
基于日志数据分析算法的异常检测研究
2016-11-12 07:50张亮赵娜
微型电脑应用 2016年3期
张亮,赵娜
基于日志数据分析算法的异常检测研究
张亮,赵娜
为了维护现在复杂的软件系统,快速准确定位故障点,就需要及时发现和分析异常点。目前最为常用的方法就是通过合理的算法,从系统日志中寻找异常点。介绍了对结构化和非结构化的日志处理采样,去除噪声数据并使用监督学习和无监督学习的方法来进行异常检测,通过各种算法和其改进提高检测的效率和准确率,并用对比实验进行验证得出结论。
日志;子空间;结构化;贝叶斯
0 引言
庞大的信息系统进入高度自动化之后,系统维护仅仅依靠人力就远远不够。利用系统产生的大量日志和事件记录查找系统运行中的问题是常使用的方法。但是系统自动记录的日志文件常常存在过多无效信息或者存在管理者根本不需要关注的过多细节,甚至很多日志都是非结构化的,无法靠人力进行分析。如何从这些数据中发现系统异常就是目前面临的一个问题。
基于日志分析算法的异常检测[1]法分为基于监督的学习的和基于无监督的学习两类。
1 基于监督学习的日常检测
基于监督学习[2]的方法就是判断一个事件、一个操作是“正常”还是“异常”,例如在Windows服务器系统中,每个域或组管理员都有不同的权限,如果有的用户企图获得更高的权限,那么这个操作就是“异常”的。利用收集到的“正常”和“异常”日志数据[3],就可以创建有类别的训练数据。用训练算法训练得到一个分类器,对未知用户操作进行判断。基于监督学习的方法就是一个分类函数:
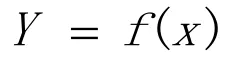
x是一个或一段日志,y∈{0,1},y=0表示“正常”,y=1表示“异常”。
日志文件通常分为结构化日志和无结构化日志。例如Windows系统日志[4]是结构化的,Linux下的日志[5]是无结构化的。如何对两种不同的日志进行分析判定呢?
1.1结构化日志
截取以下日志数据
process=“hriuhg.com”
cpu=68%
memory=256
san=3456
end=6789
使用贝叶斯学习。x、y表示成不相关的属性集合得到
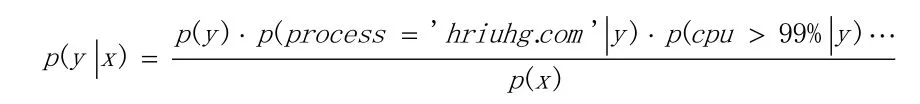
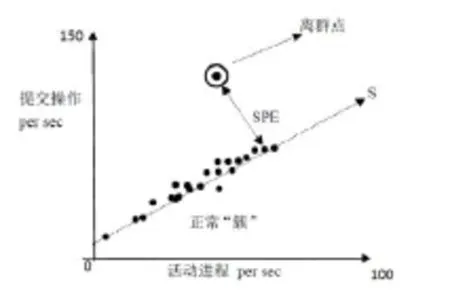
其中x是给定的,那么P(X)就是常量。各属性值(cpu,memory……)也是定量,只有y是变量。观察分子中各项概率,p(y=0),p(y=1),p(process=“hriuhg.com” |y=0),p(process=“hriuhg.com” |y=1),在训练数据中计算可得。最终从结果中看,如果p(y=0|x) 1.2无结构化日志事件 我们截取某VPN系统无结构化日志片段 Thu Mar 26 12:46:50 2015 tread_id:0x979798 ThuMar2612:46:502015SocketBuffers:R=[8192->8192] S=[8192->8192] Thu Mar 26 12:46:50 2015 TCPv4_CLIENT link local: [undef] Thu Mar 26 12:46:50 2015 TLS: Initial packet from 124.129.172.46:1194,sid=8ad7ba9c 43791f63 Thu Mar 26 12:46:51 2015 VERIFY OK: depth=1, Thu Mar 26 12:46:51 2015 Data Channel Encrypt: Cipher 'BF-CBC' initialized with 128 bit key 根据时间判断这些日志[6]是一个事件,可以表示为一堆令牌: tread_id,Socket Buffers,TCPv4_CLIENT link local,TLS,VERIFY OK,Data Channel Encrypt 用贝叶斯分类函数表示为: 其中p(y|x)表示x在y类别中出现的概率。 这里要进行数据处理,处理掉无意义数据,加重重要数据出现时的计算权重。 a抽取出现次数低的数据删除,这些是噪声数据。比如id:0x979798只是序号,未来出现的很少,计算概率没有意义,做删除操作。 b因为贝叶斯分类中,所有的属性的是离散的,但是某些数据是非常有用的,只是要用到划分区间法。比如数据吞吐量突然变大,系统通常是有异常,可把吞吐量划分为高、中、低三档,加重高档异常发生概率的估算。 c加重异常发生概率的估算,比如error、exception等通常代表发生异常。 