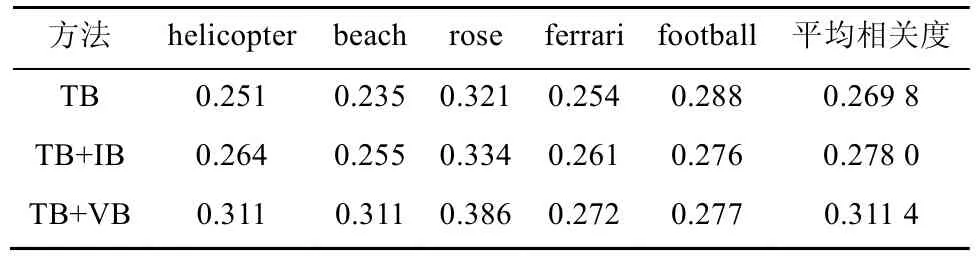
表2 3种方法的检索结果相关度对比
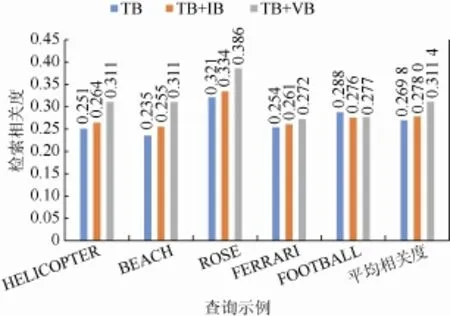
图6 检索结果相关度对比图
图7是用 TB视频检索校准算法检索出来的TOP-8视频结果,并进行了重排列。每张图片代表该段视频的缩略图,可以观察到总体上与“rose”内容相关度低的视频的排列等级被降低,内容相关度高的视频经过校准后排名靠前,而且语义相似度高的也能被检索到并排名靠前。比如图中的“月季”,由于在ESA语义相似性分析结果中与“玫瑰”的语义相似度高,所以检索排名也被校准到检索结果列表中。

图7 查询“rose”的TOP-8视频检索结果校准样例
相比目前主流视频检索平台如优酷的 SOKU平台、YouTube的视频管理器提供的视频检索方式,本文提出的视频检索校准方案能提供基于视频内容及基于开放数据的检索校准方式。特别是在视频无对应文本信息、视频被贴上坏标题等情况下,该方法的性能要明显优于目前主流视频检索平台提供的方法。由于该方法在校准过程中引入了外部开放数据,因此“负向”的外部开放数据的返回结果同样也会干扰校准结果,在后续的研究中将继续探索如何对顶层的返回结果进行除噪。但外部开放数据的引入也更丰富了检索内容的基本信息,对视频类非结构数据的语义填充工作有很大的意义。本文将视频的内容信息和语义信息融合到了视频的检索校准过程中,有效地提高了检索结果的相关度。实验结果显示,与传统的基于文本的视频检索方法相比,本文的平均检索结果相关度提高了15%。
4 结论与展望
互联网技术的发展带来视频信息的爆炸式增长,如何优化视频检索结果是当前非结构化数据检索领域所面临的重大挑战,传统的基于文本的视频检索方法忽略了其所包含的丰富内容信息,用户的检索满意度不高。
本文的主要贡献是提出了基于BOVW的视频检索校准方法,并结合了外部的开放数据和视频的可视化特征来解决视频检索的内容缺失和语义隔阂问题,该方法利用SURF等可视化特征解决视频检索的内容缺失问题,利用开放数据解决检索语义隔阂问题,并结合了TF-IDF、关键帧提取等技术优化了视频检索结果。该方法弥补了传统视频检索方法的不足,提高视频的检索结果相关度。在大多数检索示例中都表现良好,但是在小部分示例中,由于特征值提取困难,会反向干扰检索校准结果,引入其他的视觉特征值可能会提高校准结果,这也是下一步的研究工作。同时基于文本的检索结果也会给后续的检索校准带来噪声传递,所以需结合传统搜索引擎的优势,减低噪声传递,同时扩充视频数据集合,提高参数训练精度,完善BOVW模型中的视觉词典,优化查询语句关键字切分粒度,继续优化视频检索校准结果。
[1] Mei T, Rui Y, Li S P, et al. Multimedia search reranking: aliterature survey [J]. ACM Computing Surveys (CSUR), 2014, 46(3): 38: 1-38: 38.
[2] Wnuk K, Soatto S. Filtering internet image search resultstowards keyword based category recognition [C]// Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on. IEEE, 2008: 1-8.
[3] Hsu W H, Kennedy L S, Chang S F. Video search reranking through random walk over document-level context graph [C]//Proceedings of the 15th International Conference on Multimedia. ACM, 2007: 971-980.
[4] Jing Y S, Baluja S. Applying pagerank to large-scale image search [J]. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2008, 30(11): 1877-1890.
[5] Hervé J, Douze M, Schmid C. Improving bag-of-features for large scale image search [J]. International Journal of Computer Vision, 2010, 87(3): 316-336.
[6] Zhou W G, Lu Y J, Li H Q, et al. Spatial coding for large scale partial-duplicate web image search [C]// Proceedings of the International Conference on Multimedia. ACM, 2010: 511-520.