对于训练数据集的收集有不小的难度,我们还可以采用异常点判定的办法检测,就是通过聚类分析找出远离类簇的数据点,这种方法就是基于无监督学习[7]-[8]的异常检测。 实际数据集分析的难度很大,主要难度在于高纬度数据集中,数据点的分布可能十分稀疏,离群点的寻找一般通过子空间内进行如图1所示: 图1 子空间内的离群点检测 在图1中,X所示我们抽取时间的两个维度,活动的读写进程数和读写操作提交的速率。显然在正常情况下两者是线性关系。从图1中可知,把数据线行变化到S子空间——投影到S法线后,就能轻易发现,大部分数据落在S直线周围。远离S的点就是异常点,距离S的距离越长异常的可能性越大。原始数据是二维的,子空间的维度要更低一些。 2.1子空间聚簇分析 寻找子空间的基本前提是绝大部分日志事件都是正常情况,异常事件是极少数。子空间的聚类分析有两种方法。 一是假定子空间的坐标轴是和原始空间并行的,那么垂直投影可以获得子空间。设原始空间是 m维度的,那么任意{1,2,……m}的子集都可以构成子空间,可能性为2m。我们在高维度空间找到一个聚簇,那么无论怎么并行投影到一个子空间内,这个聚簇内的数据点在子空间内依旧是一个聚簇。假设空间T是m维度的,任意两个点x=(x1,……,xm)T和y=(y1,……,ym)T如果在一个聚簇内,既满足 其中∈是簇内距离最大的阈值,那么在其子空间{i1,……,ip}⊆{1,……,m}也存在 这里我们用维度集合来表示一个空间,其超集称为超空间,其子集称为子空间。子空间搜索可以用自底向上法,先从低维度空间找聚簇,如果一个低维度空间不存在聚簇,那么其超空间也不存在聚簇,即可停止搜索。也可以用自顶向下法,先找出存在聚簇的空间,其子空间也肯定存在聚簇,然后再继续寻找不存在聚簇的空间的子空间集。 二是严格按照线性代数描述的线性子空间这种线性子空间可以由任意一个线性变换矩阵得到。例如m维空间中的一个数据点x=(x1,x2,……xm)T,R是一个r*m矩阵,1≤r≤m,那么x投影到子空间内就是Rx,Rx是一个m维度的数据点。因为矩阵 R可以有无穷多个,所以这种线性子空间的数量是无穷多个。我们通过加入限制条件和规则来限制可能的子空间。 2.2PCA法和GPCA法 PCA 法[9]-[10]主要目的有两个:第一,进行数据降维;第二,进行数据特征提取。 PCA方法的实现步骤如下: (1)将原始数据按列组成n行m列矩阵X; (2)将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值; (3)求出协方差矩阵S; (4)求出协方差矩阵S的特征值; (5)对特征向量进行单位正交化,按大小从上到下排列矩阵; 6)取前k行组成矩阵P,Y=PX即为降维到k维后的数据。 GPCA算法的主要思想是一个线性子空间在原始空间内就是一个线性方程,那么n个线性子空间用n个线性方程表示。PCA是寻找一个维度的子空间,GPCA是寻找多个维度的子空间。,其中hi是一个k元的系数。如果一个数据点落在某个子空间,这个数据点满足: GPCA的目的是求出系数 h1,……,hn。由于数据点不可能都落在某个平面,这实际上是一个最小化问题,找到k元系数h1,……,hn,使其能够最小化。 数据点集。 几种方法的参照实验 本文用GPCA法做了5次实验,异常发现的正确率分别为92.5%,93.2%,91.6%,94.5%,93%,取其平均值92.96%。 实验结果比PCA法的84.72%要高出不少。 为了确定这些算法的可信度,在相同的实验条件下(硬件一致,系统每次恢复初始状态,未运行其他程序)用 3种方法进行了对比试验,如表1所示: 表1 几种方法的实验数据对比 通过实验可以看出,GPCA发现的异常点正确率较高,但是为何无论算法如何改进也无法没有达到100%正确呢。这是因为日志中有些虽然不常见,但不是真正的异常点。这样无论算法多精确,找出的离群点多准确也并不能提高识别的正确率。 本文主要介绍的是如何通过对日志文件的分析研究进行异常检测的方法,针对结构化或者非结构化的日志,讨论了基于监督学习的日常检测和基于非监督学习的异常检测。并在同一实验环境下对几种方法进行了对比试验,研究了误差产生的原因。如何进一步改进算法提高正确率将是下一步要做的工作。 [1] 朱应武,杨家海,张金祥.基于流量信息结构的异常检测[J].软件学报,2010,21(10):2573-2583 [2] 李奕,吴小俊.基于监督学习的Takagi Sugeno Kang模糊系统图像融合方法研究[J].电子与信息学报,2014,36(05):1126-1132 [3] 王自挺.基于系统日志的软件性能测试的设计与实施[D].上海:上海交通大学,2010:13-21 [4] 杨锋英,刘会超.面向Windows平台的日志远程采集系统研究[J].河南科学,2014,32(02):189-194 [5] 吴广君,王树鹏,陈明,李超.海量结构化数据存储检索系统[J].计算机研究与发展,2012,39(Suppl.):1-5 [6] 唐涛.基于搜索引擎日志分析的网络舆情监测方法研究[J].情报杂志,2012,31(08):27-30 [7] 刘伟峰,杨爱兰.基于BIC准则和Gibbs采样的有限混合模型无监督学习算法[J].电子学报,2011, (3A):134-139 [8] 刘伟峰,韩崇昭,石勇.修正 Gibbs采样的有限混合模型无监督学习算法[J].西安交通大学学报,2009,43(02):15-19 [9] 刘嵩.基于特征融合的人脸识别[J].湖北民族学院学报(自然科学版),2011,29(02):188-190 [10] 常飞.基于实时数据的动态异常检测方法研究[D].天津:天津理工大学,2013:10-21 Research on Anomaly Detection Based on Log Data Analysis Algorithm Zhang Liang1,Zhao Na2 In order to maintain the current complex software systems and locate the point of failure quickly and accurately,it needs to detect and analyze outliers. Currently the most common method is to look for outliers from the system log through a reasonable algorithm. This paper describes the structured and unstructured log processing samples and removes the noise data. Supervised learning and unsupervised learning approaches are used to do anomaly detection. Through a variety of algorithms and their modifications,it improves the efficiency and accuracy of the detection,and is verified by comparison experiments concluded. Log; subspace; structuring; Bayesian TP393 A 1007-757X(2016)03-0042-03 高等教育研究基金(GJK201502) 张 亮(1981-1),男,汉族,江苏启东,中国石油大学(华东),硕士,工程师,研究方向:计算机信息和网络技术,青岛,266500赵 娜(1981-11),女,汉族,山东文登,中国石油大学(华东),硕士,工程师,研究方向:安全工程信息化技术方面的研究,青岛,266500 (2015.11.21)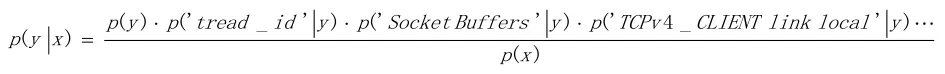
2 基于无监督学习的日常监测

3 总结
(1.Network Information Center,China University of Petroleum (East China),Shandong 266500,China; 2.Construction Quality Supervision Station,Huangdao District,Qingdao City,Shandong 266500,China)
猜你喜欢
当代陕西(2022年4期)2022-04-19
华人时刊(2021年13期)2021-11-27
河北理科教学研究(2021年4期)2021-04-19
军民两用技术与产品(2021年2期)2021-04-13
心声歌刊(2020年4期)2020-09-07
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
中华诗词(2019年7期)2019-11-25
思维与智慧·上半月(2018年9期)2018-09-22
小学生(看图说画)(2017年6期)2017-11-06