[7] 刘浏. 基于内容的重排列视频检索技术研究[D].上海: 上海交通大学, 2013.
[8] Rodriguez-Vaamonde S, Torresani L, Fitzgibbon A. What can pictures tell us about web pages?: improving document search using images [C]//Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2013: 849-852.
[9] Tian X M, Tao D C, Hua X S, et al. Active reranking for web image search [J]. Image Processing, IEEE Transactions on, 2010, 19(3): 805-820.
[10] Pei S C, Chou Y Z. Efficient MPEG compressed video analysis using macroblock type information [J]. Multimedia, IEEE Transactions on, 1999, 1(4): 321-333.
[11] Guru D S, Suhil M. Histogram based split and merge framework for shot boundary detection [M]//Mining Intelligence and Knowledge Exploration. Springer International Publishing, 2013: 180-191.
[12] Priya G G L, Domnic S. Shot based keyframe extraction for ecological video indexing and retrieval [J]. Ecological Informatics, 2014, 23(9): 107-117.
[13] Ratsamee P, Mae Y, Jinda-Apiraksa A, et al. Lifelogging keyframe selection using image quality measurements and physiological excitement features [C]//Intelligent Robots and Systems (IROS), 2013 IEEE/RSJ International Conference on. IEEE, 2013: 5215-5220.
[14] Chiu C Y, Tsai T H, Han G W, et al. 2013. Efficient video stream monitoring for near-duplicate detection and localization in a large-scale repository [J]. ACM Transactions on Information Systems (TOIS), 2013, 31(4): 22.
[15] Zagoris K, Chatzichristofis S A, Arampatzis A. Bag-of-visual-words vs global image descriptors on two-stage multimodal retrieval [C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2011: 1251-1252.
[16] Karakasis E G, Amanatiadis A, Gasteratos A, et al. Image moment invariants as local features for content based image retrieval using the Bag-of-Visual-Words model [J]. Pattern Recognition Letters, 2015, 55: 22-27. [17] Torresani L, Szummer M, Fitzgibbon A. Efficient object category recognition using classemes [M]//Computer Vision–ECCV 2010. Springer Berlin Heidelberg, 2010: 776-789.
[18] Bergamo A, Torresani L. Meta-class features for large-scale object categorization on a budget [C]// Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012: 3085-3092.
[19] Tan S, Jiang Y G, Ngo C W. Placing videos on a semantic hierarchy for search result navigation [J]. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 2014, 10(4): 37.
[20] Gabrilovich E, Markovitch S. Computing semantic relatedness using wikipedia-based explicit semantic analysis [C]//IJCAI’07 Proceedings of the 20th International Joint Conference on Artificial Intelligence. Morgan Kaufmann Pubishers Inc, San Francisco, CA, USA, 2007, 1606-1611.
[21] Hsu W H, Kennedy L S, Chang S F. Video search reranking via information bottleneck principle [C]// Proceedings of the 14th Annual ACM International Conference on Multimedia. ACM, 2006: 35-44.
Using Bag of Visual Words for Video Retrieval Calibration
Wu Lianliang,Cai Hongming,Jiang Lihong
(School of Software, Shanghai Jiao Tong University, Shanghai 200240, China)
With the rapid development of Internet technology, the number of videos is proliferating in an exploding way. The traditional text-based retrieval method may bring problems of content missing and semantic gap, and result in lower retrieval relevance score. Therefore, a video retrieval calibration method is proposed, which is based on bag of visual words and combines the visual features extraction technology, TF-IDF technology and the open data technology. First, the HSV-based clustering algorithm is used to extract the video key frames and the weight vector. Second, speed up robust features and some other visual features are used to resolve video content missing problem. Third, the TF-IDF technology is used to measure the weight of keyword, and the open data technology to obtain the visual features and semantic of the query word, then solve the semantic gap problem. Finally, our video retrieval calibration algorithm is applied on the Internet Archive data set. The result shows that compared with traditional text-based video retrieval method, our method has a 15% relative improvement on the average retrieval relevance score.
bag of visual words; speed up robust features; TF-IDF; key frame extraction; open data; video retrieval calibration
TP 391
10.11996/JG.j.2095-302X.2016010066
A
2095-302X(2016)01-0066-08
2015-06-24;定稿日期:2015-08-11
国家自然科学基金项目(61373030,71171132);上海市自然科学基金项目(13ZR1419800)
吴连亮(1991–),男,江西上饶人,硕士研究生。主要研究方向为信息可视化、多媒体检索技术。E-mail:wulianliang@sjtu.edu.cn
蔡鸿明(1975–),男,贵州盘县人,副教授,博士。主要研究方向为CAD/CG、信息集成技术。E-mail:hmcai@sjtu.edu.cn
猜你喜欢
重庆科技学院学报(自然科学版)(2022年6期)2022-02-04
微型电脑应用(2020年12期)2020-12-25
开放教育研究(2020年2期)2020-03-31
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
图学学报(2018年3期)2018-07-12
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
专利代理(2016年1期)2016-05-17
长江学术(2016年4期)2016-03-11
